Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Authors: Boyuan Chen, Diego Marti Monso, Yilun Du, Max Simchowitz, Russ Tedrake, Vincent Sitzmann Affiliations: MIT CSAIL, Technical University of Munich arXiv: 2407.01392 Project Page: boyuan.space/diffusion-forcing GitHub: buoyancy99/diffusion-forcing Venue: NeurIPS 2024
1. Motivation (研究动机)
1.1 问题背景
序列生成模型目前主要分为两大范式:
-
Next-token Prediction (Teacher Forcing):如 GPT 系列,通过 autoregressive 方式逐 token 生成。优势在于可变长度生成、支持 tree search;但缺点是 (a) 无法在 sampling 阶段对未来序列施加 guidance,(b) 在连续信号(如 video)上 autoregressive rollout 时误差会逐帧累积导致发散。
-
Full-Sequence Diffusion:如 Diffuser、Video Diffusion Models,一次性对整个序列进行 diffusion。优势在于可以施加 classifier guidance 引导生成、对连续信号生成稳定;但缺点是 (a) 必须固定序列长度,无法灵活生成可变长度序列,(b) 使用 non-causal 架构,无法建模因果不确定性(远期比近期更不确定)。
1.2 核心矛盾
两种范式各有所长,简单组合(如用 causal architecture 做 full-sequence diffusion)效果很差——因为它无法建模”早期 token 的小不确定性需要在后期 token 中放大”这一关键特性。

Figure 1 解读:对比三种方法在五种能力上的表现。Teacher Forcing 不支持 Guidance 和 Tree Search;Full-Sequence Diffusion 不支持 Causal Uncertainty 和 Flexible Horizon;只有 Diffusion Forcing 同时支持所有五种能力:Guidance、Tree Search、Compositionality、Causal Uncertainty 和 Flexible Horizon。
2. Idea (核心思想)
2.1 核心洞察:Noise as Partial Masking
论文的关键洞察是:加噪可以视为一种 partial masking。
- 在时间轴上,teacher forcing 是沿时间轴做 masking(mask 未来 token)
- 在噪声轴上,full-sequence diffusion 是沿噪声轴做 masking(所有 token 统一加噪)
- Diffusion Forcing 同时在两个轴上操作:每个 token 有独立的 noise level,形成 partial masking
2.2 Diffusion Forcing 的定义
Diffusion Forcing (DF) 是一个训练和采样框架,处理带噪序列 ,其中每个 token 的 noise level 可以独立变化。
- 当 时,token 完全无噪(unmask)
- 当 时,token 完全是纯噪声(fully masked)
- 中间值代表不同程度的 partial masking
2.3 Causal Diffusion Forcing (CDF)
将 DF 用 causal architecture(RNN 或 masked transformer)实例化,称为 Causal Diffusion Forcing。RNN 维护 latent state 来捕获历史信息,动态模型和观测模型共同构成一个条件 diffusion model。

Figure 2 解读:方法总览图。左侧展示 “Noise as Masking” 概念——图像沿时间轴(横向)和噪声轴(纵向)构成一个 2D 网格。Diffusion Forcing 的 Training 阶段对序列中每帧加不同级别的噪声(用蓝色深浅表示),模型学习去噪;Sampling 阶段通过 scheduling matrix 控制去噪顺序。对比 Teacher Forcing(只沿时间轴 mask)和 Full-Sequence Diffusion(所有帧相同噪声级别),Diffusion Forcing 是二者的统一。
3. Method (方法)
3.1 Training:Diffusion Forcing Training
训练目标是标准的 diffusion loss,但每个 token 的 noise level 独立采样:
其中 从 均匀采样,。
理论保证 (Theorem 3.1):该训练过程优化了 Evidence Lower Bound (ELBO) 的一个 reweighting,且在适当条件下同时优化了所有 noise level 序列的似然下界——即所有可能子序列的联合分布。
