目前仅有 README,代码尚未发布。
1. Motivation (研究动机)
自回归长视频生成方法(LongLive、Self-Forcing++)虽然能生成分钟级视频,但都依赖 attention sink frames(KV cache 中保留的初始帧)来稳定生成。然而 sink frames 引入了一个严重的失败模式——sink-collapse:
- Sink-collapse 现象:生成内容在特定帧索引处突然回退到初始帧,产生场景重置和周期性运动循环。例如 LongLive 和 Self-Forcing++ 都在 latent frame index 132 和 201 处发生 collapse,且与输入噪声和 prompt 无关
- 根本原因:RoPE(Rotary Position Embedding)的三角函数周期性导致远距离帧与 sink frames 的 phase 重新对齐,使 attention 机制将当前帧误认为与 sink frames 位置相近
- 现有方法失效:RIFLEx 在双向模型中通过修正单一频率维度解决重复问题,但在自回归设定中完全失效——因为 sink-collapse 不是由单一维度引起,而是多维度的集体相位对齐
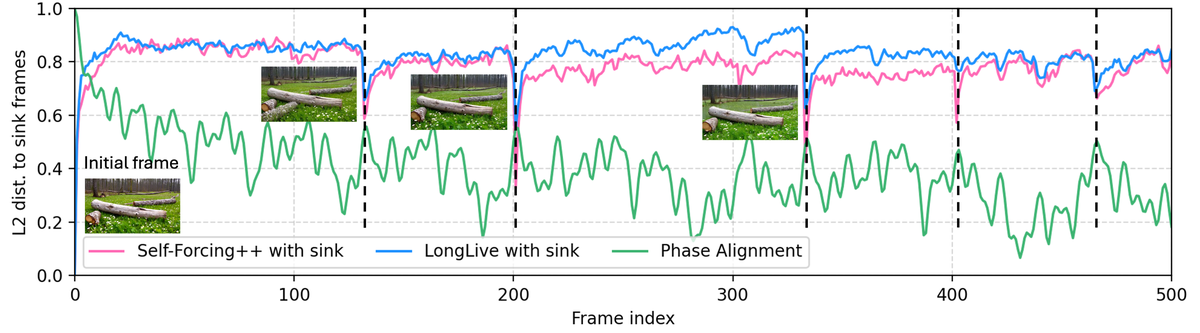
Figure 2 解读:横轴为帧索引,左纵轴为到 sink frames 的归一化 L2 距离(粉色线 = Self-Forcing++,蓝色线 = LongLive),右侧绿色线为 RoPE phase concentration。关键发现:L2 距离的剧烈下降(即 sink-collapse)几乎精确对应 phase concentration 的局部极大值。在帧索引 ~132 和 ~201 处,Self-Forcing++ 和 LongLive 的 L2 距离同时骤降至 ~0.4,画面突变回初始帧。这证明 sink-collapse 与 RoPE 的周期性相位对齐直接相关。

