MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Paper: arXiv:2603.17117 Code: AbdelStark/mosaicmem(非官方 Rust synthetic scaffold;官方项目页仍标注 Code Coming) Code reference:
main@3178e01e(2026-03-26)
1. Motivation(研究动机)
现有视频扩散模型正在从短片段生成走向可交互 world simulator,但长时一致性依赖 spatial memory:模型需要在相机移动、离开后回访、用户插入事件或编辑场景时,仍记得哪些结构应保持、哪些动态应更新。
- 显式 3D memory 的问题:点云、surfel、Gaussian/Splat cache 能通过重投影保证静态几何一致,但把生成器变成强约束的 video inpainting,动态物体和文本驱动事件容易僵硬,跨视角误差还会在全局重建里累积。
- 隐式 memory 的问题:以历史帧/latent 为 memory 能保留动态和外观,但 retrieval 粒度粗、上下文冗余大;即使给定正确 camera pose,也容易出现相机运动误差和 revisit drift,且 memory 不易解释或编辑。
- 本文目标:在不牺牲视频扩散模型动态生成能力的前提下,提供可定位、可检索、可操纵的长期空间记忆,让模型同时支持 precise camera control、promptable events、minute-level navigation 和 memory manipulation。
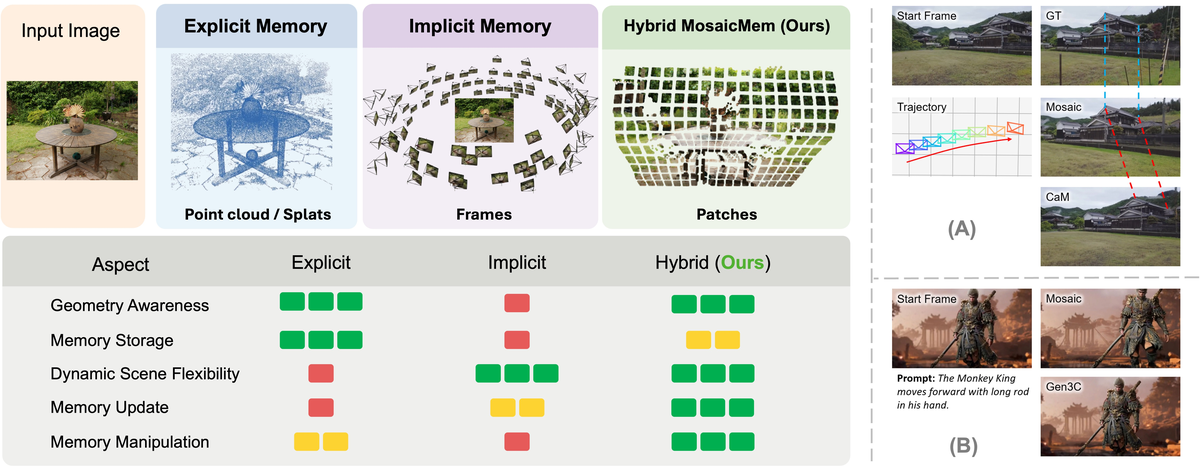
Figure 1 解读:左侧把 memory 机制拆成 explicit / implicit / hybrid 三类;MosaicMem 的核心折中是用 patch 作为 memory 单元,既保留 3D localization,又不把整段生成锁死成静态重投影。右侧示例显示:相对隐式 memory,它能更准地跟随 camera motion;相对显式 memory,它允许新物体和事件随 prompt 发生变化。
2. Idea(核心思想)
核心洞察:不要在“全局 3D cache”和“整帧 latent cache”之间二选一,而是把 patch 提升到 3D 后再作为 DiT 的条件 token 使用。Patch 是比点云更有语义/纹理的信息单元,又比整帧 memory 更可定位、可裁剪、可重排。
与 GEN3C / SEVA / VMem 这类显式 memory 相比,MosaicMem 不直接渲染固定几何结果,而是把查询视角下对齐的 patch 作为参考,让扩散模型决定哪些区域保持、哪些区域重新生成;与 WorldMem / Context-as-Memory 这类隐式 memory 相比,它不是靠整帧重用或 FOV overlap 粗检索,而是通过 3D patch location 做 targeted retrieval 和 alignment。
3. Method(方法)
3.1 总体框架:patch-and-compose hybrid memory
MosaicMem 的 pipeline 分为四步:1)从已生成/观测帧中抽取 patch;2)用 off-the-shelf 3D estimator 估计 depth、intrinsics、extrinsics,把 patch lift 到 3D;3)给定目标 camera pose,检索会投影到当前视野的 patch,并 compose 成 queried-view mosaic;4)把 mosaic patch tokens 与当前 noised latent tokens 一起送入 DiT,通过 attention conditioning、Warped RoPE / Warped Latent 和 PRoPE 对齐。
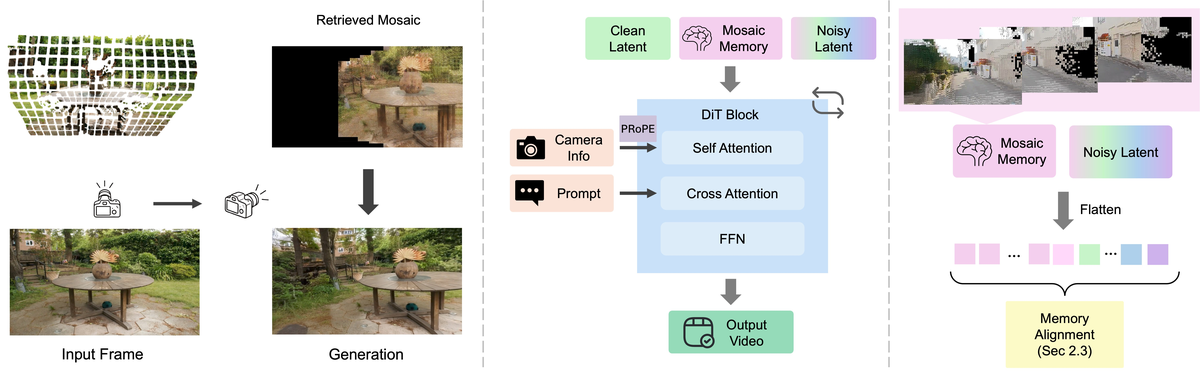
Figure 2 解读:左侧展示 patch 被 lift 到 3D 后按 target view 重新 gathering;中间展示 camera control 由 MosaicMem retrieval 与 PRoPE 共同提供;右侧是 DiT 内部 token 级融合:clean latent / noisy latent / memory latent 展平后通过 attention 交互,最终生成当前 view 的 output video。
直觉上,MosaicMem 把 memory 从“必须被完全相信的几何渲染”降级为“空间对齐的证据”。这使模型能在墙面、建筑、道路等应持久的部分复用 memory,同时在车、人、动物、天气等应变化的区域用文本条件重新 inpaint,因此适合交互式 world model。
3.2 Patch lifting 与 queried-view retrieval
给定源帧 patch 坐标 、深度 、相机内参 和外参 ,patch token 可被反投影到世界坐标,再投影到目标视角 :
检索阶段不必把整帧历史都塞进上下文,而是依据目标 frustum、可见性、时间衰减、空间多样性与 token budget 选出 top- patch。由于同一场景视频高度冗余,只要覆盖关键 spatiotemporal locations,就能用较少 token 维持 long-term persistence。
3.3 Memory alignment:Warped RoPE 与 Warped Latent
3D VAE 的时空压缩会降低 RoPE 坐标分辨率,导致检索 patch 和当前 latent token 的中心不完全对齐。MosaicMem 用两种互补 alignment:
