Astra: General Interactive World Model with Autoregressive Denoising

Figure 1 解读:Astra teaser 图,展示 Astra 在三类场景下的交互式世界模拟能力——(a) World exploration:给定初始街景 / 森林图 + WASD 或方向键 action 流,生成长时序的真实探索视频;(b) Manipulation video prediction:给定机器人抓取台面场景 + 机器人手臂 action,生成精细的物体操控预测视频;(c) Autonomous driving:给定车前雨天街景 + 离散 action(左转、前进等),生成真实驾驶 rollout。图中每格左上角的 WASD/方向键 icon 表示当前时刻的 action 输入,可以看到生成视频的视角/场景变化完全对齐 action 指令。这张 teaser 强调 Astra 作为 general 世界模型,一个 checkpoint 覆盖多种任务、多种 action 模态。
1. Motivation (研究动机)
现有方法的问题
- 主流 T2V/I2V 扩散模型(Sora、Wan、CogVideoX 等)只能生成短、自包含的视频片段,无法根据 agent 动作、视角变化等外部信号即时响应并产出长时序、一致的 rollout。缺乏这种交互性,它们无法模拟现实世界的因果动力学。
- 已有结合 autoregression + diffusion 的混合框架(StreamingT2V、MAGI、Matrix-Game、YUME)试图延长视频时长,但仍面临两个核心矛盾:
- 长程一致性 vs 动作响应性的权衡:扩展历史条件窗口虽能改善时序一致性,却会降低对动作的响应,作者称之为 visual inertia(视觉惯性)。这是因为真实世界数据主要包含平滑运动,模型倾向于从历史中外推而忽略动作输入。
- 错误累积(error accumulation):自回归 rollout 中前一步的预测误差会逐步放大,导致长视频质量退化。
- 真实交互环境涉及异构动作模态(摄像机位姿、身体姿态、机器人末端执行器、键盘鼠标指令等),单一条件机制很难同时覆盖。
本文目标
构建一个能同时处理多种动作模态、支持长时序一致 rollout、并且对动作即时响应的 通用交互式世界模型(general interactive world model),使其成为面向自动驾驶、机器人、具身智能和沉浸式视频模拟的通用基座。
为什么值得研究
- 世界模型是具身智能、仿真环境、长时序规划与策略学习的关键基础设施。
- 大规模预训练视频扩散模型已隐式习得了 3D 感知、时序依赖和简单物理规律,但尚未被完整利用到具有交互性的世界模拟任务上;如何最小代价地”改造”预训练扩散骨干成为了关键问题。
2. Idea (核心思想)
一句话核心洞察:在保留预训练视频扩散模型高保真生成能力的前提下,通过轻量 action-aware adapter 将自回归去噪(autoregressive denoising)范式、noise-as-mask 的历史记忆和Mixture of Action Experts (MoAE) 结合起来,实现一次训练覆盖多模态动作输入与长时序一致的交互式视频预测。
三个关键创新
- ACT-Adapter + 自回归去噪:冻结 Wan-2.1 DiT 主干大部分权重,仅在每个 self-attention 块后插入一个 identity 初始化的线性层(adapter),并通过 element-wise 加法将 action features 注入 latent 空间,使动作直接影响去噪过程。
- Noise-as-Mask 历史记忆:训练时对历史 clean latent 注入一定强度的噪声,强制模型不能简单复制历史帧,而必须整合动作信号。推理时直接用干净历史。配合 FramePack 式的首帧保留 + 中间帧压缩,延长有效历史跨度。
- Mixture of Action Experts (MoAE):各模态(camera pose、robot pose、keyboard/mouse)通过模态特定的 projector 投影到统一空间,再由 router 路由到专门的 expert MLP,聚合后得到统一 action embedding。
