Links: arXiv:2604.08995 · Project · Code · HF Model
相关笔记:Matrix-Game 2.0 - An Open-Source, Real-Time, and Streaming Interactive World Model、RELIC - Interactive Video World Model with Long-Horizon Memory、HY-World 2.0 - A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds、Lingbot World。
1. Motivation (研究动机)
- 现有方法的问题:短视频 Diffusion / DiT 模型可以生成高质量 clips,但大多是 offline generation,没有显式 action control,也没有真实 streaming 场景所需的 long-horizon memory。Matrix-Game 2.0、HY-Gamecraft-2 等 open works 已能做 causal few-step streaming,但缺少长期记忆;RELIC / WorldPlay 等 memory-augmented 方法提升长程一致性,却引入额外计算,难以同时达到 720p high-resolution + real-time FPS;Genie-3 等闭源系统展示了 720p interactive world simulation,但训练 recipe、compute budget、inference stack 不公开。
- 本文要解决的具体问题:构建一个可部署的 interactive world model,同时满足三件事:action-conditioned controllability、minute-level memory consistency、720p real-time streaming generation。具体目标是让 5B 模型在 720p 达到最高约 40 FPS,并让模型在用户走回旧视角时能恢复早先看过的 scene layout / objects / textures。
- 为什么值得研究:如果这个三角同时成立,视频生成模型就能从“离线生成片段”变成“可交互的世界模拟器”,用于游戏/XR/film previs、robotics planning、embodied AI simulation 和工业数据引擎。它要求数据、模型训练和推理系统协同设计,而不是单独扩大模型或单独压缩推理。
2. Idea (核心思想)
核心洞察是:实时 interactive world model 的瓶颈不是单一的帧质量,而是训练时就要让模型面对“自己生成的、有误差的历史与记忆”,并在推理时用 camera-aware memory 选择最相关的历史视角。 Matrix-Game 3.0 因此把 long-horizon consistency 分解成两层:base model 用 error buffer 学自纠错,memory model 用相机几何检索旧帧并在同一个 DiT self-attention 空间里融合 memory / past / current tokens。
关键创新包括三部分:第一,工业级 data engine 产出 Video–Pose–Action–Prompt quadruplets,覆盖 UE5 synthetic、AAA games 和 real-world data;第二,memory-augmented bidirectional DiT 把 retrieved memory latents、recent history latents、current noisy latents 联合建模,并加入 relative Plücker / temporal RoPE jitter;第三,用 multi-segment DMD distillation 对齐训练与 streaming inference,再叠加 INT8 DiT、MG-LightVAE pruning、GPU retrieval 和 async VAE decoding 达到实时。
与 Matrix-Game 2.0 的根本差异:2.0 重点解决 real-time streaming action control,但长程回访时缺少显式记忆;3.0 在同一系列上补上 camera-aware memory 和 error-aware training。与 RELIC / memory KV cache 类方法相比,3.0 不把 memory 当外部分支反复 cross-attend,而是把 memory latents 放进同一 DiT self-attention 序列,减少特征错配和收敛困难。与 Lingbot-World 这类长 context scaling 相比,3.0 重点是检索与系统级部署,而不是单纯拉长上下文。
3. Method (方法)
3.1 Overall framework:data–model–deployment co-design

