MetaClaw: Just Talk — An Agent That Meta-Learns and Evolves in the Wild
Paper: arXiv:2603.17187 Code: aiming-lab/MetaClaw Code reference:
main@fc163ba8(2026-04-11)
1. Motivation (研究动机)
现有 LLM agent 在真实部署里最大的错位不是“单题能力不够”,而是服务中的任务分布持续漂移,agent 本身却基本静态。以 OpenClaw 这类连接 20+ messaging channels 的 CLI agent 为例,用户工作流可能从文件系统操作切到多 agent 消息编排;冻结模型会在低频规则、项目习惯、文件副作用、schema 约束上重复犯错。
现有适应方法各自只覆盖一半问题:memory 方法保留原始轨迹,但冗长且难以抽取可迁移行为模式;skill 方法把经验压缩成可复用指令,但通常只是静态 skill library,不和权重优化闭环;RL 方法能更新权重,但多在离线或小规模设置里运行,而且忽视技能进化后旧轨迹 reward 已经“过期”的数据有效性问题。MetaClaw 要解决的具体目标是:让部署中的个人/CLI agent 在不中断服务的前提下,把失败会话转化为可立即生效的 skills,并在用户空闲窗口中用 post-adaptation 轨迹更新模型权重。
这个问题值得研究,因为它把 agent 从“每次任务独立求解”推进到“越用越会适应”。如果该机制成立,用户不需要本地 GPU 或离线重训流程,agent 也能从日常真实使用中累积行为知识,并在后续任务中减少重复错误。这与 OpenClaw-RL - Train Any Agent Simply by Talking 的“从对话训练 agent”方向相邻,但 MetaClaw 更强调 skill evolution、support/query separation 与 idle-window scheduling 组成的连续 meta-learning 系统。
2. Idea (核心思想)
核心 insight:MetaClaw 把部署中 agent 的适应拆成两个天然互补的时间尺度——秒级的自然语言 skill 更新和分钟到小时级的 LoRA/RL 权重更新。前者把失败轨迹蒸馏成可立即注入 prompt 的行为规则,后者只用 skill 生效后的 query trajectories 去更新 base policy,使模型学会在已有 skill library 的帮助下执行得更稳。
关键创新不是简单叠加“memory + skills + RL”,而是把 agent 的 meta-model 定义为 ,其中 是 LLM policy 权重, 是随失败积累而扩展的 skill library。MetaClaw 用 skill generation versioning 防止 support data 泄漏进 RL buffer;再用 OMLS(Opportunistic Meta-Learning Scheduler)把权重更新推迟到 sleep、keyboard idle 或 calendar busy 的窗口,避免 active serving 时热切换造成用户体验下降。
与 Reflexion/Expel 这类 memory/skill-only adaptation 相比,MetaClaw 不只把失败写进外部记忆,而是进一步让权重通过 PRM/GRPO-style 信号适应 post-skill 行为;与常规 online RL 相比,它不把旧 skill context 下的失败轨迹直接用于梯度更新,而是显式区分 support/query data,避免优化已经被新 skill 修复的旧错误。
3. Method (方法)
3.1 Overall framework
Figure 1 解读:左侧是 fast loop:agent 处理任务后收集失败轨迹,由 LLM skill evolver 生成新 skills,并立即扩展 ,不改模型权重;右侧是 slow loop:post-adaptation trajectories 进入 RL buffer,OMLS 在用户不活跃窗口触发 cloud LoRA / GRPO-style 更新 。中间的关键约束是 support/query separation:触发 skill evolution 的失败样本只用于更新 ,不会污染后续 RL。
问题设定中,每个任务 包含用户指令和环境上下文(文件系统、shell history 等),agent 行为由 meta-model 决定:
给定当前任务,agent 先检索相关 skills,再由 policy 产生 actions:
这里 有双重角色:作为 meta-parameter,它跨任务流累积行为知识;作为 adaptation basis,它在 inference-time 被检索成任务专用 instruction set。直觉上,这让“一个失败会话”可以被压缩成未来很多任务都能复用的操作偏好,例如“修改文件前先创建 .bak”或“时间必须写 ISO 8601 + timezone”。
3.2 Skill-driven fast adaptation
在 skill generation 下,失败轨迹组成 support set 。Skill evolver 读取当前 skill library 和失败轨迹,输出新的自然语言行为指令:
这个步骤是 gradient-free 的,不是近似梯度下降:skill library 存在于离散自然语言空间,最自然的更新方式是让 LLM 做 failure analysis、总结可执行规则、写成 skill file。由于它只改 prompt 注入内容,新增 skill 对后续任务立即生效,服务不需要暂停。
源码对应实现:metaclaw/api_server.py 会把 session turns 缓存在 _session_turns,达到 skill_evolution_every_n_turns 或 session_done 时异步调用 _evolve_skills_for_session(...);metaclaw/skill_evolver.py 构造 failure-analysis prompt 并调用 evolver LLM;metaclaw/skill_manager.py:add_skills() 将新 skill 写入 SKILL.md 并递增 generation。
3.3 Opportunistic policy optimization
当训练窗口打开时,MetaClaw 用 post-adaptation query trajectories 更新 :
其中 是 process reward model (PRM), 表示样本收集时的 skill generation。论文强调:这里优化的不是“raw task performance”,而是“skill adaptation 后的表现”。因此更好的 会产生更有信息量的失败,失败又会让 更强,形成 virtuous cycle。
Released code 中,metaclaw/data_formatter.py:compute_advantages() 对 batch 内 reward 做 GRPO-style normalization:
随后 metaclaw/trainer.py:_train_on_batch() 把 ConversationSample 转为 Tinker Datum,调用 training_client.forward_backward_async(..., loss_fn=config.loss_fn) 与 optim_step_async(AdamParams(learning_rate=config.learning_rate)),再 save_weights_and_get_sampling_client_async(name="openclaw_lora") 热切换 sampling client。
3.4 Skill generation versioning:防止 stale reward contamination
每条 trajectory 收集时带有 skill_generation。如果轨迹 触发 ,它的 reward 反映的是旧 skill context 下的失败;若把它放进 RL buffer,梯度会惩罚 一个已经由 skill 更新修复的问题。因此 MetaClaw 做两件事:
- support set :触发 skill evolution 的失败轨迹,只给 evolver,总结完后不进入 RL buffer;
- query set :新 skill 生效后的轨迹,才允许进入 policy optimization。
源码中 ConversationSample.skill_generation 在 metaclaw/data_formatter.py 定义,metaclaw/api_server.py 提交样本时读取当前 self.skill_manager.generation 打戳;metaclaw/trainer.py 在 _drain_with_pause_check()、train_step_external() 和 pending-batch carryover 处过滤低于当前 generation 的样本;当 SkillManager.add_skills() 递增 generation 后,trainer 清空 _pending_batch 并调用 rollout_worker.clear_output_queue() 丢弃旧样本。
3.5 Opportunistic Meta-Learning Scheduler (OMLS)
OMLS 解决 slow loop 的服务可用性问题。论文设定三类 idle signal:用户配置 sleep window(如 23:00—07:00)、系统键鼠 idle 超过 分钟(默认 30)、Google Calendar 正在会议中。任一条件满足时打开训练窗口;用户返回时窗口关闭,trainer 通过 checkpoint/pending batch 机制暂停并等待下一个窗口。
源码对应 metaclaw/scheduler.py:SlowUpdateScheduler:状态机从 IDLE_WAIT 到 WINDOW_OPEN,trainer 确认后进入 UPDATING;如果窗口关闭则进入 PAUSING 并设置 pause_event。metaclaw/idle_detector.py 负责 macOS ioreg HIDIdleTime / Linux xprintidle / proxy activity fallback,metaclaw/calendar_client.py 负责 Google Calendar v3 readonly 查询。
3.6 PyTorch-style pseudocode(基于 released code)
Code reference:
main@fc163ba8(2026-04-11) — pseudocode and mapping based on this commit