Figure 3 解读:展示同一 DiT 层、同一 diffusion step 下不同 attention head 的注意力热力图(KV cache size=12,前 3 帧为 sink tokens)。上行(正常帧):各 head 将注意力权重主要分配给正在生成的最后 3 帧(自注意力),对 sink frames 的关注较小且分布均匀——不同 head 捕获了不同的表征子空间。中、下行(sink-collapse 帧):几乎所有 head 同时将极高权重分配给 sink frames(前 3 帧),形成 inter-head attention homogenization(跨头注意力同质化),导致模型从所有子空间同时复制 sink frames,产生场景突变。
2. Idea (核心思想)
LoL 的核心 insight:sink-collapse 源于 RoPE 周期性导致的多头注意力同质化——当所有 head 在同一帧位置对 sink frames 产生相同的高 phase concentration 时,注意力多样性退化为全局同步复制。
解决方案极其简洁:Multi-Head RoPE Jitter——对每个 attention head 施加不同的 RoPE base 扰动,打破跨头的全局相位对齐。
核心特性:
- Training-free:不需要重新训练,仅在推理时修改 RoPE 频率
- 即插即用:兼容 LongLive 和 Self-Forcing++ 等现有模型
- 无限长度:结合 streaming RoPE generation、动态噪声采样和 3D causal VAE decoder,实现无限长度的流式视频生成
与现有 position embedding 扩展方法的根本区别:
- PI(Position Interpolation):压缩频率有效抑制 collapse,但导致运动严重停滞(Dynamic Degree 从 34.62 降到 0.35)
- NTK / YARN:在 collapse 缓解和运动保持之间做不同权衡,但无法同时做好两者
- RIFLEx:假设问题由单一频率维度主导,在双向模型上有效,但在自回归设定中完全失败
- LoL(本文):通过打破跨头同步,在保持运动动态的同时有效缓解 collapse
3. Method (方法)
3.1 背景:RoPE 与 Sink Frames
RoPE 对 position index 、channel dimension 的旋转定义为:
其中 (标准 base), 为隐藏维度。注意力依赖相对位置差:
Sink Frames(来自 StreamingLLM):在 rolling KV cache 中保留最初的几帧(通常 3 帧),它们始终保持 position index 不变。这增强了长期稳定性,但当生成帧 与 sink 帧 的相对位移 满足 RoPE 的周期性对齐条件时,就会触发 sink-collapse。
3.2 Sink-Collapse 的两层机制
Intra-head phase concentration(头内相位集中):定义 phase coherence kernel:
其中 为 RoPE 频率,。Sink-relative phase concentration 为 。当 取局部极大值时,多个频率分量同时相位对齐,导致 sink frame 在注意力计算中获得异常高的权重。
Inter-head attention homogenization(头间注意力同质化):所有 head 使用相同的 ,因此在相同帧位置同时经历高 phase concentration。当所有 head 的注意力同时偏向 sink frames 时,模型从所有子空间复制 sink frames,导致全局退化。
3.3 Multi-Head RoPE Jitter

