Links: arXiv:2509.19296 · Project · Code · Model · Dataset
相关笔记:Lyra 2.0 - Explorable Generative 3D Worlds。
1. Motivation (研究动机)
- 现有路线的瓶颈: 传统 3D reconstruction / feed-forward reconstruction 依赖真实多视角图像、精确相机位姿和高质量同步采集;动态场景还需要多机位同步。RealEstate10K / DL3DV 这类数据多样性有限,导致 scene-level 3D 模型 out-of-domain generalization 差。另一方面,Video Diffusion Model 已经有很强的“想象”和相机运动建模能力,但输出仍是 2D video,不提供可实时渲染、可物理交互的显式 3D 表示。
- 本文要解决的具体问题: 不采集真实 multi-view training data,也不做每个场景的优化式重建,而是把 camera-controlled video diffusion model 隐含的 3D knowledge 蒸馏成一个 feed-forward 3D Gaussian Splatting (3DGS) decoder:输入单张图或单段视频,先由 GEN3C 生成多轨迹 video latents,再直接解码出静态 3DGS 或动态 4D Gaussian scene。
- 为什么值得做: 一旦可行,video diffusion model 就不只是生成“看起来合理”的视频,而能变成可部署到 simulation / robotics / autonomous driving / industrial AI 的 3D data engine。Lyra 的输出是 explicit 3DGS,可 novel-view real-time rendering、导出
.ply/.usdz到 Isaac Sim,并能用合成数据训练而非依赖真实多视角采集。
2. Idea (核心思想)
核心洞察是:不要先让 diffusion model 生成多视角 RGB、再用一个外部优化器重建 3D;而是把视频模型的 latent 直接接一个 3DGS decoder,并用视频模型自己的 RGB decoder 作为 teacher 做 self-distillation。 这样 student 只需要学习“从生成模型内部 latent 到显式 3D 表示”的转换,监督信号来自同一个 pre-trained video model 的 RGB branch,不需要真实 3DGS ground truth。
关键创新是一个双分支解码框架:冻结 GEN3C / Cosmos VAE / RGB decoder,训练新的 3DGS decoder;同一个 denoised video latent 一边被 RGB decoder 解成 teacher video,另一边被 3DGS decoder 解成 Gaussians,再通过 differentiable rendering 对齐 teacher RGB / depth。为扩展视角覆盖,训练时每张图采样 条相机轨迹、每条 帧;动态版本再加入 source/target time embeddings 和 motion-reversed supervision。
与 CAT3D 的差异:CAT3D 生成多视角图后仍需要优化式 3D reconstruction;与 Bolt3D 的差异:Bolt3D 基于 multi-view image diffusion 和 pointmap / geometry head;与 Wonderland / BTimer 的差异:Lyra 直接在 video latent space 融合多轨迹长序列,并输出 feed-forward 3DGS / dynamic 3DGS,不在 pixel space 处理 726 张高分辨率输入帧。
3. Method (方法)
3.1 Overall framework:视频 teacher 到 3DGS student

Figure 1 解读:图 1 展示 Lyra 的两个目标任务。上半部分是 single image → static 3DGS:输入一张图,模型一次前向生成显式 3D Gaussian scene,并可从不同视角渲染 RGB / depth。下半部分是 single video → dynamic 3DGS:输入单目视频后,生成的 4D 表示同时支持时间维和视角维控制。

Figure 2 解读:图 2 对比了传统 multi-view reconstruction 训练与 Lyra self-distillation。左侧方法需要真实 multi-view datasets,并用真实图像监督 3D reconstruction blocks;右侧 Lyra 冻结 camera-controlled video diffusion model,把 RGB decoder 输出当作 teacher,训练 3DGS decoder 的 rendering 去匹配 teacher video,因此监督来自 video model 自身的生成结果。

Figure 4 解读:图 4 是方法主图。左侧训练流程:输入图像和多条 camera trajectories,经 GEN3C / Video Diffusion Transformer 产生 denoised video latents;同一 latent 被 RGB decoder 解成 teacher images,也被 3DGS decoder 解成 Gaussians;student rendering 与 teacher images 计算 loss。右侧放大 3DGS decoder:video latents、Plücker embeddings、动态版本的 source/target time embeddings 分别 patchify 后相加,经 multi-view reconstruction blocks 和 transposed 3D conv 输出 3D Gaussian attributes。
