Knot Forcing: Taming Autoregressive Video Diffusion Models for Real-time Infinite Interactive Portrait Animation
Authors: Steven Xiao*, Xindi Zhang*, Dechao Meng*, Qi Wang, Peng Zhang, Bang Zhang Affiliations: Tongyi Lab, Alibaba Group arXiv: 2512.21734 Project Page: humanaigc.github.io/knot_forcing_demo_page GitHub: https://github.com/HumanAIGC
1. Motivation (研究动机)
1.1 实时 Portrait Animation 的核心需求
Real-time portrait animation 需要同时满足四个关键要求:高视觉保真度 (high visual fidelity)、时序一致性 (temporal coherence)、超低延迟 (ultra-low latency) 和 动态交互控制 (responsive control from dynamic inputs)。现有方案存在根本性矛盾:
- Bidirectional diffusion models (如 Wan2.1-T2V):质量优秀,但依赖全序列 iterative denoising,无法实现 streaming generation,延迟高
- Causal autoregressive (AR) video diffusion models (如 CausVid, Self Forcing, Rolling Forcing, LongLive):通过 score distillation 将 bidirectional teacher 蒸馏到 few-step causal student,支持逐帧/逐 chunk 流式生成,但存在三大问题:
1.2 Causal AR 模型的三大痛点
痛点一:Attention context 周期性跳变 → Chunk 边界处 motion discontinuity
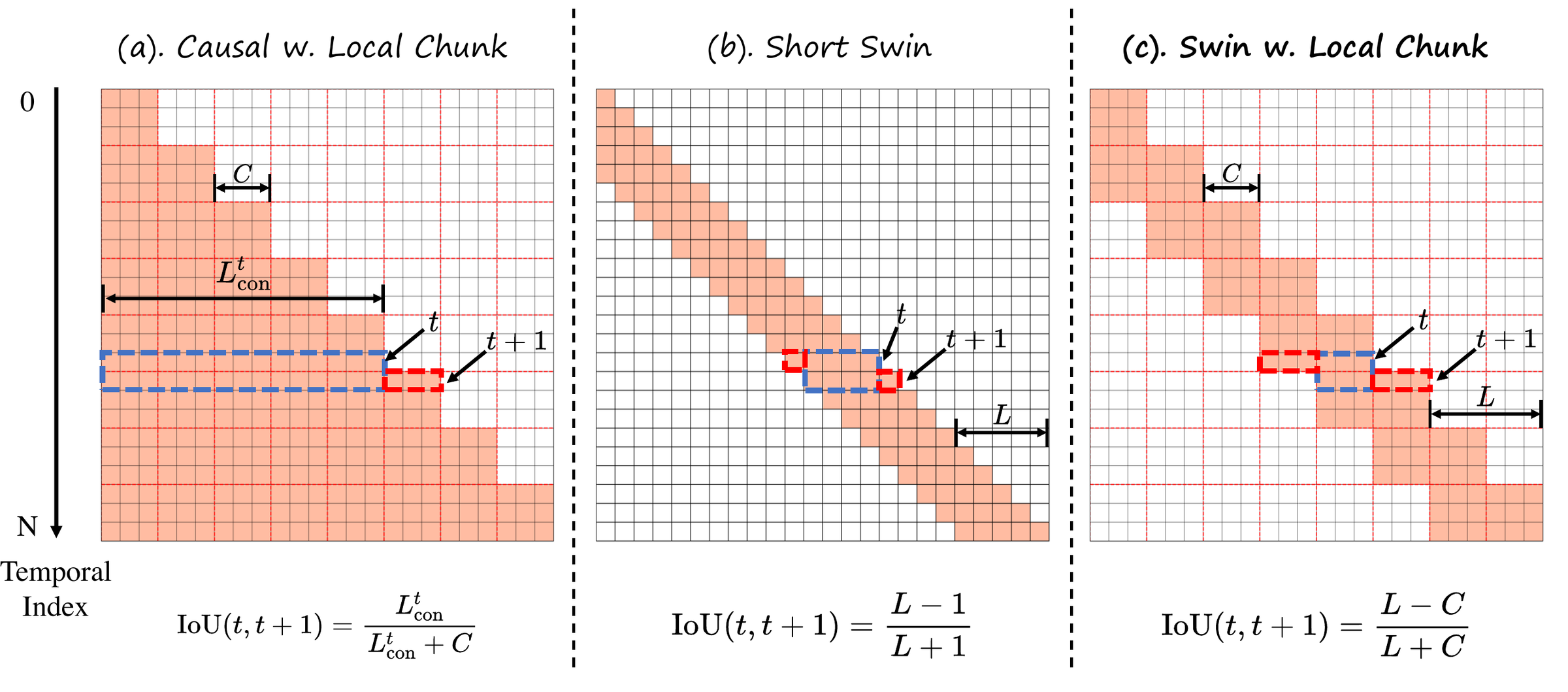
Figure 3 解读:作者可视化了不同 causal 设计下的 attention mask。(a) Causal w. Local Chunk (CausVid / Self Forcing):每个 chunk 内部有完整 attention,但相邻 chunk 之间 attention context 发生 剧烈跳变,IoU(t, t+1) = k_com / (k + C)。(b) Short Swin (LongLive):采用 sliding window,IoU 稍高但仍有周期性波动,IoU = (L-1)/(L+1)。(c) Swin w. Local Chunk (Ours):结合 sliding window + local chunk overlap,IoU = (L-C)/(L+C),跳变幅度最小,更接近 bidirectional teacher 的平滑 context 变化。这种 attention context 的周期性跳变是导致 flickering、shape warping、motion jitter 等 artifact 的 根本原因。
痛点二:Error accumulation → Long-term visual degradation
Causal model 的 attention receptive field 有限,生成过程中小误差不断累积传播,导致纹理、结构逐渐退化,时序一致性崩溃。现有方法用初始帧作为 attention sink 来保持全局一致性,但随着时间推移,生成内容仍会逐渐偏离全局语义。
痛点三:Train-inference gap
Teacher Forcing / Diffusion Forcing 用 ground-truth prefix 训练但推理时用 model-generated history,导致分布不匹配。Self Forcing 通过直接采样模型自身生成的视频来训练,缓解了此问题,但仍不能完全解决。

Figure 2 解读:展示了 Rolling Forcing、LongLive、Self Forcing 在长序列生成中的 temporal artifact。顶行和中间行可以观察到相邻帧之间不一致的物体运动(形变、位置突变);底行可以看到 色调周期性跳变 (abrupt color tone changes)。这些 artifact 直接源于上述 attention context 跳变问题。
