1. Motivation (研究动机)
1.1 核心问题
Autoregressive (AR) diffusion 模型可以逐帧因果地生成视频,天然支持 streaming 和 interactive prompt 控制,但在生成分钟级长视频时面临三个瓶颈:
- Error Accumulation:AR 逐帧生成时误差会随时间累积,导致画面质量逐渐退化
- Motion Drift:缺乏全局上下文,场景主体会逐渐偏移或变形
- Content Repetition:现有 attention sink 方法冻结早期帧作为全局锚点,导致生成内容陷入重复循环
1.2 现有方案的局限
| 方案 | 复杂度 | 问题 |
|---|---|---|
| Dense Attention | O(T^2) | 不可扩展到长序列 |
| Window Attention (Rolling KV) | O(TL) | 窗口外信息丢失,长程 drift |
| Attention Sink | O(TL) | 早期帧被冻结为 static anchor,内容重复 |
| 3D-coupled Memory (VMem, WorldMem) | - | 依赖显式 3D 结构,无法处理自由视角 |
1.3 关键洞察
作者从人类记忆系统 (working memory + long-term memory) 获得启发:短期记忆 保留精细的运动细节(local lossless),长期记忆 压缩存储全局场景动态(global compressed)。两者协同工作才能在长时间尺度上保持连贯且动态的生成。
2. Idea (核心思想)
VideoSSM 的核心思想是为 AR DiT 引入一个 hybrid state-space memory,将视频生成重新定义为一个 recurrent dynamical process:
- Local Memory:causal sliding-window attention + KV cache,保留窗口内的无损细节(motion cues, fine appearance)
- Global Memory:State Space Model (SSM) 持续压缩窗口外被 evict 的 token 到一个固定大小的 hidden state,作为不断演化的全局场景摘要
- Position-Aware Router:根据序列位置动态融合 local 和 global memory 输出
关键创新点:
- SSM 作为 global memory 是 动态演化的(而非 attention sink 的静态锚点),避免内容冻结和重复
- 整体复杂度保持 O(TL)(L 为窗口大小),线性可扩展
- 通过 Self-Forcing distillation + DMD loss 两阶段训练,从 bidirectional teacher 蒸馏到 causal student
3. Method (方法)
3.1 整体架构
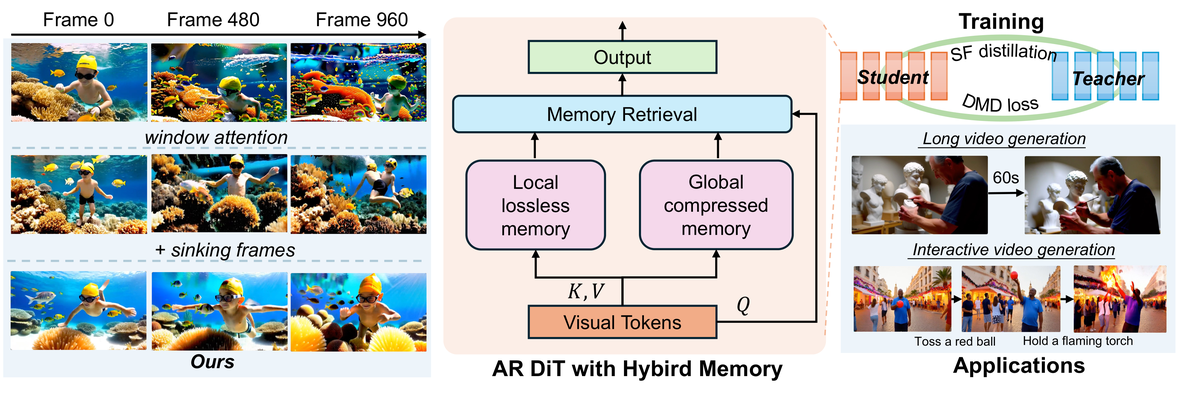
Figure 1 解读: 左侧展示 VideoSSM 在 960 帧(60 秒)上的生成效果,水下场景保持了一致的主体和动态运动。右上展示训练流程:通过 Self-Forcing distillation 和 DMD loss 从 bidirectional teacher 蒸馏 student。右下展示两大应用:60 秒长视频生成和 interactive prompt 切换生成。核心架构是 AR DiT with Hybrid Memory,包含 local lossless memory(sliding window)和 global compressed memory(SSM),通过 memory retrieval 将全局信息注入当前生成。
3.2 DiT Block 对比

Figure 2 解读: 对比三种 DiT block 设计。(a) Standard DiT 使用 full self-attention,支持长上下文但非因果、不可 streaming。(b) Causal DiT 使用 masked causal attention,支持 AR 和 streaming,但长程误差累积。(c) VideoSSM 的 Causal DiT Block with Memory:在 causal attention 旁并行一个 Memory Module,两路输出通过 Router 动态融合后送入 cross-attention 和 FFN。同时保持因果性、streaming 能力和长程一致性。
3.3 Attention 机制对比

Figure 3 解读: 四种 attention 机制的可视化对比。(a) Dense Attention:全量注意力,O(T^2),不实际。(b) Window Attention:仅关注最近 L 个 token,窗口外信息被 evict 后丢失。(c) + Attention Sink:在窗口前保留固定的 sink tokens 作为静态锚点,虽改善长程一致性但导致内容重复。(d) + Memory(VideoSSM):被 evict 的 token 不是被丢弃或冻结,而是通过 SSM 压缩到动态 memory state H_global 中,实现 O(TL) 复杂度下的全局动态记忆。
3.4 Sliding Window 细节

Figure 4 解读: 展示在 causal DiT 中 sink、evicted、window tokens 如何随时间步变化(窗口长度 L=3)。生成 Frame 4 时窗口包含 token 1-3 加上 sink;生成 Frame 7 时窗口滑动到 token 4-7,token 1-3 被 evict。被 evict 的 token 正是被 SSM 吸收进 global memory 的输入。
3.5 Hybrid Memory Module

