Stable Video Infinity: Infinite-Length Video Generation with Error Recycling
1. Motivation (研究动机)
1.1 长视频生成的核心瓶颈:Error Accumulation
当前 video DiT (如 Wan 2.1) 单次生成长度有限 (通常约 5 秒)。要生成更长视频,需要 autoregressive 方式逐 clip 生成,但 error accumulation (误差累积) 会导致:
- 图像质量退化 (blur, color shift)
- 运动漂移 / 语义失控
- 场景同质化 (scene homogeneity bias)
1.2 现有方案的局限
现有三大路线都只是 缓解 (mitigate) error,而非 纠正 (correct):
| 路线 | 代表方法 | 局限 |
|---|---|---|
| Noise modification | FreeNoise, Rolling Diffusion | 改 noise schedule,无法消除根本误差 |
| Frame anchoring | StreamingT2V, FramePack | 用 clean reference image 做 anchor,仍受限于单 prompt 单场景 |
| Improved sampling | FramePack (Zhang & Agrawala, 2025) | Anti-drifting sampling,长度仍受限 (~1 min) |
1.3 关键洞察:Training-Test Hypothesis Gap
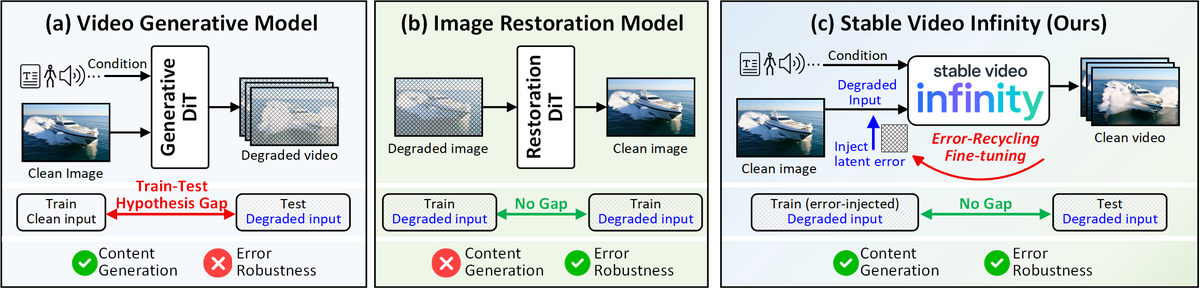
Figure 1 解读:对比三种模型的 train-test 假设:
- (a) Video Generative DiT:训练时 trajectory 上的中间态 基于 clean latent 构建 (error-free),但推理时 autoregressive 条件下 来自上一次自身的 imperfect 输出 → train-test hypothesis gap
- (b) Image Restoration DiT:训练和测试都接收 degraded input → 没有 gap → 天然具备 error robustness
- (c) SVI (本文):借鉴 restoration 思路,在训练时主动注入 self-generated errors,使 train 和 test 都面对 error-injected input → 消除 gap,同时保留 generation 能力
核心理念:与其训练一个 fragile 的 generator 然后设法让推理不出错,不如训练一个 能在有错条件下自动纠错的 generator。
2. Idea (核心思想)
一句话总结:提出 Error-Recycling Fine-Tuning (ERFT),将 DiT 自身产生的 error 回收为 supervisory prompt 注入训练,使模型学会在 autoregressive 推理时主动识别并纠正自己的错误,从而支持无限长度视频生成。
核心设计的三步闭环:
- Error Injection — 将历史 error 注入 clean input,模拟推理时的 degradation
- Bidirectional Error Curation — 单步双向积分高效计算 error
- Error Replay Memory — 动态存储与重采样 error,形成闭环
关键优势:
- 无限长度:error 被主动纠正,不再随时间累积
- 零额外推理开销:只训练 LoRA adapter,推理与原始 pipeline 一致
- 多模态兼容:支持 text / audio / skeleton 等多种 condition
- 数据高效:仅需 300-6k 短视频 LoRA 微调
3. Method (方法)
3.1 整体架构
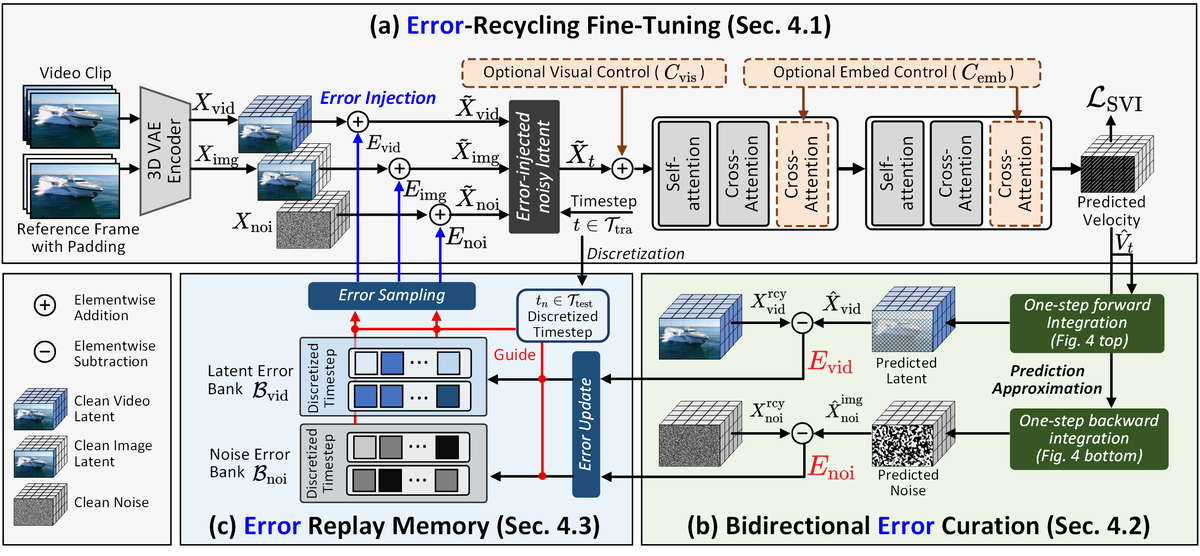
Figure 3 解读:SVI 整体架构由三个核心模块组成:
- (a) Error-Recycling Fine-Tuning (Sec 4.1):从 3D VAE 获取 , , ,从 Error Replay Memory 中采样 , , ,按概率注入 clean input 得到 error-injected 版本 , , 。拼接后送入 DiT blocks (Self-Attention + Cross-Attention) 预测 velocity