和现有方法的根本差异
- 相较于 Matrix-Game 用 cross-attention 注入 action,本文 ACT-Adapter 直接在 latent 空间做加法变换,类似 optical flow 思想,参数更少(366.8M vs 1.8B)、对预训练破坏更小。
- 相较于 Yume 用随机 masking 视觉 token,本文 noise-as-mask 不需改结构、不增加参数,且训练/推理天然解耦(推理可用干净历史)。
- 相较于 CameraCtrl / NVM 等专用世界模型,本文通过 MoAE 统一多模态动作输入,实现跨域(自动驾驶 / 机器人 / 探索 / 多视角相机)的一个 checkpoint。
3. Method (方法)
3.1 整体框架
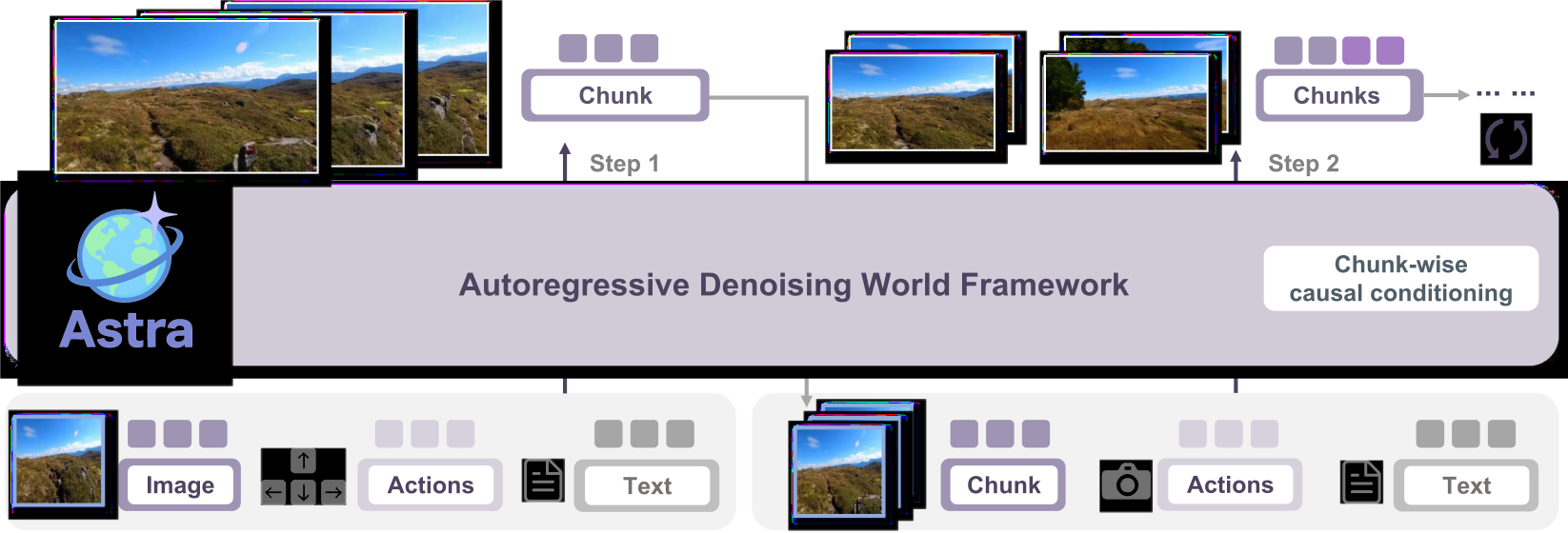
Figure 2 解读:Astra 自回归去噪世界框架的高层视图。Step 1:以 Image + Actions + Text 作为输入,生成第一个视频 chunk;Step 2:把前一步生成的 Chunk 连同新的 Actions + Text 一起送入框架,生成下一个 Chunk。“Chunk-wise causal conditioning”(图右上标注)意味着每个 chunk 的生成只依赖历史 chunk 和当前/历史的动作——严格遵循因果时序。这张图说明 Astra 是 chunk-by-chunk 滚动生成,而非一次性生成长视频,从而支持任意长度的 rollout 与即时动作响应。
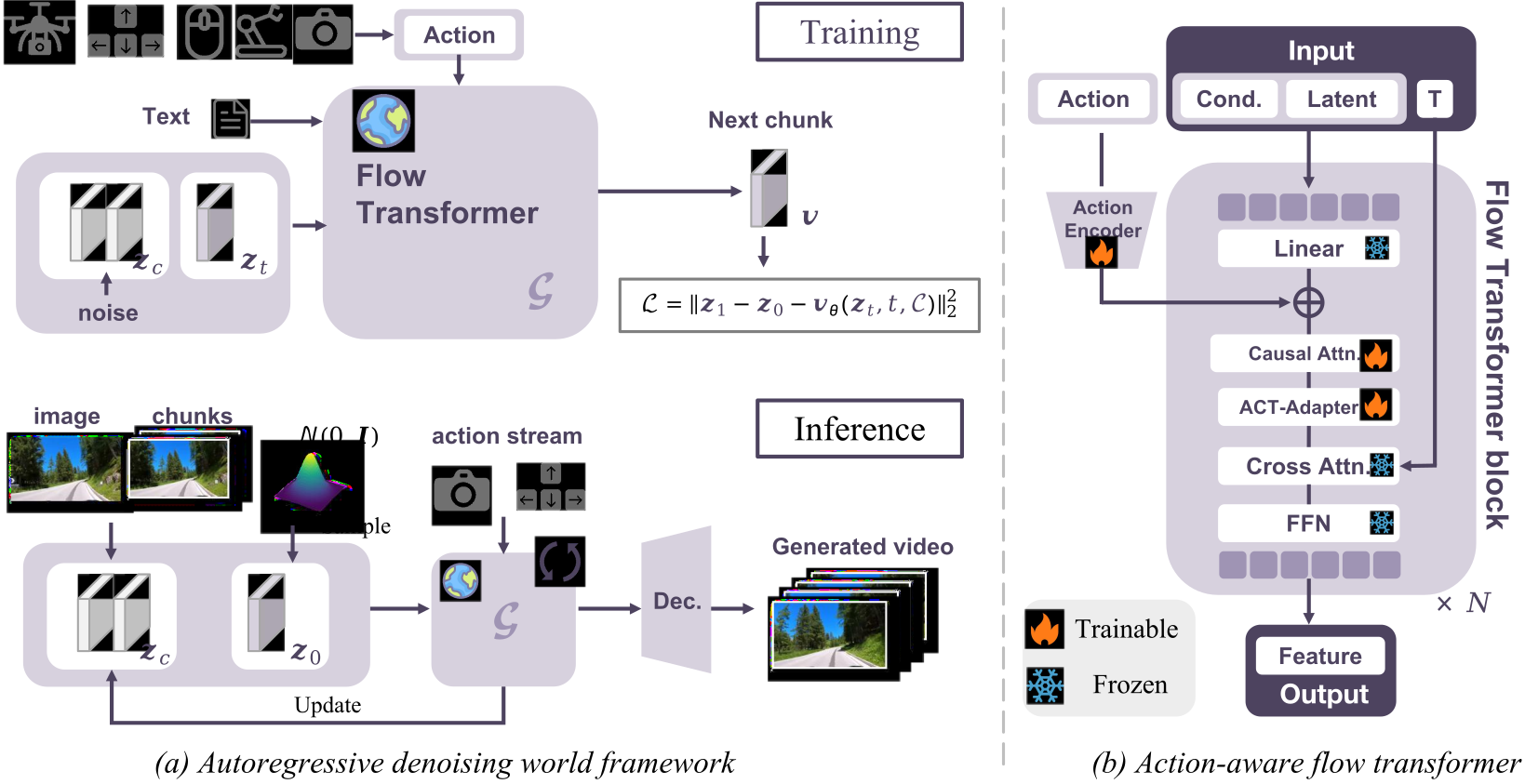
Figure 3 解读:左侧展示 Astra 的自回归去噪世界框架。训练(左上)时,给定条件历史 、动作 、文本 ,模型学习预测下一 chunk 到 方向的 flow velocity,损失为 flow-matching 平方误差 。推理(左下)时,给定图像、action stream 和历史 chunk,模型自回归地逐 chunk 生成新 latent,由 VAE Decoder 解码成视频,并把新生成的 chunk 反馈回 用作下一次预测的历史。右侧展示 Action-Aware Flow Transformer(AFT)单个 block 的结构:action 经过 Action Encoder 得到 action feature;Cond. + Latent + T 通过 Linear 组合输入 Causal Attention;紧跟一层 ACT-Adapter(trainable 火焰图标)对 self-attention 输出做线性变换,再经过 Cross Attention(与 text context 交互)和 FFN。全图颜色标记:橙色火焰为可训练(Linear、Causal Attn、ACT-Adapter、Action Encoder),蓝色雪花为冻结(Cross Attn、FFN、Input 编码)。堆叠 个这样的 block 组成完整 DiT。
3.2 前置:自回归去噪范式(Autoregressive Denoising)
给定视频序列切成 chunk 序列 ,生成目标被因式分解为:
每步下一 chunk 通过 flow matching 去噪:先采样噪声插值 ,,然后训练 flow 模型 估计 clean direction:
推理时从纯噪声去噪到 ,然后追加到历史中再预测下一 chunk,形成 AR–denoising 循环。
3.3 ACT-Adapter:action 注入机制
设计出发点:作者借鉴 optical flow 的思想,把动作看作视频特征的一个”shift”——在扩散模型中就是对 latent 的变换。因此,他们把 action 作为额外条件信号,直接作用在 denoiser 的 latent feature 上。
具体做法(见 Figure 3 右):
- Action Encoder(一个模态特定的 MLP)把 action 投影到与 video latent 对齐的特征空间;