2. Idea (核心思想)
Knot Forcing 的核心思想用一句话概括:
通过 Temporal Knot (相邻 chunk 的重叠边界帧) + Global Context Running Ahead (reference image 的动态前瞻定位),在保持 streaming 效率的同时恢复 bidirectional teacher 的信息流模式,实现无限长实时 portrait animation。
三个关键设计思想:
| 层次 | 问题 | 解决方案 | 类比 |
|---|---|---|---|
| 局部 | Chunk 内时间建模 | Short sliding window attention + Reference KV cache | 滑动窗口保证局部连续,reference 锚定全局身份 |
| 边界 | Chunk 间不连续 | Temporal Knot:相邻 chunk 共享重叠帧,通过 I2V mask inpainting 传递 spatio-temporal cues | 像绳结一样把相邻 chunk “系” 在一起 |
| 全局 | 长期 error 累积和 drift | Running Ahead:动态更新 reference image 的 RoPE 位置编码,始终位于当前生成帧的”未来” | reference 始终是”前方的灯塔”,持续校正方向 |
核心 insight:Temporal Knot 解决 local coherence,Running Ahead 解决 global coherence,两者互补。
3. Method (方法)
3.1 Chunk-wise AR Generation with Sliding Window and Global Context
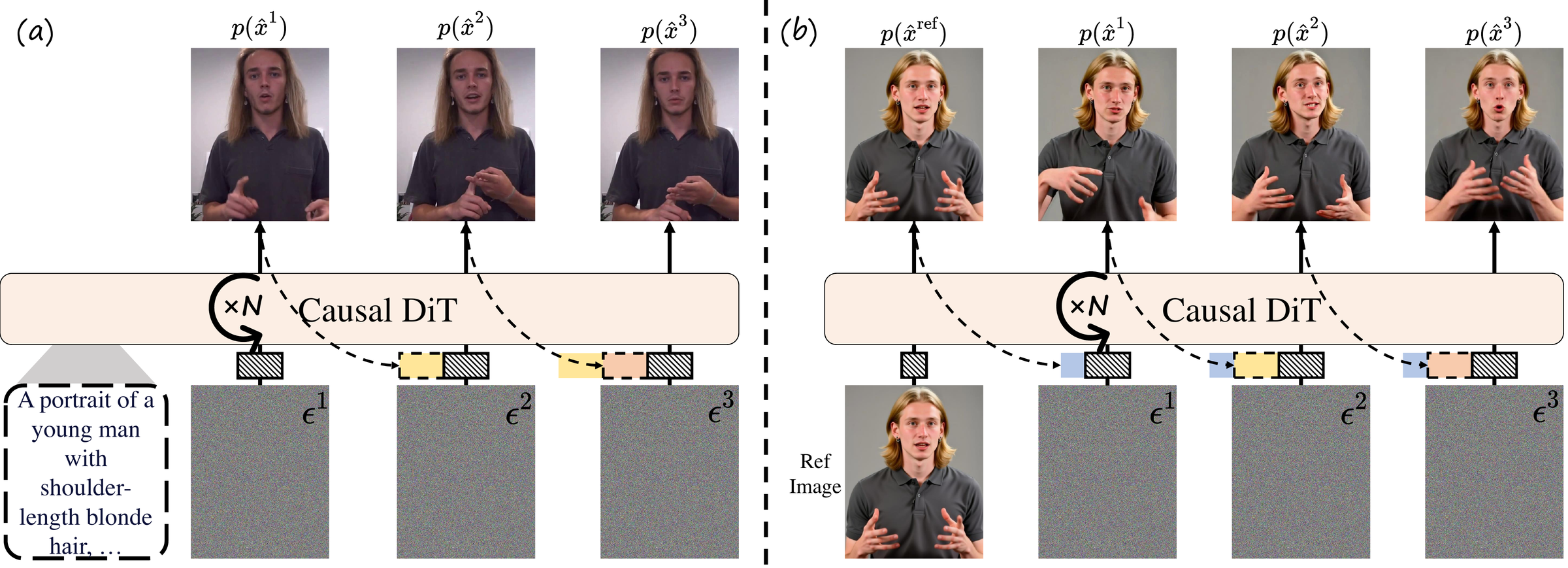
Figure 1 解读:对比了 (a) 标准 T2V causal video diffusion 和 (b) 本文的 portrait animation 方案。(a) 中模型以 text prompt 为条件,逐 chunk 自回归生成视频帧。(b) 中模型以 reference image 为条件,通过 cached KV states 保持全局身份一致性,同时使用 short sliding window 进行局部时间建模。注意 (b) 中 reference image 的 KV cache 是独立维护的全局锚点。
基础框架:基于 Wan2.1-T2V-1.3B 的 DiT architecture,采用 Self Forcing 训练范式(直接用模型自身生成的视频训练,消除 train-inference gap),蒸馏为 4-step causal AR model。
ID Injection:将 reference image 通过 video VAE 编码为 static latent,沿 temporal dimension 与 video latents 拼接,通过 masked inpainting (来自 text-to-video diffusion model) 实现 identity 注入。训练时随机 expose reference image 和 past frames,推理时仅 reference image 可见。
Driving Signals Injection:在选定的 DiT blocks 之后插入 cross-attention layers,实现 audio、expression parameters、motion strength 等 driving signal 与 video features 的 frame-wise、content-aware fusion。
Streaming generation 公式:
其中 是 chunk size, 是 sliding window length, 是 reference image, 是 forward diffusion process。
# Pseudocode: Chunk-wise Streaming Generation (基础框架)
def streaming_generate_base(model, x_ref, chunk_size=3, window_len=6, num_steps=4):
"""基于 sliding window 的 chunk-wise streaming generation"""
