Matrix-Game 2.0: An Open-Source, Real-Time, and Streaming Interactive World Model
论文信息
- 作者: Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, Baixin Xu, Hao-Xiang Guo, Kaixiong Gong, Size Wu, Wei Li, Xuchen Song, Yang Liu, Yangguang Li, Yahui Zhou (Skywork AI)
- 链接: arXiv:2508.13009
- 项目主页: matrix-game-v2.github.io
- 代码: github.com/SkyworkAI/Matrix-Game
- 模型权重: Skywork/Matrix-Game-2.0 (HuggingFace)
- License: MIT
1. Motivation (研究动机)
1.1 核心问题
现有交互式世界模型 (Interactive World Model) 存在三大瓶颈:
| 问题 | 具体表现 | 影响 |
|---|---|---|
| 双向注意力延迟 | 生成单帧需要处理整个视频序列,计算量随帧数二次增长 | 无法实时响应用户输入 |
| 去噪步数过多 | 需要多步迭代去噪,推理开销大 | 长视频生成不经济 |
| 自回归误差累积 | 基于前帧预测下一帧,误差逐帧放大 | 长视频质量严重退化 |

Figure 1 解读: 展示了 Matrix-Game 2.0 的实时交互生成结果。覆盖多种场景和风格(中世纪村庄、自然风光、卡通、日系、Minecraft、GTA驾驶等),每帧左下角显示当前键盘/鼠标操作状态(W/A/S/D 移动 + 鼠标视角)。模型能在 25 FPS 下自回归生成分钟级高质量交互视频。
2. Idea (核心思想)
Matrix-Game 2.0 提出三大核心组件协同解决实时交互世界模型的挑战:
- 可扩展数据生产管线 — 基于 Unreal Engine 和 GTA5,生成约 1200 小时带交互标注的视频数据,覆盖 Minecraft、野外场景、驾驶等多种环境
- 去语义化动作注入模块 — 去掉所有文本输入,帧级鼠标/键盘输入通过 MLP+Temporal Self-Attention(鼠标)和 Cross-Attention(键盘)分别注入 DiT,专注学习视觉-物理规律
- Self-Forcing 蒸馏 + 因果架构 — 通过 ODE 初始化 + DMD-based Self-Forcing 将双向 Foundation Model 蒸馏为因果自回归模型,配合 VAE Cache、Action Module 裁剪、去噪步数优化,在单张 H100 上达到 25 FPS
3. Method (方法)
3.1 整体架构
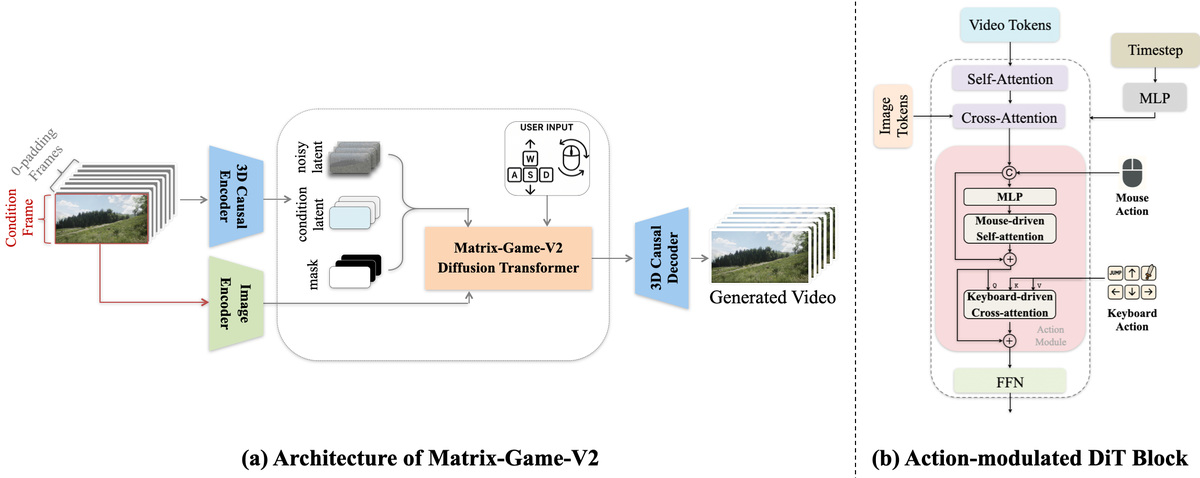
Figure 2 解读: Matrix-Game 2.0 的训练和推理流程概览。训练阶段分两步:(1) 对 Base Model 进行带 Action Module 的 Foundation Model SFT;(2) 基于 Self-Forcing 进行 Causal Model Distillation,将双向模型蒸馏为因果自回归模型。推理阶段:输入图像经 Video & Image Encoder 编码,动作序列经 Action Encoder 编码,通过 KV Caching 的 Causal Diffusion Model 流式输出视频。