形式化地,GEN3C 的 RGB video 经过 VAE encoder 得到 latent:
其中论文使用 。对输入图像 和第 条相机轨迹 ,teacher video model 生成 latent:
Lyra 的 student decoder 融合多条轨迹 latent 和相机编码:
再通过 renderer 得到 student views:
方法直觉:Video diffusion model 已经从海量 2D 视频中学到了相机运动、遮挡补全和场景布局的隐含 3D 规律;但 RGB decoder 只能把 latent 投影回 2D。Lyra 的关键是把 RGB decoder 旁边接一个 3DGS decoder,让它在完全相同 latent 上学习一个“显式 3D 投影”。由于 teacher 和 student 共享 latent,student 不必从有限真实多视角数据里学习全部世界多样性,而是继承 video model 的生成覆盖;由于输出是 3DGS,它又比纯视频更适合仿真和实时交互。
3.2 Camera-controlled video teacher:GEN3C 的 3D cache 与 structured guidance
GEN3C 为 Lyra 提供 camera-controlled、3D-consistent 的 video latents。其 spatiotemporal 3D cache 记作 ,其中 是时间、 是输入视角;每个 由 RGB + depth 反投影得到 colored point cloud。给定目标相机 ,渲染函数输出 structured guidance:
其中 是 forward-rendered RGB guidance, 是 disocclusion mask,提示 diffusion model 哪些区域需要补全。Lyra 不训练这个 teacher,而是依赖它输出足够一致的多视角 synthetic supervision。

Figure 8 解读:图 8 来自附录,对比普通 forward warping 与更 conservative 的 rendering function。左侧 forward warping 会把背景错误填到本应 disoccluded 的区域;右侧把不可靠区域 mask 掉,让 diffusion model 正确补全。这个细节解释了 teacher video 的 camera-control 质量为何会直接影响 Lyra 的 3DGS student。
3.3 3DGS decoder:在 latent space 做 multi-view reconstruction
Figure 3 解读:图 3 展示训练时对每张输入图采样的 6 条 camera trajectories,用来扩大单个输入图的视角覆盖。论文主配置为 ,因此每张图会产生 个高分辨率 views;这正是作者选择 latent-space decoder 而非 pixel-space reconstruction 的核心动机。
3DGS decoder 的输入包括多轨迹 video latent 和 camera Plücker encoding 。原始 Plücker embedding 为 ;代码将 ray directions 与 ray moment 两个 3-channel 部分分别通过 Cosmos VAE encoder,再沿 channel concat,得到 latent-space camera tokens。
Decoder 架构:
- video latents 与 Plücker embeddings 分别用
PatchEmbed3Dpatchify 到 hidden dimension;动态版本再加 source/target time embeddings; - reconstruction blocks 采用 Long-LRM 风格的 hybrid sequence mixer:每 8 层中 1 层 Transformer + 7 层 Mamba-2,重复两次,共 16 层、hidden dim 512;
- transposed 3D conv 先输出 12 个 raw channels:distance、RGB、scale、rotation、opacity;随后
gaussian_processing()根据 camera rays 把 distance 转成 3D position,并拼出最终 14 维 Gaussian attributes:position 、opacity 、scale 、rotation quaternion 、RGB ; - inference 时可以按 opacity pruning,论文默认移除最低 80% opacity 的 Gaussians,使 rendering 从 30ms 降到 18ms,约 加速。
代码中 Gaussian attribute processing 的核心为:
其中 分别来自 camera ray origin / direction;opacity 使用 ,scale 使用 capped exponential,rotation 做 normalize,RGB 用 。
3.4 Loss:RGB teacher rendering + depth + opacity regularization
论文的总损失为:
权重设置为:
MSE / LPIPS 约束 3DGS rendering 和 RGB decoder teacher images;depth loss 用 ViPE 估计的一致 video depth,缓解只用 RGB loss 时出现的 flattened geometry;opacity loss 与 pruning 让表示更紧凑。开源训练配置默认 lambda_lpips=0.5、lambda_depth=0.05,并在一些 stage/config 中使用 pruning;代码 compute_loss() 中 opacity 项需要 lambda_opacity>0 才启用。
3.5 Dynamic 4D extension:time-conditioned dynamic 3DGS
