OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Paper: arXiv:2604.04707 Code: OpenDCAI/OpenWorldLib Code reference:
main@61c6baa2(2026-05-08)
1. Motivation (研究动机)
当前 World Model 研究的核心问题不是缺少单个生成模型,而是缺少可复用的定义和工程边界。论文指出,很多工作把 next-frame prediction、text-to-video、3D reconstruction、simulator、VLA、web/code agent 等都混称为 World Model,但这些任务是否真正具备“感知真实世界、根据交互进行预测、维护长期记忆”的能力并不清晰。结果是:不同论文评估对象不一致、方法接口碎片化、模型难以协同调用,也很难在同一工程框架中比较 interactive video generation、3D generation、multimodal reasoning 与 VLA。
这篇论文要解决的具体目标是两层:第一,给出一个更窄且可操作的 Advanced World Model 定义;第二,把这个定义落到 OpenWorldLib 代码库中,用统一的 Operator、Reasoning、Synthesis、Representation、Memory 与 Pipeline 接口组织多类世界模型任务。作者给出的定义是:World Model 是一个以 perception 为中心、具备 interaction 与 long-term memory 能力、用于理解并预测复杂世界的模型或框架。
这个问题值得研究,是因为真正可用的 World Model 需要跨任务闭环:输入可能是图像、视频、音频、机器人状态或动作指令;输出可能是视频、3D 表示、自然语言推理或可执行动作。如果没有统一接口,研究者只能把每个模型作为孤立 demo 使用;有了统一框架后,才能复用 perception/memory/evaluation 组件,让不同模型在同一 pipeline 中协同推理、生成和评估。

Figure 1 解读:图中把 OpenWorldLib 画成围绕真实世界交互的闭环系统:左侧是来自物理世界的视觉、音频、文本等 perception signal,中间通过 Operator 进入框架,Thinking 对应 reasoning / representation 等理解能力,Synthesis 输出可观察结果,Memory 维持跨轮次状态。它强调论文的主张:World Model 不只是生成视频,而是把感知、交互、记忆和输出组织为统一工作流。
2. Idea (核心思想)
核心 insight:World Model 应该按能力闭环来定义,而不是按单一任务名或模型架构来定义。OpenWorldLib 把“是否以 perception 为中心、是否接收 interaction signal、是否有 long-term memory、是否能理解并预测复杂世界”作为判断标准,从而把 interactive video、3D / simulator、multimodal reasoning、VLA 纳入同一接口族,同时把纯 text-to-video、code generation、web search 等任务排除在核心定义之外。
关键创新不是提出新的训练 loss,而是提出一个标准化 inference framework:Operator 负责输入和交互信号标准化,Reasoning 负责多模态理解,Synthesis 负责隐式生成,Representation 负责显式 3D / simulator 表示,Memory 负责跨轮次历史,Pipeline 负责把这些模块组合成端到端调用。相较于只讨论定义的 position/survey 论文,OpenWorldLib 的差别是把定义落到公开代码库;相较于 Matrix-Game、Hunyuan-GameCraft、VGGT、 等单模型项目,它提供跨模型的统一调用和评估入口。
与常见 text-to-video 方法的根本区别在于:text-to-video 主要从文本 prompt 生成视觉内容,不要求对真实感知输入进行持续交互,也不要求在跨轮次任务中保存状态;OpenWorldLib 定义下的 World Model 必须把 perception、action-conditioned simulation 和 memory 合在一起,才能支持长期互动和复杂世界预测。
这也解释了论文的任务划分:interactive video generation 是最接近经典 的分支,因为它直接检验动作条件下的未来视觉状态;multimodal reasoning 检验模型能否把视觉、音频、时间、空间和因果关系变成可解释判断;VLA 检验语言目标、视觉状态和连续动作之间的闭环;3D / simulator 则提供显式空间状态,让模型预测可以被渲染、重投影或物理环境验证。相反,纯文本或娱乐向生成即使有长序列结构,也不一定触及复杂物理世界。
