ParetoSlider: Diffusion Models Post-Training for Continuous Reward Control
1. Motivation(研究动机)
- 现有方法的问题:视觉生成里用 RL / Flow 后训练对齐(如 DDPO、DPOK、FlowGRPO、基于前向过程的 DiffusionNFT、以及偏好优化类 FPO 等)时,绝大多数实现都把多个评价维度压成单一标量 reward,或在训练开始就把多目标做成固定的加权和(early scalarization)。其直接后果是:策略在训练期就被「锁死」在某个静态折中点上;推理阶段用户无法按需调节「prompt 遵循 vs. 源图保真」「美学 vs. 对齐」「照片感 vs. 风格化」等彼此冲突的目标。
- 本文要解决的问题:在 diffusion / flow-matching 后训练场景下,用单个模型近似整条 Pareto front,并在推理时用连续的控制量(preference 权重向量 )在冲突目标之间平滑导航,而无需为每个折中点单独训练或保存多份 checkpoint。
- 为何重要:真实产品部署中,不同用户/场景对 trade-off 的需求不同;若只能在训练时选定一个标量化方案,会牺牲可控性与可解释性。把多目标 RL 显式做成「preference-conditioned policy」,才能把「对齐」从一次性离线决策变成可交互的推理时服务。
与相关 skill 的横向关系(阅读地图):DiffusionNFT - Online Diffusion Reinforcement with Forward Process 提供高效的前向过程 RL 微调基座;flow-grpo 代表反向轨迹上的 group-normalized RL;Flow Matching Policy Gradients 等更偏偏好/流形上的目标设计。ParetoSlider 不是在单一标量上「再挤一点分」,而是把 DiffusionNFT 式更新推广到多目标 + 条件化,解决的是「一条 front,一个模型」而非「一个 reward,一个点」。
2. Idea(核心思想)
- 核心洞见(1–3 句):把 M 维 preference 向量 (位于概率单纯形 上)作为与文本/图像并列的条件信号喂给去噪策略 ;训练时在 上随机采样 ,并对每个 reward 通道单独做 group-relative advantage 与 DiffusionNFT 损失,仅在损失聚合阶段用 做加权和(late scalarization)。这样单个网络在功能上扮演了「一族标量化问题」的共享解,从而在推理时对任意 输出对应的 Pareto 折中,而无需重训。
- 与主流做法的本质区别:传统 pipeline 是「先把 合成标量再算 advantage / policy gradient」,偏好只存在于训练脚本超参里;ParetoSlider 让偏好进入网络输入,并把标量化推迟到 per-objective NFT loss 之后,避免某一维 reward 的尺度/方差「劫持」梯度并冲淡 的语义。
3. Method(方法)
3.1 Overall framework
整体是 DiffusionNFT 风格的三阶段循环:(1) 条件于 从当前策略采样 条样本;(2) 用 个 reward 模型打分,并在每个 prompt 组内、每个目标独立做标准化得到 advantage;(3) 对每个目标构造 NFT 损失 ,再按当前样本的 线性聚合后反传,并加 KL 约束贴近参考策略。

Figure 1 解读:上图概括了论文问题设定:在 text-to-image 中在「照片感 reward」与「线稿/sketch reward」之间连续滑动;在 image editing 中在「源图保真」与「编辑指令遵循」之间滑动。关键是同一套参数在推理时接受不同 ,输出沿 Pareto 前沿分布的不同点,而不是训练时锁死一个折中。

Figure 2 解读:训练流水线与正文 Figure 2 一致:Stage (1) 对每个 prompt 采样 并生成 张图;Stage (2) 各 reward 通道独立算组内均值方差标准化 advantage;Stage (3) 分别算每条 reward 的 DiffusionNFT loss,再用 加权求和得到总 NFT 项,最后与 KL 正则一起更新。Late scalarization 体现在: 不参与各通道 advantage 的标准化,只参与损失层的凸组合。
3.2 Preference-conditioned policy 与 reward 组合
偏好向量:,满足 且 。对固定 ,理想标量化目标是最大化
但若策略不显式依赖 ,单个网络无法对所有 同时最优;因此引入 。
Late-scalarization advantage:对组内样本 、目标 ,在该 prompt、该 条件下的 个样本上,逐通道做 FlowGRPO / DiffusionNFT 风格的 group-relative 标准化(论文式 (3),本文不把 混入标准化):
再对每个 独立映射插值权重 (式 (4) 的 clip + 线性映射),构造逐目标 NFT 损失(式 (9)):
其中 为 flow 目标速度, 由 EMA old policy 与当前 policy 按 DiffusionNFT 的 implicit velocity steering(式 (5–6))得到。最终在样本 上聚合(式 (10)):
总目标(正文):
(附录 Algorithm 1 将 KL 写成当前条件策略速度 与无 条件的参考速度 的平方误差形式,与实现中「ref 前向不传 preference」一致。)
训练时 的采样(论文附录 A.3):先从对称 Dirichlet 采样;再以固定概率强制采样单纯形顶点(one-hot)或随机两目标的边(Dir(1,1) 在两维上),以覆盖边界与极端 trade-off;并对分布式训练保证「给定 prompt 与 step, 可复现」。