动态版本把输入从单图换成 monocular video。Teacher 生成保留同一 motion state 的多视角视频 latent;student decoder 在 基础上加入 source time 和 target time embeddings:
原始 source time / target time 先归一化到 ,再拼接 2D sinusoidal embedding 变成 3-channel map,并通过 RGB VAE encoder 编成 latent time tokens。训练时随机抽取 target timestep,只监督对应时间的 dynamic Gaussians。

Figure 5 解读:图 5 说明 dynamic decoder 的一个失败模式:如果只用原始 outward trajectory 监督,早期时间步在极端视角处缺少覆盖,容易产生 low-opacity / missing Gaussian artifacts。Lyra 用 motion-reversed video 生成 inward trajectories,使每个时间步都有近/远两侧视角监督。

Figure 9 解读:图 9 展示 zoom-out 和 zoom-in 两类 trajectory 的 original / augmented supervision。Augmented videos 的相机运动被翻转,训练时与原始 6 条轨迹合并成 12 条 supervision views;推理时不需要这些 flipped trajectories。
3.6 与 3D generation 相关路线的结构差异

Figure 13 解读:图 13 总结三条路线。CAT3D 是 multi-view image diffusion + 后处理 optimization;Bolt3D 是 multi-view image/pointmap generation + feed-forward Gaussian head;Lyra 则直接接在 multi-view video diffusion model 的 latent 后面,用 3DGS decoder 输出 Gaussians,避免 pixel-space 726-frame reconstruction 的内存瓶颈。
3.7 Pseudocode:基于官方代码的 PyTorch 风格流程
(a) Teacher synthetic data generation / self-distillation targets
@torch.no_grad()
def generate_teacher_latents(pipeline, prompt, image_path, cache, trajectories, vae_rgb_decoder):
teacher_batches = []
for cams in trajectories: # V=6 static, V=12 for dynamic training with flipped supervision
rendered_warp_images, rendered_warp_masks = cache.render_cache(cams.w2cs, cams.intrinsics)
generated = pipeline.generate(
prompt=prompt,
image_path=image_path,
rendered_warp_images=rendered_warp_images,
rendered_warp_masks=rendered_warp_masks,
return_latents=True,
)
if generated is None:
continue
video, final_prompt, latents = generated # Gen3cPipeline.generate(..., return_latents=True)
rgb_teacher = vae_rgb_decoder(latents) # paper teacher branch; official script also saves video outputs
teacher_batches.append({"latents": latents, "rgb_teacher": rgb_teacher, "cameras": cams})
return teacher_batches(b) LatentRecon.forward_gaussians():latent-space 3DGS decoder
class LatentRecon(nn.Module):
def forward_gaussians(self, video_latents, plucker_latents, rays_o, rays_d, time_latents=None,
num_input_multi_views=1):
x = self.reshape_mv_temp_to_batch(video_latents, num_input_multi_views)
plucker = self.reshape_mv_temp_to_batch(plucker_latents, num_input_multi_views)
rays_o = self.reshape_mv_temp_to_batch(rays_o, num_input_multi_views)
rays_d = self.reshape_mv_temp_to_batch(rays_d, num_input_multi_views)
tokens = self.patch_embed(x) # PatchEmbed3D over video latents
tokens = tokens + self.patch_plucker_embed(plucker)
if time_latents is not None:
src_t, tgt_t = self.get_time_embedding(time_latents, V=x.shape[1],