- Warped RoPE:不移动 latent feature,而是把每个 memory patch token 的 RoPE 坐标改成重投影后的 fractional target coordinate 。论文的核心投影式为:
- Warped Latent:直接在 feature space 中对 memory latent 做 differentiable bilinear grid sampling,可写作:
其中 是由源/目标相机和 depth 计算得到的 warp grid。Warped RoPE 更像“改 attention 坐标”,Warped Latent 更像“把 patch feature 本身 warp 到目标视角”;二者混合训练在极端慢相机运动和 autoregressive rollout 中更稳。

Figure 3 解读:即使不 fine-tune,直接注入 Mosaic Memory 也能给 Wan 2.2 提供空间参考;但 training-free 版本只能证明 patch memory 是有效条件,不能替代后续的 Warped RoPE / Warped Latent / PRoPE 对齐训练。
3.4 PRoPE camera conditioning
Mosaic Memory 本身提供的是“哪里有可复用视觉证据”,并不足以严格表达连续 camera trajectory;大幅旋转、稀疏 memory 或 3D VAE 的 temporal compression 都会让 motion signal 不够细。论文因此把 PRoPE 作为 DiT self-attention 内的 camera-conditioning interface。
给定每帧投影矩阵 ,PRoPE 用相对投影变换 编码 view-to-view geometry,并在 attention 中通过 camera-dependent transformation 作用到 。由于视频 latent frame index 对应原始四帧 ,实现上需要为同一个 latent slice 展开 sub-index ,保证每个 compressed latent token 使用正确的 per-frame camera matrix。

Figure 5 解读:隐式 memory baseline 在回访和大旋转时 camera path 明显偏移;MosaicMem + PRoPE 同时利用 memory registration 与显式 trajectory signal,因此能把 replay frame 对齐到更准确的相机位置。图中不带 PRoPE 的版本说明:memory reference 不能完全替代 camera control。
3.5 Pseudocode(基于论文与公开 Rust scaffold 的 PyTorch 风格重写)
公开仓库是非官方 Rust synthetic scaffold,不含 Wan 2.2 checkpoint、训练脚本或真实 DiT 权重;下面伪代码对应其 src/memory/*、src/attention/*、src/pipeline/* 的组件边界,并按论文公式补齐张量语义。
import torch
import torch.nn.functional as F
class MosaicMemoryStore:
def __init__(self, max_patches=4096, patch_size=16, latent_patch_size=2):
self.patches = []
self.max_patches = max_patches
self.patch_size = patch_size
self.latent_patch_size = latent_patch_size
def add_frame(self, image, latent, depth, K, T, timestamp):
# src/memory/store.rs + src/geometry/depth.rs + src/geometry/projection.rs
for rect, z_patch in patchify(latent, size=self.latent_patch_size):
uv = patch_center(rect)
xyz = backproject(K, T, uv, depth[uv])
self.patches.append({
"latent": z_patch,
"source_rect": rect,
"source_xyz": xyz,
"source_depth": depth[uv],
"K": K,
"T": T,
"timestamp": timestamp,
})
self.evict_low_score_if_needed()def retrieve_mosaic(store, target_K, target_T, target_time, top_k):
# src/memory/retrieval.rs + src/memory/mosaic.rs
candidates = []
for p in store.patches:
uv_t, visible = project_to_view(target_K, target_T, p["source_xyz"])
if not visible:
continue
recency = torch.exp(-abs(target_time - p["timestamp"]) / store.temporal_half_life)
visibility = frustum_visibility_score(uv_t)
diversity = spatial_diversity_penalty(uv_t, candidates)