kv_ref = model.compute_kv(x_ref, rope_index=0) # Reference image KV cache (全局锚点)
kv_prefix = [] # 前序帧的 KV cache (sliding window)
generated_frames = [] # 已生成的所有帧
i = 0 # 当前 chunk 起始帧 index
while i < total_frames:
# 初始化当前 chunk 为纯噪声
x_noisy = torch.randn(chunk_size, C, H, W) # z^{i:i+c+1} ~ N(0, I)
# Sliding window: 取最近 L-c 帧作为 clean prefix context
prefix = generated_frames[max(0, i + chunk_size - window_len):i]
# Multi-step denoising (T=4 steps)
for j in range(num_steps, 0, -1):
t_j = noise_schedule[j]
# DiT forward: 条件为 noisy chunk + clean prefix + ref KV cache
x_pred = model(x_noisy, t_j, kv_prefix=kv_prefix, kv_ref=kv_ref)
if j > 1:
# Forward diffusion 加噪到下一个 noise level
x_noisy = forward_diffuse(x_pred, noise_schedule[j - 1])
else:
x_clean = x_pred
generated_frames.extend(x_clean)
# 更新 prefix KV cache (sliding window 滚动)
kv_prefix = model.compute_kv(generated_frames[-window_len:], rope_index=0)
i += chunk_size
return generated_frames3.2 Forcing Inter-frame Coherence with Temporal Knot
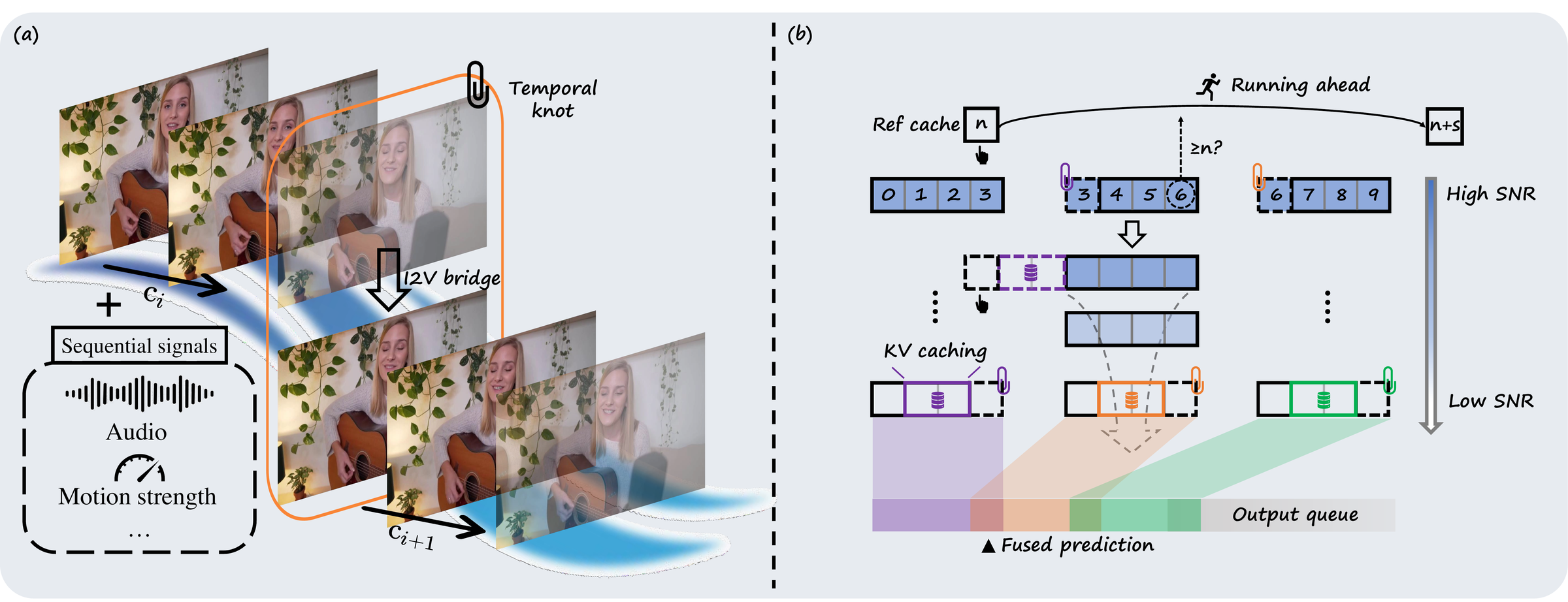
Figure 4 解读:Knot Forcing 的两个核心组件。(a) Temporal Knot Module:当前 chunk 生成时,不仅 denoise 自身帧,还包含前一个 chunk 尾部的 k 帧(即 temporal knot)。这些 knot 帧通过 I2V bridge (mask inpainting) 从前一 chunk 传播到当前 chunk,充当跨 chunk 的语义桥梁。下方的 Sequential signals (Audio, Motion strength) 通过 cross-attention 注入 DiT blocks。(b) Rollout Inference Pipeline with Running Ahead:Reference image 的 KV cache 在最开始计算一次;每个 chunk 生成后,prefix context 的 KV 被缓存用于下一个 chunk。Reference image 的 RoPE index n 在每次 chunk 生成后动态更新 (n ← n + s),确保它始终位于当前帧的”未来”位置。chunk 边界处的 knot 帧(橙色/紫色标记)被两次 denoise(一次作为前 chunk 的后缀,一次作为后 chunk 的前缀),最终取平均 (fused prediction)。
核心问题:Causal model 中每个 token 只能看到过去的帧,而 bidirectional teacher 能看到完整序列。这种 attention context 的结构性差异导致 chunk 边界处的 feature misalignment,表现为 flickering、shape warping、motion jitter。
解决方案:引入 Temporal Knot --- 在 denoise 当前 chunk 时,同时 denoise 下一个 chunk 的前 k 帧。这些重叠的 knot 帧通过 I2V mask inpainting 从上一 chunk 传播 spatio-temporal cues。
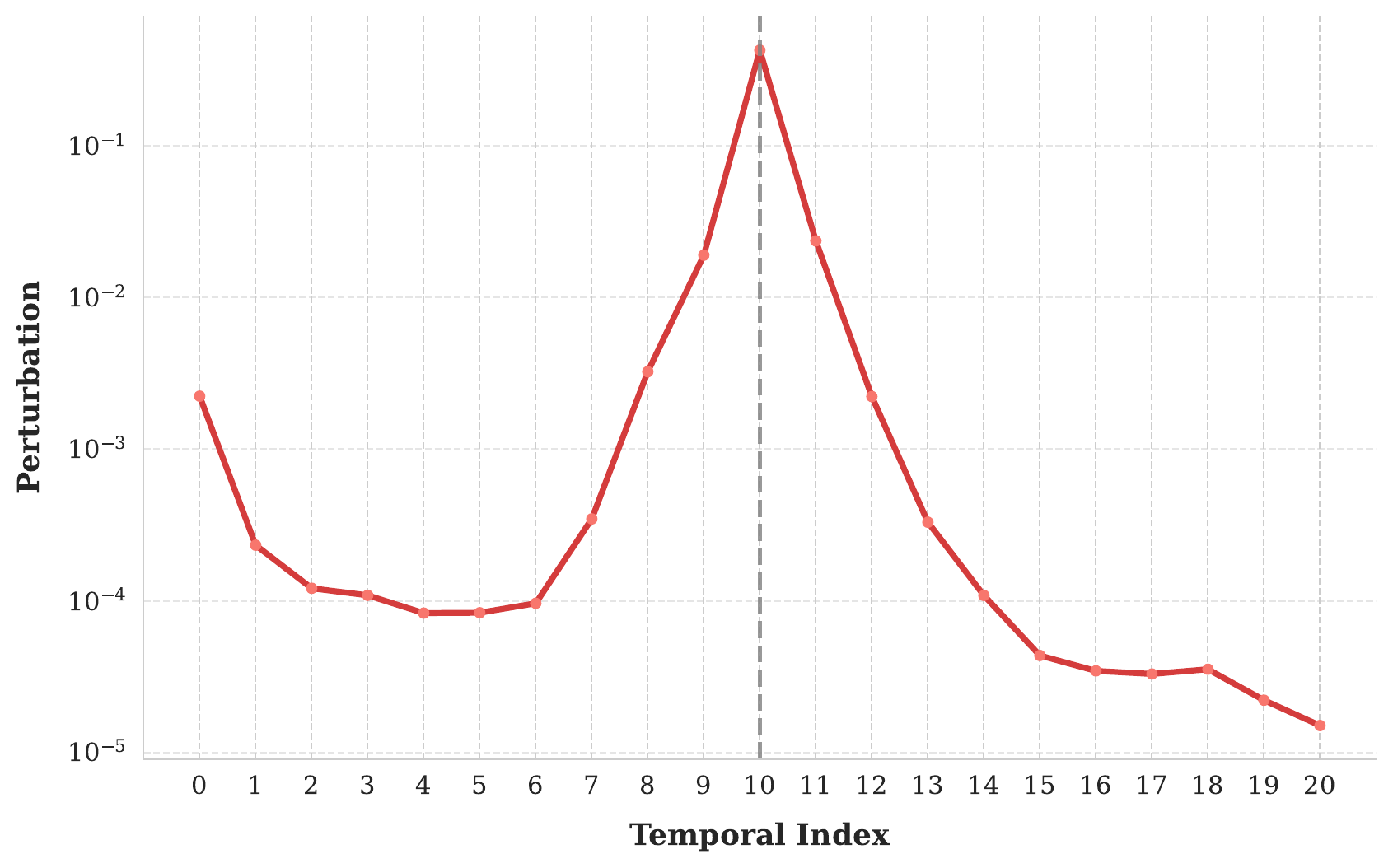