工程上的核心取舍是“统一接口而非统一模型”。OpenWorldLib 不尝试把所有后端重写成一个 monolithic model,而是通过 from_pretrained()、process()、predict()/inference()/get_representation()、stream() 等接口约定,让异构模型能进入同一个运行时。这个思路降低了集成成本,但也意味着框架质量高度依赖每个模型 adapter 是否忠实处理输入、动作模板、memory 状态与输出格式。
3. Method (方法)
3.1 Overall framework:从交互输入到统一 Pipeline
OpenWorldLib 的总流程可以写成:环境或用户提供 raw interaction signal 与 perception input;Operator 检查动作合法性并把图像、视频、音频、机器人状态等转成模型输入;Pipeline 根据任务调用 Reasoning、Synthesis 或 Representation;Memory 保存历史 observation、reasoning chain、action trajectory 与生成结果;最终输出视频、图像、音频、3D 表示、语言答案或动作序列。
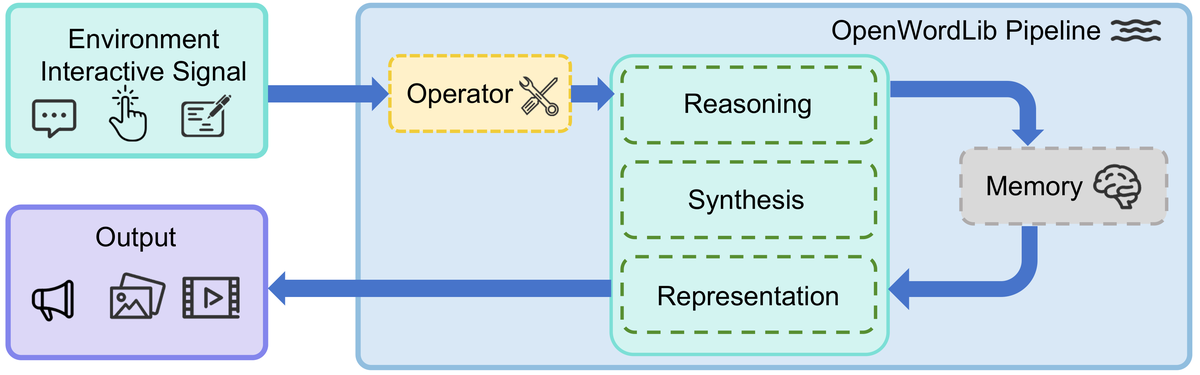
Figure 2 解读:左侧 Environment Interactive Signal 被送入 Operator;Operator 是所有任务的入口适配层。中间绿色模块表示可被 Pipeline 动态调度的三类核心能力:Reasoning、Synthesis、Representation。右侧 Memory 与核心模块之间有双向箭头,表示多轮任务中历史状态会被读取并更新。最左下角 Output 说明框架输出不限定为文本,也包括图像、视频、音频等多模态结果。
这个框架的直觉是“把 World Model 从模型 zoo 改造成 operating system”。单个世界模型方法通常只解决一个任务:例如 navigation video generation 只关心从参考图像和动作序列生成视频,VGGT 只关心从图像估计相机与点云,VLA 只关心从视觉和语言目标预测动作。OpenWorldLib 的做法是把这些任务共同的 I/O 生命周期抽出来:先把外部世界信号标准化,再让不同后端在统一接口下工作,最后把结果和上下文写回 Memory。这样做并不会让所有模型共享同一个神经网络,但能让它们共享调用约定、评估脚本和多轮交互状态。
3.2 World Model 的形式化边界
论文回到经典 World Model 的三个条件分布:
其中 是包含历史信息的 latent state, 是动作或任务相关输出, 是视觉、音频、proprioception 等 perception, 是与环境交互后的反馈。作者认为仅满足这种形式还不够;真正的 World Model 还要面向复杂物理世界,有感知输入、交互动作和长期记忆。因此,纯 text-to-video 生成、code generation、web search、偏娱乐的 avatar video generation 都可能有序列预测结构,但不属于本文重点定义下的 World Model。
3.3 隐式表示与显式表示

Figure 3 解读:左侧 Figure 3a 是 implicit representation:交互信号进入模型后,模型内部直接生成图像或音频等输出,典型例子是 video/audio generation。右侧 Figure 3b 是 explicit representation:模型先生成 3D structure 或 simulator state,再由 renderer 产生输出。论文把这一区分用于解释为什么 Synthesis 与 Representation 要分成两个模块:前者生成可观察媒体,后者生成可被仿真、验证和渲染的显式环境。
隐式路线适合快速得到可观察结果,例如根据 camera control 生成未来视频帧;显式路线适合需要物理一致性或可验证空间状态的场景,例如点云、depth map、camera pose、3D Gaussian / mesh / simulator。二者在框架中互补:Synthesis 让世界模型“想象未来”,Representation 让世界模型“构造一个可检查的世界”。
3.4 Key components
Operator:负责把 raw input 转成下游模型可接受的结构。论文模板要求 check_interaction()、process_interaction()、process_perception();released code 中 src/openworldlib/operators/base_operator.py 是抽象壳,具体逻辑落在各模型 operator。例如 HunyuanGameCraftOperator 会验证动作是否在 forward/left/right/backward/camera_l/camera_r/camera_up/camera_down 模板内,把这些动作映射到 w/a/d/s/left_rot/right_rot/up_rot/down_rot,并把输入图像经 crop/resize/normalize/VAE encode 变成 latent context。