Figure 1 解读:图 1 展示 Matrix-Game 3.0 的核心卖点:输入用户 prompt 和 action,模型可以在 0s、20s、40s、60s 的长序列中持续生成,并通过 spatial memory / temporal frames 维持旧场景记忆。图中强调 720p 最高 40 FPS 的实时交互性能,以及多样化生成能力。

Figure 2 解读:图 2 是系统总览。左侧 Data Engine 用 Unreal Engine / AAA games / real videos 产生长视频、动作、相机 pose;中间 Model Training 是带 error buffer 与 memory 的 DiT;右侧 Inference Deployment 用 few-step sampling、quantization、VAE pruning 加速,输出 5B model 720p@40FPS。它不是单个模型模块,而是从数据到部署的端到端 co-design。
3.2 Error-aware interactive base model

Figure 3 解读:图 3 展示 base model 的 error collection / error injection。输入序列被分成 past frames 和 current frames;current frames 加噪后由 bidirectional DiT 预测,模型输出的 clean estimate 与 ground truth 的残差进入 error buffer;随后从 error buffer 采样残差注入 past latent,模拟推理时 self-generated history 的误差。
令 latent 序列为 ,前 帧为 history,后 帧为 current prediction target。模型先从 predicted flow 还原 clean estimate ,收集残差:
训练时从 error buffer 采样 ,扰动历史 latent:
并只在 current latent group 上施加 flow-matching objective:
其中 是 action condition。键盘离散动作通过 dedicated Cross-Attention 注入,鼠标连续控制通过 Self-Attention 影响当前视觉状态;这沿用 Matrix-Game 2.0 / GameFactory 的 action module 思路。
直觉段落:长视频 drift 的根源是 train–test mismatch:训练看到 clean history,推理只能看到自己生成的 history。error buffer 的作用不是简单加噪,而是把模型真实会犯的 prediction residual 作为 perturbation 重新喂回条件分支,让 base model 学会在“略脏”的上下文中恢复正确轨迹。这样 few-step distilled student 才能从 base model 得到更接近真实 streaming inference 的 target。
3.3 Camera-aware long-horizon memory

Figure 4 解读:图 4 展示 memory-augmented base model。模型不只输入 recent past frames,还会根据当前相机视角检索 memory frames;memory、past、noised current frames 被拼到同一个 DiT 序列里做 self-attention。error buffer 同时污染 memory 和 history,使训练条件更接近推理时的 imperfect contexts。

Figure 5 解读:图 5 是 frame-level self-attention 可视化。即使 memory frames 距离 current prediction 很远,模型仍对 retrieved memory 给出非忽略的 attention 权重,说明 head-wise RoPE perturbation 没有压制长期记忆访问,反而缓解了远距离 RoPE 周期性混叠。
Memory 训练同样收集 residual,但覆盖 memory / history / current 三类 latent。对任意 latent :
扰动 history 和 memory:
Memory-enhanced objective 为:
其中 是 geometric condition。相机检索使用 pose / frustum overlap 选择当前 view 最相关历史帧;推理时还可保留第一帧 latent 作为 persistent sink,给全局风格和外观统计提供 anchor。
RoPE jitter 使用 head-wise perturbed rotary base:
其中 是 head-dependent perturbation coefficient。实验设置里 , 在 attention heads 间线性分布。
3.4 Multi-segment DMD few-step distillation

