World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
1. Motivation(研究动机)
当前 video foundation models 已经能生成高质量视觉内容,但在世界模拟语境下仍常见几何不一致:物体会随镜头漂移、背景结构会在视角变化时重排,2D 上看似合理的视频在 3D 重建或新视角渲染时会暴露出 flat billboard、floaters、遮挡关系错误等问题。已有 3D-aware 或 camera-control 方法通常把 3D prior 注入 architecture、显式输入图像/相机轨迹或依赖特定视频数据分布,这会增加计算成本、限制扩展到强大的 text-to-video foundation model,并且难以保持开放文本生成能力。
World-R1 要解决的具体问题是:在不修改底层 T2V 模型结构的前提下,把 3D geometric consistency 作为可优化的行为约束对齐到视频生成策略中,同时保留原模型的视觉质量、文本覆盖面和动态场景生成能力。它不是训练一个新的 3D-conditioned generator,而是把预训练视频模型看作 policy,通过 RL feedback 让模型在 rollout 中学会生成可被 3D foundation model 重建、相机轨迹更一致、meta-view 更可信的视频。
这个问题值得研究,因为“世界模型”不只是生成单段漂亮视频,还需要跨视角、跨时间保持稳定的 scene permanence。若 T2V 模型能在纯文本提示下产生更可靠的几何结构,就能更自然地服务于 3D reconstruction、camera-control generation、long-video simulation、robotics/embodied AI 中的环境想象与物理推理。
2. Idea(核心思想)
核心洞察是:3D consistency 不一定要通过改模型架构或显式监督视频数据来获得,可以把“生成视频能否被重建成一致 3D 世界”定义成 reward,并用 Flow-GRPO 在 diffusion/flow sampling trajectory 上优化。World-R1 的新意在于把 Depth Anything 3 的 3DGS 重建、camera trajectory alignment、VLM meta-view critique 和 general video reward 组合成在线 RL 信号,让原始 T2V 模型在采样过程中内化几何约束。
关键创新可以概括为三点:第一,用 camera-aware latent initialization/noise wrapping 把文本中的镜头运动先验注入初始 latent,而不是只靠 prompt conditioning;第二,用 analysis-by-synthesis 的 3D-aware reward 检测 2D 视频中难以直接度量的几何错误;第三,用 periodic decoupled training 在主阶段优化 3D+general reward,在动态阶段暂时关闭 3D reward,只用 general reward 训练动态子集,避免模型变得过度刚性。
与 ReCamMaster、TrajectoryCrafter、GCD 等 camera-control/3D-aware 方法相比,World-R1 的根本差异是它不要求给定输入图像或重构好的 3D 条件,也不通过架构改造绑定到特定控制模块;它把 Wan2.1 这类 foundation T2V 模型作为可强化学习的 policy,在纯文本数据上学习“更像 3D 世界”的生成偏好。
3. Method(方法)
3.1 Overall framework

Figure 1 解读:这张 teaser 展示了 World-R1 的目标形态:输入是 text prompt,输出是具有更强 3D consistency 的视频;作者同时可视化视频帧和对应 3D reconstruction,用重建结果说明生成内容是否拥有稳定几何结构。左侧/失败样例通常在重建时出现结构破碎或视角不稳定,World-R1 的结果则更接近可重建、可新视角查看的 scene。
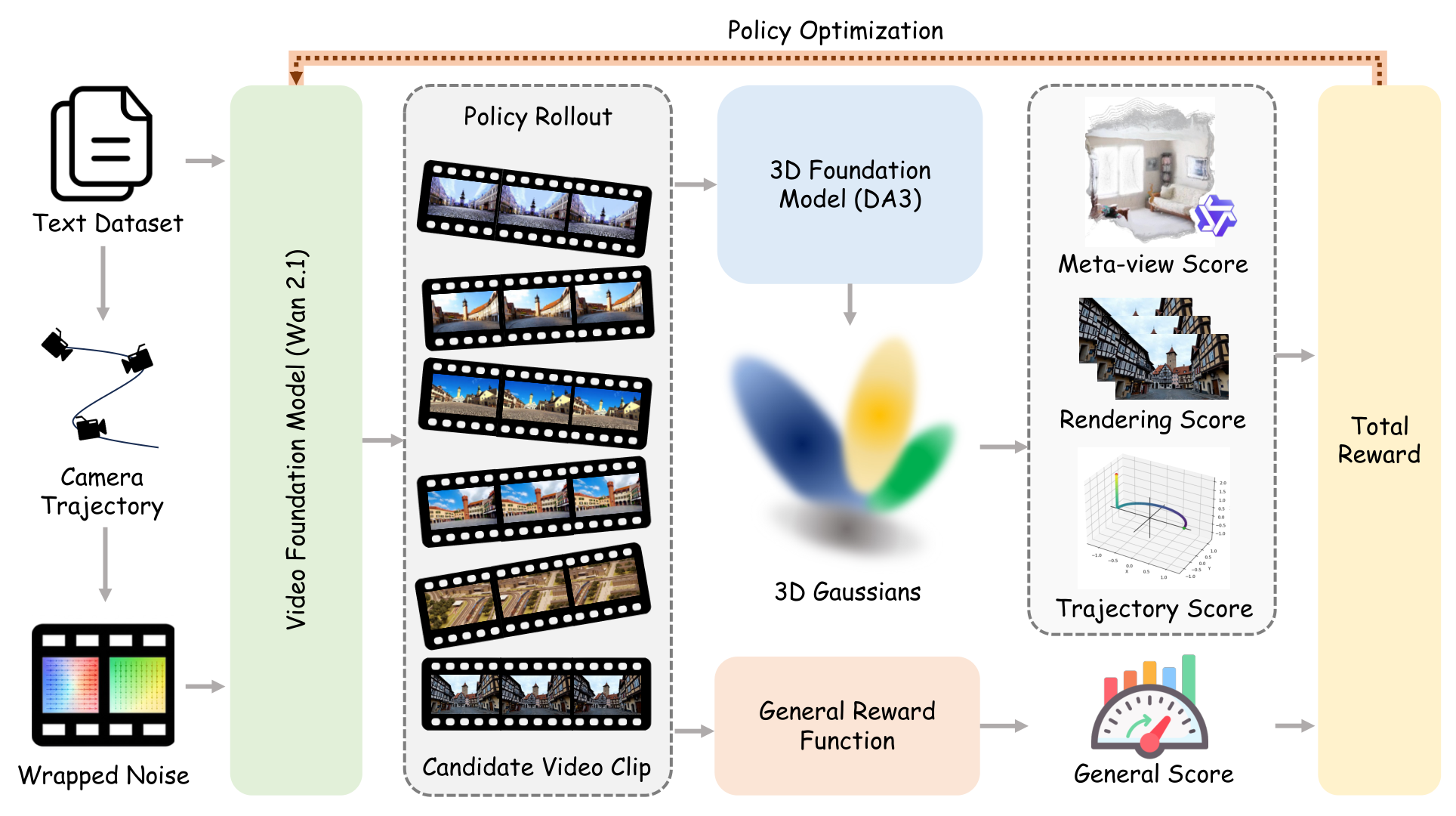
Figure 2 解读:pipeline 图把方法拆成四个闭环:prompt dataset 提供纯文本世界模拟描述;camera conditioning/noise wrapping 根据 prompt 中的相机运动准备 rollout latent;T2V policy 生成视频;reward servers 调用 3D reconstruction、trajectory comparison、meta-view VLM critique 和 general VLM reward,最后用 Flow-GRPO 更新 policy。这个设计的关键是 reward 在生成后才计算,因此可以利用强 3D/VLM evaluator,而不需要改造 generator architecture。
整体训练过程可视为把 flow-based video generation 的 denoising trajectory 当作 Markov Decision Process。给定文本条件 ,模型从 stochastic sampling trajectory 中生成一组视频样本,reward 由 3D-aware term 与 general term 组成,Flow-GRPO 用组内归一化 advantage 更新模型,使高 reward 视频的 trajectory probability 增大。