score = visibility * recency - diversity
candidates.append((score, p, uv_t))
selected = sorted(candidates, key=lambda x: x[0], reverse=True)[:top_k]
return compose_mosaic_frame(selected, target_T)def warped_rope_positions(retrieved_patches, target_K, target_T):
# src/attention/warped_rope.rs; paper Eq. (2)
coords = []
for p in retrieved_patches:
uv = token_grid(p["source_rect"])
depth = p.get("depth_tile", p["source_depth"])
xyz = backproject(p["K"], p["T"], uv, depth)
uv_target = project(target_K, target_T, xyz) # fractional (u', v')
t_rel = p["timestamp"]
coords.append(torch.stack([torch.full_like(uv_target[..., :1], t_rel), uv_target], dim=-1))
return torch.cat(coords, dim=0)def warped_latent_patch(z_patch, source_K, source_T, target_K, target_T, depth_tile):
# src/attention/warped_latent.rs
grid = compute_warp_grid(source_K, source_T, target_K, target_T, depth_tile)
# grid: [H, W, 2] normalized to [-1, 1]
valid_mask = (grid[..., 0].abs() <= 1) & (grid[..., 1].abs() <= 1)
z_warped = F.grid_sample(z_patch[None], grid[None], mode="bilinear", align_corners=False)[0]
return z_warped * valid_mask.float()[None]def generate_window(dit, noisy_latent, text_emb, memory_store, trajectory, intrinsics):
# src/pipeline/inference.rs
mosaics = [retrieve_mosaic(memory_store, intrinsics, pose.T, pose.t, top_k=512)
for pose in trajectory]
mem_tokens = flatten_memory_tokens(mosaics)
rope_coords = warped_rope_positions(mem_tokens, intrinsics.K, trajectory.target_T)
prope = build_prope_transforms(trajectory.camera_matrices, temporal_compression=4)
return dit(noisy_latent, text_emb, memory_tokens=mem_tokens,
memory_rope=rope_coords, prope=prope)def autoregressive_rollout(pipeline, init_frame, trajectory, segment_len=80, total_seconds=120):
# src/pipeline/autoregressive.rs; paper Mosaic Forcing
memory = MosaicMemoryStore()
prev = init_frame
outputs = []
for poses in chunk_trajectory(trajectory, segment_len):
segment = pipeline.generate(prev, poses, memory)
memory.add_frame_sequence(segment, poses) # generated segment updates memory
prev = segment[-1:] # last frame becomes next first frame
outputs.append(segment)
return torch.cat(outputs, dim=1)Code reference:
main@3178e01e(2026-03-26)
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Patch-based 3D memory store | src/memory/store.rs, src/memory/mosaic.rs | MosaicMemoryStore, MosaicFrame, patch metadata |
| Target-view retrieval / patch-and-compose | src/memory/retrieval.rs | MemoryRetriever, retrieve, retrieve_window, frustum and diversity selection |