Skill retrieval and session-level evolution
from pathlib import Path
import torch
import torch.nn.functional as F
class SkillBank:
def __init__(self, skill_files, embedding_model=None, top_k=6, task_top_k=10):
self.skills = self._load_skill_md(skill_files)
self.generation = 0
self.embedding_model = embedding_model
self.top_k = top_k
self.task_top_k = task_top_k
def retrieve(self, task_text: str):
if self.embedding_model is None:
return keyword_template_retrieve(self.skills, task_text, self.top_k, self.task_top_k)
query = F.normalize(torch.tensor(self.embedding_model.encode(task_text)), dim=-1)
skill_emb = F.normalize(torch.stack([s.embedding for s in self.skills]), dim=-1)
scores = skill_emb @ query
idx = torch.topk(scores, k=min(self.top_k + self.task_top_k, len(self.skills))).indices
return [self.skills[i] for i in idx.tolist()]
def add_skills(self, generated_skills):
added = 0
for skill in generated_skills:
if not self._is_duplicate(skill):
self._write_skill_md(Path(skill["name"]) / "SKILL.md", skill)
self.skills.append(skill)
added += 1
if added > 0:
self.generation += 1
return added
async def maybe_evolve_session(session_turns, skill_bank, evolver, every_n: int):
if len(session_turns) < every_n:
return 0
prompt = build_failure_analysis_prompt(session_turns, existing_skills=skill_bank.skills)
new_skills = await evolver.generate(prompt)
return skill_bank.add_skills(new_skills)Support/query separation with skill_generation stamping
from dataclasses import dataclass
@dataclass
class ConversationSample:
prompt_tokens: list[int]
response_tokens: list[int]
reward: float
loss_mask: list[int]
skill_generation: int
class FreshSampleBuffer:
def __init__(self, skill_bank):
self.skill_bank = skill_bank
self.pending = []
self.queue = []
self.current_generation = skill_bank.generation
def submit_turn(self, prompt_ids, response_ids, reward, exclude=False):
sample = ConversationSample(
prompt_tokens=prompt_ids,
response_tokens=response_ids,
reward=reward,
loss_mask=[0 if exclude else 1] * len(response_ids),
skill_generation=self.skill_bank.generation,
)
if not exclude:
self.queue.append(sample)
def on_skill_generation_bumped(self):
self.current_generation = self.skill_bank.generation
self.pending.clear()
self.queue = [s for s in self.queue if s.skill_generation >= self.current_generation]
def drain_fresh_batch(self, batch_size: int):
fresh = [s for s in self.pending + self.queue if s.skill_generation >= self.current_generation]