# Algorithm 1: Diffusion Forcing Training (伪代码)
def diffusion_forcing_training(model, dataset, K):
"""
model: causal sequence model (RNN/masked transformer) with diffusion head
dataset: sequence dataset
K: total diffusion timesteps
"""
for x_1_to_T in dataset:
# 对每个 token 独立采样 noise level
for t in range(1, T+1):
k_t = random.randint(0, K) # 独立随机 noise level
x_t_noised = forward_diffuse(x_t, k_t) # 加噪
epsilon_t = (x_t_noised - sqrt(alpha_bar_k) * x_t) / sqrt(1 - alpha_bar_k)
# 通过 causal model 递推更新 latent
for t in range(1, T+1):
z_t = model.dynamics(z_{t-1}, x_t_noised, k_t) # RNN 更新 latent
epsilon_hat_t = model.predict_noise(z_{t-1}, x_t_noised, k_t) # 预测噪声
# MSE Loss
loss = MSE([epsilon_hat_1, ..., epsilon_hat_T], [epsilon_1, ..., epsilon_T])
loss.backward()
model.update()代码对应 (df_base.py → training_step + _generate_noise_levels):
# 核心:独立随机 noise levels
def _generate_noise_levels(self, xs, masks=None):
num_frames, batch_size = xs.shape[:2]
# "random_all": 每个 (frame, batch) 独立采样
noise_levels = torch.randint(0, self.timesteps, (num_frames, batch_size), device=xs.device)
return noise_levels
# training_step 中调用 diffusion_model.forward
def training_step(self, batch, batch_idx):
xs, conditions, masks = self._preprocess_batch(batch)
xs_pred, loss = self.diffusion_model(xs, conditions,
noise_levels=self._generate_noise_levels(xs))
loss = self.reweight_loss(loss, masks)
return {"loss": loss, ...}代码对应 (diffusion.py → forward):
def forward(self, x, external_cond, noise_levels):
noise = torch.randn_like(x)
noised_x = self.q_sample(x_start=x, t=noise_levels, noise=noise) # 每个 token 用自己的 k_t
model_pred = self.model_predictions(x=noised_x, t=noise_levels, external_cond=external_cond)
# 计算 loss (epsilon-prediction)
loss = F.mse_loss(pred, target.detach(), reduction="none")
loss_weight = self.compute_loss_weights(noise_levels) # min-SNR reweighting
loss = loss * loss_weight
return x_pred, loss3.2 Sampling:Scheduling Matrix
Sampling 通过一个 2D scheduling matrix 控制去噪过程:
- 列对应时间步 ,行对应去噪迭代
- 指定第 轮迭代时第 帧的 noise level
- 从第 0 行(全是 ,纯噪声)到最后一行(全是 0,干净数据),逐行去噪

Figure (Sampling Schemes) 解读:展示四种不同的 sampling scheme。(1) Stable Auto-Reg. Rollout:类似 autoregressive 但用小噪声稳定化;(2) Diffuse w/ Causal Uncertainty:zig-zag 方式,近期 token 先去噪,远期保持高噪声,建模因果不确定性;(3) Full Traj. Guidance:对整个轨迹施加 guidance;(4) Condition on Corrupted Obs.:可以处理带噪/缺失观测。
