VGGT-Ω
Paper: arXiv:2605.15195 Code: facebookresearch/vggt-omega Code reference:
main@c337ad0f(2026-05-15)
1. Motivation (研究动机)
VGGT 这类 feed-forward reconstruction model 已经能在无需 bundle adjustment 的情况下,从多张图像直接预测 camera pose 与 depth,并且其 geometry-aware feature 对下游任务有价值;但原始 VGGT 在三点上受限:一是训练/推理内存高,尤其 dense head 和跨帧 global attention 需要缓存大量 high-resolution feature;二是主要面向静态场景,遇到真实视频里的动态物体时,camera motion 与 scene motion 容易耦合;三是 3D reconstruction 的 scaling law 还没有像 LLM/vision foundation model 那样被系统验证。
本文要解决的具体问题是:能否把 feed-forward reconstruction 扩展到 10B 参数、约 2M sequence 的规模,同时保持或提升静态/动态场景的 camera pose 与 depth 质量,并让中间 register 表征能服务 VLA、language alignment、motion-aware analysis 等下游任务。
这个问题值得研究,因为 reconstruction 可以成为 3D spatial understanding 的 proxy task:如果模型能从大规模视频中学习稳定的 geometry prior,那么它不仅能输出显式 3D 信息,还能提供比 2D backbone 更空间感知的 representation,为 embodied AI、world model、VLA、novel view synthesis 等任务提供通用基础特征。
2. Idea (核心思想)
核心洞察:不是简单给 VGGT 堆更多参数,而是把跨帧信息交换压缩到 camera/register tokens,并用训练-only 的多任务损失替代多个昂贵 dense prediction heads。这样模型仍能在 register 中聚合全局 scene information,但训练/推理只需少量关键 token 和少量 cached layer。
VGGT-Ω 的关键创新是三件事叠加:用 DINOv3 初始化并 scaling 到 200M/500M/1B/10B;把 25% 的 global attention layer 替换为 register attention,只让 camera/register tokens 跨帧交互;构建保守的视频 annotation pipeline 与 teacher-student self-supervised protocol,把动态视频纳入训练。
与 DA3/MegaSaM 等对比,VGGT-Ω 的根本差异在于它不是 test-time optimization 或 dynamic point map 的专门系统,而是一个 feed-forward Transformer:一次 forward 同时输出 cameras 和 depth。与原始 VGGT 对比,它少了冗余 dense heads 和高分辨率卷积层,换来可扩展的训练内存与更强动态场景泛化。
3. Method (方法)
3.1 Overall framework
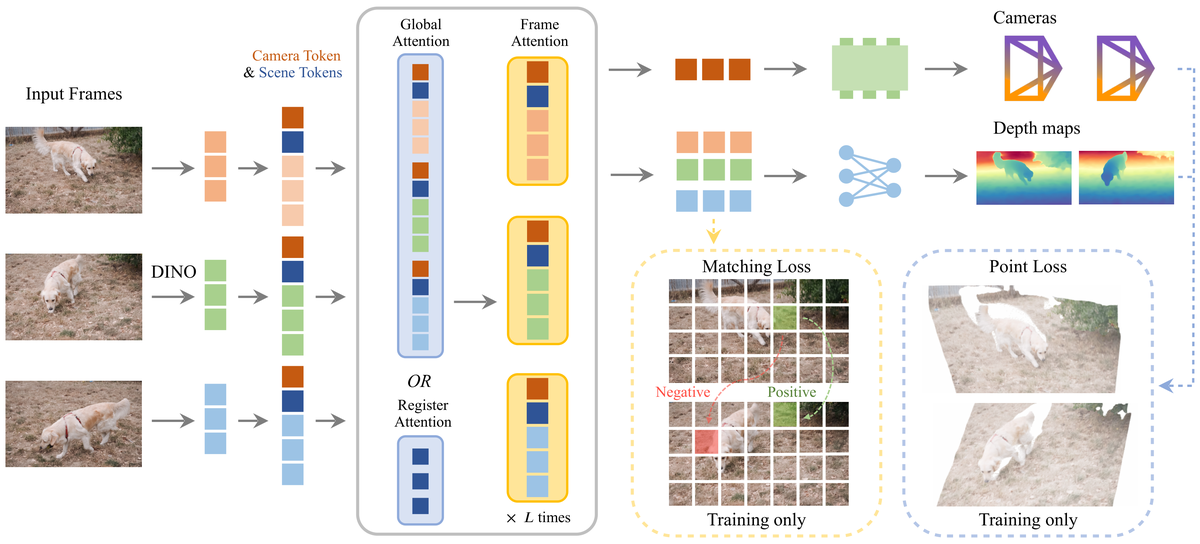
Figure 2 解读:左侧输入多帧图像,经 DINOv3 tokenization 得到 patch tokens;每帧额外拼接一个 camera token 与 16 个 scene/register tokens。中间 alternating attention block 在 frame-wise attention 与 global/register attention 之间交替。右侧只在输出端预测 camera 与 depth;matching loss 和 point loss 是 training-only supervision,不作为推理时 dense head 输出,从而减少冗余 head 与缓存。
形式化地,模型从 张输入图像 预测:
其中 是第 帧 depth map, 包含 rotation quaternion 、translation 和 field of view 。每帧 token 由 patch feature 、camera token 与 16 个 scene tokens 拼接而成。
