FLARE: Robot Learning with Implicit World Modeling
Authors: Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Loic Magne, Avnish Narayan, You Liang Tan, Guanzhi Wang, Qi Wang, Jiannan Xiang, Yinzhen Xu, Seonghyeon Ye, Jan Kautz, Furong Huang, Yuke Zhu, Linxi Fan Affiliations: NVIDIA, University of Maryland (College Park), Nanyang Technological University, University of Texas (Austin) arXiv: 2505.15659 Project Page: research.nvidia.com/labs/gear/flare
1. Motivation (研究动机)
-
现有 World Model 方法的问题: 近期工作(如 GR-1, GR-2, UWM)尝试联合学习 World Model 和 Policy,通过预测未来视频帧来辅助策略学习。但这种像素级预测存在根本性问题:
- 需要大规模生成模型,计算开销和延迟巨大
- 像素级重建和动作预测对模型容量的需求相互冲突 —— 视频生成强调空间细节和纹理合成,而动作建模需要紧凑的、任务相关的抽象表征
- 同时优化两个目标导致学习效率降低
-
核心问题: 能否在不进行昂贵的像素级预测的情况下,让 Policy 具备对未来状态的推理能力?
-
为什么值得研究: 人类的运动控制本质上是隐式预测未来的 —— 我们在抓取咖啡杯时不需要”想象”完整的未来画面,而是在紧凑的内部表征空间中推理。如果能在 Latent Space 而非 Pixel Space 中实现世界建模,就能以极小的代价获得显著的性能提升。
2. Idea (核心思想)
核心洞察: 将世界建模从”预测像素”转变为”预测 Embedding” —— 在 Diffusion Transformer 的中间层提取 Future Token 的表征,对齐到未来观测的 Latent Embedding,从而实现隐式世界建模。
关键创新:
- 只需在标准 VLA 模型的输入序列中添加少量可学习的 Future Token,通过辅助 Cosine Similarity Loss 将它们与未来观测的 Embedding 对齐
- 预训练一个 Action-Aware 的 Vision-Language Embedding 模型作为对齐目标,确保 Latent Space 是任务相关的
- 推理时不需要计算未来的 Vision-Language Embedding,零额外开销
与现有方法的根本区别: UWM 等方法需要解码 VAE Latent 来预测未来帧,属于显式重建;FLARE 则在紧凑的 Latent Space 中通过 Alignment Loss 隐式建模世界动态,完全避免了像素级生成。
3. Method (方法)
3.1 整体框架
FLARE 采用两阶段训练流程:
- Stage 1: 预训练 Action-Aware Vision-Language Embedding 模型
- Stage 2: 联合训练 Policy(Flow Matching Loss + Future Latent Alignment Loss)
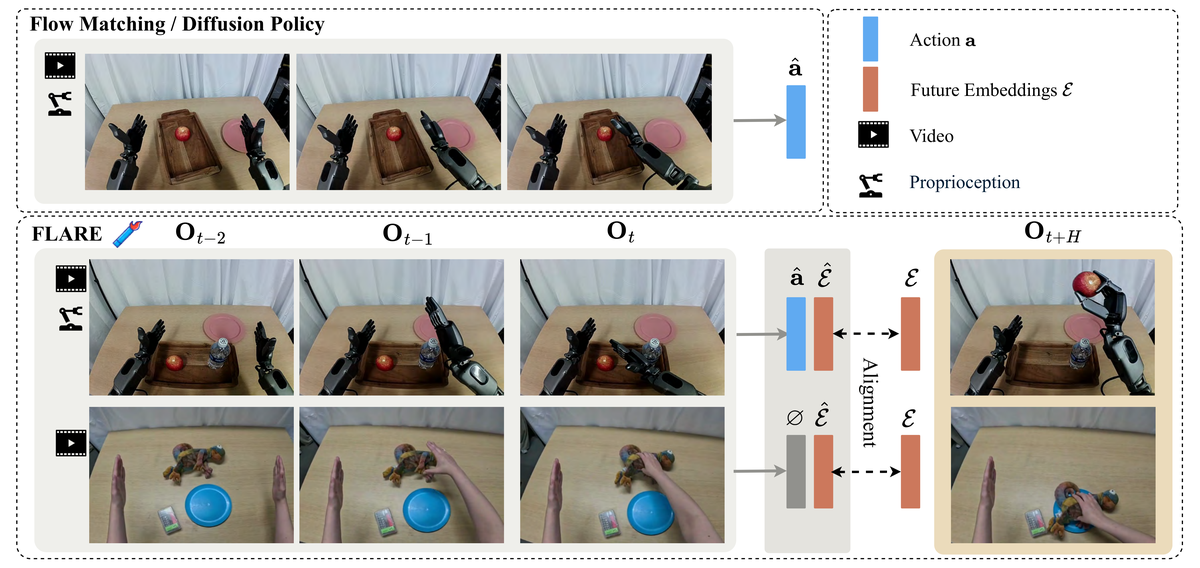
Figure 1 解读: 上半部分是传统 Flow Matching / Diffusion Policy,只接收当前和历史观测,输出动作。下半部分是 FLARE:同样接收历史观测,但额外输出 Future Embeddings ,并与未来观测 的真实 Embedding 进行对齐。关键在于:有 Action Label 的 Robot 数据同时训练 Action Loss 和 Alignment Loss;没有 Action Label 的人类视频数据只训练 Alignment Loss,从而实现无标注视频的利用。

Figure 2 解读: FLARE 的详细架构图。左侧为 DiT(Diffusion Transformer)主体,输入序列由三部分拼接而成:State Token 、Noised Action Tokens 、以及 Future Tokens。DiT 包含多层交替的 Self-Attention 和 Cross-Attention(条件为当前观测的 Vision-Language Embedding)。在第 层(默认第 6 层),提取 Future Token 对应的中间表征,通过 MLP 投影后与冻结的 Target Embedding(未来观测 的 Vision-Language Embedding)计算 Cosine Similarity Loss。Action Token 对应的输出则经过 Action Decoder 计算 Flow Matching Loss。
3.2 背景: Flow Matching
设 为机器人当前观测(含图像和语言指令), 为本体感知状态, 为 Action Chunk。 为 Vision-Language Embedding。
给定 Flow Matching 时间步 和噪声 ,构造 Noised Action Chunk:
Flow Matching Loss:
时间步 从 Beta 分布采样:,。
推理时使用 步 Euler 积分去噪:
3.3 Future Latent Representation Alignment
