Authors: Tianchang Shen, Sherwin Bahmani, Kai He, Sangeetha Grama Srinivasan, Tianshi Cao, Jiawei Ren, Ruilong Li, Zian Wang, Nicholas Sharp, Zan Gojcic, Sanja Fidler, Jiahui Huang, Huan Ling, Jun Gao, Xuanchi Ren
Affiliations: NVIDIA
Links: arXiv:2604.13036 · Project · Code: nv-tlabs/lyra(Lyra-2/)
1. Motivation(研究动机)
- 现有方法缺什么能力? 生成式重建(generative reconstruction)用 camera-controlled video diffusion 合成 walkthrough,再用 feed-forward 模型抬升到 3D,但在长轨迹、大视角变化、多次回访同一区域时,视频模型很快崩坏:早期帧滑出有限 temporal context 后,模型只能对旧区域“凭空重画”,破坏全局布局;同时自回归合成的小误差会沿时间累积,造成颜色漂移与几何扭曲。依赖全局累积 3D 再渲染 conditioning 的方法还会把生成瑕疵写入几何,反过来污染后续帧(error amplification)。
- 本文要解决的具体问题: 在任意长的探索式相机轨迹上,生成全局 3D 一致、可控的长视频,并进一步可靠重建为高质量 3DGS / mesh,以支撑交互探索与仿真。
- 为什么值得做: 一旦长程一致性与重建鲁棒性同时成立,就能从单张图规模化生成可探索的静态大场景,并导出到 Isaac Sim 等引擎,降低 embodied AI 与沉浸式内容的数据与制作成本。
2. Idea(核心思想)
- 核心洞察(What’s new): 把 per-frame 3D geometry 从“外观/几何的硬 conditioning”降级为纯 information routing——只负责检索最相关的历史观测、并在目标视点建立 dense 3D correspondence;像素与外观仍由 diffusion 的生成先验完成,从而避免 warped RGB 与错误累积点云对生成的绑架。与此同时,用 self-augmented histories 在训练期模拟推理时的 imperfect conditioning,强迫模型学会纠正漂移而非放大误差。长程一致视频再用于 fine-tune Depth Anything v3(DAv3) 等 feed-forward 重建,弥合生成域与重建域的 gap。
- 与强相关路线的本质区别: 相对 GEN3C 等深度 warp 渲染作为强几何约束的做法,本文强调 warp canonical coordinates 而非 RGB,把几何对齐与外观生成分离;相对 SPMem 等融合成单一全局点云再渲染 conditioning,本文永不融合 per-frame cache,避免跨视角深度误差在单一表示里累积。
3. Method(方法)
3.1 两阶段总览(视频生成 → 3D 抬升)
阶段 A:长程 3D 一致视频。 以单帧 与相机轨迹 为输入,循环执行:(i) geometry-aware 检索 (ii) 在 FramePack 压缩的 temporal context + spatial slots + Plücker rays 下生成下一段 (iii) 用估计深度更新 per-frame 3D cache。核心模块为 anti-forgetting(§4.2)与 anti-drifting(FramePack §3 + self-augmentation §4.3)。
阶段 B:feed-forward 重建。 对生成序列用 DAv3 预测 3DGS;将 Gaussian head 下采样因子设为 以控制 Gaussian 数量;并在 Lyra 2.0 自生成数据上 fine-tune,类似 Lyra 1.0 [2] 提升对生成伪影的容忍度。随后可用分层稀疏网格 + OpenVDB 提取 mesh。
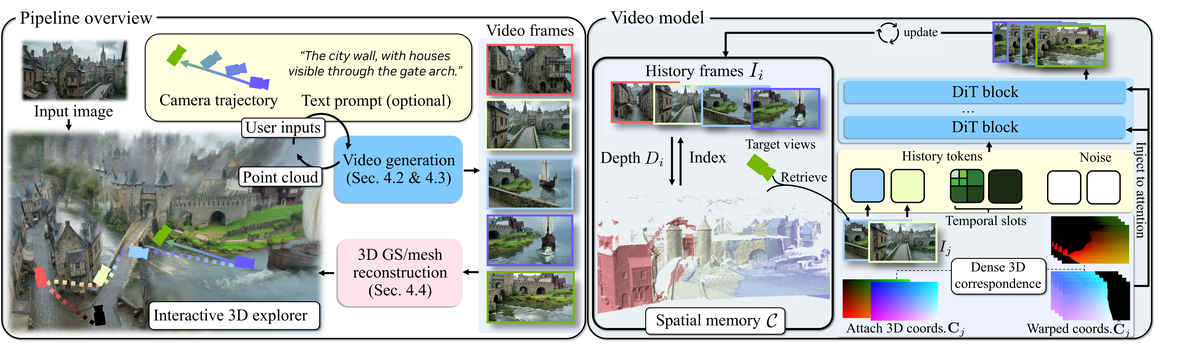
