OpenClaw-RL: Train Any Agent Simply by Talking
Paper: arXiv:2603.10165 Code: Gen-Verse/OpenClaw-RL Code reference:
main@ffdebf1d(2026-05-11)
1. Motivation (研究动机)
现有 agentic RL 通常把交互轨迹当作离线数据或只在 episode 结束后使用 outcome reward:用户改口、工具报错、GUI 状态变化、terminal stdout/stderr、测试结果等“下一状态”虽然包含强反馈,却没有被系统性地转成实时训练信号。对个人 agent 来说,这导致模型不能在真实使用中连续学习用户偏好;对 terminal/GUI/SWE/tool-call 等通用 agent 来说,长 horizon 任务的大部分中间步骤没有梯度监督。
本文要解决的具体问题是:如何让一个正在服务请求的 agent,在不阻塞推理的前提下,从每一步 action 后的 next state 同时提取“这个动作好不好”的 evaluative signal 和“应该怎么改”的 directive signal,并把二者合并成稳定的在线 RL 更新。OpenClaw-RL 把 RL server 做成 inference API,用户本地或云端 agent 只需继续调用 API 并回传交互数据;PRM/judge 与训练器异步运行,使模型可以“边被使用、边被训练”。
这个问题值得做,因为它把 agent 的真实使用流从日志变成训练数据源:个人 agent 可以通过普通对话学会用户写作风格、TA/teacher 反馈方式;通用 agent 可以在 terminal、GUI、SWE、tool-call 环境中用 step-wise process reward 缓解 sparse outcome reward 的信用分配问题。
2. Idea (核心思想)
核心洞察:每个 agent action 后的 next state 都是一个统一接口,它既可以被 PRM 判成标量奖励,也可以被压缩成 hindsight hint 来构造 teacher distribution。也就是说,用户回复、工具返回、GUI diff、测试日志不是互不相干的 modality,而是同一种“下一状态监督”。
关键创新有三点:第一,系统层面将 serving、rollout collection、PRM/judge、policy training 拆成四个异步组件,避免在线训练阻塞用户使用;第二,方法层面提出 Hybrid RL,把 binary/process reward 的 sequence-level 优势和 Hindsight-Guided OPD 的 token-level 优势放在同一次 policy update 里;第三,为了让 OPD 稳定,使用 top- vocabulary overlap 选择 hint,并对 teacher/student log-prob gap 做 clipping。
与标准 RLVR/GRPO 的差别是:GRPO 主要消费可验证 outcome 或标量 reward,而 OpenClaw-RL 还从 next state 中抽取 directive hint,形成 token-level distillation advantage。与纯 OPD 的差别是:纯 OPD 只在有可用 hint 的 turn 上工作,OpenClaw-RL 同时保留每个 scored turn 的 evaluative signal,因此覆盖更密、稳定性更强。

Figure 2 解读:图中用 student、TA、teacher 三类个人 OpenClaw 场景展示“通过使用而优化”的效果。模型初始回答会暴露 AI 化格式、反馈不够具体或不符合教师偏好;经过若干真实/模拟会话后,输出模式向用户偏好移动,说明 next-state feedback 不只是评价信号,也能携带个性化目标。
3. Method (方法)
3.1 异步系统框架

Figure 1 解读:OpenClaw-RL 的基础设施分成 personal agents 与 general agents 两条输入流。个人 agent 运行在用户设备上,经由 HTTP/API 将 conversation next state 回传;通用 agent 环境运行在云端,覆盖 terminal、GUI、SWE、tool-call 等高并发场景。RL server 侧同时有 policy actor、policy server、PRM actor/PRM server,使 inference、judging、training 解耦。
直觉上,这个架构把 agent runtime 和 RL trainer 之间的边界压缩到“completion API + next-state stream”。只要某个 agent 能调用模型 API,并能把 action 后看到的状态发回服务器,就不需要为每种 agent 写一套训练管线;这也是论文能同时覆盖个人 OpenClaw 和大规模通用 agent 环境的原因。
3.2 Next-state signal:evaluative + directive

Figure 3 解读:左侧 binary reward 从用户/环境反馈中抽取“good or not”;中间 OPD 从 next state 中提取 hint,构造 hint-augmented teacher;右侧 general agentic RL 将 outcome reward 与 PRM step-wise reward 相加并标准化。图中强调三种训练信号可以进入同一个 online update,而不是分成独立任务。
给定 action 与下一状态 ,PRM 被查询 次,每次返回 中的 vote,取多数作为:
如果 包含有意义的 correction,PRM 还抽取 hint ,拼到原始 prompt 上得到 ,再用同一模型在 hint-augmented prompt 下得到 teacher distribution 。evaluative signal 稠密但只有一个标量;directive signal 稀疏但能给每个 token 一个方向性优势。
Hybrid objective 对第 个 token 使用:
默认 。personal setting 的实际 launch script openclaw-combine/run_qwen3_4b_openclaw_topk_select.sh 也设置 OPENCLAW_TOPK_W_RL=1.0、OPENCLAW_TOPK_W_OPD=1.0。
3.3 Overlap-guided hint selection 与 clipped top- OPD
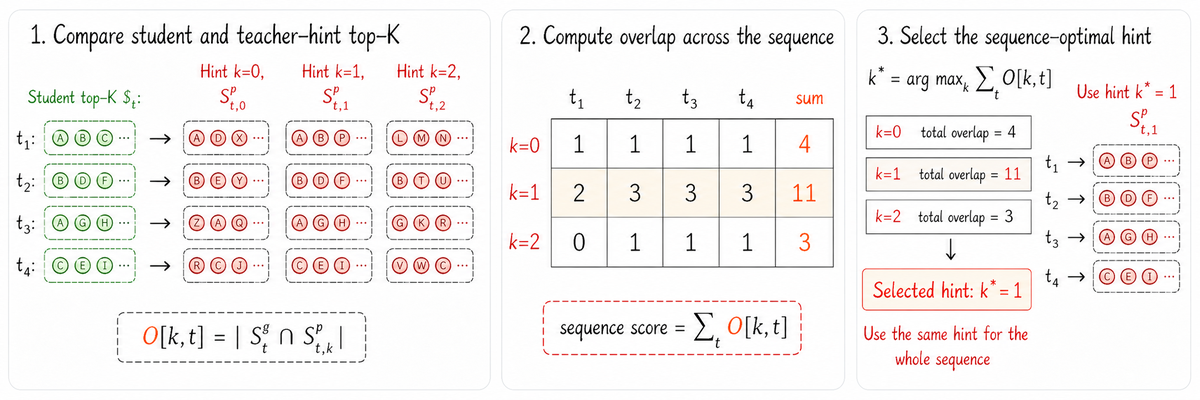
Figure 4 解读:PRM 可能为同一个 next state 生成多个 candidate hints。图中方法不是选最长或最自信的 hint,而是比较 student top- vocabulary 与每个 hint-conditioned teacher top- vocabulary 的重叠,选择让 teacher/student 分布最接近的 hint,从而降低 off-policy distillation 的不稳定性。
令 student 在 token position 的 top- vocabulary 为
hint 对应 teacher 的 top- vocabulary 为
重叠分数为
sequence-level 选择 ;token-level 选择 。选定 后,在 上计算 clipped log-prob gap:
再用 per-vocab ratio 构造 PPO-style surrogate:
personal setting 用 、、每样本 个 hint;general hybrid extension 用 、、 个 hint。
3.4 General agent 的 step-wise process reward
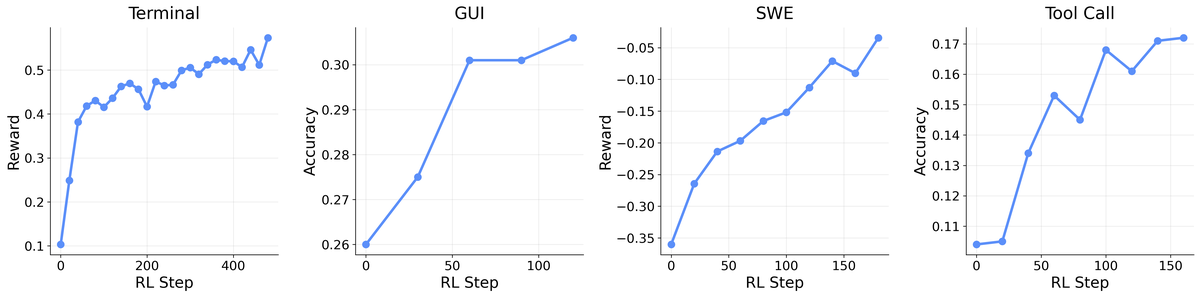
Figure 5 解读:四个子图对应 terminal、GUI、SWE、tool-call。它们的 next state 表现形式不同:terminal 是 stdout/stderr/exit code,GUI 是屏幕状态与 accessibility tree,SWE 是 patch/test/lint 结果,tool-call 是 API return/error。OpenClaw-RL 将它们统一成 PRM 可评分的 step-level evidence。
长 horizon agent 只用 terminal outcome reward 会让中间动作没有监督。论文沿用 RLAnything 的做法,把 verifiable outcome 和 次 PRM step-wise reward 相加:
其中 来自 。真实环境中状态难以聚类,论文改用相同步数 index 的 actions 做 standardization。
3.5 PyTorch-style pseudocode
import torch
import torch.nn.functional as F
def extract_next_state_signals(prm, action_text, next_state, m=3, hint_m=3):
votes, hints = [], []
for _ in range(m):
vote = prm.vote(action_text, next_state) # +1, -1, or 0
votes.append(vote)
reward = torch.mode(torch.tensor(votes)).values.item()
for _ in range(hint_m):
hint = prm.extract_hint(action_text, next_state) # None if no correction
if hint is not None:
hints.append(hint)
return reward, hintsdef choose_hint_by_overlap(old_logits, teacher_logits_by_hint, k=4, mode="sequence_optimal"):
student_topk = old_logits.topk(k, dim=-1).indices # [T, k]
teacher_topk = [logits.topk(k, dim=-1).indices for logits in teacher_logits_by_hint]
overlap = torch.stack([
(student_topk[:, :, None] == t[:, None, :]).any(dim=-1).sum(dim=-1)
for t in teacher_topk
]) # [H, T]
if mode == "token_optimal":
return overlap.argmax(dim=0) # one hint per token
return overlap.sum(dim=-1).argmax().expand(old_logits.size(0))def topk_opd_loss(old_logp, cur_logp, teacher_logp, subset_idx, c=1.0, eps_lo=0.2, eps_hi=0.28):
old_s = old_logp.gather(-1, subset_idx)
cur_s = cur_logp.gather(-1, subset_idx)
tea_s = teacher_logp.gather(-1, subset_idx)
