WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Paper: arXiv:2603.16871 / HF Papers Code: cvlab-kaist/WorldCam Code reference:
main@8e31bf7d(2026-05-01)
1. Motivation (研究动机)
现有 interactive gaming world model 已经能把起始画面和用户动作滚动生成成长视频,但其控制信号通常仍是“抽象动作”:直接注入 WASD / mouse token、用文本描述动作,或用线性位移近似相机运动。这会导致两个问题耦合爆炸:短期看动作对不准,长期看再次回到同一位置时 3D 几何漂移。
WorldCam 的问题定义是:给定初始观测 、文本提示 和动作序列 ,自回归生成帧 ,同时满足:动作可控、世界几何一致、长时视觉质量稳定。核心动机是把“动作控制”和“3D consistency”统一到同一个几何中间变量:camera pose。

Figure 1 解读:teaser 展示了三类能力:复杂键鼠输入下的精确动作控制、超过 10 秒的 20 FPS 长时交互,以及 revisiting view 中红框区域的 3D 一致性。它不是只追求更长视频,而是要求动作造成的相机轨迹能在生成模型内部成为可复用的空间索引。
2. Idea (核心思想)
核心 insight:在游戏环境中,键盘和鼠标动作不是任意条件 token,而是诱导相机在 3D 世界中的相对运动;这些相对运动累积成 global camera pose。WorldCam 因此把 camera pose 作为统一几何表示:短期用于精确控制视角,长期用于检索历史 latent 以约束 revisited locations。
与 Yume / Matrix-Game / GameCraft 等直接 action-conditioned world model 不同,WorldCam 先将用户动作映射到 相机位姿,再把位姿转换为 Plücker embedding 注入 DiT;与 CameraCtrl / MotionCtrl 等 camera-controlled video generation 不同,它面向交互式长时 roll-out,并通过 pose-anchored memory + progressive autoregressive inference 稳定 200-frame 级别生成。
方法可概括为三个层次:
- Action → Camera Pose:在 Lie algebra 中表示 6-DoF twist,避免线性平移/旋转解耦近似。
- Camera Pose → DiT Conditioning:将 camera pose 转成 Plücker embedding,通过轻量 MLP 在每个 DiT block 的 self-attention 后注入。
- Global Pose → Memory Retrieval:用 global camera pose 检索历史 latent,使生成模型在回到相近位置/视角时能看到几何相关的过去观测。
3. Method (方法)
3.1 总体框架

Figure 2 解读:架构从用户动作出发,经 Lie algebra 映射得到相机 pose;DiT 主干使用 camera embedder 获得精确 action alignment;长时生成时,global pose 作为 spatial index 从 memory pool 检索历史 latent 和对应 pose,并与 short-term memory、attention sink 一起作为 progressive autoregressive denoising 的上下文。
WorldCam 基于 Wan2.1-1.3B-T2V 视频 DiT。VAE 将视频 编码为 latent ,DiT 学习 flow matching velocity field:
3.2 Action-to-Camera Mapping
用户动作在每个相邻帧 被表示为 twist:
相对相机位姿通过矩阵指数映射到 :
其中 是 twist 的 矩阵。相比线性地独立更新平移/旋转,这个形式在 manifold 上联合积分线速度和角速度,能处理键鼠输入同时发生时的耦合相机运动。
代码状态:public repo 当前没有实现 raw action → Lie algebra pose 的训练/预处理代码;repo 推理入口使用预先生成的
*_poses_palindrome.npy和*_intrinsics_palindrome.npy。因此本小节公式来自论文,代码映射中标注为 paper-only gap。
3.3 Camera-Controlled Video Generation