3.2 Foundation Model 架构
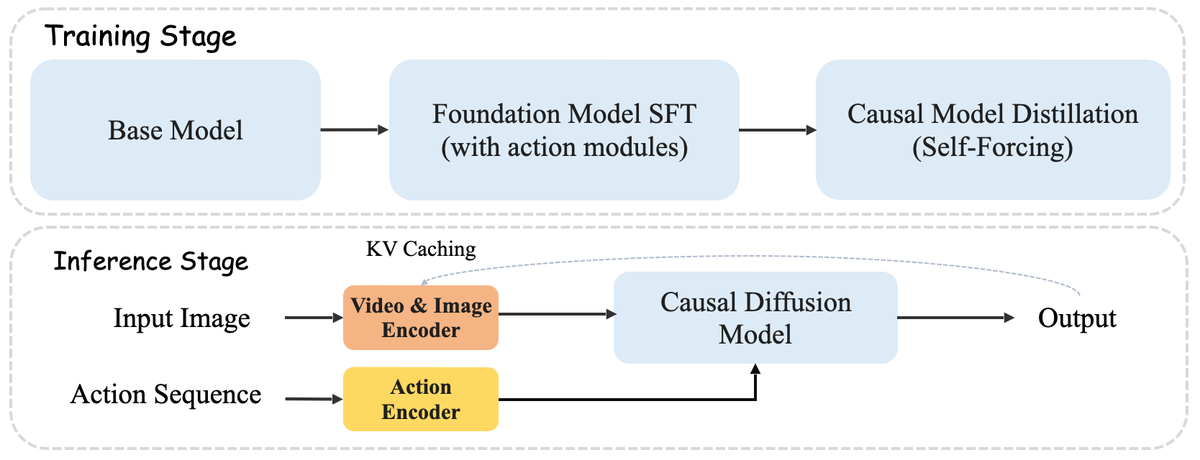
Figure 8 解读: (a) Matrix-Game-V2 整体架构:基于 Wan 2.1 I2V 设计,移除文本分支,仅从视觉内容和对应动作预测下一帧。输入图像经 3D Causal VAE(空间 、时间 倍压缩)和 CLIP Image Encoder 编码为条件输入,DiT 在动作引导下生成视觉 token 序列,再由 3D VAE Decoder 解码为视频。(b) Action-modulated DiT Block:鼠标动作经 MLP + 时序 Self-Attention 处理后直接拼接到 latent 表示;键盘动作经 Cross-Attention 查询融合特征,实现帧级精确控制。使用 RoPE 替代 sin-cos 位置编码以支持长视频生成。
关键设计:去语义化建模
- 去掉所有文本输入,专注学习图像中的空间结构和动态模式
- 灵感来自 Spatial Intelligence 概念:模型能力应源自对视觉和物理规律的直觉理解,而非语义先验
动作注入模块:
- 鼠标动作(连续):直接拼接到 latent → MLP → Temporal Self-Attention
- 键盘动作(离散):通过 Cross-Attention 与融合特征交互
基础模型:SkyReels-V2-I2V-1.3B,总参数量加上 Action Module 后为 1.8B
3.3 实时自回归视频生成(核心创新)
蒸馏过程分为两个阶段:Student Initialization 和 DMD-based Self-Forcing。
阶段一:Student Initialization via ODE Trajectories

Figure 9 解读: 因果学生模型的初始化方法。从双向 Foundation Model 推理获得 clean output,在不同噪声水平下随机采样获得 ODE 轨迹数据集 ( 从 中 3 步子集采样)。训练时将 帧噪声输入分成 个 chunk,每个 attention layer 应用 block-wise causal mask。学生模型以噪声 chunk 和动作为输入,用回归损失学习去噪:
其中 为因果学生生成器, 为条件(包含动作), 为独立时间步。
阶段二:DMD-based Self-Forcing
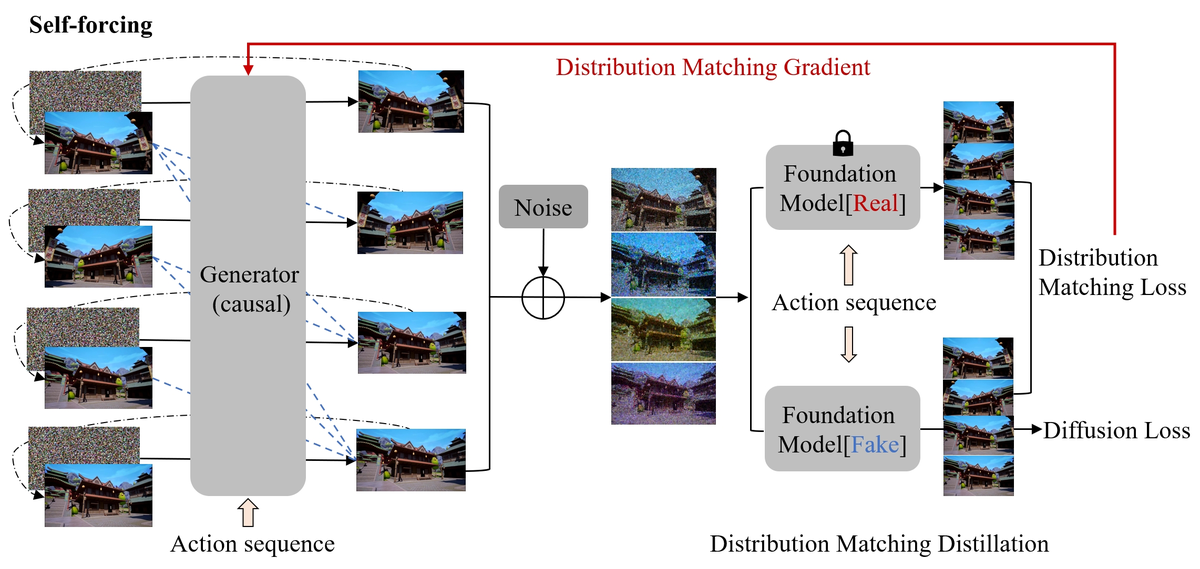
Figure 10 解读: 基于 Self-Forcing 的因果扩散模型蒸馏训练。左侧:因果 Generator 以 Self-Forcing 方式生成(每帧条件于自身先前生成的帧而非 ground truth),右侧:Distribution Matching Distillation,将学生分布 与教师分布 对齐。Generator 从自身分布采样先前帧(而非 GT),有效缓解 train-test gap 和误差累积。
Self-Forcing 的关键价值:
- 解决 Teacher Forcing / Diffusion Forcing 中的 exposure bias 问题
- 训练时每帧条件于自生成输出,与推理时一致
- 是一种 data-free 训练方法,可以手动设计动作序列分布
KV-Cache 机制
