Green-VLA: Staged Vision-Language-Action Model for Generalist Robots
Paper: arXiv:2602.00919 Code: greenvla/GreenVLA Code reference:
main@952a80c3(2026-03-05)
1. Motivation (研究动机)
当前 VLA 的核心问题不是“模型还不够大”这么简单,而是机器人数据和控制接口本身不统一:不同 embodiment 的相机、proprioception、控制频率、action parameterization 都不同;同一个 padding 维度在不同机器人上可能代表完全不同的物理含义;数据质量还混有 jitter、blur、idle / failure segment 和低多样性场景。直接把这些轨迹拼起来做 Behavior Cloning,会把跨机器人差异变成噪声。
论文把传统 BC 写成:
这个目标在短 horizon 模仿上有效,但对长任务中的失败恢复、任务级 reward、精确目标选择没有显式优化;当机器人偏离 demonstration manifold 时,BC 也缺少机制把策略拉回安全状态。已有 EO-1 / WALL-OSS 等显式 reasoning VLA 能改善长程规划,但 autoregressive reasoning loop 会增加实时控制延迟。
Green-VLA 要解决的具体问题是:如何在真实 humanoid 部署中保留低延迟控制,同时把 web-scale 语义先验、3,000 小时机器人演示、多 embodiment action、DataQA、JPM guidance 和 RL alignment 串成一个可部署的 staged VLA pipeline。解决后带来的价值是:同一个策略可以跨 humanoid、mobile manipulator、fixed-base arm 迁移,并在 Green humanoid 的 32 DoF 上执行双臂、躯干、头部和 dexterous hands 的真实任务。
2. Idea (核心思想)
Green-VLA 的核心 insight 是:generalist robot 不应该只靠“更多数据 + 单阶段 BC”,而应把不同瓶颈拆成连续 stage:L1 学物理世界和空间语义,R0 学多 embodiment affordance,R1 针对目标 embodiment 做 SFT,R2 再用 reward / Q-gradient / source-noise optimization 处理 BC 饱和后的长程鲁棒性。
与 naive VLA 的根本区别有三点:第一,action space 不再是简单 padding,而是语义固定的 unified slots + embodiment/control prompt + mask loss;第二,数据不是按规模盲采样,而是用 DataQA、optical-flow temporal alignment 和 target sampling schedule 控制质量与速度;第三,推理侧不只输出动作,还引入 episode progress、OOD manifold correction、JPM 目标点和 high-level task planner,让真实机器人可以在长任务中终止、replan 和精确对齐目标。
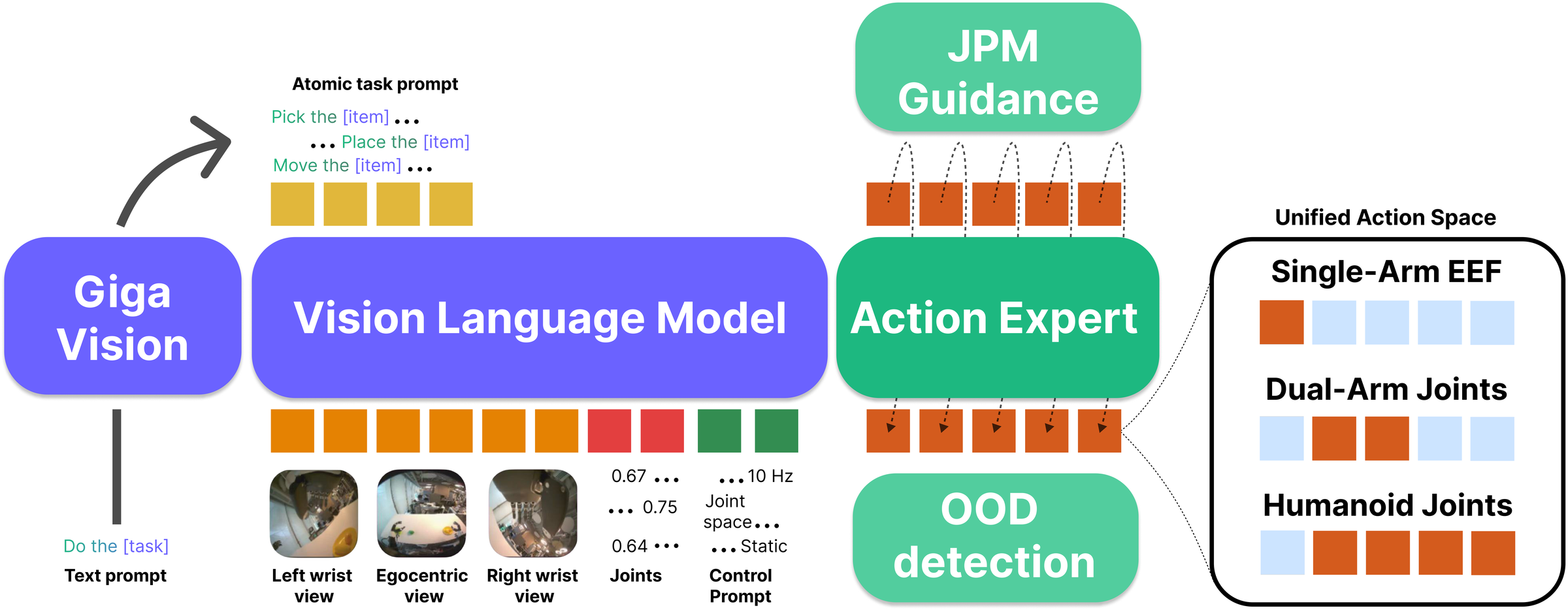
Figure 1 解读:整体架构由高层 task planner、VLM encoder、flow-matching action expert 和辅助安全/目标模块组成。planner 把用户目标拆成 atomic subtasks;VLM 接收语言、三路相机和 proprioception;action expert 生成 action chunk;episode-end、OOD detector 和 JPM guidance 则分别负责终止判断、安全回拉和精确目标定位。
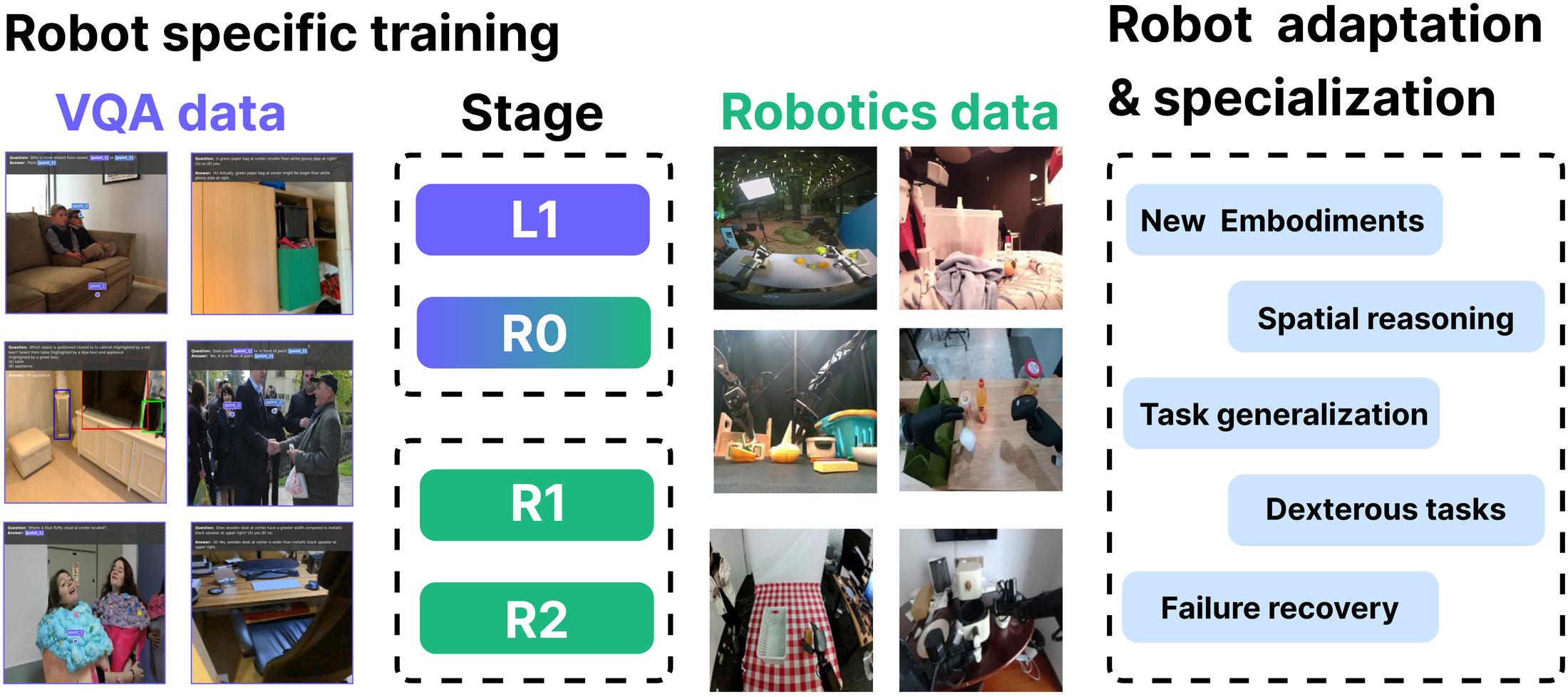
Figure 2 解读:五阶段训练是论文的主线:L0 是 base VLM,L1 用 web / multimodal VQA 强化物理世界理解,R0 用多 embodiment 机器人数据学通用操控,R1 做 embodiment-specific SFT,R2 做 RL alignment。每个阶段对应不同瓶颈,而不是把所有目标塞进同一个 BC objective。