- Action feature 通过 element-wise 加法 注入到每个 transformer block 的输入;
- 每个 self-attention 之后插入一个 linear adapter(单层 Linear),初始化为单位矩阵(identity)并与 self-attention 参数一起联合微调;
- 其他所有参数(FFN、Cross-attn)全部冻结,最大化利用预训练先验。
全条件集合:,其中 是历史 chunk、 是动作序列、 是文本 prompt。
历史条件策略:frame-dimension 拼接——把历史 chunk 沿时间维度拼到 predicted chunk 前面,一起送进 flow transformer 处理(即历史帧作为前缀)。
3.4 Action-Free Guidance (AFG)
受 Classifier-Free Guidance (CFG) 启发,作者在训练时以一定概率随机 drop 动作条件(代码中 camera_dropout_prob = 0.05),让模型学会在无 action 情况下也能预测;推理时用下式合成引导后的速度场:
其中 是 guidance scale(论文 appendix 中设 ), 表示 null-action(代码中用全零 camera embedding 实现)。这样放大了 action 的影响,使响应更精准。
3.5 Noise-Augmented History Memory(noise-as-mask)
动机:实验发现增长历史窗口长度能提高视觉一致性但严重损害 action 响应(即 visual inertia)。Figure C 直观说明了这个权衡:
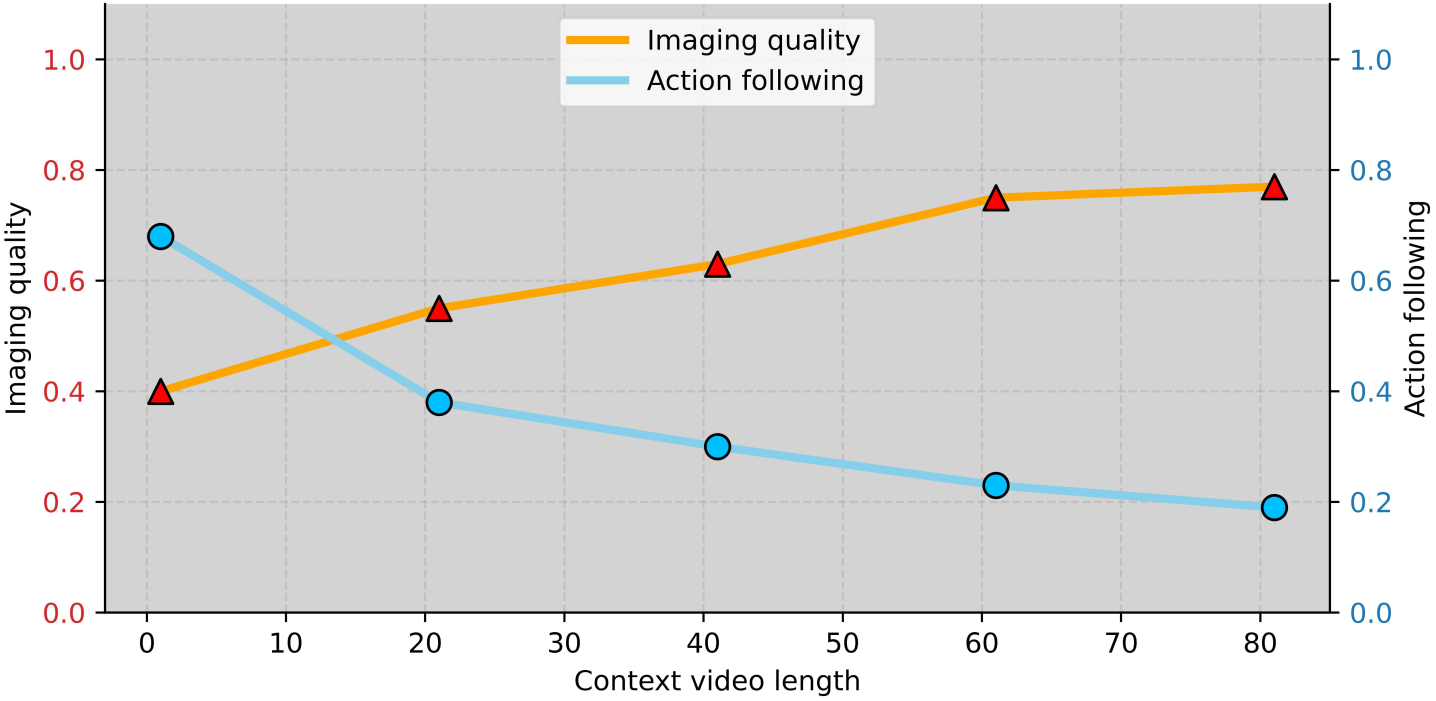
Figure C 解读:横轴是 context video length(历史视频长度,单位帧),左纵轴(橙色 Imaging quality)、右纵轴(天蓝色 Action following)分别是两个指标。随着上下文从 1 增加到 81,imaging quality 从约 0.4 稳步上升到 0.77,而 action following 从约 0.68 急剧下降到 0.20。两条曲线呈相反方向,直观显示了”视觉惯性”——越长的历史越让模型依赖视觉外推、忽视动作。
解决方案:在训练时对历史条件 latent 注入独立噪声(noise-as-mask),从而”模糊”历史的信息量,逼迫模型关注动作。代码中以 80% 的概率对 clean_latents 调用 scheduler.add_noise(clean_latents, noise_cond, timestep_cond),其中 timestep_cond 从 均匀采样。两大优势:
- 无需架构改动:不增加任何可学参数。
- 训练/推理解耦:corruption noise 与 diffusion noise 独立,推理时直接用干净历史即可,不引入额外开销。
3.6 FramePack 多尺度历史压缩
为了延长有效历史跨度但不让历史淹没动作信号,Astra 沿用 FramePack (Zhang & Agrawala, 2025) 的多尺度 input packing 技巧:
- 1x 尺度(原始分辨率):保留最近的若干历史帧;
- 2x 尺度(压缩):更早的中间历史帧以 2x 时空压缩进 latent;
- 4x 尺度(强压缩):最远的历史用 4x 压缩,只保留粗略时序锚点。
训练/推理时三种尺度的历史 latent 都会一并作为 condition 传入 DiT,通过独立的 3D Conv embedder 映射到主 latent 维度,与噪声 latent 拼接后送入自回归去噪网络。CleanXEmbedder 为此专门提供了 3 个不同 kernel/stride 的 nn.Conv3d:
代码位置:train_single.py L853-876(add_framepack_components → CleanXEmbedder)。
class CleanXEmbedder(nn.Module):
"""3 embedders for clean history latents at different compression scales."""
