HY-World 1.5: A Systematic Framework for Interactive World Modeling with Real-Time Latency and Geometric Consistency
Authors: Tencent Hunyuan(具体贡献者见报告末尾 Contributors) Affiliations: Tencent Hunyuan arXiv: 2512.14614 Project Page: 3d.hunyuan.tencent.com/sceneTo3D GitHub: Tencent-Hunyuan/HY-WorldPlay
1. Motivation
1.1 现有 interactive world model 的核心矛盾
这篇技术报告要解决的问题非常明确:实时性(speed) 与 长期几何一致性(memory / consistency) 之间存在根本张力。
- 一类方法通过蒸馏或轻量化模型实现低延迟,但缺少有效 memory 机制,导致用户绕场景一圈再回到原位置时,场景内容会发生漂移或重绘。
- 另一类方法虽然能维持 revisiting consistency,但依赖显式或隐式 memory,结构复杂、推理昂贵,很难做到实时 streaming generation。
- 交互式 world modeling 还比普通视频生成多出一个难点:模型不仅要”生成逼真视频”,还要精确响应键盘/鼠标动作,并在长时序 autoregressive rollout 中避免 error accumulation。

Figure 1 解读:Figure 1 展示了 HY-World 1.5 的全场景能力覆盖。从左到右依次为:real-world navigation(现实场景漫游)、stylized world(风格化世界)、third-person mode(第三人称视角)、3D reconstruction(几何重建)、promptable event(可交互事件触发)。这张图直接定义了系统的目标:不是只做某一种场景的 demo,而是一个 general-purpose 的 interactive world model。
报告在 Table 1 中将现有方法概括成一个未解问题:此前没有方法能够同时满足 general scene + real-time + long-term consistency + long-horizon。
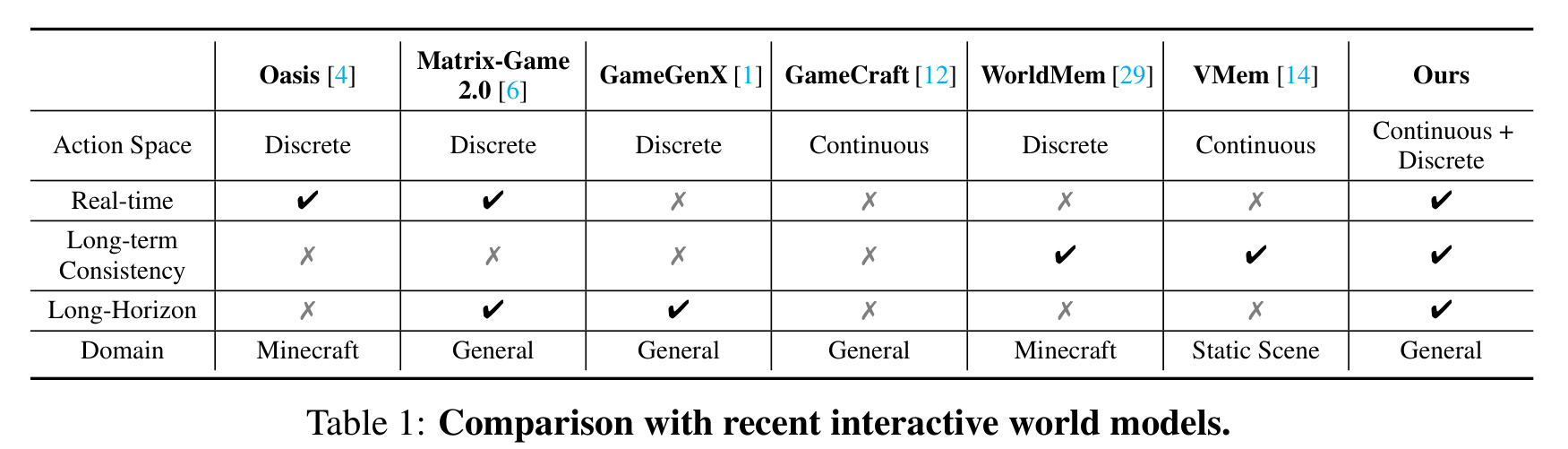
Figure 2 解读:Table 1 系统对比了 HY-World 1.5 与近期交互式 world model 在关键维度上的能力差异:是否支持 general scene、是否 real-time、是否具备 long-term memory、是否支持 long-horizon generation。可以看到,之前的方法至多覆盖其中 2-3 项,HY-World 1.5 是首个声称四项全部达成的系统。
1.2 HY-World 1.5 要回答什么问题
HY-World 1.5 试图构建一个真正可玩的世界模型。其目标不是一次性离线生成一个 3D 世界,而是给定一张图像或一段文本描述后,模型持续预测未来视频 chunk,并对用户的导航动作实时响应:
其中:
- 是当前要生成的下一个 chunk;
- 是历史 observation;
- 是历史动作;
- 是当前动作;
- 是文本或图像条件。
换句话说,这篇报告的研究动机不是单纯提升短视频画质,而是提出一个可实时交互、可长程回访、可事件触发、可支持 3D reconstruction 的 streaming world modeling system。
1.3 为什么这个问题值得研究
- 对 embodied agent / robotics 来说,模型必须长期记住环境几何,而不是只会生成短期”看起来像”的视频。
- 对游戏与虚拟世界生成来说,低延迟决定可交互性,长期一致性决定沉浸感。
- 对 3D / 4D reconstruction 来说,多视角几何一致的视频序列本身就是更好的重建输入。
因此,HY-World 1.5 的价值在于把 world model 从”离线演示”推进到”在线可操作系统”。
2. Idea
2.1 核心思想
HY-World 1.5 的核心是 WorldPlay:一个面向 interactive streaming generation 的 chunk-wise autoregressive video diffusion model。它把未来视频生成拆成连续的 next-chunk prediction 问题,每个 chunk 对应 16 帧视频(4 个 latent)。
作者强调模型由四个关键设计共同支撑:
- Dual Action Representation:同时使用 discrete action(键盘/鼠标)与 continuous camera pose,既保留跨场景尺度的稳定控制能力,又提供精确的空间定位。
- Reconstituted Context Memory:不是简单保留全部历史,而是每次生成新 chunk 时,从历史中重建一个更有用的 memory context。
- WorldCompass RL post-training:通过专门面向 world model 的 RL post-training,强化复杂动作跟随与视觉质量。
- Context Forcing distillation:解决 teacher / student memory context mismatch,把 memory-aware autoregressive 模型蒸馏为 few-step、可实时推理的版本。
2.2 与现有方法的根本区别
这篇报告与已有 interactive world models 的区别,不是”再加一个 memory module”这么简单,而是把整个系统拆成了四个阶段:
- 数据构建;
- autoregressive generative pre-training;
- control + memory middle-training;
- RL / distillation post-training;
- 工程化 streaming inference。
也就是说,HY-World 1.5 不是一个单点 trick,而是一个从数据、模型、训练到部署端到端设计的系统框架。
2.3 一句话总结创新
HY-World 1.5 的本质创新,是把 world model 组织成一个 memory-aware autoregressive diffusion system,再通过 context-aligned distillation 和系统级 inference optimization,把它压到 24 FPS 的实时交互速度,同时尽量保住 revisiting 时的几何一致性。
3. Method
3.1 整体框架
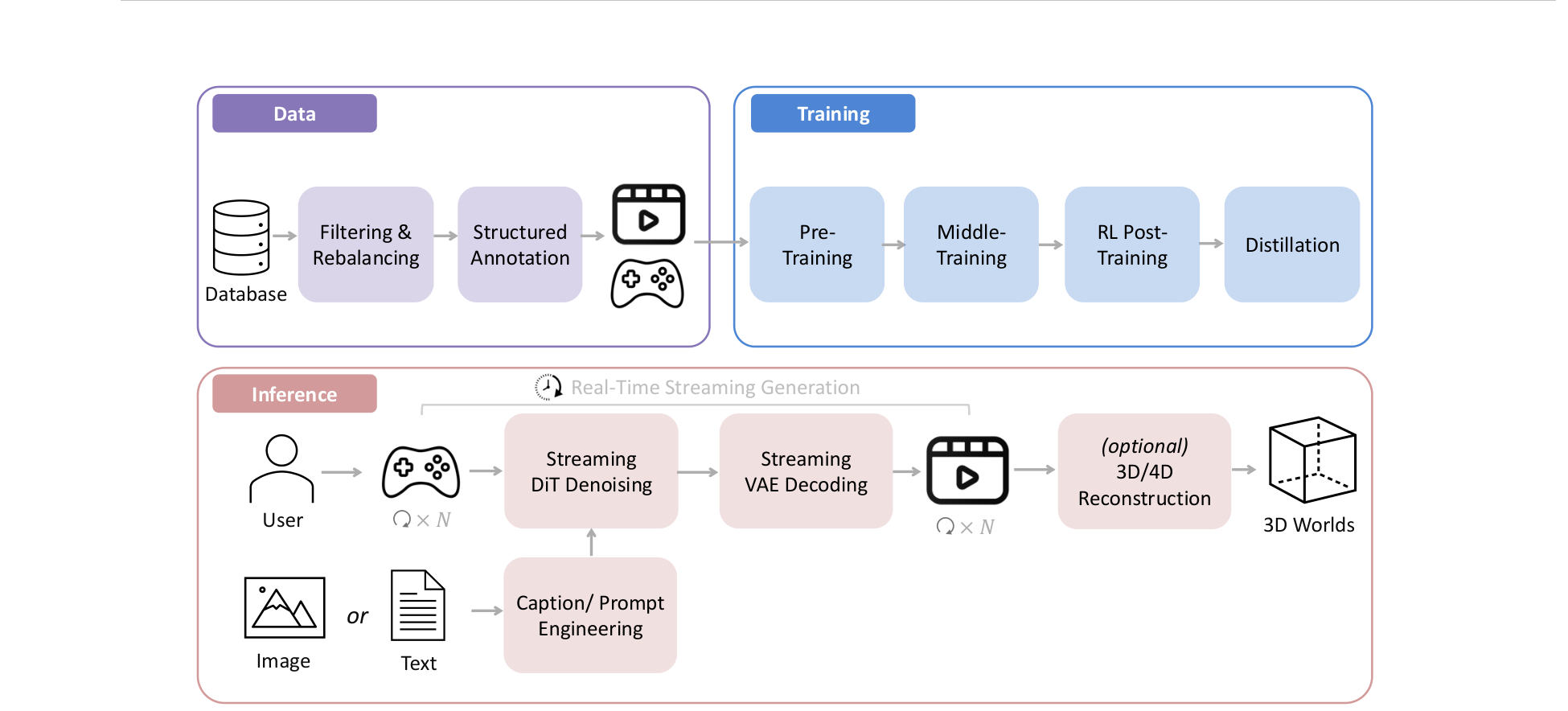