3. Method (方法)
3.1 数据框架:L1 web data + R0 robotics data + DataQA
L1 使用 24M 非机器人 internet-scale multimodal samples,覆盖 general VQA、pointing、bounding-box prediction、pixel-wise trajectory prediction、multi-view VQA、captioning、spatial reasoning 等。R0 使用 184M robotics-domain samples,合计超过 3,000 小时,来自 humanoid、ALOHA、single-arm 等多种 embodiment。每个 episode 都带语言指令;RGB 和 proprioception 会先做 temporal normalization,使不同来源在“物理进展”上对齐。
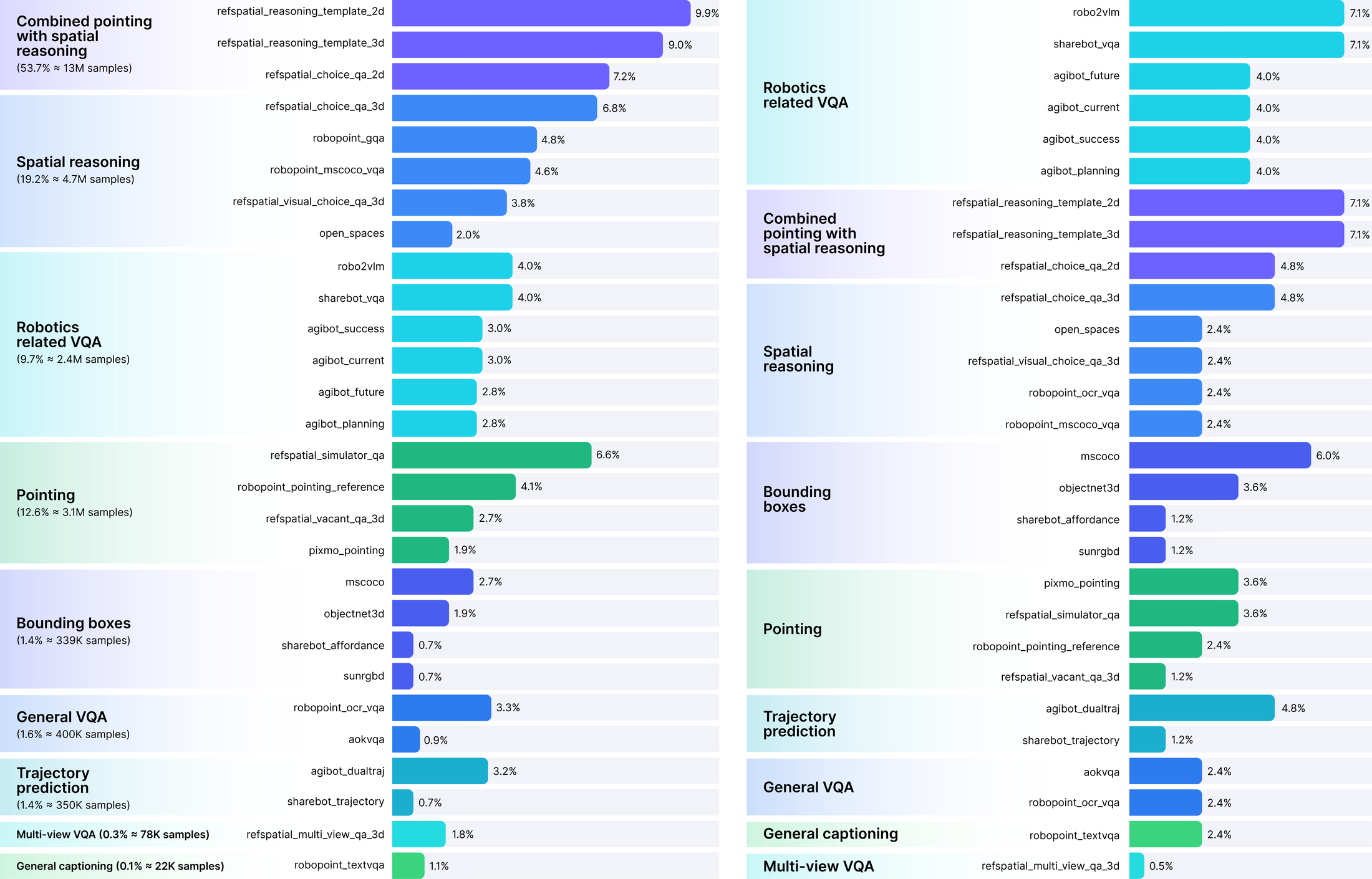
Figure 3 解读:L1 mixture 把 RefSpatial、Agibot-derived VQA、RoboPoint、ShareRobot、Robo2VLM、PixMo-Points、MS COCO、A-OKVQA、OpenSpaces、Sun RGB-D 等数据按任务类别重加权。左侧体现 sample count,右侧体现实际 sampling weight;这说明 Green-VLA 并非按 raw count 采样,而是显式平衡 spatial / pointing / robotics-related VQA。
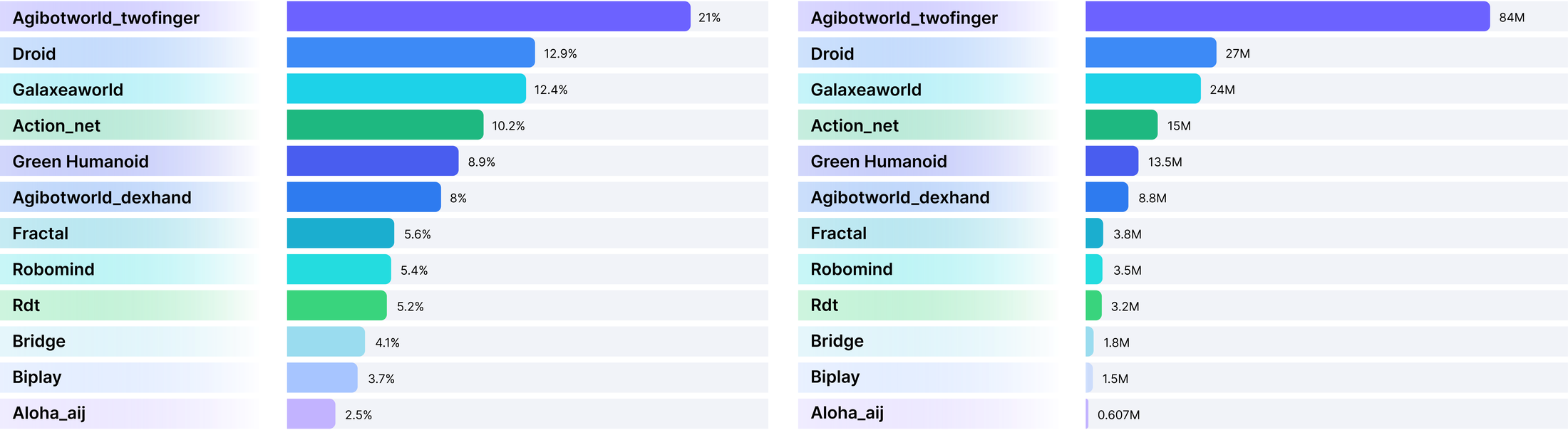
Figure 4 解读:R0 数据混合了 AgiBotWorld twofinger / dexhand、DROID、Galaxea、ActionNet、Fractal、RoboMind、RDT、Bridge、BiPlay,以及自采 Green Humanoid 和 ALOHA any_pick。自采 Green Humanoid 原始 48 小时通过左右镜像与可逆任务 time-reversal 扩到 167 training hours。
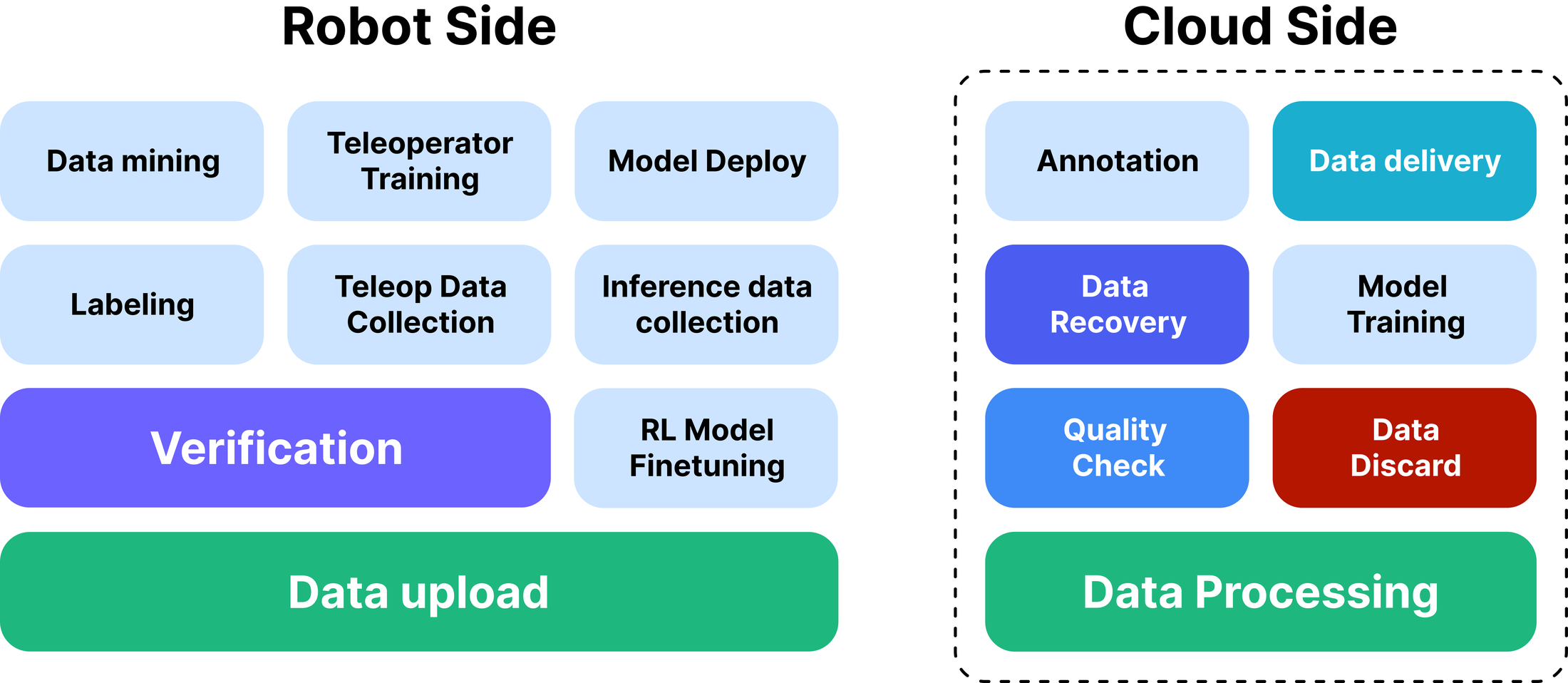
Figure 5 解读:Data pipeline 包含 robot-side teleoperation、cloud verification、open-source dataset mining、model training 和 deployment feedback。它的关键不是单次离线清洗,而是通过真实部署反馈持续更新数据和 R2 轨迹。
DataQA 过滤与加权包含:缺相机/缺帧、过短或异常过长 episode、动作活跃度、gripper pattern、tremble、sharpness、visual diversity 和 state diversity。核心指标包括:
论文表 1 的主要采样权重:AgiBot twofinger 0.210、DROID 0.129、Galaxea 0.124、ActionNet 0.102、Green Humanoid 0.089、AgiBot dexhand 0.080。AgiBot twofinger 权重大是因为 774 小时且 humanoid 相关视觉多样性高;DROID 在 single-arm 中权重最高,因为轨迹更平滑、任务/场景更丰富。
3.2 Unified Action Space:从 padding 到 semantic slots
论文先指出 naive padding 的目标:
如果 表示 embodiment 的有效维度,则 padding loss 实际包含 spurious penalty:
Green-VLA 改用 unified action space ,用 把 native action 映射到固定语义 slot,并只在有效 slot 上训练:
控制 prompt 序列化 arms/hands、gripper or dex-hand、joint/cartesian、mobile/static、slots used 等信息:
源码中的实现对应 map_to_unified_space:Bridge / Fractal 把 Cartesian xyz 映射到 slots 35–37,把旋转映射到 42–44,把 gripper 映射到 13;ALOHA 把左臂 joints 映射到 1–6、左 gripper 到 13、右臂 joints 到 15–20、右 gripper 到 27。
论文公式与 released code 实现差异:论文正文描述 ;released config 有 unified_space_dim: 64,但实际 lerobot/conf/policy/greenvla_policy.yaml 和 fine-tuning configs 使用 max_state_dim: 48、max_action_dim: 48,torch_transforms.py 注释还写着 “unified 43-dim vector”。因此当前 release 更像是公开 benchmark / fine-tuning 用的 48D padded-unified interface,而不是论文中完整 64D 生产控制栈的逐槽实现。
3.3 Temporal alignment、speed conditioning、progress 和 OOD safety
不同机器人和 operator 的速度不同,直接混合会让同一个 action step 对应不同物理进展。Green-VLA 用 wrist-camera mean optical flow 估计每个数据集的视觉运动强度,对 Bridge / Fractal 等低采样但大 optical flow 数据做 densification,对 AgiBot DexHand 等慢动作高频数据做 downsampling,并用 monotonic cubic spline 插值 action。
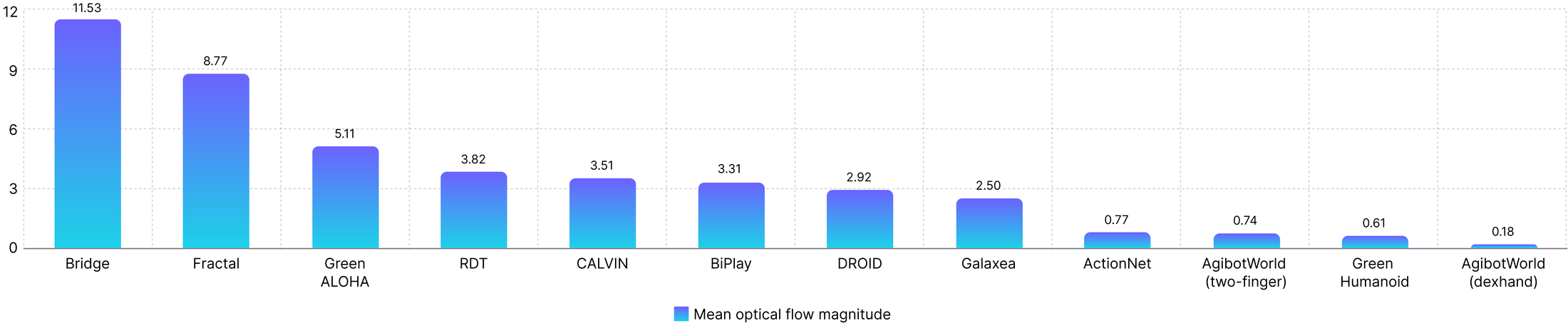
Figure 6 解读:横轴显示各数据集的 mean optical flow magnitude。高 flow 表示相邻帧视觉变化大,需要插入更多中间 waypoint;低 flow 表示相邻帧冗余更多,可以跳帧。这个图支撑了 temporal alignment 不是固定倍数重采样,而是基于视觉运动统计的 dataset-specific 策略。
在 temporal alignment 之上,模型引入 action speed scalar ,用 控制目标轨迹的有效时间分辨率。论文给出 RMS-style modulation:
其中 倾向于更慢、更密的中间 waypoint, 倾向于更快、更粗的 action chunk。flow-matching expert 还预测 episode progress ,监督信号为 ,供 high-level planner 判断 subtask 是否结束。
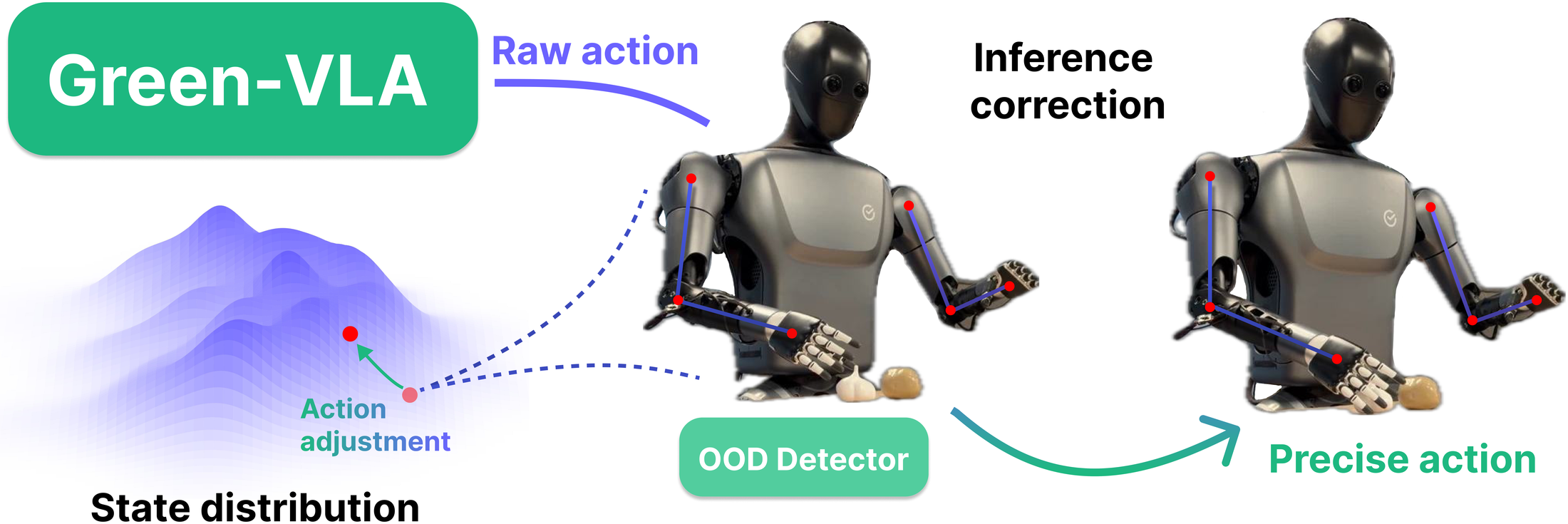
Figure 7 解读:OOD detector 用训练集 robot states 拟合 GMM:。当 rollout 进入低密度区域 ,系统按 修正目标状态,论文给出 ,目的是把机器人动作拉回训练 manifold。
论文公式与 released code 实现差异:公开仓库中没有找到 GMM OOD detector、episode progress head、speed-conditioned RMS modulation 的完整实现;release 主要包含 flow-matching policy、tokenizer、data transforms、inference 和 fine-tuning configs。
3.4 JPM guidance:把语言目标从 2D 点提升到 3D / IK 约束
JPM 针对货架等密集 SKU 场景:先用专门 VLM 在图像上预测语言条件的 2D affordance point ,再结合深度 、相机内参 和相机外参 提升到 robot-base frame:
然后用 IK 求出可达 joint configuration ,并在 flow-matching denoising 中用 pseudoinverse guidance 给 velocity field 加上朝向目标 的 correction,得到 。
