Flow Matching Policy Gradients
Authors: David McAllister*, Songwei Ge*, Brent Yi*, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, Angjoo Kanazawa (* Equal contribution) Affiliations: UC Berkeley, Max Planck Institute for Intelligent Systems arXiv: 2507.21053 Project Page: flowreinforce.github.io GitHub: akanazawa/fpo
1. Motivation(研究动机)
现有方法的问题:
-
Gaussian Policy 的表达能力受限:标准 PPO 使用对角 Gaussian 策略,天然是单峰的,无法捕捉多模态动作分布。在存在多个等价最优动作的任务中(如 GridWorld 有两个目标),Gaussian Policy 会坍缩到最近目标,丢失多样性。
-
Diffusion/Flow Policy 与 RL 融合的困难:Flow-based 生成模型(Diffusion Model、Flow Matching)能建模高维连续分布,但它们的精确 likelihood 计算需要昂贵的散度估计(通过 ODE 的 Hutchinson estimator),计算上不可行。
-
现有 Denoising MDP 方法的局限:DDPO、DPPO、Flow-GRPO 等方法通过将去噪过程重新表述为 Markov Decision Process,把每个去噪步骤当作一个 Gaussian Policy 步来进行 PPO 训练。这带来三个问题:
- 将 horizon 乘以去噪步数(10-50x),加大 credit assignment 难度
- 初始噪声值作为环境观测输入,增加问题维度
- 只支持随机采样,不支持确定性/高阶积分器
本文要解决的问题: 如何直接将 Flow Matching 与 Policy Gradient 框架融合,避免精确 likelihood 计算,同时保持采样方法的灵活性?
为什么值得研究: Flow-based Policy 兼具强大的分布建模能力和灵活的推理采样方式,将其纳入 RL 框架可以解锁更强的策略表达能力,在欠条件控制、机器人控制等高维任务中具有实际意义。
2. Idea(核心思想)
核心洞察: Flow Matching 的 Conditional Flow Matching (CFM) 损失是对数似然的变分下界(ELBO)的代理,因此可以用 CFM 损失的差值来估计新旧策略的 likelihood ratio,从而替代 PPO 中的精确 likelihood 比值。
一句话概括:
FPO 将 PPO 中的 likelihood ratio 替换为由 Conditional Flow Matching 损失差导出的比值 ,实现了对 flow-based policy 的 on-policy RL 训练。
与现有方法的根本区别:
- 不需要计算精确 likelihood(避免了 ODE 散度估计)
- 不将去噪过程建模为 MDP(不扩展 horizon,不绑定特定采样方法)
- 训练和推理时都可以使用任意 flow/diffusion 积分器(deterministic、stochastic、higher-order、任意步数)
3. Method(方法)
3.1 整体框架
FPO 是一个 on-policy RL 算法,整体框架与 PPO 高度一致,只做两处修改:
- Rollout 阶段:用 flow model 采样动作(任意积分器),并为每个动作存储 个 采样对,计算当前策略的 CFM 损失
- 更新阶段:用 CFM 损失差替代 log-likelihood 差计算 policy ratio,其余与 PPO-clip 完全相同