batch, rest = fresh[:batch_size], fresh[batch_size:]
self.pending, self.queue = [], rest
return batchGRPO-style LoRA update and hot swap
import torch
def grpo_advantages(rewards: torch.Tensor, eps: float = 1e-8):
return (rewards - rewards.mean()) / (rewards.std(unbiased=False) + eps)
async def train_on_batch(training_client, rollout_worker, batch, config, step_idx: int):
rewards = torch.tensor([s.reward for s in batch], dtype=torch.float32)
advantages = grpo_advantages(rewards)
datums = [to_tinker_datum(sample=s, advantage=float(a)) for s, a in zip(batch, advantages)]
await training_client.forward_backward_async(datums, loss_fn=config.loss_fn)
await training_client.optim_step_async(AdamParams(learning_rate=config.learning_rate))
sampling_client = await training_client.save_weights_and_get_sampling_client_async(
name="openclaw_lora"
)
if step_idx % 5 == 0:
await training_client.save_state_async(name=f"step_{step_idx:04d}")
rollout_worker.update_sampling_client(sampling_client)
return {
"mean_reward": float(rewards.mean()),
"success_rate": float((rewards > 0).float().mean()),
}OMLS idle-window gating
import enum
class SchedulerState(enum.Enum):
IDLE_WAIT = "idle_wait"
WINDOW_OPEN = "window_open"
UPDATING = "updating"
PAUSING = "pausing"
class SlowUpdateScheduler:
def __init__(self, config, idle_detector, calendar_client, trigger_event, pause_event):
self.state = SchedulerState.IDLE_WAIT
self.config = config
self.idle_detector = idle_detector
self.calendar_client = calendar_client
self.trigger_event = trigger_event
self.pause_event = pause_event
async def tick(self):
open_now = self.sleep_window_active() or self.system_idle() or await self.calendar_busy()
if self.state is SchedulerState.IDLE_WAIT and open_now:
self.state = SchedulerState.WINDOW_OPEN
self.trigger_event.set()
elif self.state is SchedulerState.WINDOW_OPEN and not open_now:
self.trigger_event.clear()
self.state = SchedulerState.IDLE_WAIT
elif self.state is SchedulerState.UPDATING and not open_now:
self.pause_event.set()
self.state = SchedulerState.PAUSING
def notify_trainer_started(self):
if self.state is SchedulerState.WINDOW_OPEN:
self.state = SchedulerState.UPDATING
def notify_trainer_finished(self):
self.trigger_event.clear()
self.pause_event.clear()
self.state = SchedulerState.IDLE_WAIT3.7 论文公式与 released code 实现差异
论文把 skill-driven fast adaptation 写成“失败轨迹形成 support set,evolver 合成 skills”,但 released code 有两条触发路径:API server 在 skill_evolution_every_n_turns 或 session_done 时按 session turns 调 evolver;trainer 的 _maybe_evolve_skills() 才按 reward⇐0 的 failed samples 触发。因此代码不等价于“每条失败轨迹立即触发一次 evolution”,而是 session/turn/batch 粒度的异步总结。