Figure 6 解读:图 6 展示 distilled student 的 multi-segment rollout。每个 segment 从 noise 开始,当前 segment 的 past frames 来自上一 segment 的 tail,memory 从 online memory pool 按当前 camera viewpoint 检索。训练不会只看单段 ground-truth history,而是随机停在某个 self-generated segment,把最后一段送入 teacher / critic 做 distribution matching。
DMD objective 近似 reverse KL 的梯度:
其中 是 memory, 来自上一 segment 结尾。关键点是:student 的训练轨迹模拟实际 few-step streaming inference,因此减少用 ground-truth past frames 训练带来的 exposure bias。
3.5 Real-time inference:INT8 / MG-LightVAE / GPU retrieval / async decoding
推理端使用三个主要加速组件:
- INT8 DiT quantization:只量化 DiT attention projection layers(repo 中
q/k/v/o),保留 FFN、VAE、text encoder 的原精度;实现改自 LightX2V。 - MG-LightVAE:缩小 decoder hidden dims,不改总体架构;50% / 75% pruning 分别提供约 / decode speedup;repo 默认
mg_lightvae_v2对应 75% pruning。 - GPU memory retrieval:CPU 精确 frustum intersection 太慢;GPU 版使用采样近似估计 overlap。
Memory retrieval 选择:
CPU 精确 overlap:
GPU 近似 overlap:
3.6 Data engine:Video–Pose–Action–Prompt quadruplets

Figure 7 解读:图 7 展示 data engine 的场景与 agent trajectories。数据不是单一游戏或单一 web dataset,而是 UE5 synthetic、AAA games、real-world video 的组合;核心是同时记录 video、pose、action、prompt,使 interactive world model 能学到 action-conditioned dynamics 和可检索的相机几何。
Unreal-Gen 的单帧同步数据为:
其中 是 RGB, 是 player position/rotation, 是 camera 6-DoF pose, 是 discrete action vector。AAA game 数据中,WSAD 动作由位置增量投影到相机局部坐标推断:
系统声称 AAA game recording 的总体数据精度超过 99%,最终 filtering 移除 20% raw data。
3.7 Qualitative outputs and memory behavior

Figure 8 解读:图 8 展示 interactive base model 的 action controllability。每一列是连续时间帧,action symbol 表示当前操作;画面展示角色/相机响应,同时背景没有明显漂移。

Figure 9 解读:图 9 是 controlled scene revisitation:后半段 action 反向,让相机回到先前区域。成功恢复红框中的局部 geometry、object configuration 和 facade / texture details,说明结果不能只靠短期 continuity,而需要 long-range memory retrieval。
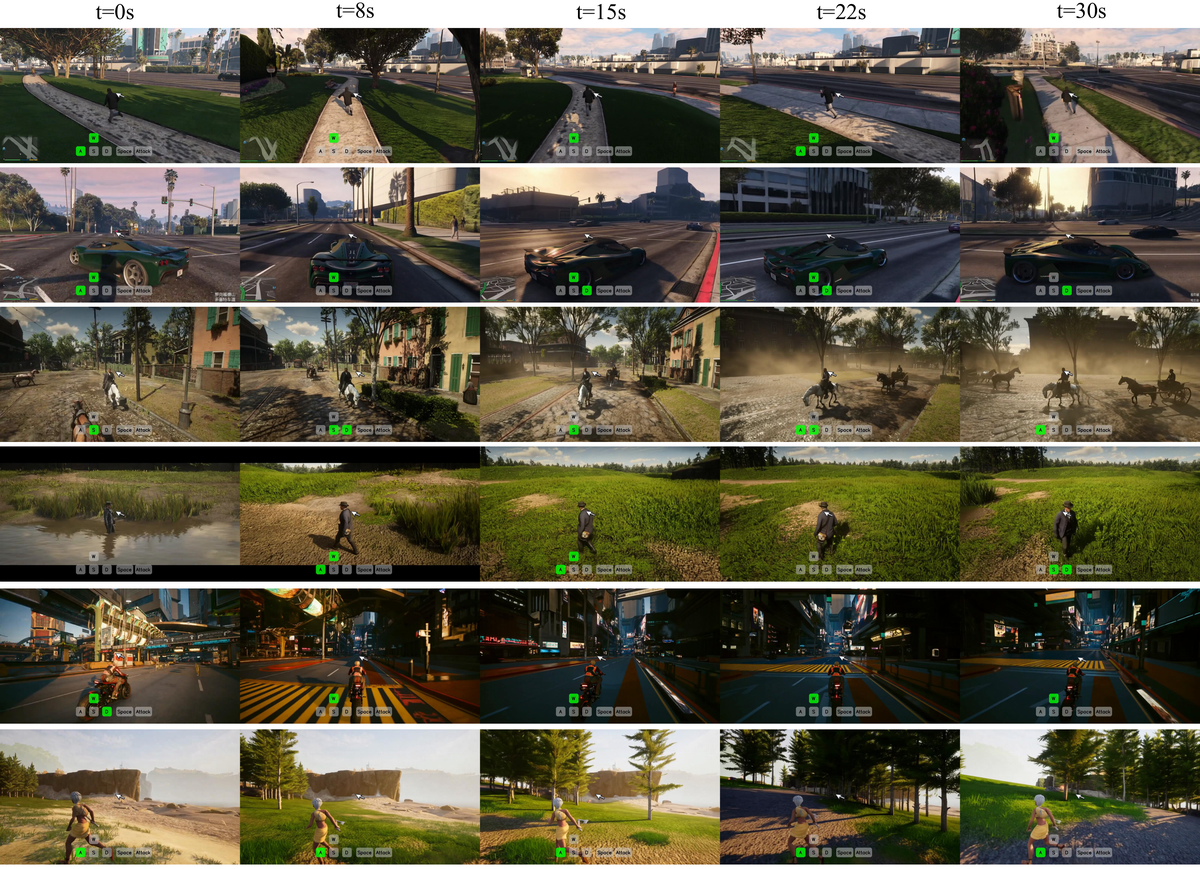
Figure 10 解读:图 10 展示 28B model 在 third-person AAA / Unreal scenes 上的长程生成。相较 5B real-time release,28B 侧重质量、dynamics 和 generalization,覆盖 outdoor exploration、urban driving、horseback traversal、night riding 等复杂动作与场景。

Figure 11 解读:图 11 展示 distilled model 的长程输出。动作序列刻意让模型回访多个视角,distilled student 仍能继承 memory-augmented base model 的能力:之前出现后被遮挡的内容在后续帧可恢复,新出现区域也没有明显 style drift。

Figure 12 解读:图 12 对比原始视频与 50% pruned MG-LightVAE reconstruction。视觉上主体结构和内容保持较好,对应 Table 2 中 PSNR 从 33.79 降到 31.84,但 decoder-only time 从 0.76s 降到 0.30s。