- (b) Bidirectional Error Curation (Sec 4.2):用 predicted velocity 单步前向/后向积分,近似预测 latent 和 noise,与 ground-truth 作差得到 和
- (c) Error Replay Memory (Sec 4.3):维护两个 memory bank 和 ,按 discretized timestep 存储 error,训练时选择性重采样
3.2 Training-Test Hypothesis Gap 的数学分析
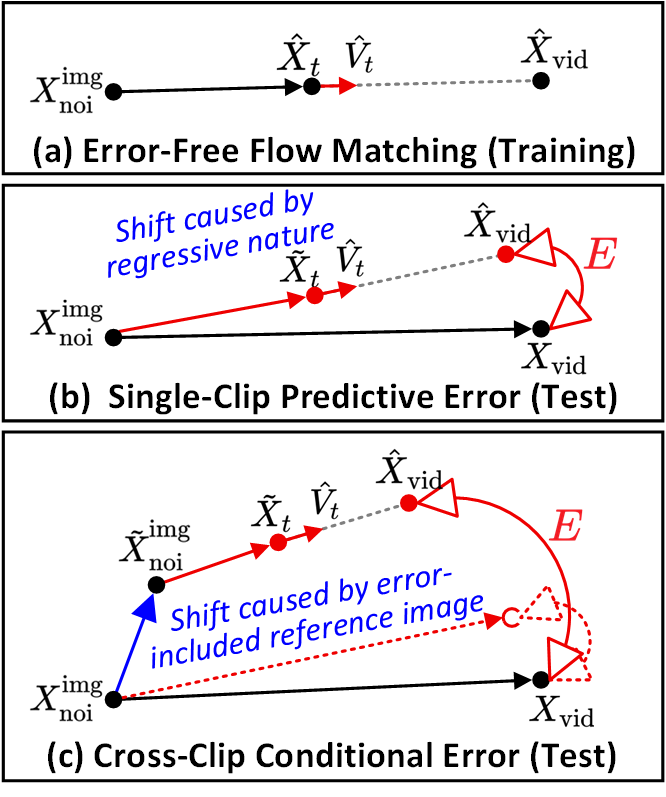
Figure 2 解读:展示 flow matching 中两种 error 的来源:
- (a) Error-Free Training:训练假设中间态 trajectory 无误差
- (b) Single-Clip Predictive Error:推理时 regressive nature 导致 predicted velocity 与 ground-truth 之间存在偏差 ,使 trajectory 终点偏离
- (c) Cross-Clip Conditional Error:autoregressive 多 clip 生成时,error-included reference image 进一步偏移 trajectory 起点 → 两种 error 相互放大
数学定义:
训练目标 (Error-Free Flow Matching):
其中 ,。
推理时步进积分:
问题根源:训练时 基于 clean 构建,但推理时实际是 (基于上一步 imperfect 预测)。
# Pseudocode: Error-Free Flow Matching Training (Baseline)
def flow_matching_train_step(x_vid, x_img, x_noi, condition, t, model):
"""标准训练:假设所有 input 都是 clean 的"""
x_t = t * x_vid + (1 - t) * x_noi # clean 中间态
v_t = x_vid - x_noi # ground-truth velocity
v_hat = model(x_t, x_img, condition, t) # predicted velocity
loss = mse(v_hat, v_t)
return loss
# Pseudocode: Autoregressive Inference (暴露 hypothesis gap)
def autoregressive_inference(model, ref_image, prompts, n_steps=50):
"""推理时 error 不断累积"""
x_img = encode(ref_image) # 初始 clean
videos = []
for prompt in prompts:
x_noi = torch.randn_like(x_img)
x_t = x_noi # t=0
for k in range(n_steps):
t_k = k / n_steps
v_hat = model(x_t, x_img, prompt, t_k) # x_t 已含 error!
x_t = x_t + (1/n_steps) * v_hat
x_vid_hat = x_t # 含 accumulated error
videos.append(decode(x_vid_hat))
x_img = x_vid_hat[-1] # error-included → 传递到下一 clip
return videos3.3 Error-Recycling Fine-Tuning (ERFT)
核心目标:预测 error-recycled velocity ,无论当前 trajectory 历史是否含 error,都指向 clean latent 。
3.3.1 Error Injection
将从 replay memory 采样的三类 error 按概率注入 clean input:
其中 w.p. ,否则为 0。默认 ,保留一半 clean input 维持生成能力。
# Pseudocode: Error Injection
def inject_errors(x_vid, x_noi, x_img, error_bank_vid, error_bank_noi, t, p=0.5):