Figure 1 解读:本图展示了 FPO(蓝色)与 Gaussian PPO(橙色)在 GridWorld 中的对比。左图为 25×25 GridWorld,上下两端为绿色目标区域,红星为 agent。FPO 训练的策略(蓝色箭头)在地图各处都学到了多样化的动作——朝向不同目标的箭头并存,体现了多模态分布的捕获能力。Gaussian PPO 的箭头(蓝色流线图,右侧)则几乎一致朝向最近的目标,表现出单模态的确定性行为,无法覆盖两个目标。
3.2 Policy Gradient 基础与 PPO
标准 policy gradient 目标:
PPO 通过 likelihood ratio clipping 引入 trust region:
其中 likelihood ratio 为:
对于 flow/diffusion model,精确 likelihood 计算不可行。FPO 的目标形式与式 (3) 相同,但将 替换为 :
3.3 Conditional Flow Matching (CFM) 损失回顾
CFM 目标:
其中 是在 flow timestep 下的带噪样本。
对于给定动作 和观测 ,per-sample CFM 损失估计为:
3.4 FPO Ratio 的推导:从 ELBO 到 CFM 损失
关键桥梁: Kingma & Gao (2023) 证明,加权去噪损失 等于 ELBO 的负值加常数:
其中 为时间相关权重函数, 为 log-SNR。对于 diffusion schedule():
因此,定义 ELBO ratio:
等价地分解为:
这个比值同时包含 likelihood ratio 和 KL gap 的逆比,最大化它既鼓励选择高奖励动作,又收紧 ELBO 的近似。
用 CFM 损失代入得到最终估计式(ELBO 关系中常数项 在新旧策略间相消):
单个 对的一步估计:
梯度无偏性证明: 虽然单样本估计上偏(Jensen 不等式),但梯度方向是无偏的:
3.5 Algorithm 1:FPO 完整算法
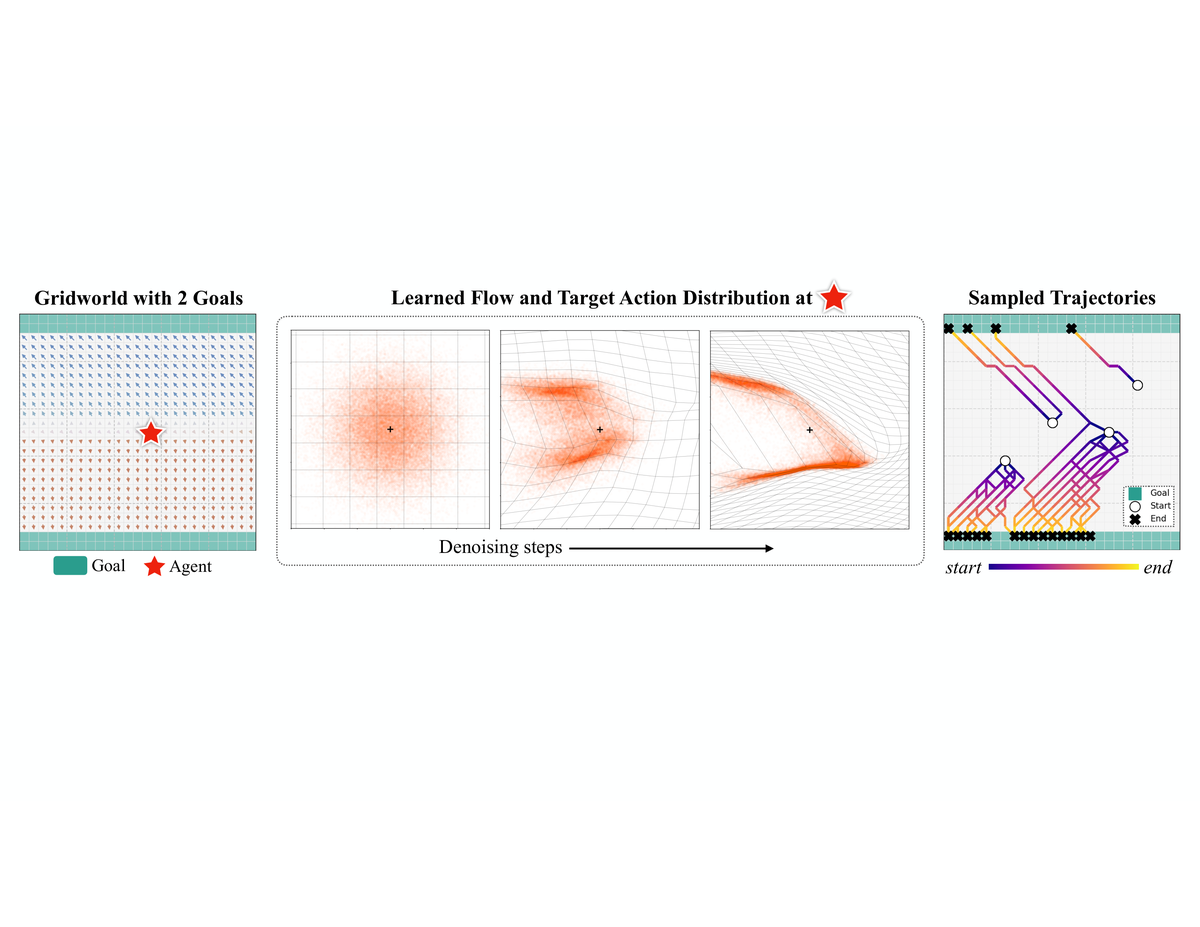
Figure 1 解读:左图展示了 25×25 GridWorld 环境,绿色格子为两个目标区域,红星为 agent 位置,箭头展示 FPO 策略在每个格子处的去噪动作(条件于不同初始噪声向量)——多个方向的箭头并存,体现多模态。中图可视化了在鞍点(★)处 flow 的去噪过程:初始 Gaussian 分布经过三步 逐渐变形为双峰目标分布,说明 flow 学会了捕获两个等价目标方向。右图展示从相同起始点采样的多条轨迹,agent 实际上分散到了两个不同目标,验证了多模态行为的实现。
FPO 伪代码(对应 Algorithm 1):
def fpo_train(policy_theta, value_phi, clip_eps, N_mc, total_steps):
"""
FPO主训练循环。
policy_theta: flow model (velocity field v_theta)
value_phi: value function critic
clip_eps: PPO clipping epsilon
N_mc: Monte Carlo samples per action
"""
t = 0
while t < total_steps:
# === Phase 1: Rollout ===
trajectories = []
for env_step in range(rollout_length):
obs = env.observe()
# 用任意 flow 积分器采样动作(deterministic/stochastic/higher-order)
action = flow_sample(policy_theta, noise=randn(), obs=obs)
# 存储 N_mc 个 (tau_i, eps_i) 对用于后续损失计算
tau_samples = uniform(0, 1, size=N_mc)
