Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models
Paper: arXiv:2603.25716 Code: H-EmbodVis/HyDRA Code reference:
main@48652bec(2026-04-29)
1. Motivation (研究动机)
现有 video world model 的“记忆”机制大多把环境当成静态画布:相机移动时需要记住背景,模型还能通过 FOV overlap 或上下文窗口找回历史区域;但当主体本身在运动、离开视野、再重新出现时,问题变成同时追踪两类状态:静态背景的几何/外观一致性,以及动态主体的身份、外观、动作连续性。
这篇论文要解决的具体问题是 exit-entry dynamics:主体在 context frames 中出现,随后由于相机和主体各自运动而暂时不可见,未来帧里又进入视野。若模型只用静态几何记忆,常见失败是主体冻结、形变、消失,或重新出现时动作/身份不连续。
这个问题值得研究,因为长时程视频世界模型要服务交互式仿真、机器人/具身环境预演、长镜头生成等场景;这些场景中“看不见”不代表对象状态停止更新。模型必须具备类似 object permanence 的混合记忆能力:背景要像档案馆一样精确保存,动态主体要像追踪器一样持续预测。
更细地说,传统 video prediction / long-horizon generation 往往把“历史可见帧”当成静态参考:如果目标像素对应的是曾经看过的墙面、地板或家具,模型可以通过空间对齐或相机轨迹找回纹理;但动态主体的未来状态不只由历史位置决定,还由不可见区间内的运动动画、速度方向、遮挡关系和再入画时刻决定。因此,这不是单纯的 long-context problem,而是 memory representation 必须从“保存画面”升级到“保存可继续演化的对象状态”。
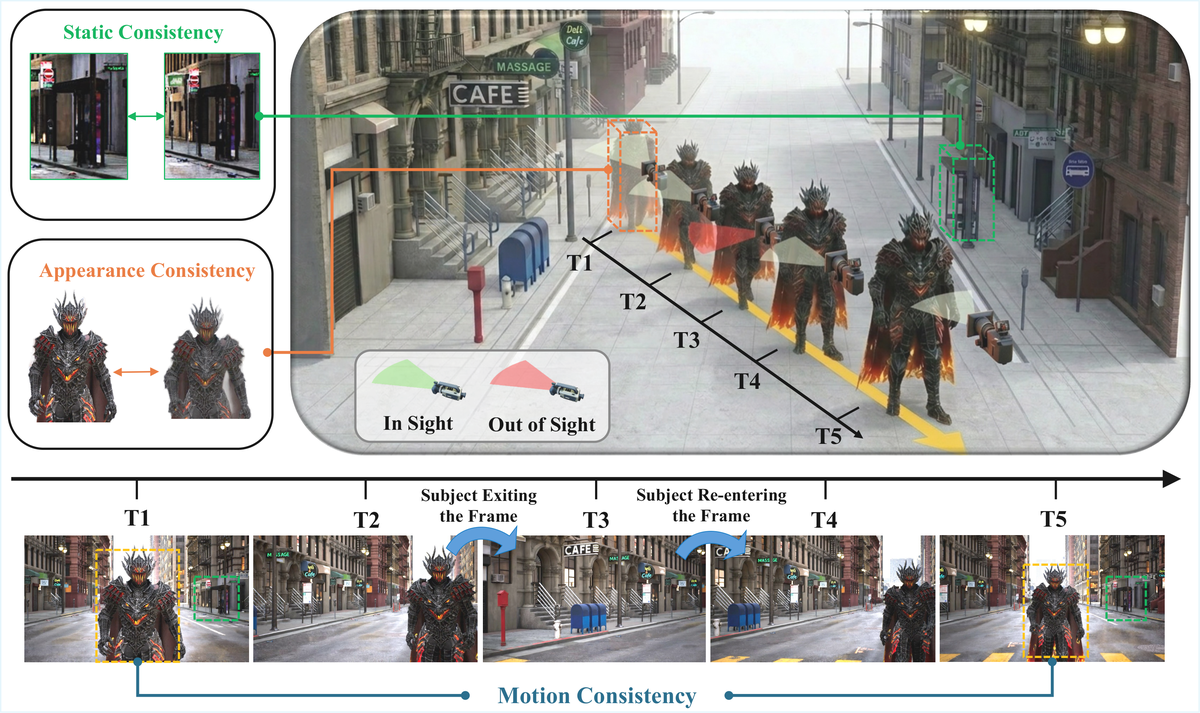
Figure 1 解读:图中把 static memory 与 hybrid memory 的差异可视化:背景只需保持静态一致,而动态主体在离开画面后仍需维持运动与外观状态;红色失败例展示了只记背景会让主体再入画时发生冻结、扭曲或消失。
2. Idea (核心思想)
核心洞察:长时程视频记忆不能只按相机 FOV 的几何重叠来检索,因为动态主体的位置和状态并不固定在某个静态背景区域里;更合理的做法是先把历史 context 压缩成时空 memory tokens,再让当前 denoising query 通过语义/时空相关性动态检索最相关的历史 token。
论文贡献拆成三层:1) 定义 Hybrid Memory 任务范式,要求模型同时维护静态背景一致性和动态主体连续性;2) 构造 HM-World,专门包含主体离开/进入视野事件的大规模合成数据集;3) 提出 HyDRA (Hybrid Dynamic Retrieval Attention),在 Wan2.1-T2V-1.3B 上用 memory tokenization + dynamic retrieval attention 替换普通 3D self-attention。