论文称 policy optimization 使用 GRPO;released code 的 reward normalization 确实是 GRPO-style,但实际传给 Tinker 的 loss 由 config.loss_fn 决定,MetaClawConfig 默认是 "importance_sampling",benchmark rl.yaml 未显式覆盖。因此笔记里的“GRPO-style”指 reward-to-advantage 与 on-policy RL pipeline,而不是源码中手写了完整 GRPO loss。
论文描述 OMLS 包含 sleep、system inactivity、calendar 三个信号;released code 中 calendar 是 optional(scheduler.calendar.enabled 默认 false,需要 credentials/token path),benchmark rl.yaml 还把 scheduler 关掉并使用 manual_train_trigger: true,所以论文实验配置与默认产品 auto mode 的 scheduler 行为不是同一个启动形态。
3.8 Code-to-paper mapping
Code reference:
main@fc163ba8(2026-04-11) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Meta-model serving proxy and trajectory capture | metaclaw/api_server.py | MetaClawAPIServer, _maybe_submit_ready_samples, _evolve_skills_for_session |
| Skill library retrieval and generation counter | metaclaw/skill_manager.py | SkillManager, _embedding_retrieve, add_skills |
| LLM-based skill evolver | metaclaw/skill_evolver.py | SkillEvolver.should_evolve, SkillEvolver.evolve, _build_analysis_prompt |
| Conversation sample + generation stamp | metaclaw/data_formatter.py | ConversationSample.skill_generation, compute_advantages, batch_to_datums |
| Support/query freshness filtering | metaclaw/trainer.py, metaclaw/rollout.py | _drain_with_pause_check, _maybe_evolve_skills, clear_output_queue |
| Cloud LoRA / RL update and hot swap | metaclaw/trainer.py | _train_on_batch, forward_backward_async, save_weights_and_get_sampling_client_async |
| OMLS idle-window scheduling | metaclaw/scheduler.py | SlowUpdateScheduler, _is_window_open, notify_trainer_started/finished |
| Idle/calendar signals | metaclaw/idle_detector.py, metaclaw/calendar_client.py | IdleDetector, GoogleCalendarClient |
| Benchmark RL launch config | benchmark/scripts/config/rl.yaml | manual_train_trigger, batch_size, lora_rank, skills.auto_evolve |
4. Experimental Setup (实验设置)
Benchmarks and scale
- MetaClaw-Bench:共 934 questions、44 simulated workdays;Part I 是 30-workday simulation,346 questions,每天 10—15 题,workspace state 跨 round 持久化,任务包含 file-check 与 multi-choice;Part II 是 14-workday simulation,588 questions,其中 434 multi-choice、154 file-check,每天 42 题,强调 rule-based transformations 与 procedural heuristics。