Synthesis:负责隐式生成,包含 visual synthesis、audio synthesis 和 action/VLA signal synthesis。visual 分支覆盖 Matrix-Game、Hunyuan-GameCraft、Lingbot-World、YUME、Wan、Cosmos 等;audio 分支覆盖 MMAudio、ThinkSound 等;VLA synthesis 覆盖 、Spirit、LingBot-VA、GigaBrain 等动作生成模型。
Reasoning:负责把 perception 与 instruction 转成可解释的语义结论、空间判断或跨模态回答。released code 中 Qwen2p5OmniReasoning 使用 processor 的 chat template 组织 image/audio/video/text,再调用 model.generate(),输出文本或 text+audio。
Representation:负责显式世界表示,如 camera pose、depth map、point map、tracks、3DGS rendering 或 simulator state。released code 中 VGGTRepresentation.get_representation() 会对图像预处理后调用 VGGT aggregator,并按 flags 预测 camera、depth、point、track,再在具备 depth/camera/points 时 unproject 出 point_map_from_depth。
Memory:负责跨轮次历史。论文强调 record/select/compress/manage;released code 的 BaseMemory 还额外加入 process(refined_data, target_format="kv_cache"),说明 Memory 不只是存储,还需要把筛选后的记忆转成模型输入格式。
Pipeline:顶层调度器。每个具体 pipeline 都实现自己的 from_pretrained()、process()、__call__() 与可选 stream()。例如 HunyuanGameCraft 的 __call__() 先 process() 得到 visual_context 与 operator_condition,再把 ref_latents/action_list/prompt/num_frames/cfg_scale/infer_steps 传给 synthesis_model.predict()。
论文公式与 released code 实现差异:本文没有提出训练 loss;代码主要是 inference/evaluation 框架。论文 Listing 中的抽象模板与 released code 也不是逐字一致:BaseOperator 论文版直接实现 interaction 检查与 append,而 src/openworldlib/operators/base_operator.py 中相应函数是 pass,具体实现转移到模型级 operator;论文称 BasePipeline,released code 中抽象类名为 PipelineABC;论文版 BaseMemory 没写 process(),released code 添加了 process(refined_data, target_format="kv_cache")。因此,本笔记的伪代码按 released code main@61c6baa2,而不是按论文 Listing 逐字复写。
3.5 Released code 伪代码
Operator 的 released code 行为可以概括为:
class HunyuanGameCraftOperator(BaseOperator):
def get_interaction(self, interaction):
if not isinstance(interaction, list):
interaction = [interaction]
for act in interaction:
self.check_interaction(act)
self.current_interaction.append(interaction)
def process_perception(self, image, output_H, output_W, process_model):
x = crop_resize_center_crop_to_tensor(image, size=(output_H, output_W))
x = normalize(x, mean=0.5, std=0.5).to(process_model.device)
with torch.autocast(device_type="cuda", dtype=process_model.weight_dtype):