与 Context-as-Memory 这类静态检索方法的根本差异是:Context-as-Memory 主要根据目标视角与历史视角的 FOV overlap 选历史帧,适合静态场景;HyDRA 则用 target latent query 与 memory token key 的 QK 相似度做 Top-K 检索,能选择包含隐藏主体运动/外观线索的历史 token,即使它们和当前相机视角的静态重叠并不最大。
这个设计的关键不是把所有历史帧塞进 attention,而是把历史压缩后再选择性读取:local temporal window 保证当前 denoising 的局部连续性,Top-K memory tokens 提供跨较长时间跨度的主体线索。这样 HyDRA 同时避免了全量 context attention 的噪声/显存开销,以及 FOV-only 检索无法处理移动主体的盲点。
3. Method (方法)
3.1 问题设定与总体框架
给定 context frames 和完整相机轨迹 ,目标是生成未来帧 。训练仍采用 diffusion/flow matching 形式:
HyDRA 在 Wan2.1-T2V-1.3B 的 DiT block 中加入三类改动:相机条件注入、memory tokenizer、dynamic retrieval attention。整体上,context latents 作为历史记忆,target noisy latents 作为要去噪的未来片段;每个 target query 在去噪过程中检索局部窗口和全局 memory tokens。

Figure 4 解读:架构图展示 HyDRA 在 DiT 中插入相机编码、memory tokenizer 和 Dynamic Retrieval Attention。相机轨迹先被 MLP 编码后加到 latent feature 上;历史 context 经 3D VAE/Tokenizer 变成 memory tokens;target denoising latent 在 attention 中检索这些 token。
3.2 HM-World 数据构造
HM-World 使用 Unreal Engine 5 渲染,沿四个维度组合:17 个风格多样的 3D scenes、49 个 subjects(人和动物,组合成 1–3 个主体)、10 条 subject trajectory、28 条 camera trajectory。相机轨迹刻意包含 back-and-forth 运动,让主体发生 exit-entry 事件。过滤掉没有 exit-entry 的片段后,得到 59,225 个高保真视频,每个样本带视频、MiniCPM-V caption、相机 pose、逐帧 subject position、exit/entry 时间戳。

Figure 2 解读:图中展示主体由于相机往返运动而离开/回到视野的情况;这类样本专门测试模型是否能在不可见区间继续维护主体身份和动作状态。