FLARE 的核心贡献:在 DiT 输入序列中添加 个可学习的 Future Token,在第 层提取其表征并对齐到未来观测的 Embedding。
设 为 DiT 第 层 Future Token 的激活(经 MLP 投影), 为未来观测 的 Encoder 输出。
Latent Alignment Loss:
总体训练目标:
其中 (最优值)。
关键设计选择:
- 对齐层: 选择第 6 层(共 8 层),在更深层应用让更多参数受益于未来预测监督
- 推理时: Future Token 仍参与 Self-Attention 计算,但不需要计算 Target Embedding,无额外开销
3.4 Action-Aware Future Embedding Model

Figure 10 解读: Q-former 架构详细图。左侧分支:SigLIP-2 Vision Model 输出 256 个 Patch Token,SigLIP-2 Text Model 输出 32 个 Language Token,拼接后通过 4 层 Self-Attention Transformer 得到 288 个 Fused Token。右侧分支:32 个随机初始化的 Learnable Query Token 通过交替的 Self-Attention 和 Cross-Attention 层(Cross-Attend 到 288 个 Fused Token),最终压缩为 32 个紧凑的 Vision-Language Embedding Token。
设计目标: 紧凑性 (Compactness) + 动作感知 (Action-Awareness)
架构细节:
- Backbone:
siglip2-large-patch16-256,处理 256x256 分辨率图像 - Vision Tokens: 256 个 SigLIP-2 Patch Token
- Language Tokens: 32 个 Language Token
- Fusion: 4 层 Self-Attention Transformer → 288 个 Fused Token
- Compression: Q-former 将 288 → 32 个 Learnable Query Token()
- 训练: 端到端使用 Action Flow-Matching 目标训练,附加 8 个 DiT blocks
为什么需要 Action-Aware Embedding 而非通用 Encoder: 实验证明(Table 2),使用针对动作预测优化的 Embedding 比直接用 SigLIP-2 特征好 5-6 个百分点,因为它能过滤掉与任务无关的视觉信息。
3.5 EMA 更新 Target Embedding
为了缓解预训练 Embedding 和下游任务之间的分布偏移,采用 EMA 更新 Target Embedding:
最优 EMA 系数 。

Figure 9 解读: EMA 系数消融实验。Baseline(无 FLARE Loss)为 60.1%, 时 63.5%(更新过快导致不稳定), 时 66.4%(最优), 时 65.7%,(完全冻结)时 64.6%。说明适度的 EMA 更新优于完全冻结。
3.6 利用无标注人类视频
FLARE 的独特优势:对于没有 Action Label 的人类第一视角视频,只应用 (不计算 ),让模型从人类演示中学习任务动态的 Latent 表征。

Figure 7 解读: 左侧展示实验设置 —— 选取 5 个训练集中未见过的新物体,收集 150 个 GoPro 人类演示 + 少量(1 或 10 个)机器人遥操作演示。右侧柱状图:仅 1 个 Robot Demo 时,FLARE(37.5%)vs FLARE + Human Ego Videos(60%);10 个 Robot Demo 时,FLARE(42.5%)vs FLARE + Human Ego Videos(80%)。人类视频约使性能翻倍。
3.7 伪代码
论文附录 D 提供了官方伪代码:
Algorithm: FLARE Training Loop
# Key components:
# target_vl_embedding: pretrained action-aware vision language embedding
# vl_embedding: vision language embedding of the current policy
# dit: diffusion transformer of the current policy
# action_embedding: 2-layer MLP to embed noisy actions
# state_embedding: 2-layer MLP to embed proprioceptive state
# action_decode: 2-layer MLP to decode robot's actions
# embedding_decode: 2-layer MLP to decode predicted embeddings
# M: Number of tokens in VL embedding (32)
# lambda: coefficient of FLARE loss (default 0.2)
### Initialization
future_tokens = nn.Embedding(M, hidden_dim)
vl_embedding.load_state_dict(vl_embedding.state_dict())
target_vl_embedding.requires_grad = False
for n in range(N):