eps_samples = randn(N_mc)
# 计算当前策略的 CFM 损失(存储为 theta_old 的损失)
loss_old = compute_cfm_loss(policy_theta, action, obs, tau_samples, eps_samples)
reward, next_obs, done = env.step(action)
trajectories.append((obs, action, reward, tau_samples, eps_samples, loss_old))
t += 1
# 用 GAE 计算 advantage
advantages = compute_gae(trajectories, value_phi)
theta_old = copy(policy_theta)
# === Phase 2: Policy Update ===
for epoch in range(n_epochs):
for minibatch in sample_minibatches(trajectories):
obs, actions, advs, tau_i, eps_i, loss_old_stored = minibatch
# 重新计算当前策略的 CFM 损失
loss_new = compute_cfm_loss(policy_theta, actions, obs, tau_i, eps_i)
# 计算 FPO ratio(在指数前先 clamp 防止爆炸)
cfm_diff = loss_old_stored - loss_new # shape: [B, N_mc]
cfm_diff = clamp(cfm_diff, -3, 3)
r_fpo = exp(mean(cfm_diff, dim=1)) # shape: [B]
# PPO-clip 目标
L_fpo = min(r_fpo * advs,
clip(r_fpo, 1 - clip_eps, 1 + clip_eps) * advs)
# 反向传播更新
loss = -mean(L_fpo)
optimizer.zero_grad()
loss.backward()
clip_grad_norm_(policy_theta.parameters(), max_norm)
optimizer.step()
# 更新 value function(与标准 PPO 相同)
update_value_function(value_phi, trajectories)3.6 CFM 损失计算组件伪代码
def compute_cfm_loss(policy, action, obs, tau_samples, eps_samples):
"""
计算 per-sample conditional flow matching 损失 (ε-prediction 参数化)。
对应论文 Eq.(7)(8)(9)
"""
losses = []
for tau_i, eps_i in zip(tau_samples, eps_samples):
# 构造带噪动作 a_tau = alpha_tau * a + sigma_tau * eps
alpha_tau, sigma_tau = noise_schedule(tau_i)
a_noisy = alpha_tau * action + sigma_tau * eps_i
# 模型预测噪声 eps_hat(ε-prediction 参数化)
eps_hat = policy.predict_noise(a_noisy, tau_i, obs)
# ε-MSE 损失:||eps_hat - eps||^2
# 等价于 velocity MSE:||v_hat - (a - eps)||^2
loss_i = mse(eps_hat, eps_i)
losses.append(loss_i)