Figure 3 解读:数据流程把场景、主体、主体轨迹、相机轨迹组合后渲染成动态视频。关键不是单纯增加视频数量,而是显式控制主体运动和相机运动的解耦,从而稳定制造 hybrid-memory 测试事件。
3.3 Camera condition injection
每帧相机 pose 写成旋转 与平移 ,展平成 ,经 MLP 编码后广播到空间维度,并与 DiT block 输入特征逐元素相加:
直觉上,camera injection 提供“将要看向哪里”的控制信号;如果没有它,模型只能从图像上下文猜未来视角,记忆检索也无法对齐相机运动。
3.4 Memory tokenization
历史 memory latents 不直接全量注入,因为这会带来计算开销并引入大量无关噪声。HyDRA 用 3D convolution tokenizer 压缩成 memory tokens:
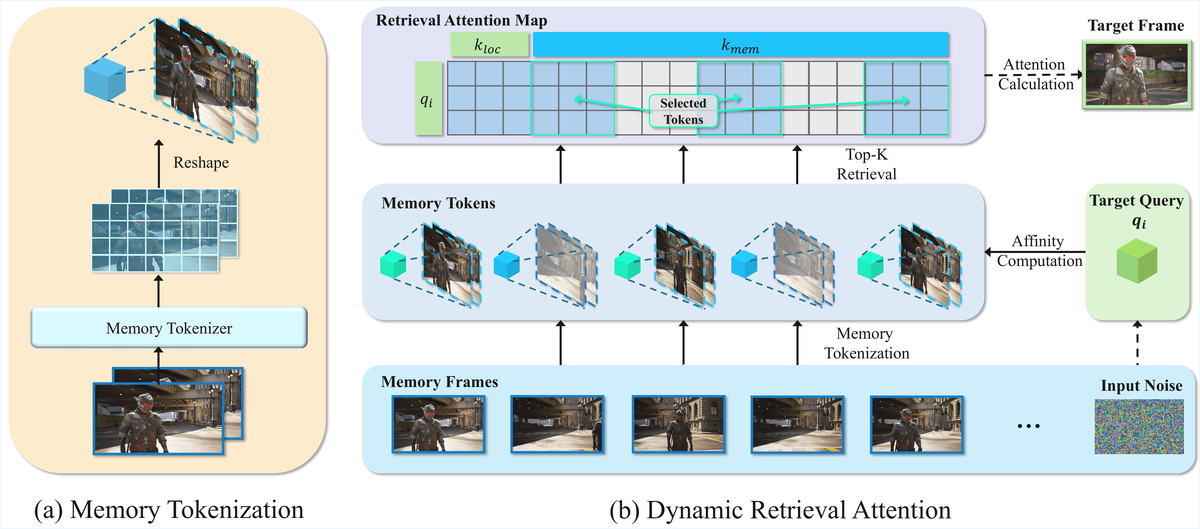
Figure 5 解读:左侧 memory tokenization 把 context frames 压缩成低分辨率时空 token;右侧 dynamic retrieval attention 对每个 target query 计算与 memory tokens 的相关性,选 Top-K token 与本地 temporal window 一起参与 attention。
3.5 Dynamic Retrieval Attention
对 target denoising latents 投影得到 query ,对 memory tokens 投影得到 。由于 query 和 memory token 空间分辨率不同,先把 池化到 ,然后计算第 个 target latent 与第 个 memory token 的时空亲和度:
之后选 Top-K memory tokens:
为了不破坏 denoising 的局部稳定性,HyDRA 还强制加入以当前帧 为中心的 local temporal window,得到 、,再做标准 attention:

Figure A4 解读:FOV overlap 的 token 选择分布较固定,因为它依赖静态几何重叠;dynamic affinity 的选择更分散,说明模型会在不同 DiT 层、不同 denoising 时刻检索不同历史线索。
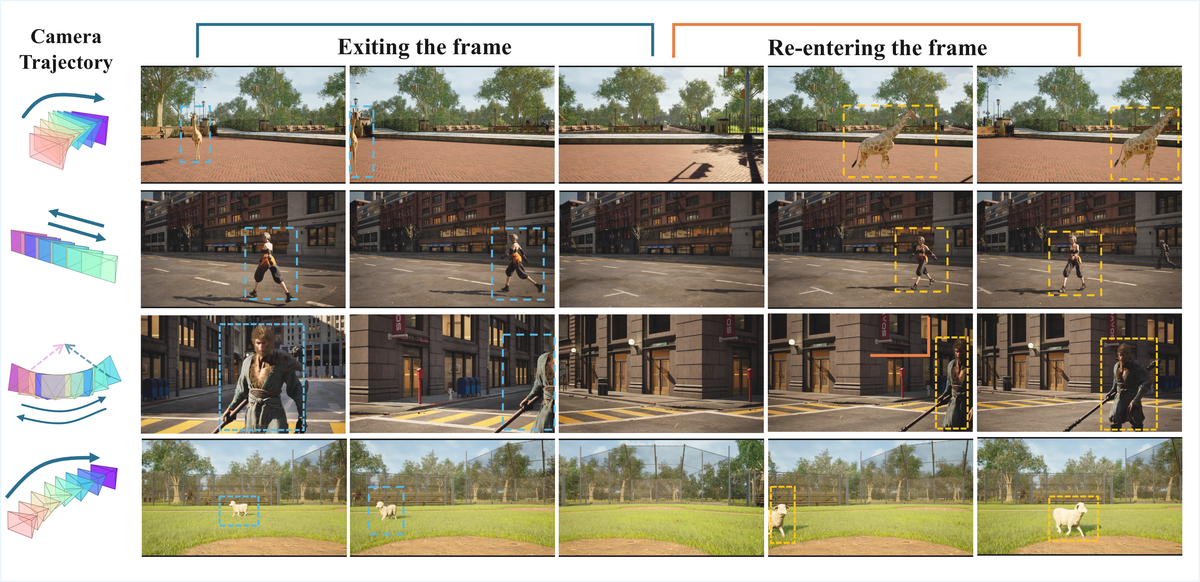
Figure A3 解读:对比检索方法时,上半部分显示被选中的历史 token 来源帧,下半部分显示生成结果;动态检索更容易取回与隐藏主体相关的帧,而 FOV overlap 更容易被静态视角几何约束住。
3.6 伪代码(基于 released code)
Code reference:
main@48652bec(2026-04-29) — pseudocode and mapping based on this commit
Component 1 — camera injection (diffsynth/models/wan_video_dit.py:558-575)
import torch
from einops import rearrange