"""从 replay memory 采样 error 并按概率注入"""
# 将训练 timestep t 映射到最近的 test discretized timestep t_n
t_n = find_nearest_test_timestep(t)
# 选择性采样 error (Sec 4.3)
E_vid = uniform_sample(error_bank_vid[t_n]) # timestep-aligned
E_noi = uniform_sample(error_bank_noi[t_n]) # same timestep
E_img = uniform_sample_across_T(error_bank_vid) # 跨 timestep 采样
# 按概率注入
mask_vid = (torch.rand(1) < p).float()
mask_noi = (torch.rand(1) < p).float()
mask_img = (torch.rand(1) < p).float()
x_vid_tilde = x_vid + mask_vid * E_vid
x_noi_tilde = x_noi + mask_noi * E_noi
x_img_tilde = x_img + mask_img * E_img
return x_vid_tilde, x_noi_tilde, x_img_tilde3.3.2 Control Injection & Velocity Prediction
SVI 通过两种方式注入额外控制信号:
- Visual Control :如 skeleton,通过 element-wise addition 注入 tokenized input → 精确空间控制 (SVI-Dance)
- Embedding Control :如 text, audio,通过 cross-attention 层注入 → 多模态语义控制 (SVI-Talk)
# Pseudocode: SVI Forward Pass
def svi_forward(x_vid_tilde, x_noi_tilde, x_img_tilde, condition, t, model,
c_vis=None, c_emb=None):
"""Error-injected 输入 → DiT → predicted velocity"""
# 构建 noisy latent
x_t_tilde = t * x_vid_tilde + (1 - t) * x_noi_tilde
# 拼接 image condition
x_input = concat(x_t_tilde, x_img_tilde) # along channel
# 可选 visual control (element-wise add after tokenization)
if c_vis is not None:
x_input = x_input + c_vis # e.g., skeleton encoding
# DiT blocks with optional embedding control in cross-attention
v_hat = model.dit_blocks(x_input, condition, t, c_emb=c_emb)
return v_hat3.4 Bidirectional Error Curation
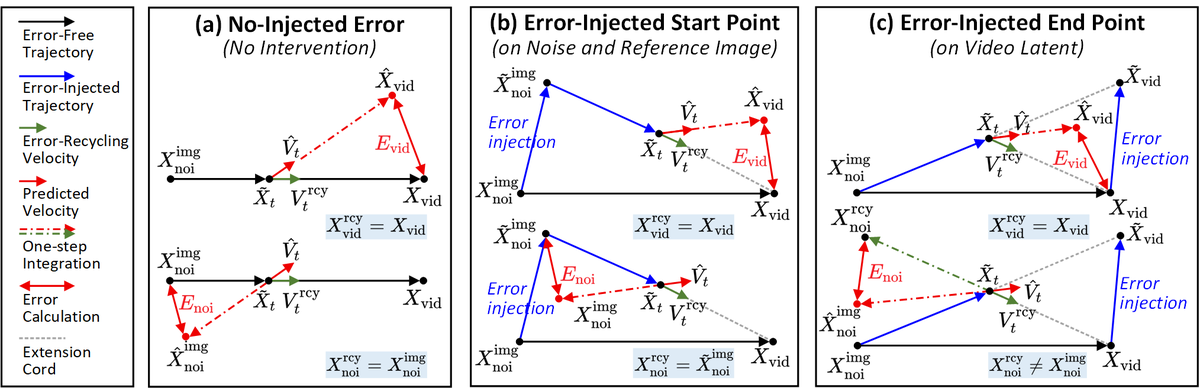
Figure 4 解读:展示三种 error injection 场景下的 error 计算方式:
- (a) No Injected Error:无注入时,模拟 single-clip predictive error。前向积分 得到 predicted latent,后向积分得到 predicted noise。,
- (b) Error-Injected Start Point:error 注入到 noise / reference image,模拟 cross-clip conditional error
- (c) Error-Injected End Point:error 注入到 video latent,模拟累积 error 视角
核心近似:避免完整 ODE 求解,用 单步积分 近似预测:
Error 统一公式:
# Pseudocode: Bidirectional Error Curation
def compute_errors(x_t_tilde, v_hat, t, x_vid, x_noi_img, x_vid_rcy, x_noi_rcy):