3.3 Conditioning 注入方式(按 backbone)
- SD3.5(T2I):在共享 timestep embedding 上加 MLP 映射的 (式 (11)),使 AdaLN 全局感知偏好;再用正弦编码 + MLP 得到共享向量 ,在每个 block 的 image stream 上按门控残差注入(式 (12))。实现与开源代码中
SD3Transformer2DModelWithConditioning/ ablation 变体一致。 - FluxKontext(I2I):将 与池化文本嵌入拼接,经 MLP 预测 context stream AdaLN 的 scale/shift 残差(式 (13)),与 Kontinuous Kontext 的「调制空间控制」同脉络,但把标量强度换成多维 。
- LTX-2(T2V):复用 SD3.5 的 shared block-residual 思路,作用在 video stream、隐藏维改为 3840;并对 MLP 末层做小方差初始化以稳定早期 RL。
3.4 推理阶段
用户指定 ,标准采样流程中对 transformer 全程传入同一 ;无需多 checkpoint 插值、无需逐步梯度引导(对比 PROUD 等)。
3.5 直觉段落:为何 preference conditioning 能近似整条 Pareto front?
若只在损失里用固定的 ,网络学到的是「单一折中策略」;把 作为条件,相当于在函数逼近层面学习映射 「在该线性效用权重下应偏向的生成统计」。Late scalarization 保证每个 reward 通道在自己的组内相对优势上都被充分更新,避免某一维 raw reward 因尺度更大而支配梯度;在此前提下再用 做凸组合,梯度方向与「当前样本声明的效用」一致。结合在 上覆盖顶点、边与内部的采样,网络在训练分布上「填满」不同效用方向的最优折中,从而在推理插值 时得到平滑、单调的轨迹(实验上表现为连续的 slider 与更好的 hypervolume)。
3.6 开源代码与伪代码(Python / PyTorch 风格)
Code reference:
main@8ce73f28(2026-04-12) — 以下伪代码与映射基于该 commit 的T2I/子目录(公开实现当前主要覆盖 SD3.5 T2I 管线;论文还包含 FluxKontext / LTX-2 的工程化扩展,未完全体现在该仓库树中)。
Preference 采样(结构化顶点 / 边 / 内部 + 分布式一致性):
import numpy as np
import torch
import hashlib
def stable_prompt_hash_u32(prompt: str) -> int:
digest = hashlib.sha256(prompt.encode("utf-8")).digest()
return int.from_bytes(digest[:4], byteorder="little", signed=False)
def sample_structured_preference(num_rewards: int, rng: np.random.Generator) -> np.ndarray:
if num_rewards == 2:
w = rng.dirichlet([1.0, 1.0]).astype(np.float32)
return w / w.sum()
roll = rng.random()
if roll < 0.50: # vertex
pref = np.zeros(num_rewards, dtype=np.float32)
pref[int(rng.integers(0, num_rewards))] = 1.0
elif roll < 0.85: # edge
pref = np.zeros(num_rewards, dtype=np.float32)
pair = rng.choice(num_rewards, size=2, replace=False)
w = rng.dirichlet([1.0, 1.0]).astype(np.float32)
pref[pair[0]], pref[pair[1]] = w[0], w[1]
else: # interior
pref = rng.dirichlet([1.0] * num_rewards).astype(np.float32)
return pref
def preferences_for_batch(prompts: list[str], num_rewards: int, epoch: int, batch_idx: int,
base_seed: int, device: torch.device) -> torch.Tensor:
prefs = []
for p in prompts:
seed = (base_seed + stable_prompt_hash_u32(p) + epoch * 100000 + batch_idx) % (2 ** 32)
rng = np.random.default_rng(seed)
w = sample_structured_preference(num_rewards, rng)
prefs.append(torch.tensor(w, device=device, dtype=torch.float32))
return torch.stack(prefs, dim=0)Per-objective advantage(组内、逐通道标准化):
def per_objective_advantages(prompts: list[str], reward_vec: np.ndarray) -> np.ndarray:
"""reward_vec: (N, M) raw rewards; group by identical prompt string."""