num_input_multi_views=num_input_multi_views)
tokens = tokens + src_t + tgt_t
if self.process_multi_views:
tokens = self.reshape_mv_batch_to_temp(tokens, num_input_multi_views)
for block in self.enc_blocks: # hybrid Transformer/Mamba-2 blocks
tokens = block(tokens)
tokens = self.enc_norm(tokens)
if self.process_multi_views:
tokens = self.reshape_mv_temp_to_batch(tokens, num_input_multi_views)
dense = self.deconv(rearrange(tokens, "b (t h w) c -> b c t h w", h=self.h, w=self.w))
dense = maybe_subsample_gaussians(dense, rays_o, rays_d)
gaussians = self.gaussian_processing(dense, rays_o, rays_d)
return self.gaussian_pruning(gaussians)(c) gaussian_processing():从 decoder channels 到 3DGS attributes
def gaussian_processing(x, rays_o, rays_d, dnear=0.1, dfar=500.0, scale_cap=0.3):
distance, rgb, scaling, rotation, opacity = x.split([1, 3, 3, 4, 1], dim=-1)
w = torch.sigmoid(distance - 1.65)
depth = dnear * (1.0 - w) + dfar * w
position = rays_o + rays_d * depth
alpha = torch.sigmoid(opacity - 2.0)
scale = torch.minimum(torch.exp(scaling - (1.0 - math.log(scale_cap))),
torch.tensor([scale_cap], device=x.device, dtype=x.dtype))
quat = F.normalize(rotation, dim=-1)
color = 0.5 * torch.tanh(rgb) + 0.5
return torch.cat([position, alpha, scale, quat, color], dim=-1) # [B, N, 14](d) train_step():student rendering 与 teacher RGB/depth 对齐
def train_step(batch, vae, transformer, optimizer, lr_scheduler, lpips_loss_module, config, accelerator, train_loss=0.0):
gt_images = batch["images_output"] # RGB-decoded teacher frames
gt_depths = batch.get("depths_output") # ViPE depth supervision when enabled
if "rgb_latents" in batch:
batch["images_input_embed"] = batch["rgb_latents"].to(torch.bfloat16)
else:
batch["images_input_embed"] = encode_multi_view_video(
vae, batch["images_input_vae"], batch["num_input_multi_views"], config.vae_backbone
)
batch["plucker_embedding"], batch["rays_os"], batch["rays_ds"] = get_plucker_embedding_and_rays(
batch["intrinsics_input"], batch["c2ws_input"], config.img_size,
config.patch_size_out_factor, batch["flip_flag"], get_batch_index=False,
)
if config.time_embedding_vae:
batch = encode_latent_time_vae(batch, lambda x: encode_video(vae, x, config.vae_backbone), config.img_size)
if config.plucker_embedding_vae:
batch = encode_plucker_vae(batch, lambda x: encode_multi_view_video(vae, x, batch["num_input_multi_views"], config.vae_backbone))
output = transformer(batch)
# Mirrors train.py: compute_loss uses the real Accelerator to gather logging loss.
train_loss, loss = compute_loss(
accelerator=accelerator, train_loss=train_loss,
pred_images=output["images_pred"], gt_images=gt_images,
pred_depths=output["depths_pred"], gt_depths=gt_depths,