3.2 Flow-GRPO policy formulation
论文先把 deterministic flow ODE 转成带随机性的 reverse-time SDE,使采样过程能产生 RL 所需的 stochastic action:
离散化后,policy 的一步更新为:
其中 。GRPO 目标函数写作:
这里 是新旧 policy 的 probability ratio, 来自同一 prompt 下 group samples 的 reward normalization;KL term 防止 policy 远离 reference T2V model,避免 RL 只追逐 reward 而破坏视觉先验。
3.3 Camera conditioning / noise wrapping
World-R1 从 prompt 中抽取或指定相机运动,把 trajectory 编码进初始 latent 的时序结构。开源实现中,prepare_rollout_latents_and_callback 会调用 camera trajectory utility,根据 detected_movements_batch 和 camera_trajectories 生成 camera-aware latent;默认配置使用 wrap_injection_mode="stepwise_delta"、noise_wrap_flow_scale=16、delta_lowpass_kernel=9、stepwise_guidance_steps=8,Small/Large 的 wrap_strength 分别为 0.35/0.4。
直觉上,这一步给 RL 降低了搜索难度:如果所有镜头运动都只由 prompt token 隐式控制,policy 必须同时学会视觉内容、相机路径和几何约束;camera-aware latent initialization 先把“镜头应该怎样动”的低频结构放进噪声场,后续 RL reward 更聚焦于“这个运动下场景是否仍像一个稳定 3D 世界”。
3.4 Reward design
总 reward 是:
3D-aware reward 是三个分量的直接相加:
附录说明每个 3D 分量限制在 ,因此 ;,并使用 直接相加。四个 reward 的含义如下:
- :用 Depth Anything 3 把视频提升为 3DGS,再从偏离原轨迹的 meta-view 渲染,由 Qwen3-VL/OpenAI-style VLM critic 判断结构是否可信,专门抓 2D plausible 但 3D 错误的 billboard/floaters。
- :比较重建/重渲染结果与原视频帧的一致性,代码中记录
gs_score,用于度量视频是否能被稳定 3DGS 表示。 - :比较 Depth Anything 3 估计的 camera trajectory 与 prompt/conditioning 目标轨迹,代码中记录
camera_motion_score。 - :general VLM reward,约束美学质量、prompt alignment、主体/背景一致性和动态自然性,防止模型为了 3D 分数生成乏味或过度刚性的内容。
3.5 Dataset preparation and periodic decoupled training
论文构造了一个 pure text dataset:约 3,000 条由 Gemini 合成的高质量世界模拟 prompt,覆盖 natural landscapes、urban structures、surrealist environments,并按控制复杂度区分 implicit motion、single directional commands、complex composite trajectories。训练集中另有约 500 条 highly dynamic scenes,用于 decoupled dynamic phase;评估集是独立的 30 条 complex prompts。
Periodic decoupled training 的周期是主阶段 100 steps + 动态阶段 50 steps。主阶段在混合数据上优化完整 reward ;动态阶段只采样 dynamic subset,暂时关闭 3D-aware reward,只优化 。这种交替相当于把“几何刚性”和“非刚性动态”分开对齐:前者让场景不漂移,后者防止火焰、水流、人群等高熵运动被 3D reward 压成静态物体。

Figure 3 解读:这张动态场景可视化说明 decoupled training 的必要性。World-R1 既要保留场景的 3D frame-to-frame structure,又不能把动态物体“冻结”;图中的 dynamic examples 展示了模型在复杂运动中仍能维持较稳定的环境结构。
3.6 Pseudocode from open-source implementation
以下伪代码基于官方仓库 microsoft/World-R1 的 main@cf54603d (2026-05-01),抽象自 scripts/train_world_r1.py、flow_grpo/rewards.py、reward_server/reward_3d.py、reward_server/general_reward.py 和 flow_grpo/diffusers_patch/wan_pipeline_with_logprob.py。