Figure 5 解读: Hybrid Memory Module 的详细架构。输入 hidden state H_t^in 被分成两路处理:Local path(上方)通过 window attention 从 KV cache 中检索局部信息,输出 H_t^local。Global path(下方)通过 SSM 将被 evict 的 token 递归压缩到 memory state M_t,再通过 memory retrieval(Eq.8)生成 H_t^global。两个 gate alpha_t(decay)和 beta_t(injection)控制信息的遗忘与注入。最终 Router 根据位置感知 gate gamma_t 将 local 和 global 融合。
3.6 核心公式推导
Local Memory: Sliding Window Self-Attention
给定当前帧的输入 hidden state H_t^in,计算 query, key, value:
Local KV cache 包含 sink token 和最近 L 个 token 的 KV:
Local attention 输出:
Global Memory: SSM Dynamic State
Synchronized Gate Caching: 两个 learnable gate 控制信息流:
- Injection gate beta_t:控制 evicted token 对 global state 的写入强度
- Decay gate alpha_t:控制过去 memory 的衰减速度
State Update(Gated Delta Rule):
其中 Predict 预估 evicted value 中可以从上一步 state 推导出的部分(即可预测成分),V_new 只保留 不可预测的新信息。cumulative decay gate g_bar_t 控制整体衰减。
Memory Retrieval:
通过 query 投影到压缩 state M_t 上检索相关信息,output gate 控制全局信息暴露量。
Position-Aware Gated Fusion
定义相对位置比 rho_t = (t+1)/T,通过可学习参数控制 global memory 的注入强度:
当 t 较小(序列开头)时 rho_t → 0,log(rho_t) → -inf,gamma_t → 0(主要依赖 local);当 t 增大时 gamma_t 逐渐增大(global memory 权重增加)。
最终融合:
3.7 Pseudocode
# ===== VideoSSM Hybrid Memory Module =====
> **Authors**: Yifei Yu*, Xiaoshan Wu*, Xinting Hu, Tao Hu, Yang-Tian Sun, Xiaoyang Lyu, Bo Wang, Lin Ma, Yuewen Ma, Zhongrui Wang, Xiaojuan Qi
> **Affiliations**: HKU, PICO (ByteDance), SUSTech
> **Year**: 2025
class HybridMemoryModule:
def __init__(self, d_model, window_size, sink_size):
self.W_Q, self.W_K, self.W_V = Linear(d_model), Linear(d_model), Linear(d_model)
self.W_alpha = Linear(d_model, d_model) # decay gate
self.W_beta = Linear(d_model, d_model) # injection gate
self.A = Parameter(d_model) # base decay
self.B = Parameter(d_model) # bias
self.W_out = Linear(d_model, d_model) # output gate
self.w_router = Parameter(d_model) # position-aware router
self.b_router = Parameter(d_model)
self.L = window_size
self.kv_cache = RollingKVCache(window_size, sink_size)
self.M = zeros(d_model, d_model) # global memory state
def forward(self, H_in, t, T):
# === Compute Q, K, V ===
Q, K, V = H_in @ self.W_Q, H_in @ self.W_K, H_in @ self.W_V
# === Compute gates ===
beta = sigmoid(self.W_beta(H_in)) # injection gate
alpha = -exp(self.A) * softplus(self.W_alpha(H_in) + self.B) # decay gate
# === Update KV cache, get evicted tokens ===
evicted_K, evicted_V, evicted_alpha, evicted_beta = self.kv_cache.push(K, V, alpha, beta)
# === Local Memory: Window Attention ===
K_local, V_local = self.kv_cache.get() # [sink + window] KV
H_local = causal_self_attention(Q, K_local, V_local)
# === Global Memory: SSM State Update ===
if evicted_K is not None:
# Gated Delta Rule: only store unpredictable new info
V_predicted = predict(self.M, evicted_K, evicted_beta)
V_new = evicted_V - V_predicted