prompts = np.array(prompts, dtype=object)
adv = np.zeros_like(reward_vec, dtype=np.float32)
for p in np.unique(prompts):
mask = prompts == p
g = reward_vec[mask] # (K, M)
for m in range(reward_vec.shape[1]):
ch = g[:, m]
adv[mask, m] = (reward_vec[mask, m] - ch.mean()) / (ch.std() + 1e-4)
return adv训练步:per-objective NFT + 线性 scalarize(对应式 (9–10) 的实现骨架):
def nft_losses_from_advantages(adv_per_obj: torch.Tensor, pos_loss: torch.Tensor,
neg_loss: torch.Tensor, adv_clip: float, beta: float) -> torch.Tensor:
"""adv_per_obj: (B, M) ; pos_loss/neg_loss: (B,) — broadcast per objective."""
adv = torch.clamp(adv_per_obj, -adv_clip, adv_clip)
rho = 0.5 + 0.5 * torch.clamp(adv / adv_clip, -1.0, 1.0) # (B, M)
# per-objective NFT
loss_m = rho * (pos_loss[:, None] / beta) + (1.0 - rho) * (neg_loss[:, None] / beta)
return loss_m # (B, M)
def linear_scalarize(pref: torch.Tensor, losses_m: torch.Tensor) -> torch.Tensor:
"""pref, losses_m: (B, M) -> (B,)"""
return (pref * losses_m).sum(dim=1)推理:将 preference 张量传入 pipeline_with_logprob / transformer forward(与训练同形),保持 CFG、步数、噪声日程与论文 Table 1–3 一致。
Code-to-paper mapping
| Paper 概念 | 源码路径(T2I 子目录) | 关键符号 / 说明 |
|---|---|---|