Figure 2 解读: 左支展示交互式 explorer 驱动的 retrieve–generate–update 闭环:每段视频经深度估计写入点云记忆,供后续导航;右支强调在每一步从 spatial memory 取出对目标视点可见性最高的历史帧,将 canonical coordinates 前向 warp 得到 dense correspondence,与 FramePack 压缩的时间历史一并注入 DiT 的 attention。
3.2 Anti-forgetting:per-frame 3D cache 与检索
对每帧维护深度 、内外参,以及下采样因子 得到的点云 (不融合成全局点云)。对目标相机 ,将所有历史点云投影到目标平面,用 per-pixel 最小深度处理遮挡;若某点深度与最小深度差小于阈值 ,视为可见。可见性得分 为帧 的可见点数。训练时按 比例采样历史;推理时 greedy 覆盖:迭代选取能覆盖最多尚未覆盖目标像素的帧,直至 帧(论文与附录取 ,,)。
3.3 注入 DiT:spatial slots + canonical warp(非 RGB)
检索帧 经 VAE 成 spatial slots(与 FramePack temporal slots、生成 token 同级,共享可变核空间压缩)。dense 对齐通过 canonical map (通道为归一化 与 )与全分辨率深度前向 warp:
并拼接 warp 后的 depth 形成 4 通道 ;经位置编码 + MLP 聚合后 加到每个 transformer block 的 token 上。刻意不用 warped RGB,以免孔洞与拉伸被模型复刻。
上下文排布(与 FramePack 一致): anchor( 全分辨率)+ spatial slots(例如 4 帧 2× 下采样 + 1 帧全分辨率)+ temporal slots + 待生成的 (20 帧目标),全文见论文式 (2) 与 §4.2 图示。
3.4 Anti-drifting:FramePack + self-augmentation
Flow matching 目标(标准 rectified flow 形式):
Observation bias: 训练用 GT 历史,推理用模型自身输出,导致误差不被纠正而累积。FramePack 用近细远粗的时空 token 压缩,在固定 token 预算下延长有效历史,并把 anchor 作为早期锚点缓解漂移,但不能完全消除 train–test gap。
Self-augmentation(论文式 (4)(5)): 以概率 (附录 )对历史 latent 加噪:
一步向量场预测并重构历史条件:
用 替换 DiT 条件,但 目标 chunk 仍在干净历史 cache 下编码,flow matching 仍监督去噪到干净目标,从而学会在 imperfect history 下恢复质量。
Intuition paragraph: 可以把 pipeline 理解成“几何负责指路,像素负责画画,训练负责预习翻车”。3D cache 从不追求合成一帧好看的渲染图,它只回答两个问题:哪些旧帧在几何上与下一步最相关、每个像素对应到历史上的哪个 3D 位置——这样即使时间索引上早就被 FramePack 压成粗 token,回访仍能通过 3D 重叠把“真正见过的地方”拉回上下文。反过来,若把错误深度熔进全局点云或把 warped RGB 直接喂给模型,模型会学会抄捷径复制瑕疵。Self-augmentation 则对准 autoregressive 的观测分布偏移:让网络在训练中就习惯“脏历史”,主损失却仍指向 GT latent,等价于把一步纠错写进向量场,而不是假设历史永远完美。
3.5 推理加速:DMD
在教师模型上通过 Distribution Matching Distillation (DMD) 得到 4 步学生模型,并蒸馏 CFG;蒸馏阶段保留 self-augmentation,使学生对误差累积仍鲁棒。论文报告每步生成时间约 13× 加速(35 步+CFG 4 步、单前向)。
3.6 伪代码(分组件)
A. Geometry-aware spatial memory 更新与检索(概念 + 推理贪心覆盖)
def visibility_score(point_cloud_i, depths_all_frames, T_star, K_star, delta):
"""Count points of frame i visible from target (T_star, K_star) with occlusion threshold delta."""