- 滚动缓存:固定长度 cache,超出容量时驱逐最旧 token,支持无限长度生成
- Cache 窗口约束:训练时限制 KV-cache window size,使初始帧对后续 latent 不可见,迫使模型更依赖自身先验和输入动作
- 最优 local size = 6 帧:平衡上下文保持与误差修正能力(9 帧反而导致更早出现伪影)
3.4 训练伪代码
# Phase 1: Foundation Model Training
# 初始化: SkyReels-V2-I2V-1.3B (去除 text branch)
# Step 1: 冻结主体,训练 Action Module 5k steps
# Step 2: 全量微调 Foundation Model 120k steps
# lr=2e-5, batch_size=256
# Phase 2: Distillation
# Step 1: Student Initialization
foundation_model.eval()
for batch in ode_dataset: # 40k ODE pairs
x_0 = foundation_model.inference(image, actions)
t = sample_timesteps(subset=[0, T], num_steps=3)
x_t = add_noise(x_0, t)
chunks = split_into_chunks(x_t, chunk_size=3)
# Apply block-wise causal masks
x_pred = student_model(chunks, actions, t)
loss = MSE(x_pred, x_0)
loss.backward() # 6k steps
# Step 2: DMD-based Self-Forcing
for step in range(4000):
# Student generates via self-forcing (causal, self-conditioned)
x_fake = student_model.self_forcing_generate(image, actions)
noise = sample_noise()
x_t_fake = add_noise(x_fake, t)
# Teacher scores (frozen foundation model)
score_real = foundation_model(x_t_fake, actions) # real branch
score_fake = foundation_model(x_t_fake, actions) # fake branch
# Distribution matching loss + Diffusion loss
loss = distribution_matching_loss(score_real, score_fake) + diffusion_loss
loss.backward() # lr=6e-6, chunk_size=3, attn_local_size=63.5 数据生产管线
3.5.1 Unreal Engine 数据管线

Figure 3 解读: Unreal Engine 数据生产管线架构。输入层接收 Navigation Mesh 和 3D Scene,核心组件包括 Auto Movement Component 和 Camera Control Component(由 Character Controller 驱动),数据处理层通过 Video Recorder (MP4) 和 Data Collector (CSV) 输出同步的视频文件和行为数据。
三大创新:
- Navigation Mesh-based Path Planning System
- 基于 Unreal Engine 的 NavMesh 基础设施
- 自定义路径规划优化,平均查询延迟 < 2ms
- 引入受控随机性,在遵守导航约束的同时产生多样化运动模式

Figure 4 解读: 导航系统示例。绿色区域表示 agent 可自由移动的区域(Navigation Mesh),蓝色方块为 agent 位置。NavMesh 确保 agent 不会撞墙或卡住,同时支持确定性的实时路径规划。
- RL-Enhanced Agent Training(PPO 强化学习增强)
奖励函数设计:
- :碰撞惩罚(安全约束)
- :探索新区域奖励
- :运动多样性奖励
- Precise Input and Camera Control
输入-视觉同步公式:
四元数精度优化(双精度算术)消除 0.2% 的相机旋转误差。

Figure 5 解读: Unreal Engine 收集的轨迹示例。上排展示多种 3D 场景(室外自然、城市建筑、室内等),下排展示对应的导航轨迹(绿色线段)。复杂场景中也能规划合理路径。
3.5.2 GTA5 数据管线
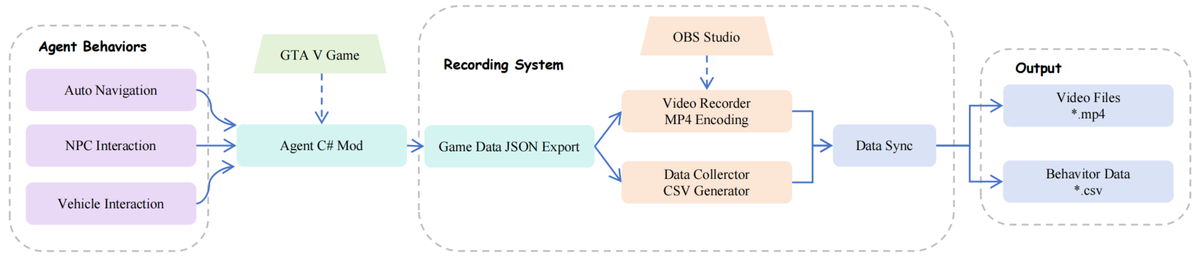
Figure 6 解读: GTA5 交互数据录制系统。Agent Behaviors(自动导航、NPC 交互、车辆交互)通过 C# Mod 集成到 GTA V 中,导出 JSON 行为数据。Recording System 使用 OBS Studio 录制视频,Data Sync 模块确保视频帧与行为数据的时间对齐,最终输出 .mp4 视频和 .csv 行为数据。
相机位置公式:
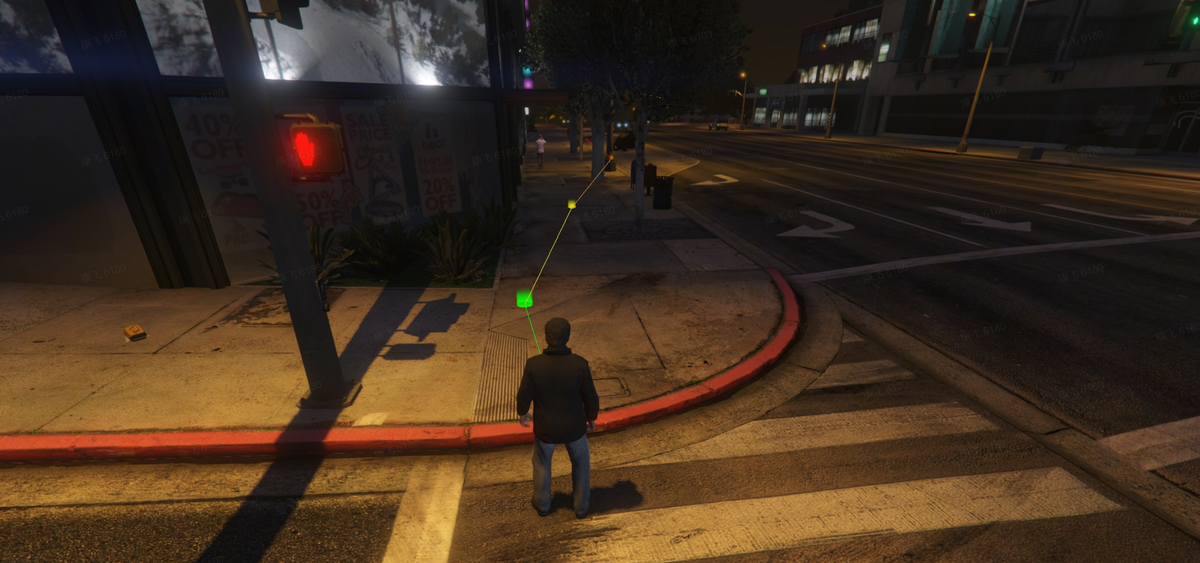
Figure 7 解读: GTA5 收集的轨迹示例。城市街道场景中第三人称视角,显示了交通灯、行人、车辆等动态元素。线条表示 agent 移动路径,数据管线可规划合理路径避免碰撞。
3.5.3 数据统计
| 数据源 | 时长 | 说明 |
|---|---|---|
| Minecraft | 153 小时 | 每段 57 帧 |
| Unreal Engine | 615 小时 | 多样 3D 场景 |
| Sekai (开源) | 85 小时 | 真实场景,需帧率重采样对齐 |
| GTA-driver | 574 小时 | 驾驶交互场景 |
| Temple Run | 560 小时 | 跑酷游戏交互 |
| 总计 | ~1200+ 小时 | 分辨率统一为 |
Data Curation:
- 基于 OpenCV 的冗余帧过滤
- 速度验证机制排除无效样本:
- 多线程管线加速:单张 RTX 3090 支持双流并行数据生产
- 总计收集超 120 万 视频片段,数据精度 > 99%,相机旋转精度提升 50 倍
4. Experimental Setup (实验设置)
4.1 实验设置
| 项目 | 详情 |
|---|---|
| Base Model | SkyReels-V2-I2V-1.3B (Wan 2.1 架构) |
| 总参数量 | 1.8B (含 Action Module) |