相对 pose 序列 先在窗口内累积为 global camera pose,再转换为每帧 6 维 Plücker embedding 。由于 VAE 在时间上压缩 倍,模型把连续 个 Plücker embedding 拼接为 latent-frame 条件:
camera embedder 是两层 MLP,注入到 DiT feature :
代码对应:diffsynth/models/wan_video_dit.py 中 convert_to_plucker() 根据 extrinsics / intrinsics 构建每像素 ray direction 和 moment vector,PluckerEmbeddingChannelStack 将时间上每 4 帧的 Plücker 特征 stack 后投影,DiTBlock.forward() 在 self-attention 后把 plucker_features 加到当前 token 序列尾部的相机条件 tokens 上。
# Source-aligned pseudocode: diffsynth/models/wan_video_dit.py
class PluckerEmbeddingChannelStack(nn.Module):
def __init__(self, output_dim, t_ratio=4):
self.mlp = nn.Sequential(
nn.Linear(6 * t_ratio, output_dim * 2),
nn.GELU(),
nn.Linear(output_dim * 2, output_dim),
)
def forward(self, plucker): # [B, F, H, W, 6]
B, F, H, W, P = plucker.shape
plucker = rearrange(plucker, "b (f g) h w p -> b f h w (g p)", g=self.t_ratio)
plucker = rearrange(plucker, "b f h w c -> b (f h w) c")
return self.mlp(plucker)
def convert_to_plucker(extrinsics, intrinsics, height, width):
camera_position = extrinsics[:, :, :3, 3]
fx, fy, cx, cy = scale_intrinsics(intrinsics, height, width)
direction_camera = normalize([(x - cx) / fx, (y - cy) / fy, 1])
direction_world = normalize(extrinsics[:, :, :3, :3] @ direction_camera)
moment = torch.cross(camera_position, direction_world, dim=-1)
return torch.cat([direction_world, moment], dim=-1) # [B, F, H, W, 6]3.4 Pose-Anchored Long-Term Memory
WorldCam 将每个历史 latent 与 global pose 绑定。global pose 由相对 pose 累积:
并写成:
检索分两级:先按相机位置选 Top-,再按朝向选 Top-:
检索出的 latents 被拼到当前 latent 序列末尾,对应 pose 会 realign 到当前 denoising window 的第一帧,再通过同一个 camera embedder 注入 DiT。直觉是:模型不需要把所有过往帧都作为连续上下文,而是通过 pose 找到“空间上该看的历史证据”。
# Source-aligned pseudocode: diffsynth/pipelines/wan_video_new.py
def retrieve_combined_history_indices(reference_poses, memory_pool_poses,
num_total_to_retrieve=4, frames_per_clip=4):
ref_poses = reference_poses.cpu().numpy()
pool_poses = memory_pool_poses.cpu().numpy().squeeze()
pool_trans = pool_poses[:, :3, 3]
candidate_clips, distances = [], []
for ref_pose in ref_poses:
ref_trans = ref_pose[:3, 3]