| Preference-conditioned SD3 transformer | flow_grpo/diffusers_patch/transformer_sd3.py | SD3Transformer2DModelWithConditioning, forward(..., preference=...) |
| Conditioning 消融(Token / Hybrid 等) | flow_grpo/diffusers_patch/transformer_ablations.py | SD3AblationTransformer, conditioning_mode |
| 结构化 采样 + 分布式一致 | flow_grpo/preference_utils.py | build_consistent_preferences_for_global_batch, _sample_structured_preference |
| Late scalarization 聚合 | flow_grpo/scalarization.py | make_scalarizer → linear(pref, losses) |
| DiffusionNFT + per-objective 训练循环 | scripts/train_pareto_nft_sd3.py | loss_mode == "per_objective" 分支;pipeline_with_logprob(..., preference=preferences) |
| Reward 组合 / 多目标展开 | flow_grpo/rewards.py, expand_reward_fn_to_objectives | 将配置中的 reward_fn 映射为 个标量通道 |
| 组统计 / GDPO advantage | flow_grpo/stat_tracking.py | PerPromptAndPreferenceStatTracker.update_from_reward_vectors_gdpo |



Figure 3 解读:在同一条 photorealism–sketch 轴上,三个样本展示 从偏向照片感(左)经平衡(中)过渡到线稿化(右)时,语义与构图保持相对连续。该现象对应主文「多目标风格插值」定性:单模型在单纯形边上平滑移动,而不是离散换 LoRA / 换 checkpoint。



Figure 4 解读:Instruction-based editing 上, 控制「保留源图身份与细节」与「执行风格/语义编辑」的权衡:左侧更接近 preservation,右侧更激进地遵循编辑指令(面部细节随 adherence 上升而让位于风格化)。中间点展示 ParetoSlider 的「可控中点」。