Camera-aware rollout latent preparation
import torch
def prepare_camera_aware_latents(pipeline, prompts, config, metadata):
camera_trajectories, detected_movements = get_camera_trajectories_for_batch(
prompts,
batch_size=len(prompts),
frames_per_trajectory=81,
force_camera_movement=config.sample.force_camera_movement,
)
metadata = add_camera_trajectory_metadata(metadata, camera_trajectories)
latents, step_callback = prepare_rollout_latents_and_callback(
pipeline=pipeline,
prompt=prompts,
batch_size=len(prompts),
num_channels_latents=pipeline.transformer.config.in_channels,
height=config.height,
width=config.width,
num_frames=config.frames,
dtype=torch.bfloat16,
device=pipeline.device,
vae_scale_factor_temporal=pipeline.vae_scale_factor_temporal,
frames_per_trajectory=81,
force_camera_movement=config.sample.force_camera_movement,
noise_wrap_compute_dtype=config.sample.noise_wrap_compute_dtype,
noise_downtemp_interp=config.sample.noise_downtemp_interp,
noise_downspatial_mode=config.sample.noise_downspatial_mode,
noise_degradation=config.sample.noise_degradation,
noise_wrap_flow_scale=config.sample.noise_wrap_flow_scale,
wrap_strength=config.sample.wrap_strength,
wrap_injection_mode=config.sample.wrap_injection_mode,
delta_lowpass_kernel=config.sample.delta_lowpass_kernel,
stepwise_guidance_steps=config.sample.stepwise_guidance_steps,
camera_trajectories=camera_trajectories,
detected_movements_batch=detected_movements,
)
return latents, step_callback, metadataStochastic rollout with log probability
import torch
def rollout_with_logprob(pipeline, prompts, latents, callback, config):
videos, trajectory = wan_pipeline_with_logprob(
pipeline=pipeline,
prompt=prompts,
height=config.height,
width=config.width,
num_frames=config.frames,
num_inference_steps=config.sample.num_steps,
guidance_scale=config.sample.guidance_scale,
latents=latents,
output_type="np",
callback_on_step_end=callback,
determistic=False,
kl_reward=config.sample.kl_reward,
use_camera_trajectory=True,
)
return {
"videos": videos,
"latents": trajectory.latents,
"next_latents": trajectory.next_latents,
"timesteps": trajectory.timesteps,
"log_probs": trajectory.log_probs,
}Composite reward with dynamic-phase skipping
import numpy as np
def compute_world_r1_reward(videos, prompts, metadata, reward_fns, score_dict):
total_scores = np.zeros(len(prompts), dtype=np.float32)