ref_rot = ref_pose[:3, :3]
dist_t = np.linalg.norm(pool_trans - ref_trans, axis=1)
for idx in np.argsort(dist_t):
dist_r = calculate_rotation_distance(ref_rot, pool_poses[idx][:3, :3])
candidate_clips.append(idx // frames_per_clip)
distances.append(dist_r) # public code currently sorts by rotation only after translation scan
sorted_clips = np.array(candidate_clips)[np.argsort(distances)]
final_unique = []
for clip in sorted_clips:
if clip not in final_unique:
final_unique.append(clip)
if len(final_unique) >= num_total_to_retrieve:
break
return np.array(final_unique)代码与论文的一个细节差异:论文公式写的是先 position Top- 再 orientation Top-;public code 中 num_cands = len(pool_poses),并且最终 all_distances.append(dist_r),等价于遍历所有候选后主要按旋转距离排序、再做 unique clip 去重。这不否定论文机制,但说明当前 release 的 retrieval 实现与公式的 Top- translation gate 不完全一致。
3.5 Progressive Autoregressive Inference
WorldCam 对 denoising window 内不同 latent frame 赋予单调递增噪声级别:早期 frame 低噪声,作为稳定 anchor;未来 frame 高噪声,保持可修正。若扩散过程有 个 inference steps,并划分为 个 stages,则每个 latent frame 要跨过所有 个 stage 才完全 denoise。完成后,最早 latent 被 VAE decode 并移出窗口,末尾 append 一个新 pure-noise latent。
此外:
- attention sink:保留初始帧 token 作为全局 attention anchor,减少长时 roll-out 中 UI / 风格漂移。
- short-term memory:把最近生成的 latents 作为局部上下文;论文实验中 short-term memory latent 数量设为与 generated latents 相同。
- long-term memory:推理代码默认
LONG_TERM_MEMORY_START=30后启用,检索LONG_TERM_MEMORY_NUM_CLIPS=4个历史 clips。
# Source-aligned pseudocode: inference.py + diffsynth/pipelines/wan_video_new.py
def autoregressive_worldcam(pipe, cond_video, intrinsics, extrinsics):
latents = initialize_progressive_latents(cond_video, noise, num_ar_steps=50)
latents_cond = clean_condition_latents()
memory_pool = init_memory_pool(cond_latents=latents_cond,
poses=extrinsics[:, :condition_num * 4],
intrinsics=intrinsics[:, :condition_num * 4])
for ar_step in range(NUM_AR_STEPS):
window_intrinsics = slice_intrinsics(intrinsics, ar_step)
window_extrinsics = slice_extrinsics(extrinsics, ar_step)
if ar_step >= LONG_TERM_MEMORY_START:
ref_poses = window_extrinsics[:, [48, 52, 56, 60]]
