Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Paper: arXiv:2602.10090 / HF Papers Code: Snowflake-Labs/agent-world-model Code reference:
main@6a956c57(2026-05-01)
1. Motivation(研究动机)
现有 agentic RL 的瓶颈不是缺少策略优化算法,而是缺少可扩展、可重复、可验证的交互环境。真实业务环境难以并行采样、状态不可控;LLM-simulated environment 每一步都依赖模型补全,容易在状态转移中幻觉,且 rollout 成本高;已有 programming-based 环境通常规模小、依赖人工任务/文档,或没有 SQL 状态支撑,难以给多轮工具调用 agent 提供稳定奖励。
本文要解决的具体问题是:如何从很少的人类种子(100 个 popular domain names)出发,自动生成大量 code-driven、SQL-backed、MCP-accessible 的交互环境,并用这些环境训练能泛化到未见 benchmark 的 tool-use agent。这个问题重要在于:一旦环境可执行且状态可读,RL 不再只能依赖粗糙 outcome 或人工环境,而可以在 1,024 个隔离实例上并行采样,并用数据库前后状态构造更可靠的 reward。

Figure 1 解读:这张 teaser 强调 AWM 的三点定位:环境由代码驱动、状态由 SQL 数据库维护、最终形成 1,000 个 ready-to-use environments。它不是仅生成对话数据,而是生成可以被 agent 反复调用和 reset 的交互世界。
2. Idea(核心思想)
核心洞察:把“世界模型”从隐式的 LLM simulator 改成显式的可执行程序 + 数据库。LLM 负责合成 scenario、task、schema、tool interface、verifier;真正的状态转移由生成代码和 SQLite 数据库执行,因此 rollout 时不需要每一步都让 LLM 模拟世界。
与 EnvScaler/AutoForge 这类 programming-based 环境相比,AWM 的差异是端到端生成完整 POMDP:数据库定义状态,MCP interface 定义动作/观测/转移,verification code + LLM judge 定义 task reward;与 LLM simulation 相比,AWM 把“下一状态是什么”交给程序执行,降低了状态幻觉和采样成本。
最关键的设计不是单个 prompt,而是合成闭环:每个生成阶段都执行检查,失败后把错误反馈给 LLM 自修复;训练时再把 code verifier 的结构化证据交给 GPT-5 judge,避免纯代码检查过脆,也避免纯 LLM judge 不看数据库状态。
3. Method(方法)
3.1 POMDP 化的环境定义
每个环境 被定义为适合 agentic RL 的 POMDP:
其中 transition function 为:
在 AWM 中, 由 SQLite database 表示;、、 由 MCP interface 和生成的 server code 表示;每个 task 的 由 verifier 和 judge 提供。
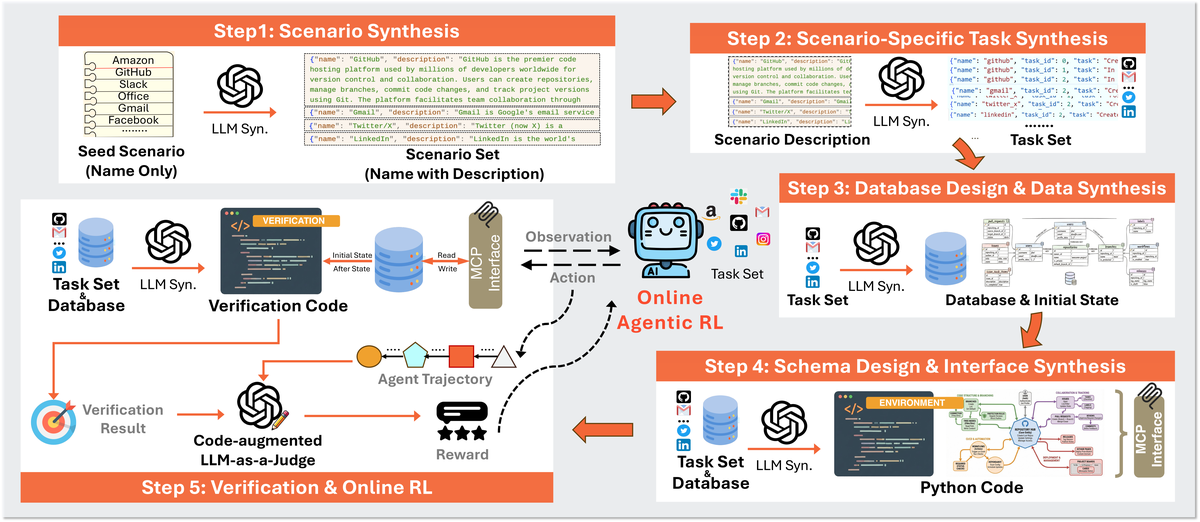
Figure 2 解读:overview 展示了从 scenario 到 task,再到 database/interface/verifier 的渐进合成过程。注意 task、database、tool interface 不是独立生成的:后一级都把前一级作为约束输入,保证任务能落到状态表和工具 API 上。
3.2 环境合成流水线
AWM 的合成阶段可以分成七步:
- Scenario generation:从 100 个热门领域名出发,筛选 stateful apps / tools collection,而不是静态信息检索网站。
- Task generation:每个 scenario 合成 10 个用户任务,要求多步工具调用、条件逻辑、状态修改或查询。
- Database schema:为任务生成 SQL schema,使任务目标有可检查的状态承载。
- Sample data:生成可插入数据库的 records,并执行插入检查。
- Interface specification:根据任务和 schema 生成最小必要 toolset schema。
- Environment code:把每个 endpoint 实现成 MCP tool,执行数据库操作并返回 observation。
- Verification synthesis:为每个任务生成 verifier,比较 initial/final database state,并产出结构化证据。

