Infinite-World: Scaling Interactive World Models to 1000-Frame Horizons via Pose-Free Hierarchical Memory
Authors: Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xunliang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, Ming-Ming Cheng Affiliations: Nankai University, Meituan, NKIARI, HKUST arXiv: 2602.02393 Project Page: rq-wu.github.io/projects/infinite-world/index.html GitHub: MeiGen-AI/Infinite-World Year: 2026
1. Motivation
1.1 Real-World World Model 面临的三个核心挑战
现有 interactive world model(如 HY-World 1.5、Matrix-Game 2.0、Hunyuan-GameCraft)在合成数据(Unreal Engine、GTA5)上表现良好,但迁移到真实世界视频时遇到根本性障碍:
-
Inaccurate Pose and Unreliable Control:合成环境有完美的 camera extrinsics,但真实视频的 camera pose 必须通过估计获得,inevitably 引入误差。pose estimation 的不准确直接破坏 action-response 映射,导致动作控制能力退化。
-
Scarcity of Viewpoint Revisit Data:自然视频流几乎总是”线性”的——camera 很少回到之前访问过的位置。这种 revisit 数据的稀缺使模型无法学习全局几何结构,long-range spatial memory 几乎不可能从标准数据集中习得。
-
Lack of Efficient Pose-Free Memory Mechanisms:Standard attention 的 复杂度在长视频生成中成为计算瓶颈。现有解决方案要么依赖显式 camera pose 做 FOV-based retrieval(对 noisy pose 敏感),要么用简单的 uniform temporal downsampling(严重信息损失)。一个既 pose-free 又计算高效的 memory 机制仍然缺失。

Figure 1 解读:Figure 1 展示了 Infinite-World 在超过 1000 帧的长程交互中维持空间一致性的能力。从 frame 0 到 frame 1134,模型通过键盘式控制在室内环境中导航,关键的窗户和桌面布局在全程回访中保持一致,证明了 long-range memory 和 loop-closure 能力。
1.2 Infinite-World 要解决什么问题
Infinite-World 的目标是在真实世界视频上训练一个能够维持 1000+ 帧一致性的 interactive world model,同时不依赖显式 camera pose。这与 HY-World 1.5 等方法的关键区别在于:后者依赖精确的 camera pose(通过 PRoPE 注入)和大量合成数据,而 Infinite-World 完全在 noisy real-world video 上工作,使用 pose-free 的 memory compression。
1.3 为什么这个问题值得研究
- Genie-3 等闭源系统已展示 real-world world model 的巨大潜力,但其技术细节不可获取;Infinite-World 旨在填补这一开源空白。
- 对 embodied AI 来说,real-world 场景远比合成场景复杂,能在 noisy real-world data 上工作的 world model 才具有真正的实用价值。
- Memory efficiency 对长时序生成是核心约束——如果 memory 随时间线性增长,1000 帧级别的交互在实践中不可行。
2. Idea
2.1 核心思想
Infinite-World 提出三个互补的创新来解决 real-world interactive world modeling:
-
Hierarchical Pose-free Memory Compressor (HPMC):一个两阶段递归压缩器,将任意长度的历史 latent 压缩到固定大小的 memory budget ,无需任何 camera pose 信息。通过与 DiT backbone 联合训练,压缩器自主学会保留对未来生成最有用的信息。
-
Uncertainty-aware Action Labeling (UAL):将 continuous camera motion 离散化为三态逻辑——No-operation、Discrete Action、Uncertain。关键创新是显式保留 “Uncertain” 类别来表示 low-SNR 的模糊运动,而不是强行归类为某个动作或直接丢弃这些数据。
-
Revisit-Dense Finetuning Strategy (RDD):基于一个 pilot study 的发现——loop-closure 能力可以用极少量数据(仅 30 分钟的 revisit-dense 视频)高效激活——设计了两阶段训练策略:先在大规模 open-domain 数据上 pre-train,再在 compact RDD 数据集上 finetune。
2.2 与现有方法的根本区别