3.8 Pseudocode:基于官方开源 inference code 与论文训练描述
代码搜索结果:官方 repo
SkyworkAI/Matrix-Game已开源Matrix-Game-3推理、模型结构、action module、camera memory retrieval、INT8/LightVAE/async VAE pipeline;本次检索未在 repo 中发现 error-buffer base training、DMD distillation training、data engine 生产代码,因此这些训练部分的 pseudocode 标注为 paper-derived,源码映射只锚定已开源部分。
(a) Error-aware base / memory training sketch(paper-derived;training code 未开源)
class ErrorBuffer:
def __init__(self, max_size=8192):
self.storage = []
self.max_size = max_size
@torch.no_grad()
def push(self, residual):
self.storage.append(residual.detach().flatten(0, 1).cpu())
self.storage = self.storage[-self.max_size:]
def sample_like(self, x):
bank = torch.cat(self.storage, dim=0).to(x.device, x.dtype)
idx = torch.randint(0, bank.shape[0], (x.shape[0] * x.shape[1],), device=x.device)
return bank[idx].view_as(x)
def error_aware_flow_train_step(model, batch, error_buffer, optimizer,
gamma_h=1.0, gamma_m=1.0, use_memory=True):
# x: [B, N, C, H, W] video latents; split into memory, past, current targets.
x = batch["latents"]
memory = batch.get("memory_latents") if use_memory else None
past, current = x[:, :batch["k"]], x[:, batch["k"]:]
noise = torch.randn_like(current)
t = torch.rand(current.shape[0], device=current.device)
x_t = (1.0 - t.view(-1, 1, 1, 1, 1)) * current + t.view(-1, 1, 1, 1, 1) * noise
if len(error_buffer.storage) > 0:
past = past + gamma_h * error_buffer.sample_like(past)
if memory is not None:
memory = memory + gamma_m * error_buffer.sample_like(memory)
# The DiT sees imperfect history + noised current in one window; loss is sliced to current frames.
model_input = torch.cat([past, x_t], dim=1)
t_full = torch.cat([torch.zeros_like(t).repeat_interleave(past.shape[1]).view(t.shape[0], past.shape[1]),
t[:, None].expand(-1, current.shape[1])], dim=1)
pred_full = model(
x=model_input, t=t_full, x_memory=memory,
mouse_cond=batch["mouse_cond"], keyboard_cond=batch["keyboard_cond"],
plucker_emb=batch.get("plucker_emb"),
)
pred_flow = pred_full[:, past.shape[1]:] # Eq. (3)/(6): supervise current frames only.
target_flow = noise - current
loss = F.mse_loss(pred_flow, target_flow)
with torch.no_grad():
x0_hat = x_t - t.view(-1, 1, 1, 1, 1) * pred_flow
error_buffer.push(x0_hat - current) # Eq. (1)/(4): residual collection.
