Generative World Renderer
一句话概括: 通过在 ReShade 图形 API 级别从两款 3A 游戏(Cyberpunk 2077 / Black Myth: Wukong)中拦截 G-buffer 渲染目标,构建 4M 帧、720p/30FPS、6 通道同步的连续视频数据集,用它同时微调 DiffusionRenderer(RGB→G-buffer,逆向渲染)和 Wan2.1(G-buffer+Text→RGB,游戏编辑),并提出基于 VLM 的无 GT 评估协议,弥补合成数据到真实世界的 domain gap。
1. Motivation (研究动机)
核心痛点:现有的生成式双向渲染(inverse rendering 与 forward rendering 的统一范式)受限于合成数据集的规模与真实度,无法 scale 到真实世界场景。
具体表现为:
- 数据瓶颈:以往数据集(如 InteriorNet、MatrixCity 等)多为静态相机、短片段、简化材质模型,缺少极端天气(雨雾雪)、长时序(分钟级)、真实动态场景(人车运动)。
- 域差距:在合成数据上训练的模型(如 NVIDIA DiffusionRenderer)在真实视频上存在:
- 复杂反射 / 光照无法去除(delighting 不彻底)
- 细粒度植被几何丢失
- 长序列下的时序闪烁(temporal flickering)
- 真实场景元素(人车)分解质量差
- 评估困境:真实视频无 GT,传统 PSNR/LPIPS 失效;用户研究需要专业图形知识、规模难以扩展。

Figure 2 解读:论文对比了 DiffusionRenderer(第二行)与本文方法(第三行)在 5 种真实世界挑战场景下的表现:
- a. 复杂反射:DR 无法正确剥离城市夜景中的镜面反射和湿滑路面,本文方法将其还原为干净的基础色
- b. 真实场景元素:DR 对汽车/行人的 metallic 预测混乱(把人体当成金属),本文方法清晰分离
- c. 丰富细节:DR 对树枝等细粒度几何估计模糊,本文方法保留了高频结构
- d. 动态场景:DR 在动作视频的 1st / 57th 帧间深度估计不一致,本文方法保持时序稳定
- e. 长时序:DR 在 113 帧长序列中 normal 预测出现漂移,本文方法直至 113 帧仍稳定
这直观展示了论文想要解决的「in-the-wild」挑战。
本文目标:同时解决数据瓶颈(长时序、多模态、真实动态)和评估瓶颈(无 GT 场景下的自动化评测),为生成式世界渲染提供一个 scalable 的训练和评估基础设施。
2. Idea (核心思想)
三位一体的解决方案:
- 数据层面:利用 ReShade 在图形 API 级别非侵入式地拦截 AAA 游戏的运行时 G-buffer,通过「多屏拼接 + OBS 录制」策略以近无损方式捕获 720p/30FPS 的同步 RGB + 5 通道 G-buffer(albedo / normal / depth / metallic / roughness)。
- 模型层面:基于同一数据集同时微调两个开源基模型——逆向渲染方向微调 Cosmos-Transfer1-DiffusionRenderer 7B,游戏编辑(forward rendering)方向微调 Wan2.1-T2V-1.3B 并通过扩展 patch_embedding 通道实现 G-buffer 条件控制。
- 评估层面:针对真实世界视频无 GT 的场景,提出基于 VLM(Gemini 3 Pro)的 2×2 grid 排序协议,从语义正确性、空间质量、时序一致性三个维度打分,并通过 25 名 CG 专家用户研究验证其与人类偏好的相关性。
与已有工作的本质差异:不是提出新的网络架构或损失函数,而是以「数据 + 评估协议」为核心贡献,证明 scaling 高质量训练数据本身就是逆向渲染在野外泛化的直接路径(“data is all you need for bidirectional rendering in the wild”)。
3. Method (方法)
3.1 整体框架

Figure 1 解读:数据集总览。
- (a) 同步 G-buffer 与 RGB 帧:同一场景下 Roughness\Metallic(左,红绿双通道打包)、Albedo、RGB、Depth、Normal(右)在像素级严格对齐
- (b) 连续真实视频流:展示驾驶场景下 motion blur on/off 的变体以及白天/夜晚的视角切换
- (c) 多样场景、天气、季节:从雪景、阳光森林到黑暗山洞,覆盖不同光照与环境条件
论文的方法分为三大模块:(1) 数据构建 pipeline、(2) 逆向渲染器微调、(3) 游戏编辑器(前向渲染器)微调,另加 VLM 评估协议。
3.2 数据构建 Pipeline(三阶段)
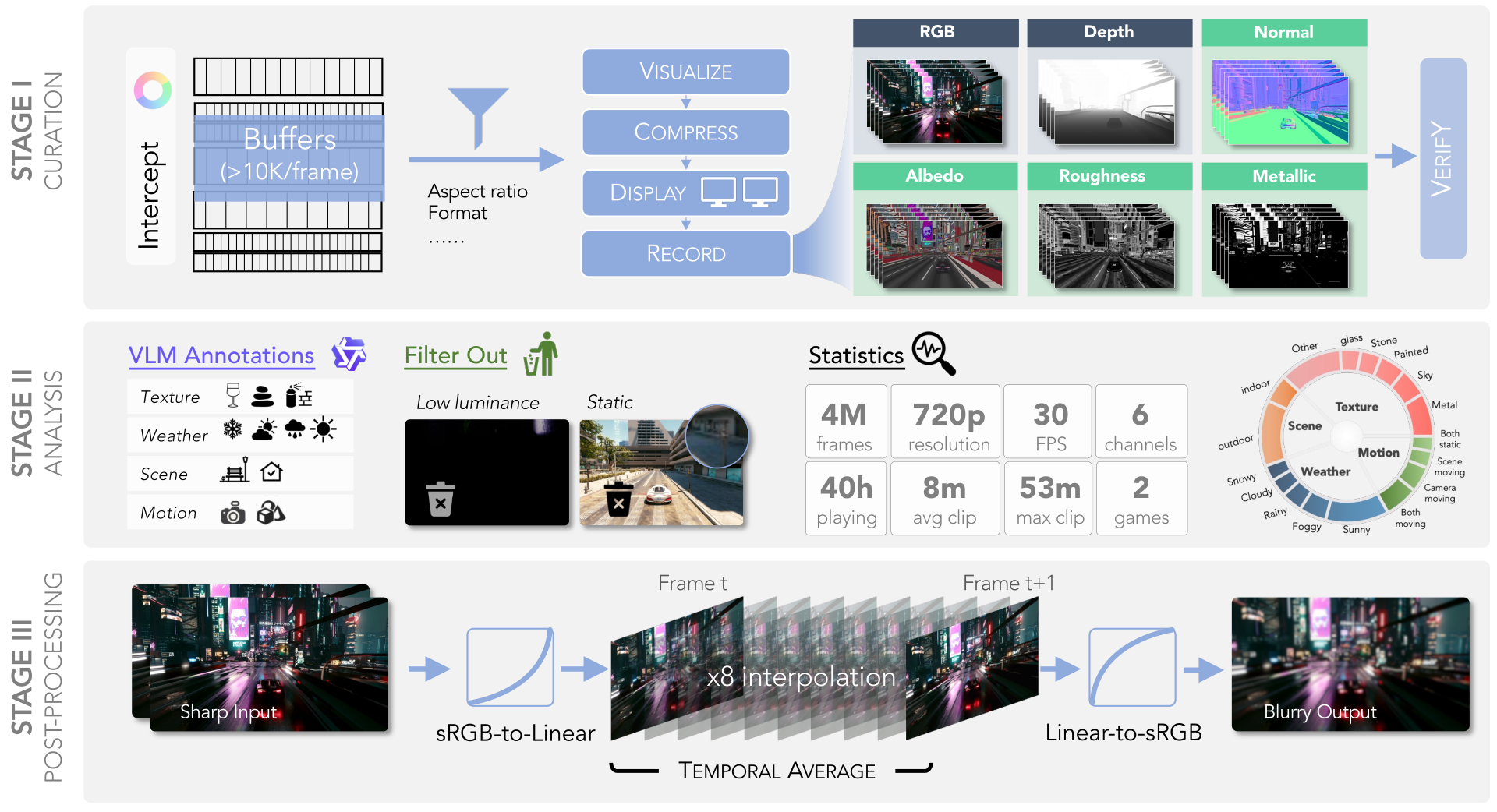
Figure 3 解读:三阶段数据构建流水线(严格对应论文 §3.1–§3.5 的阶段命名)。
- Stage I(Curation):数据采集与记录阶段。ReShade 在渲染 pass 中拦截 >10K 个 buffer,基于 aspect ratio / format 等元数据过滤候选;图中
