HY-Embodied-0.5: Embodied Foundation Models for Real-World Agents
Paper: arXiv:2604.07430 Code: Tencent-Hunyuan/HY-Embodied Code reference:
master@c9b3530e(2026-04-14); model implementation dependencyhuggingface/transformers@9293856c(2026-04-08)
1. Motivation (研究动机)
现有通用 VLM 已经能做图文理解,但它们离真实物理 agent 仍差两步:第一,缺少足够细粒度的视觉/空间感知,尤其是 2D/3D grounding、深度、尺度、计数、mask、点位和跨视角对应;第二,训练数据多来自静态网页语料,缺少面向预测、交互、规划和机器人操作的 embodied supervision。因此,模型常能“描述场景”,但在需要判断可交互对象、估计几何关系、规划下一步动作或输出轨迹时不稳定。
HY-Embodied-0.5 的目标是把 VLM 变成真实机器人/VLA 系统可用的 foundation brain:既保留通用视觉问答能力,又显式增强 spatial-temporal visual perception 与 embodied reasoning。论文给出两个规模:MoT-2B(4B total / 2.2B activated,面向边缘部署与实时性)和 MoE-A32B(407B total / 32B activated,面向复杂推理)。
这个问题值得做的原因是:一旦 VLM 可靠理解物理世界,VLA policy 就不必从零学习全部语义/空间推理;上层 “brain” 可以负责视觉 grounding、动作意图解释、任务规划和状态判断,低层 action expert 再把这些语义转成控制。
从任务形态看,这篇 paper 把 embodied capability 明确拆成三层:低层视觉感知决定“看没看准”,空间/几何推理决定“理解没理解物理关系”,高层 planning/interaction 决定“能不能把目标转成动作序列”。这也是它没有只报告通用 VQA,而是集中评测 22 个 embodied-relevant benchmarks 并补充真实 VLA 实验的原因。
具体来说,论文把缺口落到三个可评测层面:
- Perception:depth、detection、segmentation、pointing、counting 等低层任务要足够准。
- Spatial reasoning:跨视角、距离、方向、尺度和动态关系要能被语言化。
- Embodied reasoning:affordance、trajectory、planning、interaction 需要和任务目标绑定。
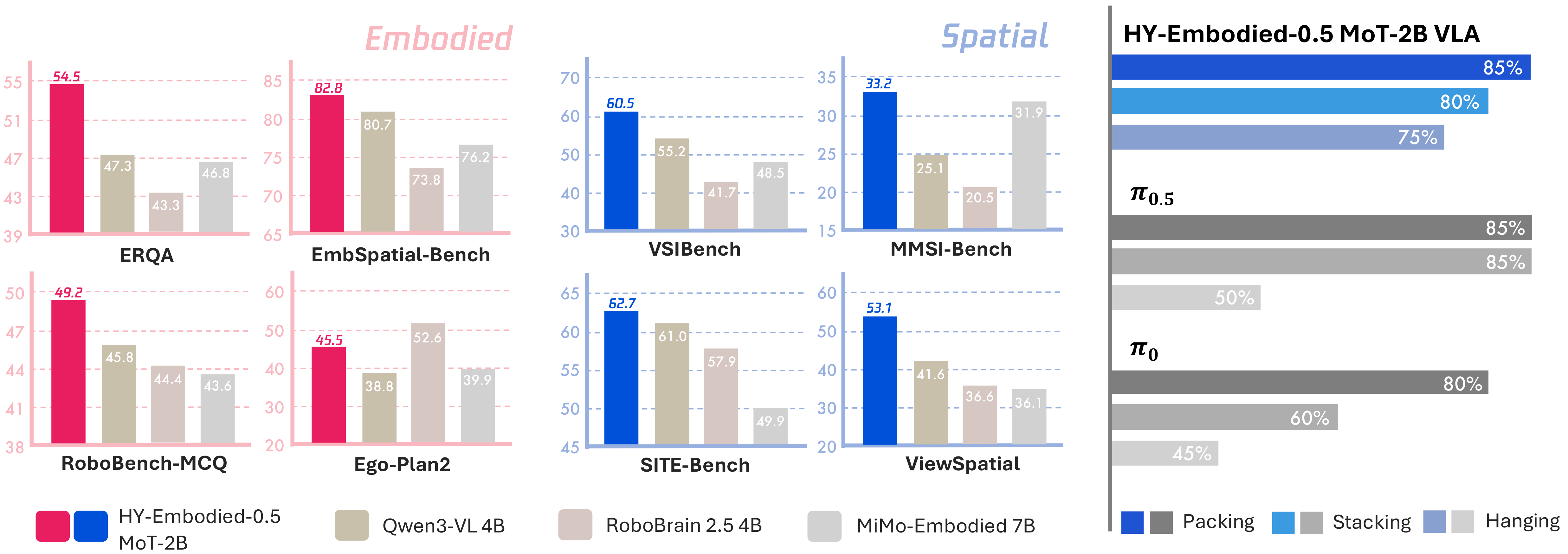
Figure 1 解读:teaser 把核心结论压缩成两组证据:MoT-2B 在 embodied/spatial benchmark 上相对同尺寸模型有优势,同时作为 VLA backbone 在 Packing、Stacking、Hanging 三个真实双臂任务上取得高成功率。这说明论文不是只做离线 VLM benchmark,而是把 foundation model 接到机器人控制里验证迁移。
2. Idea (核心思想)
核心 insight 是:embodied VLM 的瓶颈不是单纯扩大 LLM,而是要让视觉 token 在 Transformer 内有更适合物理感知的计算路径。HY-Embodied-0.5 用 MoT 为视觉和文本 token 分离 QKV/FFN/norm,并让视觉片段使用 full attention;再用 visual latent token 作为图像全局语义的桥,让视觉分支既能保留细节,又能被语言推理读取。
与常见 VLM(例如把 ViT features 直接投影进 LLM,再用统一 causal decoder 处理所有 token)相比,它的关键差异有三点:MoT 把 visual/text compute path 解耦;pre-training 从一开始加入大规模 spatial/robotics/perception 数据;post-training 不只做 SFT,而是用 GRPO-style RL + RFT self-evolution + large-to-small on-policy distillation 把 A32B 的深推理能力转给 MoT-2B。
这篇文章的创新更像“系统性 embodied foundation model recipe”,不是单一模块论文:architecture 负责提高视觉建模效率,data 负责补齐物理世界监督,post-training 负责把可验证任务奖励和长链 reasoning 稳定下来,VLA 实验负责验证模型可作为真实控制系统的 brain。
一个重要取舍是:MoT-2B 不追求把所有能力都塞进 dense 2B decoder,而是用 4B total / 2.2B activated 的方式给视觉分支更多专用容量,同时让 inference activated compute 接近 2B。这样它能服务边缘 VLA 场景:视觉 token 得到更强建模,decode latency 又不会像完整大模型那样增长。
方法上的分工也很清晰:
- Architecture:MoT 与 visual latent tokens 解决视觉 token 的表示/计算路径问题。
- Data:>600B tokens pre-training 与 30M mid-training instances 把物理世界监督前置。
- Post-training:RL/RFT/OPD 让长链 reasoning 从偶然成功变成稳定策略。
3. Method (方法)
3.1 Overall framework:HY-ViT 2.0 + MoT decoder + visual latent tokens
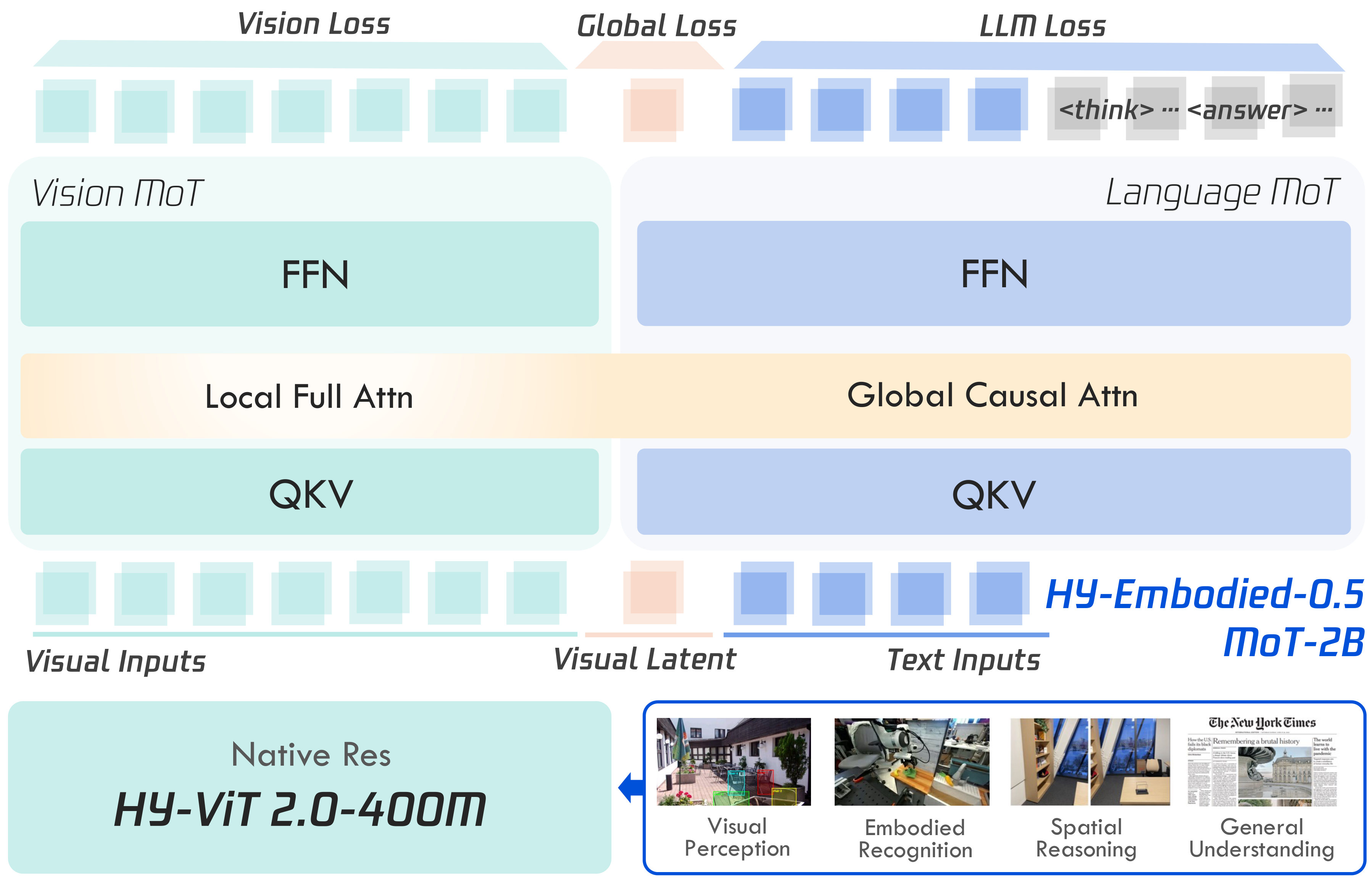
Figure 2 解读:整体结构仍是 VLM:HY-ViT 2.0-400M 先把原生分辨率图像/视频转成 visual tokens,再送入 HY-Embodied-0.5 decoder。关键不同在 MoT decoder:视觉 token 走 Vision MoT 的 QKV/FFN 和 local full attention,语言 token 走 Language MoT 的 QKV/FFN 和 global causal attention。训练时同时有 Vision Loss、Global Loss 和 LLM Loss;其中 visual latent token 位于视觉输入与文本输入之间,用 global teacher feature 监督,充当视觉全局语义桥。
HY-ViT 2.0 是任意分辨率视觉编码器,论文强调它通过更大规模视觉预训练、tiny LLM language supervision、visual reconstruction supervision,以及从更强 internal ViT 蒸馏来兼顾感知精度和边缘部署。对于 MoT-2B,ViT 约 400M 参数;另外训练了一个更大 ViT,把每个 image patch 压缩成 codebook size 2k 的 discrete code,作为 visual next-code prediction 的监督。
3.2 Modality-Adaptive MoT:分离视觉/文本路径与视觉 full attention
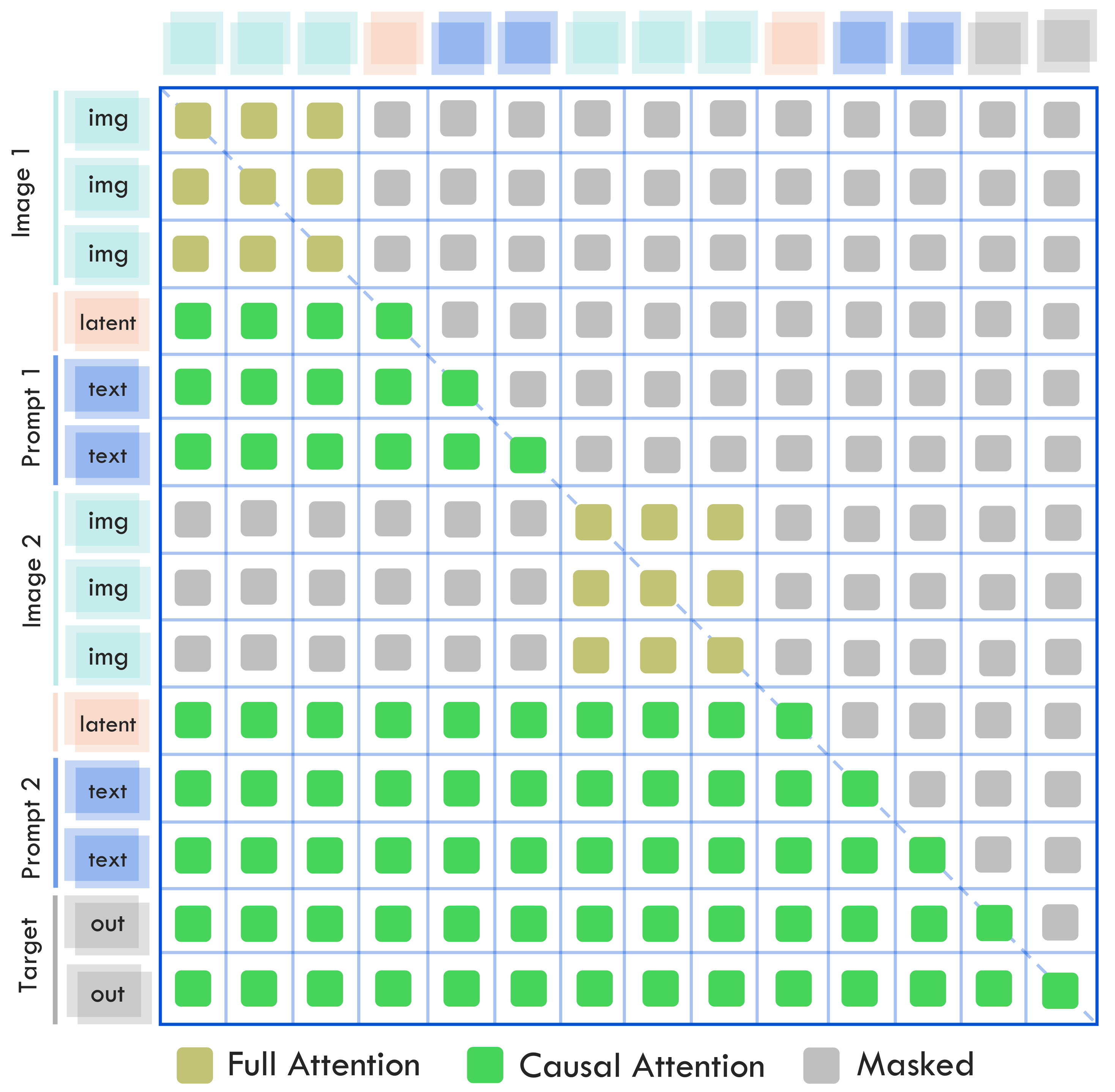
Figure 3 解读:attention mask 图展示同一个 interleaved multimodal sequence 内,不同 token 走不同 attention 规则:语言部分保持 causal attention,视觉块内部使用 full attention,跨段位置按任务需要被 masked。这样做的直觉是:图像/视频 token 没有自然的单向时间语言顺序,强行 causal 会削弱同一视觉元素内部的全局对齐;而把视觉 token 段拿出来做 bidirectional attention,可以更好建模局部空间结构。
released Transformers 实现与论文设计一致:HunYuanVLMoTAttention 同时定义文本投影 q_proj/k_proj/v_proj/o_proj 和视觉投影 q_proj_v/k_proj_v/v_proj_v/o_proj_v;HunYuanVLMoTDecoderLayer 也有文本 mlp/input_layernorm/post_attention_layernorm 与视觉 mlp_v/input_layernorm_v/post_attention_layernorm_v。forward 时通过 modality_mask 对视觉 token 和文本 token 分派不同函数。
