MMPL: Macro-from-Micro Planning for High-Quality and Parallelized Autoregressive Long Video Generation
Authors: Xunzhi Xiang, Yabo Chen, Guiyu Zhang, Zhongyu Wang, Zhe Gao, Quanming Xiang, Gonghu Shang, Junqi Liu, Haibin Huang, Yang Gao, Chi Zhang, Qi Fan, Xuelong Li Affiliations: Nanjing University, Institute of Artificial Intelligence (China Telecom / TeleAI), Shanghai Jiao Tong University, Chinese University of Hong Kong (Shenzhen), University of Chinese Academy of Sciences GitHub: Tele-AI/MMPL
1. Motivation (研究动机)
1.1 长视频生成面临的核心挑战
当前自回归 (AR) 扩散模型在视频生成方面表现出色, 但在生成长视频时面临两个根本性问题:
- 误差累积导致时序漂移 (Temporal Drift): AR模型每一帧依赖之前所有帧, 早期帧的小误差会在后续预测中不断放大, 导致语义偏移、颜色变化和结构性伪影
- 严格串行生成阻碍并行化: 现有AR方法逐帧生成的特性使其无法在多GPU上并行加速
1.2 理论分析:误差累积的数学本质
论文从模仿学习 (Imitation Learning) 的角度分析了AR模型的误差累积。将AR视频生成建模为序列决策问题:
训练时使用 teacher forcing (ground-truth 前缀), 推理时使用模型自身的预测, 产生 exposure bias。基于行为克隆的 regret 分析:
其中 是每步平均误差。这说明即使每步误差很小, 累积误差也可能随 线性甚至二次增长, 解释了长视频生成中观察到的渐进漂移现象。
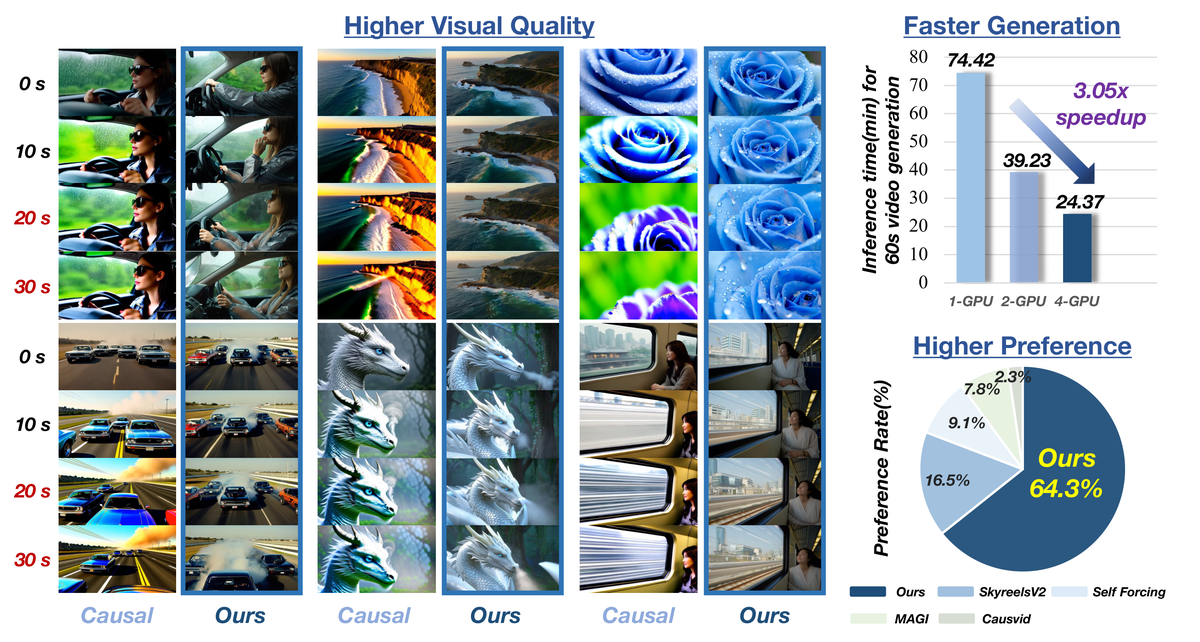
Figure 1 解读: 左侧对比展示 Causal (传统AR) 和 MMPL 在0s/10s/20s/30s的视觉质量, 传统AR方法随时间推移出现严重的语义偏移、颜色漂变和结构伪影, 而MMPL保持稳定的视觉质量。右上角柱状图显示推理加速效果: 1-GPU (74.42 min) → 2-GPU (39.23 min) → 4-GPU (24.37 min), 实现 3.05x 加速。右下角饼图显示用户偏好: MMPL获得 64.3% 的偏好率, 远超其他方法。
2. Idea (核心思想)
2.1 Planning-then-Populating
受专业电影制作流程启发 (先制作分镜, 再并行拍摄各场景), 论文提出先规划后填充的范式:
- 先通过层级规划建立全局故事线 (稀疏关键帧)
- 再并行填充各段中间帧

