MAGI-1: Autoregressive Video Generation at Scale
Affiliations: Sand AI arXiv: 2505.13211 GitHub: SandAI-org/MAGI-1 Year: 2025
1. Motivation (研究动机)
1.1 现有方法的问题
当前主流视频生成模型(如 Sora、HunyuanVideo、Wan2.1)采用**双向去噪(bi-directional denoising)**架构,存在以下核心问题:
- 缺乏因果性: 所有帧使用统一噪声水平、全局注意力同时处理整段视频,忽略了时间序列的因果结构
- 不支持流式生成: 必须一次性生成完整视频序列,无法在推理过程中逐步输出已完成的内容
- 固定视频长度: 推理时峰值资源消耗与视频总长度线性相关,无法生成任意长视频
- 多任务需要微调: T2V、I2V、V2V(视频续写)需要不同的模型架构或额外微调
1.2 核心洞察
将视频分割为固定长度的 chunk(每个 chunk = 24帧 = 1秒@24FPS),对每个 chunk 独立采样噪声,且时间上噪声单调递增(早期 chunk 更干净),就能在一个统一的自回归去噪框架中:
- 保持严格的因果性(每个 chunk 只依赖之前的 chunk)
- 天然支持流式生成(chunk 去噪到一定程度就可以开始下一个)
- 统一 T2V、I2V、V2V 任务(只需调整 clean chunk 的比例)
2. Idea (核心思想)
MAGI-1 的核心思想是将自回归建模与扩散去噪相结合,在 chunk 级别实现因果生成:
- Chunk-wise 自回归去噪: 视频被分为固定长度的 chunk 序列,每个 chunk 包含 24 帧。训练时对每个 chunk 独立加噪,且强制 (),即前面的 chunk 噪声更小(更干净)
- 流水线并行推理: 一个 chunk 不需要完全去噪就可以开始下一个 chunk 的生成,最多同时处理 4 个 chunk
- Block-Causal Attention: 在 chunk 内部使用双向注意力,chunk 之间使用因果注意力
- Shortcut Distillation: 训练单一模型支持 8/16/32/64 步推理,通过自一致性约束实现蒸馏
3. Method (方法)
3.1 Transformer-based VAE

Figure 2 解读:MAGI-1 的 Transformer VAE 架构。编码器使用 3D 卷积(kernel , stride )将输入映射为 1024 维特征,经过 24 层 Transformer Block 后投影到 32 维(16维 mean + 16维 log-variance)。解码器对称设计,使用 PixelShuffle 恢复空间分辨率。相比卷积 VAE,Transformer VAE 在推理速度上更快(得益于 GPU 对 Transformer 的优化),解码时间仅 12.28ms(最快)。
关键设计:
- 空间压缩 8x, 时间压缩 4x: 编码后特征维度为
- 24 层 Transformer Block: 使用 QKV Normalization 稳定训练
- 两阶段训练:
- Stage 1: 固定 分辨率,16帧短视频
- Stage 2: 可变分辨率( 或 像素),图像+视频联合训练
- 损失函数: L1 loss + KL divergence + LPIPS loss + GAN loss
- 推理: 空间滑窗(, stride 192, 25% overlap),时间无 overlap
VAE 性能对比:
| 模型 | PSNR | Params(M) | Encode(ms) | Decode(ms) |
|---|---|---|---|---|
| OpenSoraPlan-1.2 | 28.39 | 239 | 51.08 | 17.48 |
| CogVideoX | 35.99 | 216 | 40.19 | 142.96 |
| HunyuanVideo | 37.27 | 246 | 124.39 | 47.11 |
| Wan2.1 | 35.95 | 127 | 51.91 | 79.43 |
| MAGI-1 VAE | 36.55 | 614 | 36.68 | 12.28 |
VAE 伪代码
class MAGI1_VAE_Encoder:
"""Transformer-based VAE Encoder"""
def forward(self, video): # video: [B, T, 3, H, W]
# 3D Conv embedding: kernel=8x8x4, stride=8x8x4
x = self.conv3d_embed(video) # [B, T/4, H/8, W/8, 1024]
x = x + self.pos_embed # absolute positional embedding
for block in self.transformer_blocks: # 24 layers
# Self-attention with QKV normalization
x = block(x)
x = self.layernorm(x)
x = self.linear_proj(x) # -> [B, T/4, H/8, W/8, 32]
mean, logvar = x[:, :, :, :, :16], x[:, :, :, :, 16:]
z = mean + torch.randn_like(mean) * torch.exp(0.5 * logvar)
return z # [B, T/4, H/8, W/8, 16]
class MAGI1_VAE_Decoder:
"""Symmetric Transformer-based Decoder"""
def forward(self, z): # z: [B, T/4, H/8, W/8, 16]
x = self.linear_proj(z) # -> [B, T/4, H/8, W/8, 1024]
x = x + self.pos_embed
for block in self.transformer_blocks: # 24 layers
x = block(x)
x = self.layernorm(x)
x = self.pixel_shuffle(x) # spatial upsample 8x
x = self.conv3d_out(x) # kernel=3x3x3 -> [B, T, 3, H, W]
return x3.2 自回归去噪模型
3.2.1 训练目标(Flow Matching)
给定包含 个 chunk 的训练视频,对每个 chunk 独立采样高斯噪声。第 个 chunk 的噪声插值:
其中 是第 个 chunk 的 clean latent, 是对应的高斯噪声。Ground-truth velocity:
关键约束: 对每个 chunk 采样的时间步 满足 单调递增 (),即前面的 chunk 噪声更小。训练目标:
与双向模型的对比——双向模型所有 chunk 共享同一时间步:

Figure 1 解读:MAGI-1 的 chunk-wise 自回归去噪过程示意。左侧展示了视频以 24 帧为一个 chunk 进行分段生成,每个 chunk 的噪声水平递增(越靠后的 chunk 噪声越大)。右侧展示了 Block-Causal Attention Mask,chunk 内部双向注意力,chunk 之间因果注意力。一旦前面的 chunk 去噪到一定程度,后续 chunk 就可以开始生成,实现流水线并行。
3.2.2 模型架构(Diffusion Transformer)

Figure 3 解读:MAGI-1 的自回归去噪模型架构。基于 DiT 架构进行了多项关键修改:(a) 整体架构包含 Patch Embed、N 层 Transformer Block、Final Stem;(b) Parallel Attention Block 将 self-attention 和 cross-attention 并行计算,减少 TP 通信;(c) FFN 使用 Sandwich Normalization,在 FFN 前后各加一层 LayerNorm,SoftCap Gate 替代 adaLN 用于时间步调制。
核心架构修改:
- Block-Causal Attention: chunk 内全注意力 + chunk 间因果注意力,使用可学习的 3D RoPE 编码位置信息
- Parallel Attention Block: self-attention 和 cross-attention 共享 Q 投影,并行计算,将 TP 通信从每个 block 2轮降到1轮
- QK-Norm + GQA: 同时应用于 spatial-temporal attention 和 cross-attention
- Sandwich Normalization: FFN 前后各加 LayerNorm,解决大模型数值不稳定
- SwiGLU: 24B 模型的 FFN 激活函数(4.5B 使用 GLU)
- Softcap Modulation: 用 Softcap(值域 )替代 adaLN 的缩放因子,避免大模型中激活值爆炸
模型规格:
| 配置 | 4.5B | 24B |
|---|---|---|
| Layers | 34 | 48 |
| Model Dim | 3072 | 6144 |
| FFN Dim | 12288 | 16384 |
| FFN Activation | GLU | SwiGLU |
| Attention | GQA + QK-Norm | GQA + QK-Norm |
| Attention Heads | 128 (8 groups) | 128 (8 groups) |
| Cross Attn Heads | 128 (8 groups) | 128 (8 groups) |
| Position Embed | Learnable 3D RoPE | Learnable 3D RoPE |
| Optimizer | AdamW | AdamW |
| Peak LR | ||
| Warmup | 1000 steps | 10000 steps |
DiT Block 伪代码
class ParallelAttentionBlock:
"""Parallel self-attention + cross-attention with SoftCap modulation"""
def forward(self, x, text_cond, timestep_embed):
# Input normalization
x_normed = self.layernorm(x)
# Shared Q projection (reduces TP communication)
q = self.q_proj(x_normed) # shared for self-attn & cross-attn
# Self-attention (block-causal: full within chunk, causal across chunks)
k_self, v_self = self.kv_proj_self(x_normed)
# Apply learnable 3D RoPE
q_self, k_self = apply_3d_rope(q, k_self)
# QK-Norm
q_self, k_self = l2_normalize(q_self), l2_normalize(k_self)
attn_self = block_causal_attention(q_self, k_self, v_self) # GQA
# Cross-attention with text condition
k_cross, v_cross = self.kv_proj_cross(text_cond)
k_cross, v_cross = l2_normalize(k_cross), l2_normalize(v_cross)
attn_cross = attention(q, k_cross, v_cross) # GQA
# Combine and apply SoftCap gate
attn_out = self.linear(torch.cat([attn_self, attn_cross], dim=-1))
gate = torch.tanh(self.softcap_gate(timestep_embed)) # [-1, 1]
x = x + gate * attn_out
return x
class FFNWithSandwichNorm:
"""FFN with Sandwich Normalization and SoftCap gate"""
def forward(self, x, timestep_embed):
x_normed = self.layernorm_pre(x) # pre-norm
h = self.ffn(x_normed) # SwiGLU for 24B
h = self.layernorm_post(h) # post-norm (sandwich)
gate = torch.tanh(self.softcap_gate(timestep_embed))
return x + gate * h3.2.3 训练配置
三阶段训练策略 (以 4.5B 为例):
- Stage 1: 360p, 视频长度 8s, image:video = 4:1
- Stage 2: 480p, 视频长度 8s, image:video = 4:1, AR caption 10%
- Stage 3: 720p, 视频长度 16s, image:video = 4:1, AR caption 10%
24B 模型 Stage 1 分辨率降为 256p 以提高训练效率(更多 iteration 学习运动动力学)。
3.2.4 多任务统一

Figure 4 解读:不同任务通过调整 clean chunk 的比例实现统一。T2V 是所有 chunk 都加噪的情况;I2V 是第一个 chunk 只有第一帧是 clean 的特殊情况;V2V(视频续写)是前面若干 chunk 完全 clean 的情况。三种任务在同一个训练目标下统一,无需额外微调。
3.2.5 时间步采样策略