更细节地,_flash_attention_forward_mot 先执行常规 causal flash attention,然后根据 v_seqlens 抽取视觉段,重新以 causal=False 跑一遍 flash attention,并把视觉段的输出写回原序列。因此 MoT 的额外开销主要发生在视觉段 prefill;decode 阶段仍由语言生成主导,Figure 10 也显示总 inference time 接近 Dense-2B。
3.3 Pre-training data 与 losses
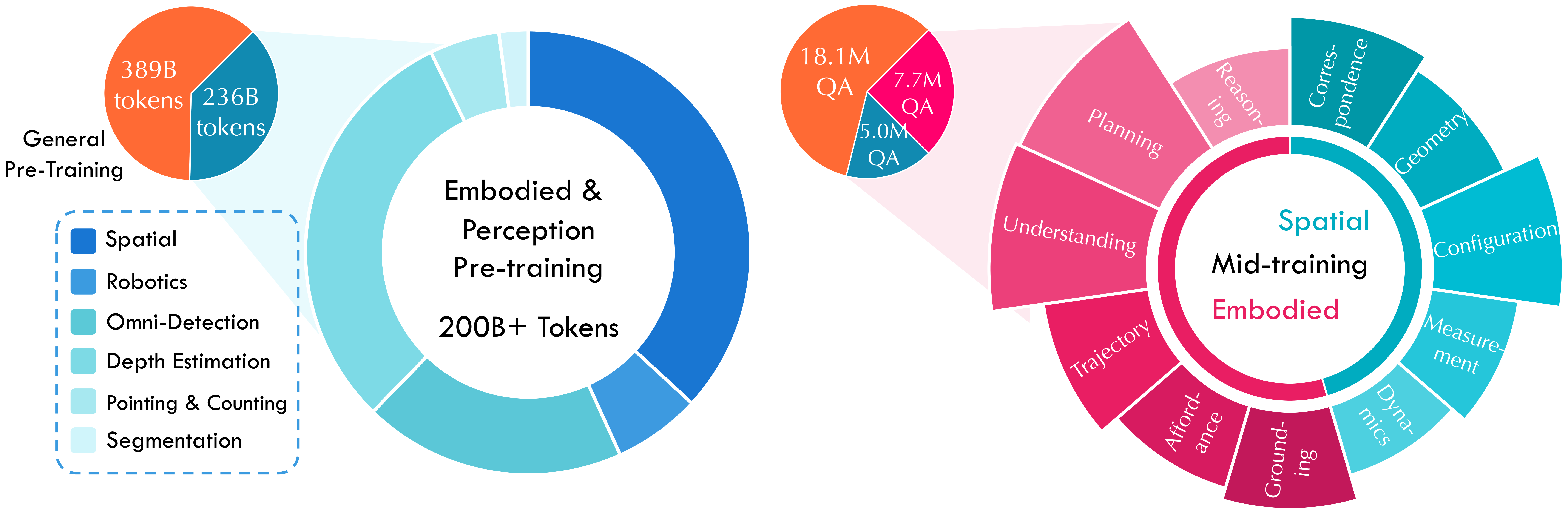
Figure 4 解读:pre-training mixture 分成 general、embodied/perception、spatial/robotics 等部分。论文主文给出 pre-training 总量超过 600B tokens,其中 general understanding 389B tokens,embodied/perception 236B tokens;后者中 spatial and robotics 占 43%,其余为 visual perception。mid-training 使用约 30M instances,并按 general:embodied:spatial = 12:5:3 混合。
视觉感知数据包括:62M Omni-Detection(OpenImages、Objects365、RefCOCO、SA-1B 等,含 2D/3D boxes,坐标归一化到 0–1000)、36M depth samples、5M segmentation samples、11M pointing/counting samples。Embodied-centric 数据覆盖 grounding、affordance、trajectory、understanding、planning、reasoning;spatial-centric 数据覆盖 correspondence、geometry、configuration、measurement、dynamics。
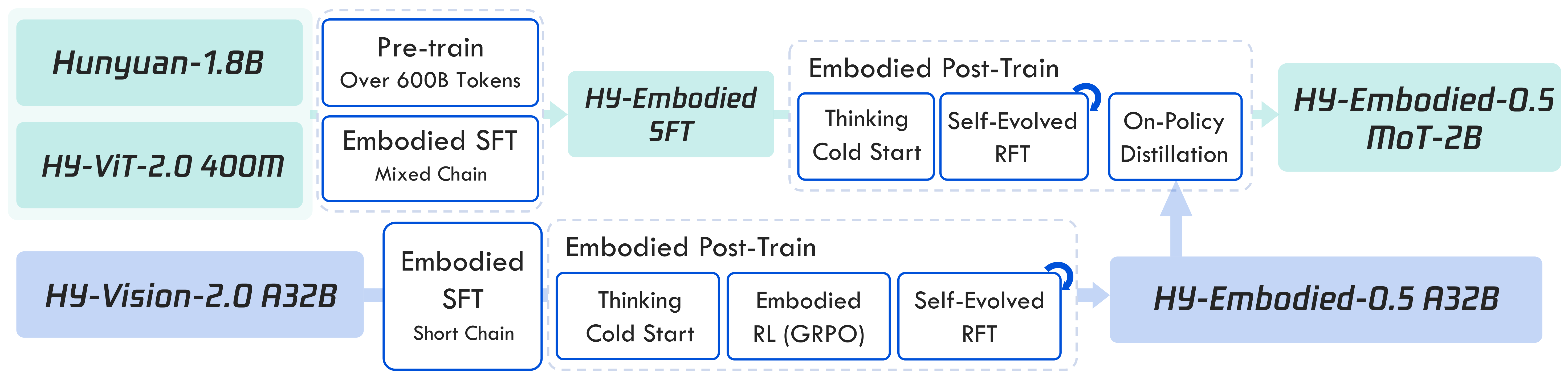
Figure 5 解读:训练管线从 Hunyuan-1.8B 和 HY-ViT2.0-400M 开始,先做 >600B tokens multimodal pre-training,再做 embodied-spatial mid-training;随后进入 embodied post-training:cold-start SFT、RL/GRPO、self-evolving RFT,最后做 on-policy distillation,把 HY-Embodied-0.5 B32B/A32B 的能力迁移到 MoT-2B。
pre-training 阶段联合优化三个目标。视觉 next-code prediction 对视觉 branch 的预测 logits 做交叉熵:
visual latent token 的 global loss 用 mapped latent hidden state 对齐 teacher ViT CLS feature ,是负余弦相似度:
总目标为:
mid-training 和后续 fine-tuning 阶段丢弃 vision/global supervision,只保留 autoregressive language loss 。pre-training 具体超参来自论文而非 released code:base LR ,ViT LR ,weight decay ,global batch size 256,sample packed 到 32k tokens;ViT、MoT、latent visual tokens 均可训练,ViT 和 visual tokens 每 5 step 更新一次。mid-training 继承初始 LR 和 packing,使用 cosine decay,冻结 ViT,只更新 HY-Embodied modules。
3.4 Post-training:cold-start SFT、task-aware RL、self-evolving RFT、OPD
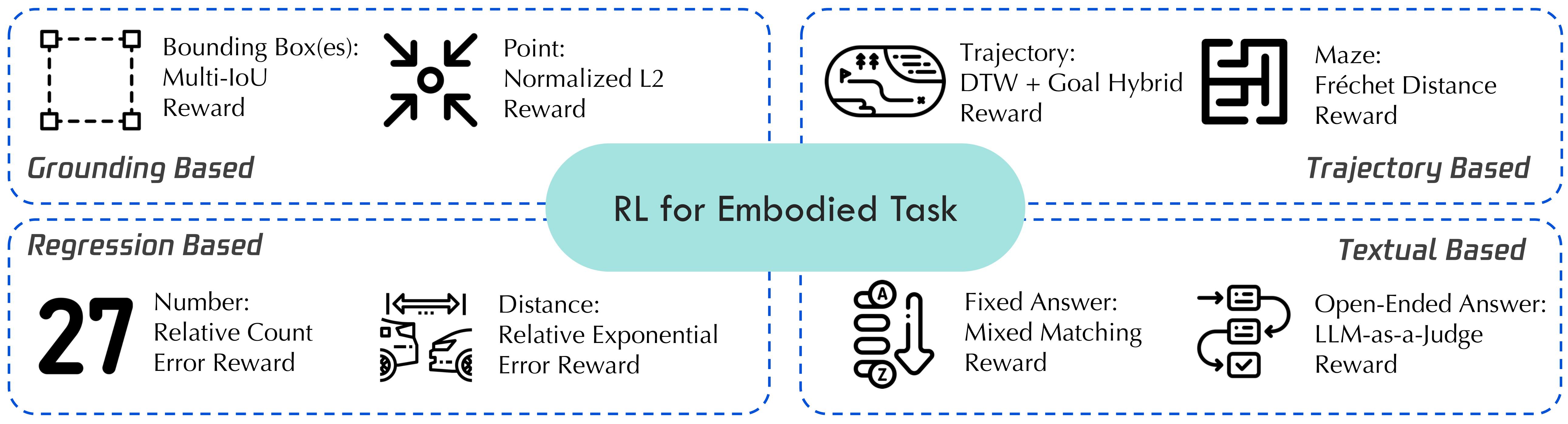
Figure 6 解读:RL reward 被设计成四类:Grounding-Based、Regression-Based、Trajectory-Based、Textual-Based。图中把每类 reward 对应到具体指标,例如 bounding boxes/masks IoU、points normalized L2、trajectory DTW/Chamfer/Fréchet distance、relative count/reward、exact match、LLM-as-judge reward 等。核心原则是“输出结构决定 reward 结构”:有几何结构就用 dense reward,有离散答案就用 exact/sequence similarity,开放问答才用 LLM judge。
SFT 阶段从 spatial、embodied、general data 里采高复杂多步问题,通过 human-model collaborative pipeline 生成 CoT,并由 LLM 评估 reasoning quality、logical correctness、sequence repetition,同时验证 final answer exact match,得到约 100k cold-start CoT instances。训练使用标准 cross-entropy,不使用 sequence packing,base LR 维持 。
RL 数据不是固定集:每轮用最新模型对 large candidate pool 做 multi-sample evaluation,丢弃全对(太容易)和全错(太难)的样本,只保留 partial success 的 frontier examples,并在 perception、prediction、interaction、planning 间平衡;每个 RL stage 使用新构造的 50K samples。
任务 reward 记为:
开放式任务使用 LLM judge fallback:
GRPO-style RL 中,对每个 multimodal input 采样 个 responses,组内 reward 标准化得到 advantage:
clipped policy-ratio loss 为:
其中:
论文给出的 RL 超参:group size ;PPO mini-batch size 与 rollout batch size 匹配以近似 on-policy;mask zero-reward-variance groups;对过长/重复回答做 quality control;对部分主观任务加 length shaping;asymmetric clipping 的有效范围是 ;maximum prompt length 16,384,maximum response length 16,384;sampling temperature 1.0、top-、top-;training batch size 128,LR ,每个 RL stage 5 epochs,并启用 gradient checkpointing 与 parameter/optimizer offloading。
RFT self-evolution 在 RL 之后从 curated pool 多样本 rollout,保留“部分成功”的 frontier 样本,再由强 teacher 给 reasoning trace 打分,约 1M candidates 过滤成约 300K high-quality traces 用于下一轮 SFT。RL 负责探索和扩展能力边界,RFT 把成功轨迹转成稳定的正监督。
large-to-small on-policy distillation (OPD) 不是离线模仿 teacher outputs,而是在 student 自己 roll out 的前缀上让 teacher teacher-forcing 给 next-token distribution。student 先生成:
再最小化:
直觉上,OPD 在 student 自己会访问的 decoding states 上学习 teacher,减少 offline distillation 的 train/inference mismatch;这对长链 embodied reasoning 尤其关键,因为能力分布在整个推理过程而不只在 final answer。
3.5 Public code search、released code 差异与 implementation-based pseudocode