Figure 5 解读:LTX-2 text-to-video 上,在 animation vs. photoreal 两目标之间调节 :左帧更偏动画质感,中间为折中,右侧更接近实拍影像。单模型跨三段偏好生成,体现方法在时序生成骨干上的可迁移性。
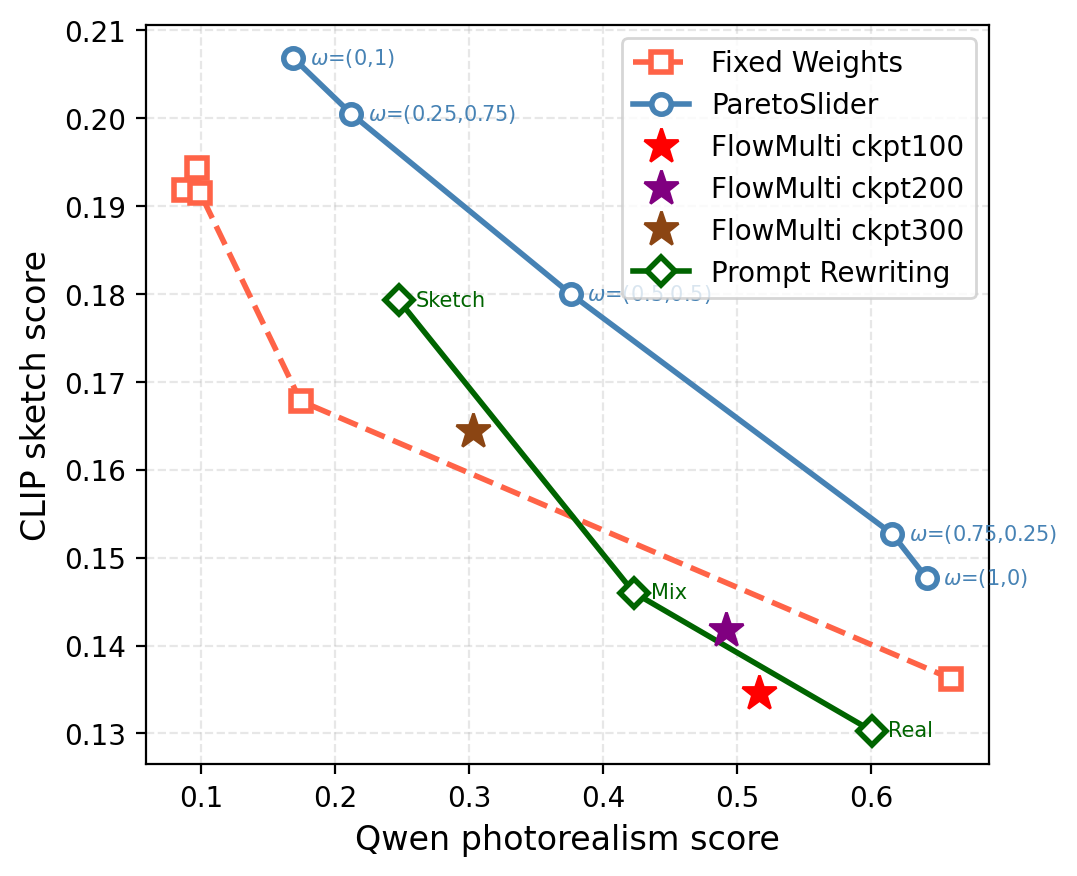
Figure 6 解读:左:在 SD3.5 上,ParetoSlider 随 扫出光滑且占优的 Pareto 曲线;FixedWeights 需多点独立训练且易向某一 reward 塌缩;FlowMulti 仅静态策略;Prompt Rewriting 只在少数改写点上离散采样。右:同一 prompt 的定性插值显示 ParetoSlider 的连续性与保真过渡。
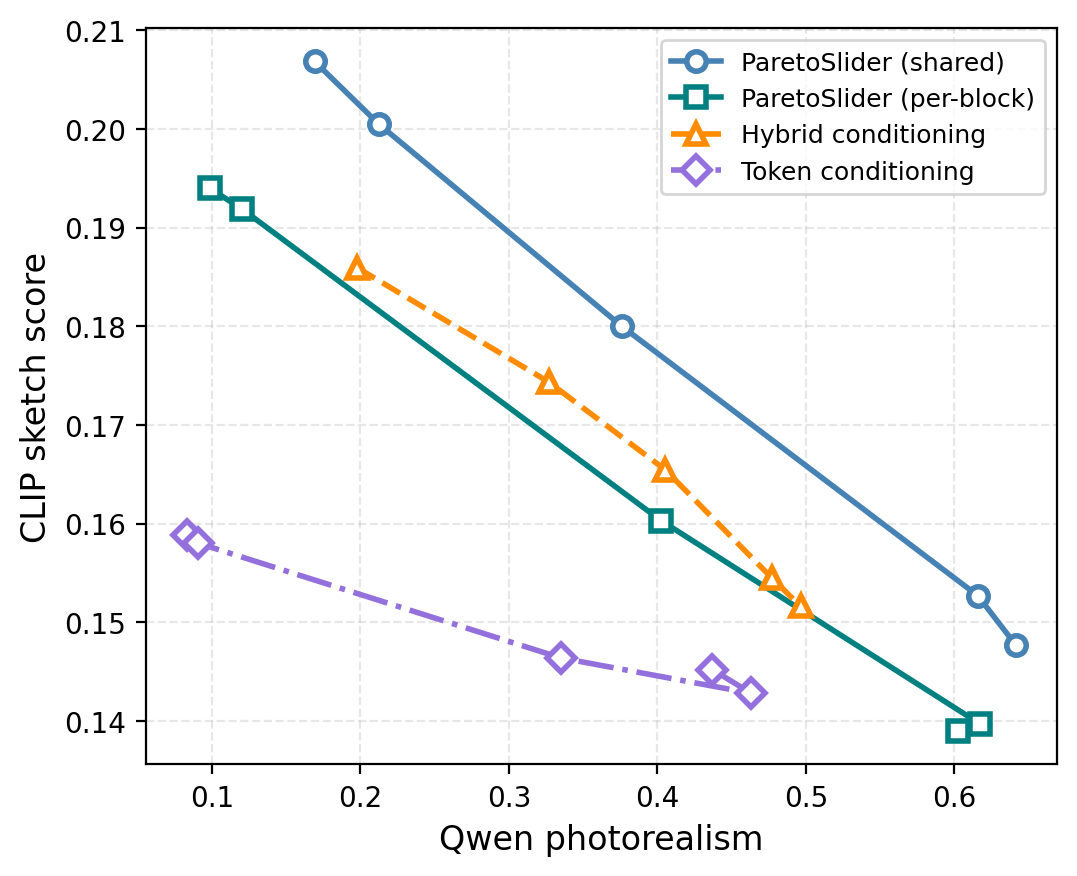
Figure 7 解读:在 photorealism–sketch 任务上比较 Shared / Per-block / Hybrid / Token 等注入方式:Shared(时间嵌入 + 跨 block 共享图像流残差)在前沿覆盖与定性平滑度上最佳;Token / Hybrid 易出现可控性弱或向主指标塌缩。
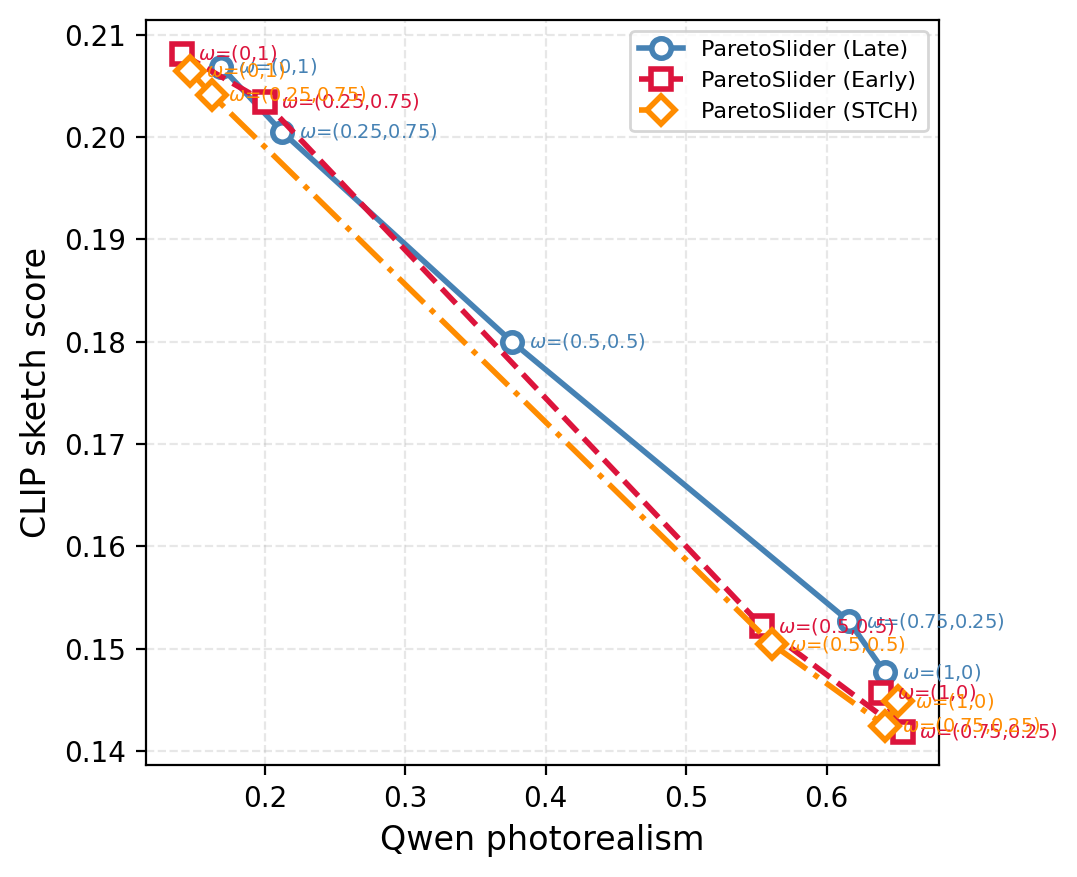
Figure 8 解读:比较 late vs early scalarization 与 Smooth Tchebycheff (STCH):三者整体前沿形状可相近,但 late scalarization 在中间 区域的过渡更平滑,更少出现「提前偏向 photoreal」的塌缩;与 Panacea 等「线性聚合仍可用」的理论叙述相容,但实现细节决定可控性质量。
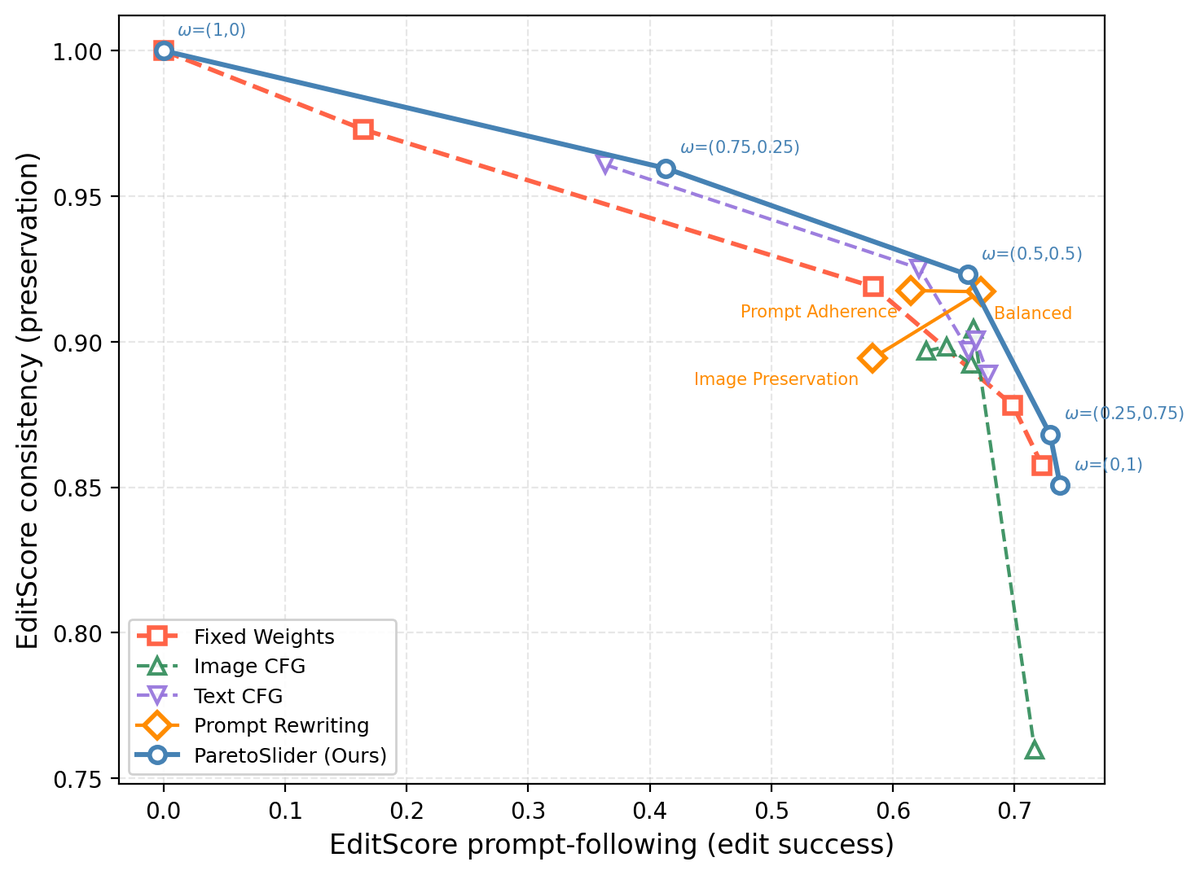
Figure 9 解读:I2I 上与 Text-CFG / Image-CFG / FixedWeights 对比:ParetoSlider 的前沿更宽且单调;CFG 扫描虽提供推理旋钮,但易引入伪影或饱和,且前沿不如显式 条件训练光滑。右列定性显示从 preservation 到 adherence 的连续过渡。
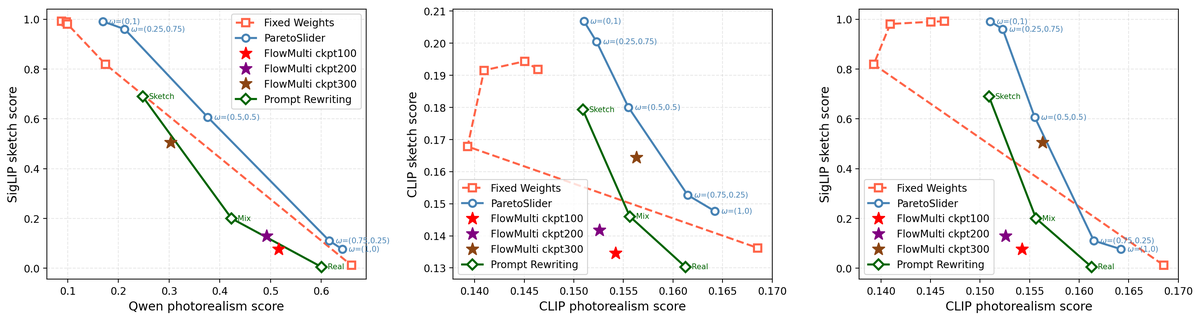