pred_opacity=output["opacity_pred"], config=config,
lpips_loss_module=lpips_loss_module, lpips_img_size=config.img_size,
)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(transformer.parameters(), config.max_grad_norm)
optimizer.step(); lr_scheduler.step(); optimizer.zero_grad()
return loss.item()(e) Dynamic flipped supervision:gen3c_dynamic_sdg.py --flip_supervision
def build_dynamic_supervision_trajectories(base_trajectories, flip_supervision: bool):
trajectories = []
trajectories.append({name: {**cfg, "flip_supervision": False}
for name, cfg in base_trajectories.items()})
if flip_supervision:
n = len(base_trajectories)
flipped = {}
for name, cfg in base_trajectories.items():
flipped[name] = {**cfg, "traj_idx": cfg["traj_idx"] + n, "flip_supervision": True}
trajectories.append(flipped)
return trajectories
def maybe_flip_input_for_supervision(video, depth, mask, w2c, intrinsics, flip_supervision: bool):
if not flip_supervision:
return video, depth, mask, w2c, intrinsics
return (video.flip(dims=[0]), depth.flip(dims=[0]), mask.flip(dims=[0]),
w2c.flip(dims=[0]), intrinsics.flip(dims=[0]))3.8 Code-to-paper mapping
Code reference:
main@52e50798(2026-04-18) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| 官方 Lyra 1.0 入口与复现实验说明 | Lyra-1/README.md | demo / training / model weights / dataset workflow |
| 训练主循环与 self-distillation student optimization | Lyra-1/train.py | main(), inner train_step() |
| 3DGS decoder / latent reconstruction network | Lyra-1/src/models/recon/model_latent_recon.py | LatentRecon, forward_gaussians(), forward() |
| Gaussian attribute decoding、opacity pruning | Lyra-1/src/models/recon/model_latent_recon.py | gaussian_processing(), gaussian_pruning() |
| RGB / LPIPS / depth / opacity loss | Lyra-1/src/models/utils/loss.py | compute_loss(), compute_depth_loss() |
| Plücker/time latent encoding helpers | Lyra-1/src/models/utils/model.py | encode_plucker_vae(), encode_latent_time_vae(), get_model_blocks() |
Camera rays / pixel subsampling / .ply export | Lyra-1/src/models/utils/render.py | get_plucker_embedding_and_rays(), subsample_x_and_rays(), save_ply() |
| 3DGS rendering backend | Lyra-1/src/rendering/gs.py, Lyra-1/src/rendering/gs_deferred.py | GaussianRenderer, GaussianRendererDeferred |
| Inference and export pipeline | Lyra-1/sample.py | load_model(), main_single() |
| Dynamic flipped supervision generation | Lyra-1/cosmos_predict1/diffusion/inference/gen3c_dynamic_sdg.py | --flip_supervision, trajectory duplication and input flipping |
| Progressive training configs | Lyra-1/configs/training/*.yaml | 3dgs_res_704_1280_views_121_multi_6*.yaml, default.yaml |
4. Experimental Setup (实验设置)