"""单步双向积分计算 error"""
# 前向积分:近似预测 video latent
x_vid_hat = x_t_tilde + (1 - t) * v_hat
# 后向积分:近似预测 noise (image-conditioned start)
x_noi_img_hat = x_t_tilde - t * v_hat
# 计算 latent error 和 noise error
E_vid = x_vid_hat - x_vid_rcy # video latent error
E_noi = x_noi_img_hat - x_noi_rcy # noise error
# Image error: 从 E_vid 跨 temporal axis 均匀采样
E_img = uniform_sample_temporal(E_vid)
return E_vid, E_noi, E_img3.5 Error Replay Memory
维护两个按 discretized timestep 索引的 memory bank: 和 。
关键设计:
- Timestep 对齐:将训练 timestep () 映射到 test timestep (),存储到对应位置
- 容量控制:每个 bank 上限 ,满时用 距离替换最相似的 entry,保持 diversity
- Warmup:跨机 cross-machine gathering 加速初始 bank 填充 (借鉴 Federated Learning)
选择性采样策略:
| Error 类型 | 采样策略 | 原因 |
|---|---|---|
| 从 (timestep-aligned) 均匀采样 | step-wise error 与 timestep 强相关 | |
| 从 (同 timestep) 均匀采样 | noise-latent 对偶性 | |
| 从 跨 timestep 均匀采样 | reference image error 是全 trajectory 累积的 |
# Pseudocode: Error Replay Memory
class ErrorReplayMemory:
def __init__(self, n_test=50, max_size=500):
self.n_test = n_test
self.max_size = max_size
# 按 test timestep 索引的 bank
self.B_vid = {n: [] for n in range(n_test)}
self.B_noi = {n: [] for n in range(n_test)}
def update(self, E_vid, E_noi, t_train):
"""将新计算的 error 存入对应 timestep slot"""
t_n = self._align_timestep(t_train)
for bank, error in [(self.B_vid, E_vid), (self.B_noi, E_noi)]:
if len(bank[t_n]) < self.max_size:
bank[t_n].append(error)
else:
# 替换 L2 距离最近的 entry,保持 diversity
dists = [torch.norm(error - e) for e in bank[t_n]]
idx = torch.argmin(torch.tensor(dists))
bank[t_n][idx] = error
def sample(self, t_train):
"""选择性采样三类 error"""
t_n = self._align_timestep(t_train)
E_vid = random.choice(self.B_vid[t_n])
E_noi = random.choice(self.B_noi[t_n])
# E_img 跨 timestep 采样
all_vid_errors = [e for slot in self.B_vid.values() for e in slot]
E_img = random.choice(all_vid_errors)
return E_vid, E_noi, E_img
def _align_timestep(self, t_train):
"""将连续训练 timestep 映射到最近的 discrete test timestep"""