Figure 10 解读(附录 Fig. 10 精神复现):在 T2I 上换用与训练 reward 不同的评测组合(如 Qwen2.5-VL sketch + CLIP photorealism)绘制 Pareto 曲线时,ParetoSlider 相对 FixedWeights / FlowMulti / Prompt Rewriting 仍保持占优前沿,说明学到的可控性不完全是「过拟合单一 reward 口径」。
4. Experimental Setup(实验设置)
4.1 任务、骨干与数据
| 骨干 | 任务 | 数据 / 设定 |
|---|---|---|
| SD3.5 Medium | Text-to-image | 与 DiffusionNFT 对齐,使用 PickScore 数据集 split;主实验关注 photorealism vs. sketch;另展示多风格(水彩、动漫、三目标等) |
| Flux.1 Kontext dev | Instruction editing | 基于 FFHQ-512 caption 用 Claude 4.6 Opus 生成多样化编辑指令;附录还给 EditScore 训练的结果 |
| LTX-2 (19B) | Text-to-video | 1,000 条由 Claude 4.6 Opus 生成的中等长度 prompt |
4.2 Reward 设计(摘要)
- T2I:PickScore、CLIPScore;抽象风格用 Qwen2.5-VL / UnifiedReward-2.0 提示词打分;结构化 sketch 用 PACS 风格分类器 + Sobel 边缘统计 的自定义指标。主消融在 PickScore(photoreal 提示模板) + sketch metric 上训练,评测可用 Qwen sketch + CLIP photoreal 以检验未过拟合。
- I2I:Qwen2.5-VL 编辑成功度 + CLIP I2I 余弦相似度 衡量 preservation(附录给出显式公式 )。
- T2V:UnifiedReward-2.0 在 8 帧子采样上分别用两份 rubric 提示评估 photoreal 与 animation,分数离散 0–5 再归一化到 。
4.3 Baselines
- T2I:FixedWeights(多次独立 DiffusionNFT);Flow-Multi(GRPO + batch Pareto 选点,但推理无 );Prompt Rewriting(Gemini 3 改写 prompt,仅离散点)。
- I2I:Text-CFG / Image-CFG(类 InstructPix2Pix 双引导扫描);Prompt Rewriting;FixedWeights(5 个 DiffusionNFT 模型)。
4.4 指标