details = {}
is_any_dynamic = any(m.get("is_dynamic", False) for m in metadata)
skip_3d_rewards = {"reward_3d"}
for reward_name, weight in score_dict.items():
if is_any_dynamic and reward_name in skip_3d_rewards:
continue
reward_scores, reward_metadata = reward_fns[reward_name](
videos, prompts, metadata
)
reward_scores = np.asarray(reward_scores, dtype=np.float32)
total_scores += float(weight) * reward_scores
details[reward_name] = reward_scores.tolist()
if reward_metadata:
details.update(reward_metadata)
return total_scores, details3D-aware reward server
import torch
def compute_3d_reward(batch_videos, batch_prompts, camera_trajectories, da3_model, meta_scorer):
scores = []
details = []
for video, prompt, target_traj in zip(batch_videos, batch_prompts, camera_trajectories):
gs_scene, estimated_traj = da3_model.reconstruct_3dgs_and_camera(video)
recon_score = compute_lpips_gs_score(gs_scene, video)
meta_view = render_meta_view(gs_scene, offset_from=estimated_traj)
meta_score = meta_scorer([prompt], [meta_view])[0]
traj_score = compare_camera_trajectory(estimated_traj, target_traj)
reward_3d = meta_score + recon_score + traj_score
scores.append(float(reward_3d))
details.append({
"meta_score": float(meta_score),
"gs_score": float(recon_score),
"camera_motion_score": float(traj_score),
})
return scores, detailsFlow-GRPO training loop
import torch
import torch.nn.functional as F
def train_world_r1(policy, ref_policy, pipeline, dataloaders, reward_fns, config, optimizer):
global_step = 0
for epoch in range(config.num_epochs):
cycle = config.dynamic_training.main_steps + config.dynamic_training.dynamic_steps
use_dynamic = (global_step % cycle) >= config.dynamic_training.main_steps
loader = dataloaders["dynamic"] if use_dynamic else dataloaders["main"]
batch = next(iter(loader))
prompts, metadata = batch["prompt"], batch["metadata"]
latents, callback, metadata = prepare_camera_aware_latents(
pipeline, prompts, config, metadata
)
samples = rollout_with_logprob(pipeline, prompts, latents, callback, config)
rewards, reward_info = compute_world_r1_reward(
samples["videos"], prompts, metadata, reward_fns, config.reward_fn
)
advantages = normalize_rewards_per_prompt_group(
torch.tensor(rewards, device=policy.device),
group_size=8,
)
new_log_probs = compute_log_prob(policy, pipeline, samples, prompts, config)
old_log_probs = samples["log_probs"].detach()