Figure 1 解读:核心算法伪代码。对每个 head ,从均匀分布 采样随机扰动 ,然后计算扰动后的 base ,用扰动后的 base 计算该 head 的全部 RoPE 频率 ,最后对 Q、K 应用旋转。关键参数 为最佳 jitter 强度。
import torch
import numpy as np
def multi_head_rope_jitter(Q, K, base_theta=10000, sigma=0.8, d_time=None):
"""
LoL: Multi-Head RoPE Jitter — training-free sink-collapse mitigation.
Args:
Q: (B, T, H, D) query tensor
K: (B, T, H, D) key tensor
base_theta: RoPE base frequency (default 10000)
sigma: jitter scale (default 0.8)
d_time: temporal dimension count (default D)
Returns:
Q_rot, K_rot: rotated Q and K with head-wise perturbed frequencies
"""
B, T, H, D = Q.shape
if d_time is None:
d_time = D
# Frequency exponents: nu_i = -2i / d_time for i in [0, D/2)
nu = -2.0 * torch.arange(D // 2, device=Q.device) / d_time # (D/2,)
# Position indices
positions = torch.arange(T, device=Q.device).float() # (T,)
Q_heads, K_heads = [], []
for h in range(H):
# Sample random perturbation for this head
eps_h = torch.empty(1, device=Q.device).uniform_(-1, 1)
# Perturbed base for this head
theta_h = base_theta * (1.0 + sigma * eps_h)
# Head-specific frequencies: omega_h[i] = theta_h^(nu_i)
omega_h = theta_h ** nu # (D/2,)
# Compute rotation angles: (T, D/2)
angles = positions.unsqueeze(-1) * omega_h.unsqueeze(0)
# Apply rotation to Q and K for this head
q_h = Q[:, :, h, :] # (B, T, D)
k_h = K[:, :, h, :]
q_rot = apply_rope_rotation(q_h, angles)
k_rot = apply_rope_rotation(k_h, angles)
Q_heads.append(q_rot)
K_heads.append(k_rot)
Q_rot = torch.stack(Q_heads, dim=2) # (B, T, H, D)
K_rot = torch.stack(K_heads, dim=2)
return Q_rot, K_rot
def apply_rope_rotation(x, angles):
"""Apply RoPE rotation given precomputed angles."""
# x: (B, T, D), angles: (T, D/2)
B, T, D = x.shape
x_pairs = x.reshape(B, T, D // 2, 2)
cos_a = torch.cos(angles).unsqueeze(0) # (1, T, D/2)
sin_a = torch.sin(angles).unsqueeze(0)
x0 = x_pairs[..., 0] # (B, T, D/2)
x1 = x_pairs[..., 1]
out0 = x0 * cos_a - x1 * sin_a
out1 = x0 * sin_a + x1 * cos_a
return torch.stack([out0, out1], dim=-1).reshape(B, T, D)
def streaming_infinite_generation(
model, prompt, sink_frames=3, local_window=9, sigma=0.8, fps=20
):
"""
LoL infinite streaming video generation pipeline.
Key components:
1. Rolling KV cache with sink frames
2. Multi-Head RoPE Jitter (this paper)
3. Streaming noise sampling
4. 3D Causal VAE sliding-window decoding
"""
kv_cache = None
frame_idx = 0
chunk_size = local_window # 9 latent frames per chunk
while True: # infinite loop
# Sample noise for this chunk
noise = torch.randn(1, chunk_size, C, H, W)
# Build position indices for RoPE
# Sink frames: positions [0, 1, 2] (fixed)
# Generation frames: positions [frame_idx, ..., frame_idx + chunk_size - 1]
sink_positions = torch.arange(sink_frames)
gen_positions = torch.arange(frame_idx, frame_idx + chunk_size)
positions = torch.cat([sink_positions, gen_positions])
# Denoise with multi-head RoPE jitter
# Inside model attention: replace standard RoPE with jittered RoPE
clean_latents = model.denoise(
noise,
prompt=prompt,
kv_cache=kv_cache,
positions=positions,
rope_jitter_sigma=sigma # <-- LoL's contribution
)
# Decode latents to pixels via 3D Causal VAE (sliding window)
video_frames = model.vae.decode_streaming(clean_latents)
yield video_frames # stream output
# Update rolling KV cache
# Keep sink frames + replace generation frames with new ones
kv_cache = update_rolling_cache(kv_cache, clean_latents, sink_frames)
frame_idx += chunk_size源码参考:GitHub repo 目前仅有 README。推理基于 LongLive 和 Self-Forcing 的代码框架,LoL 仅需修改 attention 层中的 RoPE 计算。
3.4 Infinite Streaming Generation
除 Multi-Head RoPE Jitter 外,实现无限长度生成还依赖两个架构特性:
- 3D Causal VAE:Wan2.1 的 VAE 具有时间因果性,支持 sliding-window decoding,内存消耗恒定不随视频长度增加
- Local Attention:模型仅对最近 个 latent frames 做 attention(3 sink + 9 generation),注意力只依赖相对位置差,因此 RoPE 和噪声可以在推理时动态流式采样
3.5 不同 PE 扩展方法对比