def modulate(x, shift, scale):
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
def inject_camera_features(x, cam_emb_tgt, cam_emb_con, norm1, cam_encoder_tgt, cam_encoder_con,
shift_msa, scale_msa):
# x: [B, F*H*W, C], released code assumes F=40, H=30, W=52.
h = modulate(norm1(x), shift_msa, scale_msa)
h = rearrange(h, "b (f h w) c -> b c f h w", f=40, h=30, w=52).contiguous()
tgt = cam_encoder_tgt(cam_emb_tgt) # [B, 20, C]
tgt = tgt.unsqueeze(2).unsqueeze(3).repeat(1, 1, 30, 52, 1).permute(0, 4, 1, 2, 3)
h[:, :, 20:, ...] = h[:, :, 20:, ...] + tgt
ctx = cam_encoder_con(cam_emb_con) # [B, 20, C]
ctx = ctx.unsqueeze(2).unsqueeze(3).repeat(1, 1, 30, 52, 1).permute(0, 4, 1, 2, 3)
h[:, :, :20, ...] = h[:, :, :20, ...] + ctx
return rearrange(h, "b c f h w -> b (f h w) c").contiguous()Component 2 — memory tokenization (diffsynth/models/wan_video_dit.py:213-219)
import torch.nn as nn
class ReleasedMemoryTokenizer(nn.Module):
def __init__(self, dim: int):
super().__init__()
self.conv = nn.Conv3d(dim, dim, kernel_size=(2, 2, 2), stride=(2, 2, 2))
def forward(self, x):
# x: [B, C, F, H, W] -> [B, C, F/2, H/2, W/2]
return self.conv(x)Component 3 — dynamic retrieval attention (diffsynth/models/wan_video_dit.py:231-401)
import torch
import torch.nn.functional as F
from einops import rearrange
def flash_attention_simple(q, k, v, num_heads):