Figure 2 解读: 展示现有AR方法的逐帧串行生成过程。左右两个segment各自通过 “Next Frame Predict” 逐步生成, 然后通过 “Segment Connect” 拼接。这种方式每一帧都严格依赖前一帧, 无法并行, 且误差逐帧累积。

Figure 3 解读: MMPL整体框架。(a) Micro Planning: 对单个segment (N帧), 从初始帧 出发, 通过DiT一次性联合预测3个稀疏关键帧 (early , midpoint , terminal )。(b) Macro Planning: 将多个segment的Micro Planning串联, segment 的末端规划帧作为 segment 的初始帧, 形成段级自回归链。关键创新在于: 段内关键帧联合生成 (无误差累积), 段间通过稀疏锚点传递 (大幅压缩AR链长度)。
2.2 核心思想总结
- 用稀疏规划帧替代逐帧生成中的长AR链
- 用段级规划把长视频拆成若干更稳定的局部片段
- 用并行内容填充把段内中间帧一次补齐
3. Method (方法)
3.1 Micro Planning (微观规划)
目标: 为每个segment构建短时间线, 预测稀疏关键帧作为后续内容生成的稳定锚点。
具体实现: 给定segment的初始帧 , 联合预测三个 pre-planning frames:
其中:
- : early frame, 初始帧的近邻
- : midpoint frame, 全局中点
- : terminal frame, segment末尾
关键优势: 所有pre-planning frames都仅以初始帧 为条件联合优化:
- 与 的偏差可忽略
- 各帧之间相互约束, 残差误差可忽略
- 避免了逐帧AR的累积漂移
实际参数设置 (基于Wan2.1模型, 21个latent token):
- (indices 2-3 对应 early)
- (indices 10-12 对应 midpoint)
- (indices 19-20 对应 terminal)
3.2 Macro Planning (宏观规划)
目标: 将各segment的Micro Plan串联为全局故事线, 确保长程一致性。
其中 segment 的初始帧 来自上一个 segment 的末端规划帧。
核心效果: 将原始 帧级别的逐帧AR链压缩为 段级别的段级AR链 (), 大幅降低误差累积规模。
3.3 Drift-Resilient Re-Encoding and Decoding (抗漂移重编码)
问题: 直接将前段末端latent作为下段前缀, 会因分布不匹配导致段间边界的颜色偏移和闪烁。原因是: 第一帧latent仅编码静态图像, 而后续帧latent包含了时间压缩信息, 统计特性不一致。

Figure 4 解读: 抗漂移重编码策略。Segment-1的末端latent tokens与初始latent token拼接后送入VAE Decoder解码为视频帧, 再通过VAE Encoder重新编码为Segment-2的初始latent tokens。这种”解码-重编码”操作确保了跨段边界的统计一致性和时间连续性, 抑制颜色偏移和边界闪烁。
具体操作:
- 将前段初始latent token与末端planning tokens拼接
- 送入VAE decoder解码为视频帧
- 由于VAE decoding要求时间连续的输入, 将末端planning tokens复制一份插入初始token和原始末端tokens之间
- 重新编码后的latent作为下段Micro Planning的初始条件
3.4 MMPL-based Content Populating (内容填充)
Micro Plan将每个segment划分为两个 sub-segment, 以连续的planning frames为边界:
- Sub-segment 1: (early到midpoint)
- Sub-segment 2: (midpoint到terminal)

Figure 5 解读: 两阶段Content Populating。(a) Stage 1: 以initial frame和early planning frame为头、midpoint planning frame为尾, 生成中间内容。(b) Stage 2: 以所有已有帧 (initial到midpoint) 为头、terminal planning frame为尾, 生成剩余内容。两个阶段填充了planning frames之间的所有中间帧。
数学表达:
并行化核心: 各sub-segment的内容生成仅依赖其边界planning frames, 一旦planning frames就绪, 所有segment的content populating可以并行执行:
3.5 Adaptive Workload Scheduling (自适应负载调度)
问题: 由于Macro Planning是段级AR, 必须等所有段的planning frames生成后才能开始并行填充, 引入前缀延迟。
解决方案: 动态调整Micro Planning、Macro Planning和Content Populating的执行顺序, 实现流水线并行。