obs, proprio, actions, future_obs = dataset.next()
### Prepare noisy action inputs
noise = gaussian.sample()
timestep = beta.sample() # sample flowmatching timestep
noisy_action = timestep * actions + (1 - timestep) * noise
velocity = actions - noise
### Get state, action, and observation embedding tokens
action_tokens = action_embed(noisy_action, timestep)
state_token = state_embed(state)
vl_tokens = vl_embedding(obs)
### Pass through DiT layers
sa_tokens = torch.concat([state_token, action_tokens, future_tokens], dim=1)
policy_outputs = dit(sa_tokens, vl_tokens)
### Calculate action flowmatching loss
action_outputs = action_decoder(policy_outputs[:, 1:1 + action_tokens.shape[1]])
action_loss = MSE(action_outputs, velocity)
### Calculate FLARE loss
with torch.no_grad():
embedding_to_align = target_vl_embedding(future_obs)
predict_embedding = decode_embedding(policy_outputs[:, -M:])
flare_loss = 1 - COSINE_SIMILARITY(predict_embedding, embedding_to_align)
### Optimize the combined loss
loss = action_loss + lambda * flare_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()Algorithm: Action-Aware Embedding Pretraining
# Pretrain the Q-former based VL embedding with flow-matching objective
# siglip2_vision: SigLIP-2 vision encoder (256 patch tokens)
# siglip2_text: SigLIP-2 text encoder (32 language tokens)
# fusion_layers: 4-layer self-attention transformer
# qformer: Q-former with 32 learnable query tokens
# dit_pretrain: 8-layer DiT for action prediction
for n in range(150000):
obs, text, proprio, actions = dataset.next() # diverse robot data
# Encode vision and language
vision_tokens = siglip2_vision(obs) # [B, 256, D]
lang_tokens = siglip2_text(text) # [B, 32, D]
# Fuse and compress
fused = fusion_layers(concat(vision_tokens, lang_tokens)) # [B, 288, D]
vl_embedding = qformer(fused) # [B, 32, D]
# Flow-matching action prediction
noise = gaussian.sample()
timestep = beta.sample()
noisy_action = timestep * actions + (1 - timestep) * noise
velocity = actions - noise
action_tokens = action_embed(noisy_action, timestep)
state_token = state_embed(proprio)
sa_tokens = concat(state_token, action_tokens)
pred = dit_pretrain(sa_tokens, vl_embedding)
loss = MSE(action_decoder(pred), velocity)
loss.backward()
optimizer.step()Algorithm: FLARE Inference (K-step Euler Denoising)
# K = 4 denoising steps
# No need to compute future VL embedding at inference time
def flare_inference(obs, proprio):
vl_tokens = vl_embedding(obs)