def __init__(self, inner_dim):
super().__init__()
self.proj = nn.Conv3d(16, inner_dim, kernel_size=(1, 2, 2), stride=(1, 2, 2)) # 1x (每帧 2x2 patch)
self.proj_2x = nn.Conv3d(16, inner_dim, kernel_size=(2, 4, 4), stride=(2, 4, 4)) # 2x (2 帧 4x4 patch)
self.proj_4x = nn.Conv3d(16, inner_dim, kernel_size=(4, 8, 8), stride=(4, 8, 8)) # 4x (4 帧 8x8 patch)
def forward(self, x, scale="1x"):
if scale == "1x":
return self.proj(x)
elif scale == "2x":
return self.proj_2x(x)
elif scale == "4x":
return self.proj_4x(x)
raise ValueError(f"Unsupported scale: {scale}")
def add_framepack_components(self):
"""Attach CleanXEmbedder to pretrained DiT if not present.
Method of `MultiDatasetLightningModelForTrain`; `self.pipe.dit` is the DiT.
"""
if not hasattr(self.pipe.dit, "clean_x_embedder"):
inner_dim = self.pipe.dit.blocks[0].self_attn.q.weight.shape[0]
self.pipe.dit.clean_x_embedder = CleanXEmbedder(inner_dim)训练 batch 中除 clean_latents(1x)之外,还会提供 clean_latents_2x、clean_latents_4x 以及三组对应的 *_indices(见伪代码 (b) 的入参),供 DiT 在做 causal-attention 时恢复位置信息。这种多尺度设计让 Astra 能”记得”很远的历史场景却只付出少量 token 的代价,直接缓解自回归 rollout 的错误累积。
3.7 Mixture of Action Experts (MoAE)
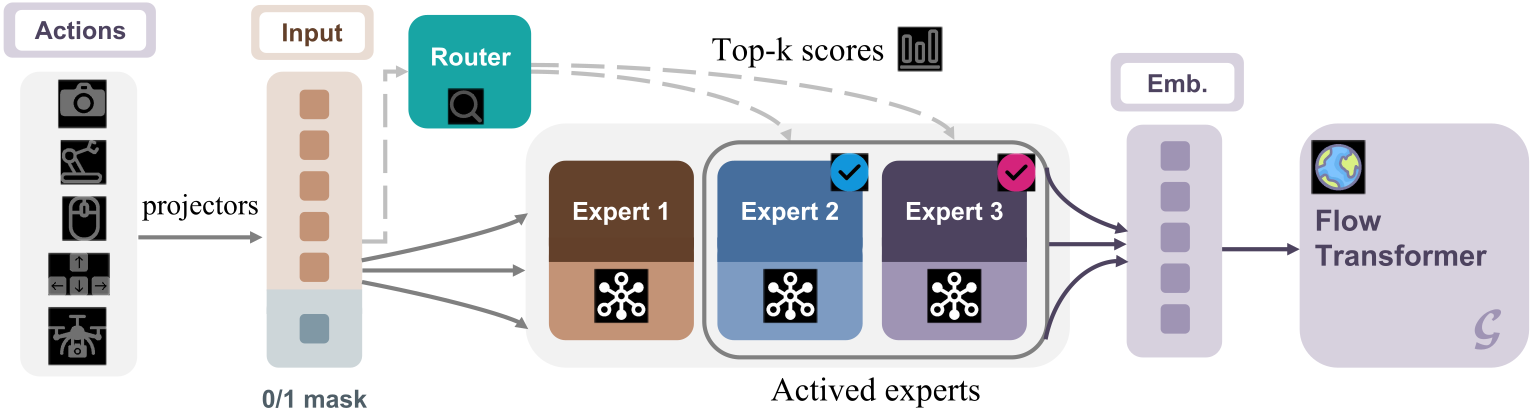
Figure 4 解读:左侧 “Actions” 列出各种输入动作的 icon(相机、机器人手臂、鼠标、键盘等);“Input” 列是把所有模态 projector 处理后的统一 embedding + 一位 0/1 mask 指示”历史 / 当前”。“Router” 对 Input 计算 gating 分数,产生 Top-k scores 并选中 top-k 个 Expert(图中示意了 Expert 2、Expert 3 被激活,Expert 1 未激活)。激活的 Expert 是 MLP,他们的输出按 gating 权重加权得到最终的 action embedding “Emb.”,再输入到右侧的 Flow Transformer(Astra denoiser) 。
数学形式:
- 模态对齐:,, 是模态特定的投影器(Linear)。
- Router 打分:,选 top-K。
- 专家聚合:,其中 是 MLP 专家。
- 历史/当前标志:给 增加一位二值指示符(past=0, current=1)。
- 得到的 送入 flow transformer。
MoAE 的作用:
- 模态专精化(每个 expert 专门处理一种 action)、
- 易扩展(新模态只需加一个 projector + expert)、
- 推理高效(只激活相关 expert)。
- 论文说 MoAE 对跨域泛化性有决定性作用——表 3 中
w/o MoAE只能在单一 camera-action 数据上训练,其他模态无法处理。
3.8 伪代码
Code reference:
main@3fb82e19(2026-02-02) — 以下所有伪代码和映射表均基于该 commit。
Astra 代码主要构建在 diffsynth/ 框架上,新增:
- 每个 DiT block 上的
projector(identity-init Linear)和cam_encoder(zero-init Linear)——在外部初始化后注入到预训练 DiT block; MultiModalMoE、ModalityProcessor、global_router——在wan_video_dit_moe.py中;- FramePack 多尺度
CleanXEmbedder——在train_single.py中; - 训练时的 noise-as-mask + 5% action dropout。
(a) ACT-Adapter 初始化与 block 前向
def attach_act_adapter_and_action_encoder(dit, dim):
"""Inject per-block ACT-Adapter and action encoder into pretrained DiT.