Figure 4 解读:对比五种方法的长视频生成效果。每行左侧为 L2 距离曲线,右侧为生成帧截图。PE(Position Extrapolation):L2 距离在 ~132 帧处骤降,画面回退到雪山初始帧(红框标注 sink-collapse)。PI:L2 距离平稳,但画面几乎静止(运动大幅减弱)。NTK:仍存在 sink-collapse。RIFLEx:collapse 严重程度与 PE 接近。Ours(LoL):L2 距离平稳且保持高值,画面持续变化无 collapse。LoL 是唯一同时消除 collapse 并保持运动动态的方法。
3.6 代码-论文映射
| 论文概念 | 源码/参考 | 说明 |
|---|---|---|
| RoPE 基础旋转 | 论文 Eq. 2-4 | 标准 RoPE 定义 |
| Phase Coherence Kernel | 论文 Eq. 5 | 量化多维度相位对齐程度 |
| Multi-Head RoPE Jitter | 论文 Algorithm 1 | 核心贡献,修改 attention 层的 RoPE |
| DMD 训练 | 论文 Eq. 1, LongLive/Self-Forcing++ | LoL 本身不涉及训练 |
| Streaming Generation | 论文 Section 3.4 | Causal VAE + Local Attention + 动态 RoPE |
| Sink-Collapse 指标 | 论文 Section 4.1 | 基于 RIFLEx 的 No-Repeat score 改进 |
4. Experimental Setup (实验设置)
- 基础模型: Wan2.1-T2V-1.3B(1.3B 参数,经 DMD 蒸馏)
- 应用对象: LongLive 和 Self-Forcing++(两个 SOTA 超长视频模型)
- 推理配置:
- Local attention window: 12 latent frames(3 sink + 9 generation)
- 帧率: 20 FPS(单张 NVIDIA H100)
- Jitter 强度:
- Jitter 比例: 100% heads
- Baselines:
- PE 扩展方法: PE(直接外推)、PI、NTK、YARN、RIFLEx
- 自回归视频模型: NOVA (0.6B)、MAGI-1 (4.5B)、SkyReels-V2 (1.3B)、CausVid、Self-Forcing、Self-Forcing++、LongLive
- 评估指标:
- Sink-Collapse Max: 最差 prompt 的最大 L2 距离下降(越低越好)
- Sink-Collapse Avg: 所有 prompt 平均 L2 距离下降(越低越好)
- Dynamic Degree: 运动幅度(越高越好)
- Temporal Quality / Text Alignment / Framewise Quality: VBench 标准维度
- 评估设置: 128 prompts(MovieGen),75s 和 100s 视频
5. Experimental Results (实验结果)
PE 扩展方法对比(100s 视频,Table 1)
Results on LongLive:
| Method | Sink-Collapse Max↓ | Sink-Collapse Avg↓ | Dynamic Degree↑ | Temporal Quality↑ | Imaging Quality |
|---|---|---|---|---|---|
| PE | 73.06 | 30.54 | 34.62 | 88.56 | 69.59 |
| PI | 4.97 | 2.27 | 0.35 | 85.25 | 56.47 |
| NTK | 41.11 | 11.64 | 28.72 | 87.95 | 69.83 |
| YARN | 11.17 | 5.08 | 2.67 | 85.17 | 68.89 |
| RIFLEx | 70.95 | 29.93 | 35.11 | 88.61 | 69.47 |
| Ours (LoL) | 16.67 | 3.93 | 35.27 | 88.69 | 69.45 |
Results on Self-Forcing++:
| Method | Sink-Collapse Max↓ | Sink-Collapse Avg↓ | Dynamic Degree↑ | Temporal Quality↑ | Imaging Quality |
|---|---|---|---|---|---|
| PE | 68.07 | 34.11 | 83.32 | 93.14 | 63.06 |
| PI | 17.07 | 2.62 | 1.95 | 84.66 | 69.80 |
| NTK | 49.65 | 14.96 | 82.90 | 93.04 | 62.86 |
| YARN | 33.04 | 6.69 | 36.71 | 88.29 | 67.50 |
| RIFLEx | 66.56 | 32.86 | 82.36 | 93.01 | 63.26 |
| Ours (LoL) | 22.70 | 6.12 | 81.20 | 92.91 | 62.92 |
关键发现:
- LoL 的 Sink-Collapse Avg 接近 PI(3.93 vs 2.27 on LongLive),但 Dynamic Degree 保持与 PE 相当(35.27 vs 34.62 on LongLive)
- PI 虽然 collapse 最低,但运动几乎完全停滞(Dynamic Degree 0.35 / 1.95)
- RIFLEx 在自回归设定下完全失效(collapse 与 PE 接近)
- LoL 是唯一在 collapse 和 motion 两个维度都表现优良的方法
自回归模型对比(Table 2)
100s 视频:
| Model | Text Alignment↑ | Temporal Quality↑ | Dynamic Degree↑ | Framewise Quality↑ |
|---|---|---|---|---|
| NOVA | 22.89 | 86.24 | 31.09 | 31.03 |
| MAGI-1 | 23.75 | 87.62 | 22.21 | 50.90 |
| SkyReels-V2 | 22.05 | 88.80 | 38.75 | 50.48 |
| CausVid | 24.41 | 89.06 | 34.60 | 61.01 |
| Self-Forcing | 22.00 | 87.39 | 26.41 | 58.25 |
| Self-Forcing++ | 26.04 | 90.87 | 54.12 | 60.66 |
| LongLive | 28.09 | 88.56 | 34.62 | 64.05 |
| Self-Forcing++ (LoL) | 27.38 | 92.91 | 81.20 | 60.25 |
| LongLive (LoL) | 27.80 | 88.69 | 35.27 | 63.76 |
- Self-Forcing++ (LoL) 的 Dynamic Degree 达到 81.20,远超所有 baseline(最高 54.12)
- Temporal Quality 92.91 为所有方法最高
- 加入 LoL 后 Text Alignment 基本不降,Framewise Quality 损失极小
消融实验
单维度无法解决(Figure 5a):