test_steps = torch.linspace(0, 1, self.n_test)
return torch.argmin(torch.abs(test_steps - t_train)).item()3.6 Optimization 目标
最终训练 loss:
其中 , 指向 clean latent。
只训练 LoRA adapter,冻结原始 DiT 权重 → 用户可灵活切换。
# Pseudocode: Full SVI Training Loop
def svi_training_step(model, lora, vae, data, memory, p_inject=0.5):
"""完整的 SVI 单步训练"""
video_clip, ref_image, condition = data
# 1. Encode
x_vid = vae.encode(video_clip)
x_img = vae.encode(ref_image) # with padding
x_noi = torch.randn_like(x_vid)
t = torch.rand(1)
# 2. Error injection (from replay memory)
if memory.is_ready():
E_vid, E_noi, E_img = memory.sample(t)
x_vid_t, x_noi_t, x_img_t = inject_errors(
x_vid, x_noi, x_img, E_vid, E_noi, E_img, p=p_inject)
else:
x_vid_t, x_noi_t, x_img_t = x_vid, x_noi, x_img
# 3. Construct error-injected intermediate state
x_t = t * x_vid_t + (1 - t) * x_noi_t
# 4. Forward through DiT + LoRA
v_hat = model(x_t, x_img_t, condition, t, lora=lora)
# 5. Error-recycled velocity target (always points to CLEAN latent)
v_target = x_vid - x_noi_t # V_t^rcy
# 6. Loss
loss = F.mse_loss(v_hat, v_target)
# 7. Bidirectional error curation & memory update
with torch.no_grad():
E_vid_new, E_noi_new, _ = compute_errors(
x_t, v_hat, t, x_vid, x_noi, x_vid, x_noi)
memory.update(E_vid_new, E_noi_new, t)
return loss3.7 SVI Family — 多应用变体
| 变体 | 用途 | 训练改动 | Error 注入概率 () |
|---|---|---|---|
| SVI-Shot | 单场景长视频 | Padding + random image as anchor | 0.9, 0.9, 0.01 |
| SVI-Film | 多场景 storyline 长片 | 5 motion frames, padding frame → zero latent | 0.9, 0.9, 0.01 |
| SVI-Talk | Audio-conditioned talking | Audio cross-attention () | 0.9, 0.9, 0.01 |
| SVI-Dance | Skeleton-guided dancing | Skeleton → visual control () | 0.9, 0.9, 0.01 |
3.8 Code Mapping
| 论文概念 | 代码位置 (GitHub) |
|---|---|
| Error-Recycling Fine-Tuning | train/ 目录下的训练脚本 |
| Error Replay Memory | 训练代码中的 memory bank 实现 |
| SVI-Shot / SVI-Film inference | comfyui_workflow/ (ComfyUI workflow) |
| LoRA weights | 提供预训练 LoRA checkpoint |
| Benchmark evaluation | eval/ 目录 |