- Training data / scale:作者不使用现成真实 multi-view datasets 来训练 3DGS decoder,而构建 Lyra dataset。3D setup 使用 59,031 images;4D setup 使用 7,378 videos。每张图/视频合成 6 条 camera trajectories,得到 354,186 videos for 3D 和 44,268 videos for 4D。文本 prompts 由 LLM 采样,覆盖 indoor/outdoor、humans、animals、realistic / imaginative content;输入图像由 image diffusion model 生成,动态视频由 Cosmos / Wan 生成并用 ViPE 标注 camera poses / depth。
- Baselines:主表比较 ZeroNVS、ViewCrafter、Wonderland、Bolt3D;附录额外比较 BTimer (GEN3C)。作者说明很多 baseline 没有源码可在其 out-of-distribution Lyra set 上统一重跑,因此主表主要沿用各论文公开 protocol / reported comparisons。
- Metrics:使用 PSNR(越高越好,重建像素保真)、SSIM(越高越好,结构相似性)、LPIPS(越低越好,perceptual distance)。主任务是 single image-to-3D novel-view rendering,在 RealEstate10K、DL3DV、Tanks-and-Temples 上评测;附录在 static/dynamic Lyra dataset 上评测。
- Training config:核心 resolution / sequence setup 为 、、;decoder 为 16 layers、hidden dim 512、hybrid Transformer/Mamba-2;latent VAE compression ;optimizer config 在开源默认配置中为 AdamW、LR 、bf16、DeepSpeed、batch size 4 默认,多阶段最终 stage batch size 1。论文未详细说明完整训练 GPU type/count;README 仅说明 Lyra 在 H100 / A100 上测试,inference full offloading 最大观察显存约 43GB。
Progressive training setup(Table 3):
| Stage | Steps | |||||
|---|---|---|---|---|---|---|
| Static 1 | 17 | 1 | 17 | 4 | 10k | |
| Static 2 | 49 | 1 | 49 | 4 | 2.5k | |
| Static 3 | 49 | 1 | 49 | 2 | 2.5k | |
| Static 4 | 49 | 1 | 49 | 1 | 2.5k | |
| Static 5 | 121 | 1 | 9 | 1 | 57.5k | |
| Static 6 | 121 | 1—6 | 9 | 1 | 7k | |
| Dynamic 7 | 121 | 6 | 12 | 1 | 10k |
5. Experimental Results (实验结果)
5.1 Main benchmark:single image-to-3D novel-view rendering
| Method | RE10K PSNR↑ | RE10K SSIM↑ | RE10K LPIPS↓ | DL3DV PSNR↑ | DL3DV SSIM↑ | DL3DV LPIPS↓ | T&T PSNR↑ | T&T SSIM↑ | T&T LPIPS↓ |
|---|---|---|---|---|---|---|---|---|---|
| ZeroNVS | 13.01 | 0.378 | 0.448 | 13.35 | 0.339 | 0.465 | 12.94 | 0.325 | 0.470 |
| ViewCrafter | 16.84 | 0.514 | 0.341 | 15.53 | 0.525 | 0.352 | 14.93 | 0.483 | 0.384 |
| Wonderland | 17.15 | 0.550 | 0.292 | 16.64 | 0.574 | 0.325 | 15.90 | 0.510 | 0.344 |
| Bolt3D | 21.54 | 0.747 | 0.234 | - | - | - | - | - | - |
| Ours | 21.79 | 0.752 | 0.219 | 20.09 | 0.583 | 0.313 | 19.24 | 0.570 | 0.336 |
结论:Lyra 在三个 benchmark 的所有可比 metric 上都优于已列 baseline。提升最大的是 DL3DV / Tanks-and-Temples 上的 PSNR,相比 Wonderland 分别从 16.64→20.09、15.90→19.24,说明 self-distilled video prior 对复杂 scene-level novel-view rendering 有明显帮助。

Figure 6 解读:图 6 展示 image-to-3DGS 生成后的 5 个 novel views。重点不是单帧 photorealism,而是同一显式 3DGS 从多个视角渲染时能保持较一致的场景结构。

Figure 10 解读:图 10 与 BTimer (GEN3C) 做 qualitative comparison。BTimer 是 pixel-space feed-forward 3D baseline,使用同一 GEN3C 生成视频但只能 subsample 少量帧;Lyra 直接吸收多轨迹 latent,因此在极端视角下 artifacts 更少、细节更稳定。
5.2 Lyra dataset 上的 static / dynamic 附加结果