代码搜索记录:arXiv abstract 明确链接 https://github.com/Tencent-Hunyuan/HY-Embodied;WebSearch 查询 "HY-Embodied-0.5" github、"Tencent-Hunyuan" "HY-Embodied" github、"HY-Embodied-0.5" "arXiv" "code" 均指向同一官方仓库;Hugging Face model tencent/HY-Embodied-0.5 公开 MoT-2B weights,config 的 architectures 为 HunYuanVLMoTForConditionalGeneration,auto_map 指向 configuration_hunyuan_vl_mot / modeling_hunyuan_vl_mot / processing_hunyuan_vl_mot。官方 GitHub 仓库本身主要提供 official inference code;实际 MoT model implementation 位于 README 要求安装的 huggingface/transformers@9293856c419762ebf98fbe2bd9440f9ce7069f1a。
论文公式与 released code 实现差异:官方 released code 没有公开 pre-training、GRPO/RFT/OPD/VLA training launch scripts 或 experiment configs;因此训练超参只能来自 paper text,不能声称来自代码。released implementation 可验证的是 inference path、processor、HY-ViT wrapper、MoT attention/decoder、image/video placeholder replacement、generation settings。下面的 released-code pseudocode 仅覆盖这些可验证部分;RL/OPD 训练伪代码是 paper-formula reconstruction,不标为 released implementation。
def official_inference_entrypoint(image_path: str, prompt: str):
# Based on Tencent-Hunyuan/HY-Embodied inference.py @ c9b3530e.
model_path = "tencent/HY-Embodied-0.5"
processor = AutoProcessor.from_pretrained(model_path)
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
).to("cuda" if torch.cuda.is_available() else "cpu").eval()
messages = [{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": prompt},
],
}]
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
enable_thinking=False,
).to(model.device)
with torch.no_grad():
out = model.generate(
**inputs,
max_new_tokens=1024,
use_cache=True,
temperature=0.8,
do_sample=True,
)
new_tokens = [o[len(i):] for i, o in zip(inputs.input_ids, out)]
return processor.batch_decode(new_tokens, skip_special_tokens=True)[0]def processor_prepare_multimodal(text, images=None, videos=None):
# Based on HunYuanVLMoTProcessor.__call__ @ transformers 9293856c.
image_inputs = image_processor(images=images) if images is not None else {}
video_inputs = video_processor(videos=videos) if videos is not None else {}
if images is not None:
# Replace each image token with a 2D grid of image tokens plus newline tokens.
for image_grid in image_inputs["image_grid_thw"]:
row = "<|placeholder|>" * (image_grid.w // image_processor.merge_size)
row = row + image_newline_token
prompt_grid = row * (image_grid.t * image_grid.h // image_processor.merge_size)
text = text.replace(image_token, prompt_grid, 1).replace("<|placeholder|>", image_token)
if videos is not None:
# Each sampled video frame is wrapped by vision_start/vision_end tokens.
for video_grid, metadata in zip(video_inputs["video_grid_thw"], video_inputs["video_metadata"]):
frame_prompt = build_frame_grid(video_grid, video_processor.merge_size)
video_prompt = "".join(vision_start_token + frame_prompt + vision_end_token
for _ in range(video_grid.t))
text = text.replace(video_token, video_prompt, 1)
tokenized = tokenizer(text)
return BatchFeature({**tokenized, **image_inputs, **video_inputs})def hunyuan_mot_forward(input_ids, pixel_values=None, pixel_values_videos=None):
# Based on HunYuanVLMoTModel.forward @ transformers 9293856c.
inputs_embeds = embed_tokens(input_ids)
union_mask = None
if training_or_has_pixels(pixel_values, pixel_values_videos):
image_embeds, video_embeds, zero = get_image_video_features(
pixel_values, pixel_values_videos, image_grid_thw, video_grid_thw,
device=inputs_embeds.device,
dtype=inputs_embeds.dtype,
)
if image_embeds:
image_mask, _, union_mask = get_placeholder_mask(input_ids, inputs_embeds, image_embeds)
inputs_embeds = inputs_embeds.masked_scatter(image_mask, torch.cat(image_embeds))
if video_embeds:
_, video_mask, union_mask = get_placeholder_mask(input_ids, inputs_embeds, video_embeds)
inputs_embeds = inputs_embeds.masked_scatter(video_mask, torch.cat(video_embeds))
inputs_embeds = inputs_embeds + zero
modality_mask = union_mask if union_mask is not None else torch.zeros(input_ids.shape, dtype=torch.bool)