Figure 3 解读:Spotify 示例的 database view 说明 AWM 的状态不是自然语言缓存,而是可查询的关系数据库。agent 的工具调用最终会落到表的增删改查,因此 verification 可以检查具体 records 和 constraints。
论文报告合成结果为 1,000 个可执行环境和 10,000 个任务;pipeline 中 Database、Sample Data、Env Code 的成功率分别为 88.3%、88.2%、86.8%,平均自修复 trial 约 1.12/1.12/1.13。复杂度均值包括 18.5 张表、129.3 条 sample records、35.1 个 exposed tools、1,984.7 行 environment code、每任务 8.5 个 agent steps、7.1 个 unique tools。
3.3 Reward:step-level 格式约束 + task-level 结果验证
最终 task reward 定义为:
step-level reward 的逻辑是:若第 步格式非法并 early terminate,则 ;若 rollout 正常结束,则把 broadcast 到所有 action steps;否则 。这样做的直觉是,长 horizon 工具调用中,纯 outcome reward 太稀疏;先用格式 reward 把 action space 收窄,再用 database-grounded task verifier 给最终语义奖励,训练信号会更稳定。

Figure 4 解读:case1 展示 code verifier 和 LLM judge 在干净数据库证据上对齐的情形,适合由程序精确确认成功。

Figure 5 解读:case2 展示环境/工具缺陷导致 code-only verifier 可能给 false negative;AWM 用 judge 读取 trajectory 和 verifier evidence,避免把环境错误全归咎于 agent。

Figure 6 解读:case3 展示“局部看似成功但实体错了”的情况;数据库真实状态能防止 LLM-only judge 只看轨迹文本而误判。
3.4 History-aware GRPO
论文指出训练常用 full trajectory forward,而推理时 agent framework 会截断历史,导致 distribution mismatch。原始全历史损失形式为:
推理时只保留最近 轮:
AWM 在 GRPO 中按同样截断历史优化:
其中 。实现细节里,训练 sample 包含 system prompt、initial user message、第一次 list_tools assistant-tool exchange,以及 的最近历史;只在 turn 的 token 上计算 loss,其余上下文 loss mask 为 0。
3.5 源码对应与伪代码
公开仓库包含合成/执行/验证 infra;RL 训练代码在论文中说明基于 AgentFly + verl,当前 main@6a956c57 仓库未包含 GRPO launch scripts 或训练 config,因此训练超参只能锚定到论文表格,不能做源码级复现确认。
| Paper Concept | Source File | Key Class/Function | 说明 |
|---|---|---|---|
| 7-stage synthesis pipeline | awm/core/pipeline.py | run lines 39-156 | 依次调用 scenario/task/db/sample/spec/env/verifier |
| Scenario self-instruct + diversity filtering | awm/core/scenario.py | ScenarioSelfInstruct.generate_batch, check_diversity, run | 并行生成 scenario,做 suitability/diversity 检查 |
| Task synthesis | awm/core/task.py | generate_all_tasks, run | 每个 scenario 生成任务集合 |
| Database schema and SQLite creation | awm/core/db.py | create_sqlite_database, generate_all_databases | 把 schema 落成 SQLite 数据库 |
| Sample data execution check | awm/core/sample.py | execute_sample_data, generate_and_insert_sample_data | 执行 INSERT,错误率高则重试 |
| Interface spec | awm/core/spec.py | generate_all_api_specs | 生成 tool schema / endpoint specification |