| 分辨率 | |
| Foundation Training | 120k steps, lr=2e-5, batch=256 |
| Distillation | 40k ODE pairs → 6k steps init + 4k steps Self-Forcing, lr=6e-6 |
| 推理速度 | 25 FPS (单卡 H100) |
| GPU 要求 | >= 24GB (A100/H100) |
| 评估基准 | GameWorld Score Benchmark (Matrix-Game 1.0 提出) |
4.2 代码结构与复现
| 路径 | 功能 |
|---|---|
Matrix-Game-2/inference.py | 批量推理(随机动作轨迹) |
Matrix-Game-2/inference_streaming.py | 流式推理(自定义输入动作+图像) |
Matrix-Game-2/pipeline/ | 核心管线模块 |
Matrix-Game-2/wan/ | Wan 架构相关组件 |
Matrix-Game-2/configs/inference_yaml/ | 推理配置文件 |
Matrix-Game-2/demo_utils/ | Demo 工具函数 |
4.3 关键代码-论文映射
| 论文概念 | 代码位置 | 说明 |
|---|---|---|
| Foundation Model (I2V) | wan/ | 基于 Wan 2.1 架构 |
| Action Module (Mouse) | pipeline/ DiT Block | MLP → Temporal Self-Attention → Concatenate |
| Action Module (Keyboard) | pipeline/ DiT Block | Cross-Attention 查询融合 |
| KV-Cache (Rolling) | pipeline/ | 固定长度滚动缓存,FIFO 驱逐 |
| Self-Forcing Inference | inference_streaming.py | 自回归流式生成 |
| 3D Causal VAE | wan/ | 空间 8x8 + 时间 4x 压缩 |
4.4 环境要求 & 快速复现
# 环境要求
# GPU: NVIDIA A100/H100 (>= 24GB)
# RAM: >= 64GB
# Python 3.10
# 安装
git clone https://github.com/SkyworkAI/Matrix-Game.git
cd Matrix-Game/Matrix-Game-2
conda create -n matrix-game python=3.10 -y
conda activate matrix-game
pip install -r requirements.txt
python setup.py develop
# 批量推理(随机动作)
python inference.py --config configs/inference_yaml/xxx.yaml
# 流式推理(自定义输入)
python inference_streaming.py --image <path> --actions <path>5. Experimental Results (实验结果)
5.1 Minecraft 场景结果