# q/k/v: [B, S, D]. This mirrors the released flash_attention wrapper semantically.
B, S_q, D = q.shape
head_dim = D // num_heads
q = rearrange(q, "b s (h d) -> b h s d", h=num_heads)
k = rearrange(k, "b s (h d) -> b h s d", h=num_heads)
v = rearrange(v, "b s (h d) -> b h s d", h=num_heads)
out = F.scaled_dot_product_attention(q, k, v)
return rearrange(out, "b h s d -> b s (h d)")
def mask_local_compressed_tokens(similarity, local_indices, compressed_stride=2):
# Released code masks compressed tokens whose source frame interval is already in the local window.
B, F_total, F_comp = similarity.shape
token_start = torch.arange(F_comp, device=similarity.device) * compressed_stride
token_end = token_start + compressed_stride
win_start = local_indices.min(dim=-1).values.unsqueeze(-1)
win_end = (local_indices.max(dim=-1).values + 1).unsqueeze(-1)
inside = (token_start.view(1, 1, -1) >= win_start) & (token_end.view(1, 1, -1) <= win_end)
return similarity.masked_fill(inside, -1e9)
def hydra_attention(q, k, v, k_comp, v_comp, num_heads, frame_hw=30 * 52,
top_k=10, window_size=5):
B, L, D = q.shape
F_total = L // frame_hw
q_frames = q.view(B, F_total, frame_hw, D)
k_frames = k.view(B, F_total, frame_hw, D)
v_frames = v.view(B, F_total, frame_hw, D)
# Released code builds compressed-frame representations from tokenizer output.
F_comp = k_comp.shape[1] // ((30 // 2) * (52 // 2))
HW_comp = k_comp.shape[1] // F_comp
k_comp_frames = k_comp.view(B, F_comp, HW_comp, D)
v_comp_frames = v_comp.view(B, F_comp, HW_comp, D)
q_repr = q_frames.mean(dim=2) # [B, F, D]
k_repr = k_comp_frames.mean(dim=2) # [B, F_comp, D]
similarity = torch.matmul(q_repr, k_repr.transpose(-2, -1))
radius = window_size // 2
local = []
for i in range(F_total):
start = min(max(i - radius, 0), F_total - window_size)
local.append(torch.arange(start, start + window_size, device=q.device))
local_indices = torch.stack(local, dim=0).unsqueeze(0).expand(B, -1, -1)