clip_ids = retrieve_combined_history_indices(ref_poses, memory_pool.poses, num_total_to_retrieve=4)
hist_latents, hist_intrinsics, hist_poses = memory_pool.gather(clip_ids)
latents = torch.cat([latents, hist_latents], dim=2)
window_intrinsics = torch.cat([window_intrinsics, hist_intrinsics], dim=1)
window_extrinsics = realign_and_cat(window_extrinsics, hist_poses)
for stage in range(S):
timestep = all_timesteps[stage]
noise_pred = cfg_dit_forward(latents, prompt, window_intrinsics, window_extrinsics, timestep)
latents = latents + dt_packed[stage] * noise_pred
latents[:, :, :condition_num] = latents_cond
if ar_step >= LONG_TERM_MEMORY_START:
latents[:, :, -len(hist_latents):] = hist_latents
new_latent = latents[:, :, condition_num:condition_num + 1]
latents_cond = roll_append(latents_cond, new_latent)
maybe_update_memory_pool(memory_pool, new_latent, window_extrinsics, window_intrinsics)
latents = shift_window_and_append_noise(latents, new_noise=ar_noise[:, :, ar_step:ar_step + 1])
return vae_decode(torch.cat(ar_frames, dim=2))3.6 WorldCam-50h 数据集
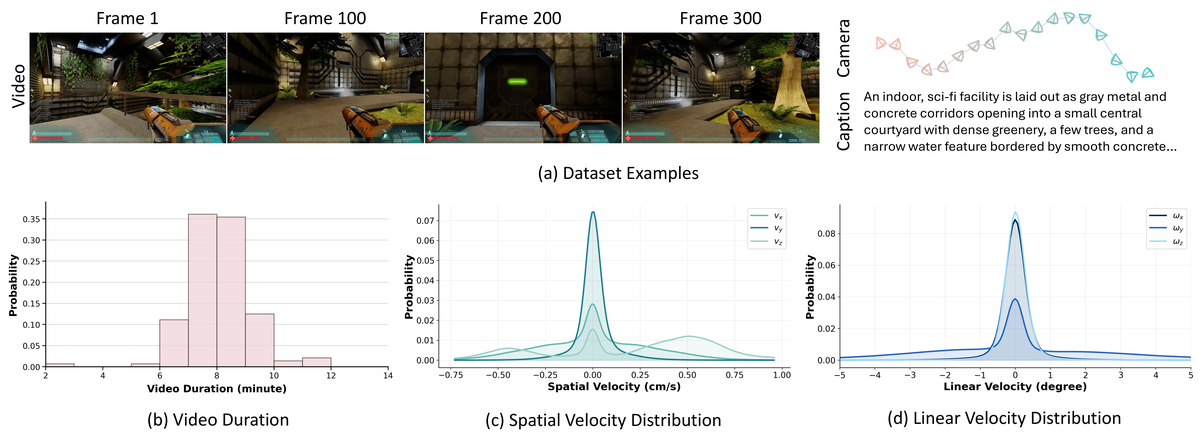
Figure 3 解读:WorldCam-50h 包含 3,000 分钟(50 小时)真实 human gameplay,标注 camera trajectories 和文本描述。图中展示样例帧、caption、视频长度分布、线速度分布和角速度分布,说明该数据集不是静态视频集合,而是为 action → camera → world generation 准备的轨迹数据。
论文训练使用 caption 保持画质和场景风格;caption 由 Qwen2.5-VL-7B 生成,prompt 要求描述静态世界的 global layout、visual theme、ambient conditions。GitHub release 中公开了 Xonotic 和 Unvanquished 的 gameplay recordings 与 raw actions,但 README 明确说明 camera poses 与 captions 不包含在公开数据包中,需要用 ViPE / DA3 和 Qwen2.5-VL-7B 自行抽取。
4. Experimental Setup (实验设置)
4.1 模型与训练配置
- Backbone:Wan2.1-1.3B-T2V video DiT。
- 分辨率:。
- 训练资源:8 张 NVIDIA H100。
- 训练 latent 设置:8 progressive latents、8 short-term memory latents、4 long-term memory latents。
- 三阶段训练:
- camera-controlled video generation + short-term memory,10k iterations,batch size 64;
- progressive autoregressive training + short-term memory,10k iterations,batch size 48;
- progressive autoregressive training + short-term and long-term memory,10k iterations,batch size 16,用于强化 3D consistency。
- Progressive AR:、,每个 latent 每阶段 denoise 8 个 sampling steps,总计 64 timesteps。