g_bar = cumsum(evicted_alpha) # cumulative decay
self.M = exp(g_bar) * self.M + evicted_K.T @ V_new
# === Global Memory Retrieval ===
g_out = self.W_out(H_in) # output gate
H_global = swish(g_out * rmsnorm(Q @ self.M))
# === Position-Aware Router ===
rho = (t + 1) / T
gamma = sigmoid(self.w_router * log(rho) + self.b_router)
# === Fused Output ===
H_fused = H_local + gamma * H_global
return H_fused
# ===== Two-Stage Training =====
def stage1_causal_distillation(teacher, student, video_clips_5s):
"""Stage 1: Distill bidirectional teacher -> causal student on 5s clips"""
for x_0 in video_clips_5s:
t = sample_timestep()
x_t = add_noise(x_0, t)
# Teacher generates target via ODE trajectory
target = teacher(x_t, t) # bidirectional, full attention
# Student generates prediction causally
pred = student(x_t, t) # causal, with memory
loss = mse(pred, target) # + Self-Forcing alignment
loss.backward()
def stage2_long_video_training(teacher, student, prompts, N=60):
"""Stage 2: Long video distillation with rolling memory"""
for prompt in prompts:
# 1. Long self-rollout: student generates N-second video autoregressively
video = student.autoregressive_generate(prompt, N_seconds=N)
# Rolling KV cache + Memory cache for sustained fixed context
# 2. Windowed teacher correction via DMD loss
i = uniform_sample(1, N - K) # random window start
z_i = video[i : i + K] # K=5 second window
L_DMD = dmd_loss(student, teacher, z_i, t)
L_DMD.backward()3.8 训练策略详解
Stage 1: Causal Model Distillation
- 从预训练的 bidirectional teacher(Wan 2.1)初始化 causal student
- 使用 CausVid 策略,student 在 5 秒片段上回归 teacher 的 ODE 采样轨迹
- Self-Forcing:训练时用自身生成的帧替代 ground truth 作为上下文,弥合 train-test gap
- 梯度选择性传播到 hybrid memory,防止 exposure bias
Stage 2: Long Video Training
- Long Self-Rollout:student 自回归生成 60 秒长视频,使用 rolling KV cache 和 global memory cache 模拟推理行为
- Windowed Teacher Correction:在长视频的随机 5 秒窗口上计算 DMD loss,利用 teacher 的短片段能力纠正退化
4. Experimental Setup (实验设置)
4.1 模型配置
| 项目 | 配置 |
|---|---|
| Base Model | Wan 2.1-T2V-1.3B (flow-matching) |
| 参数量 | 1.4B(增加了 memory module) |
| 分辨率 | 832 x 480 |
| FPS | 16 |
| 短视频长度 | 5 秒 (80 帧) |
| 长视频长度 | 60 秒 (960 帧) |
| Diffusion Steps | 4-step (蒸馏后) |
| Chunk Size | 3(每次生成 3 个 latent frames) |
| 训练数据 | VidProM 的 filtered + LLM-extended 版本 |
4.2 评测基准
- VBench:短视频(5 秒)评测,包含 Total、Quality、Semantic 三个维度
- Long Video VBench:60 秒长视频评测,包含 Temporal Flickering、Subject/Background Consistency、Motion Smoothness、Dynamic Degree、Aesthetic Quality
- User Study:40 人参与,8 个 prompt,每个 prompt 4 个模型生成的 1 分钟视频,排序评估
4.3 Baselines
- Bidirectional:LTX-Video (1.9B)、Wan2.1 (1.3B)
- AR Models:SkyReels-V2 (1.3B)、MAGI-1 (4.5B)、CausVid (1.3B)、NOVA (0.6B)、Pyramid Flow (2B)、Self Forcing (1.3B)、Self Forcing++ (1.3B)、LongLive (1.3B)、Rolling Forcing (1.3B)
