RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO
Paper: arXiv:2605.15190v1 Code: mvp-ai-lab/RAVEN Code reference:
main@ff6960c6(2026-05-15)
1. Motivation (研究动机)
RAVEN 解决的是 causal autoregressive video diffusion 的长时外推训练-推理错配:训练时常看到真实历史或 detached self-rollout 历史,但推理时只能依赖模型自己已经生成的 chunk 和 KV cache。
- 现有瓶颈:Teacher Forcing / Diffusion Forcing 的历史来自数据分布,和 inference 中模型自回归生成的历史不同;Self Forcing 虽然用 self-rollout 历史,但历史 cache 被 detach,后续 chunk 的 loss 不能反向监督历史表示。
- 本文目标:把每次 self rollout 重新打包为“clean historical endpoints + noisy denoising states”的交错序列,在训练时模拟 test-time extrapolation,并让后续 chunk loss 监督未来预测依赖的历史表示。
- 为什么重要:实时流式视频生成需要持续 extrapolate future chunks;一旦历史表示在训练中没有被端到端优化,长 horizon 会出现 identity drift、motion/quality/semantic trade-off。
2. Idea (核心想法)
一句话:RAVEN 用 training-time test 对齐自回归视频扩散的训练上下文;CM-GRPO 再把 consistency sampler 本身写成 Gaussian transition kernel,直接在推理同款 kernel 上做 GRPO。

Figure 1 解读:图 1 对比了四种历史注意力配置。Teacher Forcing 与 Diffusion Forcing 的历史状态来自真实数据,因此训练分布和推理分布不一致;Self Forcing 使用 self rollout history,但历史 cache 不接收来自后续 chunk 的梯度;RAVEN 把 self rollout 的 clean endpoint 和 noisy state 交错放进一个 causal attention 序列,让第 个 noisy state 能看到模型自己产生的 clean history,并让后续 loss 反传到这些历史表示。

Figure 2 解读:图 2 展示了完整训练管线。先在 fake-score step 中用 frozen generator 自回归 rollout,并复用 KV cache 得到 clean endpoints 与 noisy denoising states;随后 generator step 不丢弃 rollout states,而是把它们 repack 成交错序列 ,通过 causal student generator 做一次前向,使用 bidirectional real-score teacher 与 fake-score critic 给出的 reverse-KL/DMD 信号更新学生模型。chunk-wise loss scaling 把更多梯度权重给早期 chunk,因为早期历史会影响更多后续预测。
3. Method (方法)
3.1 RAVEN:Training-time Test for Autoregressive Diffusion
设一条 rollout 有 个 chunk,每个 chunk 在 consistency sampler 的某个噪声 level 处有 noisy state ,并最终得到 clean endpoint 。RAVEN 的关键是构造交错序列:
这个序列有两个作用:第一,noisy state 的 attention history 和 inference 时一致,都是模型自己生成的 clean prefix;第二,clean endpoint 不再只是 rollout 的副产物,而是在 supervised forward pass 中成为可被后续 chunk loss 反向影响的历史表示。
3.2 Chunk-wise Loss Scaling
RAVEN 观察到 earlier chunks 参与更多 future prediction,因此不应该把每个 chunk 的 loss 等权处理。对第 个 chunk,令 为元素数、 为该 chunk 的 summed loss,则 future participation score 为:
给定 weighting function 后,原始权重 ,归一化权重与总 loss 为:

Figure 5 解读:图 5 显示不同 的 chunk 权重曲线和对应指标。本文采用 Shift(),把权重显著推向更早 chunk;这与“早期历史影响更多 future chunks”的直觉一致,并在 ablation 中得到最高 Total/Quality。
3.3 CM-GRPO:在 Consistency Kernel 上直接做 RL
对 consistency sampling 的单步 ,模型先预测 clean endpoint ,再采样:
这自然定义了条件 Gaussian transition:
对同一 prompt 采样 条 trajectory,得到 reward 后,CM-GRPO 使用 group-relative advantage:
最终 stop-gradient regression 目标为:
核心区别是:Flow-GRPO 为 deterministic ODE 额外构造 Euler-Maruyama SDE,而 CM-GRPO 直接优化 consistency sampler 在 inference 中真实使用的 stochastic Gaussian transition。
3.4 Pseudocode(按代码实现改写)
Code reference:
main@ff6960c6;关键实现来自project/engines/distribution_matching_distillation.py、project/engines/group_relative_policy_optimization.py、project/meta_models/causal_wan2_1_t2v.py。
def raven_training_step(batch, cfg, student, fake_critic, teacher, sampler):