- projector: identity-init Linear (the ACT-Adapter).
- cam_encoder: zero-init Linear mapping 13-dim action embedding to latent dim.
"""
for block in dit.blocks:
block.cam_encoder = nn.Linear(13, dim)
block.projector = nn.Linear(dim, dim)
block.cam_encoder.weight.data.zero_()
block.cam_encoder.bias.data.zero_()
block.projector.weight = nn.Parameter(torch.eye(dim))
block.projector.bias = nn.Parameter(torch.zeros(dim))
def dit_block_forward(block, x, context, cam_emb, t_mod, freqs,
modality_inputs=None, router_weights=None, router_indices=None):
"""Single DiTBlockWithMoE forward. ACT-Adapter = `block.projector`.
Two action-injection paths, mutually exclusive:
- MoE path (default when use_moe=True and modality_inputs given):
combined modality input -> `block.moe(...)` -> add `moe_output` to input_x.
- Fallback path (no MoE): use `block.cam_encoder(cam_emb)` directly.
"""
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = \
(block.modulation + t_mod).chunk(6, dim=1)
input_x = modulate(block.norm1(x), shift_msa, scale_msa)
if block.use_moe and modality_inputs and router_weights is not None:
combined = None
active_modality = "unknown"
for mtype, processed in modality_inputs.items():
active_modality = mtype
combined = processed if combined is None else combined + processed
if combined is not None:
moe_output, _ = block.moe(combined, router_weights, router_indices, active_modality)
input_x = input_x + moe_output
elif cam_emb is not None and hasattr(block, "cam_encoder"):
input_x = input_x + block.cam_encoder(cam_emb)
attn_output = block.self_attn(input_x, freqs)
x = x + gate_msa * block.projector(attn_output)
x = x + block.cross_attn(block.norm3(x), context)
input_x = modulate(block.norm2(x), shift_mlp, scale_mlp)
x = x + gate_mlp * block.ffn(input_x)
return x(b) Noise-as-Mask 训练策略
说明:下面是删减版,仅保留 noise-as-mask、camera dropout、FramePack latents、flow-matching loss 的核心逻辑;完整调用(含 prepare_extra_input、image_emb、gradient checkpointing 标志等)参见 train_single.py::training_step L883-990。
def training_step(self, batch, batch_idx):
latents = batch["latents"]
clean_latents = batch["clean_latents"] # history chunks (clean)
clean_latents_2x = batch["clean_latents_2x"] # FramePack 2x compressed
clean_latents_4x = batch["clean_latents_4x"] # FramePack 4x compressed
cam_emb = batch["camera"]
dataset_type = batch["dataset_type"][0]
modality_inputs = {dataset_type: cam_emb}
camera_dropout_prob = 0.05
if random.random() < camera_dropout_prob:
cam_emb = torch.zeros_like(cam_emb)
for key in modality_inputs:
modality_inputs[key] = torch.zeros_like(modality_inputs[key])
noise = torch.randn_like(latents)
timestep_id = torch.randint(0, self.pipe.scheduler.num_train_timesteps, (1,))
timestep = self.pipe.scheduler.timesteps[timestep_id]
noisy_condition_latents = None
if clean_latents is not None:
noisy_condition_latents = copy.deepcopy(clean_latents)
if random.random() > 0.2:
noise_cond = torch.randn_like(clean_latents)
T = self.pipe.scheduler.num_train_timesteps
timestep_id_cond = torch.randint(0, T // 4 * 3, (1,))
timestep_cond = self.pipe.scheduler.timesteps[timestep_id_cond]
noisy_condition_latents = self.pipe.scheduler.add_noise(
clean_latents, noise_cond, timestep_cond
)
noisy_latents = self.pipe.scheduler.add_noise(latents, noise, timestep)
training_target = self.pipe.scheduler.training_target(latents, noise, timestep)
noise_pred, specialization_loss = self.pipe.denoising_model()(
noisy_latents,
timestep=timestep,
cam_emb=cam_emb,
modality_inputs=modality_inputs,
latent_indices=batch["latent_indices"],
clean_latents=noisy_condition_latents if noisy_condition_latents is not None else clean_latents,
clean_latent_indices=batch["clean_latent_indices"],
clean_latents_2x=clean_latents_2x,
clean_latent_2x_indices=batch["clean_latent_2x_indices"],
clean_latents_4x=clean_latents_4x,
clean_latent_4x_indices=batch["clean_latent_4x_indices"],
context=batch["prompt_emb"],
)
loss = F.mse_loss(noise_pred.float(), training_target.float())
loss = loss * self.pipe.scheduler.training_weight(timestep)
return loss(c) Mixture of Action Experts 前向
class MultiModalMoE(nn.Module):
"""Experts-only MoE: gating weights/indices are computed by the global
router in `WanModelMoe` and passed in."""