Figure 5a 解读:修改 RIFLEx 识别的维度 及其邻近维度()的频率后,L2 距离曲线仍然存在严重的周期性下降。无论修改哪个单一维度,sink-collapse 都无法缓解。这证明问题是多维度集体对齐导致的。
改变 RoPE base 无效(Figure 5b):

Figure 5b 解读:将 从 6000 变到 20000,sink-collapse 的位置随 base 值移动(如 在更早帧索引处 collapse),但现象本身不消失。改变 base 只是延迟或提前 collapse,不能根治。
Jitter 强度 (Figure 6a):

Figure 6a 解读:横轴为帧索引(100-800),纵轴为到 sink frames 的 L2 距离。 时仍有显著 collapse; 时 collapse 减轻但在 ~750 帧处仍可见; 时曲线平稳,无显著下降; 时进一步缓解但可能牺牲运动/质量。 为最佳平衡点。
Jitter Head 比例(Figure 6b):
Figure 6b 解读:横轴为帧索引,不同曲线对应不同比例的 jittered heads(10%/40%/70%/100%)。随着 jitter heads 增加,collapse 逐渐缓解。100% heads jitter 效果最好,证明 sink-collapse 是全局性的而非局限于少数 head。
12 小时生成展示

Figure 7 解读:展示 12 小时连续生成的视频截帧(翼装飞行穿越山谷),每小时一组画面。从 t=0 到 t=12 小时,场景持续变化且保持视觉质量——无场景重置、无运动停滞。这是目前公开展示的最长流式视频生成结果。

Figure 8 解读:展示另一组 12 小时长程生成样例(雪山场景)。画面在长时间跨度内保持连贯,说明方法可以在不同场景下维持持续生成,而不是在固定帧索引处反复回退到初始状态。

Figure 9 解读:展示 12 小时海洋生物样例(jellyfish)。与前面的长程示例一致,这组结果强调的是长时间滚动生成仍能持续产出变化中的画面,而不是陷入周期性重置。
局限性
- 无长程记忆:物体离开画面后重新出现时无法保持一致性
- 基础模型容量有限:1.3B 参数的蒸馏模型在 12 小时生成中视觉多样性下降
- Training-free 的天花板:仅在推理时操作,无法通过微调进一步优化
- 生成速度:单 GPU 约 16 FPS
- 可控性有限:缺乏强控制信号(如轨迹控制)