return language_model(inputs_embeds=inputs_embeds, modality_mask=modality_mask)def mot_decoder_layer(hidden_states, modality_mask, attention_mask):
# Based on HunYuanVLMoTAttention and HunYuanVLMoTDecoderLayer @ transformers 9293856c.
# Text tokens use original norm/QKV/MLP; visual tokens use _v parameters.
h = mask_apply(hidden_states, modality_mask,
text_fn=input_layernorm,
vision_fn=input_layernorm_v)
q, k, v = mask_apply(h, modality_mask,
text_fn=(q_proj, k_proj, v_proj),
vision_fn=(q_proj_v, k_proj_v, v_proj_v))
attn = flash_attention(q, k, v, causal=True, attention_mask=attention_mask)
# Visual token spans are recomputed with bidirectional attention and written back.
for start, end in modality_mask_to_visual_segments(modality_mask):
attn[start:end] = flash_attention(q[start:end], k[start:end], v[start:end], causal=False)
attn = mask_apply(attn, modality_mask, text_fn=o_proj, vision_fn=o_proj_v)
hidden_states = hidden_states + attn
ff = mask_apply(hidden_states, modality_mask,
text_fn=lambda x: mlp(post_attention_layernorm(x)),
vision_fn=lambda x: mlp_v(post_attention_layernorm_v(x)))
return hidden_states + ffdef paper_formula_grpo_step(policy, old_policy, reward_fn, batch, group_size=16):
# Paper-formula reconstruction; training implementation is not released.
responses = [old_policy.sample(x, temperature=1.0, top_p=1.0, top_k=-1)
for x in batch for _ in range(group_size)]
rewards = [reward_fn(y, y_star) for y, y_star in responses]
advantages = group_normalize(rewards) # A_i = (r_i - mean(r)) / std(r)
loss = 0.0
for y, advantage in zip(responses, advantages):
for t in range(len(y.tokens)):
rho = policy.prob(y[t], y[:t]) / old_policy.prob(y[t], y[:t])
clipped = torch.clamp(rho, 0.8, 1.35) * advantage
loss += -torch.minimum(rho * advantage, clipped) / total_response_tokens(responses)
return lossCode reference:
master@c9b3530e(2026-04-14) for official repo;huggingface/transformers@9293856c(2026-04-08) for MoT model classes — pseudocode and mapping above are based on these commits.
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Official inference entry | HY-Embodied/inference.py | load_model_and_processor, single_inference, batch_inference |
| Released model config / model type | HF model config.json | HunYuanVLMoTForConditionalGeneration, model_type=hunyuan_vl_mot, hidden_size=2048, num_hidden_layers=32, num_attention_heads=16 |
| Multimodal prompt/token preparation | src/transformers/models/hunyuan_vl_mot/processing_hunyuan_vl_mot.py | HunYuanVLMoTProcessor.__call__, pad, _get_num_multimodal_tokens |
| HY-ViT image/video feature path | src/transformers/models/hunyuan_vl_mot/modeling_hunyuan_vl_mot.py | HYViT2_400MAnyRes, _HunYuanVLMoTVisionEncoder, get_image_video_features |
| MoT modality-specific QKV/FFN | same as above | HunYuanVLMoTAttention, HunYuanVLMoTDecoderLayer, _mask_apply |
| Visual full-attention override | same as above | _flash_attention_forward_mot, _modality_mask_to_segments |
| Placeholder replacement into language model | same as above | HunYuanVLMoTModel.forward, get_placeholder_mask, masked_scatter |
| Training/RL/OPD pipeline | not released in public repo | paper equations only; no launch script/config found |
4. Experimental Setup (实验设置)
4.1 Datasets and scale
训练数据按阶段组织:pre-training 总量超过 600B tokens,其中 389B 为 general understanding data,236B 为 embodied/perception data;236B 中 spatial and robotics 占 43%,visual perception 占其余部分。visual perception 明细包括 62M Omni-Detection、36M depth estimation、5M segmentation、11M pointing/counting。mid-training 使用约 30M instances,按 general:embodied:spatial = 12:5:3 混合。
SFT 使用约 100K cold-start CoT instances。每个 RL stage 从 candidate pool 重新筛 50K samples。RFT self-evolution 从约 1M candidate examples 过滤到约 300K high-quality traces。VLA 阶段先用 5K hours UMI data fine-tune action expert,再对三项真实机器人任务采集 300–700 episodes/task 做 SFT。
4.2 Benchmarks and baselines