Figure 6 解读: 多GPU并行推理的自适应调度。左上: Causal单GPU的逐帧串行生成。右上: MMPL单GPU, 先规划所有关键帧再填充。左下: Minimum Memory Peak Prediction 模式 (2-GPU), 当segment 0的planning frames () 就绪后, segment 1立即在GPU:2上开始Micro Planning, 同时GPU:1继续填充segment 0的中间帧。右下: Maximum Throughput Prediction 模式, 使用 而非 作为下段初始帧, 消除段间帧冗余, 最大化吞吐。
两种并行模式:
| 模式 | 下段初始帧 | 特点 |
|---|---|---|
| Minimum Memory Peak | 跳过 到 , 降低峰值显存, 略减吞吐 | |
| Maximum Throughput | 段内完整生成, 无帧冗余, 最大化流水线效率 |
形式化:
3.6 Noise Initialization for Smoothing (噪声初始化平滑策略)
为解决planning frames和content frames边界处的时间不连续, 提出基于相邻planning frames噪声插值的初始化策略:
其中 和 分别为相邻planning frames的噪声向量, 控制插值权重, 确保扩散过程中噪声模式的连续演变。
3.7 Recency Bias 对策: Local Multi-Frame Set
AR decoder在sub-segment边界容易过度依赖最近的帧 (recency bias), 导致尾部累积误差传播。解决方案是用 local multi-frame set 替代单一前驱帧:
条件分布改进为:
紧凑的多帧bundle稀释了前段尾部的残差误差, 同时利用recency bias自然地优先关注bundle内帧, 抑制跨边界误差传播。
3.8 伪代码与算法流程
def MMPL_inference(prompt, image, num_segments=S, num_gpus=G):
"""Macro-from-Micro Planning inference pipeline"""
# ====== Phase 1: Macro Planning (段级自回归) ======
# 初始化: 第一个segment的初始帧
x_init = encode(image) # VAE encode initial image
all_planning_frames = []
all_content = []
for s in range(S):
# --- Micro Planning: 联合预测稀疏关键帧 ---
# 输入: segment s 的初始帧
# 输出: early (t_a), midpoint (t_b), terminal (t_c) planning frames
planning_frames_s = micro_planning(
x_init_s, # 初始帧 latent
prompt, # 文本条件
positions=[t_a, t_b, t_c] # 目标位置: [2,3,4], [9,10,11], [19,20,21]
) # DiT forward pass with attention mask
all_planning_frames.append(planning_frames_s)
# --- 段间传递: 抗漂移重编码 ---
if s < S - 1:
# 拼接初始latent + 末端planning tokens
concat_latent = cat([x_init_s, planning_frames_s.terminal])
# VAE decode -> video frames -> VAE re-encode
video_frames = vae_decode(concat_latent)
x_init_next = vae_encode(video_frames[-K:]) # 取末尾K帧重编码
x_init_s = x_init_next
# ====== Phase 2: Content Populating (并行填充) ======
# 分配各segment到不同GPU
gpu_assignments = adaptive_schedule(all_planning_frames, G)
# 并行执行各segment的内容填充
parallel_for gpu_id, segments in gpu_assignments:
for s in segments:
M_s = all_planning_frames[s]
# Stage 1: 填充 early -> midpoint
content_1 = populate(
head=cat(x_init_s, M_s.early),
tail=M_s.midpoint,
noise_init=interpolate_noise(M_s.early, M_s.midpoint, alpha)
)
# Stage 2: 填充 midpoint -> terminal
content_2 = populate(
head=cat(x_init_s, M_s.early, content_1, M_s.midpoint),
tail=M_s.terminal,
noise_init=interpolate_noise(M_s.midpoint, M_s.terminal, alpha)
)
all_content[s] = cat(content_1, content_2)
# ====== Phase 3: 拼接最终视频 ======
final_video = assemble(all_planning_frames, all_content)
return vae_decode(final_video)
def adaptive_schedule(planning_frames, num_gpus):
"""自适应负载调度 - 实现Planning和Populating的流水线并行"""
# 当segment s 的 planning frames 就绪后:
# - GPU_1 继续 segment s 的 content populating
# - GPU_2 立即开始 segment s+1 的 micro planning
# 动态分配, 最大化GPU利用率
...3.9 Planning-based Inference 详细步骤 (81帧序列, 21 latent tokens)