| Environment MCP code generation + self-correction | awm/core/env.py | generate_all_environments, test_run_specific_env, batch_test_environments | 生成 server code,启动 MCP server 测试,失败总结错误后重试 |
| Agent rollout | awm/core/agent.py | MCPToolExecutor, run_agent, parse_tool_calls | agent 只暴露 list_tools/call_tool 两个 meta-tools |
| Verifier generation | awm/core/verifier.py | VerificationCodeGenerator.process_tasks | 为每个 task 生成 SQL/code verifier |
| Code-augmented judge | awm/core/verify.py | run_verifier, run_llm_judge, run_verify | 执行 verifier,必要时调用 LLM judge 综合轨迹和数据库证据 |
伪代码 1:AWM 端到端合成流水线(对应 awm/core/pipeline.py)
def synthesize_awm(seed_domains, output_dir, model, num_tasks=10):
scenarios = run_scenario(input_path=seed_domains,
output_path=f"{output_dir}/gen_scenario.jsonl",
model=model)
tasks = run_task(input=scenarios,
output=f"{output_dir}/gen_tasks.jsonl",
num_tasks=num_tasks,
model=model)
db_schemas = run_db(input=tasks,
output=f"{output_dir}/gen_db.jsonl",
database_dir=f"{output_dir}/databases",
model=model)
sample_rows = run_sample(input_task=tasks,
input_db=db_schemas,
output=f"{output_dir}/gen_sample.jsonl",
database_dir=f"{output_dir}/databases",
model=model)
api_specs = run_spec(input_task=tasks,
input_db=db_schemas,
output=f"{output_dir}/gen_spec.jsonl",
model=model)
env_code = run_env(input_spec=api_specs,
input_db=db_schemas,
output=f"{output_dir}/gen_envs.jsonl",
database_dir=f"{output_dir}/databases",
model=model)
verifiers = run_verifier(input_task=tasks,
output=f"{output_dir}/gen_verifier.jsonl",
database_dir=f"{output_dir}/databases",
model=model)
return scenarios, tasks, db_schemas, sample_rows, api_specs, env_code, verifiers伪代码 2:环境代码生成 + 执行式自修复(对应 awm/core/env.py)
def generate_environment_with_self_correction(api_spec_item, db_schema, client, max_retries=5):
error_history = []
last_code = None
for attempt in range(max_retries + 1):
prompt = build_environment_prompt(
api_spec=api_spec_item["api_spec"],
database_schema=db_schema,
previous_errors=error_history,
)
response = client.chat(prompt)
env_config = parse_environment_code(response)
last_code = env_config.get("full_code")
ok, output, tested_config = test_run_specific_env(env_config)
if ok:
return tested_config
summarized = summarize_errors(raw_error=output, full_code=last_code)