INTERCEPT → VISUALIZE → COMPRESS → DISPLAY → RECORD → VERIFY链路覆盖 §3.1(G-buffer 拦截)与 §3.2(多屏同步录制 Mosaic),最终得到同步的 6 通道(RGB, Depth, Normal, Albedo, Roughness, Metallic)画面 - Stage II(Analysis):数据分析与标注阶段。用 Qwen3-VL-235B-A22B-Instruct 对每段 clip 标注 4 类属性(texture / weather / scene / motion),过滤低亮度和静态片段,并统计 Metallic / Roughness / Luminance / HSV 分布;Figure 3 中 Stage II 的分布面板(左侧柱状统计 + 右侧环形注释面板)对应该阶段的 VLM annotation 结果可视化
- Stage III(Post-Processing):将 sharp input 做 sRGB→Linear 转换,用 RIFE 做 x8 子帧插值,在线性域做 temporal average,再转回 sRGB,合成 motion blur 变体
Stage I.a: G-buffer 拦截(§3.1)
数据集统计:4M 帧 / 720p / 30FPS / 6 通道 / 40h gameplay / 平均每段 8 分钟 / 最长 53 分钟 / 2 款 AAA 游戏(Cyberpunk 2077 + Black Myth: Wukong)
关键技术细节:
- 离线分析(RenderDoc):识别候选 render pass 及其 attachment 的 format、dimension、sample count
- 运行时拦截(ReShade add-on):hook graphics API callbacks,监控 per-frame render-target bindings;仅 GPU-copy 满足 format/extent 稳定且周期性 binding 的 buffer
- 材质解耦:metallic 和 roughness 通常被打包进一张 render target 的不同通道(避免压缩产生通道间串扰),论文将它们解耦到屏幕的独立空间区域
- Camera-space Normal 重建:由于从渲染管线可靠获取的只有 world-space normal,但无法可靠获取 view matrix,因此从 depth 重建 camera-space normal:
其中 是从 depth buffer 通过逆投影重建的 view-space position,该计算在 ReShade effects 阶段完成。
Stage I.b: Synchronized Multi-Screen Recording(§3.2)
直接导出多通道 G-buffer 存在:存储带宽、文件管理、GPU→CPU readback stall 三大瓶颈。论文方案:
- 将所有 G-buffer 渲染到一张统一画布(canvas),用 OBS 以近无损码率录制
- 拼接两块 2K 显示器以突破单屏分辨率上限,使每个通道保持 720p 有效分辨率
- 对 source buffer 做 center-crop 再 tile,防止扩大显示区域改变游戏视场角(FOV)
Stage II: Analysis(§3.3–§3.4,数据分析与标注)
采集完成后,论文对每个 clip 提取 5 帧均匀时序采样,喂给 Qwen3-VL-235B-A22B-Instruct(通过 vLLM 部署)得到 4 类 categorical attribute:
- texture:主导材质/外观(plastic, metal, brick, sky, painted, stone, glass, …)
- weather:sunny, cloudy, foggy, rainy, snowy
- scene:indoor / outdoor
- motion:camera static scene moving、camera moving scene moving、camera moving scene static、both static
基于 VLM 结果进行 过滤:丢弃 scene + camera 全程静态 的 clip,并剔除亮度过低的帧。另外对 metallic / roughness / luminance / HSV value 做 分布分析(见 Figure 3 Stage II 面板):Cyberpunk 2077 金属像素占比更高(都市建筑),Black Myth: Wukong 粗糙像素占比更高(自然地貌 + 低亮度阴影)——两者在材质上互补。
Stage III: Motion Blur 合成(§3.5)
为弥合真实视频的曝光积分与合成数据的 sharp 帧之间的 gap,在线性域做时间平均:
- :用 RIFE 对 插值出的 个子帧
- / :sRGB↔Linear 转换
以下伪代码对应 ReShade 内部的 Normal 重建逻辑(论文未放代码,据公式与 DiffusionRenderer 规范编写):
def depth_to_camera_normal(depth: torch.Tensor, K_inv: torch.Tensor) -> torch.Tensor:
H, W = depth.shape[-2:]
yy, xx = torch.meshgrid(
torch.arange(H, device=depth.device),
torch.arange(W, device=depth.device),
indexing="ij",
)
pix = torch.stack([xx.float(), yy.float(), torch.ones_like(xx).float()], dim=-1)
P = torch.einsum("ij,hwj->hwi", K_inv, pix) * depth.unsqueeze(-1)
dP_dx = P[:, 1:, :] - P[:, :-1, :]
dP_dy = P[1:, :, :] - P[:-1, :, :]
dP_dx = F.pad(dP_dx, (0, 0, 0, 1, 0, 0))
dP_dy = F.pad(dP_dy, (0, 0, 0, 0, 0, 1))
n = torch.cross(dP_dx, dP_dy, dim=-1)
return F.normalize(n, dim=-1)3.3 Inverse Renderer(RGB → 5 G-buffers)
基座模型:Cosmos-Transfer1-DiffusionRenderer 7B(submodule @ 0f3e2dc)
架构特点:同一个扩散模型通过 context_index 索引切换输出不同的 G-buffer 通道。在 GBUFFER_INDEX_MAPPING 中:
GBUFFER_INDEX_MAPPING = {
'basecolor': 0,
'metallic': 1,
'roughness': 2,
'normal': 3,
'depth': 4,
'diffuse_albedo': 5,
'specular_albedo': 6,
}推理时按需传入 context_index,同一模型为每种 G-buffer 跑一遍扩散采样。inference_inverse_renderer.py 的 demo() 函数在每个 gbuffer_pass 上直接调用 pipeline.generate_video(...);而 generate_video 内部先走 model.generate_samples_from_batch 再调用 model.decode。下面伪代码展开 DiffusionRendererPipeline.generate_video 的核心逻辑:
def inverse_render(pipeline, video_batch, inference_passes):
outputs = {}
for gbuffer_pass in inference_passes:
context_index = GBUFFER_INDEX_MAPPING[gbuffer_pass]
video_batch["context_index"].fill_(context_index)
state_shape = [C_tokenizer, F_latent, H_latent, W_latent]
sample = pipeline.model.generate_samples_from_batch(
video_batch,
guidance=pipeline.guidance,
state_shape=state_shape,
num_steps=pipeline.num_steps,
)
outputs[gbuffer_pass] = pipeline.model.decode(sample)
return outputs微调策略:
- 全量微调官方发布的预训练权重(SVD 变体与 Cosmos 变体对比后选择 Cosmos 7B,因性能更好)
- 固定长度 57 帧 clip @ 24FPS,分辨率 1280×720
- 训练集:Cyberpunk 2077;测试集:Black Myth: Wukong
- 训练两个变体(motion blur on/off),选择 motion-augmented 版本作为最终模型
- 另外训练一个 113 帧长序列变体,显著提升长视频推理效果(见 Figure 2e)
3.4 Game Editing / Forward Renderer(5 G-buffers + Text → RGB)
基座模型:Wan2.1-T2V-1.3B(通过 DiffSynth-Studio 调用),微调于 Black Myth: Wukong,480p / 16FPS / 81 帧 clip。
核心创新:通道扩展的 Patch Embedding
Wan2.1 原生是 T2V 模型,其 DiT 的 patch_embedding 是一个 Conv3d,输入是 16 通道 VAE latent。为引入 5 个 G-buffer 条件,论文:
- 将每个 G-buffer 视频独立通过 Wan2.1 的 VAE 编码得到 16 通道 latent
- 将 5 个 G-buffer latent + 原始 latent
y在 channel 维度拼接(共 5×16=80 个额外通道) - 扩展
patch_embeddingConv3d 的in_channels:新通道权重零初始化,保证初始化阶段模型行为与原始预训练模型完全等价
Code reference:
master@c2dc64d5(2026-04-09) — pseudocode and mapping based on this commit
Patch Embedding 扩展实现(直接对应 game_editing/examples/wanvideo/model_inference/gbuffer_utils.py):
def expand_patch_embedding(pipe, num_gbuffers: int):
if num_gbuffers <= 0:
return
dit = pipe.dit
old_conv = dit.patch_embedding
old_weight = old_conv.weight
old_bias = old_conv.bias
extra_channels = num_gbuffers * 16
if old_weight.shape[1] > extra_channels:
return
new_in_dim = old_weight.shape[1] + extra_channels
new_conv = nn.Conv3d(
new_in_dim, old_conv.out_channels,
kernel_size=old_conv.kernel_size,
stride=old_conv.stride,
padding=old_conv.padding,
bias=old_bias is not None,
)
with torch.no_grad():
new_conv.weight.zero_()
new_conv.weight[:, :old_weight.shape[1]] = old_weight
if old_bias is not None:
new_conv.bias.copy_(old_bias)
dit.patch_embedding = new_conv.to(
dtype=old_weight.dtype, device=old_weight.device
)
dit.in_dim = new_in_dimG-buffer 编码与拼接(对应 WanVideoUnit_GBufferEncoder):
class WanVideoUnit_GBufferEncoder(PipelineUnit):
def __init__(self):
super().__init__(
input_params=("gbuffer_videos", "y", "tiled", "tile_size", "tile_stride"),
output_params=("y",),
onload_model_names=("vae",),
)
def process(self, pipe, gbuffer_videos, y, tiled, tile_size, tile_stride):
if gbuffer_videos is None:
return {}
pipe.load_models_to_device(self.onload_model_names)
all_latents = []
for gbuffer_video in gbuffer_videos:
video_tensor = pipe.preprocess_video(gbuffer_video)
latent = pipe.vae.encode(
video_tensor, device=pipe.device,
tiled=tiled, tile_size=tile_size, tile_stride=tile_stride,
).to(dtype=pipe.torch_dtype, device=pipe.device)
all_latents.append(latent)
gbuffer_latents = torch.cat(all_latents, dim=1)
if y is not None:
gbuffer_latents = torch.cat([y, gbuffer_latents], dim=1)
return {"y": gbuffer_latents}Prompt 构造策略(对应 inference_gbuffer_caption.py):
用 Qwen3-VL-235B-A22B-Instruct 为每个 clip 生成 caption,caption 的典型格式为 <content>; the scene is <lighting/vibe>, creating a <mood> atmosphere.。游戏编辑时,保留 <content> 部分,用用户指定的 style prompt 替换 <lighting/vibe> 部分。
def build_style_prompt(original_caption: str, style_hint: str) -> str:
if style_hint is None:
return original_caption
match = re.search(r';\s*the\s+scene\s+(is|feels|appears)\s+', original_caption)
if match:
content = original_caption[:match.start()]
return f"{content}; {style_hint}"
match = re.search(r',\s*the\s+scene\s+(is|feels|appears)\s+', original_caption)
if match:
content = original_caption[:match.start()]
return f"{content}; {style_hint}"
match = re.search(r'[,;]\s*creating\s+a[n]?\s+\w+', original_caption)
if match:
content = original_caption[:match.start()]
light_match = re.search(
r'[,;]\s*(?:under|with|lit by|illuminated by|in)\s+.*$',
content, re.IGNORECASE,
)
if light_match:
content = content[:light_match.start()]
return f"{content}; {style_hint}"
return f"{original_caption.rstrip('.')}; {style_hint}"这种设计意味着:几何与材质由 G-buffer 控制(强约束),而光照/天气/风格由 text prompt 控制(弱约束,易编辑),在保持场景结构的同时允许自由风格迁移。
3.5 VLM 评估协议(论文 Section 4)
注:论文把”VLM-based Evaluation”独立为 Section 4(与 §3 Dataset Construction 并列);本笔记为方法 Section 整体结构连贯性,把它作为 Method 的第 5 个子节。请勿将此处的 “3.5” 理解为论文 §3.5(后者是 Dataset Post-processing 即 motion blur 合成,对应本笔记 Stage III)。

Figure A.1 解读:用于 metallic 预测评估的完整 VLM prompt。
- 输入布局:2×2 grid 视频(TL=RGB reference,TR/BL/BR=三个方法的 metallic 预测)
- 评估维度:Semantic Correctness(金属 vs 非金属判定)、Appearance Quality(空间一致性、边缘对齐)、Temporal Consistency(闪烁、边界抖动、身份一致性)
- 输出格式:严格要求
ranks: rA rB rC格式,禁止平局,并要求指出具体位置的 2-3 处证据
设计要点:
- 聚焦 metallic 与 roughness 两个通道(因其有强语义先验,如皮肤≠金属、玻璃高光≠金属)
- Judge 模型选用 Gemini 3 Pro(视频理解和时序推理能力较强)
- 2×2 grid 同步播放,避免 VLM 被不同帧编码顺序干扰
- 强制输出 1/2/3 严格排列(permutation),无平局
下面伪代码展示了论文评估协议的整体流程(论文未放开源实现,依据 §4 与 Figure A.1 的 prompt 描述写出):
def vlm_rank_methods(rgb_video, method_outputs, channel, judge_vlm):
tl, tr, bl, br = _random_permute(["RGB"] + list(method_outputs.keys()))
layout = compose_2x2_grid(
top_left=rgb_video,
top_right=method_outputs.get(tr),
bottom_left=method_outputs.get(bl),
bottom_right=method_outputs.get(br),
)
prompt = build_vlm_prompt(
channel=channel,
dimensions=("semantic", "appearance", "temporal"),
force_permutation=True,
require_evidence=True,
)
response = judge_vlm.generate(video=layout, prompt=prompt)
ranks = parse_ranks(response)
return {name: ranks[slot] for slot, name in zip(["TR", "BL", "BR"], [tr, bl, br])}
def vlm_eval_dataset(test_videos, methods, channels, judge_vlm, num_repeats=3):
agg = {ch: {m: {d: [] for d in ("sem", "app", "temp")} for m in methods} for ch in channels}
for video in test_videos:
outputs = {m: m.infer(video) for m in methods}
for ch in channels:
for _ in range(num_repeats):
ranks = vlm_rank_methods(video, {m: outputs[m][ch] for m in methods}, ch, judge_vlm)
for m, r in ranks.items():
for d in ("sem", "app", "temp"):
agg[ch][m][d].append(r[d])
return {ch: {m: {d: mean(vs) for d, vs in dims.items()} for m, dims in agg[ch].items()} for ch in channels}3.6 Code-to-Paper 映射
Code reference:
master@c2dc64d5(2026-04-09) — pseudocode and mapping based on this commitSubmodule note: 下表中
inverse_renderer/...开头的路径位于主仓的 git submoduleinverse_renderer,对应nv-tlabs/cosmos-transfer1-diffusion-renderer仓库 @ commit0f3e2dc(与本 commit 绑定的 submodule 指针)。请用git clone --recursive或git submodule update --init初始化子模块,否则 GitHub 网页上直接访问这些路径会看到空目录。
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| G-buffer 通道扩展 | game_editing/examples/wanvideo/model_inference/gbuffer_utils.py | expand_patch_embedding |
| G-buffer VAE 编码 & Latent 拼接 | 同上 | WanVideoUnit_GBufferEncoder.process |
| Pipeline Unit 注入 | 同上 | inject_gbuffer_unit |
| 风格 Prompt 模板切换 | game_editing/examples/wanvideo/model_inference/inference_gbuffer_caption.py | build_style_prompt |
| 推理入口(多 GPU 多风格) | 同上 | run_single |
| Style 定义 | game_editing/examples/wanvideo/model_inference/styles.json | — |
Inverse Renderer 推理入口(submodule @ 0f3e2dc) | inverse_renderer/cosmos_predict1/diffusion/inference/inference_inverse_renderer.py | demo |
Inverse Renderer Pipeline 核心(submodule @ 0f3e2dc) | inverse_renderer/cosmos_predict1/diffusion/inference/diffusion_renderer_pipeline.py | DiffusionRendererPipeline.generate_video |
G-buffer Index 映射(submodule @ 0f3e2dc) | inverse_renderer/cosmos_predict1/diffusion/inference/diffusion_renderer_utils/rendering_utils.py | GBUFFER_INDEX_MAPPING |
数据加载器(submodule @ 0f3e2dc) | inverse_renderer/cosmos_predict1/diffusion/inference/diffusion_renderer_utils/dataset_inference.py | VideoFramesDataset |
4. Experimental Setup (实验设置)
数据集
- 训练集:Cyberpunk 2077 部分,用半自动驾驶路径和行走/室内场景采集
- 测试集(游戏内):Black Myth: Wukong 保留 39 段 clip,每段 57 帧
- 跨数据集验证:MPI-Sintel final pass(含 motion blur / DoF),提供 depth + albedo GT
- 真实世界测试:40 段从互联网采集的真实视频(室内/室外、快慢运动、不同 time-of-day)
Baseline
- DiffusionRenderer (DR):唯一可用的视频逆向渲染 baseline,论文用 Cosmos 版本因其优于 SVD 版本
- RGB↔X:图像级逆向渲染(Zeng et al., 2024),不输出 depth
- DNF-Intrinsic (DNF):Deterministic Noise-Free 扩散,图像级逆向渲染(Zheng et al., 2025)
对于游戏编辑:
- Wan-edge:基于 ControlNet + RGB 边缘图
- Wan-SDEdit:SDEdit 风格的 stochastic 编辑
- DiffusionRenderer forward:用 DiffusionLight 从输入视频提取环境贴图,用 DR 的前向渲染器合成
评估指标
合成 benchmark:
- Depth:AbsRel、RMSE、RMSE-log、δ < 1.25ⁿ(n=1,2,3)三阶段阈值精度
- Albedo:PSNR、LPIPS、si-PSNR、si-LPIPS(scale-invariant 版本)
- Normal:平均角度误差(°)、Acc@11.25°
- Metallic/Roughness:RMSE、MAE
真实 benchmark:VLM 3 维度排序 + 25 人 CG 专家用户研究
训练超参
- Inverse Renderer:57 帧 / 24FPS / 1280×720,Cosmos 7B 全量微调
- Game Editing:81 帧 / 16FPS / 832×480,Wan2.1-T2V-1.3B 全量微调
5. Experimental Results (实验结果)
5.1 逆向渲染定量结果
Black Myth Wukong 自建 benchmark(Table 1)
| 指标 | RGB↔X | DNF | DiffusionRenderer | Ours |
|---|---|---|---|---|
| Depth AbsRel ↓ | — | 0.862 | 1.118 | 0.697 |
| Depth RMSE log ↓ | — | 0.918 | 0.723 | 0.430 |
| Depth δ<1.25 ↑ | — | 0.361 | 0.267 | 0.609 |
| Depth δ<1.25² ↑ | — | 0.610 | 0.496 | 0.761 |
| Normal Angular ↓ | 78.05° | 53.21° | 45.01° | 42.57° |
| Normal Acc@11.25° ↑ | 0.035 | 0.065 | 0.110 | 0.150 |
| Albedo PSNR ↑ | 8.74 | 13.84 | 17.53 | 16.44 |
| Albedo si-PSNR ↑ | 20.11 | 15.59 | 19.90 | 21.44 |
| Metallic RMSE ↓ | 0.510 | 0.245 | 0.230 | 0.104 |
| Metallic MAE ↓ | 0.503 | 0.183 | 0.134 | 0.024 |
| Roughness RMSE ↓ | 0.349 | 0.566 | 0.281 | 0.266 |
| Roughness MAE ↓ | 0.313 | 0.543 | 0.237 | 0.218 |
关键发现:
- Depth / Normal / Metallic / Roughness 上本文模型全面领先
- Albedo 非尺度不变版 PSNR 略低于 DR(16.44 vs 17.53),但 scale-invariant PSNR 显著更高(21.44 vs 19.90),说明本文模型的相对亮度预测更准确,仅存在全局尺度偏移
- Metallic 的 RMSE 和 MAE 相对 DR 分别下降 55% 和 82%,是最显著的改进
Sintel Benchmark(Table 2)— 跨数据集泛化
| 指标 | DNF-Intrinsic | DiffusionRenderer | Ours |
|---|---|---|---|
| Depth RMSE ↓ | 0.249 | 0.268 | 0.220 |
| Depth RMSE log ↓ | 1.090 | 0.911 | 0.745 |
| Depth δ<1.25 ↑ | 0.371 | 0.331 | 0.478 |
| Albedo PSNR ↑ | 13.16 | 14.87 | 15.40 |
| Albedo si-PSNR ↑ | 13.68 | 17.46 | 17.80 |
即使 Sintel 是合成电影数据,本文模型在未见过 Sintel 风格的情况下仍全面领先,证明了跨数据集泛化能力。
5.2 VLM 评估 + 用户研究

Figure 4 解读:真实世界视频上 5 种 G-buffer 的定性对比(从上到下:albedo / normal / depth / metallic / roughness)。
- Albedo(第一行):绿色箭头标注 delighting 差异,DR 对光影分离不彻底,本文方法还原出真实底色
- Normal(第二行):夜景塔楼细节,本文方法保留了支架的高频几何
- Depth(第三行):城市夜景,绿色箭头指向远处建筑,本文方法深度层次更合理
- Metallic(第四行):路灯/旗杆等真实金属物体被正确识别,DR 将植被误判为金属
- Roughness(第五行):沙漠车辆,本文方法对沙尘环境下的粗糙度判断更准确

Figure 5 解读:两段真实视频的完整 G-buffer 对比。上图是城市街景、下图是秋日乡道。关键观察:
- DR 在 autumn road 场景下 depth 完全失效(整体偏暗、结构断裂),本文方法保留了道路透视
- Metallic 预测上,DR 将树叶误判为金属(错误的黑色区域),本文方法维持干净的非金属背景
- Roughness 上,本文方法对乡道的粗糙纹理有更细腻的响应
VLM 评估(Table 3,越低越好,1-3 rank)
| 通道 | 方法 | Sem.↓ | App.↓ | Temp.↓ |
|---|---|---|---|---|
| Roughness | DiffusionRenderer | 2.45 | 2.40 | 2.10 |
| Roughness | Ours | 1.78 | 1.78 | 2.08 |
| Roughness | Ours (w/ motion blur) | 1.78 | 1.83 | 1.83 |
| Metallic | DiffusionRenderer | 2.35 | 2.28 | 2.00 |
| Metallic | Ours | 1.90 | 2.13 | 2.15 |
| Metallic | Ours (w/ motion blur) | 1.75 | 1.60 | 1.85 |
User Study(Table 4)— VLM 与专家一致率
| 通道 | Group 1 (VLM 偏好本文) | Group 2 (VLM 偏好 DR) |
|---|---|---|
| Metallic | 85% | 70% |
| Roughness | 75% | 61% |
结论:专家与 VLM 判断高度一致,roughness 略低是因为其判断本就更模糊。
5.3 重光照应用(验证下游泛化)

Figure 6 解读:用冻结的 DiffusionRenderer forward renderer,以 baseline(DR)和本文方法估计的 G-buffer 分别作为条件进行重光照。关键发现:
- 即使 forward renderer 未在本文数据上微调,仅改进 G-buffer 质量就显著提升了合成一致性
- 尤其在天空区域(第一行夜景、第二行多云白天),本文方法的环境光匹配度更高
- 证明:scaling 数据即可突破逆向渲染歧义性的根源(intrinsic vs lighting 的解耦能力提升)
5.4 游戏编辑应用

Figure 7 解读:给定 Black Myth: Wukong 的 G-buffer 为条件,文本 prompt 控制风格。
- 第一行 Snowy weather:原始场景→本文→Wan-edge→Wan-SDEdit→DiffusionRenderer 对比。Wan-edge 完全丢失语义(变成水墨画),SDEdit 保留几何但失去整体美感,DR 维持几何但无法做激烈风格转换,本文方法自然地将山景变为雪景
- 第二行左侧 Other styles:同样的地形被渲染为 Underwater、Smoke、Cyberpunk 三种极端风格,说明模型学到了与 G-buffer 几何解耦的灵活光照先验
- 第二行右侧 Results of 2077:在未见过的 Cyberpunk 2077 场景上泛化(跨游戏域),将白天街景转换为暖色暮光,证明域外泛化能力
游戏编辑的核心优势:
- 比 ControlNet(edge map)有更稳定的时序(G-buffer 本身就稳定,边缘从 RGB 提取不稳定)
- 比 SDEdit 更保留关键语义(不会让路牌/角色消失)
- 比 DR forward renderer 支持更激进的风格变换(因为训练数据天然包含体积雾、雨等复杂效果)
5.5 Motion Blur 消融(Table 5 + Figure 8)

Figure 8 解读:强运动场景下 motion blur 变体的优势。
- 第一行(白色汽车侧视):DR 预测的 albedo 错乱,ours 干净,ours-w/o-motion 边界模糊
- 第二行(夜间行人过斑马线):w/o motion 变体在人物边缘有明显拖影伪影,带 motion blur 训练的版本更清晰
| 指标 | Ours | Ours (w/ motion blur) |
|---|---|---|
| Depth RMSE log ↓ | 0.773 | 0.745 |
| Depth δ<1.25 ↑ | 0.467 | 0.478 |
| Albedo PSNR ↑ | 15.73 | 15.40 |
| Albedo si-PSNR ↑ | 17.37 | 17.80 |
| Albedo si-LPIPS ↓ | 0.513 | 0.491 |
结论:motion blur 训练在 合成指标上大部分改善(尤其 depth 和 si-PSNR/si-LPIPS),在真实视频时序稳定性上改善明显(减少 flicker 和 boundary crawling)。少数指标(Albedo PSNR)有轻微下降,可能是 motion blur 使 albedo 匹配度变低。
5.6 局限性
- 数据集访问受限:因 EULA 合规性,数据集仅通过 gated access + 签署 Terms of Use 方式发布,且为 CC BY-NC-SA 4.0 非商用许可
- 游戏覆盖有限:目前仅覆盖 Cyberpunk 2077 和 Black Myth: Wukong 两款游戏,游戏选择依赖 ReShade 可注入性
- World-space normal → camera-space normal 的转换依赖 depth 重建,在深度估计困难区域(如远景、透明物体)可能引入额外噪声
- Forward renderer 不能完全脱离 base model:Wan2.1-1.3B 的能力上限限制了渲染保真度,上规模后可能有更大潜力
5.7 总体结论
论文的三大贡献均被实验强力验证:
- 数据集规模与质量:4M 帧 + 6 通道同步 + 长时序 + 真实动态,是现有合成数据集的 scale-up
- 数据管道的实用性:ReShade + 多屏拼接可复制到其他游戏(工具开源)
- 训练 + 评估范式:仅通过数据微调既有模型就能大幅提升野外逆向渲染质量,VLM 评估协议为无 GT 场景提供 scalable solution
核心 takeaway:在生成式渲染领域,scaling 高质量的真实感训练数据是突破合成-真实 domain gap 的直接、有效路径。