5. Experimental Results (实验结果)
5.1 短视频质量 (VBench 5s)
| Model | Params | Total | Quality | Semantic |
|---|---|---|---|---|
| LTX-Video | 1.9B | 80.00 | 82.30 | 70.79 |
| Wan2.1 | 1.3B | 84.26 | 85.30 | 80.09 |
| SkyReels-V2 | 1.3B | 82.67 | 84.70 | 74.53 |
| MAGI-1 | 4.5B | 79.18 | 82.04 | 67.74 |
| CausVid | 1.3B | 81.20 | 84.05 | 69.80 |
| Self Forcing | 1.3B | 83.00 | 83.71 | 80.14 |
| LongLive | 1.3B | 83.52 | 84.26 | 80.53 |
| Self Forcing++ | 1.3B | 83.11 | 83.79 | 80.37 |
| Rolling Forcing | 1.3B | 81.22 | 84.08 | 69.78 |
| VideoSSM | 1.4B | 83.95 | 84.88 | 80.22 |
关键发现: VideoSSM 在 Total (83.95) 和 Quality (84.88) 上均为 AR 模型最高分,超越了 4.5B 参数的 MAGI-1 和同等规模的 LongLive。Semantic 分数 (80.22) 略低于 LongLive (80.53),但整体最优。
5.2 长视频生成 (60s)
| Metric | Self Forcing | LongLive | VideoSSM |
|---|---|---|---|
| Temporal Flickering | 97.86 | 97.24 | 97.70 |
| Subject Consistency | 88.25 | 91.09 | 92.51 |
| Background Consistency | 91.73 | 93.23 | 93.95 |
| Motion Smoothness | 98.67 | 98.38 | 98.60 |
| Dynamic Degree | 35.00 | 37.50 | 50.50 |
| Aesthetic Quality | 60.02 | 55.74 | 60.45 |
关键发现:
- VideoSSM 在 Subject Consistency 和 Background Consistency 上均为最优,证明 hybrid memory 有效防止了长程 drift
- Dynamic Degree (50.50) 远超 LongLive (37.50) 和 Self Forcing (35.00),说明 VideoSSM 在保持一致性的同时不会陷入静态/冻结输出
- 这是本文最核心的结果:一致性 + 动态性的平衡,正是 hybrid memory 相比 attention sink 的本质优势
5.3 定性对比

Figure 6 解读: 60 秒长视频的定性对比。Burger 场景中:VideoSSM 全程保持汉堡的结构和光照一致性;Self Forcing 出现严重 drift;SkyReels-V2 画面完全崩溃。Underwater 场景中:VideoSSM 成功捕捉动态游泳运动并保持主体一致性;CausVid 运动停滞,小男孩近乎静止;LongLive 由于 attention sink 导致幻觉出第二个人物实例。这充分验证了 dynamic global memory 相比 static sink 的优势。
5.4 Interactive 视频生成

Figure 7 解读: 展示 interactive long video generation 能力。通过 KV recache 机制,用户可以在生成过程中切换 prompt(如”小男孩在草地上玩耍” → “向前奔跑” → “跳跃”),VideoSSM 实现了平滑、自然的语义过渡,同时保持场景连贯性。这是 AR 模型天然支持的能力,但 VideoSSM 的 hybrid memory 使得长时间交互控制更加稳定。
5.5 用户研究
| Model | Rank 1 (%) | Rank 2 (%) | Rank 3 (%) | Rank 4 (%) | Avg Rank |
|---|---|---|---|---|---|
| Self Forcing | 11.79 | 13.21 | 23.21 | 51.79 | 3.18 |
| CausVid | 7.50 | 16.07 | 42.14 | 34.29 | 3.03 |
| LongLive | 39.64 | 36.43 | 15.00 | 8.93 | 1.92 |
| VideoSSM | 41.07 | 34.29 | 19.64 | 5.00 | 1.85 |
关键发现: VideoSSM 获得最多 Rank 1 投票 (41.07%) 和最低平均排名 (1.85)。LongLive 虽然也获得较好排名 (1.92),但其 Dynamic Degree 低,用户体验更偏向”稳定但无趣”。VideoSSM 实现了 高动态性 + 高一致性 的最佳用户体验。
5.6 核心结论
- Hybrid State-Space Memory 是解决 AR 长视频生成中 error accumulation / drift / repetition 的有效方案
- SSM 作为 动态演化的全局记忆 优于 attention sink 的静态锚点设计
- Position-aware router 使模型在序列早期依赖 local memory,后期逐渐融入 global memory
- 两阶段蒸馏训练(causal distillation + long video DMD)实现了从 5 秒训练到 60 秒推理的 train-short test-long 泛化
- 整体复杂度保持 O(TL),线性可扩展