Figure 3 解读:这张图给出了 HY-World 1.5 的完整系统视角。左侧是数据系统,包括 database、filtering/rebalancing 和 structured annotation;中间是训练管线,按 pre-training、middle-training、RL post-training、distillation 串联;右侧是 inference 侧,核心是 Streaming DiT Denoising + Streaming VAE Decoding,并可选接 3D/4D reconstruction。它说明作者不是只做一个 diffusion backbone,而是把 world modeling 拆成一整套可部署的流式系统。
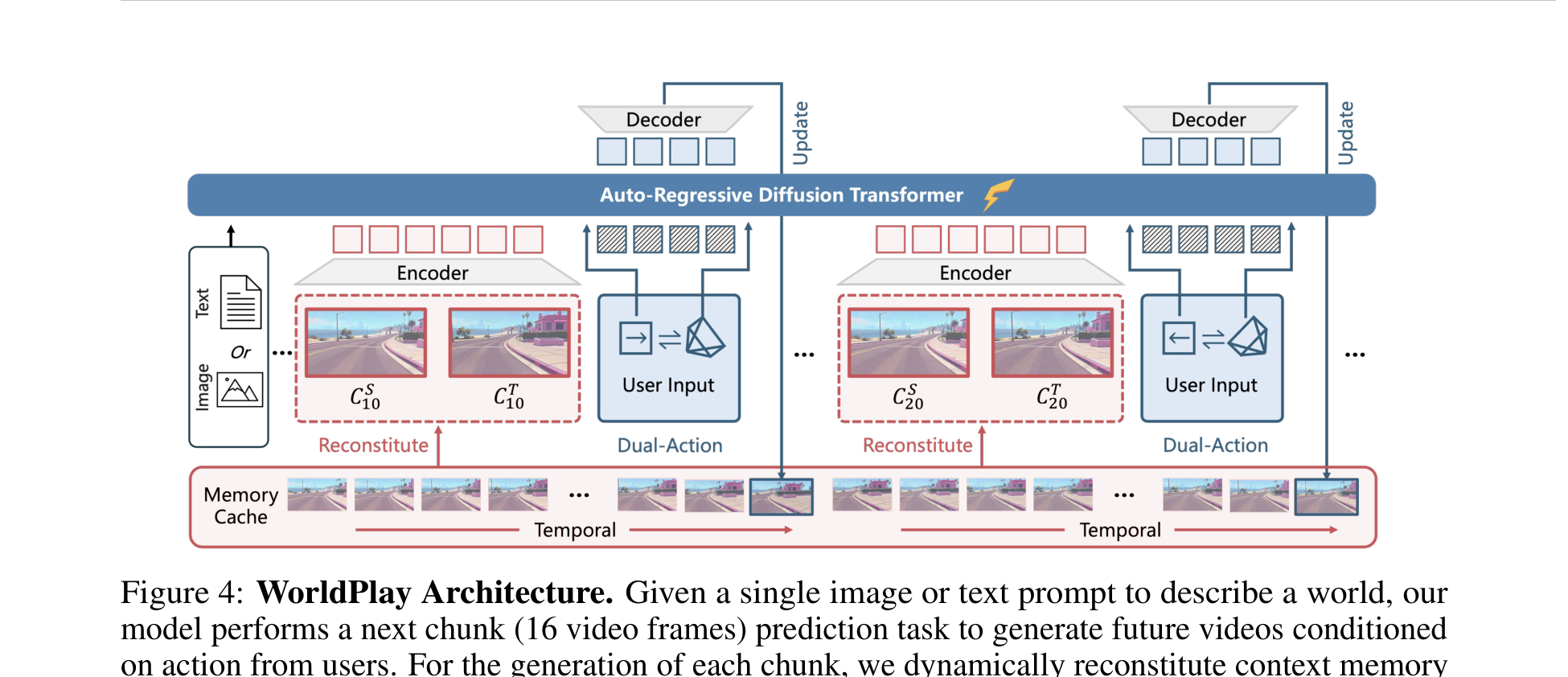
Figure 4 解读:Figure 4 直接定义了 WorldPlay 的生成范式。输入是单张图像或文本 prompt,模型执行的是”预测下一个 16-frame chunk”的任务,而不是一次性生成整段视频。每个 chunk 生成前都会从过去 chunk 中动态重建 context memory,因此模型的 autoregressive rollout 不只是串行生成,还包含 memory retrieval 和 context rebuilding 两个步骤。
3.2 Pre-Training:从 bidirectional video diffusion 到 chunk-wise autoregressive model
作者首先依赖现有 bidirectional video diffusion model 的生成能力。底层结构是:
- 3D VAE 将视频压到 latent space;
- DiT 在 latent space 上建模;
- 训练目标使用 flow matching。
对应的 paper 公式为:
其中:
- 为 3D VAE 编码后的视频 latent;
- 为高斯噪声;
- 为 diffusion timestep 下的 noisy latent;
- 为目标 velocity。
为了把 bidirectional model 变成可无限长 streaming generation 的 world model,作者将视频划分为 chunk。报告里明说:
- 一个 chunk = 4 个 latent;
- 对应 16 帧视频;
- 训练时参考 Diffusion Forcing,为不同 chunk 加不同噪声级别,并把 bidirectional self-attention 改造成 block causal attention。
因此,WorldPlay 的 generative core 不是逐帧 Transformer,也不是一次性整段 diffusion,而是chunk-wise autoregressive diffusion。
3.3 Dual Action Representation:离散动作 + 连续位姿双路控制
作者认为只用 discrete action 或只用 continuous camera pose 都有问题:
- 只用 discrete action:运动风格稳定,但无法精确定位历史位置;
- 只用 continuous pose:可精确定位,但会因场景尺度差异导致训练不稳定。
因此他们采用 Dual Action Representation:
- Discrete action:键盘与鼠标信号通过零初始化 MLP 投影到 timestep embedding 路径;
- Continuous pose:通过 PRoPE(Projective Positional Encoding)注入 self-attention。
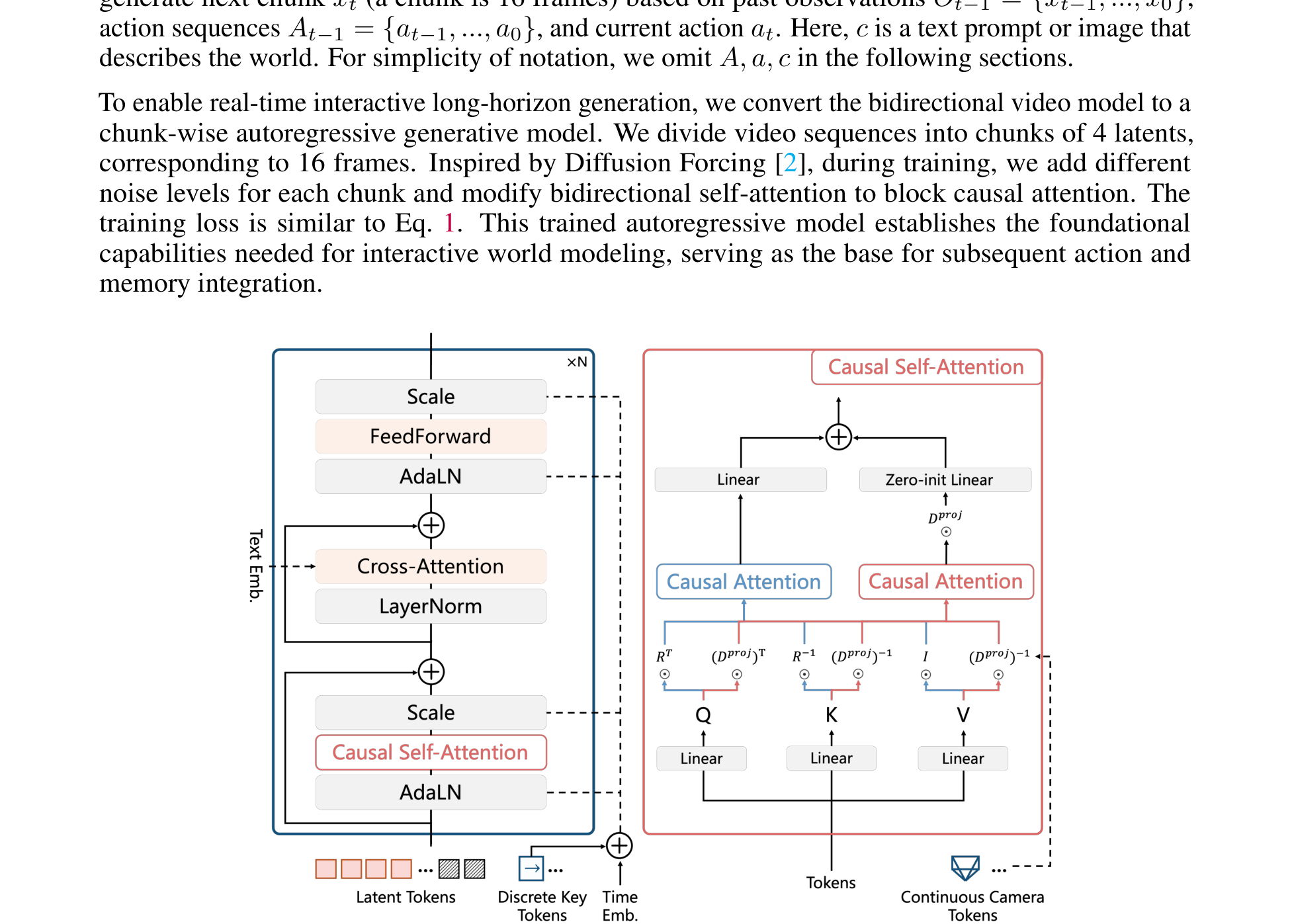
Figure 5 解读:Figure 5 展示了 DiT block 的内部结构,清晰地说明了两路 action 如何注入 Transformer。左侧的 RoPE 分支处理标准时空位置编码;右侧的 PRoPE 分支则将 continuous camera pose 通过 projective positional encoding 注入 self-attention 的 Q/K/V。两路 attention 输出通过零初始化 projection 合并回主干。这种设计使得离散的交互信号(键盘/鼠标)和连续的空间定位信号(camera pose)各司其职、互不干扰。
离散与连续控制的数学表达分别对应:
最终每个 self-attention block 输出为:
公开代码与论文完全对齐:
- 离散 action 的零初始化注入位于
hyvideo/models/transformers/worldplay_1_5_transformer.py的add_action_parameters(); - 连续 pose 的 PRoPE 变换位于
hyvideo/prope/camera_rope.py的prope_qkv(); - 在
MMDoubleStreamBlock.forward_vision()中,两路 attention 同时计算,再将 PRoPE 分支通过零初始化 projection 合回主干。
# Pseudocode: dual action injection (from released code)
def inject_dual_action(img_tokens, t, action, viewmats, intrinsics):
vec = time_embed(t)
vec = vec + action_embedder_zero_init(action)
q, k, v = project_qkv(img_tokens)
q_rope, k_rope = apply_rotary_emb(q, k)
q_prope, k_prope, v_prope, apply_out = prope_qkv(
q, k, v, viewmats=viewmats, Ks=intrinsics
)
attn_main = attention(q_rope, k_rope, v)
attn_pose = attention(q_prope, k_prope, v_prope)
attn_pose = apply_out(attn_pose)
img_tokens = img_tokens + gate(
proj_main(attn_main) + proj_pose_zero_init(attn_pose), vec
)
img_tokens = img_tokens + gate(mlp(norm(img_tokens)), vec)
return img_tokens3.4 Reconstituted Context Memory:动态重建 memory context

Figure 6 解读:Figure 6 对比了三种 memory 使用方式。(a) Full context 把全部历史都送进模型,代价过高且冗余;(b) 绝对时间索引下,历史 memory 与当前 chunk 的相对位置会越来越远,RoPE extrapolation 误差和 memory attenuation 都会加剧;(c) Relative indices / temporal reframing 则重新分配 memory 的时序索引,让远古但几何相关的 frame 在 attention 里”看起来更近”,从而保持影响力。