离线评测覆盖 22 个 embodied-relevant benchmarks:CV-Bench、DA-2K;ERQA、EmbSpatial-Bench、RoboBench-MCQ、RoboBench-Planning、RoboSpatial-Home、ShareRobot-Aff.、ShareRobot-Traj.、Ego-Plan2;3DSRBench、All-Angles Bench、MindCube、MMSI-Bench、RefSpatial-Bench、SAT、SIBench-mini、SITE-Bench-Image、SITE-Bench-Video、ViewSpatial、VSIBench、Where2Place。
MoT-2B 对比 Qwen3-VL 2B/4B、RoboBrain 2.5 4B、MiMo-Embodied 7B;A32B 对比 Kimi K2.5、Seed 2.0、Qwen 3.5 A17B、Gemini 3.0 Pro。通用视觉 benchmark 使用 RealWorldQA、Hallusion-Bench、BLINK、CharXiv-RQ、DocVQA、OCRBench、TextVQA,对比 InternVL3.5-2B 和 Qwen3-VL-2B-Thinking。机器人控制对比 与 。
4.3 Metrics and training/inference config
主要报告 micro-average;3DSRBench 和 SAT 用 circular accuracy;ShareRobot-Aff. 用 mIoU;ShareRobot-Traj. 用 ,其中 DFD 是 Dynamic Fréchet Distance,低 DFD 更好,所以报告 保持“越高越好”。真实机器人任务每个 task/model 进行 20 trials,以 success rate (%) 统计。
训练 config:pre-training base LR 、ViT LR 、weight decay 、global batch size 256、max context 32k;mid-training 约 30M instances、general:embodied:spatial = 12:5:3、cosine LR decay、冻结 ViT;SFT base LR 且不 pack;RL max prompt/response length 各 16,384、group size 16、batch size 128、LR 、每 stage 5 epochs、temperature 1.0/top- 1.0/top- -1、clip range 。
released inference config 来自 inference.py:MODEL_PATH="tencent/HY-Embodied-0.5",THINKING_MODE=False,TEMPERATURE=0.8,MAX_NEW_TOKENS=1024,torch_dtype=torch.bfloat16,device 为 CUDA if available else CPU。HF config 显示 MoT-2B released checkpoint 的 text hidden size 2048、32 decoder layers、16 attention heads、4 KV heads、max position embeddings 262,144;image processor 使用 patch size 16、merge size 2、max pixels 4,194,304;video processor 默认 fps 2.0、min frames 8、max frames 16。
5. Experimental Results (实验结果)
5.1 MoT-2B embodied/spatial benchmark results
论文主文结论:HY-Embodied-0.5 MoT-2B 在 22 个 benchmark 中拿到 16 个第一(best performance on 16 out of 22 benchmarks)、4 个第二,平均分 58.0%;相比 Qwen3-VL-4B 高 10.2 points,相比 RoboBrain2.5-4B 高 8.6 points。下表列出 paper table 中的精确数值。
| Benchmark | HY MoT-2B | Qwen3-VL 2B | Qwen3-VL 4B | RoboBrain 2.5 4B | MiMo 7B |
|---|---|---|---|---|---|
| CV-Bench | 89.2 | 80.0 | 85.7 | 86.9 | 88.8 |
| DA-2K | 92.3 | 69.5 | 76.5 | 79.4 | 72.2 |
| ERQA | 54.5 | 41.8 | 47.3 | 43.3 | 46.8 |
| EmbSpatial-Bench | 82.8 | 75.9 | 80.7 | 73.8 | 76.2 |
| RoboBench-MCQ | 49.2 | 36.9 | 45.8 | 44.4 | 43.6 |
| RoboBench-Planning | 54.2 | 36.2 | 36.4 | 39.2 | 58.7 |
| RoboSpatial-Home | 55.7 | 45.3 | 63.2 | 62.3 | 61.8 |
| ShareRobot-Aff. | 26.8 | 19.8 | 25.5 | 25.5 | 9.0 |
| ShareRobot-Traj. | 73.3 | 41.6 | 62.2 | 81.4 | 50.6 |
| Ego-Plan2 | 45.5 | 35.5 | 38.8 | 52.6 | 39.9 |
| 3DSRBench | 57.0 | 39.9 | 43.9 | 44.8 | 42.0 |
| All-Angles Bench | 55.1 | 42.3 | 46.7 | 43.8 | 49.0 |
| MindCube | 66.3 | 28.4 | 31.0 | 26.9 | 36.2 |
| MMSI-Bench | 33.2 | 23.6 | 25.1 | 20.5 | 31.9 |
| RefSpatial-Bench | 45.8 | 28.9 | 45.3 | 56.0 | 48.0 |
| SAT | 76.7 | 45.3 | 56.7 | 51.3 | 78.7 |
| SIBench-mini | 58.2 | 42.0 | 50.9 | 47.3 | 53.1 |
| SITE-Bench-Image | 62.7 | 52.3 | 61.0 | 57.9 | 49.9 |
| SITE-Bench-Video | 63.5 | 52.2 | 58.0 | 54.8 | 58.9 |
| ViewSpatial | 53.1 | 37.2 | 41.6 | 36.6 | 36.1 |
| VSIBench | 60.5 | 48.0 | 55.2 | 41.7 | 48.5 |
| Where2Place | 68.0 | 45.0 | 59.0 | 65.0 | 63.6 |
5.2 A32B frontier comparison and general VLM retention
A32B 结果:HY-Embodied-0.5 MoE-A32B 在 22 个 benchmark 中第一 7 项、第二 6 项,overall score 67.0;高于 Gemini 3.0 Pro 63.6、Seed 2.0 66.2、Qwen 3.5 A17B 66.1、Kimi K2.5 61.1。这个结果说明大模型版本不是只在专门 embodied benchmark 上有效,而是在同一 evaluation protocol 下达到 frontier-VLM 级别。
Figure 12 解读:通用视觉 benchmark 里,HY MoT-2B 没有因为 embodied specialization 而完全牺牲通用能力。按图中顺序,HY 在 RealWorldQA/Hallusion-Bench/BLINK/CharXiv-RQ/DocVQA/OCRBench/TextVQA 上分别是 66.4/66.3/63.1/35.8/87.5/76.8/72.3;InternVL3.5-2B 是 62.0/48.6/51.3/31.6/89.4/83.6/76.5;Qwen3-VL-2B-Thinking 是 69.5/54.9/57.2/37.1/92.9/79.2/77.1。HY 在 Hallusion 和 BLINK 明显更强,在 OCR/Text/Doc 任务上略低于通用模型,符合“专门增强 embodied/spatial,但保留可用 general VQA”的定位。
5.3 Qualitative, efficiency and VLA results
Figure 7 解读:perception qualitative 覆盖深度估计、detection、pointing、counting 和 region caption。关键观察是 HY 的回答更接近 GT,尤其在距离/深度、目标点位和复杂计数上更少出现 hallucination;这对应 pre-training 中 depth、segmentation、pointing/counting 和 Omni-Detection 数据的投入。