error_history.append({"raw_error": output, "summary": summarized})
return save_last_available_code(last_code, reason="max_retry_exceeded")伪代码 3:agent 与 MCP 环境交互(对应 awm/core/agent.py)
async def rollout_agent(task, mcp_server, llm, max_turns=20):
tools = await mcp_server.list_tools()
messages = [system_prompt_with_two_meta_tools(), {"role": "user", "content": task}]
trajectory = []
for turn in range(max_turns):
content, tool_calls = await generate_response(llm, messages)
messages.append({"role": "assistant", "content": content})
if not tool_calls:
trajectory.append({"turn": turn, "assistant": content, "tool_calls": []})
break
call = tool_calls[0] # repo 当前实现每轮只执行第一个 tool call
if call["name"] == "list_tools":
observation = format_tools_for_response(tools)
elif call["name"] == "call_tool":
tool_name, args = parse_call_tool_arguments(call["arguments"])
observation = await mcp_server.call_tool(tool_name, args)
else:
observation = f"Error: Unknown tool {call['name']}"
messages.append({"role": "tool", "content": observation, "tool_call_id": call["id"]})
trajectory.append({"turn": turn, "assistant": content, "tool_calls": [call], "observation": observation})
save_json({"task": task, "trajectory": trajectory, "messages": messages}, "trajectory.json")
save_database_snapshot("final.db")
return trajectory伪代码 4:code-augmented reward 与 history-aware GRPO(verification 来自源码,GRPO 来自论文公式)
import torch
async def compute_task_reward(task, trajectory, initial_db, final_db, verifier_entry, judge):
reward_type, verify_result = run_verifier(
verifier_entry=verifier_entry,
verifier_mode="sql",
initial_db_path=initial_db,
final_db_path=final_db,
final_answer=trajectory[-1].get("assistant", ""),
)
if reward_type == "judge_error":
return torch.tensor(0.0)
classification, judge_json = await run_llm_judge(
task=task,
verifier_result=verify_result,
trajectory=trajectory,
llm_model=judge,
)
if classification == "complete":
return torch.tensor(1.0)
if classification == "incomplete" and judge_json.get("partial_progress"):
return torch.tensor(0.1)
return torch.tensor(0.0)
def grpo_history_aware_loss(policy, grouped_rollouts, rewards, history_window=3):
rewards = torch.as_tensor(rewards, dtype=torch.float32)