# Mask compressed tokens whose source interval falls inside the local window;
# those local frames are handled by K_loc/V_loc, not by global Top-K memory.
masked_similarity = mask_local_compressed_tokens(similarity, local_indices)
topk_indices = torch.topk(masked_similarity, k=top_k, dim=-1).indices
outputs = []
for i in range(F_total):
k_local = k_frames[:, local_indices[:, i], :, :].reshape(B, -1, D)
v_local = v_frames[:, local_indices[:, i], :, :].reshape(B, -1, D)
k_mem = k_comp_frames[torch.arange(B).unsqueeze(1), topk_indices[:, i]].reshape(B, -1, D)
v_mem = v_comp_frames[torch.arange(B).unsqueeze(1), topk_indices[:, i]].reshape(B, -1, D)
k_all = torch.cat([k_local, k_mem], dim=1)
v_all = torch.cat([v_local, v_mem], dim=1)
out_i = flash_attention_simple(q_frames[:, i], k_all, v_all, num_heads=num_heads)
outputs.append(out_i)
return torch.cat(outputs, dim=1)Component 4 — training step (train_hydra.py:100-144)
import torch
import torch.nn.functional as F
def train_step(pipe, batch, use_gradient_checkpointing=True, offload=False):
latents = batch["latents"].to(dtype=pipe.torch_dtype)
text_context = batch["context"].to(dtype=pipe.torch_dtype)
cam_ctx = batch["context_camera"].to(dtype=pipe.torch_dtype)
cam_tgt = batch["video_camera"].to(dtype=pipe.torch_dtype)
noise = torch.randn_like(latents)
timestep_id = torch.randint(0, pipe.scheduler.num_train_timesteps, (1,), device=latents.device)
timestep = pipe.scheduler.timesteps[timestep_id].to(dtype=pipe.torch_dtype, device=latents.device)
noisy = pipe.scheduler.add_noise(latents, noise, timestep)
split = noisy.shape[2] // 2
noisy[:, :, :split] = latents[:, :, :split] # context half is frozen / clean
target = pipe.scheduler.training_target(latents[:, :, split:], noise[:, :, split:], timestep)
pred = pipe.denoising_model()(noisy, timestep=timestep, cam_emb_tgt=cam_tgt,
cam_emb_con=cam_ctx, context=text_context,
use_gradient_checkpointing=use_gradient_checkpointing,
use_gradient_checkpointing_offload=offload)
return F.mse_loss(pred[:, :, split:].float(), target.float()) * pipe.scheduler.training_weight(timestep)3.7 Code-to-paper mapping
Code reference:
main@48652bec(2026-04-29) — pseudocode and mapping based on this commit
| Paper concept | Released code location | 实现说明 |
|---|---|---|
| Wan2.1-T2V-1.3B backbone + HyDRA pipeline | diffsynth/pipelines/HyDRA.py, diffsynth/models/wan_video_dit.py::WanModel | pipeline 将 source/context latents 与 target noise 拼接,在每个 timestep 预测 target 部分 noise。 |
| Camera trajectory injection | diffsynth/models/wan_video_dit.py:558-575 | cam_encoder_tgt/cam_encoder_con 把 12D pose 编成 hidden dim,分别加到 target/context 20 帧 latent 上。 |
| Memory tokenizer | diffsynth/models/wan_video_dit.py:213-219, train_hydra.py:54, infer_hydra.py:212 | release 版是 nn.Conv3d(dim, dim, kernel_size=(2,2,2), stride=(2,2,2)),被挂到每个 block 的 self_attn.tokenizer。 |