- Optimizer:AdamW,学习率 。
4.2 Baselines
Interactive gaming world models:Yume、Matrix-Game 2.0、GameCraft。Camera-controlled video generation baselines:CameraCtrl、MotionCtrl。论文还与现有 interactive / camera-controlled 模型做功能表对比,关注 action control、3D consistency、long-horizon inference 是否同时满足。
4.3 Evaluation protocol
- Action controllability:从 test split 随机采样 70 条 action trajectories 和 70 个 starting images;interactive world model 生成 200 frames;camera-controlled baselines 因不支持长时 roll-out,仅评估 16 frames。
- Visual quality / 3D consistency:随机选 50 个 starting images,每个设 4 条 closed-loop trajectories,共 200 个 evaluation cases;interactive models 生成 200 frames。
- 指标:RPE、RPE、RPE 衡量相机控制误差;VBench 子指标衡量视觉质量;PSNR / LPIPS / MEt3R / DINO Sim. / Sharpness 衡量 closed-loop revisiting 的长时 3D consistency 与清晰度。
4.4 代码与论文映射
Code reference:
main@8e31bf7d(2026-05-01)
| Paper Concept | Source File | Key Class/Function | 备注 |
|---|---|---|---|
| Wan2.1 DiT baseline + FM denoising backbone | diffsynth/models/wan_video_dit.py | WanModel.forward, DiTBlock.forward | repo 继承 DiffSynth/Wan DiT 推理框架;训练 loss 不在 release 中。 |
| Camera pose → Plücker embedding | diffsynth/models/wan_video_dit.py | WanModel.convert_to_plucker, PluckerEmbeddingChannelStack.forward | 从 intrinsics/extrinsics 生成 ray direction + moment vector,并按 4-frame temporal stack 投影。 |
| DiT 中注入 camera feature | diffsynth/models/wan_video_dit.py | DiTBlock.forward | self-attention 后执行 x[:, -plucker_dim:, :] += plucker_features。 |
| Pose-anchored memory retrieval | diffsynth/pipelines/wan_video_new.py | retrieve_combined_history_indices, WanVideoPipeline.__call__ | public code 先扫描 translation distance 后主要按 rotation distance 排序,选 unique clip ids。 |
| Progressive AR inference | diffsynth/pipelines/wan_video_new.py | WanVideoPipeline.__call__ | 构造 all_timesteps、逐 AR step 更新 latents、roll latents_cond 并 append noise。 |
| Inference config | inference.py | constants + main() | CFG_SCALE=4, NUM_AR_STEPS=50, LONG_TERM_MEMORY_START=30, LONG_TERM_MEMORY_NUM_CLIPS=4。 |