Figure 5 解读:通过 ablation 每个 context frame 并计算 attention output 的 L2 差异(归一化),分析 inter-frame dependency。以第 10 帧为 anchor,发现 相邻帧的贡献最大(perturbation 最高),距离越远贡献衰减。这说明 k=1 即可有效传播 context,在效果和延迟之间取得最优平衡。
带 Temporal Knot 的 denoising 公式:
Knot 帧融合:边界处的 knot 帧被 denoise 两次(一次作为前 chunk suffix,一次作为后 chunk prefix),最终取平均:
这实现了一种 hinge-style latent propagation:local chunks 通过 sliding window 保持 bidirectional context awareness,temporal knots 通过 mask inpainting 桥接相邻 chunk 的 semantic gap,恢复了被中断的 inter-chunk information flow,模拟了 bidirectional teacher 的 full temporal modeling。
# Pseudocode: Temporal Knot Module
def generate_chunk_with_knot(model, chunk_idx, local_context, ref_kv_cache,
prev_knot, timesteps, c=3, k=1):
"""
带 Temporal Knot 的 chunk generation
prev_knot: k frames from tail of previous chunk (temporal knot from last step)
k: number of overlapping knot frames (default 1)
"""
# Initialize: c frames for current chunk + k frames for next chunk's knot
x = sample_noise(num_frames=c + k) # ~ N(0, I)
for j in range(len(timesteps) - 1, 0, -1):
t_j = timesteps[j]
t_prev = timesteps[j - 1]
# Inject previous knot via I2V mask inpainting at head of current chunk
if prev_knot is not None:
x[:k] = apply_mask_inpainting(x[:k], prev_knot, t_j)
# Model forward: denoise c+k frames together
x_pred = model(
concat([local_context, x], dim='time'),
t_j, kv_pre=local_kv, kv_ref=ref_kv_cache
)
if j == 1: # Last denoising step
# ---- Fused Prediction: 融合 knot 区域的前后两次预测 ----
if chunk_idx > 0 and prev_knot is not None:
x_pred[:k] = (x_pred[:k] + prev_knot) / 2.0
# Extract new knot for next chunk (tail k frames of current generation)
new_knot = x_pred[c:c + k].clone()
else:
x = forward_diffusion(x_pred, t_prev)
output_frames = x_pred[:c] # Current chunk's c clean frames
return output_frames, new_knot3.3 Mitigating Error Accumulation: Global Context Running Ahead
核心问题:即使有 attention sink(将初始帧作为全局 context),长序列生成中 content 仍然逐渐偏离全局语义 → visual drift。
关键洞察:训练时模型学习的是短 clip 生成,最后一帧作为 global context(“未来目标”)提供方向性引导。推理时如果 reference image 的 temporal position 固定在 t=0,随着生成推进,它越来越”过去”,失去引导作用。