Figure 11 解读: Minecraft 场景的定性对比。Oasis 在生成数十帧后质量严重退化(颜色失真、结构崩塌),而 Matrix-Game 2.0 在整个序列(0-350帧)中保持优秀的视觉质量和场景一致性。
Table 1: Minecraft 定量对比 (vs. Oasis)
| 指标 | Oasis | Ours | 维度 |
|---|---|---|---|
| Image Quality ↑ | 0.27 | 0.61 | Visual Quality |
| Aesthetic ↑ | 0.27 | 0.50 | Visual Quality |
| Temporal Cons. ↑ | 0.82 | 0.94 | Temporal Quality |
| Motion Smooth. ↑ | 0.99 | 0.98 | Temporal Quality |
| Keyboard Acc. ↑ | 0.73 | 0.91 | Action Controllability |
| Mouse Acc. ↑ | 0.56 | 0.95 | Action Controllability |
| Obj. Cons. ↑ | 0.18 | 0.64 | Physical Understanding |
| Scenario Cons. ↑ | 0.84 | 0.80 | Physical Understanding |
Oasis 在 Motion Smoothness 和 Scenario Consistency 上略高,原因是 Oasis 崩塌后生成静态帧,反而提升了这两个指标的分数。
5.2 Wild Scene 结果

Figure 12 解读: 野外真实场景的定性对比 (vs. YUME)。YUME 在数百帧后出现明显伪影和颜色过饱和,而 Matrix-Game 2.0 保持稳定的风格保真度和准确的交互响应。且 YUME 生成速度慢,难以直接用于交互式世界建模。
Table 2: Wild Scene 定量对比 (vs. YUME)
| 指标 | YUME | Ours |
|---|---|---|
| Image Quality ↑ | 0.65 | 0.67 |
| Aesthetic ↑ | 0.48 | 0.51 |
| Temporal Cons. ↑ | 0.85 | 0.86 |
| Motion Smooth. ↑ | 0.99 | 0.98 |
| Obj. Cons. ↑ | 0.77 | 0.71 |
| Scenario Cons. ↑ | 0.80 | 0.76 |
YUME 在 Object/Scenario Consistency 上更高,同样因为崩塌后趋向静态内容。
5.3 长视频 & 多场景生成

Figure 13 解读: Matrix-Game 2.0 的长视频生成展示(0-1350 帧)。覆盖多种野外场景(花园、森林、草地、建筑等),在超长序列中仍保持优秀的视觉质量和精确的动作可控性,展现了模型作为通用世界模型基础框架的潜力。

Figure 14 解读: GTA5 驾驶场景生成结果(0-350帧)。多种驾驶视角和路况下,模型生成的视频保持了道路结构的连贯性和车辆运动的合理性。

Figure 15 解读: TempleRun 跑酷游戏场景生成结果(0-350帧)。包含快速视角变化、复杂 3D 结构(岩石、桥梁、废墟),模型在保持游戏画面一致性的同时准确响应用户的左右转向等操作。
5.4 加速技术消融实验