Figure 11 解读: 展示基于Wan模型21个latent token的4步规划推理过程。Initial State: 所有21个token待预测。Step 1: 预测indices 2-3 (early planning frames)。Step 2: 预测indices 10-12 (midpoint planning frames)。Step 3: 预测indices 19-20 (terminal planning frames)。Step 4: 并行填充所有中间帧。Pre-Planning latent tokens在去噪过程中作为稳定锚点, 引导所有中间帧的合成。
4. Experimental Setup (实验设置)
4.1 训练配置
| 配置项 | 参数 |
|---|---|
| 基础模型 | Wan2.1-T2V-14B (DiT-based Flow Matching) |
| 分辨率 | 832 x 480 |
| 训练数据 | ~50k 精选高质量视频 (licensed + web-collected) |
| 训练设备 | 32 x H100 GPUs (80GB each) |
| 训练步数 | 8,000 iterations |
| 训练时间 | Teacher Forcing 14B: ~3天; DMD 1.3B: ~1天 |
| 优化器 | AdamW, lr = |
| Batch size | 32 (per-GPU batch = 1, no gradient accumulation) |
| Attention | FlexAttention + FlashAttention-v3 |
| 更新策略 | Only Self-Attention (最优, 见消融实验) |
4.2 评测设置
- 主评测使用 VBench-long
- 人类评估使用 19 个 30 秒视频, 共 29 名参评者
- 评估维度包括 text-visual alignment, content consistency, color shift
- 加速实验在 1 / 2 / 4 GPU 配置下报告推理时间
4.3 代码实现与复现
代码仓库结构:
MMPL/
├── MMPL_i2v/ # Image-to-Video 推理代码
├── MMPL_t2v/ # Text-to-Video 推理代码
├── requirements.txt # 依赖: DiffSynth-Studio, flash-attn
├── demo.png
└── README.md
环境要求:
- Python 3.10, Linux OS
- 32GB+ GPU (1.3B模型) / 80GB+ GPU (14B模型)
- 64GB 系统内存
推理命令:
# T2V 单GPU推理
bash MMPL_t2v/Wan_t2v_1gpu.bash
# T2V 4-GPU并行 (20秒视频)
bash MMPL_t2v/Wan_t2v_4gpu_20s.bash
# I2V 单GPU推理
bash MMPL_i2v/Wan_i2v_1gpu.bash
# I2V 4-GPU并行 (20秒视频)
bash MMPL_i2v/Wan_i2v_4gpu_20s.bash预训练权重:
- 基础模型: Wan2.1-T2V-1.3B / 14B
- MMPL checkpoints:
i2v_14B_6k.pt,t2v_14B_8k.pt
5. Experimental Results (实验结果)
5.1 主实验: VBench-long 评测
| Model | Subject Consistency | Background Consistency | Motion Smoothness | Aesthetic Quality | Imaging Quality |
|---|---|---|---|---|---|
| FIFO (Causal) | 0.956 | 0.960 | 0.949 | 0.588 | 0.603 |
| CausVid (Distilled) | 0.969 | 0.980 | 0.981 | 0.606 | 0.661 |
| SF (Distilled) | 0.967 | 0.958 | 0.980 | 0.593 | 0.689 |
| SkyReels-V2 (DF) | 0.956 | 0.966 | 0.991 | 0.600 | 0.581 |
| MAGI-1 (DF) | 0.979 | 0.970 | 0.991 | 0.604 | 0.612 |
| MMPL | 0.980 | 0.968 | 0.992 | 0.628 | 0.661 |
人类评估 (19个30秒视频, 29名参评者):
| Model | Text-Visual Alignment | Content Consistency | Color Shift |
|---|---|---|---|
| CausVid | 34.7 | 33.0 | 25.0 |
| SF | 52.0 | 46.1 | 50.5 |
| SkyReels-V2 | 47.9 | 51.4 | 51.3 |
| MAGI-1 | 34.7 | 40.4 | 39.5 |
| MMPL | 80.0 | 79.2 | 83.1 |
MMPL在所有三个人类评估维度上大幅领先, 用户偏好率达 64.3%。