process_model.pipeline.vae.enable_tiling()
latents = process_model.vae.encode(x).latent_dist.sample()
latents = latents.to(dtype=process_model.weight_dtype)
latents.mul_(process_model.vae.config.scaling_factor)
process_model.pipeline.vae.disable_tiling()
return {"ref_images": [image], "last_latents": latents, "ref_latents": latents.clone()}
def process_interaction(self):
action_map = {
"forward": "w", "left": "a", "right": "d", "backward": "s",
"camera_l": "left_rot", "camera_r": "right_rot",
"camera_up": "up_rot", "camera_down": "down_rot",
}
actions = self.current_interaction[-1]
self.interaction_history.append(actions)
return [action_map[a] for a in actions]Synthesis + visual Pipeline 的 released code 行为可以概括为:
@torch.no_grad()
def hunyuan_gamecraft_call(pipe, image, interactions, prompt=""):
processed = pipe.process(
input_image=image,
output_H=704,
output_W=1216,
interaction_signal=interactions,
)
video = pipe.synthesis_model.predict(
ref_images=processed["visual_context"]["ref_images"],
last_latents=processed["visual_context"]["last_latents"],
ref_latents=processed["visual_context"]["ref_latents"],
action_list=processed["operator_condition"],
action_speed_list=[0.2] * len(interactions),
prompt=prompt,
negative_prompt="overexposed, low quality, deformation, ...",
size=(704, 1216),
video_length=129,
guidance_scale=2.0,
infer_steps=50,
flow_shift=5.0,
)
return videoReasoning Pipeline 的 released code 行为可以概括为:
@torch.no_grad()
def qwen_omni_reason(pipe, prompt, images=None, audios=None, videos=None):
processed = pipe.process(
text=prompt,
images=images,
audios=audios,
videos=videos,
)
messages = processed["messages"]
use_audio_in_video = processed["use_audio_in_video"]
text = pipe.reasoning_model.inference(
messages=messages,
max_new_tokens=128,
generation_kwargs=None,
use_audio_in_video=use_audio_in_video,
return_audio=False,
)
return textRepresentation Pipeline 的 released code 行为可以概括为:
@torch.no_grad()
def vggt_represent(pipe, image_paths, interaction=None):
images = pipe.operator.process_perception(image_paths)
request = {
"images": images,
"predict_cameras": True,
"predict_depth": True,
"predict_points": True,
"predict_tracks": False,
"preprocess_mode": "crop",
"resolution": 518,
}