def __init__(self, unified_dim=30, output_dim=1536, num_experts=4, top_k=2):
super().__init__()
self.unified_dim = unified_dim
self.output_dim = output_dim
self.num_experts = num_experts
self.top_k = top_k
self.modality_to_expert = {"sekai": 0, "nuscenes": 1, "openx": 2, "unknown": 0}
self.experts = nn.ModuleList([
nn.Sequential(nn.Linear(unified_dim, output_dim))
for _ in range(num_experts)
])
def forward(self, x, expert_weights, top_k_indices, modality_type="unknown"):
"""Weighted aggregation of top-k expert outputs.
x: [B, S, unified_dim] - projected action embedding
expert_weights: [B, S, top_k] - router gating scores
top_k_indices: [B, S, top_k] - indices of selected experts
"""
expert_outputs = torch.stack([e(x) for e in self.experts], dim=-2)
output = torch.zeros(x.size(0), x.size(1), self.output_dim,
device=x.device, dtype=x.dtype)
for k in range(self.top_k):
idx = top_k_indices[:, :, k]
w = expert_weights[:, :, k:k + 1]
gathered = torch.gather(
expert_outputs,
dim=2,
index=idx.unsqueeze(-1).unsqueeze(-1).expand(
-1, -1, 1, expert_outputs.size(-1)
),
).squeeze(2)
output += w * gathered
return output, {"modality_type": modality_type}
class WanModelMoe(nn.Module):
"""Top-level DiT with a global router shared across all blocks."""
def compute_router_decisions(self, combined_modality_input, modality_type):
"""Hard routing: each modality is mapped to one fixed expert.
Despite the paper describing a learnable router, the released code uses
this deterministic mapping; `global_router` weights exist but are bypassed.
"""
B, S, _ = combined_modality_input.shape
target = self.modality_to_expert.get(modality_type, 0)
router_indices = torch.full((B, S, self.top_k), target,
dtype=torch.long, device=combined_modality_input.device)
router_weights = torch.ones((B, S, self.top_k),
dtype=combined_modality_input.dtype,
device=combined_modality_input.device)
specialization_loss = torch.tensor(0.0, device=combined_modality_input.device)
return router_weights, router_indices, specialization_loss注意:虽然论文描述使用了 learnable router,代码实际发布版本里 WanModelMoe.compute_router_decisions 采用了硬路由(sekai→expert0、nuscenes→expert1、openx→expert2),可能是为了简化训练稳定性。虽然 global_router = nn.Linear(unified_dim, num_experts) 权重在 add_moe_components 中被创建(train_single.py L842),但在实际 forward 中并未被调用。
(d) Action-Free Guidance 推理
实现位置:源码中 AFG 不是独立函数,而是内联在 scripts/infer_demo.py::inference_moe_framepack_sliding_window 的去噪循环里(L1304-1340,以 use_camera_cfg 为开关)。下面的 generate_with_afg 是示意封装,便于单独展示算法逻辑;它忽略了 FramePack latent indices、clean_latents_*、**prompt_emb 等额外参数。
def generate_with_afg(pipe, latents, timestep, cam_emb, prompt_emb,
camera_guidance_scale=3.0):
"""Illustrative AFG during one denoising step — actual source is inlined
in `inference_moe_framepack_sliding_window`, see `infer_demo.py` L1304-1340.
"""
cam_uncond = torch.zeros_like(cam_emb)
noise_pred_cond, _ = pipe.dit(
latents, timestep=timestep, cam_emb=cam_emb,
modality_inputs={"sekai": cam_emb}, **prompt_emb,
)
noise_pred_uncond, _ = pipe.dit(
latents, timestep=timestep, cam_emb=cam_uncond,
modality_inputs={"sekai": cam_uncond}, **prompt_emb,
)
return noise_pred_uncond + camera_guidance_scale * (
noise_pred_cond - noise_pred_uncond
)3.9 论文概念到源码的映射
Code reference:
main@3fb82e19(2026-02-02) — 映射表基于该 commit 的文件和类名。
| 论文概念 | 源文件 | 关键类 / 函数 |
|---|---|---|
| Autoregressive denoising pipeline | train_single.py | MultiDatasetLightningModelForTrain.training_step (L883) |
| Astra 推理主循环 | scripts/infer_demo.py | inference_moe_framepack_sliding_window (L1053) |
| 自定义 DiT with MoE | diffsynth/models/wan_video_dit_moe.py | WanModelMoe (L462)、DiTBlockWithMoE (L342) |
| ACT-Adapter(identity-init linear) | train_single.py | block.projector = nn.Linear(dim, dim) + torch.eye 初始化 (L799-803) |
| Action Encoder | train_single.py | block.cam_encoder = nn.Linear(13, dim) zero-init (L798-801) |