w = F.softmax(old_s.detach(), dim=-1)
delta = (tea_s.detach() - old_s.detach()).clamp(-c, c)
adv = delta * w
rho = (cur_s - old_s.detach()).exp()
clipped = rho.clamp(1 - eps_lo, 1 + eps_hi)
return torch.maximum(-adv * rho, -adv * clipped).sum(dim=-1).mean()def hybrid_train_step(batch, policy, optimizer, w_rl=1.0, w_opd=1.0):
logits = policy(batch.prompt, batch.response)
grpo = clipped_grpo_loss(logits, batch.old_logp, batch.reward_advantage)
opd = topk_opd_loss(batch.old_logp, logits.log_softmax(-1), batch.teacher_logp, batch.topk_idx)
loss = w_rl * grpo + w_opd * opd
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
return {"loss": float(loss.detach()), "grpo": float(grpo.detach()), "opd": float(opd.detach())}def async_online_pipeline(clients, policy_server, prm_server, trainer, buffer, min_samples=16):
while policy_server.running:
state, action, next_state = clients.recv_turn()
reward, hints = prm_server.extract_async(action, next_state)
buffer.add({"state": state, "action": action, "reward": reward, "hints": hints})
if len(buffer) >= min_samples:
batch = buffer.freeze_with_old_policy(policy_server.policy)
trainer.update(batch)
policy_server.sync_weights(trainer.policy)
buffer.clear()3.6 Code-to-paper mapping
Code reference:
main@ffdebf1d(2026-05-11) — pseudocode and mapping based on this commit
| Paper concept | Source mapping | What to check |
|---|---|---|
| Async OpenClaw combine rollout | openclaw-combine/openclaw_combine_select_rollout.py | generate_rollout_openclaw_combine_select drains OpenClaw sessions into training samples. |
| PRM evaluative/directive extraction | openclaw-combine/openclaw_combine_select_api_server.py | _opd_evaluate queries PRM votes, builds hint candidates, records teacher_tokens_candidates. |
| Hybrid GRPO + OPD loss | openclaw-combine/openclaw_topk_select_loss.py | openclaw_topk_select_loss_function dispatches subset/hint selection and combines GRPO/OPD. |
| Hint selection kernel | openclaw-combine/hint_opd_select_loss.py | _select_k_star_per_token implements shortest/token-optimal/sequence-optimal. |
| Binary RL baseline | openclaw-rl/openclaw_api_server.py | reward_func returns scalar score from PRM vote. |
| Token-level OPD baseline | openclaw-opd/topk_distillation_loss.py | topk_distillation_loss_function handles pure OPD path. |
| General terminal RL | terminal-rl/terminal-rl_qwen3-8b_prm_2nodes.sh | launch config: batch 16, 8 samples, max response 8192, context 16384, LR 1e-6. |
| General GUI/tool-call RL | gui-rl/gui_qwen3vl_8b_prm_rl.sh; toolcall-rl/retool_qwen3_4b_prm_rl.sh | launch configs expose PRM step reward, KL 0.01, PPO clip 0.2/0.28. |