作者把 memory 拆成两部分:
其中:
- 是最近的 temporal memory;
- 是从更早历史中采样的 spatial memory。
论文表述上只说 spatial memory 依据 FOV overlap 与 camera distance 选择;公开代码则把这一点实现得很具体。hyvideo/utils/retrieval_context.py 中的 select_aligned_memory_frames() 会:
- 固定保留最近
temporal_context_size=12帧; - 再从更早历史里,以 4-frame chunk 为单位评估与当前 query chunk 的重合程度;
- 相似度由
calculate_fov_overlap_similarity()估计,本质上是 Monte Carlo 采样下的 frustum overlap; - 最后补齐 memory frame,默认
memory_frames=20。
# Pseudocode: reconstituted context memory (from released code)
def select_memory_frames(w2c_list, current_frame_idx):
recent_context = range(max(0, current_frame_idx - 12), current_frame_idx)
query_clip = range(current_frame_idx, current_frame_idx + 4)
candidate_scores = []
for hist_idx in range(4, current_frame_idx - 12, 4):
score = 0.0
for query_idx in query_clip:
sim_1 = fov_overlap(query_idx, hist_idx)
sim_2 = fov_overlap(query_idx, hist_idx + 2)
score += 1.0 - 0.5 * (sim_1 + sim_2)
candidate_scores.append((hist_idx, score / len(query_clip)))
candidate_scores.sort(key=lambda item: item[1])
memory = [0, 1, 2, 3]
for hist_idx, _ in candidate_scores:
if len(memory) >= 20 - 12:
break
memory.extend(range(hist_idx, hist_idx + 4))
return sorted(set(recent_context).union(memory))这里可以看出,论文中的”reconstituted context memory”并不是模糊概念,而是按 chunk 粒度做 geometry-aware retrieval。
3.5 Temporal Reframing:让旧 memory 在注意力里”重新变近”
论文中的 temporal reframing 解决的是 standard RoPE 的绝对时间索引问题。
问题根源:Standard RoPE 使用绝对 temporal indices,随着 rollout 长度不断增长,memory token 与当前 chunk 之间的距离会无限增大。这带来两个严重后果:(1) 超出训练时的 interpolation range,导致 extrapolation artifacts;(2) 远古但几何相关的 spatial memory frame 在 attention 中的影响力被严重削弱(memory attenuation)。即便这些 frame 包含当前视角急需的空间信息,绝对索引的远距离也会让它们在 softmax 中几乎被忽略。
Temporal Reframing 方案:丢弃绝对时间索引,对当前上下文中所有 frame(包括 spatial memory、temporal memory 和当前 chunk)动态重新分配 positional encoding。核心思想是建立固定的、较小的 relative distance 到当前 chunk,而不论这些 frame 的实际 temporal gap 有多大。效果上,这相当于把重要的历史 frame 在 positional encoding space 中”拉近”,使它们始终处于模型训练时见过的有效距离范围内。
在公开推理代码中,这一点对应到 worldplay_video_pipeline.py 的两个参数:
rope_temporal_sizestart_rope_start_idx
当模型先对 history memory 建 cache,再对当前 chunk 做 denoising 时,rope 的 temporal size 会被设置为:
同时当前 chunk 的起始 rope index 被手动设为:
这和论文中的 temporal reframing 是一致的:不是沿用真实的全局绝对时间,而是对”当前 memory + 当前 chunk”这一小上下文重新编号。无论模型已经 rollout 了多少步,每一次新 chunk 的生成都只看到一个”重新编号”的 compact context window,从而始终在训练分布内工作。
3.6 WorldCompass:面向 world model 的 RL post-training
3.6.1 为什么 world model 需要 RL
报告在 Section 5.1 明确指出了 pixel-level supervised pre-training 的根本局限:pixel-level supervision 只能隐式地教会模型 action following。在简单动作下这种隐式学习尚可,但当面对复杂组合动作(如同时前进 + 转弯 + 仰视)时,模型性能会出现 plateau,且容易产生视觉伪影。
然而,对 world model 做 RL 比对 LLM 做 RL 困难得多,原因有三:
- Long-horizon rollout 代价极高:interactive world model 的 rollout 涉及连续多个 chunk 的 diffusion denoising,计算成本远高于 LLM 的 token-level generation。单次 rollout 所需的 GPU 时间和显存都很大。
- Reward function 设计尚未被充分探索:不同于 LLM 有 RLHF 和各种 reward model 的成熟经验,world model 的”好”需要同时衡量 action following accuracy、visual quality、geometric consistency 等多个维度,如何设计不引发 reward hacking 的 reward function 是开放问题。
- 有效 RL 算法选择尚未被充分探索:diffusion-based generation 的 RL 训练不同于标准 MDP,需要专门的算法设计。