| 方面 | HY-World 1.5 | Infinite-World |
|---|---|---|
| Memory 机制 | Geometry-aware retrieval (依赖 FOV overlap + camera pose) | Pose-free hierarchical compression (无需 pose) |
| 动作控制 | Dual action: discrete + continuous PRoPE | Uncertainty-aware tri-state labeling |
| 训练数据 | 混合合成 + real-world (320K clips) | 纯 real-world (30h pre-train + 30min finetune) |
| 计算复杂度 | Memory retrieval 每步搜索 | 固定 budget,恒定开销 |
| Backbone | HunyuanVideo DiT | Wan 2.1 DiT (1.3B) |
2.3 一句话总结创新
Infinite-World 的核心创新是用一个与 DiT 联合训练的 pose-free hierarchical memory compressor,把任意长度的历史压缩到固定大小的表示中,再配合 uncertainty-aware action labeling 和 revisit-dense finetuning,实现了在 noisy real-world data 上的 1000+ 帧一致性交互式世界生成。
3. Method
3.1 整体框架

Figure 2 解读:Figure 2 展示了 Infinite-World 的三个核心组件。(a) Hierarchical Pose-free Memory Compressor:左侧流程展示了 HPMC 如何通过 slide-window sampling → local compression → concat → global compression 的两阶段流程,将任意长度的历史 latent 递归压缩到固定的 memory budget。压缩后的 memory 与 last-frame latent 和 noisy target latent 拼接后送入 DiT blocks(Self-Attn → Cross-Attn → FFN ×n)进行 denoising。(b) Uncertainty-Aware Action Labeling:右侧展示了 action labeling 的 tri-state 逻辑——对每 N 帧采样 1 帧,用 VGGiT 估计 camera poses,然后分别对 translation 和 rotation 维度基于阈值 判定为 No-operation / Discrete Action / Uncertain。(c) Data Strategy:pre-trained data(web collected)+ fine-tuned data(self-captured revisit-dense videos)的两阶段训练。
3.2 Hierarchical Pose-free Memory Compressor (HPMC)
HPMC 是本文最核心的技术贡献。其目标是:将长度为 的历史 latent 序列压缩到固定大小 ,同时保留对未来 generation 最有价值的信息。
3.2.1 Mode 1: Short-Horizon Direct Compression
当历史长度在可控范围内(),直接用 temporal encoder 一次性压缩:
其中 是压缩率, 是 hidden dimension。
Temporal encoder 的结构是一个 3D-ResNet,由 ConvIn → ResBlock×2 → TemporalDownsample → ResBlock×2 → TemporalDownsample → MidBlock(Attention) → ConvOut 组成。TemporalDownsample 使用 kernel=(3,2,1) 在时间维度上做 2× 下采样,两次下采样总计实现 4× 压缩。
3.2.2 Mode 2: Long-Horizon Hierarchical Compression
当 ,启动层级压缩防止 memory drift:
- 将原始 latent 用 sliding window(窗口大小 ,动态 stride )划分为 个 overlapping chunks;
- 每个 chunk 经过 local compression(第一阶段 )提取短程时空特征;
- 所有 local compressed tokens 拼接后,经过 global compression(第二阶段 )合并为统一的全局表示。
在代码中,具体参数为:
COMPRESSION_RATE = 4MAX_T_OUT = 20(,最终 memory budget)TARGET_T_MID = 80(中间阶段目标长度)W_IN = 64(sliding window 大小)W_OUT_PER_CHUNK = 16(每个 chunk 压缩后长度)TARGET_N_CHUNKS = 5
# Pseudocode: HPMC hierarchical compression (from dit_model.py)
def hierarchical_compress(z_history, encoder, T_max=20, k=4):
L = z_history.shape[2] # temporal length
if L <= k * T_max:
# Mode 1: direct compression
z_com = encoder(z_history) # [B, C, L/4, H, W]
else:
# Mode 2: hierarchical compression
# Stage 1: local compression via sliding window
W, N = 64, 5
S = max(1, (L - W) // (N - 1)) # dynamic stride
chunks = []
for i in range(N):
start = i * S
end = min(start + W, L)
chunk = z_history[:, :, start:end] # [B, C, W, H, W]
compressed = encoder(chunk) # [B, C, W/4, H, W]
chunks.append(compressed)
# Stage 2: global compression
z_mid = torch.cat(chunks, dim=2) # [B, C, ~80, H, W]
z_com = encoder(z_mid) # [B, C, 20, H, W]
return z_com # fixed size T_max3.2.3 Context Injection to DiT
DiT 的输入是 compressed history 、last-frame latent (作为 local memory)和 noisy target latent 的时序拼接,加上 binary mask 区分 context 和 denoising target:
3.2.4 Joint Optimization — 关键设计决策
HPMC 的核心区别在于:compressor 与 DiT backbone 联合端到端训练(Figure 2a 中的火焰图标)。通过最小化 future frame 的 generation loss,compressor 自主学会保留哪些信息。这使得模型不需要显式 pose metadata 就能维持空间一致性——即 pose-free anchoring。
3.3 Uncertainty-aware Action Labeling (UAL)
3.3.1 Motion Decoupling and Tri-state Labeling
给定视频序列,先用 off-the-shelf pose estimator(VGGiT)估计连续帧间的 relative camera pose ,然后解耦为 translation magnitude 和 rotation magnitude 。
对每个维度,基于两个阈值 (noise floor)和 (action trigger)进行三态标注:
- No-operation:运动幅度低于 noise floor,判定为静止
- Discrete Action:运动幅度超过 action trigger,映射到语义方向(translation: {W, A, S, D},rotation: {Left, Right, Up, Down})
- Uncertain:介于两者之间的模糊区域,显式保留而非强行归类
3.3.2 为什么 “Uncertain” 类别至关重要
传统方法要么把低信噪比运动强行标为某个方向(引入标注噪声),要么直接丢弃这些样本(损失数据量)。UAL 通过保留 Uncertain 类别:
- 最大化 real-world video data 的利用率
- 保护 deterministic action space 不被 jitter 或 slow-drifting pose 污染
- 确保 temporal continuity(不因丢弃样本而打断序列)
3.3.3 Action Encoding
Action Encoder 将 move 和 view 两个离散序列分别通过 embedding → 两层 1D Conv(stride=2)→ linear projection 映射到模型维度(1536),实现 4× temporal downsampling 以匹配 compressed latent 的分辨率。
# Pseudocode: ActionEncoder (from dit_model.py lines 437-468)
class ActionEncoder:
def __init__(self, dim=1536, vocab_size=10):
self.move_emb = Embedding(vocab_size, dim) # 10 classes
self.view_emb = Embedding(vocab_size, dim)
self.conv1 = Conv1d(dim, dim, kernel=3, stride=2, pad=1)
self.conv2 = Conv1d(dim, dim, kernel=3, stride=2, pad=1)
self.proj = Linear(dim, dim)
def forward(self, move, view):
# move, view: [B, L] integer sequences (L=81 for val)
e = self.move_emb(move) + self.view_emb(view) # [B, L, dim]
e = e.permute(0, 2, 1) # [B, dim, L]
e = silu(self.conv1(e)) # [B, dim, L/2]
e = silu(self.conv2(e)) # [B, dim, L/4]
e = self.proj(e.permute(0, 2, 1)) # [B, L/4, dim]
return e.unsqueeze(-1).unsqueeze(-1) # [B, dim, L/4, 1, 1]3.4 Revisit-Dense Finetuning Strategy