Figure 8 解读:embodied qualitative 展示 grounding、scene understanding、task planning 三类任务。模型不仅输出物体位置,还能判断空间关系和下一步动作,例如在 cluttered robot scene 中定位目标物体、判断 cube 的相对位置、根据已完成步骤推断下一步操作。

Figure 9 解读:CoT 图展示 MoT-2B 与 A32B 的 long-chain reasoning。值得注意的是,模型会显式分析 spatial relationship 和 affordance,并在 <think> 中出现 self-reflection/correction。这支持论文的 post-training 叙事:RL/RFT/OPD 不是只提高 final answer,而是改变推理轨迹质量。
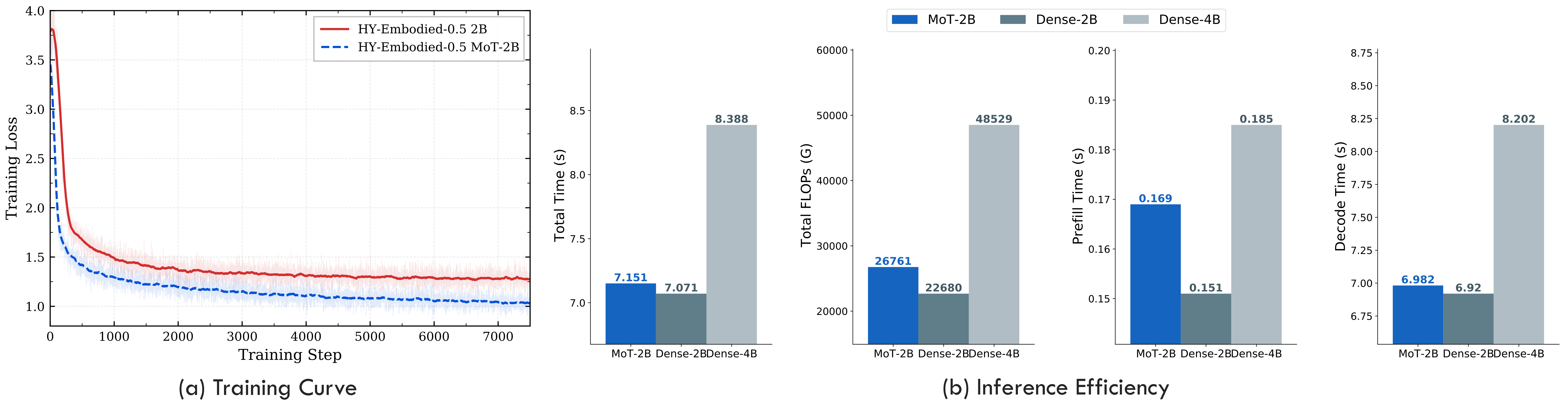
Figure 10 解读:MoT 相比 Dense-2B 收敛更快、final loss 更低;inference efficiency 图显示 total inference time 和 theoretical FLOPs 接近 Dense-2B。原因是视觉 branch 的额外 full-attention/duplicated projections 主要影响 prefill,而实际生成由 decode time 主导,因此 MoT 带来的感知收益没有转化成显著延迟惩罚。