# project/engines/distribution_matching_distillation.py:156-232
# causal_wan2_1_t2v.py:588-732 performs chunk-wise autoregressive infer/cache.
rollouts = []
for micro_batch in split(batch, cfg.slices_per_step):
latent_x0s, trajectory_xt, trajectory_pred = infer(
student,
micro_batch,
sampler=cfg.sampler, # ConsistencySampler
num_sampling_steps=4,
return_trajectory=True,
)
rollouts.append((micro_batch, (latent_x0s, trajectory_xt, trajectory_pred)))
# fake-score critic update, every iteration unless TTUR skips it
for inputs, trajectory in rollouts:
noisy_x = sample_or_use_trajectory_state(trajectory, cfg.fake_use_trajectory)
target = make_fake_score_target(noisy_x, latent_x0s)
fake_loss = mse(fake_critic(noisy_x), target)
optimize(fake_critic, fake_loss)
# generator update uses self-rollout trajectory as training context
if should_update_generator(cfg.ttur_fake):
for inputs, trajectory in rollouts:
interleaved = repack_clean_endpoints_and_noisy_states(trajectory)
x_theta = student(interleaved, causal_attention=True)
x_teacher = teacher(score_noised(x_theta))
x_fake = fake_critic(score_noised(x_theta))
dmd_loss = stop_gradient_dmd_regression(x_theta, x_teacher, x_fake)
loss = apply_chunk_wise_weighting(dmd_loss, key="dmd_losses")
optimize(student, loss)def cmgrpo_training_step(prompt_batch, cfg, policy, reward_models, sampler):
# project/engines/group_relative_policy_optimization.py:393-412
group_rollouts = []
for g in range(cfg.group_size):
video, trajectory = autoregressive_consistency_rollout(
policy, prompt_batch, sampler, return_trajectory=True
)
rewards = evaluate_rewards(video, prompt_batch, reward_models)
group_rollouts.append((video, trajectory, rewards))
# group-relative advantage, optionally with per-prompt tracker
rewards = torch.stack([r for _, _, r in group_rollouts])
advantages = (rewards - rewards.mean(dim=0)) / (rewards.std(dim=0, unbiased=False) + 1e-5)
advantages = advantages.clamp(-cfg.adv_clip_max, cfg.adv_clip_max)
# group_relative_policy_optimization.py:434-617
losses = []