解决方案:将 reference image 视为 moving “pseudo-final” frame,在每次 chunk 生成后 动态更新其 RoPE index,使其始终位于当前生成帧的 未来位置:
然后重新计算 reference image 的 KV cache:
这使得 reference image 始终像一个”前方的锚点”,持续为模型提供方向性的语义引导,有效抑制 error propagation 和 visual drift。
# Pseudocode: Running Ahead Mechanism
def update_running_ahead(model, ref_image, current_rope_index_n,
chunk_start_i, chunk_size_c, interleave_s):
"""
动态更新 reference image 的 RoPE position
current_rope_index_n: 当前 reference 的 RoPE index
interleave_s: running ahead 步进大小
"""
generated_end = chunk_start_i + chunk_size_c + 1
if generated_end > current_rope_index_n:
# Reference position 需要前瞻推进
new_n = current_rope_index_n + interleave_s
# 用新的 RoPE index 重新编码 reference image KV cache
# 模型将 reference 感知为"未来将到达的目标帧"
kv_ref = model.compute_kv(ref_image, rope_index=new_n, timestep=0)
return kv_ref, new_n
return None, current_rope_index_n # 不需要更新3.4 Complete Inference Algorithm (Algorithm 1)
# Pseudocode: Full Knot Forcing Inference (对应论文 Algorithm 1)
def knot_forcing_inference(
model, # AR diffusion model G_theta
x_ref, # Reference image
M, # Total number of frames to generate
c=3, # Chunk size
L=6, # Local window length
k=1, # Temporal knot length
s=1, # Running ahead interleave step
timesteps=None # Noise schedule: {t_0=0, t_1, ..., t_T=1000}, T=4
):
T = len(timesteps) - 1 # Denoising steps (=4)
# ---- Initialization ----
X_output = [] # Line 1: model output
KV_pre = [] # Line 2: prefix KV cache
KV_ref = model.compute_kv(x_ref, rope_index=0) # Line 3: ref KV cache
temporal_knot = None # Line 4: temporal knot x
n = 0 # RoPE index for ref
i = 0
while i < M: # Line 5
# ==== Running Ahead: 动态更新 ref RoPE ====
if i + c + 1 > n: # Line 6
n = n + s # Line 7
KV_ref = model.compute_kv(x_ref, rope_index=n) # Line 8: re-cache ref
# ==== Initialize noise ====
x_noisy = torch.randn(c + k + 1, C, H, W) # Line 10: ~ N(0, I)
# ==== Multi-step Denoising ====
for j in range(T, 0, -1): # Line 11
t_j = timesteps[j]