# Algorithm 2: DF Sampling with Guidance (伪代码)
def df_sampling(model, K_schedule, z_0, guidance_cost, T):
"""
K_schedule: M x T scheduling matrix
z_0: initial latent
guidance_cost: guidance function c(·)
"""
# 初始化为纯噪声
x_1_to_T = sample_gaussian_noise(T)
# 逐行去噪
for m in range(M-1, -1, -1): # row = M-1 down to 0
for t in range(1, T+1):
# 更新 latent
z_t_new = model.dynamics(z_t, x_t, K_schedule[m+1, t])
# Langevin sampling step
k = K_schedule[m, t]
x_t_new = langevin_step(x_t, z_t_new, k) # DDPM/DDIM step
z_t = z_t_new
# 施加 guidance(梯度传播到整个序列)
x_1_to_T = add_guidance(x_1_to_T, guidance_cost)
return x_1_to_T代码对应 (df_base.py → validation_step + _generate_scheduling_matrix):
# Pyramid scheduling matrix: 近期先去噪,远期后去噪 (zig-zag)
def _generate_pyramid_scheduling_matrix(self, horizon, uncertainty_scale):
height = self.sampling_timesteps + int((horizon - 1) * uncertainty_scale) + 1
scheduling_matrix = np.zeros((height, horizon), dtype=np.int64)
for m in range(height):
for t in range(horizon):
scheduling_matrix[m, t] = self.sampling_timesteps + int(t * uncertainty_scale) - m
return np.clip(scheduling_matrix, 0, self.sampling_timesteps)3.3 Stabilizing Autoregressive Generation
对于 video 等高维连续序列,Diffusion Forcing 通过给已生成的 context frames 添加小噪声 () 来稳定 rollout:
- 传统 autoregressive 方法将上一帧当作完美 ground truth,误差累积导致发散
- DF 将已有帧视为”稍有噪声”的观测,模型会在 Bayesian filtering 意义下进行修正
- 这使得生成可以稳定延伸到远超训练长度(如训练 36 帧,rollout 1000+ 帧)
3.4 Monte Carlo Guidance (MCG)
Diffusion Forcing 的 causal 特性使得一种新的 guidance 方式成为可能——Monte Carlo Guidance:
- 传统 full-sequence diffusion 的 guidance 只能基于单条轨迹计算梯度
- DF 可以在生成 token 时,采样多条未来轨迹 ,计算期望 reward 的梯度
- 类似 MPPI (Model Predictive Path Integral) 的思想,在 expected reward 上做 guidance
3.5 Sequential Decision Making
将 Diffusion Forcing 应用到 offline RL / planning:
- 定义 token (action + reward + observation)
- 训练时用 Algorithm 1,采样时用 Algorithm 2 + guidance
- 同时作为 policy(直接输出 action)和 planner(通过 guidance 规划长期轨迹)
代码对应 (df_planning.py → plan):
def plan(self, start, goal, horizon, conditions=None):
# 用 guidance 引导生成到达 goal 的轨迹
def goal_guidance(x):
pred = rearrange(x, "t b (fs c) -> (t fs) b c", fs=self.frame_stack)
target = torch.stack([start] * fs + [goal] * h_padded)
dist = F.mse_loss(pred, target, reduction="none")
# 对 observation 和 action 分别加权
return self.guidance_scale * episode_return
# 生成 scheduling matrix (pyramid 形式)
scheduling_matrix = self._generate_scheduling_matrix(plan_tokens)