Figure 11 解读:visual latent token 的 attention visualization 显示,视觉注意力能定位 salient objects、关键物体部件和空间区域,语言注意力则集中在实体、状态和动作词上。这是 visual latent token “连接视觉 full attention 与语言 causal attention”的证据:它不是普通占位符,而是让全局图像语义可被语言推理读取的桥。
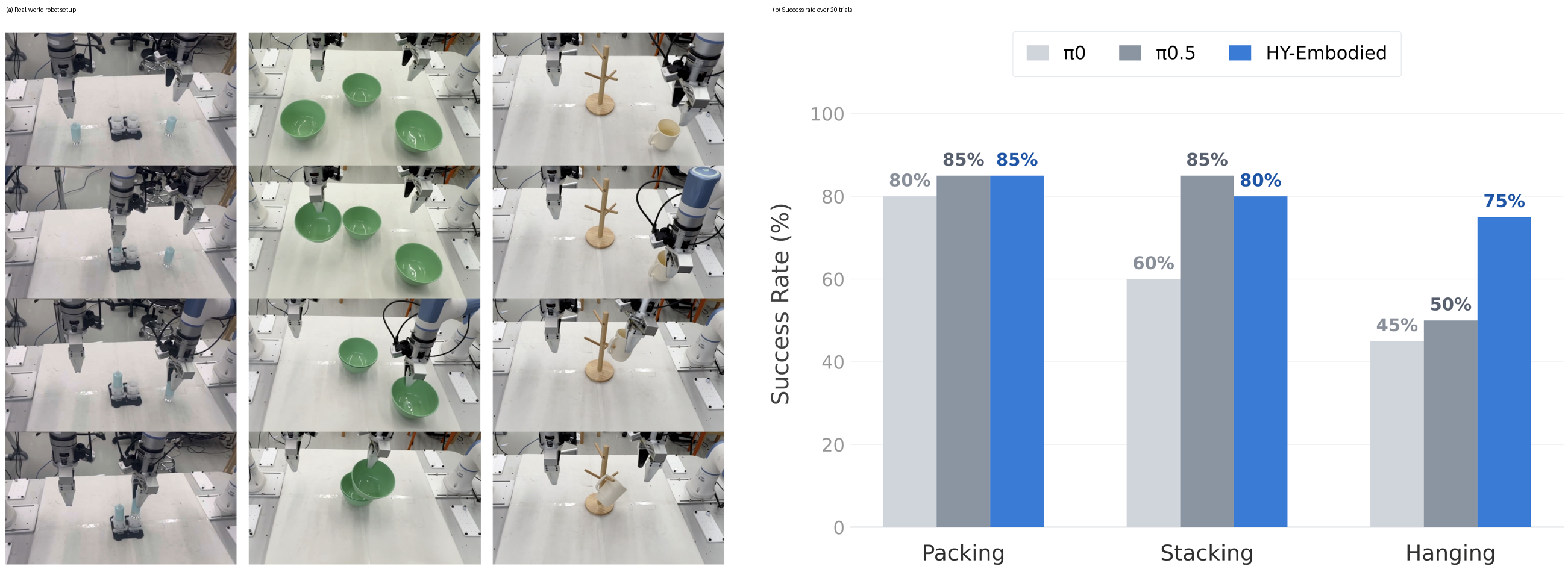
Figure 13a–13b 解读:VLA 实验使用 dual-arm Xtrainer、head-mounted 和 wrist-mounted cameras;三个任务各 20 trials/model。HY-Embodied 在 Precision Plug-in Packing 达 85%,与 持平并高于 的 80%;Tableware Stacking 为 80%,高于 的 60% 但低于 的 85%;Mug Hanging 为 75%,明显高于 的 45% 和 的 50%。作者解释为 5K hours UMI fine-tuning + MoT foundation representation 提升了迁移到 embodiment-specific manipulation 的能力。
5.4 Appendix qualitative inventory