# DiT forward: predict clean frames
x_hat = model(x_noisy, t_j, KV_pre=KV_pre, KV_ref=KV_ref) # Line 12
if j == 1: # Line 13: final step
# ---- Update Temporal Knot ----
if i > 0 and temporal_knot is not None:
# Fused Prediction: average knot region
x_hat[:k] = (x_hat[:k] + temporal_knot) / 2.0 # Line 15
# Save chunk output
x_clean = x_hat[:c] # Line 17
X_output.extend(x_clean) # Line 18
# Save new knot for next chunk
temporal_knot = x_hat[c:c + k].clone()
# Update prefix KV cache (for sliding window)
KV_pre = model.compute_kv( # Line 19
X_output[-(2 * c + k):],
t=0, KV_pre=KV_pre, KV_ref=KV_ref
)
else: # Line 20
# Intermediate step: forward diffuse to next noise level
epsilon = torch.randn_like(x_hat) # Line 21
x_noisy = forward_diffuse(x_hat, epsilon, timesteps[j - 1]) # Line 22
i += c # Line 25
return X_output3.5 Training Pipeline
训练分两阶段:
-
Stage 1 - Bidirectional base model finetuning:
- 基于 Wan2.1-T2V-1.3B,加入 mask inpainting module
- 在 70k portrait video 数据集上 finetune,学习 reference-based signal-driven video generation
- 训练时随机 expose reference image 和 past frames(通过 mask),学习在各种条件下重建目标身份
- 推理时仅 reference image 可见
-
Stage 2 - Causal distillation (Self Forcing):
- 使用 Self Forcing 方法,将 bidirectional teacher distill 为 4-step causal AR model
- 使用 DMD (Distribution Matching Distillation) loss 最小化 KL divergence
- 训练时直接用模型自身生成的视频作为训练数据 (),消除 train-inference gap
- 训练时将最后一帧作为 global context(为 running ahead 做准备)
3.6 Code Mapping
| Paper Component | 对应实现 |
|---|---|
| Base Model | Wan2.1-T2V-1.3B DiT architecture |
| ID Injection | Video VAE encode reference → concat along temporal dim + masked inpainting |
| Driving Signal Injection | Cross-attention layers after selected DiT blocks |
| Sliding Window Attention | Causal DiT with fixed window length L=6 |
| Temporal Knot | Overlap k=1 frames between chunks, I2V bridge conditioning, fused prediction (avg) |
| Global Context Running Ahead | Dynamic RoPE index update for reference KV cache, interleave s |
| Distillation | Self Forcing + DMD loss, 4-step schedule |
| 注 | 截至目前,官方代码未正式开源;代码可能发布在 HumanAIGC |