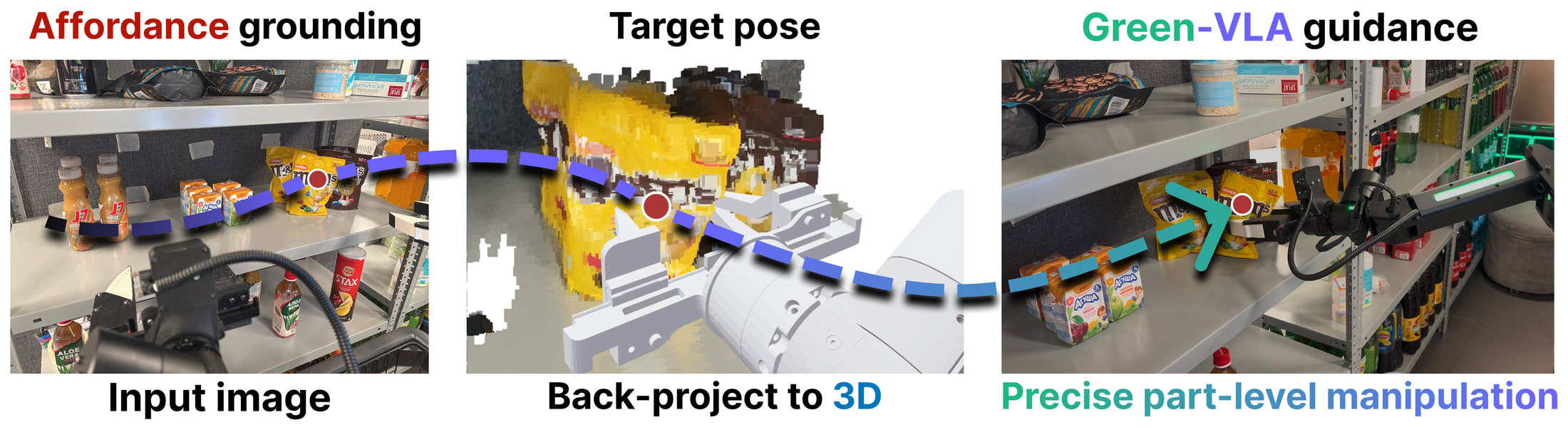
Figure 10 解读:JPM guidance pipeline 先 grounding 2D affordance,再通过深度和相机位姿 lift 到 3D,最后初始化 Green-VLA guidance 目标。它解决的是 end-to-end VLM policy 在近似包装、细粒度 SKU、OOD 包装上容易选错对象的问题。
论文公式与 released code 实现差异:公开仓库没有找到 JPM、IK guidance 或 的源码;笔记中的 JPM 解释来自论文公式和图,不把它伪装成 release code。
3.5 R2 RL alignment:不直接改 base policy,而是优化轨迹和 source noise
R2 包含两条路线。第一条是 IQL critic + trajectory optimization:训练 / ,然后对 R1 policy 生成的动作做 Q-gradient 更新,再人工/环境验证优化后轨迹,把通过验证的数据加入 R1 dataset 并从 R0 权重重新 native fine-tuning。核心目标为:
第二条是 source distribution optimization:flow-matching 训练的是 velocity field
R1 默认 为 Gaussian;R2 用 actor-critic 学一个新的 source distribution ,让 base flow policy 在环境中的 return 更高,同时动作仍接近训练分布,降低在线 RL 探索风险。
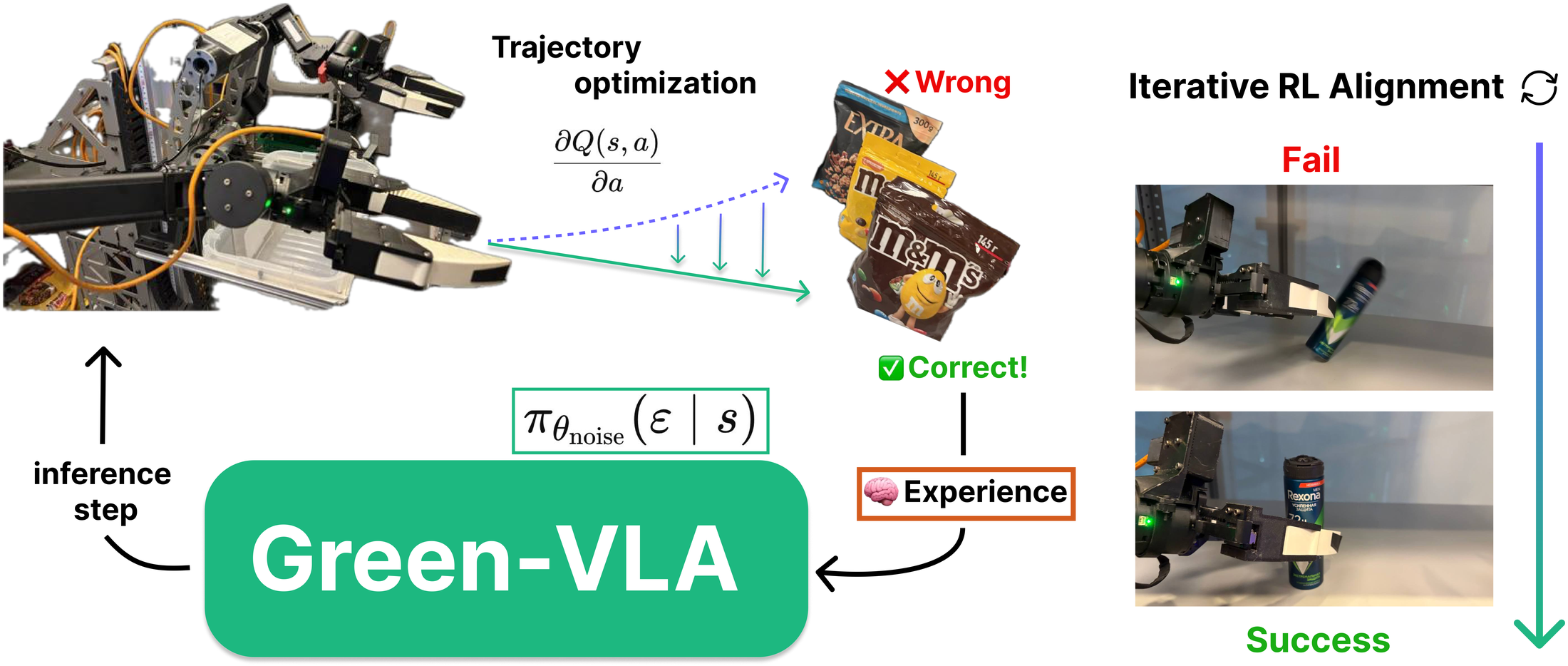
Figure 8 解读:左侧是 source noise distribution optimization:actor 不直接输出动作,而是输出 flow-matching 初始噪声,使 frozen/base policy 生成更高 return 的轨迹。右侧是 PARL-style trajectory optimization:用 Q-gradient 改进 rollout,再把验证通过的轨迹加入训练集。
论文公式与 released code 实现差异:公开仓库没有找到 IQL critic、Q-gradient trajectory optimizer 或 source-noise actor 的实现;仓库发布的是可加载 checkpoint、核心 GreenVLAPolicy、data transforms、inference / fine-tuning pipeline。
3.6 Released code mapping and pseudocode
Code reference:
main@952a80c3(2026-03-05) — pseudocode and mapping based on this commit
| Paper concept | Released code | 说明 |
|---|---|---|
| VLM prefix + action expert | lerobot/common/policies/greenvla_policy/modeling_greenvla_policy.py → GreenVLAPolicyModel | 加载 Qwen3VL / Qwen2.5VL,构造 downsampled Qwen3VLTextModel action expert,复用 VLM prefix KV cache。 |
| Flow-matching training | GreenVLAPolicy.forward_flow_matching, GreenVLAPolicyModel.forward_flow_matching | 采样 noise/time,构造 ,预测 velocity,按 action mask / robotics source mask 做 MSE。 |
| Denoising inference | sample_actions, denoise_step | 从 Gaussian noise 开始,用 num_steps 次 Euler integration 从 到 生成 action chunk。 |