return mean(losses) # 对应 hat{L}_CFM,theta(a_t; o_t)3.7 与 Denoising MDP 方法的对比
| 特性 | FPO | Denoising MDP (DDPO/DPPO) |
|---|---|---|
| Horizon 膨胀 | 无(不扩展 MDP) | × 去噪步数(10-50x) |
| 初始噪声处理 | 黑盒(采样不参与训练) | 作为环境观测输入 |
| 支持的积分器 | 任意(deterministic/stochastic/higher-order) | 仅随机采样 |
| Credit assignment | 标准 RL horizon | 扩展 horizon,更难 |
| 实现复杂度 | 仅需替换 ratio,改动极小 | 需要自定义 sampler 和环境步 |
3.8 关键超参数分析
论文还分析了两个实现细节:
-MSE vs -MSE: 在 Playground 实验中,-MSE(先将 velocity 预测转换为 预测再计算损失)优于 -MSE(直接在 velocity 上计算 MSE)。假设原因是 的尺度与动作尺度无关,有利于 的泛化。
的影响: 更多采样对通常提升性能(降低 ratio 估计方差),但即使 也能有效训练,因为梯度方向是无偏的(式 (20))。
4. Experimental Setup(实验设置)
数据集与环境
| 实验 | 环境 | 规模 |
|---|---|---|
| GridWorld | 25×25 Gymnasium GridWorld | 2D 动作空间 |
| Continuous Control | MuJoCo Playground(10 tasks, DeepMind Control Suite) | 连续动作 |
| Humanoid Control | Isaac Gym PHC,AMASS 动捕数据 | 24 关节 × 6 DoF |
基线方法
- Gaussian PPO:标准对角 Gaussian 策略 + PPO-clip
- DPPO(Ren et al., 2024):Diffusion Policy Policy Optimization,将去噪过程建模为 denoising MDP
评估指标
- MuJoCo Playground:60M 步的 evaluation reward mean ± std(5 seeds)
- Humanoid Control:Success rate(↑)、Alive duration(↑)、MPJPE(↓,Mean Per-Joint Position Error)
训练配置
MuJoCo Playground 超参数:
| 超参数 | 值 |
|---|---|
| 优化器 | Adam |
| 总环境步数 | 60M |
| Batch size | 1024 |
| Updates per batch | 16 |
| Flow timestep 采样数 | 8(最优),实验中也测试 1, 4 |
| 0.05(FPO最优);0.2(DPPO最优) | |
| Learning rate | 3e-4 |
| Policy network | MLP(4 hidden layers, 32 units) |
| Value network | MLP(5 hidden layers, 256 units) |
| Number of environments | 2048 |
Humanoid Control 超参数(Table A.3):
| 超参数 | 值 |
|---|---|
| Hidden size | 512 |
| Batch size | 131072 |
| Minibatch size | 32768 |
| Learning rate | 1e-4 |
| GAE lambda | 0.2 |
| Discount factor | 0.98 |
| Clipping coefficient | 0.01 |