ratio = torch.exp(new_log_probs - old_log_probs)
clipped_ratio = torch.clamp(
ratio,
1.0 - config.train.clip_range,
1.0 + config.train.clip_range,
)
policy_loss = -torch.min(ratio * advantages, clipped_ratio * advantages).mean()
kl_loss = compute_kl_loss(policy, ref_policy, samples, prompts)
loss = policy_loss + config.train.beta * kl_loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
global_step += 13.7 Code-to-paper mapping
Code reference:
main@cf54603d(2026-05-01) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| World-R1 experiment config | config/world_r1.py | _build_world_r1_config, world_r1_small, world_r1_large |
| Pure text prompt dataset / dynamic subset | scripts/train_world_r1.py | TextPromptDataset, collate_fn |
| Camera conditioning / noise wrapping | scripts/train_world_r1.py; flow_grpo/diffusers_patch/camera_trajectory_utils.py | prepare_rollout_latents_and_callback, add_camera_trajectory_metadata, get_camera_trajectories_for_batch |
| Stochastic rollout with log-prob | scripts/train_world_r1.py; flow_grpo/diffusers_patch/wan_pipeline_with_logprob.py | rollout_with_logprob, sde_step_with_logprob, wan_pipeline_with_logprob |
| Flow-GRPO optimization | scripts/train_world_r1.py | compute_log_prob, compute_kl_loss, main training loop |
| Composite reward routing | flow_grpo/rewards.py | multi_score, remote_reward_3d, remote_reward_general |
| 3D-aware reward | reward_server/reward_3d.py | MultiGPUReward3DManager.compute_batch_scores, compute_lpips_gs_score |
| General VLM reward | reward_server/general_reward.py | compute_score, general reward manager |
| Reward server launch | scripts/serve_reward_3d.py; scripts/serve_general_reward.py; scripts/run_reward_3d_server.sh; scripts/run_general_reward_server.sh | HTTP/pickle reward service wrappers |
| Training entry point | scripts/train_world_r1.py; scripts/run_training.sh | main, distributed sampling/training orchestration |
4. Experimental Setup(实验设置)
Datasets and scale. 训练数据是一个 pure text dataset,约 3,000 unique prompts,由 Gemini 合成并覆盖 natural landscapes、urban/architectural scenes、micro/still life、surreal environments 等世界模拟场景;其中约 500 prompts 被标为 high-dynamic subset,用于 periodic decoupled training 的 dynamic phase。评估集是独立的 30 complex prompts,用于 stress-test world modeling。数据规模实验还比较了 1K、2K、3K prompt 的训练效果。