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
return loss.item()(b) Streaming generation loop:pipeline/inference_pipeline.py::MatrixGame3Pipeline.generate
def generate_streaming_video(pipeline, prompt, pil_image, args):
text_cond = pipeline.text_encoder([prompt], device=pipeline.device)
neg_cond = pipeline.text_encoder([pipeline.config.sample_neg_prompt], device=pipeline.device)
current_image, extrinsics_all, keyboard_all, mouse_all = get_data(
num_frames=57 + (args.num_iterations - 1) * 40,
height=args.height, width=args.width, pil_image=pil_image,
device=pipeline.device, dtype=torch.bfloat16,
)
img_cond = pipeline.vae.encode([current_image[0]])[0].unsqueeze(0)
all_latents = []
vae_cache = [None for _ in range(32)]
for clip_idx in range(args.num_iterations):
first_clip = clip_idx == 0
start, end = segment_frame_range(clip_idx, first_clip_frame=57, clip_frame=56, past_frame=16)
lat_start, lat_end = frame_to_latent_idx(start), frame_to_latent_idx(end)
plucker = build_plucker_from_c2ws(extrinsics_all[start:end], base_K=get_intrinsics(704, 1280))
if first_clip:
x_memory, memory_idx, memory_plucker = None, None, None
else:
selected_idx = select_memory_idx_fov(extrinsics_all, start, selected_index_base=end - torch.arange(1, 34, 8), use_gpu=True)
x_memory = torch.cat(all_latents, dim=2)[:, :, [frame_to_latent_idx(i) for i in selected_idx]]
memory_plucker = build_relative_memory_pluckers(extrinsics_all, selected_idx)
plucker = torch.cat([memory_plucker, plucker], dim=2)
memory_idx = [frame_to_latent_idx(i) for i in selected_idx]
latents = torch.randn(1, 48, lat_end - lat_start, img_cond.shape[-2], img_cond.shape[-1], device=pipeline.device)
latents = torch.cat([img_cond, latents[:, :, img_cond.shape[2]:]], dim=2)
for t in FlowUniPCMultistepScheduler().set_timesteps(args.num_inference_steps, device=pipeline.device, shift=args.sample_shift):
timestep = build_per_latent_timestep(latents, t, image_cond_len=img_cond.shape[2])
noise_pred = pipeline.model(
x=latents, t=timestep, context=text_cond, seq_len=pipeline.max_seq_len,
mouse_cond=mouse_all[:, start:end], keyboard_cond=keyboard_all[:, start:end],
plucker_emb=plucker, x_memory=x_memory, memory_latent_idx=memory_idx,
predict_latent_idx=(lat_start, lat_end), fa_version=args.fa_version,
)
latents = scheduler.step(noise_pred, t, latents, return_dict=False)[0]
latents = torch.cat([img_cond, latents[:, :, img_cond.shape[2]:]], dim=2)
img_cond = latents[:, :, -4:]
denoised = latents if first_clip else latents[:, :, -10:]
all_latents.append(denoised)
video, vae_cache = pipeline.vae.stream_decode(denoised, vae_cache, first_chunk=first_clip)
return concatenate_decoded_segments()(c) Memory retrieval:utils/cam_utils.py::select_memory_idx_fov
def select_memory_idx_fov_gpu(extrinsics_all, current_start_frame_idx, selected_index_base):
if current_start_frame_idx <= 1:
return [0] * len(selected_index_base)
candidates = torch.arange(1, current_start_frame_idx, device=extrinsics_all.device)
sampled_frustum_points = sample_points_inside_query_frustum(num_side=10, near=0.1, far=30.0)
selected = []
for query_idx in selected_index_base:
query_pose = extrinsics_all[query_idx]
points_world = transform_camera_points_to_world(sampled_frustum_points, query_pose)
ratios = []
for cand_idx in candidates:
points_cam = transform_world_points_to_camera(points_world, extrinsics_all[cand_idx])