# Project P_i to target plane; compare per-pixel depth to min depth across all frames
...
def retrieve_spatial_frames(cache, target_pose, N_s, training: bool):
scores = [visibility_score(cache.P[i], cache.depths, *target_pose, delta=0.1) for i in range(len(cache))]
if training:
return sample_without_replacement(range(len(cache)), weights=scores, k=N_s)
# Inference: greedy coverage on target image pixels
selected, covered = [], set()
while len(selected) < N_s:
best = argmax_i(coverage_gain(i, covered, scores))
selected.append(best)
update_covered(best, covered)
return selectedB. Canonical correspondence 构造与注入(式 (3) 管线)
def build_correspondence_tokens(I_j, D_j, T_j, K_j, T_star, K_star, mlp_pos, pe):
C_j = canonical_coordinate_map(H, W, N_j_s) # [-1,1]^3 channels (u,v,depth_norm)
C_hat, D_hat = forward_warp(C_j, D_j, T_j, K_j, T_star, K_star)
corr = torch.cat([C_hat, D_hat], dim=0) # 4 x H x W
return mlp_pos(pe(corr)) # added to DiT tokens each blockC. Self-augmentation 训练步(论文式 (4)(5);与仓库 multi-step Stage-A 并存)
def maybe_corrupt_history_latents(z_hist_clean, v_theta, p_aug: float = 0.7):
if random.random() > p_aug:
return z_hist_clean
t = torch.empty(1).uniform_(0.0, 0.5)
eps = torch.randn_like(z_hist_clean)
z_hist_t = (1 - t) * z_hist_clean + t * eps
z_hist_tilde = z_hist_t - t * v_theta(z_hist_t, t, cond)
return z_hist_tilde
def training_step(v_theta, E, batch, optimizer):
x_hist, x_cur = batch.history_frames, batch.target_chunk
z_hist_clean = E(x_hist)
z_cur_target = E(x_cur | cache_from=x_hist) # causal VAE: clean cache for target
z_hist_cond = maybe_corrupt_history_latents(z_hist_clean, v_theta)
loss = flow_matching_loss(v_theta, z_cur_target, cond=z_hist_cond, ...)
loss.backward()
optimizer.step()
return loss开源仓库
Lyra2Model.training_step在self_aug_enabled时实现了更完整的 Stage-A 短采样(可配置self_aug_steps、CFG、self_aug_max_T等),在 latent 域构造近似自回归误差后再回写像素并重新编码;与式 (4)(5) 的“对历史加噪 + 短去噪”同一目标,但工程上更贴近 Wan 2.1 因果 VAE 与分布式训练需求。
D. DAv3 微调(紧凑 Gaussian + 生成域适应)
def finetune_dav3(student, generated_video_dataset, k_downsample: int = 2, steps: int = 10000):
student.head = gaussian_dpt_head_with_stride(k_downsample) # k^2 fewer Gaussians
opt = torch.optim.AdamW(student.parameters(), lr=5e-5)
for batch in generated_video_dataset:
loss = student(batch.frames, batch.intrinsics, batch.extrinsics)
loss.backward()
opt.step()Code reference:
main@52e50798(2026-04-18) — 伪代码与下表映射基于该 commit。
| Paper Concept | Source Path(Lyra-2/) | Key Class / Function |
|---|---|---|
| Lyra 2.0 DiT + FramePack + self-aug 训练 | lyra_2/_src/models/lyra2_model.py | Lyra2Model, Lyra2T2VConfig, training_step |
| 空间检索自回归推理 | lyra_2/_src/inference/lyra2_ar_inference.py | spatial overlap retrieval, spatial_cache |
| 深度 / warp 数据与工具 | lyra_2/_src/datasets/depth_warp_dataloader.py, forward_warp_utils_pytorch.py | forward_warp_multiframes, unproject_points |
| 相机 / Plücker 条件 | lyra_2/_src/datasets/plucker_embed_corrupter.py, wan_t2v_model.py | ray / conditioner 注入 |
定性图示(与论文 Fig.1/3–9 对应)

Figure 1 解读: 单图出发的长轨迹探索:look back、大尺度外延、多域泛化,以及编辑后开门等交互;并展示视频与 3DGS 渲染、仿真资产导出。

Figure 3 解读: Tanks and Temples 上约第 800 帧附近的长程对比;基线出现结构崩塌、几何扭曲或严重漂移,本文仍保持合理几何与外观。

Figure 4 解读: 由各方法视频重建的 3DGS 渲染对比;基线 floaters 与噪声更明显,本文重建更干净。

Figure 5 解读: 与 Lyra(短序列 3D 重建)与 FantasyWorld 的尺度对比;红框标示同一空间区域,本文交互式扩展覆盖更大范围与复杂度。

Figure 6 解读: 在 Tanks and Temples 上对 full model 与各消融变体的定性对比,对应 Tab.3 中全局点云、显式 correspondence 融合、去掉 FramePack、去掉 self-augmentation 等设置。
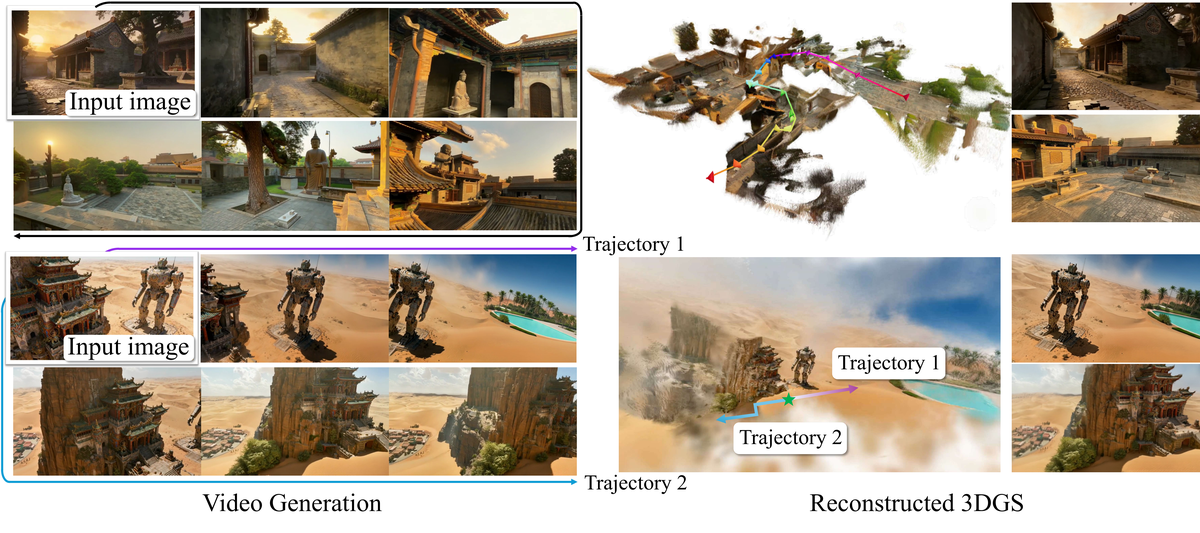
Figure 7 解读: 交互 GUI 中累积点云、轨迹规划与实时探索流程,可回访已探索区域或向外延拓。

Figure 8 解读: 导出到 NVIDIA Isaac Sim 等下游的仿真就绪资产示例,体现 embodied AI 应用路径。

Figure 9 解读: 训练视频上统计不同检索帧数 对目标帧像素覆盖率; 在覆盖率与计算间折中。
与 Lyra 1.0 的关系
| 维度 | Lyra 1.0 [2] | Lyra 2.0(本文) |
|---|---|---|