outputs = pipe.representation_model.get_representation(request)
return {
"camera_params": (outputs.get("extrinsic"), outputs.get("intrinsic")),
"depth_map": outputs.get("depth_map"),
"point_map": outputs.get("point_map"),
"point_map_from_depth": outputs.get("point_map_from_depth"),
}VLA Pipeline 的 released code 行为可以概括为:
@torch.no_grad()
def lingbot_va_act(pipe, images, task_prompt):
cfg = pipe.config
cfg.guidance_scale = 5.0
cfg.action_guidance_scale = 1.0
cfg.num_inference_steps = 25
cfg.action_num_inference_steps = 50
pipe.reset(task_prompt)
processed = pipe.process(images=images, prompt=task_prompt)
init_latent = pipe.synthesis.encode_images(processed["videos"], env_type=cfg.env_type)
result = pipe.synthesis.predict(
operator=pipe.operator,
init_latent=init_latent,
prompt_embeds=pipe.prompt_embeds,
negative_prompt_embeds=pipe.negative_prompt_embeds,
num_chunks=10,
decode_video=False,
cache_name=pipe.cache_name,
)
return {"actions": result["actions"], "latents": result["latents"], "video": result["video"]}Memory 的 released code 是抽象接口,真实方法由具体 memory 类实现;框架意图可以概括为:
class MultimodalMemory(BaseMemory):
def record(self, data, metadata=None):
self.storage.append({
"content": data,
"type": metadata.get("type", "other"),
"timestamp": metadata.get("timestamp"),
"metadata": metadata,
})
def select(self, context_query):
return retrieve_relevant_items(self.storage, query=context_query)
def compress(self, memory_items):
return summarize_or_embed(memory_items)
def process(self, refined_data, target_format="kv_cache"):
return convert_to_model_inputs(refined_data, target_format=target_format)Code reference:
main@61c6baa2(2026-05-08) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Operator template | src/openworldlib/operators/base_operator.py | BaseOperator |
| Hunyuan interactive video operator | src/openworldlib/operators/hunyuan_game_craft_operator.py | HunyuanGameCraftOperator |
| Synthesis template | src/openworldlib/synthesis/base_synthesis.py | BaseSynthesis.predict() |
| Visual generation pipeline | src/openworldlib/pipelines/hunyuan_world/pipeline_hunyuan_game_craft.py | HunyuanGameCraftPipeline.__call__() |
| Reasoning module | src/openworldlib/reasoning/general_reasoning/qwen/qwen2p5_omni_reasoning.py | Qwen2p5OmniReasoning.inference() |