训练配置出处:personal combine 的实际脚本是 openclaw-combine/run_qwen3_4b_openclaw_topk_select.sh,其中 NUM_GPUS=8、ACTOR_GPUS=4、ROLLOUT_GPUS=2、PRM_GPUS=1、PRM_TEACHER_GPUS=1;rollout-batch-size=16、n-samples-per-prompt=1、rollout-max-response-len=8192、rollout-max-context-len=32768、rollout-temperature=0.6;custom loss 为 openclaw_topk_select_loss.openclaw_topk_select_loss_function;distill-topk=4、hint-m=3、hint-selection=sequence_optimal、eps-clip=0.2、eps-clip-high=0.28、lr=1e-5。论文公式与 released code 实现差异:未发现核心 Hybrid/OPD 公式与 openclaw-combine/openclaw_topk_select_loss.py、openclaw-combine/hint_opd_select_loss.py 的实现冲突;但 repo 中存在工程化分支差异:README 提到若干 SWE launch scripts,当前 commit 下 swe-rl/scripts/ 只看到 4B colocate/eval 脚本,未见 README 中列出的 32B/8B remote scripts;GUI PRM 脚本的 rollout-max-response-len=1024 也低于论文 Table 6 的 8192。
4. Experimental Setup (实验设置)
Personal agent 设置:用 Qwen3-32B 模拟 student、TA、teacher 三类用户,每个 session 中用户让 OpenClaw 完成一个从 GSM8K 抽取的任务;首条消息固定且不暴露偏好,若模型连续 3 个 session 的首轮响应满足偏好,则认为优化成功。每个设置默认最多 72 个 conversation sessions,报告 5 次独立试验均值。策略/PRM 使用 Qwen3-4B-Thinking-2507;训练配置为 、、、每样本 3 个 hints、学习率 、每收集 16 个 samples 触发异步训练;硬件拆分为 policy actor 4 GPUs、policy server 2 GPUs、PRM actor 1 GPU、PRM server 1 GPU。
General agent 设置:terminal、GUI、SWE、tool-call 四类环境分别提供 stdout/stderr/exit code、screen/accessibility tree、repo/test/lint、API return/error 等 next state。论文报告大规模并行环境数为 terminal 128、GUI 64、SWE 64、tool-call 32;每步采样 GUI/SWE 8 个任务、terminal 16 个任务、tool-call 32 个任务,每个任务 8 个 rollouts;最大交互步数 GUI 30、SWE 20、terminal 10。Table 6 的通用超参包括 LR 、weight decay 0.1、Adam 、KL coefficient 0.01、PPO clip 、entropy 0、max response 8192、max context 16384、temperature 1.0、PRM votes for GUI and for others、PRM temperature 0.6。
Hybrid RL extension 设置:tool-call 使用 Retool-4B(Retool dataset SFT)作为 policy、Qwen3-8B 作为 PRM;RLVR 使用 DeepSeek-R1-Distill-Qwen-1.5B 作为 policy、Qwen3-4B 作为 PRM,在 DAPO 上训练、AIME 上评估。该扩展设置使用 LR 、KL 0.01、log-prob gap clip 、PPO clip 、每步 32 tasks、每 task 8 rollouts、response length 8192、context length 32768、sampling temperature 0.6。
Baselines 与指标:personal agent 比较 Hybrid RL、GRPO、OPD、Mem0、Cognee;指标是达到优化效果所需的最少 sessions,数值越小越好。general process reward 比较 PRM + Outcome 与 Outcome;指标是环境任务 accuracy。消融实验比较 random/sequence-optimal/token-optimal hint selection、不同 、不同 support set 、不同 PRM teacher model,并观察 response length/truncation ratio 作为稳定性指标。
5. Experimental Results (实验结果)
5.1 Personal OpenClaw 优化效率
Table 3 的核心结论是:在 Qwen3-4B-Thinking-2507 上,Hybrid RL 需要的会话数最低;joint optimization 平均 10.3 sessions,separate optimization 平均 15.0 sessions。具体数值如下(越小越好):