visible = project_and_test_in_image(points_cam, width=1280, height=720, near=0.1, far=30.0)
ratios.append(visible.float().mean())
selected.append(candidates[torch.argmax(torch.stack(ratios))].item())
return selected(d) Memory-aware DiT forward:wan/modules/model.py::WanModel.forward
def wan_model_forward(model, x, t, context, x_memory=None, plucker_emb=None,
mouse_cond=None, keyboard_cond=None, memory_latent_idx=None,
predict_latent_idx=None):
memory_length = 0
if x_memory is not None:
memory_length = x_memory.shape[2]
x = torch.cat([x_memory, x], dim=2)
t = torch.cat([torch.zeros_like_memory_timestep(x_memory), t], dim=1)
tokens = model.patch_embedding(x) # [B, dim, F, H, W] -> sequence tokens
text = model.text_embedding(pad_to_text_len(context))
timestep_emb = model.time_projection(model.time_embedding(sinusoidal_embedding_1d(model.freq_dim, t)))
if plucker_emb is not None:
cam_tokens = patchify_plucker(plucker_emb, patch_size=model.patch_size)
cam_tokens = model.patch_embedding_wancamctrl(cam_tokens)
cam_tokens = cam_tokens + model.c2ws_hidden_states_layer2(F.silu(model.c2ws_hidden_states_layer1(cam_tokens)))
for block in model.blocks:
tokens = block(
tokens, timestep_emb, seq_lens, grid_sizes, model.freqs, text, None,
mouse_cond=mouse_cond, keyboard_cond=keyboard_cond,
plucker_emb=cam_tokens, memory_length=memory_length,
memory_latent_idx=memory_latent_idx, predict_latent_idx=predict_latent_idx,
)
return model.unpatchify(model.head(tokens, timestep_emb), grid_sizes)[:, memory_length:](e) Action injection:wan/modules/action_module.py::ActionModule.forward
class ActionModule(nn.Module):
def forward(self, hidden_states, tt, th, tw, mouse_condition, keyboard_condition,
mouse_cond_memory=None, keyboard_cond_memory=None):
# Mouse: local temporal window + hidden visual token -> self-attention-style update.
if mouse_condition is not None:
mouse_windows = group_by_vae_time_window(mouse_condition, ratio=4, window_size=self.windows_size)
if mouse_cond_memory is not None:
mouse_windows = prepend_memory_mouse(mouse_cond_memory, mouse_windows)
mouse_tokens = self.mouse_mlp(torch.cat([hidden_states_by_spatial_site(hidden_states), mouse_windows], dim=-1))
q, k, v = self.t_qkv(mouse_tokens).chunk(3, dim=-1)
mouse_update = flash_attention(apply_rope(q), apply_rope(k), v)
hidden_states = hidden_states + self.proj_mouse(merge_spatial_sites(mouse_update))
# Keyboard: embedded discrete keys become K/V; visual hidden states query keyboard actions.
if keyboard_condition is not None:
key_windows = group_by_vae_time_window(self.keyboard_embed(keyboard_condition), ratio=4, window_size=self.windows_size)
if keyboard_cond_memory is not None:
key_windows = prepend_memory_keyboard(self.keyboard_embed(keyboard_cond_memory), key_windows)
q = self.mouse_attn_q(hidden_states)
k, v = self.keyboard_attn_kv(key_windows).chunk(2, dim=-1)
keyboard_update = flash_attention(apply_rope(q), apply_rope(k), v, causal=False)
hidden_states = hidden_states + self.proj_keyboard(keyboard_update)
return hidden_states(f) Paper-derived multi-segment DMD training sketch(training code 未开源)
def train_dmd_multisegment(student, teacher, critic, batch, memory_pool, optimizer_s, optimizer_c):
k = torch.randint(low=1, high=7, size=()).item()
past = batch.reference_latent
memory = None
generated_segments = []