- AutoResearchClaw:23-stage autonomous research pipeline,从 idea 到 conference-ready paper,覆盖 literature search、hypothesis generation、experiment design、code synthesis、sandbox execution、result analysis、paper drafting、多 agent peer review。论文报告 19 个 scorable stages 的 completion。
Baselines and conditions
MetaClaw-Bench 比较两个 backbone:GPT-5.2 与 Kimi-K2.5。每个模型有 Baseline(无适应)与 MetaClaw (Skills)(skill-driven fast adaptation);MetaClaw (Full) 只在 Kimi-K2.5 上评估,因为 full pipeline 需要目标 backbone 的 cloud LoRA endpoint。AutoResearchClaw 只评估 skills-only adaptation(无 RL),比较 baseline pipeline 与加入 MetaClaw skill injection 后的 pipeline。
Metrics
- Accuracy / Acc.:mean per-question score。
- Completion / Compl.:file-check outputs 同时通过所有 automated checker assertions 的比例。
- Stage retry rate:AutoResearchClaw 每阶段重试比例,越低越好。
- Refine cycle count:每阶段 refinement 循环数量,越低越好。
- Pipeline stage completion:19 个可评分阶段中完成的阶段数。
- Composite robustness score:stage completion rate 40%、retry reduction 30%、refine cycle efficiency 30% 的加权平均。
Training / implementation config(paper + source verified)
论文正文说明 MetaClaw (Full) 对 Kimi-K2.5 使用 5-day training run,通过 PRM + cloud LoRA fine-tuning 完成;但没有给出具体 GPU type/count。released code 与 README 强调无需本地 GPU,训练通过 Tinker-compatible backend(Tinker cloud / MinT / Weaver)运行。
源码中的 benchmark RL 配置来自 benchmark/scripts/config/rl.yaml:mode: rl、proxy port 30000、manual_train_trigger: true、batch_size: 4、lora_rank: 32、skills enabled、auto_evolve: true、top_k: 6、task_specific_top_k: 10、max_context_tokens: 50000、scheduler disabled。TINKER_MODEL、PRM_MODEL、API keys/base URL 由环境变量注入。
默认训练超参来自 metaclaw/config.py 与 README config block:learning_rate=1e-4、max_steps=1000、loss_fn="importance_sampling"、prm_model="gpt-5.2"、prm_m=3、prm_temperature=0.6、prm_max_new_tokens=1024。默认 scheduler 参数是 sleep 23:00--07:00、idle threshold 30 minutes、minimum window 15 minutes、calendar disabled unless explicitly configured。
5. Experimental Results (实验结果)
5.1 Main results on MetaClaw-Bench
| Model | Condition | Part I Acc. (%) | Part I Compl. (%) | Part II Acc. (%) | Part II Compl. (%) |
|---|---|---|---|---|---|
| GPT-5.2 | Baseline | 41.1 | 14.7 | 44.9 | 58.4 |
| GPT-5.2 | MetaClaw (Skills) | 44.0 | 17.1 | 49.1 | 67.5 |
| Kimi-K2.5 | Baseline | 21.4 | 2.0 | 21.1 | 18.2 |
| Kimi-K2.5 | MetaClaw (Skills) | 28.3 | 2.0 | 26.9 | 33.8 |
| Kimi-K2.5 | MetaClaw (Full) | 40.6 | 16.5 | 39.6 | 51.9 |