| Setting | Hybrid joint | GRPO joint | OPD joint | Mem0 joint | Cognee joint | Hybrid separate | GRPO separate | OPD separate | Mem0 separate | Cognee separate |
|---|---|---|---|---|---|---|---|---|---|---|
| Student | 11.6 | 15.4 | 30.8 | 13.6 | 14.6 | 19.2 | 22.8 | 34.6 | 13.4 | 15.6 |
| TA | 8.2 | 12.0 | 34.0 | 15.8 | 15.4 | 11.8 | 22.4 | 36.0 | 16.0 | 14.8 |
| Teacher | 11.4 | 14.8 | 24.4 | 14.2 | 14.8 | 14.0 | 18.0 | 17.6 | 15.8 | 15.0 |
| Average | 10.3 | 14.1 | 29.7 | 14.5 | 14.9 | 15.0 | 21.1 | 29.4 | 15.1 | 15.1 |
这个结果说明:OPD 单独使用时虽然信息密度高,但 hint 稀疏且不稳定,平均需要 29.7/29.4 sessions;GRPO 单独使用更密集但信息量低;Hybrid RL 同时使用二者,joint setting 下比 GRPO 平均少 3.8 sessions,比 OPD 少 19.4 sessions。
5.2 General agent 与 process reward

Figure 6 解读:左图是 ReTool multi-turn RL,右图是 RLVR。Hybrid/PRM+Outcome 曲线相比 outcome-only 更快上升,说明 step-wise next-state reward 能在长 horizon 任务中提供 outcome reward 缺失的中间监督。
论文在 tool-call 250 steps 和 GUI 120 steps 上比较 outcome-only 与 integrated reward。PRM + Outcome 在 tool-call/GUI 上分别达到 0.25/0.33,而 outcome-only 为 0.19/0.31。提升幅度在 tool-call 更明显,因为 tool-call 的中间 API return/error 对下一步决策有直接诊断价值。
5.3 Hint selection 与 的消融

Figure 7 解读:random hint selection 带来明显不稳定;sequence-optimal 与 token-optimal 都比 random 好。右侧 log-prob difference 分布显示,hint-conditioned teacher 与 rollout student 在某些 token 上可能产生极端 gap,这解释了为什么必须用 overlap 选择和 clipping。
Table 4 在 Qwen3-32B 上比较不同方法(越小越好):sequence-optimal、token-optimal、random、GRPO、OPD 的平均 sessions 分别是 12.5、12.4、16.1、15.8、29.9。sequence-optimal 与 token-optimal 明显优于 random/GRPO/OPD,但更大 policy 不保证比 Qwen3-4B 的主实验更快优化。
Table 5 显示 的收益主要发生在 :student top- support 下,平均 sessions 从 的 20.2 降到 的 10.3;继续增大到 和 只到 10.1/9.8,收益很小。退化的 token-level OPD 平均 31.0,明显变差;使用 overlap support set 时 平均 13.5,较 student top- 的 10.3 略差但更高效。
5.4 Stability 与 PRM model 消融

Figure 8 解读:不做 log-prob gap clipping 时,response length 会持续增长,因为过长输出没有被 outcome reward 充分惩罚;最终 clipping/non-clipping 的 truncation ratio 分别是 0.2/0.5。这个图直接支撑论文的稳定性设计:不能只相信 hint teacher,必须限制 token-level advantage 的极端值。
PRM teacher model 消融(Table 7)表明 Qwen3-8B 与 Qwen3-4B-Thinking-2507 的效果接近:student 13.6 vs 14.0、TA 9.2 vs 9.6、teacher 14.2 vs 13.8。这说明方法不完全依赖更大的 PRM;PRM 资源是工程成本,但不是唯一性能瓶颈。
5.5 结论与限制
OpenClaw-RL 证明了 next-state signal 可以作为统一在线 RL 接口:personal agent 中,Hybrid RL 在 joint setting 平均 10.3 sessions 达到偏好优化;general agent 中,process reward 在 tool-call/GUI 上提升 accuracy。最重要的技术点不是单个 loss,而是“异步系统 + 双信号提取 + overlap-guided OPD + log-prob clipping”的组合。
作者明确提到的主要 trade-off 是 PRM hosting 需要额外资源;实验也显示 random hint selection 和无 clipping 都会导致训练不稳定。另一个阅读时需要注意的边界是 personal agent 实验使用 LLM-simulated users 与 GSM8K-derived tasks,虽然适合可控评估,但仍不等同于大规模真实用户流量。