| Prompt/tokenization | greenvla_tokenizer.py → GreenVLATokenizer | 可插入 `< |
| Unified mapping | torch_transforms.py, data_transforms/robots/{bridge,fractal,aloha}.py | 将不同 robot 的 state/action 映射到统一 slot,并产生 pad mask。 |
| Fine-tuning configs | lerobot/conf/finetune_greenvla_bridge.yaml, finetune_greenvla_fractal.yaml | 记录公开 fine-tuning 的 batch size、steps、lr、stride、checkpoint。 |
| JPM / OOD / R2 | 未在 release 中找到完整实现 | 这些模块在论文和项目页描述,当前代码不提供可复现源码。 |
Pseudocode 1 — unified action mapping(对应 torch_transforms.py + robot transforms)
import torch
def map_to_unified_space(x: torch.Tensor,
mapping: list[tuple[list[int], list[int]]],
target_dim: int = 48,
pad_value: float = 0.0):
out = torch.full((*x.shape[:-1], target_dim), pad_value,
dtype=x.dtype, device=x.device)
pad_mask = torch.ones_like(out, dtype=torch.bool)
for src_idx, dst_idx in mapping:
k = min(len(src_idx), len(dst_idx))
if k > 0:
out[..., dst_idx[:k]] = x[..., src_idx[:k]]
pad_mask[..., dst_idx[:k]] = False
return out, pad_mask
BRIDGE_MAPPING = [
(list(range(0, 3)), list(range(35, 38))), # xyz
(list(range(3, 6)), list(range(42, 45))), # rotation
(list(range(6, 7)), list(range(13, 14))), # gripper
]Pseudocode 2 — flow-matching training step(对应 forward_flow_matching)
import torch
import torch.nn.functional as F
def flow_matching_train_step(model, batch):
images, image_masks = model.prepare_images(batch)
lang_tokens = batch["input_ids"]
lang_masks = batch["padded_mask"]
state = batch["state"].float()
actions = batch["actions"].float()
action_mask = batch.get("action_loss_mask")
data_source = batch.get("data_source")
prefix_cache = model.model.encode_vlm_prefix_with_kv_cache(
images, image_masks, lang_tokens, lang_masks, return_cache=True
)
noise = torch.randn_like(actions)
time = torch.rand(actions.shape[0], device=actions.device)
x_t = time[:, None, None] * noise + (1.0 - time[:, None, None]) * actions
target_velocity = noise - actions