Figure 3 解读:Figure 3 展示了一个关键的 pilot study 发现。Row 1-3 显示:仅 10-100 个训练序列就足以激活 loop-closure 能力(Memory activation saturates at ~100 sequences)。Row 4 揭示了一个严重问题:当推理时的 horizon 显著超过训练时的 context window(如训练 4 chunks、推理 6 chunks)时,memory 会发生 catastrophic collapse——视觉漂移和幻觉大量出现。
基于 pilot study 的两个关键发现:
发现 1: High Sample Efficiency:loop-closure 不需要海量数据,100 个 revisit-dense 序列就够了。关键不是数据总量,而是单条轨迹的时长和拓扑密度。
发现 2: Context-Bound Extrapolation:memory stability 与 training temporal window 严格耦合。训练时只见过 4-chunk context 的模型,在推理 6-chunk 时会 collapse。
据此设计两阶段训练:
-
Open-Domain Pre-training:在 30+ 小时的 internet 第一人称探索视频上预训练,学习 diverse visual priors 和 local dynamics。此阶段使用 direct compression(Mode 1),context 限制在 4 temporal chunks。
-
Memory Activation via RDD:在仅 30 分钟的 Revisit-Dense Dataset 上 finetune。该数据集用 iPhone 17 Pro Action Mode 录制,特点是频繁 loop-closure。此阶段启用 hierarchical compression(Mode 2),temporal receptive field 扩展到 16 chunks。
3.5 Inference Pipeline
推理时以 chunk-wise autoregressive 方式生成:
# Pseudocode: inference pipeline (from infworld_inference.py)
def generate_long_video(model, vae, cond_image, actions, num_chunks=13):
# Encode condition image
z_cond = vae.encode(cond_image) # [1, C, 1, h, w]
buffer = z_cond
all_frames = [cond_image]
for chunk_i in range(num_chunks):
# Compress history
z_com = model.hierarchical_compress(buffer) # [1, C, T_max, h, w]
z_loc = buffer[:, :, -1:] # last frame latent
# Get action for this chunk
move_chunk = actions['move'][chunk_i]
view_chunk = actions['view'][chunk_i]
# Generate next chunk (81 frames → 21 decoded frames)
z_pred = scheduler.sample(
model, z_size=(1, C, 21, h, w),
additional_args={
'image_cond': torch.cat([z_com, z_loc], dim=2),
'move': move_chunk, 'view': view_chunk
}
)
# Decode and accumulate
frames = vae.decode(z_pred)
all_frames.append(frames)
buffer = torch.cat([buffer, z_pred], dim=2) # grow history
return all_frames3.6 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| HPMC (Hierarchical Pose-free Memory Compressor) | infworld/models/dit_model.py L1011-1084 | TemporalLatentEncoder, compression logic in WanModel.forward() |
| Temporal Encoder (3D-ResNet) | infworld/models/dit_model.py L149-220 | TemporalLatentEncoder (ConvIn→ResBlock→Down→MidAttn→ConvOut) |
| Temporal Downsampling | infworld/models/dit_model.py L69-77 | TemporalDownsample (kernel=(3,2,1), stride=(2,1,1)) |
| Action Encoder | infworld/models/dit_model.py L437-468 | ActionEncoder (move/view embeddings + Conv1d ×2) |