Baselines. 主要 foundation model baseline 包括 CogVideoX-1.5-5B、Wan2.2-T2V-14B、Wan2.2-T2V-5B、Wan2.1-T2V-14B、Wan2.1-T2V-1.3B。3D-aware / camera-control 对比包括 ViewCrafter、Voyager、FlashWorld、VerseCrafter、GCD、Traj.-Attn.、DAS、ReCamMaster、TrajectoryCrafter、CamCloneMaster。用户研究按参数规模匹配:World-R1-Small 对 Wan2.1-T2V-1.3B,World-R1-Large 对 Wan2.1-T2V-14B。
Evaluation metrics. 3D consistency 用 3DGS reconstruction/re-rendering 指标 PSNR↑、SSIM↑、LPIPS↓ 衡量;MVCS↑ 作为 reconstruction-independent multi-view consistency;camera-control 用 RotErr↓、TransErr↓、CamMC↓;general video quality 用 VBench 的 Aesthetic Quality、Imaging Quality、Motion Smoothness、Subject Consistency、Background Consistency;用户研究采用 double-blind 2AFC,统计 win rate,并有 20 人、30 video pairs 的 metric-validation agreement study。
Training config. 基座模型为 Wan 2.1:World-R1-Small 初始化自 Wan2.1-T2V-1.3B,World-R1-Large 初始化自 Wan2.1-T2V-14B。Small 使用 48 NVIDIA H200 GPUs,Large 使用 96 H200 GPUs;训练分辨率 ,81 frames,rollout denoising steps 50,guidance scale 5.0,noise level 0.7,GRPO group size ,总 batch 分布在 48 parallel groups。官方配置中 learning rate 为 、、clip range 、mixed precision bf16、EMA enabled、reward weights reward_3d=1.0 与 reward_general=1.0,dynamic training 周期为 100 main steps + 50 dynamic steps。
5. Experimental Results(实验结果)

Figure 4 解读:qualitative comparison 同时展示生成视频帧和 3D reconstruction。与 Wan/CogVideoX 等 foundation baseline 相比,World-R1 的视频在相机运动下更能保持 scene permanence:建筑、物体边界和背景布局不会随帧随机重排,因此 3DGS 重建更稳定。
5.1 Main quantitative results
VBench general video quality(World-R1-Large 未因资源约束测试):
| Method | Aesthetic↑ | Imaging↑ | Motion Smoothness↑ | Subject Consistency↑ | Background Consistency↑ |
|---|---|---|---|---|---|
| CogVideoX-1.5-5B | 62.07 | 65.34 | 98.15 | 96.56 | 96.81 |
| Wan2.1-T2V-1.3B | 62.43 | 66.51 | 97.44 | 96.34 | 97.29 |
| GCD | 38.21 | 41.56 | 98.37 | 88.94 | 92.00 |
| Traj.-Attn. | 38.50 | 51.00 | 98.21 | 90.60 | 92.83 |
| DAS | 39.86 | 51.55 | 99.14 | 90.34 | 92.03 |
| ReCamMaster | 42.70 | 53.97 | 99.28 | 92.05 | 93.83 |
| World-R1-Small | 65.74 | 67.53 | 98.55 | 97.58 | 96.67 |
3D consistency reconstruction metrics:
| Method | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| CogVideoX-1.5-5B | 24.44 | 0.783 | 0.242 |
| Wan2.2-T2V-14B | 23.47 | 0.779 | 0.253 |
| Wan2.2-T2V-5B | 22.36 | 0.716 | 0.303 |
| Wan2.1-T2V-14B | 19.76 | 0.629 | 0.405 |
| Wan2.1-T2V-1.3B | 17.40 | 0.550 | 0.467 |
| World-R1-Small | 27.63 | 0.858 | 0.201 |
| World-R1-Large | 27.67 | 0.865 | 0.162 |
这些数值说明 World-R1 不只是改善某个视觉评分:Small 相比 Wan2.1-1.3B 的 PSNR 从 17.40 提升到 27.63,LPIPS 从 0.467 降到 0.201;Large 相比 Wan2.1-14B 的 PSNR 从 19.76 提升到 27.67,LPIPS 从 0.405 降到 0.162。