suffix_embs, suffix_mask = model.model.embed_suffix(state, x_t, time)
velocity = model.model.action_expert_with_prefix_cache(
suffix_embs=suffix_embs,
suffix_mask=suffix_mask,
prefix_cache=prefix_cache,
lang_masks=lang_masks,
)
velocity = model.model.action_out_proj(velocity[:, -model.config.n_action_steps:])
loss = F.mse_loss(velocity, target_velocity, reduction="none")
if model.config.mask_padded_actions and action_mask is not None:
loss = loss * action_mask.float()[:, None, :]
if data_source is not None:
robotics_only = (data_source == 0).float()[:, None, None]
loss = loss * robotics_only
return loss.sum() / loss.numel()Pseudocode 3 — flow-matching action sampling(对应 sample_actions / denoise_step)
import torch
@torch.no_grad()
def sample_action_chunk(model, batch):
images, image_masks = model.prepare_images(batch)
lang_tokens = batch["input_ids"]
lang_masks = batch["padded_mask"]
state = batch["state"].float()
prefix_cache = model.model.encode_vlm_prefix_with_kv_cache(
images=images,
img_masks=image_masks,
lang_tokens=lang_tokens,
lang_masks=lang_masks,
return_cache=True,
)
x_t = torch.randn(
lang_tokens.shape[0],
model.config.n_action_steps,
model.config.max_action_dim,
device=lang_tokens.device,
)
dt = -1.0 / model.config.num_steps
time = torch.tensor(1.0, device=lang_tokens.device)
while time >= -dt / 2:
v_t = model.model.denoise_step(
state=state,
prefix_pad_masks=lang_masks,
vlm_output_with_cache=prefix_cache,
x_t=x_t,
timestep=time.expand(lang_tokens.shape[0]),
)
x_t = x_t + dt * v_t
time = time + dt
return x_t4. Experimental Setup (实验设置)
数据与规模:L1 使用 24M non-robotics multimodal samples;R0 使用 184M robotics-domain samples,总量超过 3,000 小时。robotics 数据包括 AgiBotWorld twofinger 774h、AgiBot dexhand 82h、ActionNet 143h、Green Humanoid 48h→167h effective、Galaxea 477h、RDT 59/60h、Bridge 105h、DROID 501/512h、Fractal 350/351h、RoboMind 33h、BiPlay 9.7/31h、ALOHA any_pick 11/11.2h。论文中的 DROID / Fractal / RDT / BiPlay 小时数在正文和表 1 有轻微不一致,笔记保留原文/表中数字。