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-6)
loss = torch.tensor(0.0)
for rollout, adv in zip(grouped_rollouts, advantages):
for t, action in enumerate(rollout.actions):
h_trunc = rollout.history_until(t, window=history_window)
logp = policy.log_prob(action, context=h_trunc)
loss = loss - adv.detach() * logp
return loss / len(grouped_rollouts)4. Experimental Setup(实验设置)
训练数据/环境规模:AWM 总共合成 1,000 个 environments 和 10,000 个 tasks;受算力限制,实际 RL 训练使用 526 个 environments、3,315 个 tasks。
评测 benchmark:BFCLv3(Non-Live、Live、Multi-Turn、Hallucination、Overall),-bench verified version(Airline/Retail/Telecom,报告 Pass@1/Pass@4),MCP-Universe(Location、Financial、Browser、Web、Multi、Overall;排除需要 GUI 的 3D design tasks)。
Baselines:Base Qwen3 thinking model;Simulator(用同任务/工具集但让 LLM 模拟状态转移);EnvScaler(191 个 programming-based environments,用于比较合成质量与训练效果)。14B 表中未报告 EnvScaler baseline。
训练配置:Qwen3 thinking models 4B/8B/14B;GRPO;learning rate ;batch size 64;mini-batch size 16;rollouts per task ;instances per step 1,024;max optimization steps 96;KL coefficient 0.001;entropy coefficient 0.0;clip ratio high 0.28;temperature 1.0;max response length 2,048;max model context 32,000;max interaction turn 20;history window 。评测 decoding 使用 temperature 0.6、top-、top-,context 通过 RoPE scaling 扩展到 131,072 tokens,长上下文评测 history limit 放宽到 。论文与公开仓库未报告 GPU 型号/数量。
环境管理:每个训练 step 启动 1,024 个隔离 MCP server,每个 server 使用独立 SQLite database copy;rollout 结束后恢复 initial database。环境启动与数据库拷贝会阻塞 collection,因此实现预取,在当前 batch 做 gradient update 时后台准备下一批环境。
5. Experimental Results(实验结果)
5.1 主结果:OOD 泛化
| Model | Method | BFCLv3 Overall | Pass@1 | Pass@4 | MCP Overall |
|---|---|---|---|---|---|
| 4B | Base | 54.92 | 15.83 | 34.89 | 6.15 |
| 4B | Simulator | 55.52 | 13.67 | 35.25 | 6.15 |
| 4B | EnvScaler | 54.06 | 28.96 | 51.80 | 4.47 |
| 4B | AWM | 64.50 | 22.57 | 43.89 | 6.70 |
| 8B | Base | 53.83 | 26.44 | 50.72 | 6.70 |
| 8B | Simulator | 52.53 | 31.30 | 54.32 | 6.15 |
| 8B | EnvScaler | 36.83 | 39.39 | 63.31 | 5.59 |
| 8B | AWM | 65.94 | 33.45 | 55.40 | 11.17 |
| 14B | Base | 61.25 | 36.69 | 55.40 | 8.38 |
| 14B | Simulator | 67.68 | 31.39 | 55.40 | 10.62 |
| 14B | AWM | 70.18 | 39.03 | 57.19 | 12.29 |