for seg in range(k):
noise = torch.randn_like(batch.segment_latents[seg])
memory = retrieve_memory(memory_pool, batch.camera[seg]) if seg > 0 else None
current = student.few_step_sample(noise, past=past, memory=memory, action=batch.action[seg])
generated_segments.append(current)
memory_pool.update(current, camera=batch.camera[seg])
past = tail_frames(current)
stop_segment = generated_segments[-1]
t = sample_timestep()
score_data = teacher.score(stop_segment, t, past=past, memory=memory, action=batch.action[k-1])
score_gen = critic.score(stop_segment.detach(), t, past=past, memory=memory, action=batch.action[k-1])
dmd_loss = ((score_data - score_gen).detach() * stop_segment).mean()
optimizer_s.zero_grad(); dmd_loss.backward(); optimizer_s.step()
optimizer_c.step()3.9 Code-to-paper mapping
Code reference:
main@71c3cd7f(2026-03-30) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Official Matrix-Game 3.0 release / usage | Matrix-Game-3/README.md | model download, inference command, 720p 40FPS flags |
| CLI inference entry | Matrix-Game-3/generate.py | _parse_args(), generate() |
| Streaming non-interactive pipeline | Matrix-Game-3/pipeline/inference_pipeline.py | MatrixGame3Pipeline.generate() |
| Interactive keyboard/mouse pipeline | Matrix-Game-3/pipeline/inference_interactive_pipeline.py | get_current_action(), MatrixGame3Pipeline.generate() |
| Memory-aware DiT backbone | Matrix-Game-3/wan/modules/model.py | WanModel, WanSelfAttention, WanAttentionBlock |
| INT8 quantization | Matrix-Game-3/wan/modules/model.py | Int8Linear, convert_model_to_int8() |
| Mouse / keyboard action module | Matrix-Game-3/wan/modules/action_module.py | ActionModule.forward() |
| Camera-aware memory retrieval | Matrix-Game-3/utils/cam_utils.py | select_memory_idx_fov(), cal_intersection_ratio_gpu() |
| Plücker / pose conditioning helpers | Matrix-Game-3/utils/utils.py, Matrix-Game-3/utils/cam_utils.py | build_plucker_from_c2ws(), build_plucker_from_pose() |
| Action sequence generation | Matrix-Game-3/utils/conditions.py | Bench_actions_universal(), combine_data() |
| MG-LightVAE selection/loading | Matrix-Game-3/pipeline/vae_config.py | get_vae_config(), load_vae() |
| Async VAE decoding worker | Matrix-Game-3/pipeline/vae_worker.py | start_vae_worker_process() |
4. Experimental Setup (实验设置)
- Datasets / data scale:数据系统融合三类来源:① Unreal-Gen:超过 1,000 custom UE5 scenes,Nanite + Lumen,tick-level 同步记录 RGB / player pose / camera 6-DoF / action;角色装配组合数超过 。② AAA games:GTA V、Red Dead Redemption 2、Palworld、Cyberpunk 2077、Hogwarts Legacy,用四层 decoupled recording architecture 自动采集,60s segments,WSAD action 由位置增量推断;总体数据精度超过 99%。③ Real-world data:DL3DV-10K(超过 10,000 4K videos、65 类 POI)、RealEstate10K、OmniWorld-CityWalk、SpatialVid-HD,统一用 ViPE 重新标注 pose/depth。过滤阶段移除 20% raw data。Memory-augmented base model 的训练集约 4.8M video clips。
- Baselines / comparisons:论文主要做系统内部 comparison 和 qualitative comparison;相关方法包括 Matrix-Game 2.0、HY-Gamecraft-2、Lingbot-World、RELIC、WorldPlay、Genie-3。定量表没有对这些 baseline 的统一 FVD/LPIPS/CLIP-score 评测,而是报告加速模块 ablation 与 VAE reconstruction efficiency。
- Evaluation metrics:主要指标是 FPS(实时 throughput)、PSNR/SSIM(VAE reconstruction fidelity)、qualitative long-horizon revisitation consistency。Table 1 报告移除 INT8 / MG-LightVAE / GPU retrieval 的 FPS drop;Table 2 报告 original Wan2.2 VAE 与 MG-LightVAE 的 PSNR、SSIM、Full reconstruction time、decoder-only time。