Figure 7 解读: 定性对比。6组视频在T=0s/10s/20s/30s的帧。SkyReels、SF、CausVid和MAGI等AR baseline随时间推移出现严重的时序漂移 (模糊、褪色、色彩偏移、几何扭曲), 尤其在动态场景中退化更明显。MMPL在整个30秒序列中保持高视觉质量, 对运动漂移和颜色失真表现出强鲁棒性。
5.2 并行推理加速
| GPU数量 | 推理时间 (min) | 加速比 |
|---|---|---|
| 1 GPU | 74.42 | 1.0x |
| 2 GPUs | 39.23 | 1.90x |
| 4 GPUs | 24.37 | 3.05x |
- 2 GPU即可将推理时间减半
- 4 GPU将时间压缩至原来的约 1/3
- 对60秒视频同样显著缩短生成时间
5.3 消融实验
Planning Frame 位置消融 (Table 2):
| Variant | Subj. | Back. | Mot. | Aes. | Img. |
|---|---|---|---|---|---|
| w/o early planning | 0.972 | 0.964 | 0.991 | 0.610 | 0.640 |
| w/o midpoint planning | 0.977 | 0.968 | 0.992 | 0.618 | 0.637 |
| Full (完整MMPL) | 0.980 | 0.968 | 0.992 | 0.628 | 0.661 |

Figure 8 解读: 不同MMPL变体的定性对比。上半部分: 去掉early planning frames后, 初始帧到下一帧之间出现不连续跳变。下半部分: 去掉midpoint planning frames后, 中间帧质量下降, 远距离帧之间缺乏约束。完整MMPL的三级锚点 (early + midpoint + terminal) 产生最平滑的过渡和最稳定的长程内容。
训练策略消融 (Table 3):
| Strategy | Subj. | Back. | Mot. | Aes. | Img. |
|---|---|---|---|---|---|
| Freeze (冻结所有参数) | 0.838 | 0.923 | 0.973 | 0.484 | 0.503 |
| Only Q,K | 0.970 | 0.962 | 0.987 | 0.612 | 0.647 |
| Only Self-Attention | 0.980 | 0.968 | 0.992 | 0.628 | 0.661 |
更新整个self-attention (Q, K, V + attention output) 效果最好; 仅更新Q,K次优; 完全冻结效果最差。
5.4 数据准备

Figure 9 解读: 训练数据示例。数据集包含约50k高质量视频, 来源为: (1) 授权商业视频 (按LAION美学评分保留top 1%); (2) Mixkit/Pexels/Pixabay等开放平台网络视频 (人工质量控制)。标注使用Qwen-72B生成结构化JSON (short_caption + dense_caption), 训练时以0.8/0.2的概率采样dense/short caption。
5.5 扩展性: I2V与加速方法兼容

Figure 14 解读: MMPL从T2V无缝扩展到I2V, 无需架构修改或额外图像编码器, 仅调整自回归步数和顺序。参考图像 (左列) 到生成视频 (右列) 保持了时间一致性和视觉质量, 覆盖芭蕾、武术、跑步、瀑布等多样场景。

Figure 15 解读: MMPL与Self Forcing和DMD蒸馏策略的集成。仅需调整attention可见范围和预测顺序, 无需架构改动。结合并行解码, 可在长视频生成中达到 超过32 FPS 的推理速度, 展示了MMPL作为通用范式的灵活性。
5.6 VAE重编码效果

Figure 12 解读: 视频外推 (extrapolation) 的定性对比。当超出训练上下文长度需要段间拼接时, naive方法 (直接复用末端latent) 出现严重的颜色漂移和视觉伪影 (右列), 而MMPL的drift-resilient re-encoding策略有效缓解了这些退化 (中列), 保持了跨段的色彩一致性。
5.7 噪声初始化平滑效果

Figure 13 解读: 基于coherent noise initialization的平滑帧生成框架。上半部分为训练阶段: 对planning frame加噪得到target frame + noise, 对应ground truth。下半部分为推理阶段: 通过相邻planning frames的噪声加权插值 () 初始化content frame的噪声, 确保扩散逆过程中噪声模式的连续演变, 抑制planning frame和content frame边界处的视觉不连续。
5.8 用户研究

Figure 10 解读: 用户研究界面截图。每次试验中, 参与者评估5个由相同prompt生成的30秒视频, 在text-visual alignment、content consistency和long-sequence color stability三个维度进行1-5排名 (1=最佳, 5=最差), 并选择一个整体最喜欢的视频。29名参评者对19组视频的评估结果一致表明MMPL在所有维度上显著优于baseline。