4. Experimental Setup (实验设置)
4.1 Base Model & Training
- Base model: Wan 2.1 (14B video DiT)
- Fine-tuning: 仅训练 LoRA adapter
- 训练数据: 仅需 300-6k 短视频
- 训练效率: 数据量极小,任何人都可以制作自己的 SVI
4.2 Benchmarks
三大 benchmark,涵盖 consistent / creative / conditional 设定:
| Benchmark | 场景数 | 时长 | 描述 |
|---|---|---|---|
| Consistent Video Generation | Single | 50s / 250s | 单 prompt 单场景,不换场景 |
| Creative Video Generation | Multiple | 50s / 250s | Storyline-based prompt stream,多场景切换 |
| Multimodal Conditional Generation | Single | 300s (talk) / 50s (dance) | Audio / skeleton 条件控制 |
自动 Prompt Stream 引擎:
- Keyword → Image (自动检索)
- Image → Storyline (Qwen2.5 MLLM 自动生成 prompt stream)
- Storyline → Short Film (SVI 迭代生成)
4.3 Baselines
- Generic: Wan 2.1, StreamingT2V, HistoryGuidance, FramePack
- Audio-conditioned talking: MultiTalk
- Skeleton-conditioned dancing: UniAnimate-DiT
4.4 Metrics
- 视频质量 (VBench++): Subject Consistency, Background Consistency, Aesthetic Quality, Imaging Quality, Dynamic Degree, Motion Smoothness
- 条件生成: Sync-C, Sync-D, FVD, PSNR, SSIM
5. Experimental Results (实验结果)
5.1 主实验:Long Video Generation in the Wild

Figure 7 解读:定性对比三类生成任务:
- (a) Creative Video Generation: StreamingT2V / FramePack 在场景切换时严重退化,SVI-Film 保持平滑 transition 和高视觉质量
- (b) Consistent Video Generation: 现有方法出现 color shift、motion drift、静态退化,SVI-Shot 保持时间一致性和合理动态
- (c) Multimodal Conditional Generation: SVI-Talk / SVI-Dance 无需专门设计即可在长视频中保持条件一致性
Consistent Video Generation (Table 1 上半):
| Method | Sub. Cons. | Back. Cons. | Aest. Qual. | Img. Qual. | Dyn. Deg. | Motion Sm. |
|---|---|---|---|---|---|---|
| Wan 2.1 | 87.03% | 92.45% | 56.40% | 65.70% | 12.68% | 98.51% |
| FramePack | 93.08% | 94.72% | 63.57% | 66.72% | 7.75% | 99.57% |
| SVI-Shot | 98.13% | 98.19% | 63.84% | 71.88% | 17.61% | 98.93% |
SVI-Shot 在大多数指标上达到 SOTA,尤其 consistency (+5.05%) 和 image quality (+5.16%) 相对 FramePack 提升显著。
Creative Video Generation (Table 1 下半):
| Method | Sub. Cons. | Back. Cons. | Aest. Qual. | Img. Qual. | Dyn. Deg. | Motion Sm. |