3.2 Architecture components
Tokenization 与 alternating attention。 每张图像由 DINOv3-initialized ViT tokenized,patch size 为 16;release code 的 Aggregator 默认 embed_dim=1024、depth=24、num_heads=16、num_register_tokens=16,并缓存第 4/11/17/23 层输出给 prediction heads。每个 block 先做 frame-wise attention,再做跨帧 attention。
Register attention。 原始 global attention 对所有帧所有 token 做 self-attention,计算/显存随总 token 数二次增长。VGGT-Ω 观察到 VGGT 的 global attention 很稀疏,因此把部分跨帧 attention 限制到 camera/register tokens:
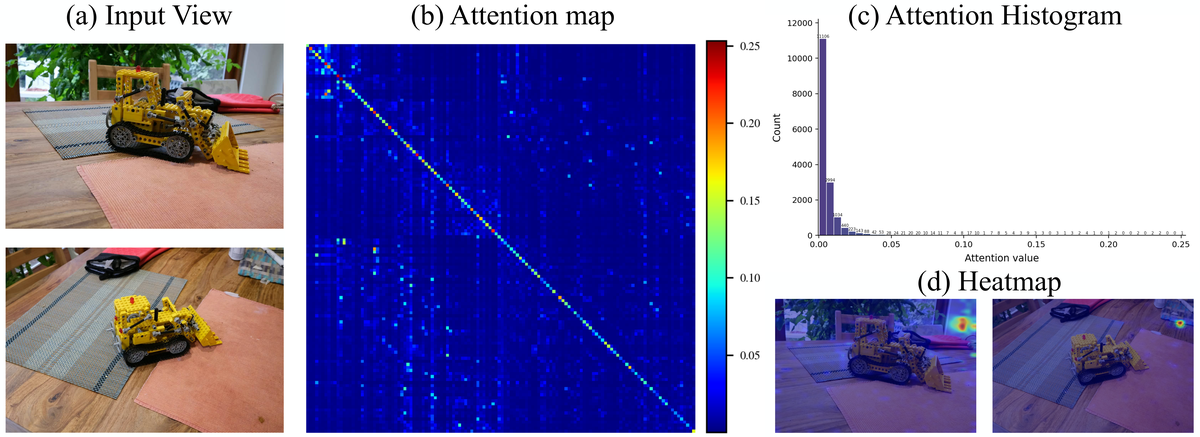
Figure 3 解读:图中展示 VGGT 第 13 层 global attention 的输入视角、attention map、value histogram 和 heatmap;大部分 attention value 接近 0,说明跨帧信息交换并不需要所有 image patch 两两交互。VGGT-Ω 因此让 registers 充当跨帧 bottleneck:registers 先汇聚场景级信息,后续 frame attention 再把信息分发回每帧 patch tokens。
Decoding。 Depth head 采用单个 dense head 产生 depth 与 confidence:release code 中 DenseHead 从 cached layers 取多尺度特征,经 projection、feature fusion、pixel_shuffle 输出 depth = exp(depth_logits) 与 depth_conf = 1 + exp(confidence_logits)。Camera head 不做 iterative refinement,而是对 camera/register tokens 运行 4 个 head-local transformer blocks 后,用 MLP 一次输出 9 维 pose encoding。
3.3 Training losses
VGGT-Ω 不直接预测 point maps/tracks,但用 training-only losses 监督这些几何量,总损失为:
Camera loss 使用 比较预测 camera 与 ground truth :
Depth loss 沿用 VGGT 的 aleatoric uncertainty 与 gradient consistency,并对相对尺度做调整:
其中 , 是 predicted uncertainty map, 是 element-wise product。Point loss 将 depth 和 camera 参数反投影成 point map 后,用类似 depth loss 的 residual:。Matching loss 施加在最后 attention layer 的 tokens 上,把同一 3D location 的 positive token pairs 拉近,把 negative pairs 推远:
3.4 Dynamic reconstruction 与 training data

Figure 数据流程解读:VGGT-Ω 先汇集公开数据集与内部数据,再对粗糙互联网视频做保守筛选。VLM pre-filter 会丢弃多 clip、极端 motion blur、水印/overlay 等不适合 reconstruction 的视频;Grounding DINO 标注可动物体并在 matching/tracking/verification 中排除动态区域;随后用 feature matching/tracking、COLMAP、multi-view consistency 与 supervised geometric filtering 生成高置信 camera/depth pseudo labels。