5.2 Camera control, MVCS and user study
| Method | RotErr↓ | TransErr↓ | CamMC↓ |
|---|---|---|---|
| ReCamMaster | 1.53 | 3.12 | 4.17 |
| TrajectoryCrafter | 3.08 | 7.46 | 10.22 |
| CamCloneMaster | 1.36 | 2.02 | 3.05 |
| Wan2.1-T2V-1.3B | 9.29 | 62.94 | 66.21 |
| Wan2.1-T2V-14B | 17.01 | 60.90 | 70.55 |
| World-R1-Small | 1.50 | 2.76 | 3.39 |
| World-R1-Large | 1.21 | 1.30 | 2.95 |
| Method | MVCS↑ |
|---|---|
| Wan2.1-T2V-1.3B | 0.974 |
| World-R1-Small | 0.989 |
| Wan2.1-T2V-14B | 0.963 |
| World-R1-Large | 0.993 |
用户研究中,World-R1 相比 Wan2.1 的 win rate 为:Geometric Consistency 92%,Camera Control Accuracy 76%,Overall Preference 86%。metric-validation study 有 20 participants、30 video pairs,automatic metric ranking 与多数人类偏好的 agreement 为 91.17%。
5.3 Ablations
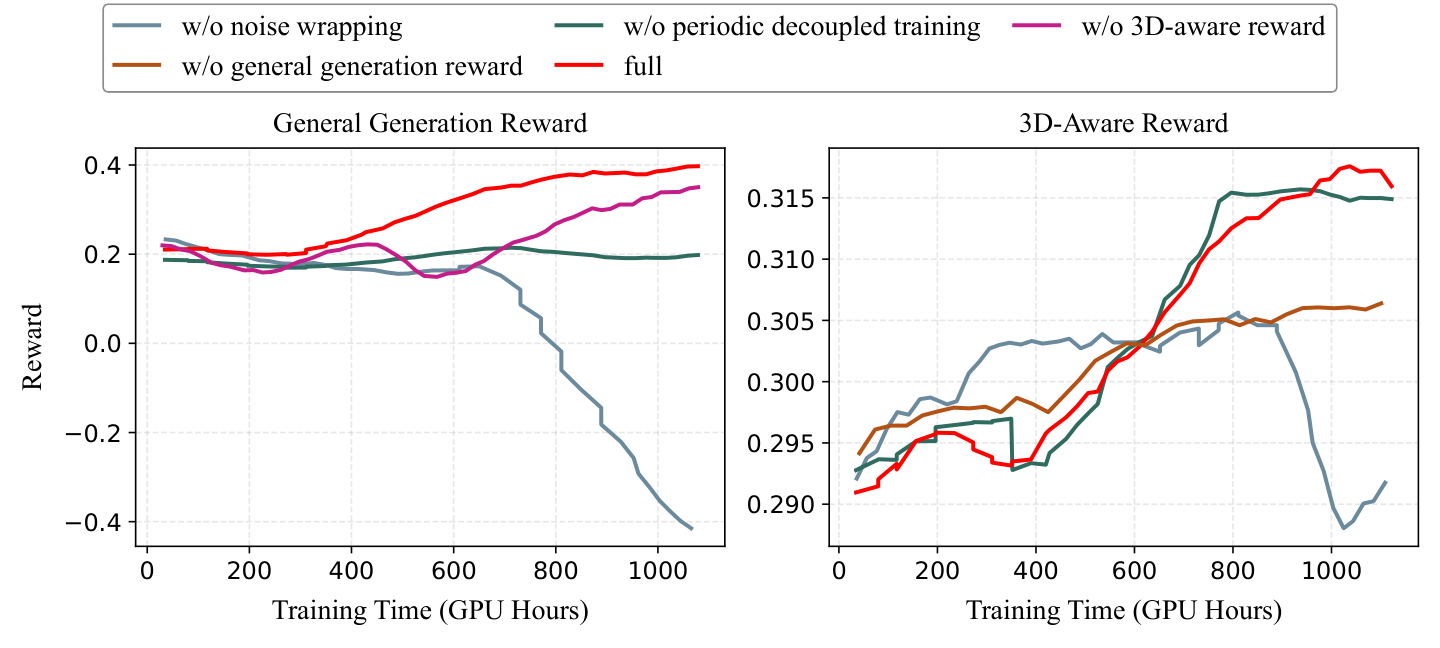
Figure 5 解读:ablation 曲线展示 general generation reward 与 3D-aware reward 在 fine-tuning 过程中的变化。它直观说明单纯强化几何会影响一般生成质量,而 periodic decoupled training 和 general reward 能维持动态与视觉质量的平衡。
Reward component ablation on World-R1-Small:
| Variant | PSNR↑ | SSIM↑ | LPIPS↓ | VBench AVG↑ |
|---|---|---|---|---|
| Full pipeline | 27.63 | 0.858 | 0.201 | 85.21 |
| w/o | 26.91 | 0.841 | 0.218 | 83.67 |
| w/o | 25.14 | 0.798 | 0.271 | 84.35 |
| w/o | 26.27 | 0.829 | 0.237 | 84.53 |
Training and conditioning ablation:
| Variant | PSNR↑ | SSIM↑ | LPIPS↓ | VBench AVG↑ | ↑ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|---|---|
| Full | 27.63 | 0.858 | 0.201 | 85.21 | 0.342 | 0.296 | 0.307 | 0.37 |
| w/o noise wrapping | 24.46 | 0.745 | 0.298 | 76.39 | 0.312 | 0.213 | 0.275 | -0.42 |
| w/o periodic decoupled training | 27.89 | 0.898 | 0.192 | 82.64 | 0.348 | 0.310 | 0.298 | 0.18 |
| w/o 3D-aware reward | 18.93 | 0.502 | 0.496 | 84.96 | — | — | — | 0.33 |
| w/o general reward | 27.57 | 0.849 | 0.206 | 83.44 | 0.388 | 0.231 | 0.305 | — |
关键结论:w/o 3D-aware reward 几何指标大幅崩塌(PSNR 18.93、SSIM 0.502、LPIPS 0.496),说明 RL 的 3D feedback 是核心;w/o noise wrapping 同时损害 3D 和 VBench AVG,说明 camera-aware latent 对可控相机轨迹很重要;w/o periodic decoupled training 虽然 PSNR/SSIM 甚至更高,但 VBench AVG 从 85.21 降到 82.64,说明单纯追求刚性几何会牺牲一般视频质量和动态自然性。
5.4 Data scaling and long-video generalization
| Data Size | PSNR↑ | SSIM↑ | LPIPS↓ | VBench AVG↑ |
|---|---|---|---|---|
| 1K | 25.82 | 0.812 | 0.258 | 83.23 |
| 2K | 26.54 | 0.839 | 0.223 | 84.76 |
| 3K | 27.63 | 0.858 | 0.201 | 85.21 |