|---|---|---|---|---|---|---|
| Wan 2.1 | 81.44% | 89.81% | 51.33% | 53.09% | 61.97% | 98.57% |
| SVI-Film | 84.27% | 90.68% | 57.02% | 57.04% | 57.04% | 99.12% |
| SVI-Shot | 93.52% | 95.86% | 58.07% | 62.81% | 55.63% | 98.42% |
现有 long video 方法在多场景切换时全面失败,SVI 显著领先。
Conditional Generation:
| Task | Method | Key Metrics |
|---|---|---|
| Audio-talking | SVI-Talk | Sync-C: 6.12, Sync-D: 8.74, FVD: 390 |
| Skeleton-dance | SVI-Dance | PSNR: 20.01, SSIM: 0.71, FVD: 299 |
5.2 Stability Analysis
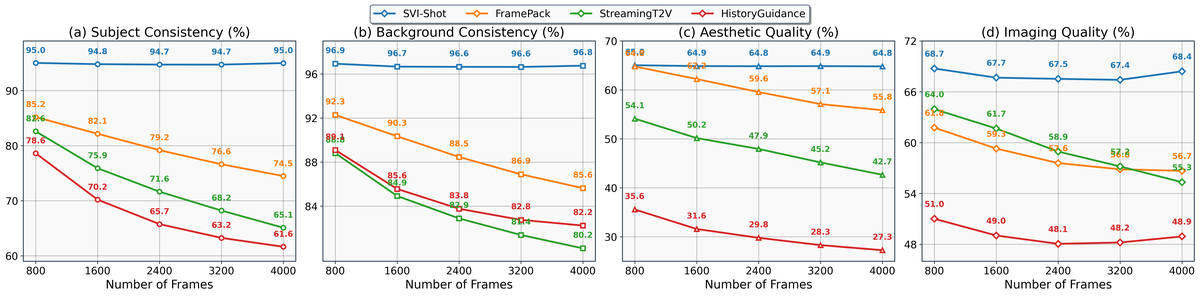
Figure 5 解读:随着生成帧数增加 (800 → 4800),所有现有方法的 consistency 和 quality 均明显下降,而 SVI 保持稳定 (几乎水平线)。这证明 SVI 真正实现了 error correction 而非仅仅 mitigation。
5.3 Error 可视化

Figure 6 解读:
- 上行: Wan 2.1 对自身 error 敏感, (decoded error) 显示明显结构化 degradation → SVI fine-tuning 后 error 大幅减小
- 下行: 注入 error ( by Wan 2.1) 可以很好地模拟 autoregressive drifting → 验证 error recycling 策略的有效性
5.4 Ablation Study
| Method | Sub. Cons. | Back. Cons. | Aest. Qual. | Img. Qual. |
|---|---|---|---|---|
| Wan 2.1 (baseline) | 66.73% | 82.83% | 43.95% | 42.31% |
| SVI w/o | 73.82% | 84.21% | 49.58% | 57.63% |
| SVI w/o | 94.22% | 94.87% | 59.80% | 69.90% |
| SVI w/o | 93.56% | 95.01% | 58.99% | 71.50% |
| SVI full | 94.69% | 95.39% | 61.88% | 71.22% |
关键发现:
- 去除 导致所有指标大幅下降 → reference image error injection 是核心 (直接模拟 cross-clip conditional error)
- 和 起辅助作用,三者结合效果最佳
5.5 定性展示
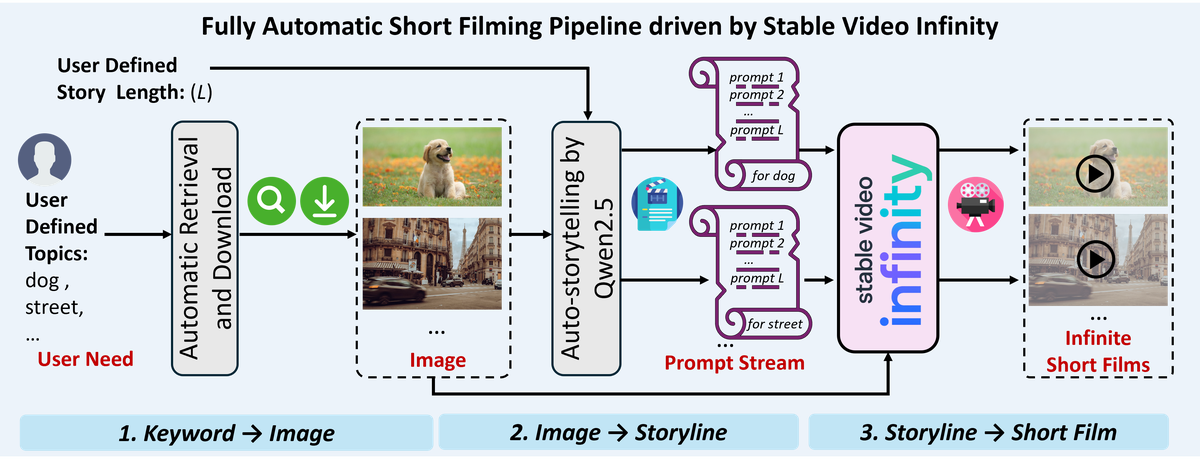
Figure 8 解读:展示 SVI-Film 的定性结果,重点是多场景长视频中的连续性与场景切换表现。

Figure 9 解读:展示 cat creative short 的定性结果,重点是创意视频生成中的画面连贯性。

Figure 10 解读:展示 baby creative short 的定性结果,重点是创意视频生成中的主体稳定性。

Figure 11 解读:展示 zoo creative short 的定性结果,重点是多场景生成中的整体连贯性。

Figure 12 解读:展示 motorcycle creative short 的定性结果,重点是动作与画面的一致性。

Figure 13 解读:展示 airplane creative short 的定性结果,重点是长视频生成中的视觉稳定性。

Figure 14 解读:展示 dance_034 的定性结果,重点是 skeleton-guided dancing 的动作控制效果。

Figure 15 解读:展示 talkingface_vis 的定性结果,重点是 audio-conditioned talking face 的一致性。

Figure 16 解读:展示 tom_vis 的定性结果,重点是长视频中的视觉连贯性与条件一致性。