Table 3: 加速技术逐步叠加对比
| 加速技术 | Image↑ | Aesthetic↑ | Temporal↑ | Motion↑ | Keyboard↑ | Mouse↑ | Object↑ | Scenario↑ | FPS↑ |
|---|---|---|---|---|---|---|---|---|---|
| (1) +VAE Cache | 0.61 | 0.51 | 0.93 | 0.97 | 0.91 | 0.95 | 0.68 | 0.81 | 15.49 |
| (2) (1)+Halving action modules | 0.61 | 0.51 | 0.94 | 0.97 | 0.92 | 0.95 | 0.63 | 0.81 | 21.03 |
| (3) (2)+Reducing steps 4→3 | 0.61 | 0.50 | 0.94 | 0.98 | 0.91 | 0.95 | 0.64 | 0.80 | 25.15 |
三项加速策略:
- VAE Cache:集成 Wan2.1-VAE 的缓存机制,加速长视频解码 → 15.49 FPS
- Halving action modules:仅在 DiT 前半部分使用 Action Module → 21.03 FPS
- Reducing denoising steps (4→3):减少去噪步数 → 25.15 FPS
质量几乎无损地达到了 25 FPS 实时生成。
5.5 KV-Cache Local Size 消融

Figure 16 解读: 不同 KV-cache local size 的定性对比。上半部分为跑道场景,下半部分为街景。Local Size = 9 时在 frame 375-500 出现明显伪影和质量退化;Local Size = 6 在所有帧上保持更好的视觉质量和内容保真度。结论:更大的 cache 反而导致过度依赖缓存信息,累积误差通过 cache 被”记忆”,适中的 cache(6帧)在上下文保持与误差修正之间取得最佳平衡。
5.6 失败案例

Figure 17 解读: 模型的典型失败模式。左侧:处理 OOD 场景时出现过饱和区域(颜色不自然的鲜艳色块)。右侧:长时间向前运动或向上抬头等极端操作导致画面退化。这些限制可通过扩展训练数据域和模型规模来改善。
6. 主要局限性 (Limitations)
6.1 局限性
- OOD 泛化不足 — 对训练分布外场景(如持续向上看/向前走)可能产生过饱和或退化结果
- 分辨率有限 — 当前输出 ,低于 SOTA 视频生成模型
- 长程记忆缺失 — 自回归模型缺乏显式历史记忆机制,长视频中内容一致性仍有挑战
7. 总结
Matrix-Game 2.0 的核心贡献在于将交互式世界模型推向实时可用水平:
- 数据层:构建了业界最大规模的交互视频数据管线(~1200h),覆盖 UE、GTA5、Minecraft 等多种环境
- 模型层:基于 Wan 2.1 架构 + Action Module + Self-Forcing 蒸馏,1.8B 参数实现因果自回归少步生成
- 工程层:VAE Cache + Action Module 裁剪 + 去噪步数优化,在单卡 H100 上达到 25 FPS
- 开源:MIT License,权重和代码完全开放
在 GameWorld Score Benchmark 上全面超越 Oasis(Minecraft)和 YUME(Wild Scene),是目前首个同时满足实时、流式、交互、开源的世界模型。