| Dynamic retrieval attention | diffsynth/models/wan_video_dit.py:231-401 | 计算 target-frame query 表示与 compressed memory key 表示的相似度,mask 本地窗口后 Top-K,再拼接 local window 与 compressed memory 做 flash attention。 |
| Training skeleton | train_hydra.py:100-144 | context 半段保持 clean,target 半段加噪并用 scheduler target 做 MSE;只训练 cam_encoder_*、projector、self_attn 相关模块。 |
| Inference wrapper | infer_hydra.py:196-231, infer_hydra.py:265-293 | 加载 base Wan2.1、HyDRA checkpoint、condition video 和 camera JSON,默认 480×832、77 frames、50 steps。 |
论文公式与 released code 实现差异:论文实验设置写 memory tokenizer kernel 为 ,Table 4 的最优配置也是 ;但 released code MemoryTokenizer 在 wan_video_dit.py:216 固定为 kernel_size=(2,2,2), stride=(2,2,2),train_hydra.py:54/infer_hydra.py:212 也没有传入 空间 kernel。此外 LightningModelForTrain.__init__ 有 top_k 参数,但 train_hydra.py:70-76 实例化 DynamicRetrievalAttention 时硬编码 top_k=10;这与论文默认值一致,但不是可配置实现。released repo 还明确说明训练代码是 skeleton,不包含内置 Dataset/DataLoader/完整 trainer loop,因此论文中的 10K iterations、32 GPUs、batch size 32 只能由论文文本锚定,不能从 release launch script 复现。
4. Experimental Setup (实验设置)
Datasets. 主训练集是 HM-World:59,225 个高保真合成视频,17 个 diverse scenes,49 个 distinct subjects,主体以 1–3 个为组,10 条 subject trajectories,28 条 camera trajectories;每个样本带 caption、camera poses、per-frame subject positions、exit/entry timestamps。测试集从 HM-World 随机抽取 1000 个视频样本,并包含训练未见过的 scenes 和 subjects。
Baselines. 论文比较 Baseline(Wan2.1-T2V-1.3B + camera encoder,直接拼接 context latents 与 noisy latents 作为 DiT 输入)、DFoT、Context-as-Memory,以及 zero-shot commercial model WorldPlay。除 WorldPlay 外,baseline/DFoT/Context-as-Memory 都在 HM-World 上按同一训练配置训练。
Metrics. PSNR/SSIM/LPIPS 衡量整体重建质量;Subject Consistency 和 Background Consistency 来自 VBench,用于 frame-level coherence;DSC 专门评估 re-entry 动态主体一致性,先用 YOLOv11 框出 moving subjects,再用 CLIP features 计算 DSC_{GT}/DSC_{ctx}:
Training config. 论文报告基座为 Wan2.1-T2V-1.3B;输入编码 77 个 context frames,经 3D VAE 时间下采样 4 倍;memory tokenizer 使用 3D conv;retrieval token length 为 10;denoising latent local window 为 5;训练 10K iterations,32 GPUs,总 batch size 32。released code 可确认 train_hydra.py 默认 learning_rate=1e-5、train_timesteps=1000,但没有发布实际 HM-World launch config 或 DataLoader。
5. Experimental Results (实验结果)
主结果。 HyDRA 在 HM-World 上所有指标领先。相对 Baseline,PSNR 从 18.696 提升到 20.357,SSIM 从 0.517 提升到 0.606,DSCctx/DSCGT 达到 0.827/0.849;这说明它不仅更像 GT,也更能对齐历史 context 中的主体身份和运动状态。
| Method | Ref. | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DSCctx ↑ | DSCGT ↑ | Subject Cons. ↑ | Background Cons. ↑ |
|---|---|---|---|---|---|---|---|---|
| Baseline | - | 18.696 | 0.517 | 0.356 | 0.812 | 0.837 | 0.903 | 0.925 |
| DFoT | ICML 25 | 17.693 | 0.482 | 0.410 | 0.803 | 0.826 | 0.893 | 0.913 |