| Tri-state Action Labeling | 代码中未直接包含标注脚本 | Vocabulary: 10 classes (0=no-op, 1-8=directions, 9=uncertain) |
| History-Current Separation in Attention | infworld/models/dit_model.py L757-789 | WanAttentionBlock.forward() with num_c parameter |
| DiT Backbone (Wan 2.1) | infworld/models/dit_model.py L864-1286 | WanModel (dim=1536, layers=30, heads=12) |
| 3D RoPE | infworld/models/dit_model.py L373-416 | rope_params(), rope_apply() |
| Causal VAE | infworld/vae/vae.py L17-36 | CausalConv3d, WanVAE |
| RFlow Scheduler | infworld/models/scheduler.py L72-150 | RFlowScheduler (shift=7, steps=30) |
| Inference Pipeline | scripts/infworld_inference.py L295-381 | chunk-wise autoregressive generation, 13 chunks |
4. Experimental Setup
4.1 训练配置
- Backbone: Wan 2.1-1.3B(dim=1536, 30 layers, 12 heads, in_channels=20)
- 分辨率: 480P
- Optimizer: AdamW, lr = , constant
- Memory Compressor: 3D-ResNet, temporal compression factor
- Hierarchical compression: overlapping chunks, frames,
- Hardware: 16 × NVIDIA H800 GPUs
- Mixed precision: bfloat16
- Text encoder: UMT5-XXL (model_max_length=512)
- Scheduler: RFlow (shift=7, 30 sampling steps)
- Pre-training: direct compression, max 4 temporal chunks, history ≤ 320 frames
- Finetuning: hierarchical compression, 16 chunks from 1 image
4.2 数据
- Pre-training Set: 30+ 小时 internet 第一人称探索视频(缺少 revisit)
- Finetuning Set (RDD): 30 分钟高质量 revisit-dense 视频,iPhone 17 Pro Action Mode 录制
- 推理时: num_frames=81 per chunk(21 decoded frames),共 13 chunks
4.3 评测
- Benchmark: 100 diverse scenes(Indoor, Street, Nature, Fantasy),每个场景 10 条 handcrafted 16-chunk 轨迹
- 初始帧生成: Nanobanana text-to-image model
- Baselines: HY-World 1.5, Hunyuan-GameCraft, Yume 1.5, Matrix-Game 2.0
- VBench 指标: Motion Smoothness↑, Dynamic Degree↑, Aesthetic Quality↑, Imaging Quality↑
- User Study (ELO): Memory Consistency↓, Visual Fidelity↓, Action Responsiveness↓ + Overall ELO↑
5. Experimental Results
5.1 主结果

Figure 7 解读:Table 1 同时报告了 VBench 客观指标和 User Study 主观评分。Infinite-World 在 VBench 平均分(0.8119)上略低于 Yume 1.5(0.8141,主要靠 aesthetic quality 的 5B 模型优势),但在 User Study 所有维度上全面领先——特别是 Memory Consistency(1.92 vs 次优 2.43)和 Visual Fidelity(1.67 vs 次优 1.91),ELO Rating 达到 1719,领先次优 HY-World 1.5(1542)177 分。
核心数字:
| 模型 | VBench Avg | Memory↓ | Fidelity↓ | Action↓ | ELO↑ |
|---|---|---|---|---|---|
| Hunyuan-GameCraft | 0.7785 | 2.67 | 2.49 | 2.56 | 1311 |
| Matrix-Game 2.0 | 0.8068 | 2.98 | 2.91 | 1.78 | 1432 |
| Yume 1.5 | 0.8141 | 2.43 | 1.91 | 2.47 | 1495 |
| HY-World 1.5 | 0.7949 | 2.59 | 2.78 | 1.50 | 1542 |
| Infinite-World | 0.8119 | 1.92 | 1.67 | 1.54 | 1719 |