训练数据包含约 3M sequences 的已有公开/内部数据,单个 sequence 约 10 到 20,000 张图像;新 annotation pipeline 额外从约 40M internet-style videos 中得到约 200K dynamic scenes 与 600K static scenes 的高质量 camera/depth annotations。公开数据来源包括 Aria series、Bedlam、BEHAVIOR-1K、Co3Dv2、uCo3D、DL3DV、Dynamic Replica、EDEN、EFM3D、HOT3D、Habitat、Hypersim、Mapfree、Mapillary Metropolis、MPSD、Megadepth、Megasynth、Mid-Air、MVSSynth、ParallelDomain-4D、Replica、SAIL-VOS、ScanNet Series、TartanAirV2、TartanGround、Taskonomy、UnrealStereo4K、Virtual KITTI、Waymo 和 WildRGBD;论文明确排除了 Kubric 与 PointOdyssey,因为背景 geometry fake 且 depth invalid。
3.5 Self-supervised learning
Self-supervised stage 使用 teacher-student 策略。Student 通过 gradient descent 更新,teacher 仅用 EMA 更新:
两者都从 supervised VGGT-Ω checkpoint 初始化,同一视频帧集合分别施加 color jitter、blur、随机 rotation、random patch masking 与 random frame reordering。Student 要在 common order 中匹配 teacher:一方面用 feature-matching loss 对齐多层 tokens,另一方面用 regression losses 监督 camera 与 depth。为避免 collapse,camera/depth heads 在 self-supervised 阶段被冻结。
3.6 为什么有效:intuition
VGGT-Ω 的设计把“全局几何理解”和“每像素输出”解耦:registers 负责跨帧、场景级、语义/几何混合的信息汇聚;patch tokens 保留局部结构并通过 frame-wise attention 接收 register 汇总的信息。这样一方面不会像 global attention 那样让所有 patch 之间无差别通信,另一方面也不会像只输出 point map 的方法那样把 camera motion 和 object motion 强耦合。动态视频里的 moving pixels 被 annotation pipeline 保守过滤,模型训练时仍看到大量动态场景上下文,于是可以学习到“哪些 motion 是 camera,哪些 motion 是 scene”的统计 prior。
3.7 Pseudocode based on released code
Code reference:
main@c337ad0f(2026-05-15) — pseudocode and mapping based on this commit. Released code is inference-focused and contains no training launch script/loss implementation; training losses/config below are therefore marked as paper-derived when not present in code.
Aggregator / alternating attention + register attention
import torch
import torch.nn as nn
class AggregatorSketch(nn.Module):
def __init__(self, patch_embed, frame_blocks, inter_blocks, camera_token, register_token):
super().__init__()
self.patch_embed = patch_embed
self.frame_blocks = frame_blocks
self.inter_blocks = inter_blocks
self.camera_token = camera_token # [1, 2, 1, C]
self.register_token = register_token # [1, 2, 16, C]
self.patch_token_start = 1 + 16