| 121-frame Method | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| Wan2.1-T2V-14B | 18.32 | 0.558 | 0.534 |
| World-R1-Large | 26.32 | 0.828 | 0.257 |
数据规模实验显示纯文本 prompt 规模从 1K 到 3K 会持续改善几何和 VBench;long-video 实验说明虽然训练主要在较短 rollout 上进行,World-R1-Large 在 121-frame generation 仍保持明显更好的 3D consistency。
5.5 Scene complexity breakdown
| Scene Type | N | Method | PSNR↑ | SSIM↑ | LPIPS↓ | MVCS↑ |
|---|---|---|---|---|---|---|
| Static Scene | 30.11% | Wan2.1-1.3B | 20.14 | 0.632 | 0.389 | 0.981 |
| Static Scene | 30.11% | World-R1-Small | 30.52 | 0.912 | 0.142 | 0.994 |
| Single-obj Dynamic | 29.03% | Wan2.1-1.3B | 17.86 | 0.563 | 0.452 | 0.976 |
| Single-obj Dynamic | 29.03% | World-R1-Small | 28.17 | 0.869 | 0.189 | 0.991 |
| Multi-obj Dynamic | 21.51% | Wan2.1-1.3B | 15.23 | 0.487 | 0.528 | 0.968 |
| Multi-obj Dynamic | 21.51% | World-R1-Small | 25.41 | 0.812 | 0.248 | 0.985 |
| Non-rigid Motion | 19.35% | Wan2.1-1.3B | 14.58 | 0.462 | 0.548 | 0.965 |
| Non-rigid Motion | 19.35% | World-R1-Small | 24.73 | 0.793 | 0.267 | 0.982 |
| Long-horizon Dynamics | 12.89% | Wan2.1-1.3B | 12.53 | 0.382 | 0.683 | 0.951 |
| Long-horizon Dynamics | 12.89% | World-R1-Small | 23.59 | 0.781 | 0.299 | 0.974 |
World-R1 的提升在静态和动态场景都存在;越复杂的 dynamic/long-horizon 类别,baseline 指标下降越明显,而 World-R1 仍保持更高 PSNR/SSIM/MVCS 和更低 LPIPS。
5.6 Additional visualizations and limitations

Figure 6 解读:meta-view 图说明为什么只看原视频帧不够。左侧样例在原视角可能局部可接受,但从偏移 meta-view 看 3DGS 会不稳定或破碎;右侧高质量样例在 meta-view 下仍符合 prompt 描述,说明 能捕捉 2D 指标难以发现的几何幻觉。

Figure 7 解读:高质量 reconstruction 展示了 World-R1 生成视频可以被 3DGS 更稳定地重建,物体位置和背景结构在新视角下仍然 coherent。这是论文把 video generation 与 scalable world simulation 连接起来的主要证据。

Figure 8 解读:失败 reconstruction 展示了几何不一致的典型形态:原视频中看似连续的帧,在 3D lifting 后可能出现漂浮物、断裂结构或无法解释的相机路径。它也说明 World-R1 的 reward 依赖 evaluator 能否可靠发现这些错误。
作者没有在正文中单列局限性章节,但从方法和实验可见几个边界:训练成本很高(48/96 H200 GPUs);reward pipeline 依赖 Depth Anything 3、3DGS reconstruction 和 VLM critic,评估器偏差可能影响优化方向;World-R1-Large 未报告 VBench general quality;camera-control/3D-aware baseline 与 World-R1 的输入设置并不完全相同,附录也说明 3D-conditioned baselines 以 image-to-video setting 评估,而 World-R1 是 text-to-video general scenes。
总体结论是:World-R1 证明了不改 T2V architecture 也可以通过 RL 将 3D constraints 对齐进视频 foundation model。它在 PSNR/SSIM/LPIPS、MVCS、camera-control 和用户偏好上都显著提升,并通过 ablation 证明 3D-aware reward、noise wrapping、general reward 与 periodic decoupled training 分别承担几何对齐、相机先验、视觉质量保护和动态保留的作用。