Figure 5 解读:训练时间步的概率密度分布。采用 Logit-Normal 采样策略并结合 timestep shift,将 70% 的训练计算分配给 的区域(低噪声区),因为视频在 时已经能生成清晰内容。参数设置:。
时间步密度函数(Logit-Normal + shift):
其中 。Timestep shift:
设置 ,使得 70% 训练计算分配到 。
时间步采样伪代码
def sample_timesteps_for_chunks(n_chunks, m=0, s=0.5, w=1/3):
"""Sample monotonically increasing timesteps for n chunks"""
# Sample from logit-normal distribution
t_raw = torch.sigmoid(torch.randn(n_chunks) * s + m)
# Apply timestep shift (bias toward lower noise)
t_shifted = w * t_raw / (1 - (1 - w) * t_raw)
# Sort to enforce monotonicity: t_0 < t_1 < ... < t_{n-1}
t_sorted, _ = torch.sort(t_shifted)
return t_sorted # earlier chunks have less noise3.2.6 Clean Chunk 设计
三个关键设计:
- Clean chunk 不使用文本条件: 用户在视频续写时通常会动态更新 prompt
- 注入最多 5% 噪声: 缓解 exposure bias
- Loss 仅应用于 noisy chunk: 避免 clean chunk 主导训练,但 clean chunk 仍通过 attention 参与梯度更新
3.3 Shortcut Distillation
采用 Shortcut Model(Frans et al., 2024)作为蒸馏目标。模型预测 velocity field ,其中 是期望步长。
Bootstrap 训练: 利用一个大步等价于两个半步的原理:
- 最小步长 (对应 64 步推理)
- 蒸馏步长从集合 循环采样
- 单一蒸馏模型支持 8, 16, 32, 64 步推理
- 蒸馏时同时融合 CFG distillation
Shortcut Distillation 伪代码
def shortcut_distillation_step(model, x_clean, x_noise, t, s):
"""One distillation training step using bootstrap"""
# Student: predict velocity with step size 2s
v_2s = model(noisy_x, t, step_size=2*s)
# Teacher (stop-grad): two consecutive steps of size s
with torch.no_grad():
v_s1 = model(noisy_x, t, step_size=s)
x_mid = noisy_x + delta_t1 * v_s1 # first half step
v_s2 = model(x_mid, t + delta_t1, step_size=s)
# Target: weighted average of two half-steps
dt1, dt2 = delta_t1, delta_t2
v_target = (dt1 * v_s1 + dt2 * v_s2) / (dt1 + dt2)
loss = mse_loss(v_2s, v_target)
return loss3.4 推理策略
3.4.1 Diffusion Guidance(扩展 CFG)
MAGI-1 将 classifier-free guidance 扩展为三项分解——无条件先验、时序上下文、文本条件:
- Non-distilled model: , ,需要 3 次 forward pass
- Distilled model: 直接使用 ,最终阶段加入

Figure 7(a) 解读: 时相邻 chunk 之间存在明显的对齐问题(如烟雾形状不连续)。

Figure 7(b) 解读: 时,chunk 间对齐显著改善,烟雾运动更平滑连续。这说明增强时序 guidance 对自回归视频生成非常重要。
3.4.2 Fine-Grained Guidance Control

Figure 9 解读:(a) 不使用 fine-grained control 时,超过 5 秒的视频会出现饱和和棋盘格伪影;(b) 当 时将 guidance 降为 ,伪影消除。这基于观察: 时视频的语义结构已基本确定,后续去噪步骤主要是超分辨率式的细节优化。
3.4.3 推理时间步采样
在推理时进一步引入幂次变换:
实验发现 (Quadratic-Shift)效果最佳。

Figure 8 解读:推理时间步采样策略对比。Quadratic-Shift(,绿线)在前期采样更密集,在低噪声阶段分配更多去噪步,最终视觉质量最优。
3.4.4 KV Cache
自回归结构天然支持 KV Cache:
- 已去噪的 chunk 的 KV 可缓存复用
- 通过限制 KV Range(如设为 8),生成长视频的计算成本恒定
- 动态调整不同去噪阶段的 KV Range 可实现可控镜头切换
3.5 模型能力展示
Chunk-wise 文本可控性

Figure 10 解读:近 30 秒的视频生成示例,展示通过逐 chunk 文本提示实现复杂叙事结构。每个子标题对应一个 chunk 的文本条件,从 (a)“微笑托腮” 到 (g)“狮子 logo 渐现”,展现了 MAGI-1 对复杂动作序列的分段控制能力。
可控镜头切换
![]()
Figure 12(a) 解读:通过在高噪声去噪阶段设置 KV Range=1(模型无法访问前面的视频内容),同时在其他阶段保持正常 KV Range=8,可以实现保持角色身份的镜头切换。
![]()
Figure 12(b) 解读:反过来,仅在低噪声阶段设置 KV Range=1,可以实现场景布局一致但物体细节变化的过渡效果。
3.6 数据处理流水线

