Context Forcing: Consistent Autoregressive Video Generation with Long Context
Authors: Shuo Chen, Cong Wei, Sun Sun, Ping Nie, Kai Zhou, Ge Zhang, Ming-Hsuan Yang, Wenhu Chen Affiliations: UC Merced, University of Waterloo, Netmind.AI, M-A-P arXiv: 2602.06028 Project Page: chenshuo20.github.io/Context_Forcing GitHub: TIGER-AI-Lab/Context-Forcing Year: 2026
1. Motivation (研究动机)
1.1 问题背景
当前实时长视频生成方法普遍采用 streaming tuning 策略:用短上下文(约5秒)的 teacher 来训练长上下文的 student。这造成了一个根本性的 student-teacher mismatch:teacher 无法看到完整的生成历史,因此无法指导 student 学习全局时间依赖关系,有效地限制了 student 可学习的上下文长度。
这种不匹配导致了作者定义的 Forgetting-Drifting Dilemma:
- Forgetting(遗忘): 限制模型使用短记忆窗口可以减少 error accumulation,但会导致模型丢失之前的主体和场景信息,生成结果缺乏长期一致性
- Drifting(漂移): 保持长上下文可以维持身份一致性,但在没有能纠正长程误差的 teacher 的情况下,模型暴露在自身累积的错误中,视频分布逐渐偏离真实数据流形

Figure 1 解读: 该图展示了 Forgetting-Drifting Dilemma。左侧对比了不同方法在 50 秒视频中的帧质量:LongLive(context 3.0s)和 LongLive(context 3.75s, 5.25s)分别展示了 forgetting(场景/角色不一致)和 drifting(画面渐变失真)的问题。Context Forcing(context 20s+)在整个序列中保持了一致的角色外观和背景。右侧的 DINOv2 和 CLIP-F 曲线定量验证了这一点:Context Forcing 在整个时间轴上维持了稳定的高分,而其他方法随时间急剧下降。
1.2 现有方案的不足
- Self-Forcing [Huang et al., 2025]: short teacher → short student,只能生成约5秒视频,无法长程外推
- LongLive [Yang et al., 2025]: short teacher → long student(memoryless long tuning),teacher 无法看到历史,无法修正长程误差
- Infinity-RoPE [Yesiltepe et al., 2025]: 通过修改位置编码减少 error accumulation,但有效上下文仅约1.5秒
- Rolling Forcing [Liu et al., 2025]: 有效上下文约6秒,依然有限
- FramePack [Zhang & Agrawala, 2025]: 有效上下文约9.2秒,通过帧压缩延长,但压缩损失信息
1.3 关键洞察
根本原因在于 teacher 的能力不足:现有方法的 teacher 只能处理短窗口(~5s),而 student 需要在长序列上进行 rollout。解决方案应该是让 teacher 也具备长上下文能力,从而实现 long teacher → long student 的蒸馏范式。

Figure 2 解读: 三种训练范式的对比。(a) Self-Forcing:short teacher → short student,teacher 和 student 都只看短片段。(b) Memoryless Long Tuning(如 LongLive):short teacher → long student,student 做长序列 rollout 但 teacher 只能在短窗口内提供监督,造成 student-teacher mismatch。(c) Context Forcing(本文):long teacher → long student,teacher 和 student 都配备了 Memory 模块,teacher 能看到完整生成历史并提供全局指导,彻底消除了监督不匹配问题。
2. Idea (核心思想)
Context Forcing 提出了一个完整的框架来实现 long teacher → long student 的蒸馏:
- 两阶段训练课程: Stage 1 学习局部动态(Local DMD),Stage 2 通过 Contextual DMD 在长 rollout 上进行上下文蒸馏
- Slow-Fast Memory: 基于双过程记忆理论的 KV cache 管理系统,将线性增长的上下文压缩为固定大小的三段式缓存(Attention Sink + Slow Memory + Fast Memory)
- Robust Context Teacher: 通过 Error-Recycling Fine-Tuning (ERFT) 增强 teacher 对漂移输入的鲁棒性
核心结果:有效上下文长度超过 20秒,是 SOTA 方法的 2-10倍(LongLive 3.0s, Infinity-RoPE 1.5s, FramePack 9.2s)。
3. Method (方法)
3.1 问题形式化
在因果自回归框架下,长视频 被分解为一系列条件步骤:
目标是最小化全局 KL 散度:
通过 chain rule 分解为两部分:
这个分解自然地对应了两阶段训练:Stage 1 优化 ,Stage 2 优化 。
3.2 Stage 1: Local Distribution Matching
在短窗口(1-5秒)上,使用标准 DMD 将双向 teacher 蒸馏到因果 student:
梯度估计:
其中 是 student 从噪声 生成的结果, 是其加噪版本, 和 分别是 student 和 teacher 的 score function。
3.3 Stage 2: Contextual Distribution Matching (核心创新)
Contextual DMD 目标
Stage 2 优化 ,关键在于 student 在自身生成的上下文上训练,teacher 也能看到同样的上下文:
关键点:期望是在 上取的,即 student 自己的 rollout 结果作为上下文,这直接缓解了 exposure bias。
Score-based CDMD Gradient
注意 fake score 和 real score 都以相同的 student 生成上下文 为条件,确保了监督的一致性。
两个关键假设
- Assumption 1 (Teacher reliability near student contexts): 当 接近真实数据流形时,teacher 的续写 是准确的
- Assumption 2 (Approximate real prefixes): Stage 1 成功地将 与 对齐,保证 student 的 rollout 落在 teacher 的可靠区域内
Long Self-Rollout Curriculum
直接让 取很大值会导致训练早期的严重分布偏移。因此采用动态 horizon schedule:
每次迭代,rollout 长度 ,从 Stage 1 的稳定区间开始,逐步扩展到 10-30 秒。
Clean Context Policy
- Target frames :使用完整 denoising 步数 ,保证目标输出稳定
- Context frames :使用随机 exit timestep ,提升 teacher 对上下文分布的鲁棒性
- 这一策略确保 context 既覆盖真实 rollout 分布,又不会引入过多噪声
3.4 Slow-Fast Memory 机制
三段式 KV Cache
Context Forcing 将 KV cache 分为三部分:
| 模块 | 容量 | 作用 | 策略 |
|---|---|---|---|
| Attention Sink () | 保留初始 token 稳定注意力 | 永不更新 | |
| Slow Memory () | 存储高信息量的关键帧 | Surprisal-based consolidation | |
| Fast Memory () | FIFO 队列,捕捉最近局部上下文 | 先进先出 |
总计 21 个 latent frame slots。
Surprisal-Based Consolidation
当新 token 进入 Fast Memory 后,通过 key vector 相似度评估其信息价值:
其中 是相似度阈值。低相似度 = 高 surprisal = 表示场景转换或显著变化,这些 token 被提升到 Slow Memory;高相似度的 token 被认为是冗余的,不需要长期保留。
当 时,最老的 entry 被驱逐。Consolidation 在每 2 个 chunk 间隔执行一次,每次只保留第一个 latent。
Bounded Positional Encoding
与标准 AR 视频模型的无界位置编码()不同,Context Forcing 采用 Bounded Positional Indexing:
所有 token 的 temporal RoPE position 被约束在固定范围 内,无论生成到第几步。这创造了一个静态的 attention window:Fast Memory 的高 index 不断滑动,Slow Memory 压缩到低 index,稳定了长序列上的注意力分布。
3.5 Robust Context Teacher (ERFT)
标准训练在 clean context 上条件化,但推理时 teacher 面对的是 student 自生成的(可能包含误差的)context。为消除这一 exposure bias,采用 Error-Recycling Fine-Tuning (ERFT):
构造扰动上下文:
其中 从过去模型残差的 bank 中采样, 是 Bernoulli indicator。Teacher 被优化为从 恢复正确的 velocity 。
4. Experimental Setup (实验设置)
4.1 训练设置
- Stage 1: 使用 VidProM 数据集的 81 帧片段,batch size 64,训练 600 iterations
- Stage 2: 采用动态 horizon schedule,rollout 长度 ,从 Stage 1 的稳定区间逐步扩展到 10-30 秒
- Teacher 训练: 使用 Wan2.1-T2V-1.3B 作为基础模型,在 40k 高质量视频(>10s,来自 Sekai + Ultravideo)上训练 8k steps,batch size 8,采样 5-20 秒区间的帧作为 context
4.2 评估设置
- 短视频评估: 5 秒生成结果,报告 Total、Quality、Semantic、BG Consistency、Subject Consistency
- 长视频评估: 60 秒单 prompt 生成,报告 Background Consistency、Subject Consistency,以及 DINOv2 / CLIP-F / CLIP-T 时间轴指标
- 消融实验: 主要考察 Contextual Distillation、Bounded Positional Encoding、Surprisal-based selection 和 ERFT 的贡献
4.3 论文未详细说明
- 更细的优化器设置、学习率、采样器参数和训练硬件配置:论文未详细说明
- 60s 之外更长视频的系统性评测:论文未详细说明
5. Experimental Results (实验结果)
5.1 Context Teacher 验证
将 Stage 1 student 生成的视频喂给 context teacher,teacher 能有效续写下一段视频,验证了 Assumption 1 和 2 的合理性。
5.2 短视频(5s)性能
| Model | Params | Total | Quality | Semantic | BG Consistency | Subject Consistency |
|---|---|---|---|---|---|---|
| LTX-Video | 1.9B | 80.00 | 82.30 | 70.79 | 95.30 | 95.01 |
| CausVid | 1.3B | 81.20 | 84.05 | 69.80 | 95.12 | 95.96 |
| Self Forcing (chunk-wise) | 1.3B | 84.31 | 85.07 | 81.28 | 95.98 | 96.29 |
| Ours, student | 1.3B | 83.44 | 84.98 | 77.29 | 97.38 | 96.84 |
5秒短视频上性能与 baseline 持平或略优,说明 Context Forcing 没有牺牲短视频质量。
5.3 长视频(60s)性能
Table 1: 60秒单 prompt 视频一致性评估
| Model | Context Length | BG Consistency | Subject Consistency |
|---|---|---|---|
| FramePack-F1 | 9.2s | 91.61 | 89.15 |
| LongLive | 3.0s | 94.92 | 93.05 |
| Infinity-RoPE | 1.5s | 92.42 | 90.11 |
| Ours, teacher | 20s+ | 95.24 | 94.67 |
| Ours, student | 20s+ | 95.95 | 95.68 |
Student 模型在 60 秒视频上的背景一致性和主体一致性均达到最佳。
细粒度时间轴指标(DINOv2 / CLIP-F / CLIP-T): Context Forcing 在 10s-60s 的整个时间轴上都保持了稳定的高分,而 LongLive 等方法随时间显著下降。

Figure 4 解读: 1分钟视频生成的定性对比。从上到下分别是 LongLive(context 10s)、Rolling Forcing(context 6.0s)、Infinity-RoPE(context 1.5s)、FramePack-F1(context 9.2s)和 Ours(context 20s+)。可以看到:LongLive 在后半段出现主体身份变化(紫色机器人变形);Rolling Forcing 和 Infinity-RoPE 出现背景漂移和角色一致性下降;FramePack 有轻微场景变化;Context Forcing 在整个 60s 中保持了一致的紫色机器人外观和城市背景。
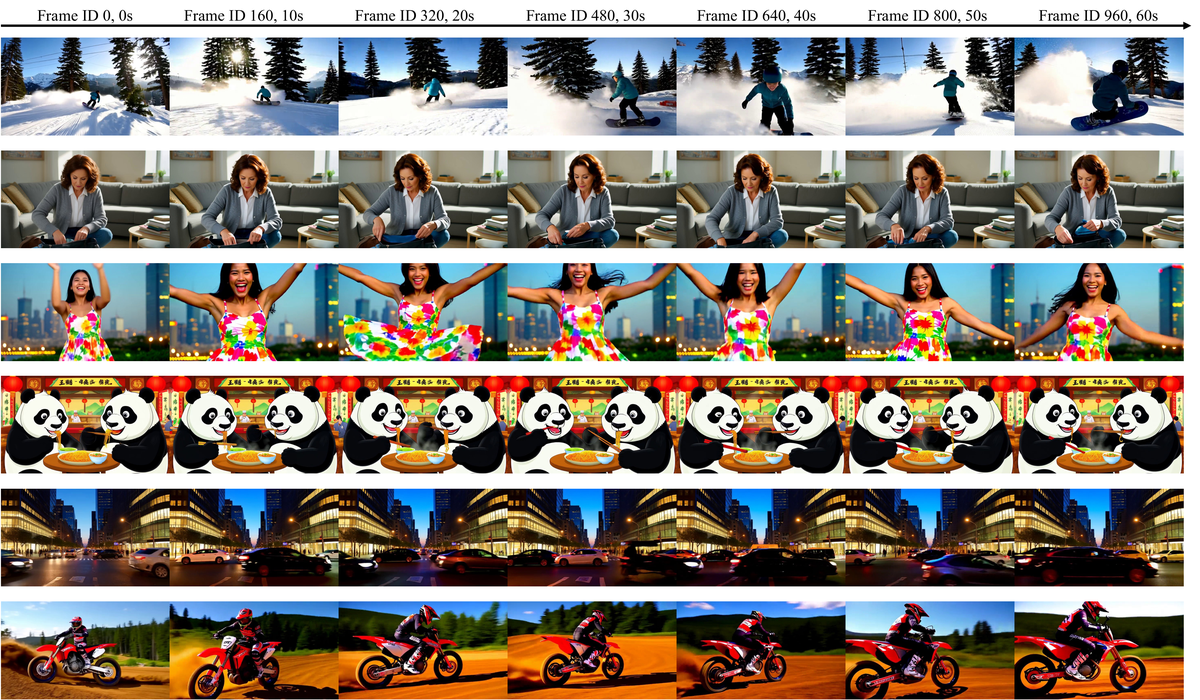
Figure 5 解读: Context Forcing 的更多定性结果。展示了 4 个不同场景的 60 秒生成结果,涵盖户外风景(雪山+女性)、卡通(奔跑的熊猫)、动物(两只猫嬉戏)、运动(摩托车越野)等多样化场景。每个场景在 0s-60s 的全时间轴上都保持了角色一致性和场景连贯性,证明了方法的泛化能力。
5.4 Ablation Studies
Table 3: Ablation 结果(60s 视频)
| Configuration | Total | Semantic | BG Consistency | Subject Consistency | Dynamic Degree |
|---|---|---|---|---|---|
| Uniform sample, interval 1 | 80.82 | 75.32 | 92.45 | 92.10 | 52.15 |
| Uniform sample, interval 2 | 81.11 | 75.12 | 93.12 | 92.85 | 55.90 |
| w/o Contextual Distillation | 80.36 | 72.70 | 93.55 | 93.20 | 48.12 |
| w/o Bounded Positional Encoding | 73.52 | 65.82 | 84.68 | 79.24 | 27.45 |
| Ours (full) | 82.45 | 76.10 | 95.34 | 94.88 | 58.26 |
关键发现:
- Bounded Positional Encoding 至关重要: 移除后背景一致性从 95.34 暴降至 84.68,动态程度从 58.26 降至 27.45
- Contextual DMD 显著提升语义一致性: 移除后 Semantic 从 76.10 降至 72.70
- Surprisal-based selection 优于 uniform sampling: 基于相似度的选择策略在所有指标上优于固定间隔采样

Figure 7 解读: ERFT 的消融实验。上排(w. ERFT)和下排(w/o ERFT)对比了 context teacher 在接收 student 生成的 5s 视频作为输入后,续写 0-30s 视频的质量。有 ERFT 的 teacher 生成的续写更加清晰自然,而没有 ERFT 的 teacher 产生了明显的 artifacts 和失真,说明 ERFT 对于 teacher 鲁棒性的重要性。
6. Limitations & Future Work
- 记忆压缩策略仍有优化空间: 当前的 Surprisal-Based Consolidation 基于简单的 key 相似度阈值,对信息密度的建模较为粗糙。未来可以探索可学习的 context compression 和自适应记忆保留机制
- 代码尚未完全开源: 截止目前,GitHub 仓库仍在整理中,inference code 和 checkpoints 待发布
- 基础模型规模有限: 实验仅在 Wan2.1-T2V-1.3B 上验证,更大规模模型上的效果有待探索
- 固定 cache 大小的限制: 21 个 latent frame 的 cache 在更长视频(>2min)上是否足够仍需验证
7. Figure 解读汇总
| Figure | 文件名 | 内容 |
|---|---|---|
| Fig 1 | teaser_v1.svg | Forgetting-Drifting Dilemma 的定性和定量展示 |
| Fig 2 | context_explain.svg | 三种训练范式对比(Self-Forcing / Memoryless / Context Forcing) |
| Fig 3 | pipeline_v1.svg | 整体训练流程 + Slow-Fast Memory 的 KV cache 管理机制 |
| Fig 4 | long_compare_v3.png | 1分钟视频生成的定性对比(5种方法) |
| Fig 5 | main_demo_v3.png | Context Forcing 多场景 60s 生成结果展示 |
| Fig 6 | context_demo_v1.png | Context Teacher 续写验证 |
| Fig 7 | erft_ablation_v1.svg | ERFT 消融实验 |
| Fig 8 | longlive_back_v1.svg | LongLive 的视觉 artifacts(闪回现象) |
8. Python Pseudocode
import torch
import torch.nn.functional as F
from dataclasses import dataclass
@dataclass
class SlowFastMemoryConfig:
n_sink: int = 3 # Attention Sink slots
n_slow: int = 12 # Slow Memory (context) slots
n_fast: int = 6 # Fast Memory (local) slots
sim_threshold: float = 0.95 # Surprisal threshold tau
consolidation_interval: int = 2 # Chunk interval for consolidation
class SlowFastMemory:
"""Slow-Fast Memory: KV cache management with three-part structure."""
def __init__(self, config: SlowFastMemoryConfig):
self.cfg = config
self.sink_kv = None # [B, N_s, H, D] - never updated after init
self.slow_kv = [] # list of (k, v) tuples, up to N_c
self.fast_kv = [] # FIFO queue, up to N_l
self.chunk_counter = 0
def initialize(self, first_kv_pairs):
"""Fill sink with first N_s tokens, rest into slow/fast."""
self.sink_kv = first_kv_pairs[:self.cfg.n_sink]
remaining = first_kv_pairs[self.cfg.n_sink:]
# Fill slow memory first, then fast
self.slow_kv = list(remaining[:self.cfg.n_slow])
self.fast_kv = list(remaining[self.cfg.n_slow:
self.cfg.n_slow + self.cfg.n_fast])
def update(self, new_k, new_v):
"""
Process a new token: add to fast memory (FIFO),
then potentially consolidate to slow memory.
"""
# --- Fast Memory: FIFO update ---
self.fast_kv.append((new_k, new_v))
if len(self.fast_kv) > self.cfg.n_fast:
evicted = self.fast_kv.pop(0) # FIFO eviction
# --- Surprisal-Based Consolidation ---
self.chunk_counter += 1
if self.chunk_counter % self.cfg.consolidation_interval == 0:
self._consolidate(new_k)
def _consolidate(self, current_key):
"""Promote high-surprisal tokens from fast to slow memory."""
if len(self.fast_kv) < 2:
return
prev_key = self.fast_kv[-2][0] # previous token's key
similarity = F.cosine_similarity(
current_key.flatten(), prev_key.flatten(), dim=0
)
if similarity < self.cfg.sim_threshold:
# High surprisal -> consolidate to slow memory
token_to_promote = self.fast_kv[-1]
self.slow_kv.append(token_to_promote)
if len(self.slow_kv) > self.cfg.n_slow:
self.slow_kv.pop(0) # evict oldest slow entry
def get_bounded_positions(self):
"""
Bounded Positional Encoding: constrain all positions
to fixed range [0, N_s + N_c + N_l - 1].
"""
positions = []
# Sink: [0, N_s - 1]
positions.extend(range(self.cfg.n_sink))
# Slow: [N_s, N_s + N_c - 1]
for j in range(len(self.slow_kv)):
positions.append(self.cfg.n_sink + j)
# Fast: [N_s + N_c, N_s + N_c + N_l - 1]
for k in range(len(self.fast_kv)):
positions.append(self.cfg.n_sink + self.cfg.n_slow + k)
return positions
def get_full_kv(self):
"""Concatenate all KV pairs for attention."""
all_kv = list(self.sink_kv) + self.slow_kv + self.fast_kv
keys = torch.cat([kv[0] for kv in all_kv], dim=1)
values = torch.cat([kv[1] for kv in all_kv], dim=1)
return keys, values
def contextual_dmd_training_step(
student_model, # AR diffusion model G_theta
fake_score_fn, # s_theta (student score)
real_score_fn, # s_T (teacher score)
memory_student, # SlowFastMemory for student
memory_teacher, # SlowFastMemory for teacher
prompt, # text prompt
rollout_length, # k: number of chunks to rollout
noise_schedule, # {t_1, ..., t_T}
teacher_length, # l: teacher context window
):
"""
Algorithm 1: One step of Contextual DMD training (Stage 2).
"""
generated_frames = []
student_kv_cache = memory_student
teacher_kv_cache = memory_teacher
# --- Phase 1: Long self-rollout to build context X_{1:k} ---
for i in range(rollout_length):
# Sample noise
z_i = torch.randn_like(template_frame) # x^i_1 ~ N(0, I)
# Random exit timestep for target, full denoising for context
if i >= rollout_length - teacher_length:
# Target frames: use random exit for gradient coverage
r_prime = len(noise_schedule) # T steps (full)
else:
# Context frames: random exit
r = torch.randint(1, len(noise_schedule) + 1, (1,))
r_prime = r
# Multi-step denoising
x_t = z_i
for j in range(r_prime):
t_j = noise_schedule[j]
if j == r_prime - 1 and i >= rollout_length - teacher_length:
# Last step of target chunk: enable gradient
with torch.enable_grad():
x_denoised = student_model(x_t, t_j, student_kv_cache)
generated_frames.append(x_denoised)
else:
# Context steps or intermediate steps: no gradient
with torch.no_grad():
x_denoised = student_model(x_t, t_j, student_kv_cache)
# Update KV cache
student_kv_cache.update(x_denoised.key, x_denoised.value)
if j < r_prime - 1:
# Add noise for next step
eps = torch.randn_like(x_denoised)
x_t = add_noise(x_denoised, eps, noise_schedule[j + 1])
else:
x_t = x_denoised
# --- Phase 2: Compute Contextual DMD Loss ---
# Context: last (rollout_length - teacher_length) to (rollout_length - 1)
context_frames = generated_frames[:-teacher_length]
target_frames = generated_frames[-teacher_length:]
# Add noise to target for score computation
t = sample_timestep(noise_schedule)
noisy_target = add_noise(torch.cat(target_frames), torch.randn_like(target_frames), t)
# Both scores conditioned on SAME student-generated context
fake_score = fake_score_fn(noisy_target, t, context=context_frames,
kv_cache=student_kv_cache)
real_score = real_score_fn(noisy_target, t, context=context_frames,
kv_cache=teacher_kv_cache)
# DMD gradient: (fake_score - real_score) * dG/dtheta
loss = ((fake_score - real_score) * target_frames.detach()).mean()
return loss
def erft_teacher_training_step(teacher_model, clean_context, target, residual_bank):
"""
Error-Recycling Fine-Tuning: train teacher on perturbed contexts.
"""
# Sample drift errors from historical residual bank
e_drift = residual_bank.sample(clean_context.shape)
# Bernoulli mask: randomly apply drift
mask = torch.bernoulli(torch.ones_like(clean_context) * 0.5)
# Construct perturbed context
perturbed_context = clean_context + mask * e_drift
# Teacher must recover correct velocity from perturbed input
v_pred = teacher_model(target, context=perturbed_context)
v_target = compute_flow_velocity(target)
loss = F.mse_loss(v_pred, v_target)
return loss9. Code Mapping
注意:截止 2026 年 3 月,官方代码仓库 TIGER-AI-Lab/Context-Forcing 仍在整理中,尚未发布完整的训练/推理代码。以下映射基于论文描述和相关代码库(Wan2.1, Self-Forcing, CausVid)的推断。
| 论文组件 | 推测代码位置 | 说明 |
|---|---|---|
| 基础模型 (Wan2.1-T2V-1.3B) | wan/ | 基于 Wan 模型,采用 block-wise causal attention 的 DiT |
| Stage 1: Local DMD | train_stage1.py | 标准 DMD 蒸馏,参考 CausVid 实现 |
| Stage 2: Contextual DMD | train_stage2.py | 核心创新:长 rollout + CDMD loss |
| Slow-Fast Memory | memory/slow_fast_memory.py | KV cache 三段式管理 |
| Surprisal Consolidation | memory/consolidation.py | 基于 key 相似度的 token 提升策略 |
| Bounded Positional Encoding | models/rope.py | 修改 temporal RoPE 为固定范围 |
| ERFT Teacher Training | train_teacher.py | Error-Recycling Fine-Tuning |
| Inference Pipeline | inference.py | Streaming 生成 + Slow-Fast Memory 管理 |
与相关工作的代码关系
- Self-Forcing (self-forcing): Context Forcing 的 Stage 1 与 Self-Forcing 的训练逻辑相似,都使用 DMD 蒸馏
- CausVid (CausVid): DMD2 的具体实现细节可参考 CausVid
- Wan2.1 (Wan-Video/Wan2.1): 基础模型架构和推理框架