HY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
1. Motivation(研究动机)
现有方法的核心痛点:
3D 世界建模目前存在根本性的分叉:生成方法(如 HY-World 1.0)擅长从文本/单张图像合成可探索的场景,但几何精度不足;重建方法(如 MapAnything、DepthAnything3)能从多视角密集输入恢复精确 3D 结构,但缺乏在未观测区域的生成先验,无法处理稀疏输入。闭源商业产品如 Marble 虽然展示了强大的统一能力,但开源社区缺乏可与之抗衡的方案。
核心挑战:
- 现有全景生成依赖显式相机内参进行透视→全景变换,在 uncalibrated 输入下表现很差
- 视频扩散模型(VDM)的时序压缩 Video-VAE 在大视角变化下会引入运动模糊和几何畸变
- 多条轨迹的跨视图一致性难以保持,导致下游 3D 重建出现层叠伪影
- WorldMirror 1.0 的绝对 RoPE 在非训练分辨率下出现位置外推,高分辨率性能骤降
研究价值: 这是首个系统性、开源的多模态统一世界模型,将 generation 和 reconstruction 纳入同一 offline 3D world model 范式,具备游戏开发、机器人仿真、环境测绘等实用价值。
2. Idea(核心思想)
核心洞察:
离线 3D 世界建模的关键在于:以 3D Gaussian Splatting(3DGS)作为统一的输出表示,将视频扩散模型的生成先验与 feed-forward 重建模型的几何精度有机结合。
三句话总结创新:
- 用隐式自适应映射(MMDiT 在联合 latent space 中学习透视→ERP 变换)取代传统显式相机几何,实现无需相机元数据的高保真全景生成
- 将世界扩展从 video latent space 转移到 keyframe latent space,配合双记忆模块(GGM + SSM++),在多条轨迹间保持几何一致性
- 通过 Normalized RoPE、depth-to-normal loss、depth mask head 三项架构改进,使 WorldMirror 2.0 在多分辨率下保持稳定性能
与已有方法的本质区别:
| 方法 | 输入 | 输出 | 一致性机制 | 开源 |
|---|---|---|---|---|
| HY-World 1.0 | 文本/单图 | 3DGS | 无记忆 | ✅ |
| Marble | 文本/单图/多视角 | 3DGS | 闭源 | ❌ |
| video2world | 多视角 | 3DGS | ICP 迭代对齐(5h) | ❌ |
| HY-World 2.0 | 文本/单图/多视角/视频 | 3DGS | Keyframe Memory + 深度对齐 | ✅ |
3. Method(方法)
3.1 整体框架
HY-World 2.0 是四阶段流水线,如图 2 所示:

Figure 2 解读: 四个阶段从左到右依次为:
- Stage 1(蓝色):Panorama Generation,使用 HY-Pano 2.0,将多模态输入(文本/单图)转换为 360° 全景图
- Stage 2(绿色):Trajectory Planning,使用 WorldNav,对全景图进行场景解析(语义分割、NavMesh 构建),规划最大覆盖的相机轨迹
- Stage 3(橙色):World Expansion,使用 WorldStereo 2.0,沿规划轨迹生成关键帧序列,通过记忆机制维持多轨迹一致性
- Stage 4(紫色):World Composition,使用 WorldMirror 2.0,将关键帧序列重建为全局对齐的 3DGS 世界
每个阶段底部标注了使用的核心模型/算法。重建能力(WorldMirror 2.0)同时服务于 Stage 3 的相机控制和 Stage 4 的世界合成。
3.2 Stage 1:全景生成(HY-Pano 2.0)
架构:

Figure 3 解读: 左侧为全景生成 pipeline:文本经过 text encoding,perspective 图像经过 latent encoding + circular padding 后,与全景噪声 latent 拼接为统一 token 序列,输入 N 层 MMDiT Block 进行去噪,最终解码为全景图。右上角展示 Circle Padding 在 latent space 的效果(周期性边界条件);右下角展示 Pixel Blending 在 pixel space 沿等矩形边缘的线性混合,消除左右边界不连续。
关键设计 —— 隐式自适应映射:
摒弃 HY-World 1.0 的显式几何变换(需要 focal length 和 FoV),改用 MMDiT 在统一 latent space 中自动学习透视→ERP 映射:
- 将条件图像 latent 与全景 noise latent 拼接为统一序列
- MMDiT 自注意力直接建立空间对应关系
- 无需相机元数据,支持任意分辨率和 FoV 的输入
无缝边界策略:
ERP 全景的左右边界存在周期性不连续问题:
- Latent 级 Circular Padding:在去噪过程中对 latent feature 施加循环填充,强制周期性边界条件
- Pixel 级 Linear Blending:将解码后的 pixel 在等矩形边缘做线性混合
def circular_padding_latent(latent: torch.Tensor, pad_size: int) -> torch.Tensor:
# latent: [B, C, H, W]
# 在 W 维度上循环填充,使边界连续
left_pad = latent[:, :, :, -pad_size:]
right_pad = latent[:, :, :, :pad_size]
return torch.cat([left_pad, latent, right_pad], dim=-1)
def pixel_blending_erp(image: torch.Tensor, blend_width: int) -> torch.Tensor:
# 在左右边界进行线性混合消除缝合痕迹
W = image.shape[-1]
alpha = torch.linspace(0, 1, blend_width, device=image.device)
# 左边界区域
image[..., :blend_width] = (
alpha * image[..., :blend_width] + (1 - alpha) * image[..., W-blend_width:]
)
image[..., W-blend_width:] = image[..., :blend_width]
return image3.3 Stage 2:轨迹规划(WorldNav)
场景解析:

Figure 4 解读: 给定全景图,通过多个工具获得轨迹规划所需的几何和语义信息:(a) 使用 MoGe2 估计全景深度并构建全景点云 ;(b) 使用 HY-World 1.0 从点云生成全景 Mesh;(c) 使用 SAM3 获取语义 Mask;(d) 使用 Recast Navigation 生成可导航 NavMesh(蓝色区域为可通行区域)。
几何感知初始化:
- 使用 MoGe2 对 ERP 空间均匀采样的 42 个透视视角(默认 12 个,增加到 42 以提高几何质量)进行 LSMR 深度对齐
- 混合过滤:视觉语言 grounding 模型 mask 天空 + 去除深度不连续边缘(edge floaters)
- Recast Navigation NavMesh:表面不规则校正(dense ray-casting snapping)+ KD-Tree 边界 erosion + 孤立区域桥接
五种轨迹模式:

Figure 5 解读: WorldNav 设计了五种启发式轨迹,均从全景中心出发:
- (a) Regular:以 120° FoV 均匀分割全景为 3 个透视视角,相机绕中心目标轨道运动,覆盖场景整体,最多 9 条
- (b) Surrounding:环绕最显著物体旋转,轨道半径根据物体 3D 尺寸自适应,最多 5 条
- (c) Reconstruct-Aware:用 NMS 识别全景 Mesh 中的变形面(stretched/sharp faces),生成针对这些遮挡区域的补充视角,最多 10 条,迭代式规划
- (d) Wandering:将 NavMesh 分为 8 个扇形,Dijkstra 距离场找到各扇形最远可达点,沿最长路径漫游,最多 3 条
- (e) Aerial:在 surrounding 和 wandering 基础上加 +45° 仰角,消除盲区,最多 8 条
全部轨迹合计最多 35 条。
WorldNav 伪代码:
class WorldNavPlanner:
"""WorldNav 轨迹规划器(基于论文 Section 4)"""
def __init__(self, panorama: np.ndarray):
# 场景解析
self.pano_pcd = build_panoramic_pointcloud(panorama, n_views=42) # MoGe2 LSMR
self.pano_mesh = build_panoramic_mesh(self.pano_pcd)
self.semantic_masks = sam3_segment(panorama) # SAM3 语义 mask
self.navmesh = build_navmesh(self.pano_mesh) # Recast Navigation
self.navmesh = refine_navmesh(self.navmesh) # ray-casting snapping + KD-Tree erosion
self.landmarks = localize_landmarks_3d(self.semantic_masks, self.pano_pcd)
def plan_regular_trajectories(self, max_n: int = 9) -> list[Trajectory]:
"""以 120° FoV 划分全景,相机绕各视角中心轨道运动"""
trajs = []
for azimuth in [0, 120, 240]: # 均匀 3 视角
cam_target = get_orbital_target(self.pano_pcd, azimuth)
orbit = generate_orbit(cam_target, pitch=+45, azimuth_offsets=[-120, 0, 120])
orbit = add_aerial_offset(orbit, extra_azimuth=+60)
orbit = ray_cast_filter(orbit, self.pano_mesh) # 碰撞检测
trajs.extend(orbit)
return trajs[:max_n]
def plan_surrounding_trajectories(self, max_n: int = 5) -> list[Trajectory]:
"""环绕显著物体的轨迹,半径根据物体 3D 尺寸自适应"""
trajs = []
for landmark in self.landmarks[:max_n]:
radius = compute_adaptive_radius(landmark['size_3d'])
# 采样 72 个候选节点,双向贪心搜索形成弧线
candidates = sample_circle_nodes(landmark['center_3d'], radius, n=72)
valid = [c for c in candidates if ray_cast_valid(c, self.navmesh)]
arc = bidirectional_greedy(valid)
arc = tail_pruning(arc) # 去掉偏离圆形方向的末端
arc = dijkstra_close_loop(arc[0], arc[-1], self.navmesh)
trajs.append(arc)
return trajs
def plan_reconstruct_aware_trajectories(self, max_n: int = 10) -> list[Trajectory]:
"""针对未观测区域的迭代补充轨迹"""
trajs = []
iterations = 0
while len(trajs) < max_n and iterations < 3:
# 检测变形面:stretched/sharp faces(aspect ratio > threshold)
degenerate_faces = detect_degenerate_faces(self.pano_mesh)
if not degenerate_faces:
break
# NMS 提取代表性聚类中心,关联到最近语义地标
clusters = nms_cluster(degenerate_faces)
recon_nodes = associate_to_landmarks(clusters, self.landmarks)
for node in recon_nodes:
# 选择对齐遮挡区域法向量的候选视角(最大可见范围)
viewpoints = generate_viewpoints_around(node, self.navmesh)
best = max(viewpoints, key=lambda v: visible_range_in_navmesh(v, self.navmesh))
orbit = generate_orbit_around_node(node, best)
trajs.append(orbit)
iterations += 1
return trajs[:max_n]
def plan_wandering_trajectories(self, max_n: int = 3) -> list[Trajectory]:
"""Dijkstra 距离场找最远可达点,覆盖走廊/街道等狭长区域"""
trajs = []
sectors = partition_navmesh_sectors(self.navmesh, n=8)
for sector in sectors[:max_n]:
farthest = dijkstra_farthest_node(sector, self.navmesh)
path = dijkstra_path(origin=self.navmesh.center, goal=farthest)
trajs.append(path)
return trajs
def plan_all(self) -> list[Trajectory]:
"""合并全部轨迹(最多 35 条)"""
all_trajs = (
self.plan_regular_trajectories(9)
+ self.plan_surrounding_trajectories(5)
+ self.plan_reconstruct_aware_trajectories(10)
+ self.plan_wandering_trajectories(3)
)
# Aerial: 在 surrounding + wandering 基础上加 +45° 仰角(最多 8 条)
aerial = [add_pitch_offset(t, +45, self.pano_mesh) for t in all_trajs[:8]]
return all_trajs + aerial # 总计最多 35 条3.4 Stage 3:世界扩展(WorldStereo 2.0)
三阶段训练:

Figure 6 解读: WorldStereo 2.0 分三个阶段训练:Domain-Adaption(相机控制能力)→ Middle-Training(一致性记忆机制)→ Post-Distillation(快速推理)。每个阶段解锁不同能力,逐步构建。
整体 Pipeline:

Figure 7 解读: (a) 主 DiT branch:Video Diffusion Transformer,通过 SSM++(Spatial-Stereo Memory++)检索历史关键帧 → 与 target 视图水平拼接,提供 fine-grained 空间一致性约束;同时从 Memory Bank 中读取几何全局信息。 (b) 相机控制 branch(Camera Adapter):以全景点云 (Global-Geometric Memory,GGM)和 Plücker Ray Embedding 为输入,生成相机引导特征,通过 cross-attention 注入主 DiT。
5.1 Keyframe-VAE:
标准 Video-VAE 在时序维度上压缩(),导致快速相机运动下的帧质量下降和几何畸变。

Figure 9 解读: (a) 标准 Video-VAE 将 视频压缩为 ,即同时在时间和空间维度压缩。(b) Keyframe-VAE 对 帧独立进行空间-only 压缩,每帧 latent 为 ,输出 个独立 latent。,通过稀疏采样在相同视角覆盖下保留更少但更高质量的帧。
5.2 相机控制:
给定参考视图点云 ,将其 warp 到每个目标视角:
其中 和 为目标视图 的相机-世界矩阵和内参矩阵, 为单目深度估计, 为像素的齐次坐标。Warp 后的点云渲染为 view-wise 关键帧并用 Keyframe-VAE 编码。与 Uni3C 不同,WorldStereo 2.0 在 domain-adaption 阶段同时微调 Camera Adapter 和 DiT 主干(冻结 cross-attention 和 FFN 层),取得精度与泛化性的最佳平衡。
5.2 Global-Geometric Memory(GGM):
GGM 使用扩展的全景点云 作为全局 3D 先验:
其中 为从 个新视图随机采样的额外点云(如图 10a 所示)。通过渲染这些点云的视频来微调 WorldStereo 2.0,使模型学会内化 360° 环境的几何一致结构。
5.2 Spatial-Stereo Memory++(SSM++):
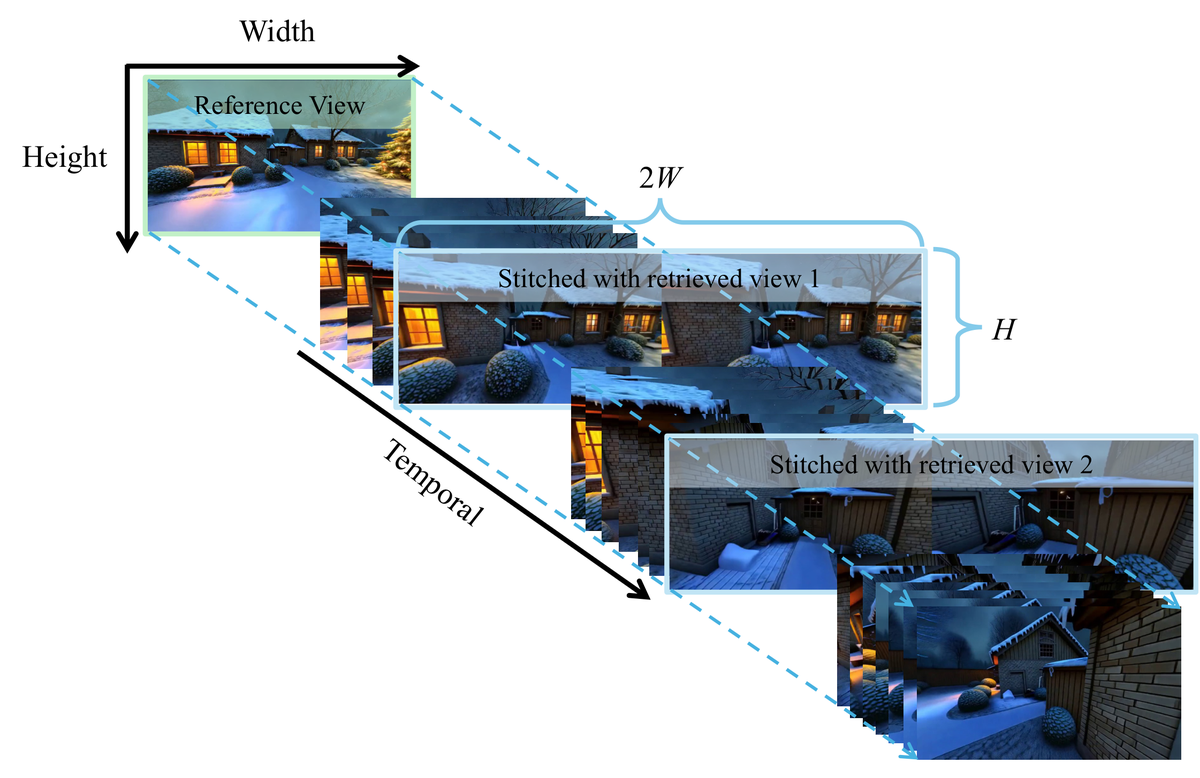
Figure 11 解读: SSM++ 的核心是水平拼接(horizontal stitching):每个 target 视图 与其检索到的最相关参考帧 在 width 维度拼接,形成宽度 的输入。关键改进:拼接后的 retrieved 视图继承其 paired target 帧的相同时间索引(而非独立时间索引),这使得 RoPE 能正确建模空间对应关系而非误认为是时序关系。
SSM++ 相对于 WorldStereo 1.0 SSM 的改进:
- 丢弃独立的 memory branch,直接在主 DiT branch 中处理 retrieved frames
- 修改 RoPE:retrieved 帧与 target 帧共享时间索引
- 从 restricted attention → full fine-tuning(移除跨 target-retrieved 对的 attention 限制)
- 将显式 pointmap guidance 替换为隐式 7D 相机向量(quaternion + translation)编码的 camera tokens
5.3 后蒸馏(DMD):
Distribution Matching Distillation 将 WorldStereo 2.0 蒸馏为 4-step DiT:
其中 为 student 生成, 为冻结的 teacher score, 为可训练的 fake score function。训练 5次每 generator 更新,使用随机梯度截断稳定训练。
class WorldStereo2Pipeline:
"""WorldStereo 2.0 推理 pipeline 伪代码"""
def __init__(self, dit_model, keyframe_vae, camera_adapter):
self.model = dit_model # 主 Video DiT
self.vae = keyframe_vae # Keyframe-VAE (spatial-only)
self.camera_adapter = camera_adapter # Camera control branch
self.memory_bank = {} # 存储已生成的关键帧