3.6.2 WorldCompass Framework 的三个关键创新
WorldCompass 针对上述挑战提出了系统性解决方案:
1. Clip-Level Rollout:重新设计了面向 interactive long-horizon generation 的 rollout 机制。与传统 full-sequence rollout 不同,WorldCompass 在 clip level 执行 rollout,这带来两个好处:(a) 显著提升 rollout efficiency,降低单次 RL 更新的计算成本;(b) 提升 reward signal 的粒度,让每个 clip 都能获得反馈而不是只在序列末尾给一个 sparse reward。此外,clip-level rollout 还能缓解 exposure bias,因为模型在 RL 训练中被迫依赖自己的 imperfect predictions 而非 ground truth context,从而更好地适应推理时的 autoregressive 误差积累。
2. Complementary Reward Functions:至少包含两类互补的 reward signal:
- Action following score:衡量生成视频是否准确响应了输入的 discrete / continuous action;
- Visual quality score:衡量生成画面的视觉保真度与时序一致性。
多维度互补反馈的关键作用是抑制 reward hacking:如果只用 action following reward,模型可能通过降低画质来”走捷径”满足动作对齐;如果只用 visual quality reward,模型可能忽略动作信号。两者互补可以互相约束,引导模型向真正的”好”方向优化。
3. DiffusionNFT:采用先进的 RL 算法 [35],并集成多种效率优化策略,专门用于引导 autoregressive video diffusion model 的行为。DiffusionNFT 的设计考虑了 diffusion model 的特殊性质——每个 denoising step 都可以看作一个 action,整个 denoising trajectory 构成一个 episode,reward 在 clip 生成完成后给出。
3.6.3 当前公开状态
这里必须明确说明:当前公开仓库没有找到 WorldCompass RL 训练代码。README 中 HY-World1.5-Autoregressive-480P-I2V-rl 和 HY-World1.5-Autoregressive-480P-I2V-rl-distill 都标注为 To be released。因此这一部分只能严格基于报告描述总结,不能伪造”来自代码的 RL 伪代码”。
3.7 Context Forcing:解决 teacher / student 的 memory context mismatch
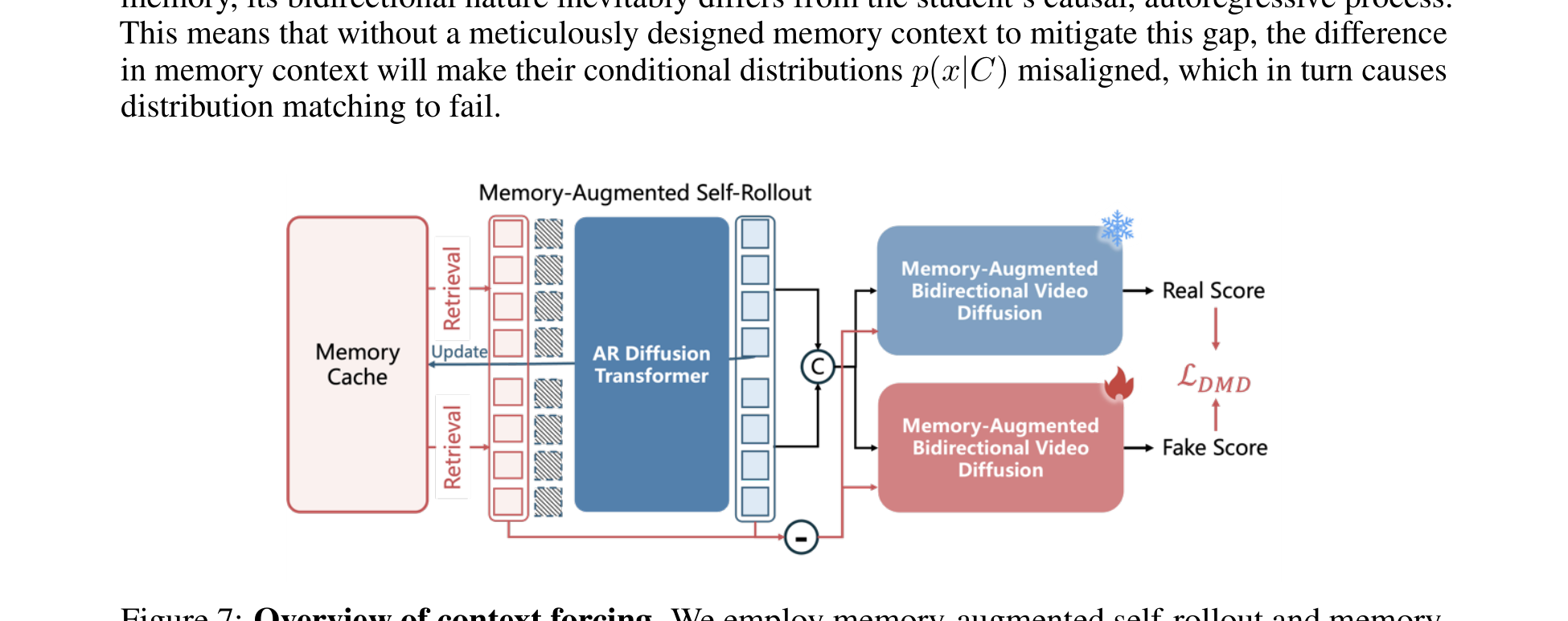
Figure 7 解读:Figure 7 展示了 context forcing 的关键思想。student 先做 memory-augmented self-rollout;teacher 不再是普通 bidirectional diffusion model,而是一个也带 memory 的 bidirectional teacher,并且它看到的 context 是从 student 的 memory context 中把待预测 chunk mask 掉之后构成的。这样 teacher / student 的条件分布更接近,减少 distillation 时最致命的 context mismatch。
3.7.1 Distribution Matching 的核心挑战
标准蒸馏方法在应用于 memory-aware autoregressive model 时会遇到一个根本性问题:teacher 和 student 的 context access pattern 完全不同。
- Teacher(bidirectional model):可以同时看到过去和未来的所有 token,具有全局双向注意力;
- Student(causal AR model):只能看到过去的 token,通过 reconstituted context memory 获取历史信息。
即使对 teacher 也做 memory augmentation,它的 bidirectional context 和 student 的 causal memory context 之间仍然存在根本差异。这导致两者的 conditional distribution 发生 misalignment——teacher 在条件 下学到的分布与 student 在条件 下需要匹配的分布不一致。因此,标准 distribution matching(如 DMD)的假设被打破,蒸馏效果大打折扣。
3.7.2 Context Forcing 方案
Context Forcing 的核心思路是:让 teacher 看到的 context 与 student 看到的 context 尽可能对齐。具体做法:
- Student self-rollout:student 先用自己的 memory mechanism 自回归生成 4 个 chunk,每个 chunk 生成后都会更新 memory context;
- Teacher context alignment:teacher 被赋予 memory,并且其 context 被构造为 student 的 memory context 减去待预测的 target chunks。即 。
- 这样,teacher 和 student 在预测同一个 target chunk 时,看到的条件信息是对齐的,从而使 distribution matching 的假设重新成立。
标准 distribution matching 梯度为:
student 的自回归 self-rollout 写为:
teacher 侧的 aligned context 为:
3.7.3 Algorithm 1 详解

Figure 8 解读:算法 1 展示了 context forcing 的训练流程。具体步骤如下:
- Progressive chunk length:逐步增大 max chunk length ,让模型从短 rollout 逐渐学会长 rollout 的蒸馏;
- Sample chunk length:随机采样当前 rollout 的 chunk length ;
- 对每个 chunk :
- 初始化 noise;
- 从历史 rollout 结果中 reconstitute memory context;
- 采样 denoising steps ;
- Student 执行 步 self-rollout 得到 denoised output;
- Teacher context alignment:将 teacher 的 context 设置为 student 的 context 减去 target chunks,确保条件分布对齐;