| Setting | Method | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| Static Lyra dataset | BTimer (GEN3C) | 16.32 | 0.580 | 0.427 |
| Static Lyra dataset | Ours | 24.92 | 0.834 | 0.183 |
| Dynamic Lyra dataset | BTimer (GEN3C) | 20.29 | 0.687 | 0.315 |
| Dynamic Lyra dataset | Ours | 23.07 | 0.779 | 0.231 |
静态 Lyra dataset 上,Ours 相比 BTimer (GEN3C) 提升 +8.60 PSNR / +0.254 SSIM / -0.244 LPIPS;动态 Lyra dataset 上提升 +2.78 PSNR / +0.092 SSIM / -0.084 LPIPS。动态提升较小但仍稳定,说明 time-conditioned 3DGS decoder 可以从 monocular video 扩展到 4D scene generation。
5.3 Ablation:哪些组件最关键
| Method | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| Ours | 24.77 | 0.837 | 0.224 |
| real data only | 19.08 | 0.659 | 0.413 |
| self-distill. + real data | 24.74 | 0.823 | 0.236 |
| w/o depth loss | 24.31 | 0.811 | 0.247 |
| w/o opacity pruning | 24.55 | 0.820 | 0.237 |
| w/o LPIPS loss | 23.74 | 0.766 | 0.370 |
| w/o multi-view fusion | 17.73 | 0.632 | 0.446 |
| w/o Mamba-2 | 24.58 | 0.818 | 0.241 |
| w/o latent 3DGS | OOM | OOM | OOM |
关键发现:
- self-distillation 比真实数据更重要:real data only 只有 19.08 / 0.659 / 0.413;加真实数据到 self-distillation 也没有超过纯 self-distillation,说明 GEN3C teacher 生成的监督已经足够多样且一致。
- multi-view fusion 是最大结构性贡献:去掉后 PSNR 从 24.77 降到 17.73,LPIPS 从 0.224 升到 0.446;这证明不能把 6 条轨迹分别重建再硬合并,必须让 tokens 在 reconstruction blocks 内互相 attend / mix。
- latent-space decoder 是可扩展性的前提:pixel-space latent 3DGS ablation 直接 OOM,因为 个 views 对 pixel-space attention 不可承受;latent compression 是能处理 726 views 的关键。

Figure 7 解读:图 7 展示同一个 extreme novel viewpoint 的 ablations。w/o self-distillation 的模型泛化差,w/o multi-view fusion 的视角一致性明显破坏,w/o LPIPS loss 的细节和高频纹理更差;对应 Table 2 的数值变化。

Figure 11 解读:图 11 聚焦 depth loss。没有 depth supervision 时,RGB 渲染可能仍看起来可接受,但 depth map 变平,几何退化;加入 ViPE depth loss 后,rendered depth 更有层次,解释了 Table 2 中 w/o depth loss 的退化。
5.4 Application:simulation export
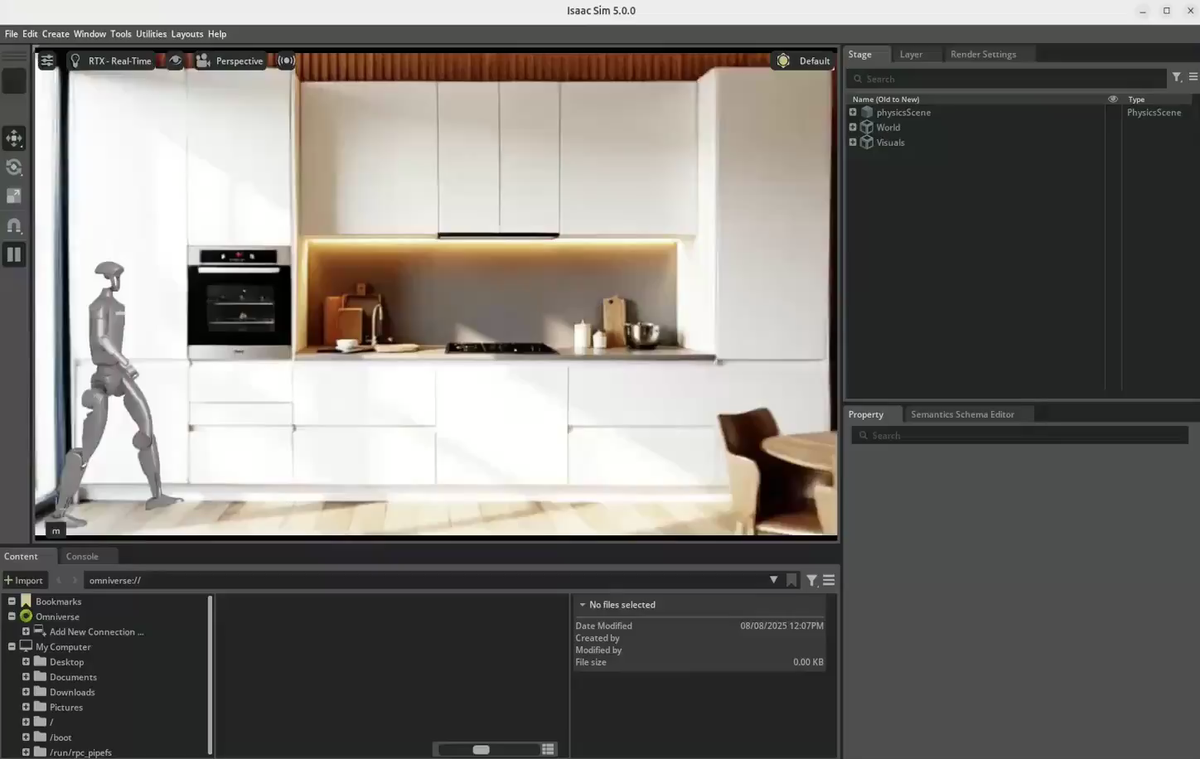
Figure 12 解读:图 12 展示 Lyra 生成的 3DGS scene 被导入 Isaac Sim 5.0 的结果。作者流程是:text → generated 3DGS → export .ply → 通过 3DGUT / .usdz 导入 Isaac,说明 Lyra 目标不只是视觉生成,而是服务 embodied AI / simulation 数据引擎。
5.5 Limitations / conclusions
作者明确指出,Lyra 的生成规模与一致性仍受 camera-controlled video diffusion model 能力上限约束;如果 teacher video model 的 long-range consistency 或 geometry 质量不足,student 3DGS 会继承这些问题。未来方向包括把 autoregressive techniques 融入大规模生成,以及在 reconstruction network 中显式建模 motion / tracking 来改善动态视觉质量。伦理上,作者也承认生成式 3D/4D 内容存在误用风险,建议 provenance tracking、dataset documentation 和严谨评测。
总体结论:Lyra 证明了 video diffusion model 的 latent 里包含可蒸馏的 3D structure;通过冻结 teacher、训练 3DGS decoder,可以在不依赖真实多视角数据、不做 per-scene optimization 的情况下得到 static / dynamic explicit 3D scenes,并在多个 benchmark 和 Lyra dataset 上超过现有 single-image-to-3D / video-to-4D baselines。