- Pareto 前沿可视化、Hypervolume (HV)(全局 min-max 归一化后,以原点为参考;论文强调 Non-Dominated 点数)。
- VIEScore 作为与训练奖励正交的编辑评测;附录还报告 CLIP Directional + LPIPS 组合。
- User study:主文未作为核心量化(论文未强调大规模人工排序为主表)。
4.5 训练配置(摘自附录 Table 1–3)
SD3.5(Table 1):冻结 VAE 与文本编码器;LoRA rank 32;warm start 6 epoch(CLIPScore + PickScore DiffusionNFT);再 9 epoch ParetoSlider;分辨率 512×512;训练 25 步、评测 40 步;DPM2;guidance scale 1.0;noise level 0.7;每 prompt 24 重复采样、2 个 preference 子组;AdamW lr ;;;implicit ;fp16。
FluxKontext(Table 2):LoRA rank 64, alpha 128;12 epoch;384×384;训练 10 步、评测 15 步;guidance 2.5;每 prompt 24 样本、4 偏好子组;;bf16。
LTX-2(Table 3):文本编码 Gemma 3 12B IT;LoRA rank/alpha 32;512×512、41 帧、25 fps;训练 20 步、评测 50 步;评测 guidance 4.0;每样本 5 个训练时间步;;EMA 0.9;bf16。
算力:致谢提到 NVIDIA Academic Grant 通过 Brev 提供 GPU 时数;主文未逐实验列出总 GPU hour。
5. Experimental Results(实验结果)
5.1 Hypervolume(附录 Table 6–7,数值照录)
Table 6 — T2I(评测:Qwen2.5-VL sketch + CLIP photorealism)
| Method | HV ↑ | Non Dom. ↑ | Pts. |
|---|---|---|---|
| ParetoSlider | 0.870 | 5 | 5 |
| Prompt Rewriting | 0.827 | 2 | 3 |
| FlowMulti ckpt300 | 0.683 | 1 | 1 |
| Fixed-Weights | 0.435 | 2 | 5 |
Table 7 — I2I(评测:VIEScore 双通道)
| Method | HV ↑ | Non Dom. ↑ | Pts |
|---|---|---|---|