Figure 13 解读:数据处理全流程。从原始视频/图像出发,经过镜头切割 → Actor-based 过滤(视频质量评估、美学评分、曝光检测、运动强度、相机稳定性、幻灯片检测、边框检测、文本检测、Logo检测、旁白人脸检测、转场检测)→ 去重(CLIP + DINOv2)→ MLLM 高级过滤 → Caption → 数据分布调整 → 训练集。
Caption 策略:
- 视频详细描述: MLLM 两阶段(先属性分析后描述生成),提取 4-12 关键帧
- 图像详细描述: MLLM 直接生成
- 自回归 Caption: 逐秒描述变化,支持 chunk-wise 文本控制
动态数据分布调整: 训练过程中持续监控模型表现,自适应调整不同类别数据的比例(如风景场景容易学习,人类表情更难)。
3.7 训练基础设施
MagiAttention

Figure 14 解读:MagiAttention 概览,包含五个核心组件:(1) Flex-Flash-Attention (FFA) 高效注意力 kernel,通过 AttnSlice 分解支持灵活 mask;(2) Dispatch Solver 实现计算负载均衡;(3) Group-Cast/Group-Reduce 零冗余通信原语;(4) 自适应多阶段计算-通信 overlap;(5) 前向和反向的流水线时间线。
核心创新:
- Flex-Flash-Attention: 基于 FlashAttention-3 扩展,通过
AttnSlice(QRange, KRange, MaskType 三元组)支持灵活的 attention mask 分解,天然适配分布式环境 - 计算负载均衡: chunk-wise permutable sharding + dispatch solver( 贪心算法)
- 零冗余通信: group-cast(仅发送到需要的 rank)+ group-reduce(仅从需要的 rank 收集),替代 all-to-all
- 自适应多阶段 Overlap: 计算和通信的流水线化,实现线性可扩展性
- 在线 Packing and Padding (PnP): 将变长视频序列高效打包,容量利用率达 99%
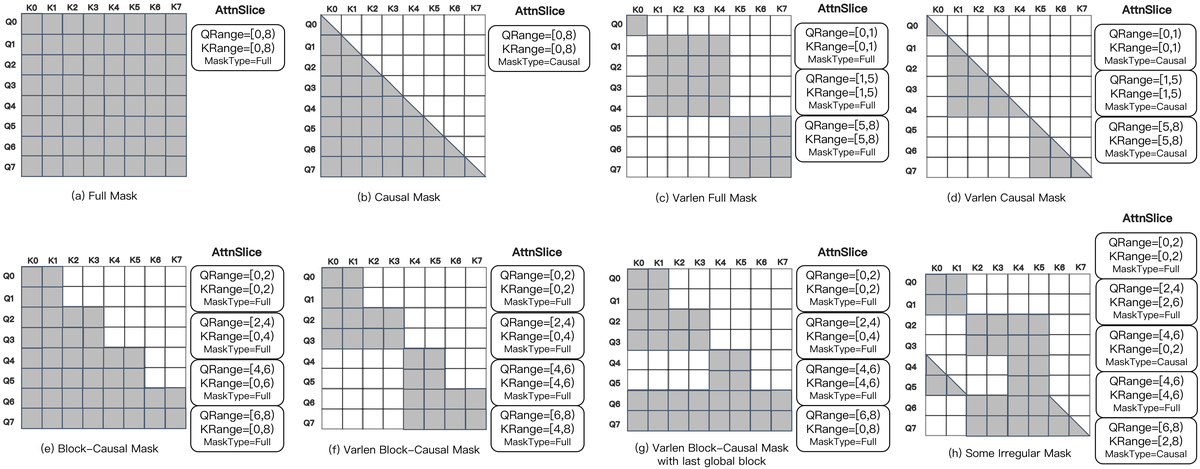
Figure 15 解读:AttnSlice 可以表达多种常见 attention mask 模式。(a)-(d) 是 FA3 兼容的标准模式(Full, Causal, Varlen Full, Varlen Causal),(e)-(h) 是超出 FA3 能力的复杂 mask(Block-Causal, Varlen Block-Causal, 含 global block 的 Varlen Block-Causal, 不规则 mask),FFA 均可无缝支持。
3.8 推理基础设施
实时流式推理(24B on 3x8 H100)
| 模型 | 优化 | TTFC(s) | 增益 | TPOC(s) | 增益 |
|---|---|---|---|---|---|
| AR Denoising | Baseline | 73.34 | - | 45.49 | - |
| AR Denoising | + KV Cache | 73.34 | - | 23.94 | 1.90X |