| Warped RoPE | src/attention/warped_rope.rs | WarpedRoPE, compute_warped_positions |
| Warped Latent | src/attention/warped_latent.rs | WarpGrid, WarpOperator, compute_warp_grid |
| PRoPE camera conditioning | src/attention/prope.rs | ProjectiveTransform, PRoPEOperator, projection matrix transforms |
| Single-window generation | src/pipeline/inference.rs | InferencePipeline, build_memory_context |
| Long-horizon / AR rollout | src/pipeline/autoregressive.rs | AutoregressivePipeline, segment chaining |
| Synthetic vs real backend boundary | src/backend.rs, src/pipeline/config.rs | BackendMode, BackendBridge, SyntheticBridge |
| Memory editing | src/memory/manipulation.rs | erase / translate / splice-style patch operations |
代码差距:该 repo 明确称自己是 synthetic scaffold;默认 backend 是 synthetic,real backend 需要 checkpoint 与 feature gate。因此它能帮助理解模块划分和 data structures,但不能作为论文中 Wan 2.2 fine-tuning、MosaicMem-World training config 或 Table 1/2 数值的复现实证来源。
4. Experimental Setup(实验设置)
- Dataset / benchmark:MosaicMem-World。论文从四类来源收集带 revisitation 的轨迹:licensed Unreal Engine 5 scenes、商业游戏环境(如 Cyberpunk 2077)、真实第一人称采集、以及 Sekai 等已有数据中 revisit frequency 最高的序列;每类来源规模描述为 “on the order of tens of hours”,论文未给精确视频数/样本数。每个 sequence 切成 32-frame segments,并用 Gemini 3 生成 static scene description 与 dynamic description;过滤 inaccurate 3D estimates 或 excessive motion blur。
- Baselines:显式 memory:VMem、GEN3C、SEVA、VWM;隐式 memory:WorldMem、Context-as-Memory (CaM);camera-control / alignment ablation:ControlMLP alone、PRoPE alone、MosaicMem w/o PRoPE、PRoPE + Warped Latent、PRoPE + Warped RoPE、MosaicMem full;AR video generation:Matrix-Game、RELIC、MosaicMem-WRoPE。
- Metrics:camera control 用 RotErr(degree,越低越好)和 TransErr(越低越好);video quality 用 FID / FVD;retrieval consistency 用 SSIM / PSNR / LPIPS;dynamic ability 用 Dynamic Score;AR 评测还采用 VBench-style Subject Consistency、Background Consistency、Motion Smoothness、Temporal Flickering、Aesthetic Quality、Imaging Quality,并报告 PSNR、SSIM、RotErr、TransErr。
- Training config:fine-tune Wan 2.2 5B TI2V DiT;optimizer 为 AdamW;learning rate ;250k training steps;effective batch size 64;8 × H100 GPU clusters;inference 使用 Wan default sampler,50 denoising steps。Mosaic Forcing 版本把 bidirectional MosaicMem distill 到 causal architecture,并结合 Rolling Forcing;报告实时 16 FPS、640 × 360 resolution。

Figure 4 解读:显式 memory baseline(GEN3C / VWM)在空间一致性上有优势,但动态物体生成和 prompt adherence 变弱;MosaicMem 能在已有场景中添加 knight、horse、car 等新动态元素,说明 patch memory 没有把生成过程锁死成静态重建。
5. Experimental Results(实验结果)
5.1 Spatial memory 主表
| Method | RotErr↓ | TransErr↓ | FID↓ | FVD↓ | SSIM↑ | PSNR↑ | LPIPS↓ | Dynamic↑ |