| Context-as-Memory | SIGGRAPH Asia 25 | 18.921 | 0.530 | 0.342 | 0.816 | 0.839 | 0.911 | 0.922 |
| HyDRA | - | 20.357 | 0.606 | 0.289 | 0.827 | 0.849 | 0.926 | 0.932 |
与 WorldPlay 比较。 WorldPlay zero-shot 在 context-referenced DSCctx 上有 0.822,说明大商业模型具备一定 hybrid consistency;但 HyDRA 经过 HM-World 训练后在 PSNR/SSIM/LPIPS/DSC/一致性全部更好,PSNR 差距为 5.502。
| Method | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DSCctx ↑ | DSCGT ↑ | Subject Cons. ↑ | Background Cons. ↑ |
|---|---|---|---|---|---|---|---|
| WorldPlay | 14.855 | 0.355 | 0.500 | 0.822 | 0.832 | 0.910 | 0.925 |
| HyDRA | 20.357 | 0.606 | 0.289 | 0.827 | 0.849 | 0.926 | 0.932 |

Figure 6 解读:绿色框表示成功保持主体一致性,红色框表示失败。DFoT 和 Context-as-Memory 更容易出现主体扭曲、运动不连续或消失;WorldPlay 外观稳定但动作有卡顿;HyDRA 更好地同时保持身份和运动。

Figure A1 解读:补充结果展示 HyDRA 在多种场景、主体和相机轨迹上的生成能力,用来说明方法不只适用于单一 synthetic layout。

Figure A2 解读:open-domain 例子展示模型在更开放 prompt/场景中的泛化趋势,但论文的严谨定量仍主要建立在 HM-World 测试集上。
Ablation:memory tokenizer kernel。 空间 kernel 从 改到 或 只让 PSNR 分别下降 0.244/0.127,说明空间压缩尺度较鲁棒;但时间维度从 2 降到 1 时,PSNR 从 20.357 降到 19.076,DSCGT 从 0.849 降到 0.841,说明 temporal interaction 对隐藏主体状态建模更关键。
| T | H×W | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DSCctx ↑ | DSCGT ↑ | Subject Cons. ↑ | Background Cons. ↑ |
|---|---|---|---|---|---|---|---|---|
| 2 | 2×2 | 20.113 | 0.599 | 0.299 | 0.820 | 0.843 | 0.919 | 0.929 |
| 2 | 4×4 | 20.357 | 0.606 | 0.289 | 0.827 | 0.849 | 0.926 | 0.932 |
| 2 | 8×8 | 20.230 | 0.610 | 0.292 | 0.822 | 0.843 | 0.923 | 0.927 |
| 1 | 4×4 | 19.076 | 0.554 | 0.337 | 0.819 | 0.841 | 0.912 | 0.925 |

Figure A5 解读:kernel size 的定性对比用红框标出不一致区域;时间维度不足时更容易丢失长程动态信息,空间 kernel 的影响相对小。
Ablation:retrieved token number。 只检索 5 个 tokens 会造成信息不足,PSNR 只有 19.309;10 和 15 的性能接近,说明适中数量已能覆盖必要时空信息,继续增加会带来冗余但收益有限。
| Retrieved tokens | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DSCctx ↑ | DSCGT ↑ | Subject Cons. ↑ | Background Cons. ↑ |
|---|---|---|---|---|---|---|---|
| 5 | 19.309 | 0.566 | 0.339 | 0.817 | 0.836 | 0.913 | 0.927 |
| 10 | 20.357 | 0.606 | 0.289 | 0.827 | 0.849 | 0.926 | 0.932 |
| 15 | 20.333 | 0.612 | 0.291 | 0.828 | 0.842 | 0.925 | 0.935 |

Figure A6 解读:检索 token 太少时,模型缺少足够历史证据来恢复再入画主体;10/15 的定性结果更稳定,也与表格中 10 已接近饱和的结论一致。
Ablation:retrieval approach。 Dynamic Affinity 比 FOV Overlap 全面更好,尤其 Subject Consistency 从 0.908 提升到 0.926;这直接验证了论文的核心主张:动态主体的记忆检索不能只靠静态几何 overlap。
| Retrieval | PSNR ↑ | SSIM ↑ | LPIPS ↓ | DSCctx ↑ | DSCGT ↑ | Subject Cons. ↑ | Background Cons. ↑ |
|---|---|---|---|---|---|---|---|
| FOV Overlap | 19.776 | 0.586 | 0.300 | 0.820 | 0.844 | 0.908 | 0.930 |
| Dynamic Affinity | 20.357 | 0.606 | 0.289 | 0.827 | 0.849 | 0.926 | 0.932 |

Figure A7 解读:动态亲和度检索比 FOV overlap 更能选择包含主体运动线索的 memory;这解释了为什么它在 Subject Consistency 和 DSC 上更稳定。
局限。 作者明确指出:当场景高度复杂、包含三个或更多主体或严重遮挡时,HyDRA 的一致性会退化;未来方向是更鲁棒的多主体记忆机制,并扩展到 unconstrained real-world environments。