for rollout, advantage in zip(group_rollouts, advantages):
step_idx = sample_policy_step(rollout.trajectory, skip_timesteps=cfg.skip_timesteps)
z_u, z_s, s = retrieve_consistency_transition(rollout.trajectory, step_idx)
x_theta = policy(z_u)
mu = alpha(s) * x_theta
target = x_theta + advantage * alpha(s) / (2 * sigma(s) ** 2) * (z_s - mu)
losses.append((x_theta - target.detach()).pow(2))
policy_loss = apply_chunk_wise_weighting(losses, key="policy_losses")
optimize(policy, cfg.policy_loss_scaling * policy_loss)def apply_chunk_wise_weighting(chunk_losses, chunk_numel, alpha=-1.0):
# project/meta_models/causal_wan2_1_t2v.py:915-1017
participation = torch.flip(torch.cumsum(torch.flip(chunk_numel, dims=[0]), dim=0), dims=[0])
participation = participation / chunk_numel.sum()
raw_weight = shift_weighting(participation, alpha=alpha)
norm = chunk_numel.sum() / (raw_weight * chunk_numel).sum()
weight = raw_weight * norm
return sum(w * loss for w, loss in zip(weight, chunk_losses)) / (weight * chunk_numel).sum()4. Experimental Setup (实验设置)
4.1 Setup
- Base model:所有实验基于
Wan2.1-T2V-1.3B,每个 chunk 为 3 latent frames;RAVEN 初始化来自 Causal Forcing 的 ODE-distilled checkpoint,CM-GRPO 从 RAVEN checkpoint 继续训练。 - Training prompts:论文称 RAVEN/CM-GRPO 训练 prompt 来自 VidProM;代码配置使用
assets/vidprom_motion_30725_v3_w95_action_subject.txt,该文件有 30,725 行。需要 real video 的 ablation 使用 OpenVidHD-0.4M,并在使用前通过 RIFE temporal upsampling。 - Evaluation:VBench Total / Quality / Semantic;Dynamic Degree 既用 VBench/RAFT,也额外用 UnifiedReward-32B 在 6,220 个 VBench prompt-suite 视频上评估;user study 使用 100 个 baseline qualitative prompts,每个方法每个 prompt 生成 4 个样本。
- Baselines:CausVid、LongLive、Rolling Forcing、Self Forcing、Reward Forcing、Causal Forcing;代码还提供
third_party/<baseline>/inference.py与一致的inference.sh接口。
4.2 Training Config from Released Code
RAVEN DMD
- Config path:
configs/trials/distribution_matching_distillation/causal_wan2.1_1.3B_t2v/raven.jsonc - Sampling / video shape:
training_steps=220,num_sampling_steps=4,num_frames=81,height=480,width=832,chunk_size=3,independent_first_chunk=3,guidance=3.0。 - Trajectory / loss:
gen_use_trajectory=true,fake_use_trajectory=false,ttur_fake=2,dmd_loss_type=dmd,chunk_wise_weighting.dmd_losses=-1.0。 - Optimizer:backbone LR
2e-6,fake-model LR4e-7,AdamW betas[0.0, 0.999]。
CM-GRPO
- Config path:
configs/trials/group_relative_policy_optimization/causal_wan2.1_1.3B_t2v/cmgrpo_raven_raft0.35ta2aq1iq1ms0.75.jsonc - GRPO sampling:
training_steps=160,group_size=4,groups_per_infer=4,slices_per_step=2,random_policy_timestep=true。 - Policy objective:
reward_aggregation=normalize_then_sum,adv_clip_max=5.0,beta=0.0,skip_timesteps=1,policy_loss_scaling=100.0。 - LoRA / optimizer:LoRA
r=256,LoRA alpha256,backbone LR5e-6。 - Reward weights(same CM-GRPO config):
raft_RAFT=0.35,videoalign_TA=2.0,aq_AES=1.0,iq_IMG=1.0,ms_MS=0.75。
论文和 release config 没有显式给出固定 GPU 数;tools/multi_run.sh 通过 N/NNODES/SLURM 或本地 GPU 自动决定 torchrun 并行参数,所以这里不编造硬件数量。
5. Experimental Results (实验结果)
5.1 Main Quantitative Results
| Method | Total | Quality | Semantic | Dyn. Deg. |
|---|---|---|---|---|
| CausVid | 83.01 | 84.18 | 78.34 | 2.340 |
| LongLive | 83.05 | 83.70 | 80.46 | 2.277 |
| Rolling Forcing | 83.25 | 84.00 | 80.25 | 2.536 |
| Self Forcing | 84.27 | 85.10 | 80.97 | 2.543 |
| Reward Forcing | 84.39 | 85.27 | 80.87 | 2.508 |
| Causal Forcing | 84.96 | 86.00 | 80.76 | 2.669 |
| Causal Forcing + CM-GRPO | 85.08 | 86.12 | 80.96 | 2.829 |
| RAVEN | 85.15 | 86.18 | 81.04 | 2.951 |
| RAVEN + CM-GRPO | 85.46 | 86.54 | 81.17 | 2.962 |
RAVEN 本身已经超过所有 causal distillation baselines;CM-GRPO 与 RAVEN 结合后在四个维度都达到最高,说明 RL 增益不是只把质量换成 motion,而是能在 RAVEN 的 aligned history 上补充优化。

Figure 3 解读:图 3 展示 qualitative samples。Causal Forcing 与 Causal Forcing+CM-GRPO 在一些序列中仍有 object identity 或 motion continuity 问题;RAVEN 及 RAVEN+CM-GRPO 对主体形态和动作一致性更稳定,和表 1 中 Dynamic Degree 与 Quality 同升的结果一致。
5.2 Ablations
| Training-time Test variant | Total | Quality | Semantic | Dyn. Deg. |
|---|---|---|---|---|
| Teacher Forcing (TF) | 82.64 | 83.11 | 80.73 | 3.000 |