| Number of environments | 4096 |
5. Experimental Results(实验结果)
5.1 MuJoCo Playground:FPO vs. Gaussian PPO

Figure 2 解读:10 个 DeepMind Control Suite 任务上,FPO(蓝色)与 Gaussian PPO(橙色)的学习曲线对比(60M 步,5 seeds)。FPO 在 10 个任务中的 8 个取得更高的最终 evaluation reward,在 BallInCup、CheetahRun、FingerSpin、FingerTurnEasy/Hard 等任务上优势明显。Gaussian PPO 在 CartpoleBalance 等简单任务上接近 FPO。

Figure 3 解读:FPO(蓝色)与 DPPO(粉色)在同样 10 个任务上的对比。FPO 相比 DPPO 优势更为突出,在 BallInCup、CheetahRun、PointMass 等任务上 FPO 明显领先。DPPO 在部分任务(如 CartpoleBalance、ReacherEasy)中接近 FPO。
Table 1:FPO 消融实验(MuJoCo Playground 平均奖励)
| 方法 | 平均奖励 |
|---|---|
| Gaussian PPO | 667.8 ± 66.0 |
| Gaussian PPO†(默认超参) | 577.2 ± 74.4 |
| DPPO | 652.5 ± 83.7 |
| FPO(8 对,-MSE,=0.05) | 759.3 ± 45.3 |
| FPO, 1 | 691.6 ± 50.3 |
| FPO, 4 | 731.2 ± 58.2 |
| FPO, -MSE | 664.6 ± 48.5 |
| FPO, =0.1 | 623.3 ± 76.3 |
| FPO, =0.2 | 526.4 ± 76.8 |
关键消融发现:
- 采样数很重要:从 1 增加到 8 对提升平均奖励有显著帮助(691 → 759),但即使 也优于所有 baseline
- -MSE 优于 -MSE:假设原因是 尺度与动作尺度无关, 更容易迁移
- Clipping 的选择至关重要:FPO 最优为 0.05,比 Gaussian PPO 的最优值(0.1)更小
5.2 Humanoid Control

Figure 4 解读:左侧曲线图(a)展示了在不同 goal conditioning 强度下 FPO 与 Gaussian PPO 的训练曲线。全关节条件(All joints)下二者性能接近,但在欠条件设置(Root-only、Root+Hands)下 FPO 明显优于 Gaussian PPO。图(b)Root+Hands 条件的可视化:FPO(蓝色)能准确跟踪参考动作(灰色),Gaussian PPO(橙色)发生漂移倒地。图(c)展示 FPO 在随机地形上稳定行走,为 sim-to-real 迁移提供可能。
Table 2:Humanoid Control 定量结果
| 方法 | Goal Conditioning | Success Rate ↑ | Alive Duration ↑ | MPJPE ↓ |
|---|---|---|---|---|
| Gaussian PPO | All joints | 98.7% | 200.46 | 31.62 |
| FPO | All joints | 96.4% | 198.00 | 41.98 |
| Gaussian PPO | Root + Hands | 46.5% | 142.50 | 95.65 |
| FPO | Root + Hands | 70.6% | 171.32 | 62.91 |
| Gaussian PPO | Root | 29.8% | 114.06 | 123.70 |
| FPO | Root | 54.3% | 152.90 | 73.55 |