def encode_keyframes(self, frames: list[torch.Tensor]) -> list[torch.Tensor]:
# 每帧独立空间压缩,无时序压缩
return [self.vae.encode(f.unsqueeze(0)) for f in frames]
def build_ggm_features(
self,
pano_pointcloud: torch.Tensor, # [N, 3] 全景点云
target_cameras: list[dict],
) -> torch.Tensor:
# Global-Geometric Memory: 渲染点云到目标视角
rendered_depths = []
for cam in target_cameras:
depth = render_point_cloud(pano_pointcloud, cam)
rendered_depths.append(depth)
# 编码为 Plücker Ray Embedding + 点云特征
plucker = compute_plucker_rays(target_cameras)
return self.camera_adapter(rendered_depths, plucker)
def retrieve_ssm_frames(
self,
target_cam: dict,
memory_bank: dict,
T_r: int = 4,
) -> list[torch.Tensor]:
# SSM++: 基于 3D FoV 相似度检索最相关的历史帧
scores = {k: fov_similarity_3d(target_cam, v['cam'])
for k, v in memory_bank.items()}
top_keys = sorted(scores, key=scores.get, reverse=True)[:T_r]
return [memory_bank[k]['latent'] for k in top_keys]
def generate_keyframes(
self,
ref_view: torch.Tensor, # [1, H, W, 3] 参考图
target_cams: list[dict], # 目标相机列表
pano_pcd: torch.Tensor, # [N, 3] 全景点云
T_kf: int = 8,
) -> list[torch.Tensor]:
# Step 1: 编码参考帧
ref_latent = self.vae.encode(ref_view)
self.memory_bank = {'0': {'latent': ref_latent, 'cam': target_cams[0]}}
# Step 2: 构建 GGM 相机引导
ggm_feat = self.build_ggm_features(pano_pcd, target_cams)
outputs = []
for i, cam in enumerate(target_cams):
# Step 3: SSM++ 检索历史帧
retrieved = self.retrieve_ssm_frames(cam, self.memory_bank)
# Step 4: 水平拼接 retrieved 帧(共享时间索引)
# target_noisy: [1, H/8, W/8, C], retrieved: [T_r, H/8, W/8, C]
target_noisy = torch.randn_like(ref_latent)
# 每个 retrieved 帧水平拼接到 target,共享同一时间 index
stitched = torch.cat([target_noisy, retrieved[0]], dim=-2) # width 方向
# Step 5: DiT 去噪(4步 DMD)
camera_tokens = encode_camera_7d(cam) # [7] → MLP → camera tokens
gen_latent = self.model.sample(
stitched, ggm_feat, camera_tokens, num_steps=4
)
# 只取左半部分(target 部分)
gen_latent = gen_latent[..., :gen_latent.shape[-2]//2, :] # 去掉 retrieved
# Step 6: 解码并更新 memory bank
gen_frame = self.vae.decode(gen_latent)
self.memory_bank[str(i+1)] = {'latent': gen_latent, 'cam': cam}
outputs.append(gen_frame)
return outputs3.5 世界重建模型(WorldMirror 2.0)
架构:

Figure 12 解读: WorldMirror 2.0 是 feed-forward 统一重建模型。输入端:多视角图像 + 可选几何先验(camera intrinsics token、pose token、depth token),通过 Token Merging 拼接为 unified geometric sequence。主干为 Transformer,通过 Feature Aggregation 后接多个 DPT decoder heads,分别预测:point maps()、camera parameters()、multi-view depth maps()、surface normals()、3D Gaussians()。训练采用 Any-Modal Tokenization:每种 prior 模态以 0.5 概率独立 drop,实现 flexible inference。
关键改进 1 —— Normalized RoPE:
标准 RoPE 使用绝对整数坐标 ,在非训练分辨率下产生位置外推。改为:
其中 ,( 为 patch size)。归一化坐标 ,将分辨率外推转化为插值,+1 偏移防止边界 patch 塌缩到 。

Figure 13 解读: (a) 中心点 RoPE 编码的跨分辨率余弦相似度:Normalized RoPE(蓝色柱)在 256/512/1024/2048 分辨率间始终 ,而 Standard RoPE(灰色柱)在 1024 和 2048 时急剧下降至 0.23 和 0.009。(b)(c) 显示 Normalized RoPE 的均值和标准差在不同分辨率下近乎恒定,而 Standard RoPE 存在系统性漂移,确认归一化将外推转化为插值。
关键改进 2 —— Depth-to-Normal Loss:
引入 depth-to-normal 转换的辅助监督路径,将预测深度 反投影为点云再通过叉积求法向量:
损失为派生法向量与监督法向量的角度误差:
对合成数据集, 来自 GT 深度的 depth-to-normal 变换(多视角一致);对真实数据集, 来自 monocular normal estimation 教师模型的伪标签(local 方向可靠,无全局一致性问题)。
关键改进 3 —— Depth Mask Prediction Head:
新增 per-pixel validity 预测头,输出 logit :
推理时 mask 直接供下游点云融合使用,替代之前基于置信度阈值的启发式过滤。
三阶段课程学习:
| 阶段 | 训练目标 | 关键操作 |
|---|---|---|
| Stage 1 | 所有几何 head(使用 native 标注) | 不含伪标签增强或 |
| Stage 2 | 所有几何 head | 引入 + 增大合成数据比例 |
| Stage 3 | 仅 3DGS head(冻结 backbone 和几何 heads) | 从 depth head 权重初始化 3DGS head |
推理加速(三策略组合):
- Sequence Parallelism(SP):输入 token 序列分片到多 GPU,每层 attention 前 All-to-All 通信;DPT head 的 frame-level parallelism(各 GPU 解码不相交的帧子集)
- Selective Mixed-Precision:多数参数 BF16,保留数值精度关键层(precision-critical modules)为 FP32,内存占用减半
- Fully Sharded Data Parallelism(FSDP):每个 Transformer block 和 DPT head 作为独立 FSDP unit,分片权重到多 GPU
Token budget 动态 batch sizing:
固定 (如 25000 tokens),先采样分辨率,再反推最大 view 数,保证 GPU 内存利用率接近 100%。
class WorldMirrorPipeline:
"""WorldMirror 2.0 推理 pipeline(基于真实代码简化)"""
@classmethod
def from_pretrained(
cls,
pretrained_model_name_or_path: str = "tencent/HY-World-2.0",
subfolder: str = "HY-WorldMirror-2.0",
use_fsdp: bool = False,
enable_bf16: bool = False,
) -> 'WorldMirrorPipeline':
model_dir = _resolve_model_dir(pretrained_model_name_or_path, subfolder)
config = _get_model_config_from_yaml(model_dir)
model = build_model(config)
state_dict = _load_checkpoint_state_dict(model_dir)
_load_state_dict_selective(model, state_dict)
if enable_bf16:
_cast_noncritical_fp32_to_bf16(model)
if use_fsdp:
model = _wrap_model_fsdp(model)
return cls(model, config)
def __call__(
self,
input_path: str, # 输入图像目录路径或视频文件路径
output_path: str = "inference_output",
camera_poses: list[np.ndarray] | None = None, # 可选: [N, 4, 4]
intrinsics: list[np.ndarray] | None = None, # 可选: [N, 3, 3]
prior_depth: list[np.ndarray] | None = None, # 可选深度图
) -> dict:
# Step 1: 从路径加载图像(支持图像目录或视频文件)
images = load_images_from_path(input_path)
# Step 2: 自适应分辨率计算(token budget 策略)
resolution = compute_adaptive_resolution(images[0].shape[:2], T_max=25000, N=len(images))
images_resized = [resize(img, resolution) for img in images]
# Step 3: 模型前向推理
with torch.cuda.amp.autocast(enabled=not self.config.use_bf16):
outputs = self._run_inference(
images_resized, camera_poses, intrinsics, prior_depth
)
# outputs 包含: depth_maps, normals, point_maps, cameras, gaussians, masks
# Step 4: 后处理(sky mask + edge mask + confidence mask)
masks = compute_masks(outputs, sky_mask=True, edge_mask=True)
point_cloud = back_project_depth(outputs['depth'], outputs['cameras'], masks)
# Step 5: 保存(点云、3DGS、法向量、相机参数)
save_results(outputs, point_cloud, output_path)
return outputs
def _run_inference(self, images, cameras, intrinsics, prior_depth):
# 构建 Any-Modal token sequence
img_tokens = self.model.image_encoder(stack_images(images))
# 可选 prior tokens(训练时 0.5 概率 drop,推理时按需提供)
prior_tokens = []
if cameras is not None:
prior_tokens.append(self.model.pose_encoder(cameras))
if intrinsics is not None:
prior_tokens.append(self.model.intrinsics_encoder(intrinsics))
if prior_depth is not None:
prior_tokens.append(self.model.depth_encoder(prior_depth))
merged = token_merge(img_tokens, prior_tokens)
features = self.model.transformer(merged) # global self-attention
# 多头并行预测
return {
'point_maps': self.model.head_build(features),
'cameras': self.model.head_camera(features),
'depth': self.model.head_depth(features),
'normals': self.model.head_normal(features),
'gaussians': self.model.head_3dgs(features),
'masks': self.model.head_mask(features),
}3.6 Stage 4:世界合成(World Composition)
点云扩展 + 深度对齐:

Figure 14 解读: 深度对齐流程:①将全景点云 渲染到每个生成关键帧的相机视角,得到稀疏 guidance depth ;②WorldMirror 2.0 对生成关键帧估计 dense depth ;③Depth Alignment 模块在 reliability mask (多个 mask 的交集)区域执行 RANSAC 线性对齐 ;④离群点检测(基于 Q=9 anchor depth 值的全局统计分布)修正异常对齐系数。
可靠性 mask 为多个 mask 的交集:
其中 为 WorldMirror 置信度 mask, 为全景点云投影 mask, 为法向量一致性 mask, 去除 edge floaters, 去除天空区域。
离群点检测:对 Q=9 个均匀分布的 anchor 深度值 ,计算变换后的锚点值 。每帧的最大相对偏差:
超过第 90 百分位的系数对被视为离群,用同视频序列中最近邻 inlier 系数替换。
3D Gaussian Splatting 优化:
初始化每个 Gaussian 的参数:
- 不透明度
- 中心位置
- 协方差矩阵 (保证半正定)
- RGB 颜色 (view-independent,不用 SH)
MaskGaussian:引入可学习的二值 mask ,通过 Gumbel-Softmax 采样:
稀疏正则化:
总损失:
其中:
Growth Strategy + MaskGaussian 的协同:仅对 (非天空区域点云)启用标准 growth(clone + split),完全阻止天空区域生成 floater;MaskGaussian 进一步消除低频过密区域的冗余 Gaussian,减少 77% Gaussian 数量而 PSNR 仅损失 0.14 dB。
class MaskGaussian3DGS(nn.Module):
"""MaskGaussian 3DGS 优化(伪代码)"""
def __init__(self, init_point_cloud: torch.Tensor):
super().__init__()
N = init_point_cloud.shape[0]
self.means = nn.Parameter(init_point_cloud.clone())
self.scales = nn.Parameter(torch.zeros(N, 3)) # log-scale
self.rotations = nn.Parameter(torch.zeros(N, 4)) # quaternion
self.opacities = nn.Parameter(torch.ones(N) * 0.1)
self.colors = nn.Parameter(torch.rand(N, 3))
self.mask_logits = nn.Parameter(torch.zeros(N)) # MaskGaussian
def compute_masks(self, temperature: float = 1.0) -> torch.Tensor:
# Gumbel-Softmax 采样二值 mask
return F.gumbel_softmax(
torch.stack([self.mask_logits, -self.mask_logits], dim=-1),
tau=temperature, hard=True
)[..., 0]
def render(self, camera: dict) -> tuple[torch.Tensor, torch.Tensor]:
masks = self.compute_masks() # [N] binary
S = torch.diag_embed(torch.exp(self.scales)) # [N, 3, 3]
R = quaternion_to_matrix(F.normalize(self.rotations, dim=-1)) # [N, 3, 3]
covs = R @ S @ S.transpose(-1,-2) @ R.transpose(-1,-2) # [N, 3, 3]
# Masked rasterization: 对 M_k=0 的 Gaussian 跳过颜色贡献
rendered_image, rendered_depth = gaussian_rasterize(
self.means, covs, self.colors * masks.unsqueeze(-1),
self.opacities, camera
)
return rendered_image, rendered_depth
def loss(self, gt_image, gt_depth_a, normals_moge2) -> torch.Tensor:
pred_img, pred_depth = self.render(camera)
pred_normals = depth_to_normal(pred_depth, camera['K'])
L_color = (0.8 * F.l1_loss(pred_img, gt_image)
+ 0.2 * (1 - ssim(pred_img, gt_image))
+ 0.05 * lpips(pred_img, gt_image))
L_geo = (F.l1_loss(pred_depth[valid_mask], gt_depth_a[valid_mask])
+ (1 - F.cosine_similarity(pred_normals, normals_moge2)).mean())
L_mask = self.mask_logits.sigmoid().mean() ** 2 # sparsity
L_reg = scale_regularization(self.scales)
return L_color + L_geo + L_mask + L_reg3.7 代码-论文对照表
| 论文概念 | 源文件 | 关键类/函数 |
|---|---|---|
| WorldMirror 2.0 Pipeline | hyworld2/worldrecon/pipeline.py | WorldMirrorPipeline |
| from_pretrained 加载 | hyworld2/worldrecon/pipeline.py | WorldMirrorPipeline.from_pretrained() |
| 推理前向 | hyworld2/worldrecon/pipeline.py | WorldMirrorPipeline.__call__(), _run_inference() |
| FSDP 加速 | hyworld2/worldrecon/pipeline.py | _wrap_model_fsdp(), _cast_noncritical_fp32_to_bf16() |
| 推理 CLI | hyworld2/worldrecon/pipeline.py | main() |
| WorldRecon 模块 | hyworld2/worldrecon/ | 整个目录 |
| WorldGen 模块 | hyworld2/worldgen/ | 整个目录(WorldStereo 2.0) |
| Pano Gen 模块 | hyworld2/panogen/ | 整个目录(HY-Pano 2.0) |
| Gradio 交互 demo | examples/worldrecon/ | 示例脚本 |
4. Experimental Setup(实验设置)
数据集:
| 任务 | 数据集 |
|---|---|
| 全景生成 (T2P) | DiT360, Matrix3D, HY-World 1.0 |
| 全景生成 (I2P) | CubeDiff, GenEx, HY-World 1.0 |
| WorldStereo 评估(相机控制) | 100 OOD 图像 [WorldScore] |
| WorldStereo 评估(单视角重建) | Tanks-and-Temples, MipNeRF360 |
| WorldMirror 2.0(点图重建) | 7-Scenes (scene), NRGBD (scene), DTU (object) |
| WorldMirror 2.0(相机/深度/NVS) | RealEstate10K, DL3DV |
| WorldMirror 2.0(法向量估计) | ScanNet, NYUv2, iBims-1 |
| Marble 对比 | 相同全景输入 + 相同 perspective 输入(Marble 1.0,截至 2026.3.30) |
训练配置:
- WorldMirror 2.0 参数量:~1.2B(Transformer backbone + DPT heads)
- 推理硬件:NVIDIA H20 GPU
- 分辨率范围:50K–500K pixels(token-budget dynamic sampling)
- WorldMirror 三阶段:Stage 1→2→3 逐步引入 、伪标签、3DGS head
5. Experimental Results(实验结果)
5.1 全景生成(HY-Pano 2.0)
Table 4:T2P 和 I2P 定量对比:
| 指标 | T2P: DiT360 | T2P: Matrix3D | T2P: HY-World 1.0 | T2P: HY-Pano 2.0 |
|---|---|---|---|---|
| CLIP-T↑ | 0.238 | 0.250 | 0.250 | 0.258 |
| Q-Align Qual (Persp)↑ | 3.788 | 2.983 | 3.992 | 4.103 |
| Q-Align Aes (Equi)↑ | 4.072 | 3.880 | 4.186 | 4.247 |
| 指标 | I2P: CubeDiff | I2P: GenEx | I2P: HY-World 1.0 | I2P: HY-Pano 2.0 |
|---|---|---|---|---|
| CLIP-I↑ | 0.828 | 0.831 | 0.831 | 0.844 |
| Q-Align Qual (Persp)↑ | 2.938 | 2.917 | 3.317 | 4.026 |
| Q-Align Aes (Equi)↑ | 3.645 | 3.646 | 3.767 | 4.056 |
HY-Pano 2.0 在 T2P 和 I2P 两个任务的所有指标上取得最佳,I2P 相比 HY-World 1.0 提升尤为显著。

Figure 17 解读: T2P(text-to-panorama)定性对比。输入为同一文本描述(机场候机大厅),从上到下分别为 Matrix3D、HY-World 1.0、DiT360、HY-Pano 2.0 的生成结果(全景图及其透视渲染视图)。HY-Pano 2.0 生成的全景图具有更高的布局一致性(等矩形格式下无拼接痕迹)、更丰富的细节(座椅纹理、灯光细节清晰)和更高的视觉美学质量,透视渲染视图也与全景内容高度一致。

Figure 18 解读: I2P(image-to-panorama)定性对比。左列为输入 perspective 图像,后续各行依次为 GenEx、HY-World 1.0、CubeDiff、HY-Pano 2.0 的生成结果(全景图及透视视图)。HY-Pano 2.0 在场景扩展的合理性(未观测区域的内容填充与输入视图风格一致)、几何连贯性(建筑结构透视关系正确)和细节丰富度上均优于其他方法,且无明显拼接伪影。
5.2 WorldStereo 2.0 相机控制能力
Table 6:相机控制能力对比:
| 方法 | RotErr↓ | TransErr↓ | ATE↓ | Q-Align↑ | CLIP-IQA+↑ | CLIP-I↑ |
|---|---|---|---|---|---|---|
| WorldStereo 1.0* | 0.762 | 1.245 | 2.141 | 4.149 | 0.547 | 89.05 |
| WorldStereo 2.0* | 0.492 | 0.968 | 1.768 | 4.205 | 0.544 | 89.43 |
单视角重建(Table 5,Tanks-and-Temples AUC):WorldStereo 2.0 (DMD) 达到 60.09,超过所有 video-based 和 3D-based 竞争者。
5.3 WorldMirror 2.0 重建性能
Table 11(7-Scenes 点图重建,Medium 分辨率):
| 方法 | Acc.↓ (Mean) | Comp.↓ (Mean) |
|---|---|---|
| Fast3R | 0.096 | 0.145 |
| 0.048 | 0.028 | |
| WorldMirror 1.0 (M) | 0.043 | 0.026 |
| WorldMirror 2.0 (M) | 0.033 | 0.020 |
| WorldMirror 2.0 (H) + all priors | 0.012 | 0.008 |
Table 12(RealEstate10K 相机位姿和深度,Medium):
- 相机位姿 AUC@30: 86.48(vs WorldMirror 1.0 的 86.13),高分辨率提升至 86.89
- 深度 AbsRel: 0.167(vs 1.0 的 0.178)
- NVS SSIM (High): 0.726(vs 1.0 的 0.659)
Table 13(ScanNet 法向量估计,Medium):
- Mean 误差: 12.3°(vs 1.0 的 13.8°,超过所有专用单任务方法如 StableNormal 的 18.5°)
关键 Ablation 发现:
- Keyframe-VAE + 冻结 Cross-Attn + FFN 的配置达到最佳相机控制 RotErr 0.492,用户研究 Quality↑ 64.39%
- GGM + SSM++ 的记忆模块使 PSNR_m 从 28.81 → 30.93(+2.12 dB)
- MaskGaussian 将 Gaussian 数从 5.254M 降至 1.383M(-73.7%),PSNR 仅损失 0.14 dB
5.4 端到端性能
Table 10:单场景生成总耗时(NVIDIA H20):
| 阶段 | 全景 | 轨迹规划 | 世界扩展 | 重建+对齐 | 3DGS | 总计 |
|---|---|---|---|---|---|---|
| 时间(s) | 15 | 182 | 286 | 102 | 127 | 712(~12分钟) |
WorldMirror 2.0 推理效率(Table 14,518×378,NVIDIA H20):
| 配置 | GPU数 | 128 views 内存(GB) | 128 views 时间(s) |
|---|---|---|---|
| FP32 Baseline | 1 | 59.26 | 18.00 |
| +BF16 | 1 | 41.73 | 16.96 |
| +SP+BF16 (×4 GPUs) | 4 | 44.47 | 5.65 |
| +SP+BF16+FSDP (×4 GPUs) | 4 | 42.71 | 5.60 |
5.5 与 Marble 对比(最终结论)
HY-World 2.0 在全景输入条件和单图输入条件两种设置下均与 Marble(闭源商业模型)竞争:

Overall Results 解读: 该图展示 HY-World 2.0 的 3DGS 渲染结果与 Marble(闭源商业模型)的对比。左列为相同全景输入条件下的对比(Fig. 23),右列为相同 perspective 单图输入条件(Fig. 24)。与 Marble 相比,HY-World 2.0 在输入条件下的保真度更高(严格遵从全景/透视图像的结构与纹理),novel view 的几何一致性更好(无明显 blurring 和 geometry collapse),且在栅栏、汽车、家具、山地等高频结构区域的细节保留更好。

Figure 25 解读: WorldMirror 1.0 和 2.0 在法向量预测和点云重建上的视觉对比。左列为输入图像,中两列为法向量预测(Normal-1.0 vs Normal-2.0),右两列为重建点云(Point Cloud-1.0 vs Point Cloud-2.0)。WorldMirror 2.0 在法向量预测上更加精细和准确(边缘更清晰、细节结构更明确),点云的多视角一致性也更强(WorldMirror 2.0 的点云密度均匀且无分层伪影),验证了 depth-to-normal loss 和 normalized RoPE 的有效性。

Figure 19 解读: 轨迹规划消融研究的定性对比。从左到右逐步添加轨迹类型:(a) 全景图;(b) 仅全景视角 → 严重几何空洞和不完整 3D 结构;(c) +Regular 轨迹 → 消除大部分宏观伪影,但遮挡结构(汽车侧面、拱门背面)仍不完整;(d) +Surrounding & Reconstruct-Aware → 针对性填充遮挡结构;(e) +Wandering → 增强纹理细节和场景边界覆盖;(f) +Aerial(全量)→ 最终消除所有盲区,整体场景完整性最佳。

Figure 22 解读: HY-World 2.0 生成的 3D 世界的交互探索演示。通过 WorldLens 渲染平台,用户可控制虚拟角色(机器人、熊猫、企鹅等)在生成的 3D 世界中导航,支持实时物理碰撞检测(能正确处理楼梯、室内布局等复杂几何结构)和物理反馈,验证了 3DGS + Mesh 表示对交互式应用的就绪性。
局限性(论文提及):
- 全景生成(HY-Pano 2.0)和世界扩展(WorldStereo 2.0)代码暂未开源,仅 WorldMirror 2.0 可用
- WorldStereo 2.0 单场景扩展耗时 286 秒(轨迹规划 182s),总流程约 12 分钟
- 相机轨迹规划和 3DGS 优化中尚未处理动态物体
- 依赖单目深度质量;在高挑战性户外场景中深度对齐仍有困难