# 初始化噪声 + 初始 token
plan = torch.cat([init_token, noise_chunk, pad], 0)
# 逐步去噪,每步都应用 guidance
for m in range(scheduling_matrix.shape[0] - 1):
plan[1:end] = self.diffusion_model.sample_step(
plan, conditions, from_levels, to_levels, guidance_fn=guidance_fn
)[1:end]
return plan_hist3.6 网络架构
- Video: Convolutional RNN + 3D UNet(时空注意力),对序列帧使用 causal temporal attention
- Planning: Causal Transformer,输入为 (observation, action, reward) bundle
- 两种架构共享相同的 Diffusion Forcing 训练/采样框架
代码对应 (diffusion.py → _build_model):
def _build_model(self):
if len(self.x_shape) == 3: # video (C, H, W)
self.model = EinopsWrapper(
from_shape="f b c h w", to_shape="b c f h w",
module=Unet3D(...) # 3D UNet with causal temporal attention
)
elif len(self.x_shape) == 1: # planning (dim,)
self.model = Transformer(...) # Causal Transformer4. Experimental Setup (实验设置)
4.1 Video Generation
- 数据集: Minecraft gameplay、DMLab navigation(均为 64x64)
- 训练长度: 36 帧
- 测试: rollout 到 1000+ 帧
- Baselines: Teacher Forcing (next-frame diffusion)、Causal Full-Sequence Diffusion
- Metrics: FVD、LPIPS、temporal consistency
4.2 Planning (D4RL Maze2D)
- 环境: Maze2D-UMaze/Medium/Large(单任务和多任务)
- 数据: 随机游走轨迹(非 expert)
- Baselines: MPPI、CQL、IQL、Diffuser
- 评估: average reward,比较有无 MCG、diffused action vs. PD controller
4.3 Compositional Generation
- 任务: 2D cross-shaped 轨迹数据
- 方法: 通过修改 sampling scheme(调整 memory horizon)实现 compositional 生成
- 无需重新训练即可组合子轨迹
4.4 Robotics (Franka Robot)
- 任务: 用第三个 slot 交换两个水果的位置
- 数据: 遥操作视频 + action
- Baseline: Diffusion Policy
- 评估: success rate, robustness to noisy/missing observations
4.5 Time Series Forecasting
- 数据集: 多变量时间序列预测标准 benchmark
- Baselines: 先前 diffusion 方法和 transformer-based 方法
5. Experimental Results (实验结果)
5.1 Video Generation

Figure 3 解读:DMLab 和 Minecraft 上的 video generation 结果。每种方法展示两条不同序列的 rollout。Diffusion Forcing(第一行)在 496、500、996、1000 帧时仍保持时间一致性,不会发散。对比 Causal Full-Sequence Diffusion(中间行)出现帧间跳变(frame-to-frame discontinuity),Teacher Forcing(最后行)在训练长度之外迅速发散。
关键发现:
- Diffusion Forcing 是唯一能稳定 rollout 到远超训练长度(1000 帧 vs 36 帧训练)的方法
- Teacher Forcing 和 Full-Sequence Diffusion 在约 500 帧后都严重发散
- Full-Sequence Diffusion 即使在训练长度内也存在帧间不连续问题
5.2 Planning

Figure (Maze) 解读:Maze2D-medium 和 Maze2D-large 上的 planning 可视化。上方行是 Diffusion Forcing,下方行是 Diffuser。随着 denoising steps 推进,DF 的规划轨迹逐渐清晰,红点表示轨迹概率密度。DF 保持了因果不确定性——近期确定、远期模糊,最终收敛到高质量路径。Diffuser 在所有时间步上均匀去噪,缺乏这种因果结构。