4. Experimental Setup (实验设置)
4.1 Implementation Details
| Setting | Value |
|---|---|
| Base Model | Wan2.1-T2V-1.3B |
| Training Data | 70k portrait videos |
| Distillation | Self Forcing + DMD loss |
| Denoising Steps T | 4 (distilled from bidirectional teacher) |
| Chunk Size c | 3 frames |
| Local Window Length L | 6 frames |
| Temporal Knot Length k | 1 frame |
| Running Ahead Interleave s | configurable |
| Resolution | 832 x 480 |
| Throughput | 17.50 FPS (real-time on consumer GPU) |
4.2 Evaluation Protocol
- 评估基准:VBench quality metrics,300 条 portrait-related prompts (from MovieGen)
- 评估维度:Temporal Flickering, Subject Consistency, Background Consistency, Aesthetic Quality, Imaging Quality, Throughput (FPS)
- 对比方法:
- AR Portrait Animation:MIDAS (multimodal AR, discrete tokens), TalkingMachines (CausVid-based, Wan2.1-14B)
- Causal Video Diffusion:CausVid, Self Forcing, Rolling Forcing, LongLive
5. Experimental Results (实验结果)
5.1 Quantitative Comparison (VBench)
| Model | FPS | Temporal Flickering | Subject Consistency | Background Consistency | Aesthetic Quality | Imaging Quality |
|---|---|---|---|---|---|---|
| CausVid | 15.38 | 96.02 | 86.20 | 88.15 | 58.93 | 65.50 |
| Self Forcing | 15.38 | 97.23 | 84.97 | 89.47 | 57.74 | 66.21 |
| Rolling Forcing | 15.79 | 96.91 | 90.89 | 93.01 | 63.11 | 70.53 |
| LongLive | 20.70 | 97.82 | 91.80 | 93.42 | 62.56 | 72.01 |
| Knot Forcing (Ours) | 17.50 | 98.50 | 94.05 | 96.26 | 63.09 | 74.96 |
关键发现:
- Temporal Flickering 98.50 (vs. LongLive 97.82):Temporal Knot 有效消除了 chunk 边界的 flickering
- Subject Consistency 94.05 (vs. LongLive 91.80, +2.25):Running Ahead 持续校正 identity drift
- Background Consistency 96.26 (显著领先所有 baseline, +2.84):全局 context 维护极为有效
- Imaging Quality 74.96 (vs. LongLive 72.01, +2.95):整体生成质量大幅提升
- FPS 17.50,略低于 LongLive 20.70(因额外 denoise k=1 knot frames),但仍满足 real-time 要求
5.2 Long-term Portrait Animation