| AR Denoising | + Ulysses | 3.86 | 18.0X | 1.26 | 18.0X |
| AR Denoising | + SmoothQuant (W8A8 FP8) | 3.00 | 1.29X | 0.98 | 1.29X |
| AR Denoising | + CUDA Graph | 2.30 | 1.30X | 0.98 | - |
| VAE Decoder | Baseline | 1.00 | - | 1.00 | - |
| VAE Decoder | + Tile Parallel | 0.20 | 5.00X | 0.20 | 5.00X |
| VAE Decoder | + torch.compile | 0.07 | 2.86X | 0.07 | 2.86X |
| End-to-End | - | 2.37 | - | 0.98 | - |
关键指标: 480p (3:4) 视频,16步去噪,KV Range=5,24 H100 GPU
- TTFC (Time to First Chunk): 2.37 秒
- TPOC (Time Per Output Chunk): 0.98 秒(<1秒,实现实时流式)
- W8A8 FP8 量化带来 30% 加速,无质量损失
RTX 4090 部署
- 4.5B 模型: 单卡 RTX 4090(峰值显存 19.07 GB)
- 24B 模型: 8x RTX 4090(峰值显存 19.29 GB/卡,MFU 66%)
- 优化: SmoothQuant + KV-offload + Pipeline Parallelism + Context Shuffle Overlap (CSO)
4. Experimental Setup
4.1 评估体系
| 评估类别 | Benchmark | 指标 |
|---|---|---|
| 感知质量 | In-house 人工评估 | Overall, Motion Quality, Instruction Following, Visual Quality |
| 感知质量 | VBench-I2V | 自动化质量指标(I2V-Camera, I2V-Subject, Dynamic Degree 等) |
| 物理评估 | Physics-IQ Benchmark | Physics IQ Score, Spatial IoU, Spatio-Temporal, MSE |
4.2 人工评估设计
- 100 组图像-文本对,覆盖简单物体运动到复杂人体活动
- 双盲配对比较: Win/Tie/Lose
- 四个维度: Overall, Motion Quality, Instruction Following, Visual Quality
- 比较对象: Kling1.6 (HD), Hailuo (i2v-01), Wan-2.1, HunyuanVideo
4.3 VBench-I2V 配置
- 生成 4 秒视频 @24 FPS, 16:9
- 两个版本: MAGI-1 (1x decoder, 1280x720) 和 MAGI-1 (2x decoder, 2560x1440)
4.4 Physics-IQ 配置
- 8 秒真实物理视频,前 3 秒作为输入
- V2V: 使用完整 24 FPS 视频(96帧)作为输入
- I2V: 仅使用最后一帧作为输入