| ParetoSlider | 0.574 | 5 | 5 |
| Text-CFG | 0.561 | 3 | 4 |
| Fixed-Weights | 0.516 | 4 | 5 |
| Prompt Rewriting | 0.459 | 3 | 3 |
| Image-CFG | 0.395 | 1 | 4 |
解读:ParetoSlider 在 HV 与 非支配点数量上整体领先;FixedWeights 虽可有多个点,但前沿质量(HV)显著落后;FlowMulti 在 T2I 上几乎退化为单有效点(ckpt300 行 Non Dom.=1)。
5.2 定性结论
- T2I:在多组风格轴上, 插值产生语义连续的图像序列;三目标(照片 / 水彩 / 线稿)也能在三角形偏好内平滑过渡。
- I2I:在身份细节保留与指令强度之间可解释地滑动;CFG baseline 在极端区域更易出现artifacts。
- T2V:在 animation–photoreal 轴上,极端与中点均合理。
5.3 Ablations(与主文 Figure 7–8 一致)
- Conditioning:Shared(默认)优于 Token / Hybrid 等变体,前沿更分散、插值更平滑。
- Scalarization:Late 在中间区域过渡最佳;Early / STCH 仍可覆盖大致前沿,但更易偏向某一目标。
5.4 Limitations(附录 Section C,作者原述)
- 强烈依赖 reward 质量:若某一维 proxy reward 与真实用户意图不一致(如把「灰度图」误认为 sketch),会扭曲整条 trade-off 表面;多目标下错误会被放大。
- 未claim:在 reward 严重错误指定时仍能恢复「真」Pareto front;需要谨慎设计与验证奖励。
5.5 结论
ParetoSlider 将 multi-objective RL 中的 preference conditioning 与 DiffusionNFT 式前向 RL 结合,并以 late scalarization 稳定多通道学习;在 SD3.5 / FluxKontext / LTX-2 三类骨干上,单模型即可在推理时连续扫描 Pareto 前沿,并在 HV 与定性上优于多模型固定权重与 CFG / 改写类基线。
备注
paper_to_skill:扫描~/ai-skills/skills/*/sources.json未找到2604.20816的匹配项,故 frontmatter 未设置该字段。- 公开仓库当前以
T2I/为主;若需 I2I / T2V 的完整复现,请同时以论文附录实现细节为准或关注仓库后续更新。