| 核心目标 | 单图/短视频 feed-forward 3DGS(自蒸馏视频 prior) | 长程可探索世界:长视频生成 + 再重建 |
| 视频 | 相对短程、强调重建质量 | Anti-forgetting + anti-drifting 的长轨迹生成 |
| 几何 | 重建模块为主 | Per-frame geometry 仅用于 routing + correspondence |
| 重建 | DAv3 类 feed-forward 微调 | 同思路:在自生成长视频上 fine-tune DAv3,并加 下采样 head |
4. Experimental Setup(实验设置)
- 数据: DL3DV — 约 10K 长视频片段;每视频采样 1000 帧训练。相机位姿 ViPE;深度 DAv3;caption Qwen3-VL-8B-Instruct。
- 训练配方: 30% 概率 I2V(首段 帧),70% 概率自回归 chunk 训练(历史 ,目标为下一段 帧)。优化器 AdamW,,weight decay 0.1,batch 64,64× NVIDIA GB200,7000 iterations,bf16;新模块零初始化以继承 Wan 2.1 行为。Flow:训练 logit-normal 时间采样;推理 FlowUniPC 35 步。CFG scale 5.0。Self-aug ;spatial memory ,,。
- 基线(长视频): Yume-1.5,GEN3C,CaM,VMem,SPMem,HY-WorldPlay(CaM/SPMem 基于 Wan2.1-14B 复现)。
- 评测数据: DL3DV-Evaluation(域内),Tanks and Temples(域外)。
- 指标: SSIM / LPIPS / FID;WorldScore 系列 Subjective Quality、Style Consistency、Camera Controllability;Reprojection Error(SLAM 深度一致性)。3D 段额外 LPIPS-P / LPIPS-G(论文 Table 2)。
- 重建微调: 自回归生成 3000 条一分钟视频构造数据;DAv3 10000 iter,lr ,batch 8,。
- 推理耗时(附录): 全模型每 80 帧一步约 194 s(GB200,含深度、检索、35 步+CFG);Ours DMD 约 15 s;检索 <1 s。
5. Experimental Results(实验结果)
Table 1(长视频生成,论文 Table 1 全表) — 每行前半为 DL3DV,后半为 Tanks-and-Temples;列为 SSIM↑ / LPIPS↓ / FID↓ / Subjective Qual.↑ / Style Consist.↑ / Camera Ctrl.↑ / Reproj. Err.↓。
| Method | D SSIM | D LPIPS | D FID | D Subj | D Style | D Cam | D Reproj | T SSIM | T LPIPS | T FID | T Subj | T Style | T Cam | T Reproj |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GEN3C | 0.346 | 0.535 | 58.96 | 24.60 | 76.77 | 69.54 | 0.068 | 0.350 | 0.589 | 79.07 | 21.75 | 75.54 | 70.91 | 0.054 |
| Yume1.5 | 0.342 | 0.719 | 84.84 | 22.80 | 66.73 | – | 0.095 | 0.348 | 0.702 | 89.69 | 28.68 | 78.63 | – | 0.083 |
| CaM | 0.370 | 0.562 | 50.43 | 35.19 | 82.63 | 42.71 | 0.069 | 0.367 | 0.605 | 59.20 | 34.22 | 82.83 | 31.86 | 0.056 |
| VMem | 0.331 | 0.744 | 120.59 | 18.54 | 76.14 | 0.68 | 0.268 | 0.338 | 0.767 | 136.48 | 16.21 | 70.54 | 0.00 | 0.263 |