关键发现:
- Yume 1.5 的 VBench 高分主要来自 aesthetic quality(5B 大模型),但 action control 很弱——经常 default 到 “move forward”
- HY-World 1.5 action responsiveness 最强(1.50),因为依赖完美合成数据训练
- Infinite-World 用 noisy real-world data 达到了接近 HY-World 1.5 的 action control(1.54 vs 1.50),同时 memory 和 fidelity 远超所有方法
5.2 定性比较

Figure 4 解读:Figure 4 对比了 5 个方法在同一场景的不同 chunk 生成结果。Matrix-Game 2.0 画质不错但无 memory 机制;Hunyuan-GameCraft 保持粗糙场景但丢失细节;HY-World 1.5 短期一致但长期出现 ghosting artifacts;Yume 1.5 因 motion distribution bias 难以执行非前进动作。Infinite-World 通过 HPMC 保持全局 landmarks 并成功执行 loop closure。
5.3 Memory Efficiency

Figure 5 解读:Figure 5 对比了三种策略在不同 context 长度下的 GPU memory 消耗(80GB H800)。No compression 在 ~180 帧时 OOM;Direct compression 呈线性增长;Hierarchical compression 在初始增长后稳定在 ~45GB,即使 context 延伸到 1300 帧也保持恒定——这是 1000+ 帧交互的关键使能条件。
5.4 User Study
Figure 6 解读:Infinite-World 在 Memory Consistency(1.92)和 Visual Fidelity(1.67)上显著优于所有 baselines,证明 HPMC 有效抑制了 1000 帧 horizon 上的 error accumulation。Action Responsiveness(1.54)与依赖合成数据训练的 HY-World 1.5(1.50)基本持平——这说明 uncertainty-aware action labeling 有效弥合了 real-world noisy pose 与 clean synthetic data 之间的 gap。
5.5 Ablation Study
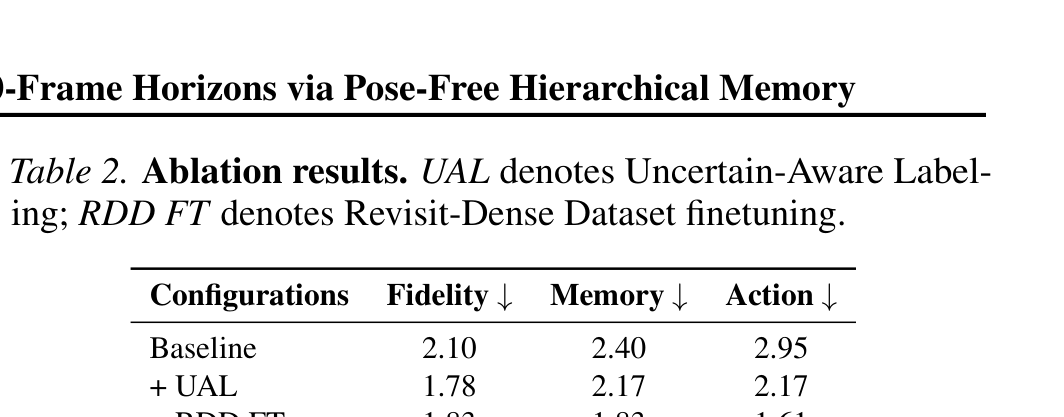
Figure 8 解读:
| Configuration | Fidelity↓ | Memory↓ | Action↓ |
|---|---|---|---|
| Baseline | 2.10 | 2.40 | 2.95 |
| + UAL | 1.78 | 2.17 | 2.17 |
| + RDD FT | 1.83 | 1.83 | 1.61 |
| Full Model | 1.75 | 1.69 | 1.38 |
- RDD Finetuning 是 memory consistency 的主要驱动力:Memory rank 从 2.40 → 1.83(+RDD FT),同时 action control 也大幅改善(2.95 → 1.61),因为 RDD 数据的轨迹稳定且动作一致。
- UAL 主要提升 action responsiveness:Action rank 从 2.95 → 2.17(+UAL),通过 tri-state logic 保护 action space 不被 noisy pose 污染。
- 两者互补:Full model 在所有维度都是最优。
5.6 局限性
报告明确指出的未来方向:
- Cumulative drift and visual degradation 仍然存在——可能通过 self-forcing 或 refined noise schedules 改善
- Model distillation and scaling 可进一步提升 inference speed 和 visual fidelity
- 当前 1.3B 模型在 aesthetic quality 上不如 5B 的 Yume 1.5
5.7 总结
Infinite-World 的最大贡献不是某个单点技巧,而是证明了一个完整的范式:
- Pose-free memory 是可行的:通过 joint optimization,compressor 自主学会保留几何信息,不需要显式 pose
- Real-world training 是可行的:通过 UAL 处理 noisy pose,30 分钟 revisit-dense data 就能激活 1000-frame memory
- 固定 memory budget 是可行的:hierarchical compression 让 GPU memory 恒定,解除 1000+ 帧交互的计算瓶颈
如果把 Infinite-World 和 HY-World 1.5 - A Systematic Framework for Interactive World Modeling with Real-Time Latency and Geometric Consistency 对比看,两者代表了 world model memory 设计的两条路线:显式几何 retrieval vs 隐式学习压缩。Infinite-World 证明后者在 real-world setting 中更鲁棒,因为它从根本上不依赖 camera pose 的准确性。