5. Experimental Results (实验结果)
5.1 VBench-I2V 结果
| 指标 | MAGI-1 (2x dec) | MAGI-1 (1x dec) | VisualPi | StepFun (TI2V) |
|---|---|---|---|---|
| I2V-Camera | 50.85 | 50.77 | 51.20 | 49.23 |
| I2V-Subject | 98.39 | 98.36 | 98.67 | 97.86 |
| I2V-Background | 99.00 | 98.98 | 98.87 | 98.63 |
| Subject Cons. | 93.96 | 94.28 | 96.87 | 96.02 |
| Motion Smooth. | 98.68 | 98.83 | 99.18 | 99.24 |
| Imaging Quality | 69.71 | 69.68 | 72.86 | 70.44 |
| Dynamic Degree | 68.21 | 63.41 | 49.93 | 48.78 |
| Aesthetic Quality | 64.74 | 61.89 | 61.91 | 62.29 |
| Total Score | 89.28 | 88.88 | 89.08 | 88.36 |
核心发现:
- MAGI-1 (2x decoder) Total Score = 89.28,排名第一
- Dynamic Degree = 68.21,大幅领先(第二名 63.41),解决了”增大运动幅度会降低图像质量”的常见 trade-off
- Aesthetic Quality 64.74 也排名第一
5.2 Physics-IQ Benchmark
| 模型 | Phys. IQ Score | Spatial IoU | Spatio-Temporal | MSE |
|---|---|---|---|---|
| MAGI-1 (V2V) | 56.02 | 0.367 | 0.270 | 0.005 |
| VideoPoet (V2V) | 29.50 | 0.204 | 0.164 | 0.010 |
| Lumiere (V2V) | 23.00 | 0.170 | 0.155 | 0.013 |
| MAGI-1 (I2V) | 30.23 | 0.203 | 0.151 | 0.012 |
| Kling1.6 (I2V) | 23.64 | 0.197 | 0.086 | 0.025 |
| Gen 3 (I2V) | 22.80 | 0.201 | 0.115 | 0.015 |
| Wan2.1 (I2V) | 20.89 | 0.153 | 0.100 | 0.023 |
| Sora (I2V) | 10.00 | 0.138 | 0.047 | 0.030 |
核心发现:
- V2V 模式下 Physics IQ = 56.02,比第二名 VideoPoet (29.50) 高出近一倍
- I2V 模式下 Physics IQ = 30.23,仍为所有 I2V 模型最高
- V2V vs I2V 的巨大差距(56.02 vs 30.23)证明了历史视频上下文对物理建模至关重要
- 自回归因果结构天然促进了物理因果推理能力
5.3 人工评估结果