| Raw action visualization | overlay_actions.py | parse_log, overlay_video | 仅用于将 keyboard/mouse log 叠加到视频;不是论文的 Lie algebra action-to-camera training code。 |
| Public release / weights / dataset instructions | README.md | Download Pretrained Weights, Download Dataset | 说明 worldcam/worldcam 权重、worldcam/worldcam-dataset 数据下载,以及公开数据不含 camera poses/captions。 |
| Action-to-camera Lie algebra mapping | not released | not released | public repo 未找到 se(3) / Lie algebra / raw action-to-pose 实现;笔记按论文公式记录。 |
| Training pipeline / caption generation / pose extraction | not released | not released | README 说明公开数据不含 camera poses 和 captions;需外部 ViPE/DA3/Qwen2.5-VL-7B。 |
5. Experimental Results (实验结果)
5.1 主结果:动作控制与视觉质量

Figure 4 解读:主定性图比较 WorldCam 与 Yume、Matrix-Game 2.0、GameCraft。在相同 action trajectory 下,WorldCam 更能遵循视角运动,并且长时 roll-out 后场景结构不易碎裂;这对应了定量表中 RPE 和 VBench Avg 的同步提升。
200-frame interactive world model 对比:
| Method | RPE ↓ | RPE ↓ | RPE ↓ | VBench Avg ↑ | Aesth. ↑ | Subj. Cons. ↑ | Bg. Cons. ↑ | Img. ↑ | Temp. ↑ | Motion ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Yume | 0.111 | 2.222 | 0.137 | 0.774 | 0.476 | 0.741 | 0.892 | 0.600 | 0.955 | 0.986 |
| Matrix-Game 2.0 | 0.098 | 1.656 | 0.119 | 0.766 | 0.457 | 0.741 | 0.843 | 0.633 | 0.937 | 0.981 |
| GameCraft | 0.086 | 1.146 | 0.100 | 0.781 | 0.464 | 0.804 | 0.850 | 0.626 | 0.958 | 0.986 |
| WorldCam | 0.080 | 0.696 | 0.086 | 0.844 | 0.508 | 0.896 | 0.959 | 0.752 | 0.964 | 0.984 |
WorldCam 在相机控制误差和视觉质量综合分上同时最优;Motion 分略低于 Yume/GameCraft 的 0.986,但差距很小,主要收益来自 RPE、subject/background consistency 和 image quality。
5.2 16-frame camera-controlled baseline 对比
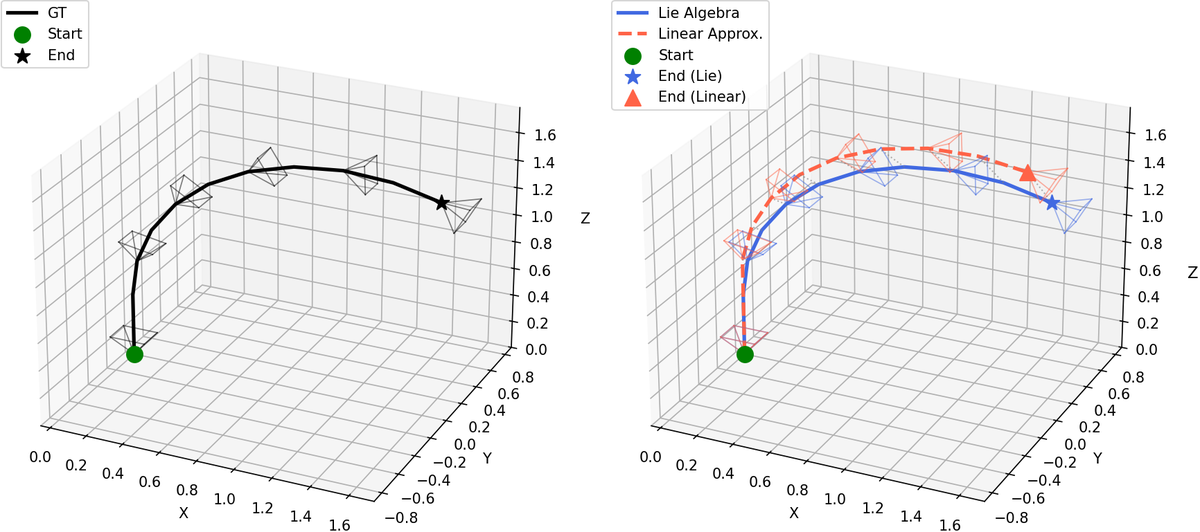
Figure 5 解读:短窗口相机控制对比说明,即便 CameraCtrl/MotionCtrl 获得 ground-truth camera trajectories,它们仍主要是短视频 camera control 模型;WorldCam 的 pose conditioning 与 gaming-domain DiT 结合后,在 16-frame 指标上也明显更准。
| Method | RPE ↓ | RPE ↓ | RPE ↓ |
|---|---|---|---|
| CameraCtrl | 0.071 | 0.943 | 0.083 |
| MotionCtrl | 0.080 | 1.271 | 0.102 |
| WorldCam | 0.026 | 0.386 | 0.030 |
5.3 长时 3D consistency
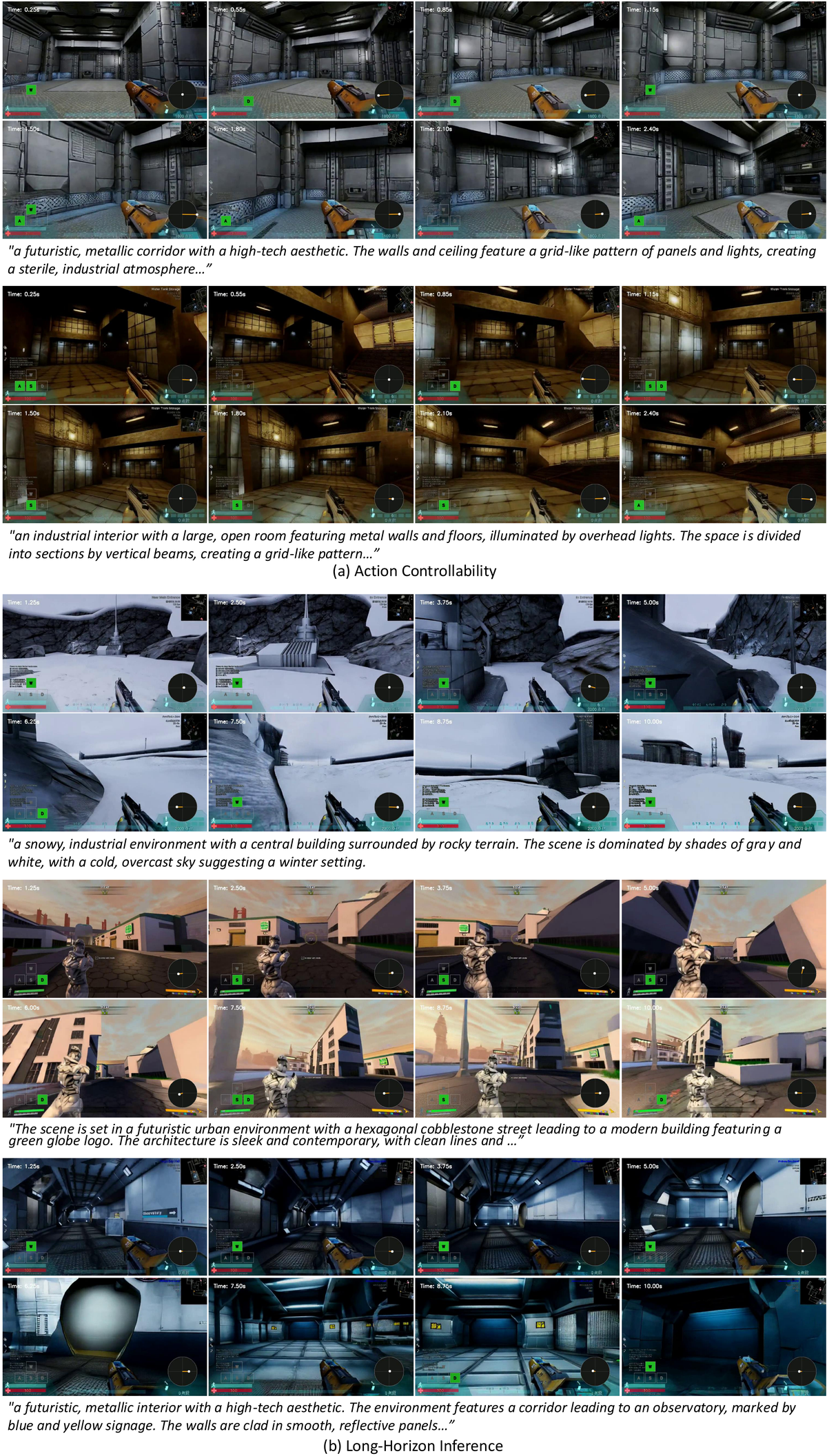