| Diffusion Forcing (DF) | 84.09 | 84.75 | 81.45 | 2.743 |
| Self Forcing (SF) | 84.06 | 84.68 | 81.56 | 2.347 |
| DF w/ Self Rollout | 83.30 | 83.96 | 80.65 | 2.979 |
| RAVEN | 85.15 | 86.18 | 81.04 | 2.951 |

Figure 4 解读:图 4 与 ablation table 对齐:TF 的 motion 较强但质量/语义低;SF 语义较好但 motion 弱;DF w/ Self Rollout 只对齐历史分布而不监督历史,质量和语义下降;RAVEN 同时使用 self rollout history 和下游 chunk loss 的端到端监督,视觉上更少 drift。
| Chunk weighting | Total | Quality | Semantic | Dyn. Deg. |
|---|---|---|---|---|
| Mode () | 82.58 | 82.86 | 81.43 | 2.996 |
| Mode () | 83.08 | 83.74 | 80.47 | 2.971 |
| Logit-Normal () | 83.31 | 83.97 | 80.65 | 2.963 |
| Shift () | 83.79 | 84.87 | 79.46 | 3.000 |
| Shift () | 83.82 | 84.67 | 80.42 | 2.924 |
| Shift (, Ours) | 85.15 | 86.18 | 81.04 | 2.951 |
| TA | DD | MS | AQ | IQ | Total | Quality | Semantic | Dyn. Deg. |
|---|---|---|---|---|---|---|---|---|
| RAVEN only | - | - | - | - | 85.15 | 86.18 | 81.04 | 2.951 |
| 1 | 0.35 | 0.75 | 1 | 1 | 84.82 | 85.77 | 80.99 | 2.913 |
| 2 | 0.30 | 0.75 | 1 | 1 | 85.07 | 86.14 | 80.81 | 2.957 |
| 2 | 0.35 | 1.00 | 1 | 1 | 85.24 | 86.27 | 81.14 | 2.936 |
| 2 | 0.35 | 0.75 | 2 | 2 | 84.92 | 85.82 | 81.33 | 2.914 |
| 2 | 0.35 | 0.75 | 1 | 1 | 85.46 | 86.54 | 81.17 | 2.962 |
5.3 Human Preference Study
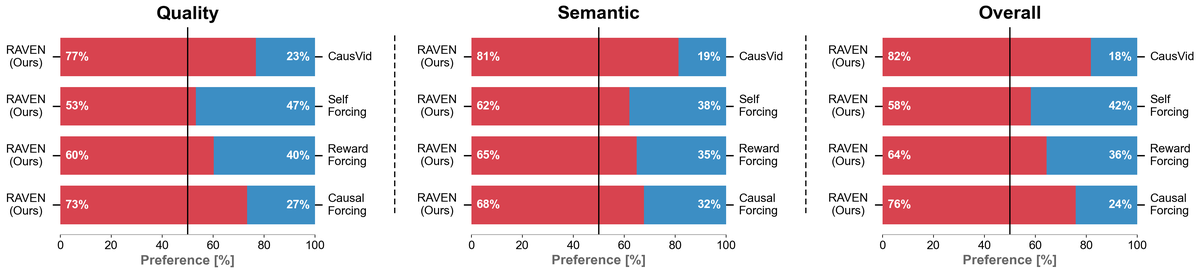
Figure 6 解读:图 6 中 RAVEN 在 Quality、Semantic、Overall 上相对 CausVid、Self Forcing、Reward Forcing、Causal Forcing 都被更多用户偏好;领先在 Semantic 和 Overall 上更明显,说明自动指标提升并非只来自 metric hacking。
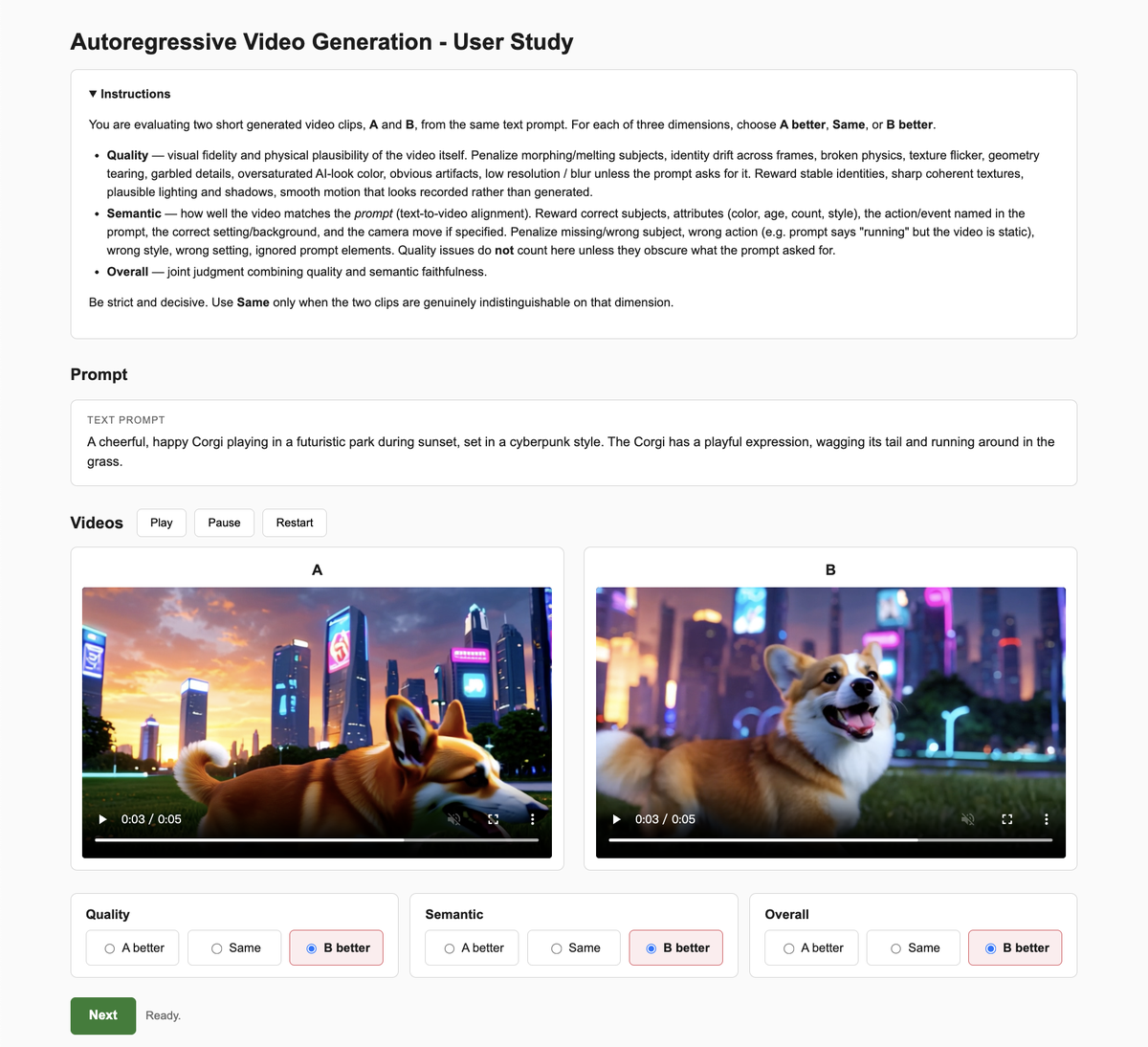
Figure 7 解读:图 7 是用户研究界面,要求标注者在 Quality、Semantic、Overall 三个维度比较 A/B 视频。这个设置补充了 VBench/UnifiedReward 等自动指标,尤其用于验证 long detailed prompts 下的主观偏好。
6. Code Reference (代码对应关系)
| Paper claim / component | Released code evidence |
|---|---|
| RAVEN 使用 rollout trajectory 训练 generator | project/engines/distribution_matching_distillation.py:156-232 构建 slice_rollouts 并保存 (latent_x0s, trajectory_xt, trajectory_pred);388-488 在 gen_use_trajectory=true 时从 trajectory 采样 noisy states 并计算 DMD loss。 |