Figure B1 解读:末端执行器轨迹预测样例展示模型如何把自然语言目标转成多步空间点列,适合检查“轨迹是否落在可执行路径上”而不只是给出终点。

Figure B2 解读:关节控制轨迹样例强调动作序列的连续性;它补充说明 ShareRobot-Traj. 一类指标并非单帧定位,而是评估完整运动曲线。

Figure B3 解读:2D bounding box grounding 样例覆盖空中/室内目标,显示模型可在自然语言指令下输出具体框坐标。

Figure B4 解读:point-based localization 样例对应训练中的 pointing 数据,展示模型能从“可交互部位”层面定位,而非只识别物体类别。

Figure B5 解读:距离估计样例对应 metric reasoning:模型需要结合多帧视角和尺度线索输出物理距离。

Figure B6 解读:面积估计样例测试绝对尺度推理,能暴露一般 VLM 只会描述场景、不会数值估计的问题。

Figure B7 解读:多视角空间推理样例要求跨图像建立对应关系,是论文中 spatial-centric data 的直接可视化。

Figure B8 解读:orientation-aware spatial reasoning 强调以观察者朝向为参考的 left/right/front/back 判断,区别于图像平面坐标判断。

Figure B9 解读:embodied perception 样例连接视觉识别与机器人操作语境,说明模型需识别场景状态和可操作对象。

Figure B10 解读:affordance-aware localization 要求模型根据任务意图找“应该操作哪里”,不是找所有可见物体。

Figure B11 解读:navigation-oriented localization 样例面向路径/导航决策,强调目标位置和可达性的联合判断。

Figure B12 解读:task planning verification 展示模型对历史步骤、当前状态和下一步动作之间一致性的判断。

Figure B13 解读:embodied QA 样例体现从图像状态到动作语义的问答能力,补充主文 Figure 8 的任务类型。

Figure B14 解读:sorting-based reasoning 样例测试多目标排序和细粒度视觉比较,是长链推理能力的可视化证据。

Figure B15 解读:counting-based reasoning 样例展示模型通过定位多个目标后再计数,呼应论文对 visual CoT 的强调。

Figure B16 解读:general VQA 样例说明模型在强化 embodied 能力后仍保留通用视觉问答能力。
5.5 Limitations and takeaway
作者没有在 Conclusion 中列出系统性 failure cases;可从公开材料确认的限制主要是 release scope:公开仓库只有 inference code、HF weights 和 Transformers 模型实现,training/RL/OPD/VLA code not public:没有训练脚本、RL/RFT/OPD 配置、数据配方或 VLA action expert 代码。因此,论文中最关键的 training recipe 目前难以完全复现,只能验证 released inference/model path 与论文架构一致。
总体结论:HY-Embodied-0.5 的贡献在于把 embodied VLM 的三件事连起来——MoT/visual latent token 改 architecture,大规模 embodied/spatial data 改 pretraining distribution,RL+RFT+OPD 改 post-training reasoning trajectory。结果上,MoT-2B 用较小 activated 参数在 22 项 benchmark 上取得 58.0 average 和 16 项第一;A32B 达到 67.0 average;VLA 实验则显示这种 VLM backbone 能转化为真实机器人操作成功率。