self.register_blocks = {2, 6, 9, 14, 20}
self.cached_layers = {4, 11, 17, 23}
def forward(self, images):
B, T, C, H, W = images.shape
x = normalize_for_resnet(images).reshape(B * T, C, H, W)
patch_tokens = self.patch_embed(x) # [B*T, P, C]
camera = expand_token(self.camera_token, B, T)
registers = expand_token(self.register_token, B, T)
tokens = torch.cat([camera, registers, patch_tokens], dim=1)
cached = []
for layer_id, (frame_block, inter_block) in enumerate(zip(self.frame_blocks, self.inter_blocks)):
tokens = tokens.view(B * T, -1, tokens.shape[-1])
tokens = frame_block(tokens, rope_for_patch_grid(H, W))
frame_tokens = tokens.view(B, T, -1, tokens.shape[-1])
tokens = frame_tokens
if layer_id in self.register_blocks:
cr = tokens[:, :, :self.patch_token_start].reshape(B, T * self.patch_token_start, -1)
patches = tokens[:, :, self.patch_token_start:].reshape(B, -1, tokens.shape[-1])
cr = inter_block(cr, rope_sincos=None)
tokens = torch.cat([cr, patches], dim=1)
tokens = unflatten_camera_register_and_patch(tokens, B, T, self.patch_token_start)
else:
tokens = tokens.reshape(B, T * tokens.shape[2], tokens.shape[-1])
tokens = inter_block(tokens, rope_sincos=None).view(B, T, -1, tokens.shape[-1])
cached.append(torch.cat([frame_tokens, tokens], dim=-1) if layer_id in self.cached_layers else None)
return cached, self.patch_token_startCamera head
class CameraHeadSketch(nn.Module):
def forward(self, aggregated_tokens, patch_token_start):
tokens = aggregated_tokens[-1].float() # [B, T, tokens, 2C]
camera_and_register = layer_norm(tokens[:, :, :patch_token_start])
B, T, K, C = camera_and_register.shape
x = camera_and_register.reshape(B, T * K, C)
for block in self.trunk: # 4 SelfAttentionBlock in released code
x = block(x, rope_sincos=None)
x = x.reshape(B, T, K, C)
camera_token = self.trunk_norm(x[:, :, 0])
pose_enc = apply_camera_activation(self.camera_branch(camera_token))
return pose_enc # [B, T, 9]Dense depth head
class DenseHeadSketch(nn.Module):
def forward(self, aggregated_tokens, images, patch_token_start, chunk_size=8):