Figure 16 解读:MAGI-1 与主要竞品的人工评估配对比较(Win/Tie/Lose 百分比)。Overall 维度上,MAGI-1 略逊于 Kling1.6 HD(17% vs 27%),但明显优于 Hailuo i2v-01(30% vs 22%)、Wan-2.1(28% vs 24%)和 HunyuanVideo(44% vs 12%)。在 Instruction Following 和 Motion Quality 方面 MAGI-1 表现尤为突出,Visual Quality 尚有提升空间。
5.4 历史上下文长度的影响

Figure 18 解读:Physics IQ Score 随 KV Range 增大而提升(从 KV Range=2 的约 47 提升到 KV Range=8 的约 56)。最显著的提升发生在 KV Range=2 处,说明短期历史上下文通常足以支持准确预测,但更长的上下文仍有边际收益。
6. 代码-论文对应表
| 论文组件 | 代码位置 (GitHub: SandAI-org/MAGI-1) | 说明 |
|---|---|---|
| 推理入口 | example/4.5B/, example/24B/ | T2V/I2V/V2V 的 JSON 配置和运行脚本 |
| 核心推理逻辑 | inference/ | 去噪循环、CFG、KV Cache 等推理代码 |
| VAE | 通过 vae_pretrained 配置加载 | Transformer VAE encoder/decoder |
| T5 Text Encoder | 通过 t5_pretrained 配置加载 | 文本条件编码 |
| MagiAttention | github.com/SandAI-org/MagiAttention (独立仓库) | 分布式注意力机制,Flex-Flash-Attention |
| ComfyUI 集成 | comfyui/ | ComfyUI 自定义节点 |
| Prompt Enhancement | Dify DSL (README 中提及) | 基于 MLLM 的 prompt 增强 |
| 模型权重 | HuggingFace sand-ai/MAGI-1 | 4.5B / 24B base + distill + fp8_quant |
注意: 仓库目前仅开源推理代码,训练代码未公开。模型架构的完整实现(DiT block, Block-Causal Attention, Shortcut Distillation 等)内嵌在模型权重中,推理代码封装了去噪循环和调度逻辑。