Figure 6 解读:补充定性图展示了长时 roll-out 的新场景生成与 revisited view 一致性。对 WorldCam 来说,long-term memory 不只是“更多上下文帧”,而是由 pose 检索到的空间相关历史 latent,因此在 closed-loop trajectory 中能更好维持同一 3D 世界。
| Method | PSNR ↑ | LPIPS ↓ | MEt3R ↓ | DINO Sim. ↑ | Sharpness ↑ |
|---|---|---|---|---|---|
| Real Videos | - | - | - | - | 577 |
| Yume | 16.03 | 0.5629 | 0.0905 | 0.4545 | 95 |
| Matrix-Game 2.0 | 13.66 | 0.4997 | 0.0662 | 0.6153 | 179 |
| GameCraft | 14.27 | 0.5749 | 0.0489 | 0.5960 | 201 |
| WorldCam | 16.69 | 0.3277 | 0.0342 | 0.8884 | 656 |
WorldCam 的 DINO similarity 和 sharpness 尤其突出,说明它在 revisited views 上不仅更相似,而且没有靠模糊化来掩盖不一致。
5.4 用户研究
| Method | Action ↑ | Visual ↑ | 3D ↑ |
|---|---|---|---|
| Yume | 2.47 | 2.83 | 1.44 |
| Matrix-Game 2.0 | 3.78 | 3.42 | 2.75 |
| GameCraft | 2.55 | 3.34 | 3.36 |
| WorldCam | 4.31 | 4.44 | 4.36 |
用户评分与自动指标一致:WorldCam 的优势不是单一视觉质量,而是 action、visual、3D 三项都明显领先。
5.5 Ablation
| Ablation | 关键数字 | 结论 |
|---|---|---|
| Linear vs Lie action-to-camera | WorldCam Linear: 0.093 / 0.962 / 0.102;WorldCam Lie: 0.080 / 0.696 / 0.086 | Lie algebra 映射显著降低旋转误差和总 camera error。 |
| Memory retrieval strategy | Random: 15.76 / 0.3645 / 0.041;Temporal: 15.18 / 0.3867 / 0.040;Ours: 16.42 / 0.3496 / 0.038 | pose-indexed retrieval 比随机或时间邻近检索更适合 closed-loop 3D consistency。 |
| Long-term memory latents | 0 个:Avg 0.840, PSNR 12.163;4 个:Avg 0.841, PSNR 12.950 | long-term memory 对几何一致性更关键,对视觉质量 Avg 影响较小。 |
| Short-term memory latents | 1 个 Avg 0.749;4 个 0.836;8 个 0.840 | 最近 latent 上下文对减少 error drift 很重要。 |
| Attention sink | w/o: Avg 0.840;with: 0.841,Temp 0.964 vs 0.961 | attention sink 主要稳定长时风格/UI/时间一致性,收益小但方向一致。 |
5.6 局限与复现风险
- public repo 是 inference/dataset release,不含完整训练代码、Lie algebra action-to-camera mapper、caption generation pipeline 或 pose extraction pipeline;因此代码级 pseudocode 只能覆盖 Plücker conditioning、memory retrieval 和推理 roll-out。
- GitHub README 中公开数据包含 raw gameplay video 与 raw actions,但不包含论文训练用 camera poses / captions;复现 WorldCam-50h 的完整监督信号需要额外运行 ViPE/DA3 与 Qwen2.5-VL-7B。
- public code 的 memory retrieval 实现与论文公式有轻微差异:代码最终主要按 rotation distance 排序,没有保留严格的 translation Top- gate。
- 论文主模型基于 8×H100 训练;repo README 的 quick start 是单 H100 推理环境,不等价于训练复现。