主要结论:skills-only 对两个模型都稳定提升 accuracy;Kimi-K2.5 的 headroom 更大,Part I accuracy 从 21.4% 到 28.3%(+32.2% relative),Part II 从 21.1% 到 26.9%(+27.5% relative)。Full pipeline 的提升更大:Kimi-K2.5 Part I accuracy 到 40.6%,几乎追平 GPT-5.2 baseline 的 41.1%;Part I completion 从 2.0% 到 16.5%,即 8.25×;Part II completion 从 18.2% 到 51.9%,即 +185% relative。
5.2 AutoResearchClaw transfer
| Metric | Baseline | + MetaClaw (Skills) | Relative Change |
|---|---|---|---|
| Stage retry rate ↓ | 10.5% | 7.9% | ↓ 24.8% |
| Refine cycle count ↓ | 2.0 | 1.2 | ↓ 40.0% |
| Pipeline stage completion ↑ | 18 / 19 | 19 / 19 | ↑ 5.3% |
| Composite robustness score ↑ | 0.714 | 0.845 | ↑ 18.3% |
这个结果说明 MetaClaw 的 skill distillation 不只适用于结构化 CLI benchmark,也能迁移到长链路、开放式 research automation。特别是 refine cycles 减少 40.0%,表明从早期 pipeline failures 提炼出的 rules(如 citation formatting、experiment code validation)能防止后续 run 重复犯错。
5.3 Analysis figures
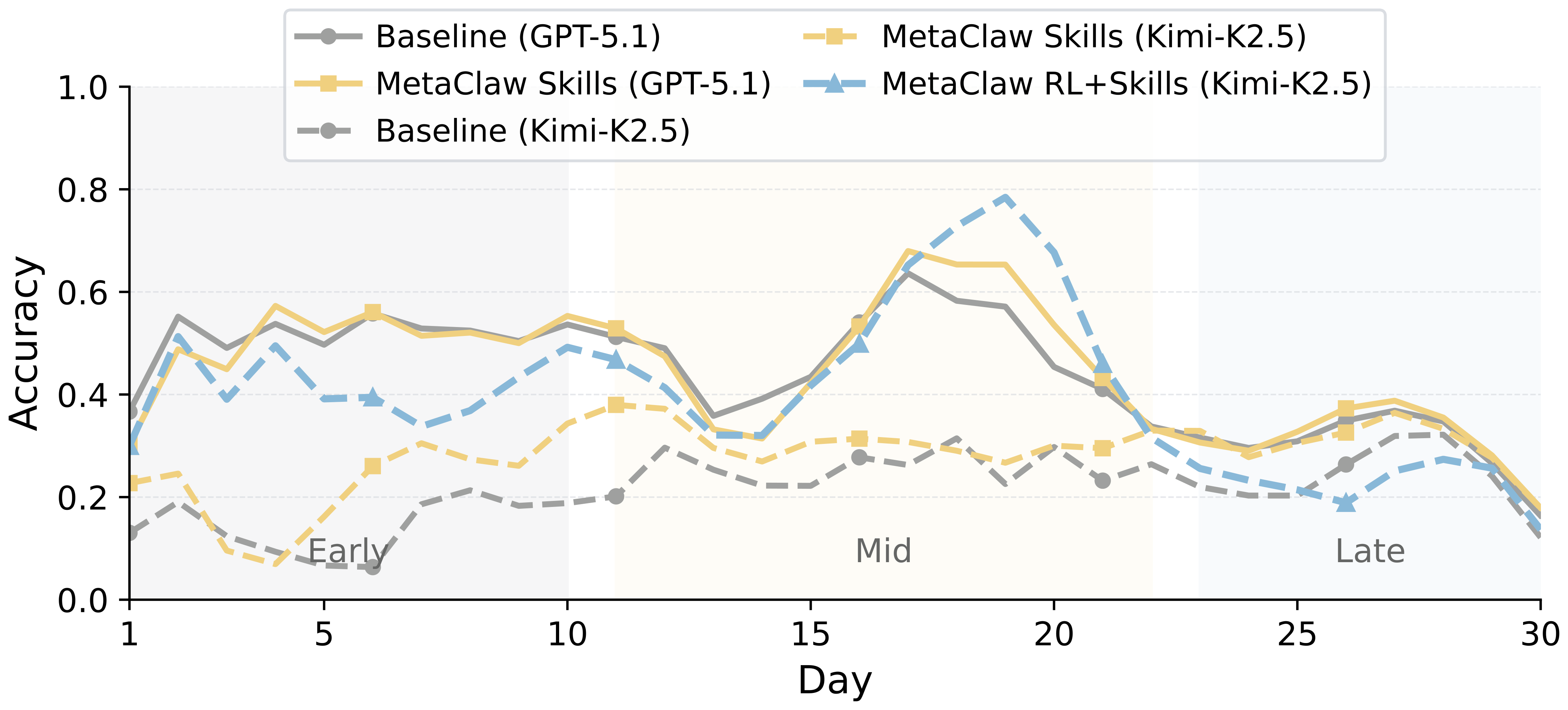
Figure 2 解读:30 simulated workdays 的 3-day rolling accuracy 显示所有模型在 day01—10 较高、day25—30 降到低位,验证 benchmark 难度随天数增加。MetaClaw 的优势主要出现在 day11—22 的中段,此时任务需要可从失败中学习的 procedural compliance;late days 太复杂,仅靠 accumulated skills 不足,曲线趋于收敛。论文还指出 MetaClaw (Full) 在 day19—20 左右达到接近 0.8 accuracy 的峰值优势。
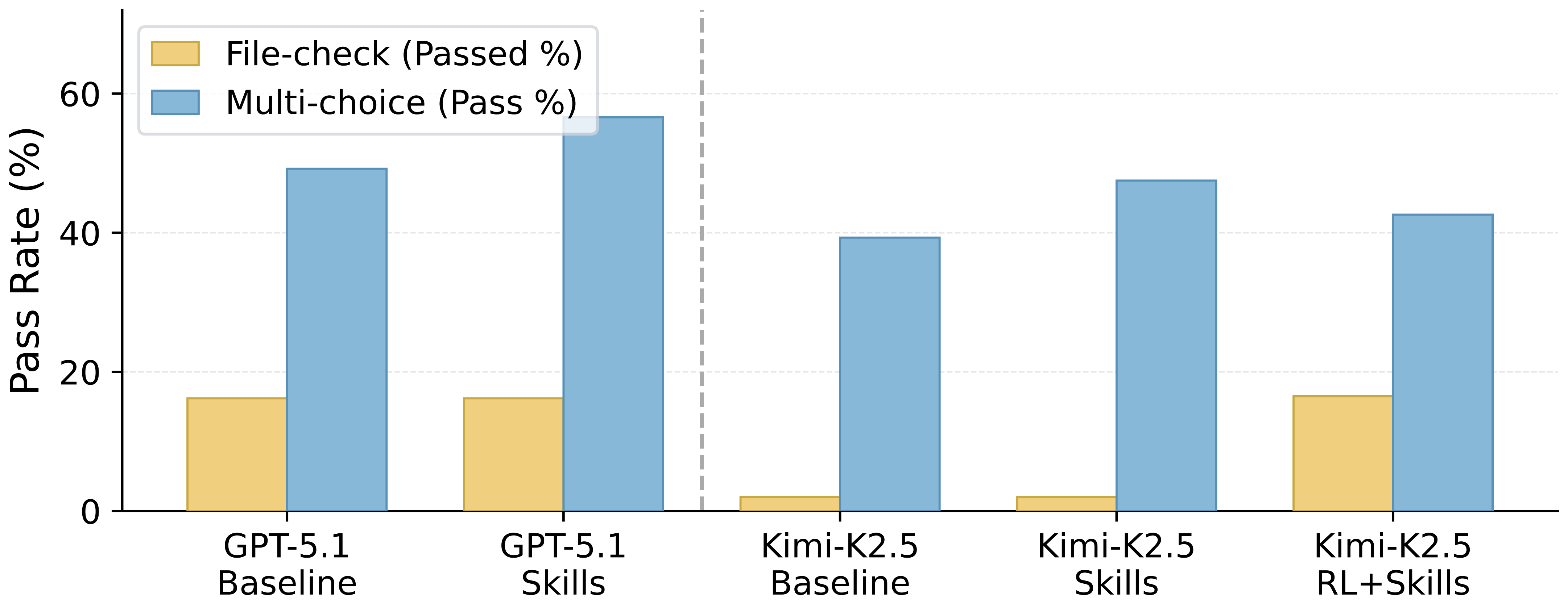
Figure 3 解读:task-type breakdown 揭示两个组件解决的瓶颈不同。Skills-only 明显提高 multi-choice pass rate,但在 Part I 的 file-check completion 上基本不动,说明显式 procedural knowledge 有助于推理但不一定保证零缺陷执行。MetaClaw (Full) 则让 Kimi-K2.5 的 file-check completion 跳到接近 GPT-5.2 baseline;同时 multi-choice 稍降,反映 RL policy shift 更偏向文件执行可靠性。
5.4 Case studies and mechanism evidence
Case 1 是 GPT-5.2 skills-only:Day 19 / Round 4 要更新 sprint8_board.json 并补 completed_at。Baseline 直接覆盖文件,checker 因缺少 sprint8_board.json.bak 给 0;MetaClaw 从 Day 2 失败蒸馏出“修改前创建 .bak”的 skill 后,创建 backup 并 patch 成功,score 1.0,当天 accuracy 从 43.9% 到 62.1%,+18.2 pp。
Case 2 是 Kimi-K2.5 full pipeline:Day 18 / Round 6 要向 deploy_log.json 追加 deployment record,必须含 timestamp、env、status、changes。Baseline 用 date 替代 timestamp 且漏掉 changes,score 0;skills-only 提醒 ISO 8601 仍漏 changes;RL 后四个字段齐全、schema valid、backup created,score 1.0,当天 accuracy 从 8.3% 到 skills-only 25.0%,再到 full 80.6%。这支持论文的核心 claim:skills 给 declarative format context,权重更新负责把复杂执行模式内化成更可靠的 action policy。
5.5 Limitations and conclusion
作者明确承认两个限制:一是 MetaClaw-Bench 是 authored simulation,不是真实用户 session 集合,因此绝对收益数值未必直接迁移到生产环境;二是 OMLS 的 idle-window detection 依赖用户配置和部署环境(sleep schedule、系统 idle API、calendar),不保证适用于所有环境。结果更应被解读为 directional evidence:skill-driven adaptation 稳定提升 partial execution quality,而 weight-level optimization 对 end-to-end completion 尤其关键。