Table 1 定量结果:
| Environment | MPPI | CQL | IQL | Diffuser* | DF w/o MCG | DF (Ours) |
|---|---|---|---|---|---|---|
| Maze2D U-Maze | 33.2 | 5.7 | 47.4 | 113.9 | 110.1 | 116.7 |
| Maze2D Medium | 10.2 | 5.0 | 34.9 | 121.5 | 136.1 | 149.4 |
| Maze2D Large | 5.1 | 12.5 | 58.6 | 123.0 | 142.8 | 159.0 |
| Single-task Avg | 16.2 | 7.7 | 47.0 | 119.5 | 129.67 | 141.7 |
| Multi2D U-Maze | 41.2 | - | 24.8 | 128.9 | 107.7 | 119.1 |
| Multi2D Medium | 15.4 | - | 12.1 | 127.2 | 145.6 | 152.3 |
| Multi2D Large | 8.0 | - | 13.9 | 132.1 | 129.8 | 167.1 |
| Multi-task Avg | 21.5 | - | 16.9 | 129.4 | 127.7 | 146.2 |
关键发现:
- DF 在所有 6 个环境中都超越 Diffuser 和传统 offline RL 方法
- MCG(Monte Carlo Guidance)带来显著提升,尤其在 Large maze 上
- Diffuser 在直接执行 diffused action 时性能急剧下降(需依赖手工 PD controller),DF 的 raw action 是 self-consistent 的
5.3 因果性建模的优势
- Causal Uncertainty: DF 的 scheduling matrix 使近期 action 确定、远期不确定,更符合 decision-making 需求
- Flexible Horizon: DF 可以动态调整 planning horizon,full-sequence model 不行
- Self-consistent Actions: DF 生成的 action-state 对是因果一致的,Diffuser 不是
5.4 Robotics

Figure 4 解读:Franka robot 水果交换任务。(a)(b) 展示两种不同初始配置——由于水果位置随机,仅从当前观测无法判断下一步该移动哪个水果,必须依赖 memory。DF 通过 RNN latent 自然具有 memory,达到 80% 成功率;Diffusion Policy(无 memory)则失败。(c) 展示 DF 同时能从单帧输入生成逼真的 video。
Robustness 结果:
- DF 在观测加噪/遮挡(missing observation)下成功率仅下降 4%~24%(从 80% 到 76%~56%)
- 对比 next-frame diffusion baseline 在 perturbed observation 下成功率降至 48%
- DF 通过设置 表示 “noisy observation”,优雅地处理噪声输入
5.5 Compositional Generation

Figure (Compositionality) 解读:展示 compositional sequential generation 能力。通过调整 sampling scheme 中的 memory horizon,DF 可以在不重新训练的情况下组合子序列。当 memory 长时,生成完整的 cross 形轨迹;当 memory 短时(类似 MPC),模型组合子轨迹形成 V 形路径。
5.6 Time Series Forecasting
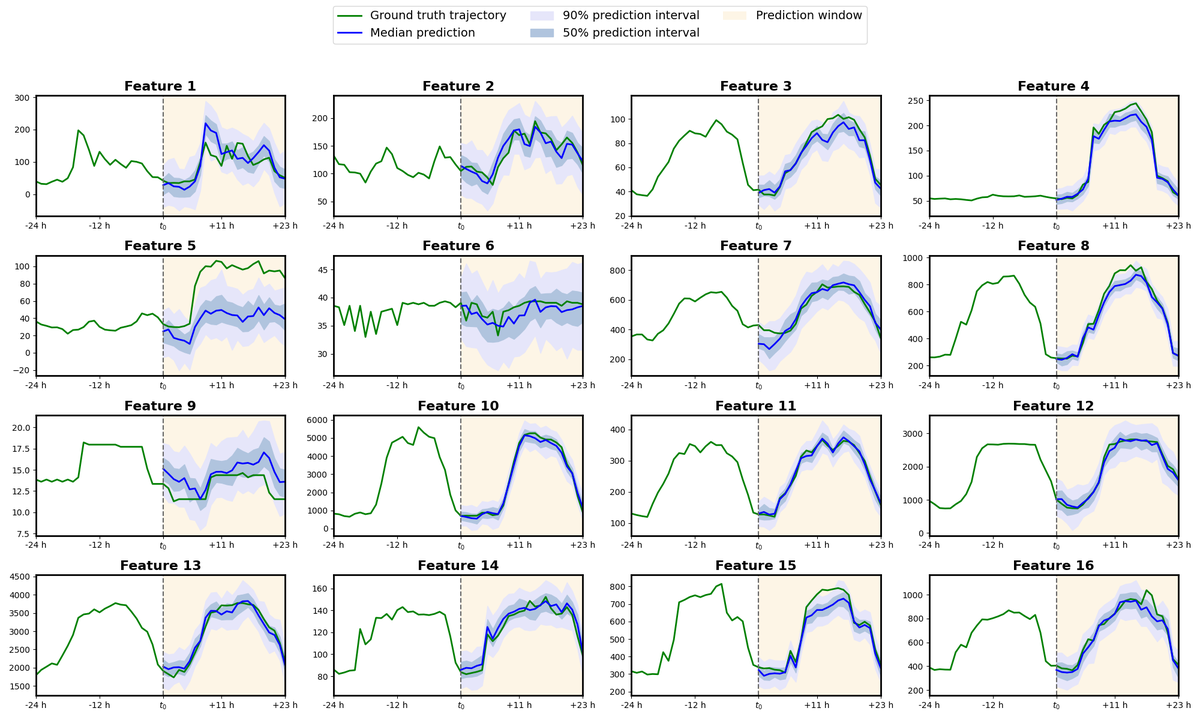
Figure (Time Series) 解读:Electricity 数据集上的时间序列预测结果。DF 与先前的 diffusion 方法和 transformer-based 方法表现具有竞争力,验证了其作为通用序列模型的能力。
总结
Diffusion Forcing 通过一个优雅的洞察——noise level 作为 partial masking 的程度——统一了 next-token prediction 和 full-sequence diffusion 两大范式。其核心创新在于训练时对每个 token 独立采样 noise level,使模型学会处理任意 noise level 组合的序列。这带来了五大能力:(1) 稳定的长 rollout,(2) 因果不确定性建模,(3) 灵活的 guidance,(4) 可变长度生成,(5) 组合式生成。在 video generation、planning、robotics 和 time series 四个领域均展示了显著优势。
Limitations: 当前实现基于 RNN,扩展到更大规模需要 transformer 架构(论文在 Appendix 中讨论了 transformer 实现的可能性)。未研究在 internet-scale 数据上的 scaling behavior。