depth_chunks, conf_chunks = [], []
for start in range(0, images.shape[1], chunk_size):
end = min(start + chunk_size, images.shape[1])
multi_scale = []
for layer_tokens, project, resize in zip(aggregated_tokens, self.projects, self.resize_layers):
if layer_tokens is None:
continue
x = layer_tokens[:, start:end, patch_token_start:].float()
x = self.norm(flatten_batch_frames(x))
x = tokens_to_feature_map(x)
multi_scale.append(resize(add_uv_position(project(x))))
fused = self.scratch_forward(multi_scale)
depth_logits = pixel_shuffle(self.proj(add_uv_position(fused)), upscale_factor=4)
conf_logits = pixel_shuffle(self.proj_conf(fused), upscale_factor=4)
depth_chunks.append(torch.exp(depth_logits))
conf_chunks.append(1.0 + torch.exp(conf_logits.squeeze(-1)))
return torch.cat(depth_chunks, dim=1), torch.cat(conf_chunks, dim=1)Language alignment head
class TextAlignmentHeadSketch(nn.Module):
def forward(self, aggregated_tokens, patch_token_start):
tokens = aggregated_tokens[-1].float()
B, T, _, C = tokens.shape
cr_tokens = self.token_norm(tokens[:, :, :patch_token_start]).reshape(B, T * patch_token_start, C)
language_token = self.language_token.expand(B, 1, C)
readout = torch.cat([language_token, cr_tokens], dim=1)
for block in self.readout_blocks:
readout = block(readout, rope_sincos=None)
embedding = self.embedding_projector(self.language_token_norm(readout[:, 0]))
return torch.nn.functional.normalize(embedding, dim=-1)3.8 Code-to-paper mapping
Code reference:
main@c337ad0f(2026-05-15) — pseudocode and mapping based on this commit.
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| VGGT-Ω inference wrapper | vggt_omega/models/vggt_omega.py | VGGTOmega.forward |
| Alternating attention encoder | vggt_omega/models/aggregator.py | Aggregator.forward, _run_frame_block, _run_inter_frame_attention_block |
| Register attention | vggt_omega/models/aggregator.py | register_attention_block_indices=[2,6,9,14,20], num_register_tokens=16 |
| Camera prediction | vggt_omega/models/heads/camera_head.py | CameraHead.forward |