|---|---|---|---|---|---|---|---|---|
| VMem | 1.59 | 0.14 | 77.12 | 363.34 | 0.64 | 21.64 | 0.17 | 1.18 |
| GEN3C | 1.61 | 0.13 | 77.41 | 372.08 | 0.64 | 21.58 | 0.17 | 1.21 |
| SEVA | 1.42 | 0.12 | 74.67 | 301.77 | 0.66 | 22.01 | 0.15 | 1.22 |
| VWM | 1.50 | 0.13 | 75.83 | 323.67 | 0.65 | 21.86 | 0.16 | 1.41 |
| WorldMem | 5.87 | 0.49 | 85.72 | 403.50 | 0.47 | 15.34 | 0.46 | 1.67 |
| CaM | 4.65 | 0.43 | 85.32 | 392.11 | 0.49 | 15.78 | 0.42 | 1.72 |
| ControlMLP alone | 6.51 | 0.52 | 89.17 | 458.45 | 0.37 | 13.55 | 0.56 | 1.84 |
| PRoPE alone | 4.91 | 0.36 | 86.44 | 412.85 | 0.45 | 14.32 | 0.52 | 1.75 |
| MosaicMem w/o PRoPE | 0.79 | 0.11 | 73.18 | 250.84 | 0.68 | 22.33 | 0.14 | 2.11 |
| PRoPE + Warped Latent | 0.66 | 0.08 | 75.46 | 268.13 | 0.65 | 21.49 | 0.15 | 1.98 |
| PRoPE + Warped RoPE | 0.70 | 0.09 | 71.89 | 243.59 | 0.69 | 22.80 | 0.12 | 2.24 |
| MosaicMem (full) | 0.51 | 0.06 | 65.67 | 232.95 | 0.75 | 23.57 | 0.11 | 2.58 |
结论:MosaicMem full 在全部指标上最佳。相对隐式 memory,最大差异来自 camera control 与 memory consistency;相对显式 memory,最大差异来自 Dynamic Score 和视觉质量,说明 hybrid patch memory 既保留几何定位,又释放了动态生成能力。
5.2 Long-horizon、memory manipulation 与 AR rollout

Figure 6 解读:2 分钟 navigation 中,蓝/绿框标出 MosaicMem 能在长时间、大尺度相机运动后召回已观察区域;红框显示 CaM 在 extended sequence 中更易产生 artifacts 或不一致。

Figure 7 解读:因为 memory 单元带 3D spatiotemporal location,作者可以把不同 scene 的 memory 在水平或垂直方向拼接,构造不现实但几何连续的探索空间。这是 frame-level implicit memory 很难直接做到的能力。

Figure 8 解读:Mosaic Forcing 把 bidirectional MosaicMem 转成 autoregressive 生成器;RELIC 会出现 memory retrieval error,只有 Warped RoPE 的版本在极端情况下可能 collapse,full 模型通过加入 Warped Latent 提升 few-step inference 的稳定性。
| AR Method | Total↑ | Subject Consist↑ | Bg Consist↑ | Motion Smooth↑ | Temporal Flicker↑ | Aesthetic Quality↑ | Imaging Quality↑ | PSNR↑ | SSIM↑ | RotErr↓ | TransErr↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Matrix-Game | 75.11 | 82.40 | 87.92 | 88.35 | 89.10 | 43.12 | 59.77 | 18.57 | 0.524 | 5.32 | 0.38 |
| RELIC | 79.08 | 86.21 | 91.08 | 94.12 | 92.05 | 47.01 | 64.02 | 20.23 | 0.591 | 4.99 | 0.36 |
| MosaicMem-WRoPE | 77.81 | 85.03 | 90.41 | 92.73 | 91.22 | 45.88 | 61.60 | 19.01 | 0.566 | 1.63 | 0.16 |
| MosaicMem (full) | 81.11 | 88.32 | 93.40 | 96.58 | 94.21 | 48.15 | 65.97 | 21.57 | 0.652 | 0.89 | 0.11 |
论文未单列 Limitations section;可确认的风险来自正文:1)MosaicMem-World 需要过滤 inaccurate 3D estimates / excessive motion blur,说明上游 depth / pose 质量仍是瓶颈;2)Warped RoPE 在极慢相机运动等极端场景会让新观察物体在边界反复生成,需 Warped Latent 修正;3)官方实现尚未发布,公开可见代码主要是非官方 synthetic scaffold,无法验证训练配置和主表结果。