AWM 在 BFCLv3 上三种模型都提升显著:4B 从 Base 54.92 到 64.50,8B 从 53.83 到 65.94,14B 从 61.25 到 70.18。 上 EnvScaler 在部分 Pass@k 更高,说明 AWM 不是每个 benchmark 都最强;但 AWM 训练集没有针对 对话域、BFCLv3 拒答/幻觉域或 MCP-Universe browser/search 域设计,整体结论更偏 OOD generalization。
5.2 环境质量与多样性
| Metric | AWM / GPT-5.1 | EnvScaler / GPT-5.1 | AWM / Claude 4.5 | EnvScaler / Claude 4.5 |
|---|---|---|---|---|
| Task Feasibility ↑ | 3.68±1.02 | 2.94±1.25 | 3.99±0.81 | 3.14±1.29 |
| Data Alignment ↑ | 4.04±0.91 | 3.73±0.89 | 4.84±0.50 | 4.11±1.02 |
| Toolset Completeness ↑ | 3.65±0.87 | 2.89±0.79 | 4.98±0.14 | 4.06±0.87 |
| Envs w/ Bugs ↓ | 74% | 88% | 83% | 83% |
| Bugs per Env ↓ | 4.13 | 1.82 | 2.70 | 2.21 |
| Blocked Tasks ↓ | 14.0% | 57.1% | 11.5% | 46.8% |

Figure 7 解读:embedding diversity 随环境池增大保持稳定,category coverage 持续增加,说明新环境不是简单重复已有 domains,而是在语义和主题上继续扩展。

Figure 8 解读:类别分布展示了 1,000 个 scenarios 覆盖多个应用域;这支撑了“训练环境多样性”这一主张,而不是只在少数工具类型上堆样本。

Figure 9 解读:wordcloud 补充显示 scenario 主题的长尾分布,有助于判断合成环境是否覆盖真实应用的多样化入口。
5.3 Ablations:verification、history、format、scale
Verification design:code-augmented strategy 在 4B/8B/14B 上均优于 LLM-only 和 code-only。以 8B 为例,BFCLv3 为 65.94(LLM 55.46,Code 60.00), P@1 为 33.45(LLM 26.44,Code 29.59),MCP 为 11.17(LLM 10.62,Code 5.59)。GPT-5 judge 的额外成本约每训练 step 1.80 美元(最多 1,024 samples),异步执行使延迟可忽略。
History-aware training(4B):Aligned setting 中 w/ HL 为 BFCLv3 64.50、 P@1 22.57、P@4 43.89、MCP 6.70;w/o HL 为 55.35、15.92、36.33、6.15。Misaligned setting 中 w/ HL 掉到 61.85、9.35、15.11、5.03,说明 history management 应作为训练目标的一部分,而不只是推理时的启发式截断。
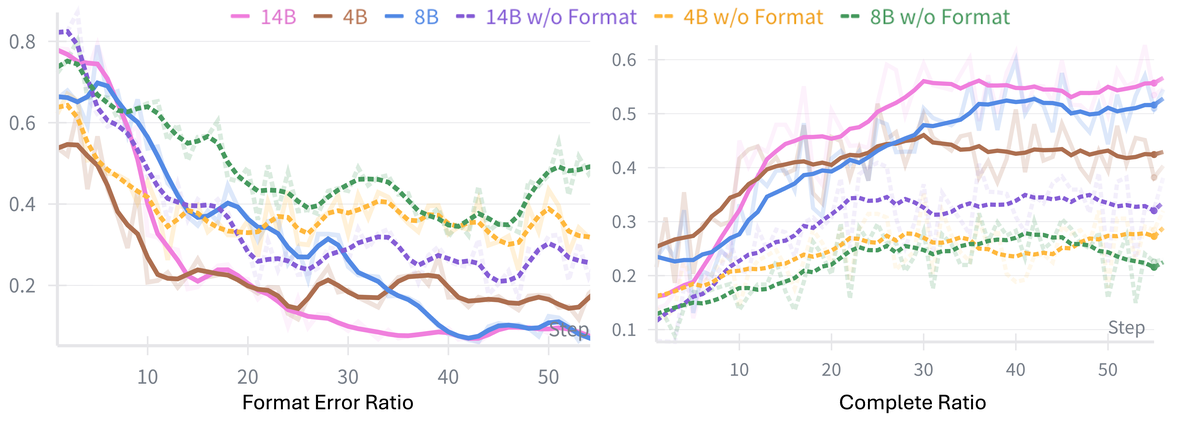
Figure 10 解读:step-level format reward 使 format error ratio 快速收敛到低水平,并把平均 rollout time 降低约 27%;没有该 reward 时,50 steps 后 format error ratio 仍高于 20%,task completion rate 低于 40%。

Figure 11 解读:4B 模型随训练环境数从 10 到 100 再到 526 持续提升;10 个环境会明显过拟合,526 仍未看到收益饱和,说明环境规模和多样性是主要驱动因素之一。
5.4 局限与可改进点
作者明确列出三类限制:第一,当前合成流程是固定 pipeline,不能让已训练 agent 反过来参与环境自进化;第二,自修复主要依赖 runtime trial-and-error,难以发现更细的语义不一致,需要更主动的逻辑校验或人工抽检;第三,训练只覆盖 526/1,000 个环境,模型族主要是 Qwen3 4B/8B/14B,尚未验证更大规模训练和更多模型族。
我的判断:这篇论文的核心价值在 released environments + synthesis pipeline,而不是单个 RL trick。最值得复用的是“代码/数据库作为世界状态 + MCP 作为动作接口 + verifier evidence 作为 reward grounding”的三件套;最大风险是合成环境仍有大量实现 bug,因此 reward 设计必须区分 agent error 和 environment error,否则会把环境缺陷误当成负样本。