模型与训练:最新版 Green-VLA 是约 5B 参数,主干为 Qwen3-VL-4B-Instruct,叠加 flow-matching action expert 和 lightweight heads;旧版本使用 PaliGemma 3B,总体约 4B。R0 机器人预训练超过 optimization steps,在 64 张 H100 GPU 上进行。公开仓库 README 还发布 2B base、5B base stride-1/stride-4、Bridge R1/R2、Fractal R1、CALVIN R2 checkpoints。
公开 fine-tuning 配置(来自源码,不用 base defaults 代替):lerobot/conf/finetune_greenvla_bridge.yaml 使用 SberRoboticsCenter/GreenVLA-5b-base-stride-1,max_state_dim=max_action_dim=48,tokenizer_max_length=356,n_action_steps=10,image_shape=448×448,proj_width=1280,expert_block_stride=1,attention_implementation=sdpa,action_head_batch_multiplier=4,mask_padded_actions=true,AdamW lr=1e-4、betas=[0.9,0.95]、weight_decay=1e-8、grad_clip_norm=1.0,warmup 1000、stable 34000、decay 15000、steps 50000、batch size 6、num_workers 16。finetune_greenvla_fractal.yaml 基本相同,但从 GreenVLA-5b-base-stride-4 启动,expert_block_stride=4,batch size 8。accelerate_config.yaml 为 1 machine、8 processes、bf16、multi-GPU。
评测任务与 baselines:R0 阶段在 Cobot Magic / ALOHA table-cleaning 与 SimplerEnv Google Robot / WidowX 上评测;R1 在 CALVIN、e-commerce shelf picking、Green humanoid pick/place/handover/sorting 上评测;R2 在 Simpler BRIDGE WidowX、CALVIN ABC→D、e-commerce difficult-object picking 上评测。Baselines 包括 、、GR00T N1 / N1.6、AgiBot GO-1、WALL-OSS、OpenVLA、RT-1X、Flower、X-VLA、Magma、DB-MemVLA、EO-1。

Figure 9 解读:Cobot Magic / ALOHA table-cleaning 评测包含单目标 pick tape、pick pliers,以及全桌清理。每个候选对象 10 次随机位置/distractor;full-task 放 15–20 个物体并顺序下达指令,统计 first-attempt correctness 与平均完成时间。
5. Experimental Results (实验结果)
ALOHA / Cobot Magic R0:Green-VLA(R0) 在未做额外 embodiment tuning 的情况下达到 Tape 83.1、Screwdrivers 52.1、Pliers 63.7、First item SR 69.5、AVG Time 1m35s。对比 为 46.3 / 29.7 / 31.8 / 35.6 / 2m59s,AgiBot GO-1 为 57.8 / 48.6 / 33.2 / 38.4 / 3m57s,GR00T N1 与 WALL-OSS 的 AVG Time 均大于 5m。这说明 R0 multi-embodiment pretraining 对训练集中相近 embodiment 已经能带来强 task-following 和效率。