- Add noise:对 student 的 self-rollout 结果加噪;
- Compute scores:计算 fake score(student output)和 real score(teacher output);
- Update :通过 DMD loss 更新 student 参数;
- Update :通过 flow matching loss 更新 teacher 参数(teacher 也在适应 student 的 context)。
报告给出了 Algorithm 1 的完整伪代码,但公开仓库没有找到名为 context forcing 的独立训练 pipeline。能确认的公开事实只有两点:
- few-step distilled checkpoint 已公开;
- 推理侧
--few_step true --num_inference_steps 4已在run.sh和README.md中公开。
因此,这一部分只保留 paper-level 公式与算法流程,不伪造”代码级 context forcing 伪代码”。
3.8 Inference:KV cache、few-step 与工程优化

Figure 9 解读:Algorithm 2 定义了完整的 inference with KV cache 流程。核心思想是把 text/vision 条件的 KV 计算做一次 cache,然后每个 chunk 只需要 (1) 更新 memory context 的 KV cache 和 (2) 对当前 chunk 做 denoising。这样避免了每个 chunk 重复计算全部历史的 attention,大幅降低了 streaming inference 的延迟。
报告中的 Algorithm 2 在公开推理代码里有很强的一一对应关系:
HunyuanVideo_1_5_Pipeline.init_kv_cache()HunyuanVideo_1_5_Pipeline.ar_rollout()HunyuanVideo_1_5_DiffusionTransformer.forward_txt()HunyuanVideo_1_5_DiffusionTransformer.forward_vision()
推理过程分成三步:
- 先对 text / vision / ByT5 条件做 K/V cache;
- 每生成一个新 chunk 前,先用 selected memory frames 更新 vision-side cache;
- 再对当前 chunk 做 denoising;few-step 模式下只保留 4 个 denoising steps。
# Pseudocode: autoregressive rollout with KV cache (from released code)
def ar_rollout(latents, prompt, prompt_mask, vision_states, cond_latents,
viewmats, intrinsics, action, num_steps):
kv_cache = init_empty_cache()
kv_cache = cache_text_and_vision_tokens(prompt, prompt_mask, vision_states, kv_cache)
for chunk_i in range(num_chunks):
if chunk_i > 0:
selected = []
for chunk_start in range(current_frame_idx, current_frame_idx + 4, 4):
selected += select_aligned_memory_frames(
viewmats, chunk_start,
memory_frames=20, temporal_context_size=12, pred_latent_size=4
)
selected = deduplicate_and_remove_current_chunk(selected)
kv_cache = cache_memory_context(
latents[:, :, selected],
cond_latents[:, :, selected],
viewmats[:, selected],
intrinsics[:, selected],
action[:, selected],
kv_cache
)
for t in scheduler.timesteps:
model_input = concat(latents[:, :, current_chunk], cond_latents[:, :, current_chunk])
noise_pred = transformer(
hidden_states=model_input,
timestep=t,
viewmats=viewmats[:, current_chunk],
Ks=intrinsics[:, current_chunk],
action=action[:, current_chunk],
kv_cache=kv_cache,
cache_vision=False,
rope_temporal_size=current_chunk_size + len(selected),
start_rope_start_idx=len(selected),
)
latents[:, :, current_chunk] = scheduler.step(noise_pred, t, latents[:, :, current_chunk])
return latents另外,报告中的工程优化也能在代码与 README 里找到对应:
- 8 GPU 并行推理:报告明说 DiT 和 VAE 的 mixed parallelism 跨 8 GPU;
- few-step inference:
run.sh中公开--few_step true --num_inference_steps 4; - SageAttention / fp8 GEMM / quantization:
README.md与hyvideo/generate.py都暴露了相关开关; - progressive decode / VAE parallel:
generate.py中提供--use_vae_parallel; - prompt rewriting:
worldplay_video_pipeline.py中集成可选 prompt rewrite。
# Pseudocode: memory-aware AR training step (from released code)
def training_step(latents, w2c, intrinsic, action, image_cond, masks):
noise = randn_like(latents)
timesteps = sample_chunkwise_timesteps(latents, shift=train_time_shift)
if select_window_out_flag == 1:
# memory training branch: force outside-window chunks to higher noise range
timesteps = replace_history_chunk_timesteps_with_high_noise(timesteps)
noisy_latents = (1 - sigma) * latents + sigma * noise
cond = prepare_i2v_condition(image_cond, noisy_latents)
model_input = concat(noisy_latents, cond)
pred = transformer(
hidden_states=model_input,
timestep=timesteps,
text_states=prompt_embed,
encoder_attention_mask=prompt_mask,
vision_states=vision_states,
viewmats=w2c,
Ks=intrinsic,
action=action.reshape(-1),
)
if select_window_out_flag == 1:
# only optimize the last chunk in memory-training mode
i2v_mask[:, :, :-4] = 0
loss = mse(pred * i2v_mask, target * i2v_mask)
loss.backward()3.9 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Bidirectional / inference transformer backbone | hyvideo/models/transformers/worldplay_1_5_transformer.py | HunyuanVideo_1_5_DiffusionTransformer |
| Autoregressive training transformer | trainer/models/hyvideo/models/transformers/ar_action_hunyuanvideo_1_5_transformer.py | ARHunyuanVideo_1_5_DiffusionTransformer |
| Discrete action injection | hyvideo/models/transformers/worldplay_1_5_transformer.py | add_action_parameters(), self.action_in(...) |
| Continuous pose via PRoPE | hyvideo/prope/camera_rope.py | prope_qkv() |
| Dual-stream attention with pose branch | hyvideo/models/transformers/worldplay_1_5_transformer.py | MMDoubleStreamBlock.forward_vision() |
| Reconstituted context memory retrieval | hyvideo/utils/retrieval_context.py | select_aligned_memory_frames(), calculate_fov_overlap_similarity() |
| AR rollout + KV cache | hyvideo/pipelines/worldplay_video_pipeline.py | init_kv_cache(), ar_rollout() |
| Memory-aware AR training | trainer/training/ar_hunyuan_mem_training_pipeline.py | _prepare_ar_dit_inputs(), _build_input_kwargs(), _transformer_forward_and_compute_loss() |
| Few-step distilled inference | run.sh, hyvideo/generate.py | --few_step true, --num_inference_steps 4 |
补充说明:
WorldCompass RL训练代码未在当前公开仓库中找到;Context Forcing的 few-step 推理 checkpoint 已公开,但未找到独立命名的 context forcing 训练 pipeline;- 因此 RL 与 distillation 在”代码映射”层面目前属于部分公开。
4. Experimental Setup
4.1 训练数据
HY-World 1.5 使用总计 320K 个 video clips。构成如下:
- AAA 游戏录屏:170K(53.125%)
- Real-world 3D(来自 DL3DV):60K(18.75%)
- Synthetic 4D(Unreal Engine 渲染):50K(15.625%)
- Real-world video(来自 Sekai):40K(12.5%)
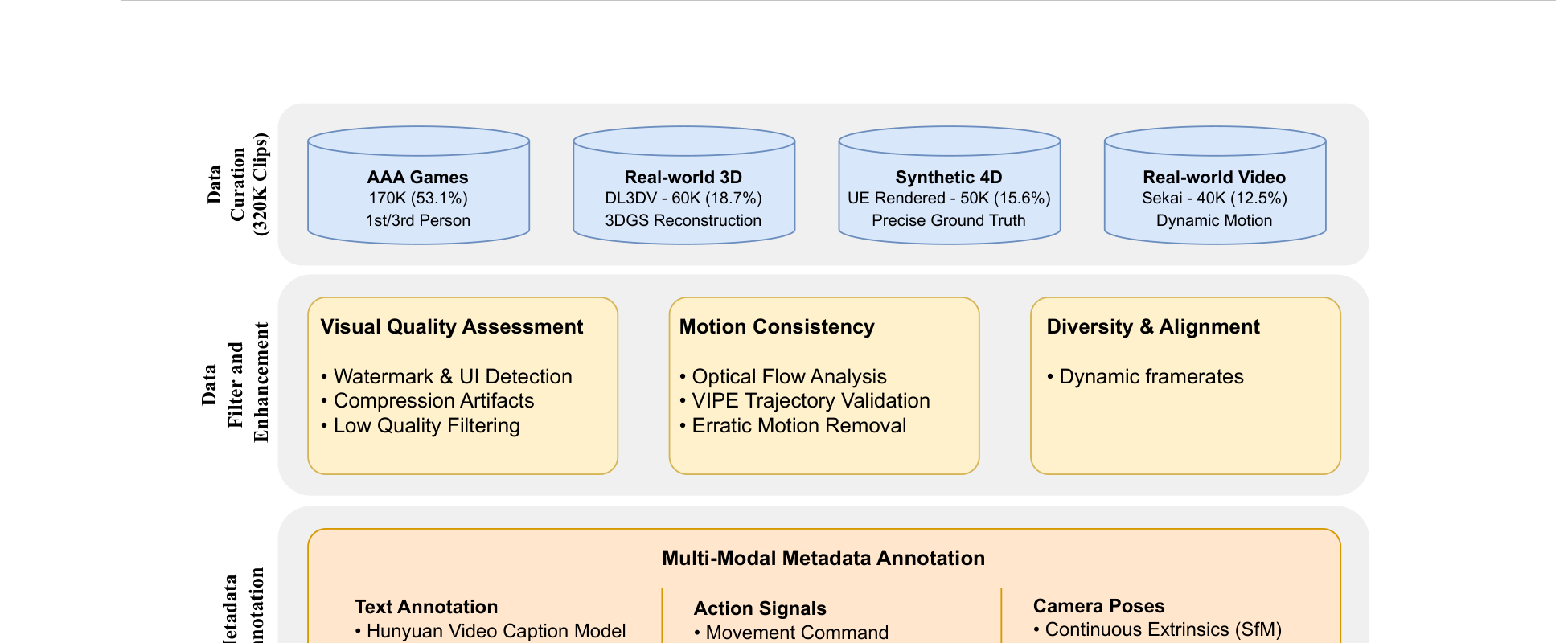
Figure 10 解读:Figure 3 说明数据系统不是简单拼盘,而是按 AAA Games、Real-world 3D、Synthetic 4D、Real-world Video 四类组织,并在后续显式加入 visual quality filtering、motion consistency filtering 和 multimodal metadata annotation。尤其关键的是 camera pose 与 action signal 都被结构化标注出来,这直接为 Dual Action Representation 和 memory retrieval 提供监督基础。
4.2 数据处理与标注
作者对原始数据做了三层处理:
-
Visual Quality Filtering:
- 自动化 video aesthetics scoring,基于学习的美学评分模型对每个 clip 进行画质评估;
- Watermark / UI 元素检测与剔除,避免叠加的游戏 HUD 或水印干扰训练;
- 压缩伪影检测,过滤编码质量过低的 clips(如低码率录屏);
- 低分辨率与模糊帧的自动剔除。
-
Motion Consistency Filtering:
- 通过 optical flow 分析运动强度(motion intensity),过滤严重 camera shake 与抖动片段;
- 验证 camera trajectory 的 smoothness 与 plausibility,过滤 abrupt(突然跳切)与 impossible movements(如穿墙、瞬移);
- 这一步对保证 continuous camera pose 标注的质量至关重要——如果原始轨迹本身不合理,PRoPE 的监督信号就会是 noisy 的。
-
Diversity Enhancement 与多模态标注:
- 利用 dynamic frame rates 实现对不同 playback speeds、camera motions、frame rate configurations 的全面覆盖;
- 文本标注来自 HunyuanVideo 1.5 caption model;
- Camera pose 标注来自 VIPE 或渲染管线(synthetic 数据直接导出 GT pose);
- Discrete action 标注来自轨迹离散化或直接录制(游戏数据可直接捕获键鼠信号)。
4.3 评测协议
评测使用 600 个 diverse test cases,来源包括:
- real-world videos;
- game recordings;
- AI-generated images。
评测分两部分:
- Short-term:61 frames;
- Long-term:至少 250 frames。
长程评测专门构造了 cycle trajectory,让模型走一条路再走回来,比较 return path 与 initial pass 的一致性。
4.4 Baselines 与指标
比较对象包括两类:
- 无 memory 的 action-controlled diffusion models:CameraCtrl、SEVA、ViewCrafter、Matrix-Game-2.0、GameCraft;
- 带 memory 的方法:Gen3C、VMem。
定量指标包括:
- 画质:PSNR、SSIM、LPIPS;
- 位姿控制:、;
- 额外还做了 VBench 与 human evaluation。
4.5 训练 / 推理配置
这里必须区分”论文明确写出的”与”开源代码补充给出的”信息:
- 论文明确写出:
- distilled real-time model 使用 4 denoising steps;
- inference 侧采用 DiT + VAE 的 mixed parallelism,跨 8 GPUs;
- 目标实时速度为 24 FPS。
- 技术报告未详细说明 的内容:
- 完整训练硬件;
- optimizer / scheduler 的全部超参数;
- RL 与 distillation 的详细 batch / reward / rollout 配置。
- 开源训练脚本补充给出的默认值(不是报告正文直接给出的):
max_train_steps=200000window_frames=24num_frames=77learning_rate=1e-5mixed_precision=bf16weight_decay=1e-4- gradient checkpointing 为
full - README 用
8×H100节点示例说明 batch size 计算方式。
因此,对训练配置最稳妥的表述是:报告重点公开了系统设计与评测协议,而完整训练 recipe 主要通过开源脚本补充,但 RL / context forcing 仍未完全开源。
5. Experimental Results
5.1 主结果:短期与长期一致性都领先
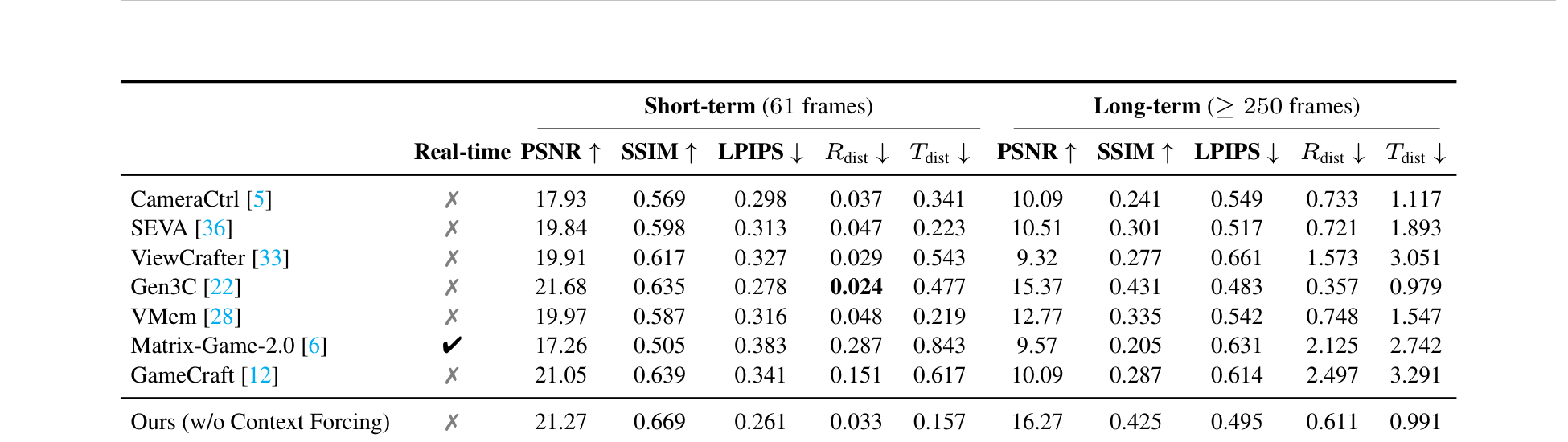
Figure 11 解读:Table 2 给出了所有方法在 short-term(61 frames)和 long-term(250+ frames)两个评测协议下的全部定量指标。可以清楚看到 HY-World 1.5 在几乎所有指标上都取得了最优或接近最优的成绩,尤其是在 long-term 场景下的优势更为显著。
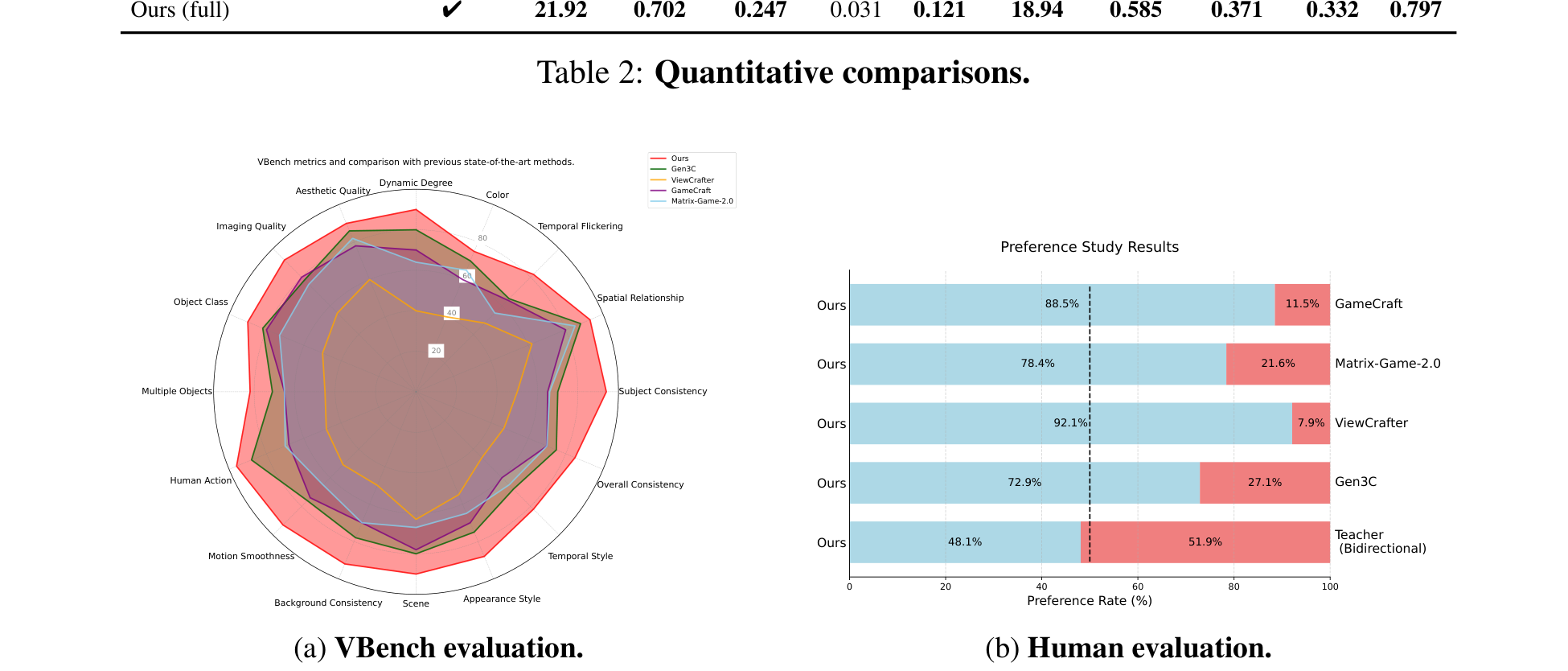
Figure 12 解读:Figure 9 左侧汇总了 VBench 指标,右侧给出人类偏好实验。虽然 VBench 雷达图没有在正文表格里逐项列出精确数值,但图形趋势显示 Ours 在 consistency、motion smoothness、appearance 等多个维度上整体领先;人类偏好结果则更直接地反映了用户体验层面的提升。
报告 Table 2 的核心数字如下。
Ours (full):
- Short-term (61 frames):
- PSNR = 21.92
- SSIM = 0.702
- LPIPS = 0.247
- = 0.031
- = 0.121
- Long-term ( frames):
- PSNR = 18.94
- SSIM = 0.585
- LPIPS = 0.371
- = 0.332
- = 0.797
去掉 Context Forcing 后(Ours w/o Context Forcing):
- Short-term:
- PSNR = 21.27
- SSIM = 0.669
- LPIPS = 0.261
- = 0.033
- = 0.157
- Long-term:
- PSNR = 16.27
- SSIM = 0.425
- LPIPS = 0.495
- = 0.611
- = 0.991
这说明 Context Forcing 的价值主要体现在长程一致性与 few-step real-time inference 上,而不是只提升短视频画质。
5.2 与代表性 baseline 的比较

Figure 13 解读:Figure 10 给出了 HY-World 1.5 与 Gen3C、GameCraft、Matrix-Game-2.0 的定性对比。可以直观看到:Gen3C 在长程 rollout 后出现明显几何漂移;GameCraft 的画质不错但长期一致性很弱;Matrix-Game-2.0 虽然支持 real-time 但视觉质量和空间一致性都有明显退化。相比之下,HY-World 1.5 在画质、动作跟随、长期一致性三方面都表现更好。
几个值得特别关注的定量对照:
- Gen3C:
- Short-term: PSNR 21.68 / SSIM 0.635 / LPIPS 0.278 / 0.024 / 0.477
- Long-term: PSNR 15.37 / SSIM 0.431 / LPIPS 0.483 / 0.357 / 0.979
- Matrix-Game-2.0(支持 real-time,但长程一致性很弱):
- Short-term: PSNR 17.26 / SSIM 0.505 / LPIPS 0.383 / 0.287 / 0.843
- Long-term: PSNR 9.57 / SSIM 0.205 / LPIPS 0.631 / 2.125 / 2.742
- GameCraft:
- Short-term: PSNR 21.05 / SSIM 0.639 / LPIPS 0.341 / 0.151 / 0.617
- Long-term: PSNR 10.09 / SSIM 0.287 / LPIPS 0.614 / 2.497 / 3.291
结论非常清楚:HY-World 1.5 是少数同时把 real-time 与 long-term consistency 拉起来的方法。
5.3 Human evaluation 的一个重要细节
Figure 9(b) 给出的人工偏好结果为:
- 对比 GameCraft:88.5% 选择 Ours