| 自回归 chunk/cache 与 trajectory 返回 | project/meta_models/causal_wan2_1_t2v.py:588-732 逐 chunk infer,更新 KV cache,并在 return_trajectory=True 时拼接 trajectory_xt / trajectory_pred。 |
| Chunk-wise weighting | project/meta_models/causal_wan2_1_t2v.py:915-1017 对 dmd_losses / policy_losses / kl_losses 按 chunk 拆 loss,计算 reverse cumulative participation,并归一化 raw weights。 |
| CM-GRPO reward aggregation | project/engines/group_relative_policy_optimization.py:159-187 支持 reward_field dict 与 normalize_then_sum;对应 config 的 RAFT/TA/AQ/IQ/MS 权重。 |
| CM-GRPO group advantages | project/engines/group_relative_policy_optimization.py:393-412 对 group rewards 做 mean/std 标准化,并记录 reward gap。 |
| CM-GRPO transition-level policy loss | project/engines/group_relative_policy_optimization.py:434-617 随机选择 policy timestep,取 trajectory_xt[step_idx] 与 next state,调用 transition_kernel,用 clipped advantage 构造 stop-gradient score-gradient loss。 |
| Launch configs | tools/multi_run.sh 统一包装 torchrun;RAVEN 与 CM-GRPO 的入口分别是 configs/trials/distribution_matching_distillation/.../raven.jsonc 与 configs/trials/group_relative_policy_optimization/.../cmgrpo_raven_raft0.35ta2aq1iq1ms0.75.jsonc。 |
Paper-vs-code gap audit:论文中的 reward composition(TA/DD/MS/AQ/IQ)能在 CM-GRPO config 中逐项对应到 videoalign_TA=2.0、raft_RAFT=0.35、ms_MS=0.75、aq_AES=1.0、iq_IMG=1.0;论文中的 Shift() chunk weighting 对应 config 中 chunk_wise_weighting.dmd_losses=-1.0 与 policy_losses=-1.0。未在论文或 config 中发现固定 GPU 数,因此笔记不填具体 GPU count。
7. Takeaways / Limitations (结论与局限)
- 最有价值的点:RAVEN 把自回归视频生成的“历史表示”从 inference-only artifact 变成训练图中的可监督对象,这比简单加入 self-rollout 更关键。
- CM-GRPO 的优势:它不需要为 consistency model 额外构造 Flow-GRPO 风格的辅助 SDE,而是直接对 inference sampler 的 Gaussian transition 做 policy optimization。
- 局限:实验主要围绕 Wan2.1-T2V-1.3B 与 text-to-video streaming;RAVEN 的 history representation 可以扩展到 noisy history、memory tokens、sliding windows / attention sinks,但论文只在 clean chunks as history 的设置下验证。
- 复现注意:release config 使用本地绝对模型路径(
/root/models/...)和自动并行 launcher;复现时需要手动下载 Wan2.1、RAVEN/CM-GRPO checkpoints、VBench/VideoReward/RAFT/Aesthetic/MUSIQ/AMT 权重,并替换 config 中的路径。