SimplerEnv Google Robot:按当前 arXiv source 的主表,Qwen3-VL-4B Green-VLA(R1) 在 Google Robot 上达到 Visual Matching AVG 77.0、Variant Aggregation AVG 66.7、Overall 71.8;EO-1 Overall 69.8,X-VLA 63.8,GR00T-N1.6 60.5,Magma 57.4, fine-tune 53.6。PaliGemma 3B Green-VLA R0/R1/R2 分别为 Overall 45.1 / 48.1 / 57.3,说明换 Qwen3 backbone 的收益在 Google Robot 表中非常明显。
SimplerEnv WidowX:Green-VLA(Qwen3, R2) 在 AVG Grasp 94.6、AVG Success 80.5,为表中最高;Qwen3 R1 是 89.6 / 72.9。PaliGemma 3B 从 R0 到 R1 到 R2 的 AVG Success 为 45.0 → 55.2 → 79.1,体现 filtered R1 + R2 RL alignment 的累计收益。对照项中 DB-MemVLA 为 73.2,EO-1 为 72.7,X-VLA 为 65.6。

Figure 11 解读:JPM guidance 在 SKU/OOD 精确目标选择上最明显。无 guidance 时 Green-VLA 为 ID-Coarse 95.4、ID-SKU 36.7、OOD 10.2;加 guidance 后图中为 ID-Coarse 62.3、ID-SKU 93.1、OOD 72.8。它牺牲/改变了 coarse 类别判定表现,但显著提升 exact variant 和 unseen SKU。
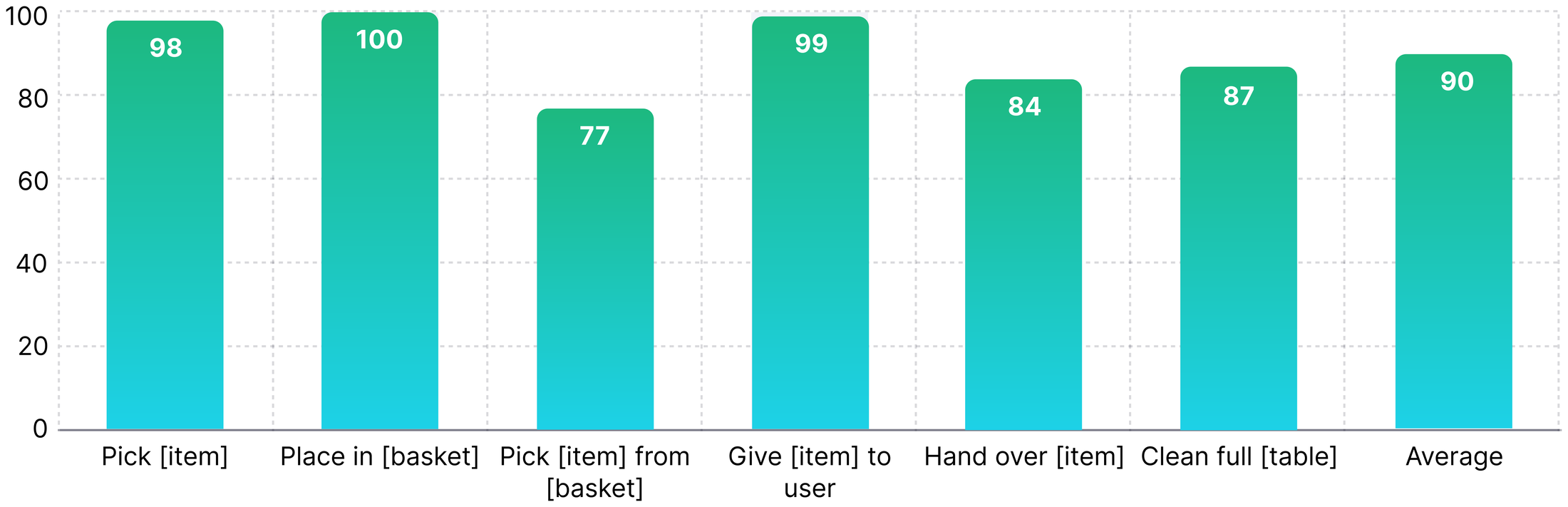
Figure 12 解读:Green humanoid 的各项成功率为 Pick 98、Place 100、Pick from basket 77、Give to user 99、Hand over 84、Clean full table 87,平均 90。该评测覆盖左右手、正确篮子、arm-to-arm handover、递给用户、fruit sorting 和全桌清理,说明模型不只在单臂 benchmark 上有效,也能控制 full upper body。

Figure 13 解读:这是一段 task-planned humanoid sorting:planner 把“sort apples and oranges into the basket”拆成 left/right hand pick、place 等 subtask,Green-VLA 负责每个 subtask 的低层控制。图中体现了论文强调的 high-level decomposition + low-latency VLA control 的分工。
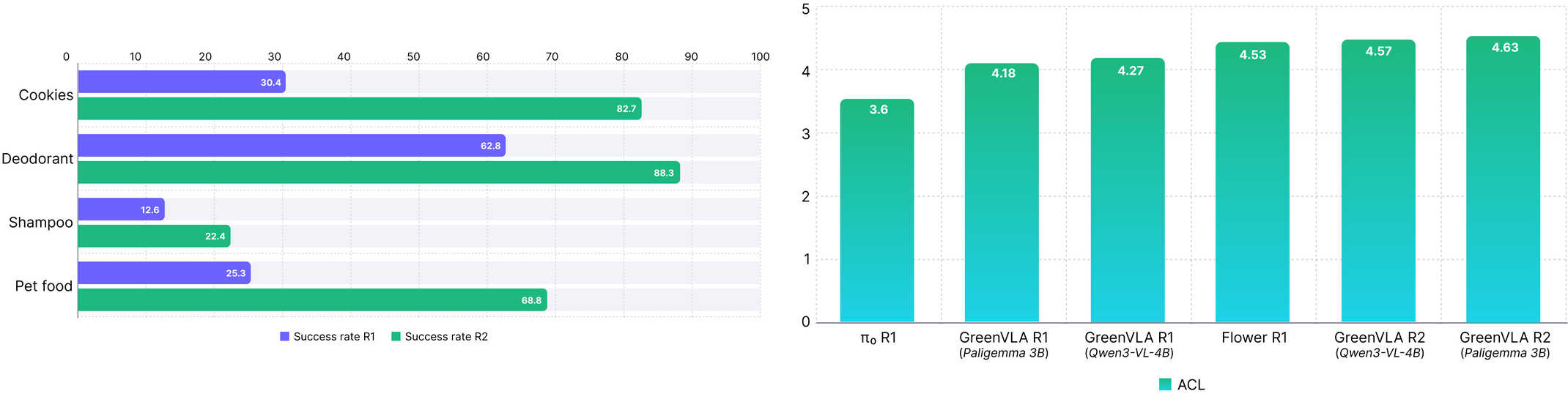
Figure 14 解读:R2 在 e-commerce difficult objects 上并非每类都单调提升:Cookies 从 30.4 到 82.7,Pet food 从 25.3 到 68.8,Shampoo 从 12.6 到 22.4,但 Deodorant 从 62.8 降到 38.3。CALVIN ACL 则从 R1 的 3.6 到 Green-VLA R1(PaliGemma) 4.18、R1(Qwen3) 4.27、Flower R1 4.53、Green-VLA R2(Qwen3) 4.57、Green-VLA R2(PaliGemma) 4.63。
Ablation / main finding:最核心的实验结论是 staging 有叠加收益:DataQA 和 unified action 让 R0 具备跨 embodiment 泛化;R1 把能力落到具体 robot;JPM guidance 专门改善 dense SKU 精确选择;R2 主要改善长程一致性、恢复能力和部分困难物体的物理抓取。限制是:R2 不是所有类别都提升,公开 release 也没有包含 JPM/OOD/R2 的训练代码,因此这几个模块目前只能由论文与 project page 验证,不能由 released code 完整复现。