state_token = state_embed(proprio)
# Initialize from noise
A_0 = gaussian.sample() # [B, H, action_dim]
for k in range(K):
tau = k / K
action_tokens = action_embed(A_0, tau)
sa_tokens = concat(state_token, action_tokens, future_tokens)
outputs = dit(sa_tokens, vl_tokens)
velocity = action_decoder(outputs[:, 1:1+H])
A_0 = A_0 + (1/K) * velocity
return A_0 # predicted action chunk3.8 代码-论文映射表
| Paper Concept | Source Location | 说明 |
|---|---|---|
| 代码搜索 | github.com/nvidia/flare (coming soon) | 代码尚未开源,伪代码来自论文附录 D |
| Q-former VL Embedding | 论文 Section 3.2 + Appendix A | SigLIP-2 + 4-layer Fusion + Q-former |
| DiT Policy | 论文 Section 2 | 8-layer DiT with Cross/Self-Attention |
| FLARE Alignment Loss | 论文 Section 3.1, Eq. (2) | Cosine Similarity at Layer 6 |
| EMA Update | 论文 Section 4.4 | for target embedding |
3.9 预训练数据混合

Figure 3 解读: Action-Aware Embedding 预训练数据饼图。总计约 2,989.5 小时,其中 GR-1 Simulation 占比最大(1,742.6 小时,~58%),其次是 DROID/OXE(428.3 小时)、RT-1/OXE(338.4 小时)、Language Table/OXE(195.7 小时)等。真实 GR-1 数据仅 88.4 小时(~3%),说明模型主要依赖仿真和多源数据进行预训练。
4. 实验设置 (Experimental Setup)
数据集与规模
| 数据集 | 帧数 | 时长 (hr) | FPS | 视角 | 类别 |
|---|---|---|---|---|---|
| GR-1 In-house (real) | 6.4M | 88.4 | 20 | Egocentric | Real robot |
| DROID (OXE) | 23.1M | 428.3 | 15 | Left, Right, Wrist | Real robot |
| RT-1 (OXE) | 3.7M | 338.4 | 3 | Egocentric | Real robot |
| Language Table (OXE) | 7.0M | 195.7 | 10 | Front-facing | Real robot |
| Bridge-v2 (OXE) | 2.0M | 111.1 | 5 | Shoulder, left, right, wrist | Real robot |
| MUTEX (OXE) | 362K | 5.0 | 20 | Wrist | Real robot |
| Plex (OXE) | 77K | 1.1 | 20 | Wrist | Real robot |
| RoboSet (OXE) | 1.4M | 78.9 | 5 | Left, Right, Wrist | Real robot |
| GR-1 Simulation | 125.5M | 1,742.6 | 20 | Egocentric | Simulation |
| Total | 169.5M | 2,989.5 | - | - | - |
评估 Benchmark
- RoboCasa: 24 个单臂操作任务(Panda Arm),模拟厨房环境,包含 pick-and-place、开关门、水龙头操作等
- GR-1 Humanoid Simulation: 24 个双手操作任务,包含 18 个物体重排和 6 个铰接物体交互
- Real GR-1: 4 个真实世界 pick-and-place 任务,每任务 100 条轨迹
- Novel Object Generalization: 5 个训练中未见过的新物体,测试泛化能力
Baseline 方法
- Diffusion Policy: U-Net 架构,基于 Diffusion 的动作生成
- UWM (Unified World Model): 联合预测 Image VAE Latent 和 Action,训练 400k steps(5x 其他方法)
- GR00T N1 (Scratch): 相同架构但 DiT 从头训练,仅加载预训练 Eagle VLM
- FLARE Policy Only: 与 FLARE 完全相同的架构,但不使用 Latent Alignment Loss
训练配置
| 配置项 | Embedding 预训练 | Policy 训练 |
|---|---|---|
| GPU | 256x H100 | 32x H100 |
| Batch Size | 8192 | 1024 |
| Gradient Steps | 150,000 | 80,000 |
| Optimizer | AdamW (=0.95, =0.999, =1e-8) | 同左 |