| Representation module | src/openworldlib/representations/point_clouds_generation/vggt/vggt_representation.py | VGGTRepresentation.get_representation() |
| VLA synthesis pipeline | src/openworldlib/pipelines/lingbot_va/pipeline_lingbot_va.py | LingBotVAPipeline.__call__() |
| Memory template | src/openworldlib/memories/base_memory.py | BaseMemory.record/select/compress/process/manage |
| Benchmark runner | examples/run_benchmark.py | load_pipeline(), run_reference(), run_evaluation() |
| Task/eval registry | examples/pipeline_load_mapping.py, examples/pipeline_infer_mapping.py | video_gen_pipe, reasoning_pipe, vla_pipe |
4. Experimental Setup (实验设置)
Datasets / benchmarks:论文没有给出大规模 benchmark 表或样本数。实验展示覆盖四类任务:navigation / interactive video generation、multimodal reasoning、3D scene generation、VLA / simulator generation。具体数据规模论文未详细说明;released code 的 data/benchmarks/tasks_map.py 注册了 navigation_video_gen、imagetext2video_gen、vla_eval,对应 benchmark 配置要求 metadata.jsonl、perception image path、task instruction 等字段,但当前 repo snapshot 没有公开完整 metadata 样本数。
Baselines / compared methods:
- Interactive / navigation video:Matrix-Game-2、Lingbot-World、Hunyuan-GameCraft、YUME-1.5、Hunyuan-WorldPlay、Wan-IT2V、WoW、Cosmos。
- 3D generation:VGGT、InfiniteVGGT、FlashWorld。
- VLA / simulator:LIBERO、AI2-THOR、、、LingBot-VA。
- Multimodal reasoning:论文讨论 spatial reasoning、omni/general reasoning、audio reasoning;released code 中主要映射到 Qwen2.5-Omni 等后端。
Evaluation metrics:论文主体以 qualitative demonstration 和 evaluator prompt 为主,没有报告 FVD、CLIP、success rate、PSNR 等数值表。released code 的 navigation video evaluator prompt 要求 MLLM 对 Navigation Fidelity、Visual Quality、Temporal Consistency、Scene Consistency、Motion Smoothness 五个维度打 - 分;text-to-video evaluator prompt 要求 Text-Video Alignment、Visual Quality、Temporal Consistency、Content Relevance、Motion Naturalness 五个维度打分。
Hardware / inference config:论文报告实验主要使用 NVIDIA A800 80GB VRAM 与 H200 141GB VRAM GPU。这里不是训练方法,论文未提供训练过程,也未提供训练 steps / LR / batch size;released code 的实际 inference defaults 来自具体文件而非 README 泛化值:HunyuanGameCraftPipeline.__call__() 默认 size=(704,1216)、num_frames=129、cfg_scale=2.0、infer_steps=50、flow_shift_eval_video=5.0;LingBotVAPipeline.from_pretrained() 默认 height=256、width=320、action_dim=30、action_per_frame=16,调用时默认 num_chunks=10、guidance_scale=5.0、action_guidance_scale=1.0、num_inference_steps=25、action_num_inference_steps=50;Qwen2p5OmniReasoning.inference() 默认 max_new_tokens=128,而 examples/pipeline_infer_mapping.py 的 Qwen evaluator wrapper 使用 max_new_tokens=1024。