- 对比 Matrix-Game-2.0:78.4% 选择 Ours
- 对比 ViewCrafter:92.1% 选择 Ours
- 对比 Gen3C:72.9% 选择 Ours
- 对比 bidirectional teacher:48.1% 选择 Ours,51.9% 选择 Teacher
最后这一项很关键:说明 few-step distilled、可实时交互的 student 虽然综合上已经很强,但在纯视觉偏好上尚未完全超越 teacher。这也从侧面证明了 Context Forcing / distillation 并没有”白送性能”,而是在 latency 与 quality 间做了系统级权衡。
5.4 RL 的效果

Figure 14 解读:Figure 11 展示了是否进行 WorldCompass RL post-training 的可视化差异。
- Without RL:模型在复杂组合动作下表现出明显的 interaction signal misalignment,同时出现 visual degradation(画面模糊、几何变形、纹理退化)。尤其是当用户同时执行多个动作(如前进 + 转弯 + 抬头)时,模型容易”忽略”部分动作指令,或以牺牲画质为代价勉强跟随。
- With RL:action following accuracy 显著提升,模型能够更准确地响应复杂组合动作;同时 visual fidelity 也更高,画面更清晰、纹理更稳定。RL 的价值不只是”锦上添花”,而是补上了 pixel-level pre-training 无法直接优化的 interaction alignment。
报告指出,关于 Action Representation Design、Memory Design、Context Forcing Design 和 RL Design 的详细 ablation studies 将分别在 WorldPlay [24] 和 WorldCompass [27] 两篇独立论文中展开。
5.5 应用:3D reconstruction、promptable event、video continuation
5.5.1 3D Reconstruction

Figure 15 解读:Figure 12 表明 WorldPlay 生成的多视角序列具有足够稳定的几何一致性,可以作为 3D reconstruction 系统(如 WorldMirror)的输入。
核心原因在于 reconstituted context memory 机制确保了exceptional long-term geometric consistency。当用户从不同角度回访同一区域时,模型能够通过 spatial memory 中保留的历史 frame 维持空间结构的一致性。这种一致的 multi-view observations 为 reconstruction pipeline 提供了理想输入——相比于缺乏 memory 的方法生成的视频,geometric coherence 显著减少了重建过程中的 artifacts(如 floating geometry、inconsistent surfaces)。
5.5.2 Dynamic Event Manipulation(Promptable Events)

Figure 16 解读:Figure 8 展示了 promptable event 的两个典型案例——在场景中动态添加气球和彩虹。这说明 HY-World 1.5 不只是一个被动的 camera navigation engine,还支持主动地修改世界状态。
HY-World 1.5 支持基于文本的交互来实时触发动态世界事件。支持的事件类别包括:
- Object addition / removal:在场景中添加或移除特定物体;
- Environmental changes:天气变化(晴转阴、下雨、下雪)、光照变化(日落、夜晚);
- Dynamics:爆炸、火焰、粒子效果等物理动态;
- Character behaviors:NPC 动作、角色互动。
这一能力使得 HY-World 1.5 能够支持 interactive storytelling 和 virtual environment manipulation,把”走世界”扩展成”操控世界”。
5.5.3 Video Continuation

Figure 17 解读:Figure 13 上半部分展示 promptable events,下半部分展示 video continuation。
Video continuation 功能允许模型在给定一段初始视频 clip 后,生成与之高度一致的后续内容。一致性体现在三个层面:
- Motion consistency:续写的运动轨迹与原视频自然衔接,无跳变或突变;
- Appearance consistency:场景外观、纹理、色调保持统一;
- Lighting consistency:光照方向与强度延续原始设定。
这一能力本质上依赖于 reconstituted context memory 和 temporal reframing 的联合作用:初始 clip 的 latent 被作为 memory 注入后续生成过程,确保 spatial-temporal consistency 被显式保持。
5.6 局限性
报告中明确和隐含的局限有几类:
- RL 与细粒度 ablation 细节被拆到独立论文:本技术报告更像系统总览,很多训练细节并未完全展开。
- Teacher 仍略强于 distilled student:human preference 里 teacher 仍有 51.9% 优势。
- 公开代码尚未完全覆盖所有阶段:
- RL checkpoint / training code 未公开;
- context forcing training pipeline 未明确公开;
- 因此当前社区能完整复现的主要是 autoregressive action+memory 训练与推理。
- 作者自己给出的未来方向:更长视频、多智能体交互、更复杂物理动力学。
5.7 总结结论
HY-World 1.5 的最大贡献,不是提出某一个单独模块,而是把 world model 做成一个真正完整的系统:
- 数据上,构建了 320K clip 的多来源训练集;
- 模型上,用 dual action + reconstituted context memory 把控制与一致性统一起来;
- 训练上,用 RL 与 context forcing 解决 interaction alignment 与 real-time distillation;
- 部署上,通过 KV cache、few-step inference、并行化和量化,把系统推到 24 FPS。
如果把它放在 2025-2026 年 world model 的技术脉络里看,HY-World 1.5 最值得记住的不是”又一个 world model”,而是它把 memory-aware AR diffusion + geometry-aware retrieval + real-time deployment 这三件事第一次比较系统地拼到了一起。