Figure 6 解读:展示了 Knot Forcing 在无限长 portrait animation 上的效果(5s → 10s → 30s → 1min → 3min)。关键观察:(1) 即使生成 3 分钟,面部身份、肤色、发型都保持高度一致,没有 identity drift;(2) 运动自然流畅,没有 error accumulation 导致的 structural degradation。Temporal Knot 成功桥接了 chunk 间的时序断裂,Running Ahead 纠正了长期 temporal drift。
5.3 与 Streaming Portrait Animation 方法对比

Figure 7 解读:与 MIDAS 和 TalkingMachines 对比(phonemes 标注在帧下方)。MIDAS 将 frames 分解为 discrete tokens 与其他 modality 混合,导致 texture fidelity 和 temporal coherence 较差(红色框标注 artifact)。TalkingMachines 基于 Wan2.1-14B,visual stability 和 ID consistency 较好。Knot Forcing 在 显著更低的计算成本 (1.3B vs 14B) 下达到了 comparable performance。
5.4 与 Causal Video Diffusion 方法对比

Figure 8 解读:与 Rolling Forcing 和 LongLive 对比。Top row 为 baseline 结果,bottom row 为 Knot Forcing。两种 baseline 虽然采用 attention sink 来缓解 error accumulation,但仍出现 color drifting、identity shift、local distortion。Knot Forcing 生成结果更稳定,保持了 structural integrity,无 liquefaction 现象。原因:(1) Temporal Knot 增强 inter-frame temporal coherence,更好地模拟 bidirectional teacher 的 generation distribution;(2) Running Ahead 提供稳定的 semantic target,防止 overall visual drifting。
5.5 Ablation Study

Figure 9 解读:逐步添加三个组件的消融实验(从 (a) 到 (c)):
- (a) 仅 Sliding Window + Global Context(无 Temporal Knot,无 Running Ahead):模型倾向于简单复制 reference image pattern,当目标 motion 显著偏离 reference 时,生成质量退化,出现明显的 motion jump
- (b) + Temporal Knot:chunk 间的 semantic discontinuity 被缓解,帧间 contextual coherence 增强,但长时间生成后仍然 逐渐偏离全局语义(最后一列可见明显 semantic deviation)
- (c) + Global Context Running Ahead(完整方案):模型在保持 inter-frame continuity 的同时,始终沿着正确的 semantic trajectory 生成,有效防止了 visual drift
结论:三个组件缺一不可,各自解决不同层次的问题。
5.6 Key Takeaways
- Attention context 跳变是 causal AR video diffusion 的核心问题:Temporal Knot 通过重叠 denoise + fused prediction 提供了优雅的解决方案,额外开销仅为 k=1 帧
- Reference image 的 temporal position 应该是动态的:Running Ahead 让 reference 始终扮演”未来目标”角色,利用 RoPE 的位置编码特性实现零参数开销的 drift 抑制
- 仅用 1.3B 参数 的模型即可实现 17.5 FPS 的实时 portrait animation,且质量全面超越同类方法
- Hinge-style latent propagation 的设计理念值得借鉴:通过 local bidirectional awareness + boundary knot bridging 来近似 full-sequence bidirectional modeling
- 未来可扩展到 world model 和 game environment simulation 等更通用的可控生成任务