Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Authors: Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, Eli Shechtman Affiliations: Adobe Research, The University of Texas at Austin Project Page: self-forcing.github.io Year: 2025
1. Motivation (研究动机)
Self Forcing 讨论的是自回归视频扩散模型里的 train-test gap:训练时看到的上下文和推理时看到的上下文不一致,导致 exposure bias 和误差累积。
当前视频扩散模型主要有两种架构范式:
- 双向扩散模型(Bidirectional DiT):如 Wan2.1、CogVideoX,一次性对所有帧去噪,使用双向注意力。优点是质量高,缺点是无法流式生成,不支持实时交互。
- 自回归扩散模型(AR Diffusion):逐帧/逐块生成,天然支持因果结构和流式输出,适用于实时交互场景(游戏、直播、世界模型)。
AR 扩散模型的训练方法主要有两种,但都存在 exposure bias:
| 训练范式 | 训练时的上下文 | 推理时的上下文 | 分布偏移 |
|---|---|---|---|
| Teacher Forcing (TF) | 干净的 ground-truth 帧 | 模型自己生成的(不完美)帧 | 训练见的是真实帧,推理见的是自生成帧 |
| Diffusion Forcing (DF) | 带不同噪声水平的上下文帧 | 模型自己生成的帧 | 训练时上下文帧来自数据分布加噪,推理时来自模型分布 |
这种分布偏移会导致 误差累积:随着自回归展开,每一帧的小误差逐渐放大,后续帧质量不断退化,常见现象包括颜色饱和度递增、过度锐化。
2. Idea (核心思想)
Self Forcing 的核心思想很直接:训练时模拟推理过程。不用 ground-truth 帧作上下文,而是在训练中就进行自回归展开(self-rollout),让模型在自己生成的帧上条件化生成下一帧。这样:
- 训练分布 = 推理分布,从根本上消除 exposure bias。
- 可以使用 视频级别的整体损失(而非逐帧损失),直接优化生成视频的全局质量。
- 模型被迫学会从自己的不完美输出中恢复,天然具备鲁棒性。
灵感来源:早期 RNN 序列建模中的 scheduled sampling / professor forcing 技术。
3. Method (方法)
3.1 自回归视频扩散模型的形式化
给定 帧视频 ,AR 扩散模型通过链式分解建模联合分布:
每个条件分布 通过扩散过程实现:从高斯噪声出发,逐步去噪生成帧 ,同时以之前的帧 为条件。
架构选择:基于 Transformer 的因果 DiT(Causal DiT),在压缩的 3D VAE 隐空间中操作,通过因果注意力实现链式分解。
3.2 Self Forcing 训练:通过自展开进行后训练
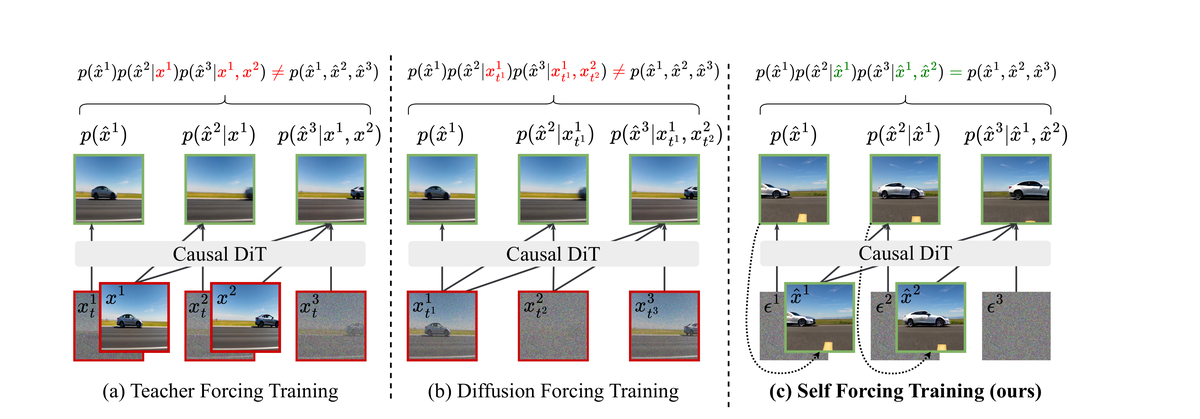 Figure 1 解读:这张图对应 Self Forcing 的整体训练思路——训练阶段直接按推理方式做自回归展开,再用分布匹配损失优化最终生成的视频。
Figure 1 解读:这张图对应 Self Forcing 的整体训练思路——训练阶段直接按推理方式做自回归展开,再用分布匹配损失优化最终生成的视频。
核心流程:在训练时按推理时的方式生成视频,然后用分布匹配损失优化。
关键技术点 1:Few-Step 扩散模型
标准多步扩散模型(如 50 步 DDPM)进行自回归展开 + 反向传播在计算上不可行。因此使用 few-step 扩散模型(4 步),大幅减少计算图深度。
去噪步序列 ,每步去噪:
然后通过前向过程注入噪声到下一噪声水平:
关键技术点 2:随机梯度截断(Stochastic Gradient Truncation)
即使用 few-step 模型,朴素地对整个自回归过程反向传播仍然内存消耗巨大。解决方案:
- 随机采样去噪步:对每个样本序列,随机采样一个去噪步 ,只用第 步的去噪输出作为最终输出。
- 只在最后一步计算梯度:只对选中的去噪步开启梯度,其余步骤用
torch.no_grad()。 - KV cache 梯度截断:将之前帧的梯度通过 KV cache 的流动截断,不反传到更早的帧。
这种随机采样确保所有去噪步都能接收到监督信号(期望上等价于完整反传)。
关键技术点 3:训练时使用 KV Caching
 Figure 2 解读:这张图展示了 Self Forcing 训练时的因果注意力组织方式,核心区别是它像推理一样逐帧输入,并用 KV caching 维护历史状态。
Figure 2 解读:这张图展示了 Self Forcing 训练时的因果注意力组织方式,核心区别是它像推理一样逐帧输入,并用 KV caching 维护历史状态。
这是 Self Forcing 区别于 TF/DF 的关键架构差异:
- TF/DF:将整个视频的所有帧并行输入 Transformer,使用特殊的注意力掩码强制因果依赖。
- Self Forcing:像推理一样逐帧/逐块输入,使用 KV caching 存储之前帧的注意力状态。
好处:
- 训练过程精确镜像推理过程。
- 可以使用标准的全注意力(FlashAttention-3),无需自定义掩码。
- 每帧/块只需处理当前 token,无需重复计算历史帧。
3.3 整体分布匹配损失(Holistic Distribution Matching Loss)
Self Forcing 的自回归展开直接生成推理时分布的样本,使得可以使用 视频级别 的分布匹配损失:
对比 TF/DF 只能做逐帧的损失,Self Forcing 优化的是整个视频序列的联合分布。
论文考察了三种分布匹配框架:
| 方法 | 散度度量 | 核心机制 | 是否需要数据 |
|---|---|---|---|
| DMD (Distribution Matching Distillation) | 反向 KL 散度 | 通过 score 差异引导梯度 | 否(data-free) |
| SiD (Score Identity Distillation) | Fisher 散度 | 匹配 score function | 否(data-free) |
| GAN | Jensen-Shannon 散度 | 判别器区分真假视频 | 是(需要视频数据) |
注意:DMD 和 SiD 方案是 data-free 的——只需要文本提示,不需要视频训练数据。这意味着可以将预训练的双向视频扩散模型直接转换为自回归模型。
3.4 Rolling KV Cache:无限长视频生成
 Figure 3 解读:这张图说明 Rolling KV Cache 如何把长视频外推的复杂度降到线性,同时避免窗口重算带来的额外开销。
Figure 3 解读:这张图说明 Rolling KV Cache 如何把长视频外推的复杂度降到线性,同时避免窗口重算带来的额外开销。
自回归模型的核心优势是可以生成无限长视频(通过滑动窗口)。但现有方法效率低下:
| 方案 | 计算复杂度 | 问题 |
|---|---|---|
| 双向滑动窗口 | 不支持 KV cache,每帧需重新计算所有注意力 | |
| 因果滑动窗口 + KV 重计算 | 窗口移动时需重新计算重叠帧的 KV cache | |
| Rolling KV Cache(本文) | 固定大小 KV cache,FIFO 淘汰最旧条目 |
Rolling KV Cache 维护一个固定大小为 帧的 KV cache。生成新帧时:
- 检查 KV cache 是否已满。
- 若满,淘汰最旧的 KV 条目。
- 添加新帧的 KV 嵌入。
分布偏移问题:朴素实现会导致闪烁,因为第一帧(图像 latent)有特殊统计性质,当它从 KV cache 中淘汰后模型无法适应。解决方案:训练时限制最后一块不关注第一块,模拟 rolling cache 场景。
4. Experimental Setup (实验设置)
基于 Wan2.1-T2V-1.3B,分辨率 ,16 FPS,5 秒视频。
4.1 对比模型与评价设置
对比对象包括 Wan2.1、CausVid、SkyReels-V2,以及 Self Forcing 的 chunk-wise 和 frame-wise 两种设置。主要指标为:
- 吞吐量(FPS)
- 首帧延迟(s)
- VBench 总分
- 质量分
- 语义分
4.2 用户偏好研究
 Figure 4 解读:这张图是用户偏好实验的汇总,说明 Self Forcing 在与多个基线对比时获得了多数选择。
Figure 4 解读:这张图是用户偏好实验的汇总,说明 Self Forcing 在与多个基线对比时获得了多数选择。
Self Forcing 在与所有基线的对比中均获得多数偏好:vs CausVid 66.1%,vs Wan2.1 62.7%,vs SkyReels-V2 57.9%,vs MAGI-1 54.2%。
4.3 训练效率评估
 Figure 5 解读:这张图展示了 Self Forcing 与 TF/DF 在训练效率上的对比,重点是它没有因为顺序展开而显著变慢。
Figure 5 解读:这张图展示了 Self Forcing 与 TF/DF 在训练效率上的对比,重点是它没有因为顺序展开而显著变慢。
训练效率对比关注每迭代时间和相同 wall-clock 时间下的质量收敛。
5. Experimental Results (实验结果)
5.1 主要性能对比
| 模型 | 参数量 | 吞吐量(FPS) | 首帧延迟(s) | VBench 总分 | 质量分 | 语义分 |
|---|---|---|---|---|---|---|
| Wan2.1 | 1.3B | 0.78 | 103 | 84.26 | 85.30 | 80.09 |
| CausVid | 1.3B | 17.0 | 0.69 | 81.20 | 84.05 | 74.53 |
| SkyReels-V2 | 1.3B | 0.49 | 112 | 82.67 | 84.70 | 74.53 |
| Self Forcing (chunk-wise) | 1.3B | 17.0 | 0.69 | 84.31 | 85.07 | 81.28 |
| Self Forcing (frame-wise) | 1.3B | 8.9 | 0.45 | 84.26 | 85.25 | 80.30 |
关键发现:
- Self Forcing 在 VBench 总分上超越所有对比方法,包括慢 150 倍的 Wan2.1。
- 实时吞吐(17 FPS),亚秒级延迟(0.45–0.69s)。
- Data-free 训练(DMD/SiD 方案不需要视频数据)。
5.2 消融实验
| Chunk-wise AR | 总分 | 质量分 | 语义分 |
|---|---|---|---|
| Diffusion Forcing (50 步) | 82.95 | 83.66 | 80.09 |
| Teacher Forcing (50 步) | 83.58 | 84.34 | 80.52 |
| DF + DMD (4 步) | 82.76 | 83.49 | 79.85 |
| TF + DMD (4 步) | 82.32 | 82.73 | 80.67 |
| Self Forcing + DMD | 84.31 | 85.07 | 81.28 |
| Self Forcing + SiD | 84.07 | 85.52 | 78.24 |
| Self Forcing + GAN | 83.88 | 85.06 | 79.16 |
关键发现:
- Self Forcing 在所有分布匹配目标下都显著优于 TF/DF 基线。
- 从 chunk-wise 切换到 frame-wise AR 时,TF/DF 基线质量显著下降(误差累积加剧),Self Forcing 保持稳定。
5.3 实验图示:基线、注意力和滚动缓存
 Figure 6 解读:这张图对比了 Teacher Forcing、Diffusion Forcing 与 Self Forcing 三种训练范式,核心是在训练时是否使用模型自生成的上下文。
Figure 6 解读:这张图对比了 Teacher Forcing、Diffusion Forcing 与 Self Forcing 三种训练范式,核心是在训练时是否使用模型自生成的上下文。
这张图对比了三种自回归视频扩散模型的训练方式:
- (a) Teacher Forcing:模型在干净的 ground-truth 上下文帧上训练去噪。条件分布的乘积 不等于联合分布 ,因为推理时用的是模型生成帧而非真实帧。
- (b) Diffusion Forcing:上下文帧是加了不同噪声的版本。同样存在分布偏移:训练时的噪声上下文来自数据分布,推理时来自模型分布。
- (c) Self Forcing(本文):训练时就用模型自生成的帧作上下文,条件分布的乘积恰好等于联合分布。分布匹配损失直接作用于最终输出视频。
Figure 7 解读:这张图说明 TF/DF 的并行掩码训练与 Self Forcing 的逐帧 KV cache 推理在结构上的差异。
展示了一个 3 帧视频、每帧 2 个 token 的例子:
- (a) Teacher Forcing:所有帧并行输入,使用 block sparse 注意力掩码实现因果依赖。Q 轴是所有帧所有去噪步,K 轴区分 clean KV 和 noisy KV。
- (b) Diffusion Forcing:类似 TF,但上下文帧有不同噪声水平。
- (c) Self Forcing/AR 推理:逐帧处理,空间去噪在帧内完成,时间 AR 展开通过 KV caching 实现。这正是推理时的流程——训练时完全复制。
Figure 8 解读:这张图对比三种长视频生成策略,强调 Rolling KV Cache 的线性复杂度和无需重计算的优势。
三种滑动窗口长视频生成策略:
- (a) 双向滑动窗口:,每个窗口完全重新计算。
- (b) 因果滑动窗口 + KV 重计算:,窗口移动时需要重新计算重叠帧的 KV。
- (c) 因果滑动窗口 + Rolling KV Cache(本文):,FIFO 淘汰最旧 KV,无需重计算。