| Weight Decay | 1e-5 | 1e-5 |
| LR Schedule | Cosine, warmup ratio 0.05 | 同左 |
| DiT Layers | 8 | 8 |
| Denoising Steps (推理) | - | K=4 |
5. 实验结果 (Experimental Results)
5.1 Multitask Benchmark 主要结果

Figure 4 解读: 展示 RoboCasa(24 个 Panda Arm 任务)和 GR-1 Humanoid(24 个双手操作任务)的示例任务截图。
| Methods | FLARE | Policy Only | UWM | GR00T N1 (Scratch) | Diffusion Policy |
|---|---|---|---|---|---|
| RoboCasa | |||||
| Pick and Place | 53.2% | 43.8% | 35.6% | 44.1% | 29.2% |
| Open & Close Doors/Drawers | 88.8% | 78.7% | 82.0% | 80.0% | 78.7% |
| Others | 80.0% | 75.2% | 74.2% | 69.6% | 61.3% |
| 24 RoboCasa Average | 70.1% | 61.9% | 60.8% | 60.6% | 51.7% |
| GR-1 Humanoid | |||||
| Pick and Place Tasks | 58.2% | 46.6% | 30.1% | 51.8% | 40.4% |
| Articulated Tasks | 51.3% | 47.4% | 38.4% | 42.8% | 50.1% |
| 24 GR-1 Average | 55.0% | 44.0% | 29.5% | 45.1% | 40.9% |
关键发现: FLARE 在所有类别上一致性地超越所有 Baseline,RoboCasa 上领先 Policy Only 8.2%,GR-1 上领先 11%。值得注意的是,UWM 使用了 5 倍训练步数(400k vs 80k)仍然大幅落后。
5.2 Data-Efficient Post-training

Figure 6 解读: 左图为 RoboCasa 24 个任务的 Post-training 结果(使用预训练 Embedding)。随数据量增加(100/300/1000 trajectories per task),FLARE 始终领先 Policy Only,且在 100 条时优势最明显(约 10% 差距)。右图为真实 GR-1 的 4 个任务:FLARE 平均 95.1% vs Policy Only 81.2%,提升 14%。
| 真实 GR-1 任务 | Policy Only | FLARE |
|---|---|---|
| Tray to Plate | 87.5% | 100% |
| Cutting Board to Basket | 62.5% | 87.5% |
| Cutting Board to Pan | 87.5% | 87.5% |
| Placemat to Basket | 87.5% | 87.5% |
| Average | 81.2% | 95.1% |
5.3 Human Egocentric Video Co-training
| 设置 | 1 Robot Demo/Object | 10 Robot Demos/Object |
|---|---|---|
| FLARE (action-only) | 37.5% | 42.5% |
| FLARE + Human Ego Videos | 60.0% | 80.0% |
人类视频 co-training 使性能几乎翻倍(1 demo: 37.5% → 60%;10 demo: 42.5% → 80%)。
5.4 Ablation Studies
Embedding 模型消融 (Table 2):
| Method | Success Rate |
|---|---|
| No FLARE loss | 43.9% |
| SigLIP2 (raw, 256 tokens) | 49.6% |
| SigLIP2 (Average Pooled, 64 tokens) | 50.9% |
| Action-aware Embedding (32 tokens) | 55.0% |

Figure 8 解读: 左图为 DiT Layer 选择消融 —— Layer 4 表现最差(约 52.5%),Layer 6 最优(约 55%),Layer 7-8 略有下降。右图为 系数消融 —— 时约 52%, 最优(约 55%),- 仍保持稳定(53-55%)。红色虚线为 Policy Only baseline(43.9%)。
5.5 局限性
- 主要关注桌面 Pick-and-Place 的 Imitation Learning
- 尚未整合 Reinforcement Learning
- 依赖少量专家示范,在难以收集数据的场景中可能受限
- 人类视频仅限受控环境下 GoPro 拍摄,尚未扩展到大规模自然场景
5.6 总体结论
FLARE 提出了一种简单而有效的隐式世界建模方案:通过在 DiT 中添加 Future Token 并对齐到未来观测的 Latent Embedding,以极小的架构修改获得了高达 26% 的性能提升。该方法还开辟了利用无标注人类视频增强机器人策略的新途径,展示了 Latent World Model 在机器人学习中的巨大潜力。