MultiWorld - Scalable Multi-Agent Multi-View Video World Models
1. Motivation(研究动机)
- 现有方法的问题:多数 video world model 把环境动力学建模为「单用户/单 agent」条件下的视频生成:输入历史帧与当前动作,预测未来帧。这样隐含假设场景中只有一个 agent,难以刻画协作机器人、多人联机游戏中同时作用、相互依赖的多 agent 交互;且每个 agent 对应不同视点,必须在不同视角的局部观测之间保持几何与外观一致,而以往工作常在多视角间出现割裂。
- 本文要解决的问题:在统一框架内实现多 agent 精确可控(每帧联合动作与身份对齐)与跨视角一致的 multi-view 视频 world modeling,并支持 agent 数量与相机视角数量的可变扩展,以及多视角并行合成以降低延迟。
- 为何值得研究:一旦能在学习到的世界模型里稳定模拟多 agent + 多视角共享场景,可直接支撑游戏内容生成、具身 VLA 训练数据增广、多机协作策略评估等,而无需完全依赖重型游戏引擎或物理仿真器手工搭环境。
2. Idea(核心思想)
- 核心洞察:多 agent 世界建模的瓶颈不只是「把更多动作向量拼进条件」,而是**(1) 动作—身份对称性导致的控制混淆,以及(2) 各视角只看到局部、却共享同一 3D 场景这一结构;因此需要在条件路径上显式打破 agent 对称并在生成前压缩出共享的 3D 感知全局状态**,再把每个视角的生成视作「同一全局状态下的并行单视角任务」。
- 关键创新(1–3 句):提出 Multi-Agent Condition Module (MACM):用沿 agent 维的 RoPE 式 Agent Identity Embedding (AIE) 区分身份,再用 agent 间 self-attention 建模交互,并用 Adaptive Action Weighting (AAW) 突出当前帧「在动」的 agent;提出 Global State Encoder (GSE):以冻结的 VGGT 从多视角图像抽取隐式 3D 场景潜变量,经 MLP 对齐后跨 attention 注入 DiT。二者与 Flow Matching 及带因果掩码的动作 cross-attention 骨干结合,实现可扩展的多视角并行 rollout 与长程自回归块生成。
- 与典型路线的本质区别:相比「每视角各训一个单 agent 模型」的 Standard、把固定多视角拼进单一序列的 Concat-View(视角一多即显存爆炸)、以及组合单 agent 子模型却难建模交互的 COMBO,MultiWorld 用 GSE 把可变多视角压到共享全局条件,用 MACM 解决谁在执行动作,从设计上同时瞄准可控性、跨视角一致性与伸缩性。
3. Method(方法)
直觉说明(intuition)
如果把多 agent 动作简单堆在一起,Transformer 很难稳定回答「这一帧到底是 agent 1 往左还是 agent 2 往左」,镜像动作会混淆;AIE 相当于在身份维度上给每个 agent 一套可外推的相位旋转,使注意力内积自然依赖 agent 相对索引,从表示层面打破对称。另一方面,各相机只看到局部,若条件里只有「本视角上一帧」,模型容易在每个视角各自「编故事」;VGGT 类 3D foundation model 的多图编码,把多视角纳入同一场景的潜空间,GSE 再把它压成 DiT 可用的全局 token,相当于告诉扩散模型「大家都在同一个世界里」,从条件上约束几何一致。最后,多视角生成拆成共享全局状态的并行单视角 FM 问题,算力随视角近似线性扩展,便于并行;块自回归时用最新帧刷新 GSE,把误差累积控制在工程可用范围。
符号与 Flow Matching 骨干(Sec. 3.1)
考虑 个 agent、 个相机。第 个视角的视频记为 ,联合动作序列 ,其中 。环境观测 由各视角视频的初始帧构成(并随模拟更新)。
对每个视角 独立做 FM:采样 ,,
速度场 拟合 。对动作 cross-attention 使用按帧因果掩码:第 帧视频 token 只能看见 的动作,避免泄漏未来动作,利于长程自回归。
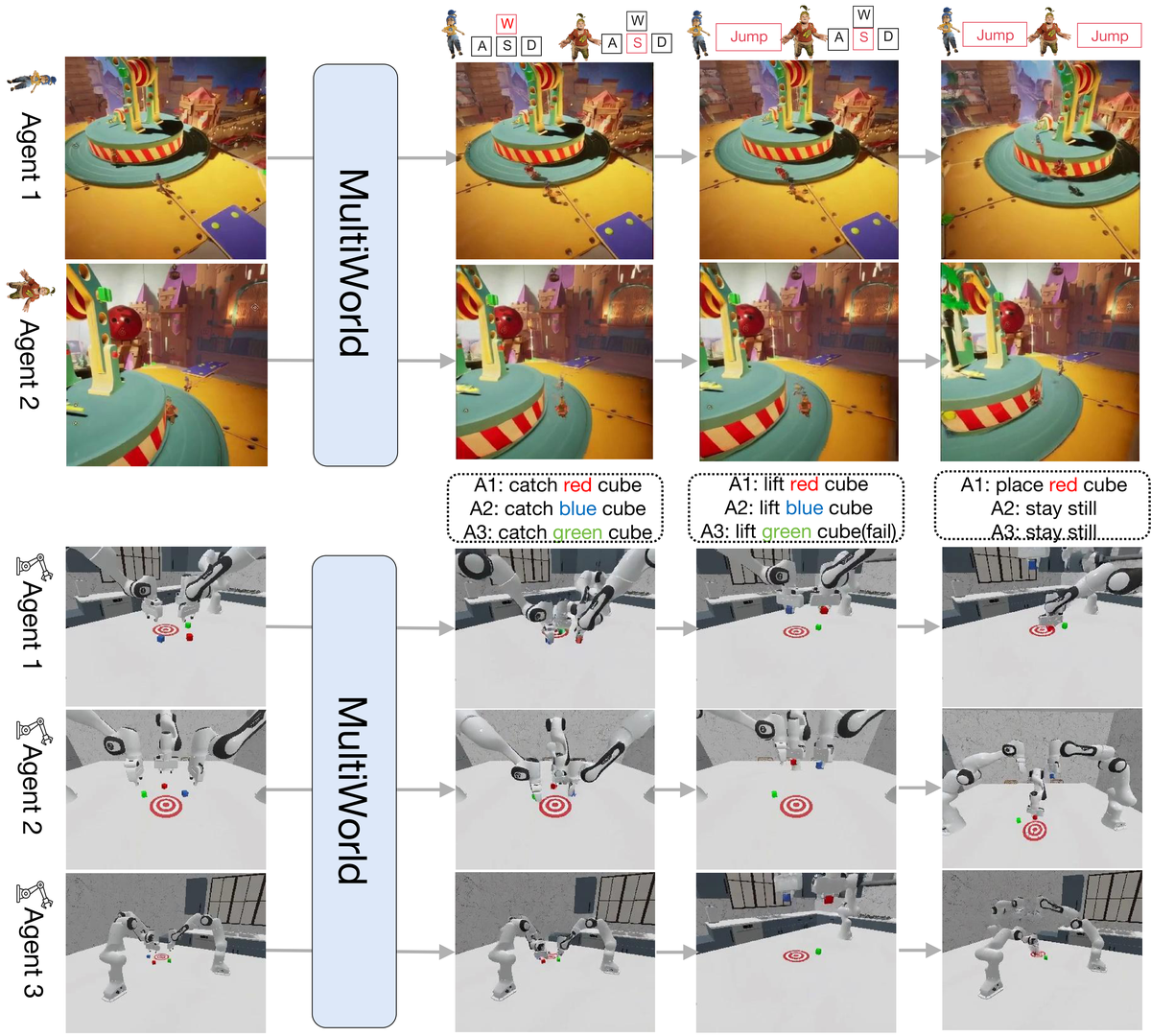
Figure 1 解读:展示 MultiWorld 在「双人游戏 + 三机械臂协作」两类设置下,给定多视角初始帧与每步 agent 控制(键位或语言指令),生成动作可控且跨视角一致的未来帧;强调 agent 数与视角数可大于 1 且控制信号异构。

Figure 2 解读:噪声视频经 DiT 块去噪;MACM 将多 agent 动作变为带身份与交互的 token,并经 AAW 聚合后因果注入;GSE 用冻结 VGGT 从多视角观测抽取隐式全局 3D 环境,经 MLP 对齐后跨 attention 条件化;不同视角在共享全局状态下并行生成,并支持块自回归延长时域。
Multi-Agent Condition Module(MACM,Sec. 3.2)
动机:(1) 身份歧义;(2) 部分 agent 静止、部分活跃时,均等对待会稀释有效动力学信号。
流程:动作嵌入为每 agent 的 latent → AIE(沿 agent 维 RoPE)→ agent 维 self-attention 建模交互 → AAW(MLP 预测权重,加权求和为每帧统一动作 token)→ 注入 DiT 的因果 cross-attention。
对 agent 的动作嵌入 ,AIE 为:
其中 由频率 的标准 RoPE 构造;二维旋转作用于维度对 。Agent 间注意力满足
使相对身份进入核函数,减轻镜像动作混淆。AAW 对每个 agent token 预测标量权重,softmax 或归一化后加权求和,突出当前帧主导变化的 agent。
Global State Encoder(GSE,Sec. 3.3)
给定同步多视角图像集合 ,:
通过 cross-attention 注入 DiT。论文强调不显式重建点云,而是利用 VGGT latent 中内嵌的 3D 结构先验,以共享全局表征约束多视角合成。
可扩展与并行多视角(Sec. 3.4)
- Agent 数:依赖 AIE 的相对身份嵌入外推,架构不随 改变形状(实现上需处理变长 agent 时的掩码与池化)。
- 视角数:GSE 将可变 压到统一全局条件;每个视角仍是独立的 FM 轨迹,但共享 ,从而可同步并行生成。论文报告双视角并行相对顺序生成约 加速(在可相应扩展算力时,延迟近似不随视角恶化)。
- 长程自回归:按块生成多视角视频,每块结束后用各视角最后一帧刷新 GSE 的全局状态,再滚动下一块;实验可在约 训练上下文长度上保持较小退化,并可达约 仅轻微质量损失。
伪代码(与开源实现一致)
下列伪代码分别对应 FM 条件生成、MACM 中 SoftmaxAgentPooling、以及 GSE(WanEnvEncoder)。实现细节以仓库为准。
import torch
import torch.nn.functional as F
from torch import nn
def flow_matching_velocity_loss(v_theta, x_c, actions, obs, noise_scale=1.0):
"""Single-view FM training objective for camera c (schematic)."""
b = x_c.shape[0]
t = torch.rand(b, device=x_c.device, dtype=x_c.dtype)
eps = torch.randn_like(x_c) * noise_scale
t_expand = t.view(b, *([1] * (x_c.ndim - 1)))
x_t = (1.0 - t_expand) * x_c + t_expand * eps
u_tgt = eps - x_c
u_pred = v_theta(x_t, t, actions, obs)
return F.mse_loss(u_pred, u_tgt)class SoftmaxAgentPooling(nn.Module):
"""MACM: agent-dim RoPE self-attention + adaptive softmax weights (repo-aligned)."""
def __init__(self, agent_attn: nn.Module, dim: int, adaptive_agent_pooling: bool = True):
super().__init__()
self.agent_attn = agent_attn
hidden = max(dim // 4, 1)
self.adaptive_agent_pooling = adaptive_agent_pooling
self.weight_proj = (
nn.Sequential(nn.Linear(dim, hidden), nn.GELU(), nn.Linear(hidden, 1))
if adaptive_agent_pooling
else None
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: [B, N, F, D] — N agents, F frames
x = self.agent_attn(x)
x = x.permute(0, 2, 1, 3) # [B, F, N, D]
if self.adaptive_agent_pooling:
logits = self.weight_proj(x) # [B, F, N, 1]
weights = torch.softmax(logits, dim=2)
return (x * weights).sum(dim=2) # [B, F, D]
return x.sum(dim=2)import torch
from torch import nn
from einops import rearrange
from diffsynth.models.vggt.models.vggt import VGGT
class WanEnvEncoder(nn.Module):
"""GSE: frozen VGGT trunk + trainable MLP connector (repo-aligned)."""
def __init__(self, input_dim: int = 2048, output_dim: int = 3072):
super().__init__()
self.env_encoder = VGGT.from_pretrained("facebook/VGGT-1B").eval()
for head in ("camera_head", "point_head", "depth_head", "track_head"):
delattr(self.env_encoder, head)
self.env_encoder.requires_grad_(False)
self.connector = nn.Sequential(
nn.Linear(input_dim, 2048),
nn.GELU(),
nn.Linear(2048, output_dim),
)
def forward(self, images: torch.Tensor) -> torch.Tensor:
# images: [B, F, K, 3, H, W]
b, f = images.shape[0], images.shape[1]
x = rearrange(images, "B F K C H W -> (B F) K C H W")
with torch.no_grad():
env_states_list, _ = self.env_encoder.shortcut_forward(x)
env_states_list = [torch.mean(t, dim=1) for t in env_states_list]
env_states = torch.stack(env_states_list, dim=1).mean(dim=1) # (B*F, N, L, D)
env_states = rearrange(env_states, "(B F) N L -> (B F N) L", B=b)
env_states = self.connector(env_states)
return rearrange(env_states, "(B F N) L -> B (F N) L", B=b, F=f)def parallel_multiview_rollout(model, init_obs_per_view, actions, num_views: int):
"""Inference sketch: shared global state, per-view FM sampling in parallel."""
global_tokens = model.encode_global_state(init_obs_per_view) # GSE
preds = []
for c in range(num_views):
preds.append(model.sample_view(latent_view_c=init_obs_per_view[c], actions=actions, global_tokens=global_tokens))
return preds # executed in parallel when batched on deviceCode reference:
main@437fabfd(2026-04-21) — 伪代码与映射基于该提交
| 论文概念 | 源码路径(节选) | 关键类/符号 |
|---|---|---|
| MACM(AIE + agent 交互 + AAW) | diffsynth/models/wan_video_robots_action.py | SoftmaxAgentPooling, AgentWiseSelfAttention, MultiAgentActionRoPE2D |
| 双人游戏动作编码 | diffsynth/models/wan_video_ittakestwo_action.py | WanActionEncoder |
| GSE(VGGT + MLP) | diffsynth/models/wan_env_encoder.py | WanEnvEncoder, WanDINOEnvEncoder(消融用) |
| VGGT 主干 | diffsynth/models/vggt/models/vggt.py | VGGT, shortcut_forward |
| FM / 训练编排 | diffsynth/diffusion/ | flow_match.py, training_module.py, runner.py |

Figure 3(补充材料风格)解读:大画幅多面板对比,用于展示 MultiWorld 与基线在动作跟随与跨视角对齐上的差异(具体面板以原论文排版为准);与正文 Fig. 3 的「Standard / Concat-View / COMBO / Ours」对比叙事一致。

Figure 4 解读:在 RoboFactory 风格多机操作里,MultiWorld 可生成协作失败(如相互阻挡、碰撞)的合理视频,用于增广难以采集的危险/失败轨迹数据。

Figure 5 解读:多块自回归延展序列,展示三机械臂按序叠放小方块时,MultiWorld 在超过训练上下文的长度上仍保持动作与几何连贯(正文给出约 与 观察)。

Figure 6 解读:宽版表格图,汇总 multi-player 与 multi-robot 设置下与 Standard / Concat-View / COMBO 的指标对比(FVD、LPIPS、SSIM、PSNR、Action、RPE);粗体/下划线标示最优与次优。

Figure 7 解读:宽版消融表,对应 MACM / GSE 组件、AIE 频率、AAW、以及 GSE 不同主干(Wan VAE / DINOv2 / VGGT)等设置;用于直观对照正文 Tab. 2–5 的结论趋势。
4. Experimental Setup(实验设置)
- 数据:(1) ItTakesTwo 真实双人游玩采集:原始约 500 小时 @60fps,清洗后保留约 100 小时(动作清晰、相机运动稳定),>2100 万帧,原始分辨率 2560×1440;(2) RoboFactory 仿真多机操作自建数据:2–4 个 agent、相机配置可变,数千 条 episode(细节见附录)。
- 基线:Standard(各视角独立 image-action-to-video);Concat-View(固定视角把多视角拼成单视频;标注 * 表示仅两相机训练,不可完全可比);COMBO(多阶段组合单 agent 子模型)。
- 指标:FVD(Fréchet Video Distance,越低越好);PSNR / SSIM / LPIPS(像素与感知质量);RPE(跨同步视角 reprojection error,越低表示几何一致越好);Action(IDM 准确率,沿用 VPT 流程,越高表示动作跟随越好)。
- 训练配置:骨干为 Wan2.2-5B; clip 81 帧;游戏每视角 320×320,机器人数据 320×256;40k iterations,lr=5e-5,cosine 调度,全局 batch size 64,8× NVIDIA A800,约 4 天。VGGT 冻结,仅训练连接器与 DiT 相关部分(与论文描述一致)。
5. Experimental Results(实验结果)
主表(Table 1,正文摘录)
Multi-Player Video Game
| Method | FVD↓ | LPIPS↓ | SSIM↑ | PSNR↑ | Action↑ | RPE↓ |
|---|---|---|---|---|---|---|
| Standard | 245 | 0.36 | 0.50 | 17.48 | 88.4 | 0.75 |
| Concat-View | 215 | 0.36 | 0.49 | 17.54 | 89.1 | 0.74 |
| Combo | 207 | 0.34 | 0.51 | 17.82 | 89.3 | 0.72 |
| Ours | 179 | 0.35 | 0.51 | 17.72 | 89.8 | 0.67 |
Multi-Robot Manipulation
| Method | FVD↓ | LPIPS↓ | SSIM↑ | PSNR↑ | Action↑ | RPE↓ |
|---|---|---|---|---|---|---|
| Standard | 100 | 0.07 | 0.90 | 26.39 | 88.2 | 1.60 |
| Concat-View* | 106 | 0.06 | 0.90 | 27.44 | 92.0 | 0.82 |
| Combo | 99 | 0.08 | 0.90 | 26.49 | 88.5 | 1.54 |
| Ours | 96 | 0.07 | 0.90 | 26.60 | 88.7 | 1.52 |
解读:MultiWorld 在两域多数指标上最优或次优;RPE 与 FVD 的增益尤其能说明 GSE 对跨视角一致性与视频统计质量的贡献。
消融(Table 2,架构组件)
| Config | FVD↓ | LPIPS↓ | SSIM↑ | PSNR↑ | Action↑ | RPE↓ |
|---|---|---|---|---|---|---|
| Standard | 245 | 0.36 | 0.50 | 17.48 | 88.4 | 0.75 |
| + MACM | 228 | 0.36 | 0.51 | 17.56 | 89.7 | 0.76 |
| Both | 179 | 0.35 | 0.51 | 17.72 | 89.8 | 0.67 |
其它消融要点(正文表格数值):AIE 频率: 时 FVD 234 / PSNR 17.53 / Action 89.2; 时 228 / 17.56 / 89.7。AAW:去掉 AAW 为 245 / 17.48 / 88.4,加入为 236 / 17.52 / 88.6。GSE 主干:无全局 228 / 0.36 / 0.51 / 17.56 / 0.75;Wan VAE 256 / 0.36 / 0.50 / 17.38 / 0.71;DINOv2 232 / 0.36 / 0.50 / 17.48 / 0.72;VGGT(Ours)179 / 0.35 / 0.51 / 17.72 / 0.67。
局限(作者自述)
- 当前训练规模仍受算力限制,大规模训练尚未充分探索。
- Future work:实时多 agent 生成;面向超长交互的时空记忆机制以降低长程 rollout 的资源压力。
结论
在多人游戏与多机操作两类可变 agent/视角设置下,MultiWorld 通过 MACM + GSE 在视频保真、动作跟随、多视角一致三方面同时较强基线更优,并给出可扩展的并行推理与块自回归长视频路径。