VideoMemory: Toward Consistent Video Generation via Memory Integration
Authors: Jinsong Zhou, Yihua Du, Xinli Xu, Luozhou Wang, Zijie Zhuang, Yehang Zhang, Shuaibo Li, Xiaojun Hu, Bolan Su, Ying-cong Chen Affiliations: HKUST(GZ), HKUST, ByteDance
1. Motivation (研究动机)
多镜头叙事视频生成(multi-shot narrative video generation)的核心痛点是跨镜头实体一致性——角色、道具、背景在时间跨度较大的不同镜头中需保持视觉身份一致,同时允许剧情驱动的合理变化(如角色衰老、道具损坏、昼夜切换)。
现有方法的三类局限:
- Plan-then-Generate 流水线(如 LLM 先生成剧本再逐镜头出图):提供了叙事结构,但缺乏持久的视觉表征。每个镜头独立生成,无法回溯之前角色的外观,导致 identity drift
- One-pass Multi-Shot 方法(如 Wan2.2、EchoShot):在单次前向传播中建模多个镜头,利用扩展时序上下文改善连贯性。但其历史记忆是 feature-centric 而非 entity-centric,不存储显式实体状态,当角色在长时间间隔后重新出现时会发生漂移
- Memory-Inspired 方法(如 FramePack、Context-as-Memory):在帧或特征层面存储信息,但没有为命名实体分配专属存储槽,一旦实体离开局部上下文窗口,身份恢复就不可靠
核心矛盾:现有方法要么没有记忆,要么记忆是帧级/特征级的,缺少实体级别的显式外部记忆来保持角色、道具、背景的长程一致性。
2. Idea (核心思想)
VideoMemory 借鉴了真实影视制作中的资产管理流程——剧组在拍摄前会定义一套角色造型、关键道具和场景设计,并随剧情推进不断更新这些资产,确保反复出场的实体始终可辨认。
核心 insight:引入一个显式的、实体级别的 Dynamic Memory Bank,为角色、道具、背景分别维护专属的视觉+语义描述符,在逐镜头生成过程中执行 retrieve-or-update 操作,实现长程实体一致性。
三个关键设计:
- Multi-Agent Cooperation:Storyboard Agent(叙事规划)+ Memory Agent(实体管理)+ Visualization Agent(视觉生成)三个 LLM agent 协作,各司其职
- Dynamic Memory Bank:三个专用存储库 、、,每个条目包含 (entity name, attribute vector, reference image),通过 LLM 语义匹配检索
- Retrieve-or-Generate 机制:对每个实体,先在 Memory Bank 中语义检索;匹配则复用参考图像,不匹配则生成新参考图像并入库
最终:基于 Gemini 2.5 Pro + Gemini 2.5 Flash-Image + Wan 2.2 I2V-14B,在 54 个测试用例上全面超越 5 个 baseline,角色一致性 0.63、道具一致性 0.58、背景一致性 0.72(DINOv2 similarity)。
3. Method (方法)
3.1 问题定义与整体架构
给定剧本大纲 ,目标是生成多镜头视频 ,形式化为自动映射:
包含两部分:(1) 叙事规划——将大纲分解为镜头级描述;(2) 视觉实现——将描述转化为关键帧和视频,同时维护实体一致性。

Figure 3 解读:VideoMemory 整体框架由三个协作 Agent 组成。左侧展示了三个 Agent 的分工:Storyboard Agent 使用 chain-of-thought 推理分析输入剧本、规划故事发展、确定镜头数量;Memory Agent 分析每个镜头所需实体并与 Dynamic Memory Bank 交互(检索/更新);Visualization Agent 基于检索到的参考图像合成关键帧和视频。中间展示了 Storyboard Agent 输出的多个镜头(shot 1, 2, 4, 8),Memory Agent 与 Dynamic Memory Bank 之间的 Retrieval/Update 双向交互。右侧展示了三个 Memory Bank(Character Bank、Prop Bank、Background Bank)的内容——以”Anna 的一生”为例,Character Bank 存储了 Anna 在不同年龄段的外观(Anna_1985, Anna_2000 等),Prop Bank 存储了道具(Lantern)在不同状态下的参考图,Background Bank 存储了场景(Anna_home)在不同时期的参考图。底部说明了 Retrieval 和 Update 的流程:LLM 识别实体并形成 attribute-based key 查询 Memory Bank,若检索失败则生成新的 Entity Frame 并存入 bank。
3.2 Multi-Agent Cooperation
整体流程见 Algorithm 1:
def videomemory_pipeline(S: str) -> list:
"""VideoMemory: Script Synopsis to Multi-Shot Video"""
# Step 1: Storyboard Agent decomposes synopsis into shot descriptions
shot_descriptions = storyboard_agent(S) # {C_i}_{i=1}^N
N = len(shot_descriptions)
# Step 2: Initialize empty memory banks for three entity types
M_char, M_prop, M_bg = {}, {}, {}
M = {"char": M_char, "prop": M_prop, "bg": M_bg}
V_hat = []
for i in range(N): # 逐镜头顺序处理
# Memory Agent analyzes entities needed for this shot
entities = memory_agent_analyze(shot_descriptions[i]) # [(e_ij, a_ij, c_ij), ...]
# Retrieve or generate reference images for each entity
ref_images = []
for e_ij, a_ij, c_ij in entities:
I_ref, M = retrieve_or_generate(e_ij, a_ij, c_ij, M)
ref_images.append(I_ref)
# Visualization Agent synthesizes keyframe from references
I_key = visualization_agent_keyframe(shot_descriptions[i], ref_images)
# Image-to-Video model generates video clip
V_i = i2v_model(I_key, shot_descriptions[i])
V_hat.append(V_i)
return V_hat # Multi-shot video {V̂_i}_{i=1}^N三个 Agent 的详细职责:
Storyboard Agent(导演):
- 使用 LLM + chain-of-thought 将高层剧本大纲展开为详细叙事和结构化镜头序列
- 先将故事分割为主要节拍(如”村庄序幕”、“桥上冲突”),再将每个节拍细化为一个或多个镜头
- 每个镜头描述 包含:场景设置、空间布局、参与角色、关键事件、镜头参数(距离、构图等)
- 采用三幕式结构:Act 1 (20-30%), Act 2 (40-60%), Act 3 (20-30%)
Memory Agent(选角/道具专家):
- 对每个镜头描述 ,解析出所有需要出场的实体
- 对每个实体 构建属性向量 (年龄、发型、服装、情绪状态、时间段等)
- 为实体打类别标签 路由到对应 Memory Bank
- 查询 Memory Bank 并返回参考图像
Visualization Agent(摄影师):
- 接收镜头描述 和参考图像
- 合成关键帧图像,然后交给 I2V 模型生成视频
3.3 Dynamic Memory Bank
Dynamic Memory Bank 是 VideoMemory 的核心组件,负责在整个视频中强制执行实体级一致性。

Figure 2 解读:对比现有方法与 VideoMemory 的差异。(a) 左上角展示 One-pass Multi-Shot Method:将所有镜头描述拼接后一次性生成,结果是跨镜头实体不一致(红圈标注);左下角展示 Plan-then-Generate Method:LLM 先生成完整剧本,存储的”记忆”是固定大小的 context bank(如 Old watch、Li Heng 等),但一旦添加新情节就需要重新处理所有内容(“No Update, All At Once”),效率低且一致性差。(b) 右侧展示 VideoMemory 的方法:Plots Pool 存储完整剧情,但逐镜头生成(“Generate Shot One By One”),每次生成前执行两步操作——Step1: 用 entity 的 Key Value 查询 Memory Bank(Retrieval Memory),Step2: 将新生成的实体更新入 Bank(Update Memory)。Dynamic Memory Bank 以 Entity Frame 为基本单元,按 Character/Prop/Background 三类分别存储,实现了跨镜头的实体一致性(Entity Consistent,绿色标注)。
Memory 表示:维护三个专用存储库 、、,每个条目为一个 entity frame:
- :实体标识符(如 “Anna”)
- :属性向量(文本形式,如 age, hairstyle, outfit 等)
- :参考图像(PNG 文件)
实践中, 和 以文本形式存储并以 LLM-friendly 格式索引(如 “Anna_1985”), 存储为磁盘上的 PNG 文件。
Retrieval(检索):对于 shot 中的实体 :
- 根据类别 选择对应的 Memory Bank
- 不依赖精确字符串匹配,而是用 LLM-based matcher 计算当前属性 与存储属性之间的语义相似度
- 这允许不同措辞的匹配,如 “middle-aged Anna in a winter coat” 与 “Anna, about 45, wearing a thick coat in the snow”
- 若找到匹配,返回 作为
Update(更新):若检索失败(无足够相似条目),调用图像生成模型创建新参考:
- :图像生成器(Gemini 2.5 Flash-Image)
- :该实体的历史参考图像集(若非空)
关键设计:当 非空时(如已有 “Anna at age 20” 的图像),生成 “Anna at age 60” 时会同时提供当前属性描述和历史图像,使模型能够在保持核心身份特征的同时反映时间变化。新生成的三元组 随后插入对应 Bank。
3.4 Keyframe & Video Generation
基于镜头描述 和参考图像 ,分两步将符号规格转化为像素级视频:
Step 1: 关键帧合成
是图像生成模块(Gemini 2.5 Flash-Image),以参考图像为显式条件生成关键帧,作为后续视频合成的视觉锚点。
Step 2: Image-to-Video 生成
是 I2V 模型(Wan 2.2 I2V-14B),基于关键帧添加运动和相机动态。
Step 3: 拼接
所有镜头按叙事顺序拼接形成完整多镜头视频。
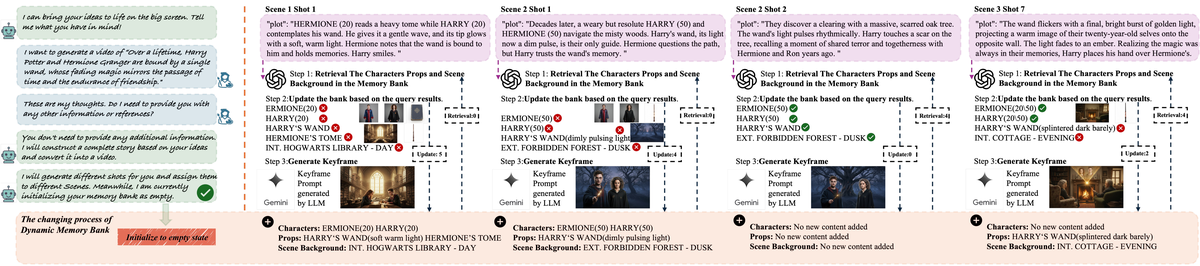
Figure 4 解读:以”Harry Potter”故事为端到端示例。左侧是用户与系统的交互界面:用户仅输入一段文本梗概(“generate a video of 7 years in Hogwarts, Harry Potter and Hermione…“),系统自动规划所有场景和镜头。中间展示了 4 个镜头的生成过程——每个镜头都经历三步:Step 1 从 Memory Bank 检索角色、道具和背景的参考图;Step 2 基于查询结果更新 Memory Bank;Step 3 生成关键帧。右侧是 Dynamic Memory Bank 的演变过程:Characters 栏记录了 Harry 和 Hermione 在不同场景/年龄的外观(如 ENHANCED HARRY (18), TEENAGE HARRY(13)),Props 栏记录了 Harry’s wand 等道具状态,Scene Background 栏记录了 INT. HOGWARTS LIBRARY, EXT. FORBIDDEN FOREST 等场景。可以看到随着故事推进,Memory Bank 不断增长但保持同一实体的身份一致性。
4. Experimental Setup (实验设置)
4.1 实验设置
实现细节:
- LLM backbone:Gemini 2.5 Pro(叙事推理、剧本解析、实体属性提取、结构化 prompt 生成)
- 图像生成:Gemini 2.5 Flash-Image(关键帧和参考图像生成)
- 视频生成:Wan 2.2 I2V-14B(Image-to-Video)
- 所有实验使用相同的 Wan 2.2 backbone,性能差异主要归因于 memory 机制
评估指标(三个互补指标,均基于各镜头中间帧的 DINOv2 特征计算):
- Character Consistency:用 Mediapipe 检测人脸区域,提取 DINOv2 特征,计算跨镜头 cosine similarity
- Prop Consistency:用 Grounded SAM 根据文本描述定位道具区域,提取 DINOv2 特征
- Background Consistency:直接对全帧提取 DINOv2 特征(无分割)
一致性得分计算:以第 1 个镜头中间帧为参考,计算后续所有镜头与参考帧的 cosine similarity 并归一化:
Benchmark:54 个测试用例 = 3 子类(Character-persistent / Prop-persistent / Background-persistent) 3 镜头长度() 6 样本。每个子类中,被测试的实体在所有镜头中保持一致,另外两类实体故意在镜头间变化。
Baselines:
- T2V native:Wan 2.2 T2V-14B、EchoShot
- Keyframe-first:IC-LoRA+Wan2.2、StoryDiffusion+Wan2.2、VGoT+Wan2.2
5. Experimental Results (实验结果)
5.1 主要结果
Table 1: Multi-Shot Consistency Results (DINOv2 Similarity)
| Method | Char 4 | Char 8 | Char 12 | Char Avg | Prop 4 | Prop 8 | Prop 12 | Prop Avg | BG 4 | BG 8 | BG 12 | BG Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wan2.2 | 0.34 | - | - | - | 0.48 | - | - | - | 0.25 | - | - | - |
| EchoShot | 0.45 | 0.44 | - | - | 0.59 | 0.51 | - | - | 0.54 | 0.37 | - | - |
| IC-LoRA+Wan2.2 | 0.42 | 0.55 | 0.43 | 0.47 | 0.50 | 0.44 | 0.34 | 0.43 | 0.31 | 0.33 | 0.29 | 0.31 |
| StoryDiffusion+Wan2.2 | 0.53 | 0.62 | 0.46 | 0.54 | 0.43 | 0.47 | 0.52 | 0.47 | 0.51 | 0.40 | 0.36 | 0.42 |
| VGoT+Wan2.2 | 0.59 | 0.53 | 0.60 | 0.57 | 0.48 | 0.22 | 0.24 | 0.31 | 0.53 | 0.36 | 0.47 | 0.45 |
| VideoMemory (Ours) | 0.61 | 0.65 | 0.64 | 0.63 | 0.69 | 0.50 | 0.55 | 0.58 | 0.71 | 0.72 | 0.73 | 0.72 |
关键发现:
- VideoMemory 在三个维度的平均分上全面领先,尤其背景一致性提升最大(0.72 vs 次优 0.45,+60%)
- 随镜头数增加(4→8→12),VideoMemory 的优势更加明显,说明 Dynamic Memory Bank 有效抑制了长程漂移
- 部分 baseline(Wan2.2、EchoShot)在 8 或 12 镜头时无法产出足够镜头数,导致评分缺失
Table 2: User Study Results(人类偏好率,5 位专家 270 对比较)
| Baseline | Character | Prop | Background | Semantic |
|---|---|---|---|---|
| vs Wan2.2 | 87.50% | 79.17% | 87.50% | 94.44% |
| vs EchoShot | 91.66% | 91.66% | 70.83% | 91.66% |
| vs IC-LoRA | 95.83% | 87.50% | 91.66% | 95.83% |
| vs StoryDiffusion | 91.66% | 79.17% | 91.66% | 87.50% |
| vs VGoT | 95.83% | 83.33% | 95.83% | 91.66% |
VideoMemory 在所有对比中均获得压倒性偏好,角色和背景一致性最高达 95.8% 偏好率。
5.2 Qualitative Results(定性结果)

Figure 5 解读:定性对比三类一致性。Character Consistency(左列):各 baseline 在不同镜头中角色面部结构、年龄、肤色均发生变化,VideoMemory(底行)保持了角色的一致身份。Prop Consistency(中列):以”红色风筝”为目标道具,baseline 中风筝频繁变形为其他红色物体或消失,VideoMemory 保持了风筝的形状和颜色。Background Consistency(右列):以”杂乱车库”为固定背景,baseline 中工具和架子的空间配置在镜头间变化,VideoMemory 保持了更稳定的空间布局。
5.3 Ablation Study
Table 3: Dynamic Memory Bank (DMB) 消融(8-shot 平均)
| Method | Character | Prop | Background |
|---|---|---|---|
| w/o DMB | 0.51 | 0.43 | 0.28 |
| Full Model | 0.65 | 0.50 | 0.72 |
移除 Dynamic Memory Bank 后,所有指标大幅下降,背景一致性从 0.72 暴跌到 0.28(降 61%),证明 DMB 是一致性的核心驱动力。

Figure 6 解读:逐步添加 Memory Bank 各组件的定性消融。顶行 (w/o DMB):无记忆基线,实体漂移严重——角色外观、道具颜色、天文台背景在不同镜头中完全不同。第 2 行 (+CB, Character Bank):添加 Character Bank 后,人物外观在各镜头间稳定下来,但道具(红色行李箱)和背景(天文台)仍然不一致。第 3 行 (+CB+PB):进一步添加 Prop Bank,红色行李箱在各镜头中保持一致的形状和颜色。第 4 行 (+CB+PB+BB, Full Model):添加 Background Bank 后,天文台背景也保持稳定,三类实体全部一致。这证明了三个 Memory Bank 各自不可或缺,且效果是递增叠加的。

Figure 8 解读:展示三种一致性模式下的成功案例。Story 1(顶部两行,Character Consistency):主角在室内、户外公园、公共交通等多样场景中保持一致的面部身份。Story 2(中间两行,Prop Consistency):一顶亮橙色硬帽在不同光照和拍摄角度下保持颜色和结构的一致性。Story 3(底部两行,Background Consistency):地铁站台作为固定背景,在多个角色和动作场景中保持稳定的空间布局和视觉特征。

Figure 1 解读:VideoMemory 的 teaser 展示。从单一故事 prompt 出发,生成了包含 12 个镜头的连贯多镜头视频。上方 34 网格展示了 Shot 1 到 Shot 12 的关键帧——场景从工业街区到森林再到室内不断切换,但核心实体保持一致。底部展示了三个 Memory Bank 的内容:Character Bank 存储了两个角色(一男一女)在不同镜头中的外观参考;Prop Bank 存储了一根羽毛道具的参考图——即使在 Shot 2、10、12 等相距很远的镜头中,羽毛的外观保持完全一致;Background Bank 存储了多个场景的参考图。
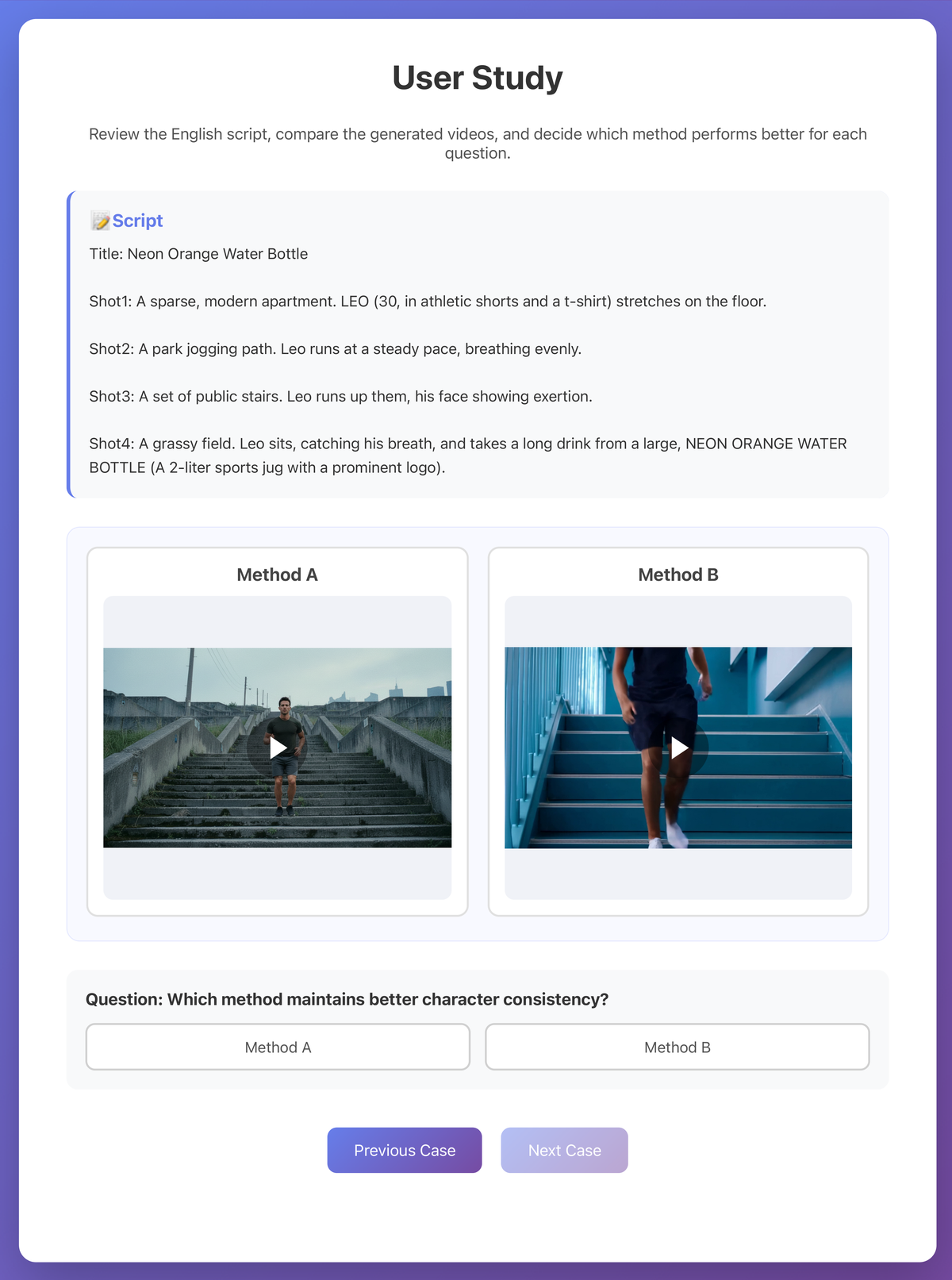
Figure 7 解读:用户研究的界面截图。顶部展示了完整的英文剧本(包含标题和逐镜头描述,如”Neon Orange Water Bottle”故事的 4 个镜头)。下方并排展示两个匿名化的视频(Method A 和 Method B),参与者可播放和暂停。底部是一个子类特定的强制选择问题:“Which method maintains better character consistency?” 参与者通过点击 Method A 或 Method B 按钮作答。
6. Limitations & Future Work(不足与展望)
当前局限:
- 依赖外部 API:整个流水线重度依赖 Gemini 2.5 Pro/Flash-Image API 进行叙事推理和图像生成,成本高且不可控
- 逐镜头串行生成:Algorithm 1 是严格顺序执行的(shot 1 → shot N),无法并行化,长故事的生成时间线性增长
- 无端到端训练:三个 Agent 之间没有梯度回传,Memory Bank 的检索/更新完全由 LLM 推理驱动,可能存在累积错误
- I2V 模型的局限:关键帧到视频的转化依赖 Wan 2.2 I2V,该模型本身在运动复杂场景下可能引入伪影
- 评估局限:54 个测试用例规模较小,DINOv2 similarity 可能无法完全捕捉人类感知的一致性
潜在方向:
- 将 Dynamic Memory Bank 机制与端到端可训练的视频生成模型融合,实现可微分的实体记忆
- 探索更高效的检索机制(如向量数据库替代 LLM 语义匹配)降低推理成本
- 扩展到更长的叙事(50+ 镜头)和更复杂的实体关系(如角色之间的交互一致性)
7. Code Mapping(代码映射)
| 论文模块 | 实现方式 | 说明 |
|---|---|---|
| Storyboard Agent | Gemini 2.5 Pro API + System Prompt (Appendix C) | LLM chain-of-thought 分解剧本为镜头描述 |
| Memory Agent | Gemini 2.5 Pro API + System Prompt (Appendix C) | LLM 解析实体属性、语义检索/更新 Memory Bank |
| Visualization Agent | Gemini 2.5 Pro API + System Prompt (Appendix C) | LLM 组合关键帧 prompt 和视频 prompt |
| Dynamic Memory Bank | 文件系统 (PNG + text index) | 三类 Bank 各自独立,entity frame = (name, attributes, image_path) |
| Keyframe Generation | Gemini 2.5 Flash-Image API | 基于参考图像和场景描述生成关键帧 |
| I2V Generation | Wan 2.2 I2V-14B (开源) | 关键帧 → 视频,添加运动和相机动态 |
| LLM-based Matcher | Gemini 2.5 Pro API | 语义相似度匹配替代精确字符串匹配 |
| Character Detection | Mediapipe | 人脸检测用于 Character Consistency 评估 |
| Prop Localization | Grounded SAM | 文本条件下的道具区域分割用于 Prop Consistency 评估 |
| Feature Extraction | DINOv2 | 所有一致性指标的视觉特征提取器 |
注:截至 2026-03-12,代码尚未开源(项目页标注 “Coming Soon”)。上述映射基于论文描述和附录 C 中公开的 System Prompt 推断。