| Modality projector () | diffsynth/models/wan_video_dit_moe.py | ModalityProcessor (L187) |
| MoAE 多专家模块 | diffsynth/models/wan_video_dit_moe.py | MultiModalMoE (L225) |
| Router(硬路由) | diffsynth/models/wan_video_dit_moe.py | WanModelMoe.compute_router_decisions (L537) |
| DiT block MoE 路径(action 注入) | diffsynth/models/wan_video_dit_moe.py | DiTBlockWithMoE.forward MoE 分支 (L387-406) |
| DiT block Fallback 路径(cam_encoder) | diffsynth/models/wan_video_dit_moe.py | DiTBlockWithMoE.forward fallback 分支 (L413-417) |
| Noise-as-Mask 历史注入 | train_single.py | noisy_condition_latents = scheduler.add_noise(...) (L950-957) |
| Training forward 主调用 | train_single.py | self.pipe.denoising_model()(...) (L963-980) |
| Action-Free Guidance (AFG) | scripts/infer_demo.py | use_camera_cfg 分支 (L1304-1340) |
| FramePack 多尺度压缩 | train_single.py | add_framepack_components + CleanXEmbedder (L853-876) |
| Flow matching loss | train_single.py | F.mse_loss(noise_pred, training_target) (L982) |
| Action dropout 5% (CFG 训练) | train_single.py | camera_dropout_prob = 0.05 (L927-932) |
| 可训练模块白名单 | train_single.py | ["cam_encoder", "projector", "self_attn", "clean_x_embedder", "moe", "sekai_processor", "nuscenes_processor", "openx_processor"] (L815-819) |
4. Experimental Setup (实验设置)
训练数据(Table 1)
| Dataset | Action (dim) | Scenario | Size |
|---|---|---|---|
| nuScenes | Camera (7) | Autonomous driving | 850 |
| Sekai | Camera (12) | Walking & drone view | 50K |
| SpatialVid | Camera (7) + keyboard/mouse | In-the-wild videos | 200K |
| RT-1 (via Open X-Embodiment) | Robotic pose (7) | Robot manipulation | 9,978 |
| Multi-Cam Video | Camera (12) | Human motion | 136K |
| Total | — | — | ~397K clips (360 hours) |
- 所有视频 resize & crop 到 480×832;
- action annotations 以 4 帧为单位插值,匹配视频 VAE 的时间压缩比;
- 训练时从像素空间随机采样
[1, 128]帧作为 condition,target frames 固定 33; - 评测用 Astra-Bench:每个数据集留出 20 个样本共 100 个。
- 附加评测:CityWalker(100 个场景图像 + 未来 action 轨迹,用于 OOD 泛化性)。
训练配置
- Backbone: Wan-2.1 T2V 1.3B(30 层 DiT block);
- GPU: 8×A100/H100 80G,per-GPU batch size 1;
- Optimizer: AdamW, lr = 1e-5;
- Epochs: 30, ≈ 24 hours 训练收敛;
- 可训练参数:ACT-Adapter + self-attn + MoAE + clean_x_embedder(共 366.8M),其他权重冻结;
- Precision: bf16 混合精度;
- Lightning DDP +
ddp_find_unused_parameters_true策略; - 推理 AFG scale 。
评测指标
- VBench 子指标:Subject Consistency、Background Consistency、Motion Smoothness、Aesthetic Quality、Imaging Quality。
- Instruction Following:找 20 位人类标注员主观评估生成视频是否正确响应 action(方向、动作类型),给出同意比例。
- Action Alignment(Table A):用 MegaSaM 估计生成视频的相机位姿,计算 RotErr / TransErr。
- 所有测试视频统一设置:480×832 分辨率、20 FPS、96 帧、50 步 inference。
基线:Wan-2.1(纯 T2V)、MatrixGame-2.0(He et al., 2025, 基于 Wan2.1-1.3B 的 game 世界模型,cross-attn adapter)、YUME(Mao et al., 2025, 基于 Wan2.1-14B 的 walking 世界模型)、NWM(Bar et al., 2025, navigation 专用 CDiT)。
5. Experimental Results (实验结果)
5.1 主表(Table 2,Astra-Bench)
| Method | Instruction Following ↑ | Subject Cons. ↑ | BG Cons. ↑ | Motion Smooth. ↑ | Aesthetic ↑ | Imaging ↑ |
|---|---|---|---|---|---|---|
| Wan-2.1 | 0.061 | 0.854 | 0.903 | 0.958 | 0.489 | 0.691 |
| MatrixGame | 0.268 | 0.916 | 0.928 | 0.981 | 0.441 | 0.748 |
| YUME | 0.652 | 0.936 | 0.938 | 0.985 | 0.523 | 0.741 |
| Astra (Ours) | 0.669 | 0.939 | 0.945 | 0.989 | 0.531 | 0.747 |
Astra 在 6 项指标中的 5 项(Instruction Following、Subject Cons.、BG Cons.、Motion Smooth.、Aesthetic) 均取得最好,其中 instruction following 比 YUME 高 +0.017、比 MatrixGame 高 +0.401;Imaging Quality 仅落后 MatrixGame 0.001(0.747 vs 0.748),视觉保真度基本持平。
5.2 Action Alignment(Table A,MegaSaM 评估)
| Method | RotErr ↓ | TransErr ↓ | Instruction Following ↑ | Imaging Quality ↑ |
|---|---|---|---|---|
| Wan-2.1 | 2.96 | 7.37 | 0.061 | 0.691 |
| YUME | 2.20 | 5.80 | 0.268 | 0.741 |
| MatrixGame | 2.25 | 5.63 | 0.652 | 0.748 |
| NWM | 2.47 | 6.13 | 0.311 | 0.635 |
| Astra | 1.23 | 4.86 | 0.669 | 0.747 |
Astra 在相机位姿对齐误差上比次优基线 YUME 下降约 44%(旋转)和 16%(平移),证明其 action 响应非常精确。