| SPMem | 0.383 | 0.522 | 53.77 | 38.32 | 82.79 | 62.05 | 0.074 | 0.383 | 0.571 | 60.11 | 34.41 | 79.68 | 45.07 | 0.059 |
| HY-WorldPlay | 0.373 | 0.765 | 139.36 | 4.79 | 54.62 | – | 0.092 | 0.380 | 0.796 | 163.54 | 3.24 | 48.22 | – | 0.084 |
| Ours | 0.388 | 0.498 | 43.43 | 44.54 | 87.46 | 64.67 | 0.076 | 0.384 | 0.552 | 51.33 | 43.35 | 85.07 | 63.87 | 0.069 |
| Ours DMD | 0.359 | 0.507 | 43.63 | 45.21 | 88.57 | 65.64 | 0.088 | 0.362 | 0.545 | 49.71 | 43.02 | 78.91 | 58.12 | 0.077 |
Table 2(3D 场景生成,论文 Table 2 全表)
| Method | DL3DV LPIPS-P↓ | DL3DV LPIPS-G↓ | DL3DV FID↓ | DL3DV Subj↑ | T&T LPIPS-P↓ | T&T LPIPS-G↓ | T&T FID↓ | T&T Subj↑ |
|---|---|---|---|---|---|---|---|---|
| GEN3C + DAv3 | 0.504 | 0.649 | 99.83 | 11.00 | 0.511 | 0.694 | 125.19 | 5.38 |
| Yume1.5 + DAv3 | 0.598 | 0.806 | 121.61 | 0.22 | 0.575 | 0.794 | 113.25 | 0.79 |
| CaM + DAv3 | 0.433 | 0.668 | 94.04 | 12.16 | 0.423 | 0.693 | 94.02 | 9.79 |
| VMem + DAv3 | 0.593 | 0.836 | 206.88 | 2.00 | 0.597 | 0.832 | 211.72 | 3.76 |
| SPMem + DAv3 | 0.419 | 0.625 | 93.56 | 13.72 | 0.412 | 0.666 | 94.11 | 9.95 |
| Ours + DAv3 | 0.413 | 0.603 | 74.39 | 17.02 | 0.409 | 0.648 | 79.36 | 14.42 |
| Ours Full | 0.381 | 0.579 | 65.94 | 20.52 | 0.372 | 0.629 | 72.47 | 18.80 |
Table 3(消融,Tanks and Temples)
| Method | SSIM↑ | LPIPS↓ | FID↓ | Subj↑ | Style↑ | Cam↑ | Reproj↓ |
|---|---|---|---|---|---|---|---|
| Ours | 0.384 | 0.552 | 51.33 | 43.35 | 85.07 | 63.87 | 0.069 |
| w/ Global Point Cloud | 0.368 | 0.562 | 52.54 | 44.58 | 82.42 | 49.86 | 0.067 |
| w/ Explicit Corr. Fusion | 0.370 | 0.554 | 49.13 | 45.71 | 83.28 | 57.29 | 0.071 |
| w/o FramePack | 0.362 | 0.549 | 50.98 | 45.27 | 80.61 | 62.62 | 0.079 |
| w/o Self-Augmentation | 0.363 | 0.568 | 55.15 | 47.88 | 77.98 | 53.92 | 0.066 |
解读: 全局点云 conditioning 显著损害相机可控性与风格一致;去掉 FramePack 漂移加剧;去掉 self-augmentation 虽略抬升单帧主观分,但 Style / Cam 大幅下降,长程一致性变差(与论文 §5.4 一致)。
局限性(§6,作者自述): 当前聚焦静态场景,未显式建模动态物体;生成继承 DL3DV 的曝光变化,可能带来 photometric inconsistency 并影响 3DGS;未来可结合光度稳定网络或游戏引擎合成数据。
项目页代码链接: nv-tlabs/lyra(README 指向 Lyra-2/ 官方实现;已开源。)