| Dense depth/confidence prediction | vggt_omega/models/heads/dense_head.py | DenseHead.forward, _forward_impl |
| Language/register alignment readout | vggt_omega/models/heads/text_alignment_head.py | TextAlignmentHead.forward |
| Pose encoding conversion utilities | vggt_omega/utils/pose_enc.py | pose_encoding_to_extri_intri |
论文公式与 released code 实现差异:论文描述完整训练 pipeline、losses、annotation 与 self-supervised learning;released GitHub commit c337ad0f 仅包含 inference model、heads 与 utilities,没有训练 loss、annotation pipeline 或 launch/config 文件。因此 §3.3/§3.5 的 loss 与 training details 来自论文正文,而不是 released code。
4. Experimental Setup (实验设置)
Datasets and scale. 训练侧:论文收集多种公开/内部数据,共约 3M sequences,每个 sequence 10–20,000 张图像;新 annotation pipeline 从约 40M internet-style videos 中产出约 200K dynamic scenes 与 600K static scenes。评测侧:camera/depth benchmark 使用 3 个 static datasets(7 Scenes、NRGBD、ETH3D)与 3 个 dynamic datasets(DyCheck、Sintel、TUM-Dynamic),每个 scene/sequence 随机采样 10 frames。VLA 应用使用 LIBERO benchmark;language alignment 使用 100 个 manually curated internet videos。
Baselines. Camera/depth 比较 MonST3R、MapAnything、MegaSaM、VGGT、PI3、DA3;qualitative comparison 包括 MegaSaM 与 Depth Anything 3;LIBERO 表中比较 Diffusion Policy、TraceVLA、Octo、OpenVLA、Dita、CoT-VLA、-FAST、、UniVLA、OpenVLA-OFT。
Metrics. Camera pose 使用 AUC@3° 和 AUC@30°,即 relative rotation/translation error 低于角度阈值的 image pairs fraction 曲线面积,越高越好。Depth 使用 (预测 depth 与 GT depth ratio 在 1.25 factor 内的像素百分比,越高越好)和 AbsRel(mean absolute relative error,越低越好)。Joint camera-depth scaling 使用 point error:将 depth 用 camera unproject 到 3D 后与 GT point 比较 distance。
Training config. 论文测试 200M、500M、1B、10B 四个模型,分别使用 12/12/24/16 个 alternating-attention blocks,hidden sizes 为 384/768/1024/4096;vision transformer 从 DINOv3 初始化且训练时不冻结。优化器为 AdamW,共 240K iterations:160K supervised、50K self-supervised、30K final supervised。学习率 5% warm-up + 95% cosine decay;peak LR 为 supervised 、self-supervised 。每个 batch 的 frame 数从 均匀采样;图像增强包括 aspect ratio 、面积约 、color jitter、grayscale conversion、random patch masking。训练使用 128 张 96GB H100 GPUs、bfloat16 mixed precision、gradient checkpointing 和 FSDP。Released repo 未提供训练 launch/config 文件,上述数字来自论文 §4.1 Implementation Details。
5. Experimental Results (实验结果)
5.1 Scaling with model/data size
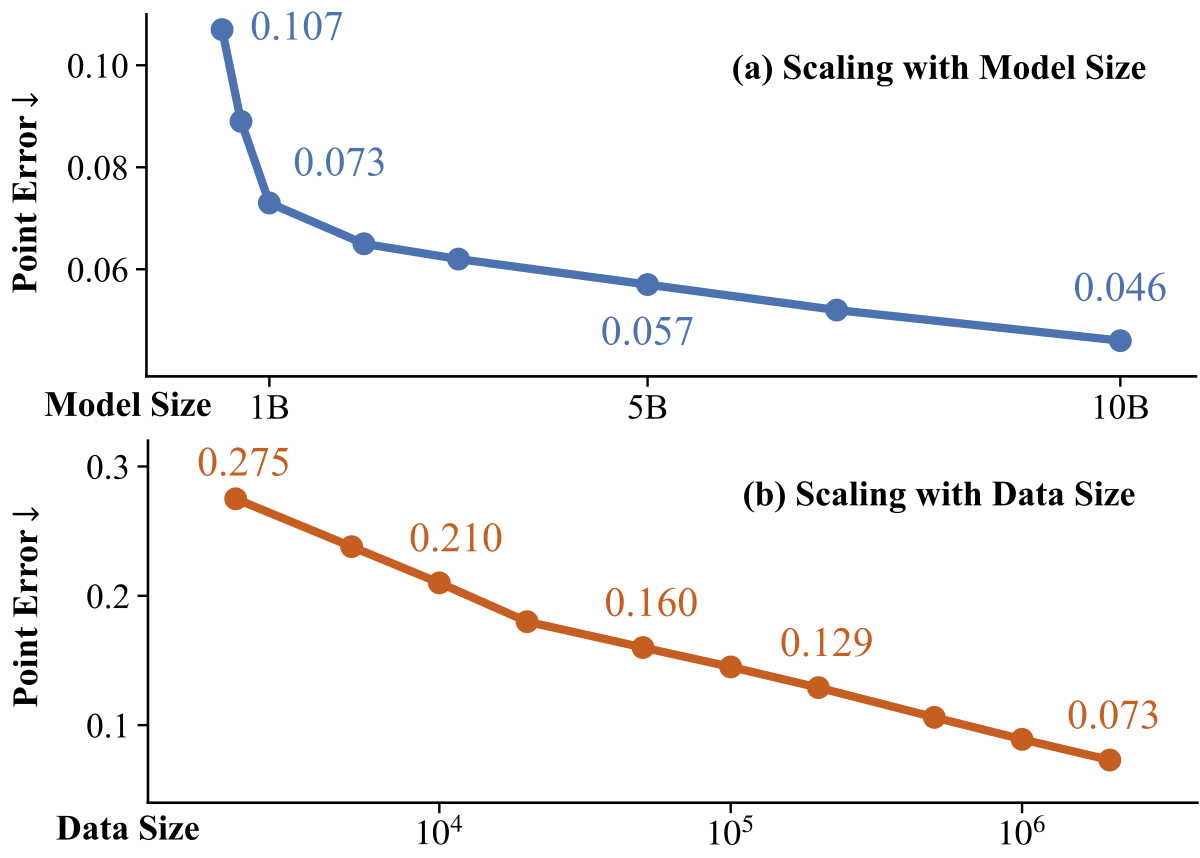
Figure 1 解读:当模型规模从 0.2B 扩到 10B、数据从 2K 扩到 2M sequences 时,平均 3D point error 稳定下降。论文明确给出数据规模从 2K 到 2M 时 point error 从 0.275 降到 0.073;10B 模型的曲线也优于小模型,说明 feed-forward reconstruction 在规模上呈现可预测收益。
5.2 Main camera/depth benchmark numbers
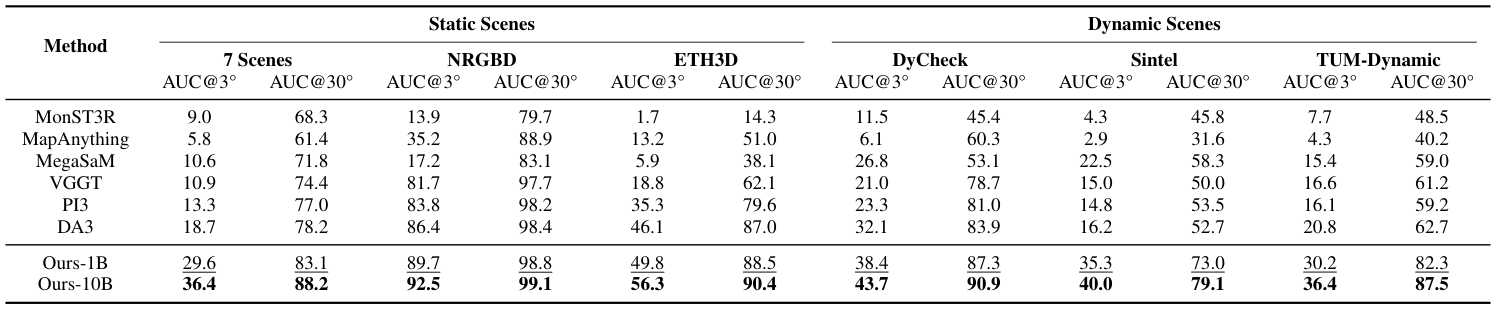
Table 1 解读:VGGT-Ω 在所有 6 个 static/dynamic benchmarks 和严格/宽松阈值上都超过 baselines。最突出的例子是 Sintel AUC@3° 从 MegaSaM 的 22.5 提升到 Ours-10B 的 40.0,相对提升 77%;ETH3D AUC@30° 从 DA3 的 87.0 提到 90.4;TUM-Dynamic AUC@30° 从 DA3 的 62.7 提到 87.5。
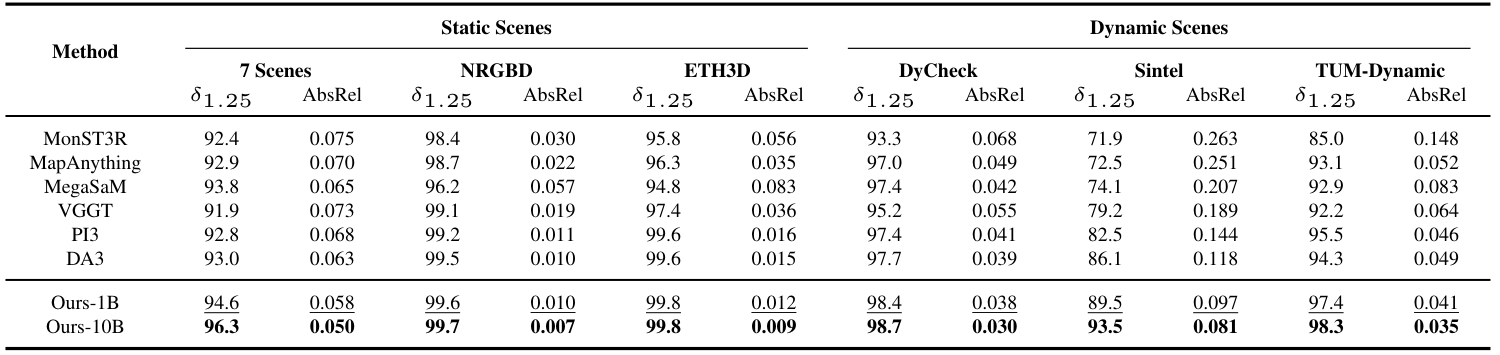
Table 2 解读:Depth 上 Ours-10B 同样领先。Sintel 的 从 DA3 的 86.1 提到 93.5,AbsRel 从 0.118 降到 0.081;TUM-Dynamic 的 为 98.3、AbsRel 为 0.035;静态 NRGBD 上 AbsRel 达到 0.007,ETH3D 上 AbsRel 达到 0.009。
5.3 Qualitative and efficiency results

Figure 4 解读:VGGT-Ω 能处理交通流、网球运动、海岸、珊瑚礁等静态/动态场景;输入帧数分别覆盖 64、4、9、16、32,说明模型能接受 variable number of frames,且不依赖固定 temporal order。

Figure 5 解读:MegaSaM 在稀疏动态、航拍、强 camera roll 场景下出现 geometric drift、texture smearing 和重复结构;VGGT-Ω 的结果更全局一致。右侧室内/人运动例子也说明模型对 sparse input 和 non-upright frames 更稳健。

Figure 6 解读:DA3 在雪地缆车序列中受重复纹理影响,几乎无法估计正确 camera trajectory;在强 roll 的塔楼航拍中生成 ghosting 与重复塔结构。VGGT-Ω 保持较一致的全局 geometry,说明 reconstruction-specific training 比纯 depth prior 更适合多视角一致性。
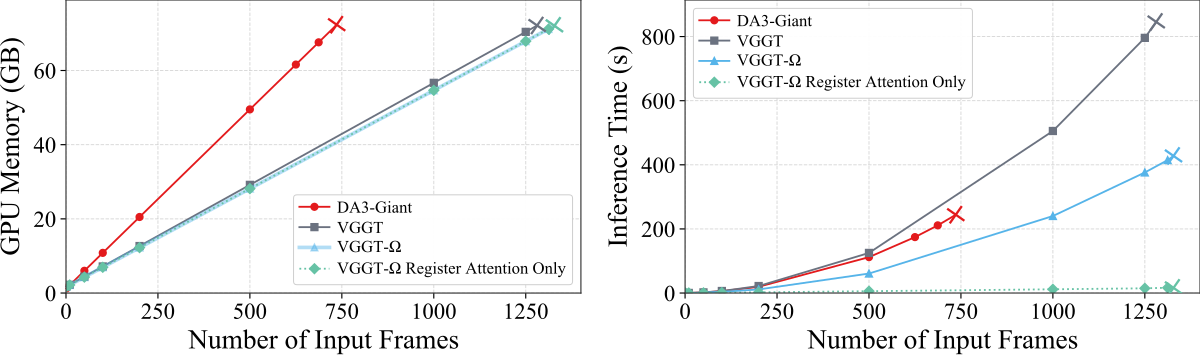
Figure 7 解读:在单张 80GB A100、flash attention v2 下,VGGT 与 VGGT-Ω 可处理约 1250 frames,而 DA3 在约 750 frames 时 out of memory。VGGT-Ω 更快的原因不是显存峰值大幅下降,而是 DINOv3 的 patch size 16 比 VGGT/DA3 的 14 减少约 25% image tokens,并且默认把 25% global attention 替换为 register attention,带来约 20–25% speedup;全 register-attention variant 可把 1000 frames runtime 从 240.2s 降到 11.7s,但会损失 reconstruction accuracy。
5.4 Ablations and applications
Register attention ablation:只用 global attention 的 point error 为 0.071;将 25% global attention 替换为 register attention 后,point error 约 0.073,性能几乎不变但训练/推理更高效。若全部使用 register attention,只保留 registers 跨帧交互,可把 FLOPs 降到原模型 6%,但性能回落到原始 VGGT 水平,适合 on-device trade-off 探索。
Multi-task learning ablation:移除 point 与 matching losses 后,point error 从 0.073 升到 0.078;采用原 VGGT 多 dense-head/multi-task setup 可达 0.070,但需要多个 dense heads、scaling 更困难。Self-supervised training ablation:把 10% training steps 从 supervised 换为 self-supervised 后,point error 从 0.073 降到 0.070,并改善 out-of-distribution generalization。
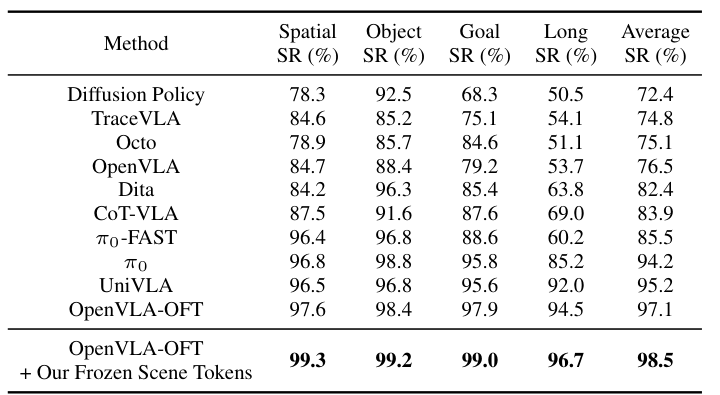
Table 3 解读:冻结 VGGT-Ω 后将 scene tokens 作为额外输入给 OpenVLA-OFT,LIBERO average SR 从 97.1% 提到 98.5%,Spatial/Object/Goal/Long SR 分别达到 99.3/99.2/99.0/96.7,说明 registers 聚合的空间信息能直接增强 VLA policy。
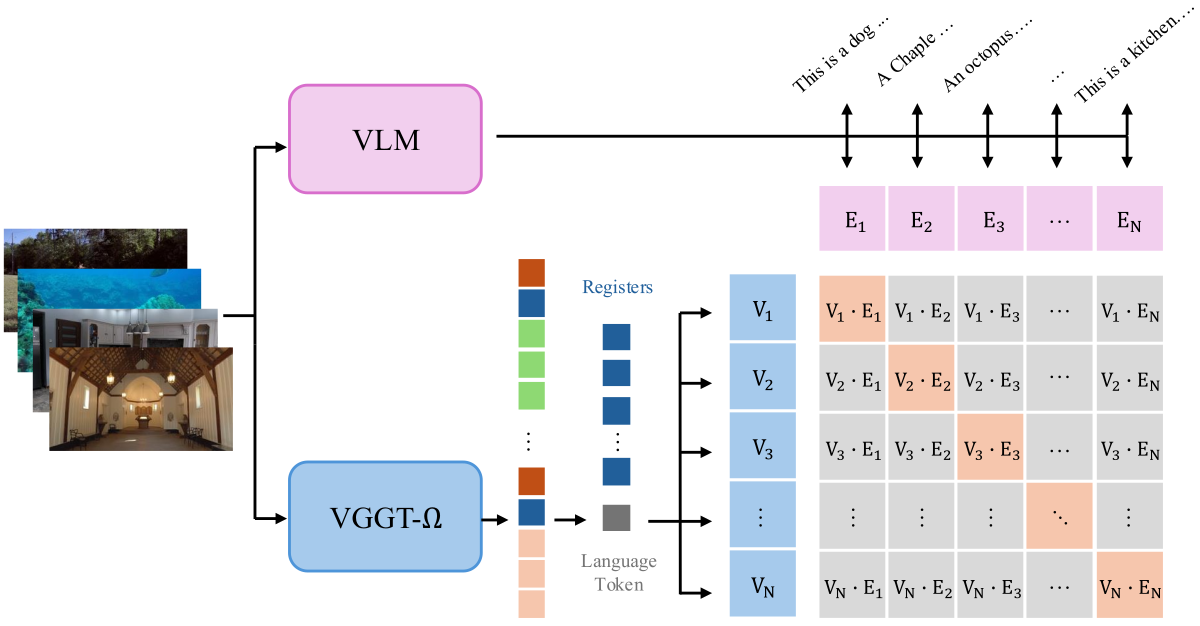
Figure 8 解读:VLM 对 sequence 生成文字描述并 mean-pool hidden states,VGGT-Ω 端用一个 learnable language token 从 registers 读出 embedding;二者用 symmetric InfoNCE 在 global batch 上对齐。只训练 10K iterations 后,用训练时 VLM embedding 检索可达 76.8% top-1 / 97.0% top-3;换成 text-only LLM embedding 且不再训练,也有 47.5% top-1 / 77.8% top-3,说明 registers 带有可语言对齐的 high-level scene information。

Figure 9 解读:对 intermediate image tokens 做 PCA 降维和 -means 聚类,不使用 labels、optical flow 或 learned probe,clusters 仍能把 moving dancer 与 static crowd/background 分开;早期层 motion segmentation 最清晰,中层保留较弱 motion signal,深层更语义化。作者把这视为 reconstruction objective 自动诱导 motion-aware representation 的证据。
5.5 Limitations and conclusions
作者承认若在原始 architecture 上加入更多 task-specific tweaks(例如 iterative camera refinement、向 dense head 注入 raw RGB)还可提升约 4–6% AUC@3° 和约 2% ,但他们刻意优先保持 base model 简洁,以便研究 scaling 与 representation。MLP-only dense head 虽更快更省内存,但会产生 patch/block artifacts,因此最终仍保留少量低分辨率 convolutional DPT layers。Self-supervised reconstruction 仍未完全解决,作者尝试 image token masking、temporal-order variants、RayZer/E-RayZer 风格合成等方案,只有 teacher-student 方法有效。
总体结论:VGGT-Ω 证明 feed-forward reconstruction 可以像 foundation model 一样从模型/数据 scaling 中获益;register attention、单 dense head + training-only multi-task losses、保守动态视频 annotation、自监督阶段共同让模型在静态/动态 3D benchmark 上刷新结果,并产出能迁移到 VLA、language alignment 与 motion-aware analysis 的 scene-level registers。