- Training config:base model 基于 Wan2.2-TI2V-5B,action modules 插入前 15 DiT blocks;训练时 0.8 概率使用 4 past-frame latents + 10 current noisy latents,否则 mask out past/memory 做 action-conditioned I2V;fine-tune LR ,50K steps。Memory base 初始化自 action-modulated base,训练 5 memory latents + 4 past-frame latents + 10 noisy latents,RoPE jitter 。Distillation teacher/critic/student 均初始化自 memory base:cold-start 600 steps,student LR ,critic LR ,student 每 iteration 更新 5 steps;multi-segment stage 2,400 steps,segments ,student/critic LR ,student 每 iteration 更新 3 steps。推理默认 async 8+1 GPUs(8 GPUs DiT + 1 GPU VAE);H-series 用 FlashAttention 3,A-series 用 FlashAttention 2。论文未详细说明完整训练 GPU type/count。
5. Experimental Results (实验结果)
5.1 Long-horizon interactive generation results
Base model 结果(Figure 8)显示:动作符号变化时,角色和相机运动能响应 action,背景在 1–5s clip 中没有明显 drift。Memory model 的 controlled revisitation(Figure 9)更关键:后半段 action 反向让相机回到旧视角,模型能恢复之前看过的局部结构、物体布局和纹理细节。Distilled model(Figure 11)在长程回访中仍能继承 memory capability,没有明显 style/content drift。
28B model(Figure 10)展示了 scale-up 的定性收益:覆盖 third-person AAA scenes 和 Unreal synthetic scenes,在 outdoor exploration、urban driving、horseback traversal、night riding、open-world movement 中保持角色身份、场景布局和物体关系一致,同时动态和光照变化更丰富。
5.2 Real-time inference ablation(Table 1)
| Configuration | FPS | Drop |
|---|---|---|
| Full | (论文只报告近似值) | — |
| - INT8 quantization | 27.38 | 12.62 |
| - MG-LightVAE | 25.79 | 14.21 |
| - GPU retrieval | 6.60 | 33.40 |
关键结论:三个加速项都必要,但 GPU retrieval 是最大瓶颈:去掉后从约 40 FPS 掉到 6.60 FPS,drop 33.40。INT8 attention quantization 和 MG-LightVAE 的收益也明显,分别带来 12.62 / 14.21 FPS 的差异。说明 Matrix-Game 3.0 的 40 FPS 不是单靠 few-step diffusion,而是 DiT、memory retrieval、VAE decoding 三段同时优化。
5.3 MG-LightVAE quality / efficiency(Table 2)
| Model | PSNR ↑ | SSIM ↑ | Full(s) ↓ | Dec.(s) ↓ |
|---|---|---|---|---|
| Wan2.2 VAE | 33.79 | 0.99 | 0.99 | 0.76 |
| MG-LightVAE (50% pruned) | 31.84 | 0.99 | 0.52 | 0.30 |
| MG-LightVAE (75% pruned) | 31.14 | 0.99 | 0.35 | 0.13 |
50% pruning 的 PSNR 下降 1.95(33.79→31.84),但 decoder-only time 从 0.76s 降到 0.30s;75% pruning 进一步降到 0.13s,但 PSNR 降到 31.14。论文结论是 50% 更稳健,75% 更偏速度;开源 README 默认推荐 mg_lightvae_v2 + --lightvae_pruning_rate 0.75 用于更快 inference。
5.4 Ablation / design findings
- Memory retrieval matters qualitatively:Figure 9 的回访实验显示,模型不是靠短期 frame continuity,而是用 camera-aware retrieval 找到和当前视角几何相关的旧帧,恢复 facade patterns / texture-level cues。
- Error-aware training supports distillation:base model 被训练在 imperfect context 上,减少和 few-step student 之间的 distribution mismatch;distilled model 在 Figure 11 中仍能回忆旧内容。
- Acceleration is system-level:Table 1 证明仅量化或仅裁剪 VAE 不够;当 memory retrieval 还在 CPU 精确计算时,long rollout 的 candidate set 增长会使实时性崩溃。
5.5 Limitations / conclusions
作者在 conclusion 中指出未来方向包括继续 scaling model/data、开发更高效架构以支持更高分辨率和更长序列,以及探索更先进 memory mechanisms 来处理更复杂交互和 long-term dependency。论文也有明显未完全覆盖的部分:缺少与 Genie-3 / RELIC / Matrix-Game 2.0 等方法的统一定量 benchmark;训练与数据系统的部分细节虽有技术报告描述,但开源 repo 当前主要是 inference stack、模型结构和权重使用,完整 data engine / training pipeline 尚未完全公开。
总体结论:Matrix-Game 3.0 的价值在于把 interactive world model 的三个工程难题放在同一系统里解决:error-aware base training 负责抗 drift,camera-aware memory 负责分钟级回访一致性,multi-segment DMD + INT8 + MG-LightVAE + GPU retrieval 负责 720p real-time streaming。5B 模型达到约 40 FPS,28B MoE 进一步提升质量和泛化,说明 open world model 正在从 demo 走向可部署系统。