⚠️ 关于 Table 2 vs Table A 的数值说明:论文原文中 Table 2 给出的 Instruction Following 为 YUME = 0.652、MatrixGame = 0.268,而 Table A 给出的是 YUME = 0.268、MatrixGame = 0.652——两表在这两行上互相颠倒。本笔记 5.1/5.2 均严格按照论文原文照录,不做修改。从 NWM(只出现在 Table A)和其他一致的条目看,两表属于同一评测集、同一指标,疑似论文排版错误。Astra 自身数值在两表中一致(均为 0.669),故 Astra 的结论不受影响;对 YUME/MatrixGame 的相对排名建议以官方后续勘误为准。
5.3 定性比较

Figure 5 解读:四个真实探索场景的长时序生成。每一行:最左列(绿色边框)为输入单帧 + action(WASD 或方向键)指示;右侧 4 帧是 Astra 顺序生成的 rollout 关键帧。第 1 行(花园 + WASD 前进):视角从入口逐步推进到花丛深处,前景花卉从左侧景切换到中央;第 2 行(雨后街道):透视随 W 前进,远处建筑慢慢接近;第 3 行(山路 + 方向键):随着 action 执行,路径弯曲和远山视角同步更新;第 4 行(河畔街道):右转后视野切换到桥梁结构。整体说明 Astra 在高视觉保真度、时序一致性和精准动作响应三个维度都表现出色。

Figure 6 解读:四行分别是四个测试场景。第一列是输入图像(带 WASD / 方向键标志指示 action),接下来四列分别是 Wan-2.1、Matrix-Game、YUME、Ours(Astra)的生成结果。可以看到:Wan-2.1 完全不响应 action,生成的内容与输入几乎脱节(例如第 3 行右转命令下生成了行人);Matrix-Game 保留了主体但构图单调、细节模糊(如第 1、4 行远处的大片植被);YUME 结果相对较好但仍然在复杂结构(桥、楼房)上出现不一致;Astra(最右)在动作执行精度(视角变化符合 WASD/方向键)、场景一致性(保持输入的街景、桥面结构等)、视觉质量(细节清晰)三方面都明显优于其他基线。
5.4 Ablation(Table 3)
| Method | Inst. Follow. ↑ | Subj. C. ↑ | BG C. ↑ | Motion ↑ | Aes. ↑ | Img. ↑ |
|---|---|---|---|---|---|---|
| w/o AFG | 0.545 | 0.841 | 0.892 | 0.957 | 0.492 | 0.703 |
| w/o noise | 0.359 | 0.903 | 0.927 | 0.979 | 0.523 | 0.739 |
| cross attn. adapter(替换 ACT-Adapter) | 0.642 | 0.926 | 0.903 | 0.948 | 0.512 | 0.694 |
| w/o MoAE(仅 camera 数据) | 0.651 | 0.930 | 0.941 | 0.975 | 0.520 | 0.727 |
| Astra (Full) | 0.669 | 0.939 | 0.945 | 0.989 | 0.531 | 0.747 |
关键发现:
- w/o noise 是最致命的消融(Instruction Following 从 0.669 掉到 0.359,-46%),证明 noise-as-mask 直接解决了 visual inertia。
- w/o AFG 大幅降低所有指标,特别是 Instruction Following(-0.124),证明 action-free guidance 是增强可控性的重要推理阶段机制。
- cross-attn adapter(对应 Matrix-Game 的方式)在 BG 一致性和 Imaging 上反而下降(BG C. -0.042),说明 ACT-Adapter 更好地保留了预训练生成能力。
- w/o MoAE 虽仅在 camera 数据上训练但也略差,更重要的是它没法处理其他模态——MoAE 是多模态通用性的关键。
5.5 参数量对比(Table B)
| Method | Base Model | Trainable Params | Notes |
|---|---|---|---|
| NWM | CDiT-XL | ~1B | Full tuning |
| YUME | Wan2.1-14B | ~14B | Full tuning |
| MatrixGame | Wan2.1-1.3B | ~1.8B | Full tuning + cross-attn adapter |
| Astra (Ours) | Wan2.1-1.3B | 366.8M | 仅调 adapter + self-attn |
Astra 以不到 YUME 3% 的参数量取得更好性能。
5.6 长视频 / CityWalker 泛化(Table D)
在 CityWalker 100 个未见场景上同样 Astra 领先(Instruction Following 0.641 vs YUME 0.619 vs MatrixGame 0.247),证明性能不是小测试集的伪造。
5.7 Out-of-Distribution 泛化

Figure A 解读:四行 OOD 场景——第 1 行是 indoor living room(训练未见的室内环境);第 2 行是 Minecraft 沙盒游戏(像素化渲染风格);第 3、4 行是同一张动漫风格日落图在两个不同复杂 action 序列下的生成结果。第 1 列为输入图像(含 action 标志,用绿色边框凸显),后 4 列是逐步生成的 frame。可以看到模型在完全不同的纹理与美学风格下都能正确执行 action(例如第 1 行 W 前进后视角逐渐进入房间;Minecraft 行 W 向前移动伴随视野切换新地块),并保持全局结构一致,说明 Astra 的三大组件都有良好的 OOD 迁移性。
5.8 扩展应用

Figure 7 解读:三个领域的扩展应用。(a) Autonomous driving:两行 nuScenes 场景,给定雾霾 / 雨天的驾驶起始帧与前进 action,生成数秒后的连续驾驶画面,路面、防护栏、远山都保持合理;(b) Manipulation video prediction:RT-1 的机器人抓取场景,机器手按照 action 逐步伸向目标物体,展示了物体操控的细粒度时序;(c) Camera control:电影式镜头控制——舞者双人互动或台阶上的小丑特写,镜头按指令做 panning、拉近等操作,主体保持稳定。整图说明 Astra 的一套架构可以覆盖驾驶、机器人、影视镜头三大差异巨大的域。

Figure 8 解读:Astra 在多智能体场景下的表现。给定一张前方两辆车的第一视角驾驶图(左绿框,WASD 表示 ego-car 的 action),Astra 生成了四帧后续画面——ego-car 逐步超越前车,同时白色前车的位置和视角变化都符合物理直觉(被超车后出现在 ego-car 的右后方),再经过一帧调整回归到稳定主路。这体现 autoregressive denoising + noise-augmented memory + MoAE 三者组合,使多智能体交互下仍保持动作响应和视觉一致。
模型天然适用于多种应用场景:
- Autonomous driving(nuScenes):给 ego 观测 + 离散 action(左转/前进),生成真实可交互驾驶视频;
- Manipulation prediction(RT-1):给当前画面 + 机器人 action,预测抓取、工具使用等细粒度视频;
- Camera control:根据 panning / zooming / rotation 指令生成对应运动;
- Multi-agent interaction(Figure 8):第一人称驾驶超车,其他车辆被真实模拟。
5.9 Limitations
- 推理效率:基于 diffusion 生成 + 自回归 rollout,每帧需要多步去噪,难以在实时场景(在线控制、交互机器人)部署。未来工作可探索蒸馏、student-teacher 压缩等手段。
- 硬路由的权衡:代码中 MoAE 实际使用的是硬路由(modality_to_expert 是字典硬编码),这牺牲了 router 的动态性,可能限制对新模态的即插即用。
总体结论
Astra 展示了:用一个轻量 ACT-Adapter(每块 DiT 仅加一层 identity Linear)+ noise-as-mask 历史记忆 + MoAE 多模态专家,就能把预训练的 Wan2.1-1.3B 改造成跨域通用的交互式世界模型,在 fidelity、长程一致性、action alignment 上全面超越同类模型,同时参数量和计算代价都最小。对于构建 scalable simulator for embodied intelligence 的路线,Astra 提供了一个可行且高效的技术方案。