发现: 全关节条件下 Gaussian PPO 略好(因为完整信息足以确定唯一动作,Gaussian 已足够);欠条件(Root-only 最难)时 FPO 大幅领先,体现了 flow-based policy 在稀疏目标下捕捉合理多模态分布的优势。
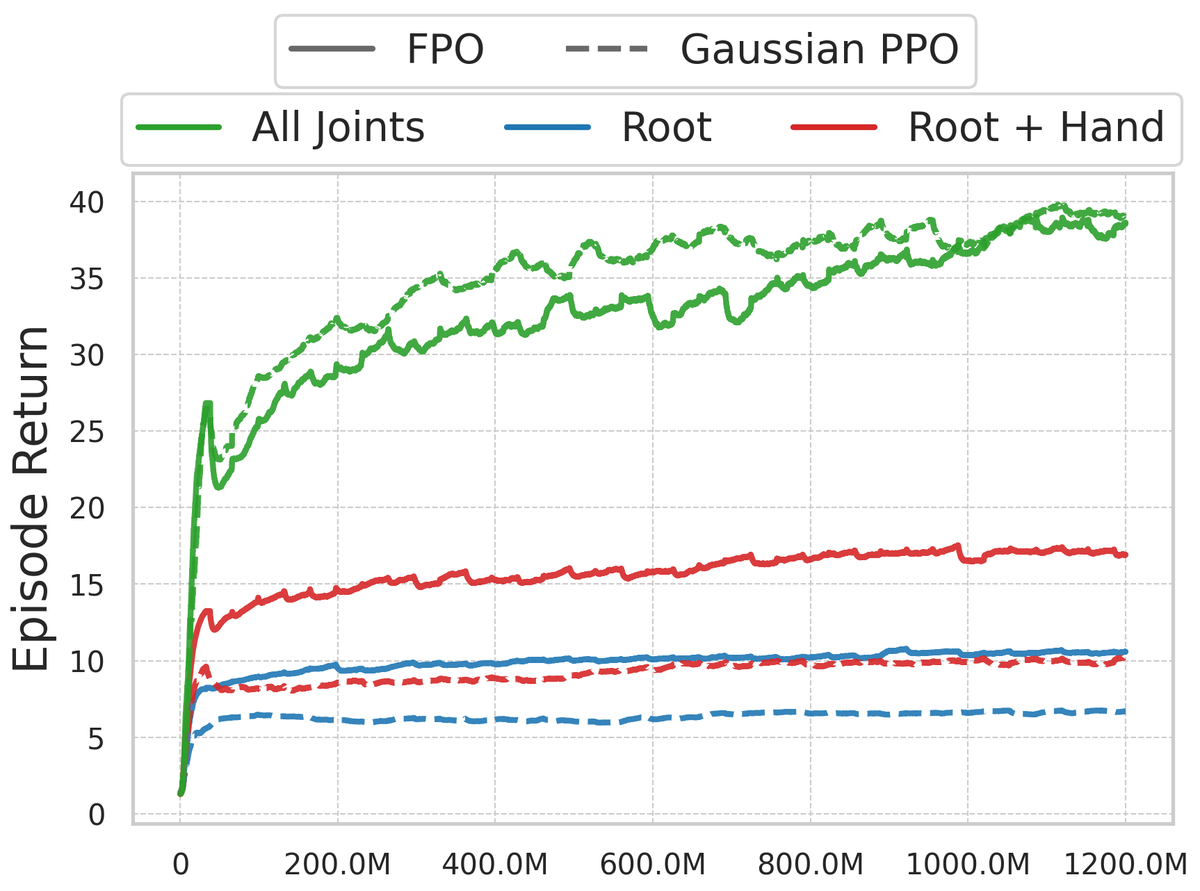
Figure 解读:此图展示了不同方法在 MuJoCo Playground 任务上的平均 episode return 对比柱状图。FPO(深蓝色)明显高于 Gaussian PPO 和 DPPO,确认了 Table 1 的定量结论。
5.3 局限性
- 计算开销更大:Flow-based policy 的采样和训练比 Gaussian policy 更昂贵(需要多步去噪 + 次损失计算)
- 缺乏自适应学习率机制:PPO 有 KL 散度监控来自适应调整学习率,FPO 尚缺乏等价工具(FPO ratio 不是精确 likelihood ratio)
- 图像生成微调不稳定:在 JPEG 压缩奖励的图像生成微调实验中,FPO 训练不稳定(受 classifier-free guidance 对自生成数据的 compounding 效应影响),被作为负面结果报告
- 更敏感:FPO 的 clipping 参数比 Gaussian PPO 更敏感,需要仔细调节
5.4 总体结论
FPO 提供了一个简单、灵活的框架将 flow-based 生成模型纳入 policy gradient 训练,在连续控制任务上超越 Gaussian PPO 和 DPPO。最大优势体现在欠条件设置下,flow-based policy 的多模态建模能力使其在 Gaussian policy 彻底失败时仍能学习到有效行为。FPO 保留了 flow model 所有的推理灵活性(任意积分器、步数),是一个真正的”drop-in replacement”。
代码到论文的映射表
| 论文概念 | 文件路径 | 类/函数 |
|---|---|---|
| FPO ratio 计算 | gridworld/models/fpo.py | learn() 中 cfm_difference, rho_s |
| CFM 损失 | gridworld/models/fpo.py | compute_cfm_loss() |
| PPO-clip 目标 | gridworld/models/fpo.py | learn() 中 L_fpo |
| Rollout 采样(存储 ) | gridworld/models/fpo.py | rollout(), FpoActionInfo dataclass |
| Flow model actor | gridworld/models/diffusion_policy.py | DiffusionPolicy |
| JAX Playground 实现(FPO ratio) | playground/src/flow_policy/fpo.py | training_step() 中 rho_s = exp(initial_loss - current_loss) |
| JAX Playground Rollout | playground/src/flow_policy/rollouts.py | rollout 逻辑 |
| Policy/Value 网络定义 | gridworld/models/network.py | MLP 网络结构 |
| 数学工具 | playground/src/flow_policy/math_utils.py | noise schedule, log-SNR 计算 |
| GridWorld 训练入口 | gridworld/main.py | 主训练脚本 |
| Playground FPO 训练 | playground/train_fpo.ipynb | Jupyter Notebook |
Sources: