MolmoAct2: Action Reasoning Models for Real-world Deployment
Paper: arXiv:2605.02881 Code: allenai/molmoact2 Code reference:
main@2ee3dc63(2026-05-14); submodulelerobot/molmoact2-policy@80633827(2026-05-14)
1. Motivation (研究动机)
当前 VLA / robot foundation model 离真实部署有四个具体缺口。第一,frontier robot policies 多为 closed systems,数据、recipe 和训练代码不可复现;第二,open-weight alternatives 往往绑定昂贵或专门硬件,难以迁移到低成本平台;第三,reasoning-augmented policies 虽然更可解释,但常要生成大量中间 token、goal image 或 world rollout,闭环控制延迟过高;第四,现实环境中的 fine-tuned success rate 仍低于可靠部署所需水平。
本文的目标是构建一个 fully open、可真实部署、可快速 fine-tune 的 action reasoning model:MolmoAct2。它不仅要有强 embodied-reasoning VLM backbone,还要有跨 embodiment 的 robot data、开放 action tokenizer、能输出连续动作的 architecture,以及低延迟的 adaptive reasoning 机制。
这个问题值得研究,因为机器人部署的瓶颈不是单次 benchmark accuracy,而是“能否在新任务、新硬件、新环境下用可获得的数据快速适配并稳定闭环控制”。如果开源模型、数据和训练流程都可用,研究者可以在自己的 robot embodiment 上复现、诊断和扩展,而不是只能调用闭源 API 或等待 vendor 支持。
2. Idea (核心思想)
核心 insight:把 VLM 的离散 reasoning 能力和机器人所需的连续动作控制分工处理,但不要只把 VLM 最后一层 hidden state 当 conditioning;应让 continuous action expert 在每一层 cross-attend 到对应 VLM layer 的 keys/values,从而直接利用 VLM 自身 attention state。
MolmoAct2 的关键创新是五段式系统:Molmo2-ER 提供 embodied spatial reasoning;MolmoAct2-BimanualYAM / DROID / SO100 数据补足高质量 robot trajectories;MolmoAct2-FAST 把 1 秒 32-D continuous actions 压成 discrete action tokens;post-training 加入 DiT-style flow-matching action expert;MolmoAct2-Think 通过 adaptive depth token cache 只重算变化区域的 depth reasoning。
与 / 或普通 action-expert VLA 相比,MolmoAct2 的根本差异在于 per-layer KV conditioning:expert 不只看一个压缩后的 VLM residual stream,而是在第 层使用第 个 VLM block 产生的 作为 cross-attention context。这使 continuous controller 能接触 VLM 做视觉语言判断时真正使用的 attention state。
3. Method (方法)
3.1 Overall framework
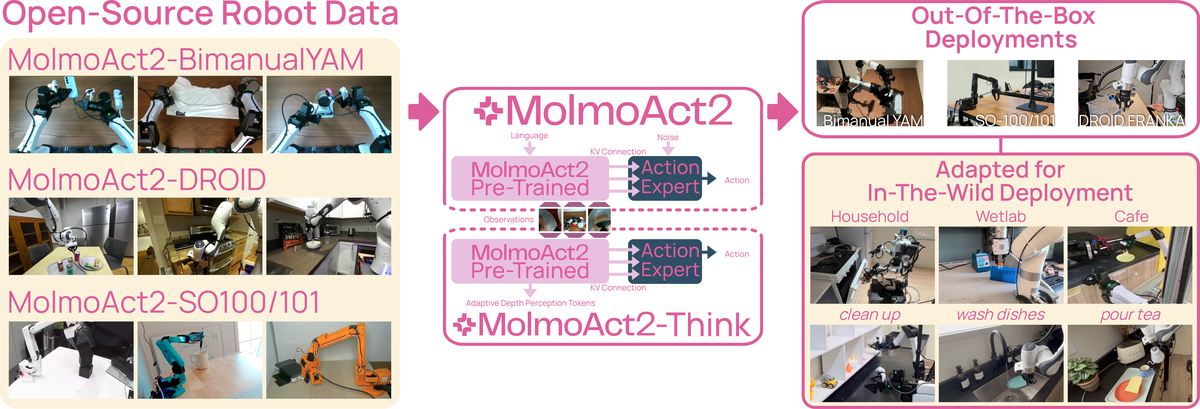
Figure 1 解读:左侧是三类低到中成本平台的数据:bimanual YAM、SO-100/101、DROID Franka;中间是 Molmo2-ER backbone、MolmoAct2 action expert、MolmoAct2-Think depth reasoning 的组合;右侧展示 out-of-the-box deployment 与 fine-tuning 后的真实任务,包括 cleanup、washing dishes、wetlab automation 和 pouring tea。

Figure 2 解读:训练数据由 robot data、multimodal web data 和 embodied-reasoning data 组成。robot data 不只来自公开数据,还包含新采集的 720 小时 bimanual YAM、filtered DROID、filtered SO-100/101;非 robot mixture 用来保留 VLM 的视觉语言和空间推理能力。
3.2 Key components
Molmo2-ER backbone. Molmo2-ER 从 Molmo2-4B mid-training checkpoint 出发,在 3.3M embodied reasoning corpus 上 specialize,然后和原始 Molmo2 multimodal data rehearse。训练数据覆盖 single-image embodied QA、image pointing、detection、video embodied QA、multi-image / ego-exo reasoning、abstract embodied reasoning。Stage 1 训练 20K steps,sequence length 4200,global batch 64,2 nodes × 8 H100;Stage 2 再训练 1.5K steps,embodied/general mixture 中 最优,sequence length 16384。
Robot data. MolmoAct2-BimanualYAM 包含 28+ real-world tasks、34.5K demonstrations、720+ hours;MolmoAct2-SO100/101 从 1,222 LeRobot public datasets / 377 users 中筛出 38,059 episodes、19.8M frames、184 hours;MolmoAct2-DROID 从 DROID 中用 supplemental annotations / idle-frame filter 得到 74,604 valid episodes 和 17,758,044 frames。语言重标注用 Qwen3.5-27B,把 unique labels 从 71,121 (22%) 提高到 146,485 (46%)。
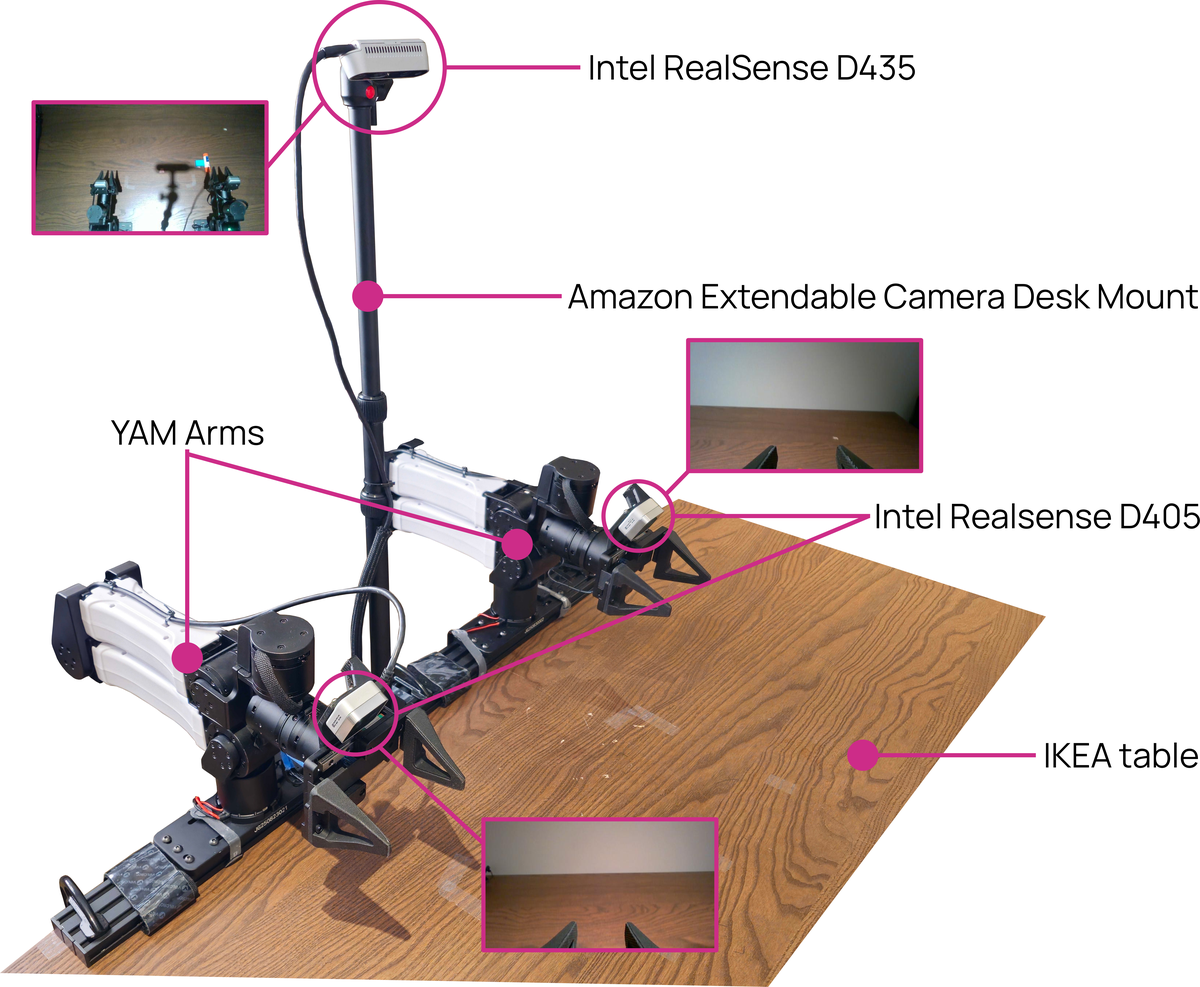
Figure 3 解读:BimanualYAM setup 强调“可买到、低成本、可复现”,整套硬件低于 6,000 USD。这个设计服务于论文的部署目标:不是只在昂贵专有硬件上表现好,而是在实验室和个人可负担平台上运行。
MolmoAct2-FAST discrete tokenizer. 预训练阶段先把 action 当作离散 token 来学:连续 action/state 用 1–99 percentile statistics normalize;gripper 单独处理;action vectors pad 到 32 维;1 秒 action chunk 被 2048-token vocabulary 编码;state 则离散成 256 state tokens 放入 prompt。
Post-training with continuous action expert. 离散 action tokens 稳定适合大规模预训练,但部署要连续轨迹。MolmoAct2 因此接上 DiT-style action expert,用 flow matching denoise noisy action trajectory。
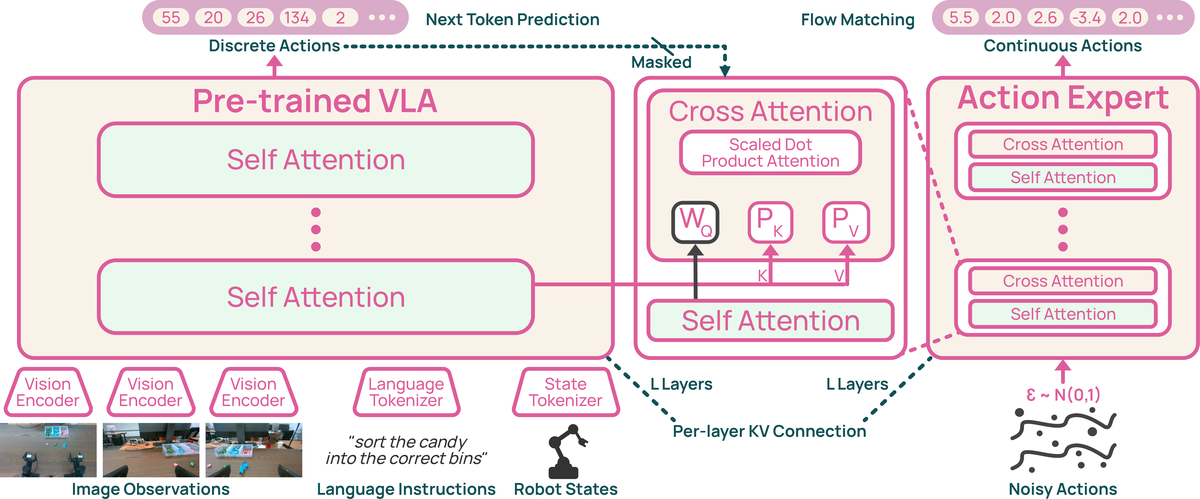
Figure 4 解读:VLM backbone 处理图像、语言、setup/control descriptors 和 state tokens;action expert 与 VLM 等深度,逐层接收对应 VLM layer 的 。训练时 backbone 仍做 discrete action token CE,expert 做 continuous flow matching;target discrete action span 会从 expert conditioning 中 mask 掉,避免连续 expert 偷看 ground-truth discrete actions。
给定 normalized action chunk 、noise 和 :
flow loss 为
其中 mask padded horizon / action dimensions。post-training 总目标:
每个 expert block 的计算可概括为:
VLM-to-expert KV projection:
MolmoAct2-Think adaptive depth reasoning.
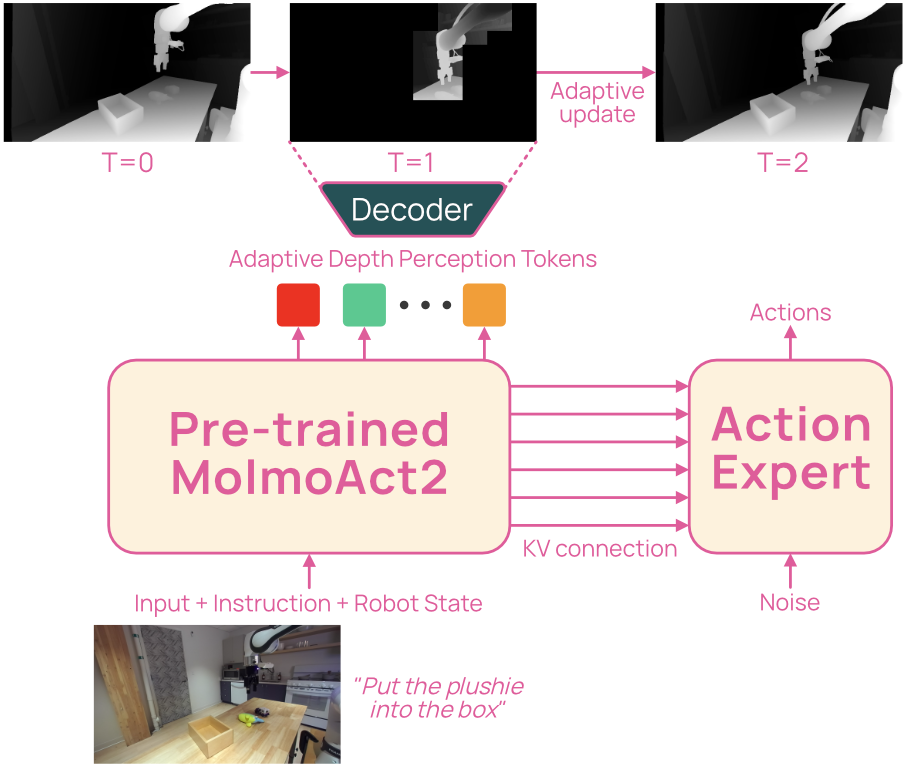
Figure 5 解读:MolmoAct2-Think 在 action generation 前预测 compact depth tokens,但不会每帧重算完整 100-token depth grid。它比较当前 RGB patch 与上一帧 patch,只对变化 cell autoregressively regenerate depth code,静态 cell 直接 replay cache,从而把 reasoning cost 从“固定 100 token”变成“随场景变化比例增长”。
Depth representation 来自 Depth Anything V2 + depth VQ-VAE:把 depth map 下采样成 code grid,每个位置是 中的 code。更新规则为:
Fine-tuning 还加入 10% depth-code input noise 和 per-layer depth gate:
只缩放 depth-token 的 ,并用 bias 初始化,让模型一开始接近标准 action-only path。
3.3 Pseudocode based on released code
Code reference: top repo
main@2ee3dc63(2026-05-14); submoduleallenai/lerobotmolmoact2-policy@80633827(2026-05-14) — pseudocode and mapping based on this commit
Released top repo 当前主要提供 README、checkpoints/data links 和 LeRobot submodule;LeRobot policy 支持 regular MolmoAct2 training/evaluation。MolmoAct2-Think adaptive depth 在 policy README 中明确为 not included / coming soon,因此 Think pseudocode 依据论文算法描述,不是 released LeRobot code。
import torch
import torch.nn.functional as F
from torch.distributions import Beta
def sample_flow_training_batch(actions, cfg, action_dim_is_pad=None):
# Mirrors MolmoAct2Policy._prepare_flow_matching_tensors.
b, horizon, dim = actions.shape
k = cfg.num_flow_timesteps
t = Beta(cfg.flow_matching_beta_alpha, cfg.flow_matching_beta_beta).sample((b * k,))
t = cfg.flow_matching_time_offset + cfg.flow_matching_time_scale * t
t = t.view(b, k).to(actions.device, actions.dtype)
if action_dim_is_pad is not None:
actions = actions.masked_fill(action_dim_is_pad[:, None, :], 0)
noise = torch.randn(b, k, horizon, dim, device=actions.device, dtype=actions.dtype)
x_t = (1.0 - t[..., None, None]) * noise + t[..., None, None] * actions[:, None]
target_velocity = actions[:, None] - noise
return t, x_t, target_velocitydef per_layer_kv_action_expert(vlm, action_expert, inputs, noisy_actions, timesteps, masks, detach_kv):
# Condensed from MolmoAct2Policy._compute_flow_matching_loss_joint_per_layer.
hidden = vlm.embed(inputs)
action_hidden = action_expert.action_embed(noisy_actions)
conditioning = action_expert.time_embed(timesteps)
for layer_idx, (vlm_block, action_block) in enumerate(zip(vlm.blocks, action_expert.blocks)):
hidden, kv = vlm_block(hidden, collect_layer_kv_states=True)
key_states, value_states = kv
if detach_kv:
key_states, value_states = key_states.detach(), value_states.detach()
k_ctx = action_expert.context_k_proj(key_states)
v_ctx = action_expert.context_v_proj(value_states)
action_hidden = action_block(
action_hidden,
conditioning,
cross_kv=(k_ctx, v_ctx),
self_attn_mask=masks.self_attn,
attn_mask=masks.cross_attn,
)
pred_velocity = action_expert.final_layer(action_hidden, conditioning)
return pred_velocitydef molmoact2_training_step(policy, batch):
# Mirrors MolmoAct2Policy.forward for action_mode='both'.
model_inputs = policy._model_inputs(batch)
flow_loss, hidden_states = policy._compute_flow_matching_loss_joint_per_layer(
batch=batch,
model_inputs=model_inputs,
)
discrete_outputs = type("O", (), {"last_hidden_state": hidden_states})
ce_loss, z_loss = policy._discrete_loss_from_backbone_outputs(batch, discrete_outputs)
return ce_loss + (z_loss if z_loss is not None else 0.0) + flow_lossdef build_robot_prompt(task, images, state_tokens, setup_text, control_text):
# Mirrors processor_molmoact2._build_robot_text.
image_prefix = "".join(f"Image {i + 1}<|image|>" for i in range(len(images)))
prompt = (
f"The task is to {task}. The setup is {setup_text}. "
f"The current state of the robot is {state_tokens}. "
f"The expected control mode is {control_text}. "
"Given these, what action should the robot take to complete the task?"
)
return image_prefix + "<|im_start|>user\n" + prompt + "<|im_end|>\n<|im_start|>assistant\n<action_output>"def adaptive_depth_cache_step(model, rgb_t, prev_rgb, prev_depth_buffer):
# Paper algorithm for MolmoAct2-Think; not present in released LeRobot policy yet.
if prev_depth_buffer is None:
return model.decode_depth_tokens(rgb_t, full_grid=True)
update = cosine_patch_similarity(rgb_t, prev_rgb, grid=(10, 10)) < 0.996
depth_buffer = prev_depth_buffer.clone()
for cell in range(100):
if update[cell]:
depth_buffer[cell] = model.decode_one_depth_token(rgb_t, prefix=depth_buffer[:cell])
else:
model.replay_cached_depth_token(depth_buffer[cell])
return depth_buffer论文公式与 released code 实现差异:论文描述的 MolmoAct2-Think adaptive depth 目前未包含在 LeRobot policy;release README 说 regular MolmoAct2 支持 training/evaluation,Think coming soon。论文 post-training 用 flow samples,fine-tuning 用 ;released config default num_flow_timesteps=8,更像 fine-tuning/evaluation 默认。代码还显式用 Beta() 采样 flow timestep,并使用 time_offset=0.001,time_scale=0.999;论文主公式只写 ,这些采样细节在代码/config 中更具体。
3.4 Code-to-paper mapping
Code reference: top repo
main@2ee3dc63(2026-05-14); submoduleallenai/lerobotmolmoact2-policy@80633827(2026-05-14) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Release wrapper / model links | allenai/molmoact2/README.md | checkpoints, datasets, submodule setup |
| LeRobot MolmoAct2 policy config | src/lerobot/policies/molmoact2/configuration_molmoact2.py | MolmoAct2Config, LR/action/flow defaults |
| Flow matching action expert training | src/lerobot/policies/molmoact2/modeling_molmoact2.py | _prepare_flow_matching_tensors, _compute_flow_matching_loss_joint_per_layer |
| Per-layer KV conditioning | src/lerobot/policies/molmoact2/modeling_molmoact2.py | collect_layer_kv_states, context_k_proj, context_v_proj, action_block |
| Discrete action CE / action token labels | src/lerobot/policies/molmoact2/modeling_molmoact2.py | _discrete_loss_from_backbone_outputs |
| Prompt/state/action packing | src/lerobot/policies/molmoact2/processor_molmoact2.py | _build_robot_text, _build_discrete_action_string, _pad_action, _build_labels |
| Training entrypoint | src/lerobot/scripts/lerobot_train.py, examples/training/train_policy.py | LeRobot training loop integration |
| MolmoAct2-Think depth reasoning | not in released LeRobot policy at this commit | paper algorithm only |
4. Experimental Setup (实验设置)
Datasets and scale. Molmo2-ER embodied corpus: 3.3M samples,含 Image Embodied QA 1.3M、Image Pointing 780K、Image Detection 100K、Video Embodied QA 703K、Multi-image/Ego-Exo 700K、Abstract Reasoning 150K。Molmo2/Tulu/general mixture 总计 12.5M samples。Robot data: BimanualYAM 34.5K demos / 720+ hours / 28+ tasks;SO100/101 filtered corpus 38,059 episodes / 19.8M frames / 184 hours from 1,222 datasets;DROID filtered subset 74,604 valid episodes / 17,758,044 frames。LIBERO 每个 suite 10 tasks × 500 demos;real-world YAM fine-tuning evaluates 8 tasks with 50 trials each。
Baselines. Embodied reasoning 对比 GR-ER 1.5/Thinking、Gemini 2.5 Pro、GPT-5、GPT-5-mini、Qwen3-VL、LLaVA-OV、InternVL3.5、Molmo2。Robot deployment/fine-tuning 对比 StereoVLA、LAP-VLA、X-VLA、、、MolmoBot、SmolVLA、TraceVLA、OpenVLA、SpatialVLA、CoT-VLA、ThinkAct、GR00T N1.7、NORA-1.5、Cosmos Policy、OpenVLA-OFT。
Evaluation metrics. 主要指标是 task success rate (%),MolmoSpace/MolmoBot/real tasks 还报告 standard error 或 15/50 trials;LIBERO 按 Spatial/Object/Goal/Long success rate;RoboEval 除 success 外评估 completion time、trajectory length、joint/cartesian path length、jerk、self-collisions、slip count 等 trajectory quality;embodied reasoning 用各 benchmark accuracy/score 和 overall average。
Training config. 这些数字来自论文源文件 tables/appendix/hyperparams_training.tex、tables/appendix/hyperparams_model.tex、sections/4-*.tex,不是 LeRobot base defaults。模型:image encoder 380M, connector 57M, LLM 4.0B, action expert 621M;image size ,image encoder patch 14,LLM 36 layers / 32 heads / 8 KV heads,action expert 36 layers / 8 heads / max horizon 30 / max action dim 32 / per-layer KV conditioning。
Pre-train
- Steps / batch / hardware: 200K steps, global batch 128, sequence length 4200, 64 H100, 90 hours, 5760 GPU-hours。
- LR: ViT , connector , LLM , action expert field in table but pre-training is discrete-only before continuous expert attachment。
- Action representation: action vectors padded to 32D; 1 second action chunk encoded by 2048-token MolmoAct2-FAST vocabulary; state values discretized into 256 tokens。
Post-train
- Architecture / objective: starts from 200K-step MolmoAct2-Pretrain; co-trains discrete LM loss and continuous flow loss; flow samples per robot chunk because of memory constraints。
- Steps / batch / hardware: 100K updates, global batch 128, robot sequence length 2100, multimodal sequence length 4200, 64 H100, 36 hours, 2304 GPU-hours。
- LR: ViT/connector , LLM , action expert ;knowledge insulation detaches VLM for flow loss。
Fine-tune
- Shared recipe: robot-only, flow times per action chunk, no knowledge insulation, full-model adaptation by default, same LRs as post-training。
- BimanualYAM: 30-step action chunk at 30 Hz, seq length 2100, global batch 128, 100K updates, 64 H100, ~2304 GPU-hours。
- DROID / SO100: 15-step DROID chunk at 15 Hz or 30-step SO100 chunk at 30 Hz, global batch 64, 100K updates, 32 H100, ~1152 GPU-hours。
- LIBERO: 10-step chunk at 10 Hz, seq length 2100, global batch 64 in text; appendix table reports suite-specific 32/64 H100 settings and best checkpoint at 40K for Goal / 30K for Think。
5. Experimental Results (实验结果)
Embodied reasoning. Molmo2-ER reaches overall average 63.8 over 13 embodied-reasoning benchmarks, beating GPT-5 57.9、Gemini 2.5 Pro 57.1、GR-ER 1.5 Thinking 61.3、Qwen3-VL-8B 61.0、Molmo2 46.8。它在 Point-Bench 77.3、RefSpatial 52.5、BLINK 72.5、CV-Bench 87.8、ERQA 46.8、EmbSpatial 78.8、MindCube 57.0、SAT 78.0、VSI-Bench 74.5 等多项上达到 best open-weight / best overall。
Out-of-the-box deployment. MolmoSpace average: MolmoAct2-DROID 37.7,超过 -DROID 34.5;Pick 43.7 vs 36.4,Pick&Place 26.7 vs 13.6,Close 70.8 vs 65.1,但 Open 9.5 低于 的 22.7,说明 articulated-object interaction 仍是弱点。Simulation held-out Avg: MolmoAct2-DROID 20.6 vs -DROID 10.0。DROID real-world tasks average: MolmoAct2-DROID 87.1 vs MolmoBot 48.4 vs -DROID 45.2。SO-100 tasks average: MolmoAct2-SO 56.7 vs -SO100/101 45.3 vs SmolVLA 2.3。
Fine-tuning. LIBERO average: MolmoAct2 97.2%,MolmoAct2-Think 98.1%,GR00T N1.7 97.0%, 96.9%,MolmoAct-7B-D 86.6%。MolmoAct2 在 Object 达 100.0%,Think 在 Spatial 98.8%、Goal 98.5%、Long 95.4%。RoboEval success: MolmoAct2 44.3%,比 高 3.8 points。真实 YAM 8-task fine-tuning:MolmoAct2 average 50.1%,比 runner-up OpenVLA-OFT 高 15 points。
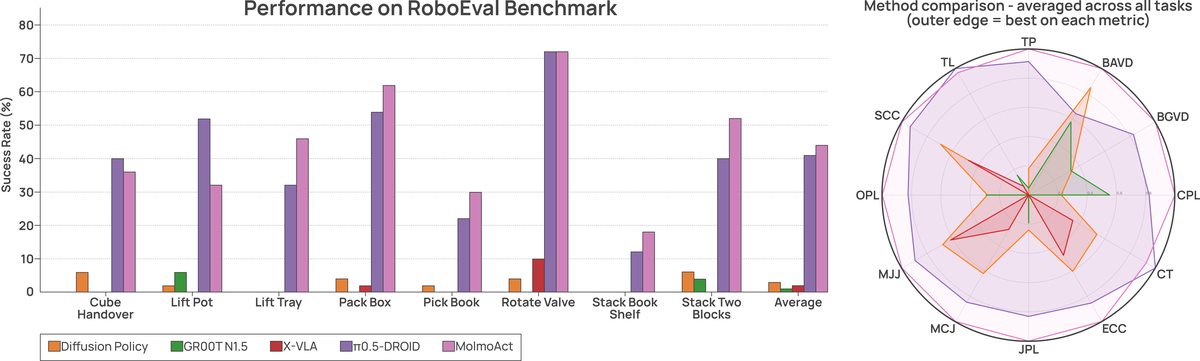
Figure 6 解读:RoboEval 图同时展示 task-wise success 和 trajectory quality radar。论文强调 MolmoAct2 不只是成功率提升,还在 completion time、path length、jerk、self-collision/slip 等部署相关指标上更接近最佳归一化值。
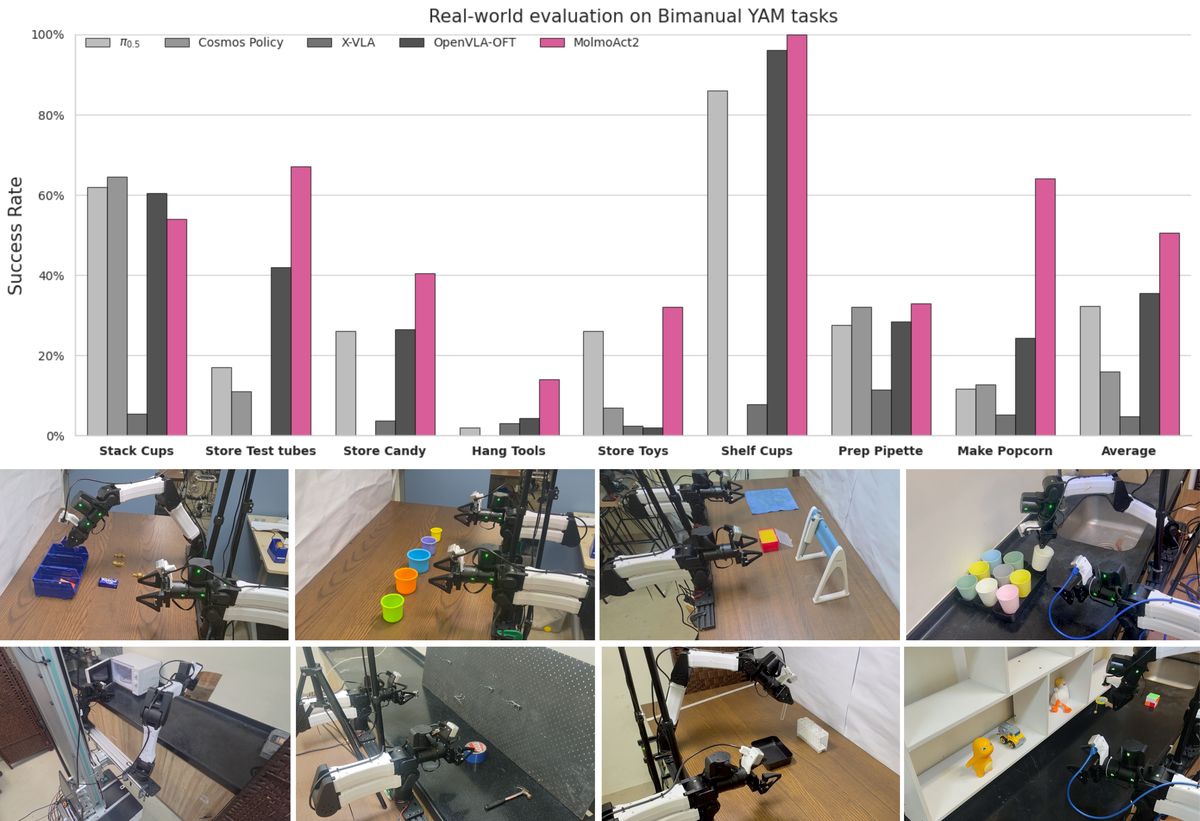
Figure 7 解读:real-world fine-tuning 覆盖实验室外场景,包括 wetlab、pantry、study room、mobile manipulation。图中任务说明 MolmoAct2 的评估目标是“少量数据快速适配新 embodiment / 新任务”,而不是只在标准模拟器跑分。
Robustness and trajectory quality. OOD perturbation overall: MolmoAct2-Think 50.69%,OpenVLA-OFT 39.89%, 27.01%,Cosmos Policy 11.25%,X-VLA 6.44%。MolmoAct2-Think 在 spatial variation 26.25、lighting 62.05、language 60.35、distractor 54.10 均最高,但 spatial variation 是最低绝对分,仍有改进空间。RoboEval trajectory 例子:Stack Two Blocks completion time 从 的 5.87s / Diffusion 的 7.27s 降到 4.70s;joint path length 从 2.16 降到 1.04;Rotate Valve completion time 8.51s vs 9.69s。
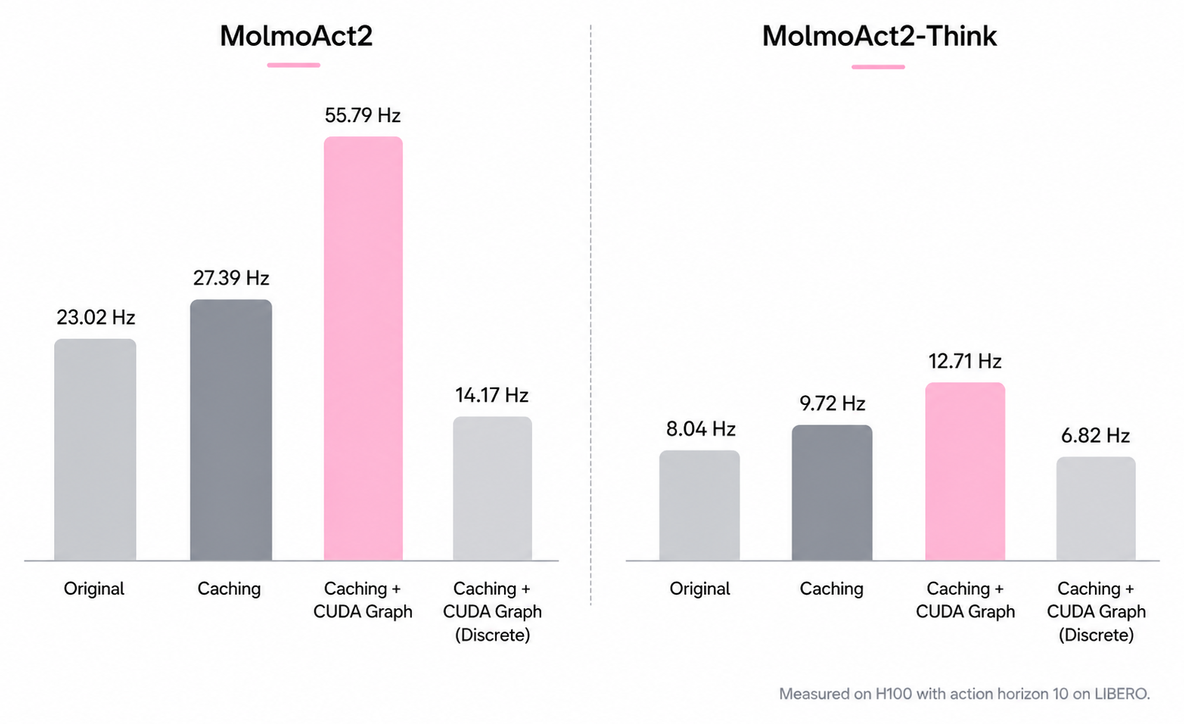
Figure 8 解读:inference speedup 图比较 original、optimized eager、CUDA Graph path 的 control rate。优化来自 action-expert 中可复用 context-dependent cross-attention state 和固定位置项缓存,以及 fixed-shape flow loop 的 CUDA Graph replay;测量条件是 LIBERO、single H100、action horizon 10。
Ablations. Backbone ablation on LIBERO Long: Molmo2 discrete 77.6%,Molmo2-ER discrete 83.6%,说明 embodied-reasoning backbone 直接提升 action token prediction。Conditioning source ablation: hidden-state conditioning average 94.0%,per-head per-layer KV 94.8%,standard per-layer KV 95.9%,支持本文核心 architectural choice。Flow samples: average 94.15%, 95.05%, 95.15%, 95.90%。Fine-tuning design: final recipe(discrete co-training enabled, knowledge insulation disabled, full fine-tuning)average 97.20%;action-expert-only 降到 93.05%。Depth fine-tuning: mixed training + noise injection + depth gate 达 98.10%;去掉 noise/gate 97.65%;只 depth-and-action 97.50%。
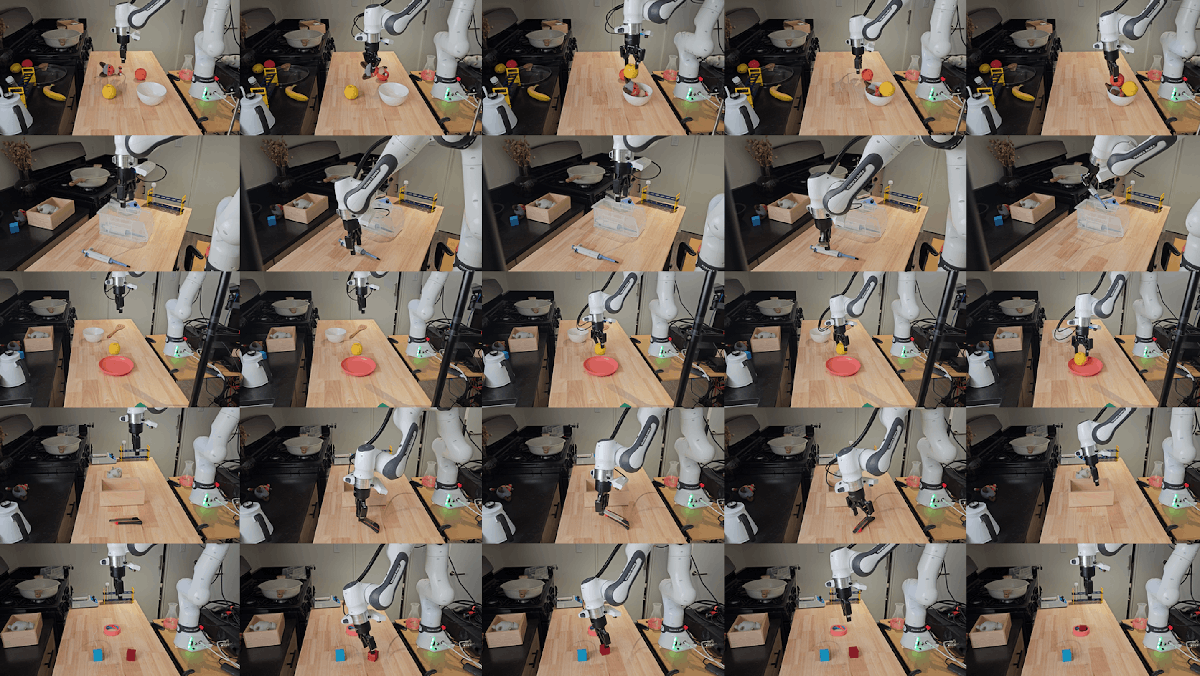
Figure 9 解读:DROID sample trajectories 展示 MolmoAct2 在真实 Franka 任务上的连续动作 rollout。相比只看 success rate,这类轨迹图帮助判断是否出现过长路径、反复试探或不稳定接触。

Figure 10 解读:BimanualYAM sample trajectories 展示双臂协作任务。MolmoAct2 的数据和模型都围绕 bimanual real-world deployment 设计,因此这类任务比单臂 tabletop 更能体现数据收集和 action expert 的价值。
Limitations. 作者明确指出 articulated-object interaction(例如 MolmoSpace Open)仍弱,spatial variation 的 OOD score 也最低;MolmoAct2-Think 的 adaptive scheduler 因 update pattern 数据依赖,不能把完整 adaptive loop 全部 CUDA Graph capture,只能用 eager scheduler + static KV cache + 部分 fixed-shape graph。release 侧的限制是:top repo 目前还有 “full code coming soon” 说明,LeRobot policy 支持 regular MolmoAct2,但 Think adaptive depth 尚未 release。
Conclusion. MolmoAct2 的证据链比较完整:更强 embodied VLM backbone 提升 reasoning;大规模高质量开放 robot data 提供部署覆盖;per-layer KV action expert 把离散 VLM reasoning 转成连续控制;adaptive depth 在困难任务上额外提升。它的主要贡献不是某一个 benchmark 的单点最优,而是把开源 VLA 推向可复现、可 fine-tune、可部署的完整系统。