5. Experimental Results (实验结果)
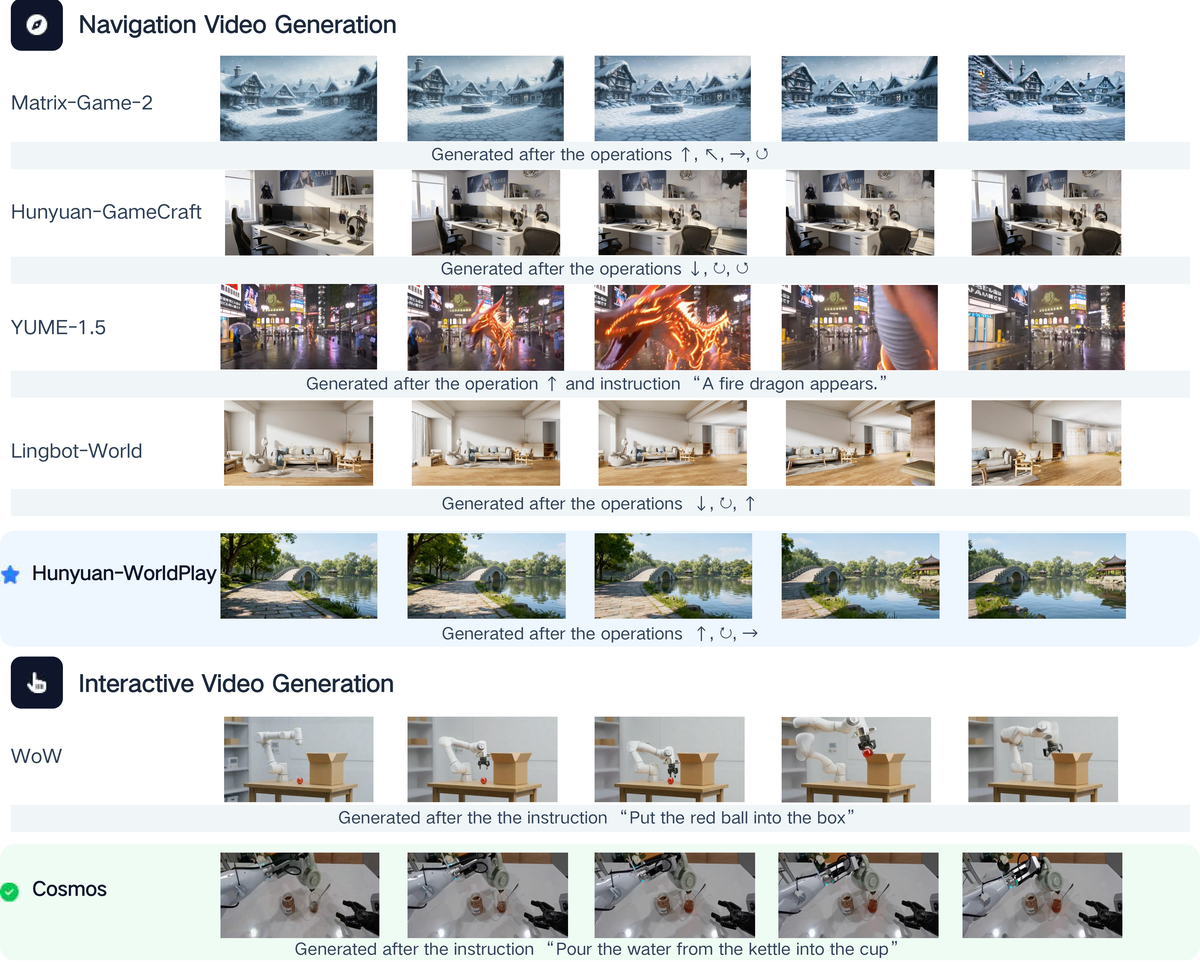
Figure 4 解读:上半部分展示 navigation video generation,下半部分展示 interactive video generation。Matrix-Game-2、Hunyuan-GameCraft、YUME-1.5、Lingbot-World、Hunyuan-WorldPlay 都接收方向或相机控制信号,生成不同时间步的视频帧;WoW 与 Cosmos 展示机器人交互任务。论文文字给出的结论是:Matrix-Game-2 速度快但长程生成有颜色漂移;Lingbot-World、Hunyuan-GameCraft、YUME-1.5 支持较高质量 navigation;Hunyuan-WorldPlay 整体视觉效果最好;Wan-IT2V 能做基础交互但物理一致性不足;WoW 支持复杂操作但质量和物理真实感不如 Cosmos。

Figure 5 解读:图中比较 VGGT、InfiniteVGGT 和 FlashWorld 的 3D scene generation / rendering case。VGGT 和 InfiniteVGGT 可以从不同视角渲染场景,但论文指出相机大幅移动时仍会出现几何不一致和复杂区域纹理模糊;FlashWorld 更快,但如何同时保持稳定 shape 与清晰 detail 仍是主要挑战。这支撑作者对显式 Representation 模块的定位:3D 不是普通视觉生成附属品,而是让 world state 可验证、可渲染、可进入 simulator 的关键能力。

Figure 6 解读:上半部分是 LIBERO manipulation case,展示根据 “Put the white mug on the left plate” 生成机器人动作序列;下半部分是 AI2-THOR embodied environment case,展示 “Take the egg out of the fridge, throw it into the trash can, then close the fridge door” 的多步骤交互。论文把这类结果作为 World Model 的闭环评估:模型不仅要识别场景,还要把语言目标、视觉状态和物理动作联系起来。
Main performance numbers:论文没有给出数值型主表;可精确记录的结果是定性比较和支持范围。Hunyuan-WorldPlay 被作者描述为 navigation video 中 best overall visual performance;Cosmos 在复杂交互生成质量和 physical realism 上优于 WoW;VGGT / InfiniteVGGT 仍受几何一致性和纹理模糊限制;FlashWorld 在速度上有优势但存在 shape-detail tradeoff。
Ablation:论文未报告消融表,也没有逐组件移除 Operator / Memory / Representation 后的数值差异。可以把这理解为本文的局限:它更像 framework / technical report,而不是一个带完整 quantitative benchmark 的新模型论文。
Limitations:作者明确指出 future work 包括更广泛硬件评估;next-frame prediction 比 next-token prediction 保留更多信息但效率需要显著提升;理想 World Model 可能需要硬件迭代、基础模型结构变化,以及复杂物理交互任务的完整实现。论文还隐含一个工程局限:released code 很多 base class 是抽象模板,具体模型依赖外部 checkpoint、子模块和安装脚本,因此复现实验更像集成多个后端,而不是一键训练一个统一模型。
Overall conclusion:OpenWorldLib 的价值在于给 World Model 研究建立“定义 + 接口 + 评估入口”的共同底座。它没有证明某个新模型在 benchmark 上取得 SOTA 数字,而是把 interactive video、3D / simulator、multimodal reasoning、VLA 与 memory-driven interaction 放到同一工程框架里,使未来模型能在可比较的 pipeline 中被调用和扩展。