GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
Paper: arXiv:2602.12099 Code: open-gigaai/giga-brain-0 Code reference:
main@61a91940(2026-03-10) Project: gigabrain05m.github.io
1. Motivation (研究动机)
当前主流 VLA(vision-language-action)模型通常把当前图像、语言指令和机器人状态直接映射到一个 multi-step action chunk。这种反应式控制在短程模仿学习上有效,但在长时程任务中缺少“先看未来再行动”的机制:模型只能依赖当前观测,对遮挡、物体状态变化、失败后纠偏和跨子任务规划的预判不足,因此容易出现 compounding error。
本文要解决的具体问题是:如何把已经具备未来视频预测能力的 world model 接入 VLA policy,使机器人 policy 不只看到当前 observation ,还获得未来状态 latent 与 value 这类 dense look-ahead condition,从而在真实机器人长任务中稳定完成 box packing、laundry folding、espresso preparation 等多阶段操作。
这个问题值得研究的原因在于,纯 imitation / offline fine-tuning 受限于示范数据覆盖;而直接对大 VLA 做 policy gradient 又不稳定、样本效率低。RAMP 的核心价值是把 RL 的“什么轨迹更好”转换成 VLA 可消费的条件输入:world model 负责预测未来和价值,policy 仍以 supervised fine-tuning 风格学习 action generation,降低了大模型 RL 的工程不稳定性。
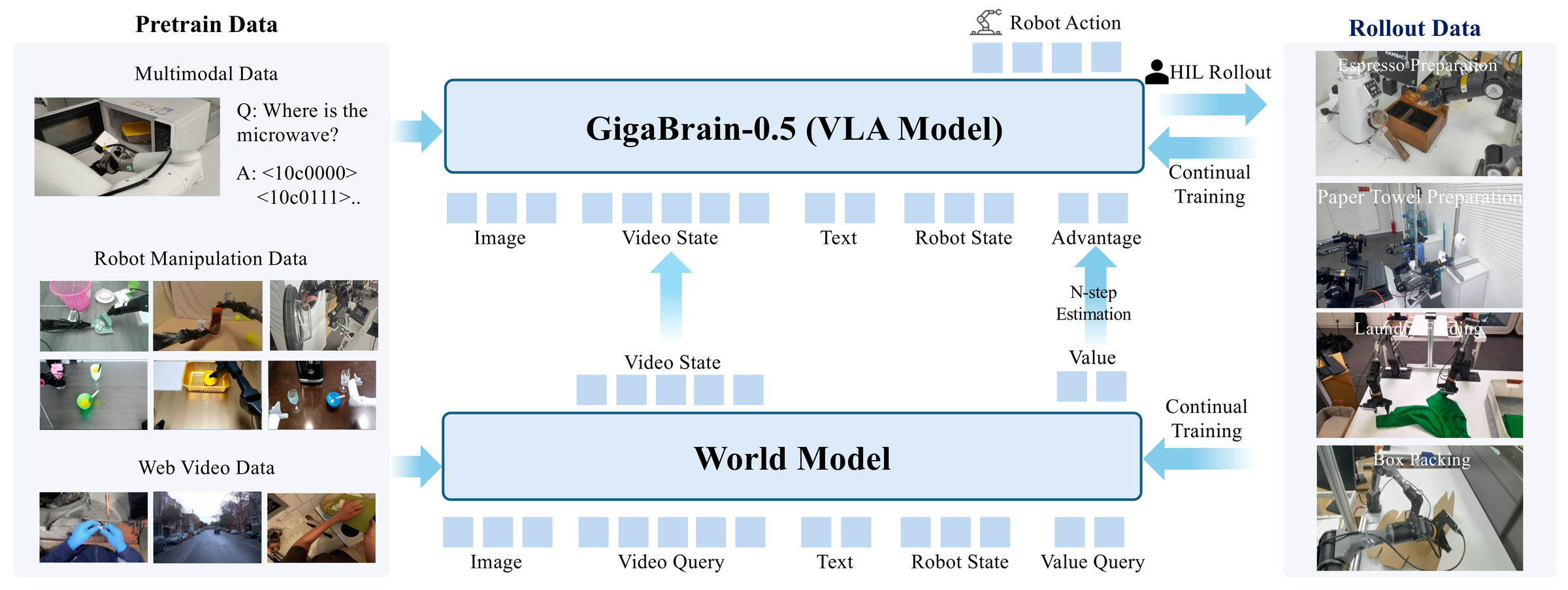
Figure 1 解读:论文把 GigaBrain-0.5M* 定位为 world model-conditioned VLA:基础 policy 来自大规模机器人数据预训练,RAMP 再通过 world model 的 future state/value、HIL rollout 和 continual training 形成闭环自我改进。图中最关键的变化不是增加一个单独 reward head,而是把 future latent 与 value 变成 policy conditioning signal。
2. Idea (核心思想)
核心 insight:RECAP 只把稀疏 advantage / improvement bit 输入 policy,本质上让 policy 在所有可能未来上学习一个“平均动作”;RAMP 则显式条件化在 world model 预测的未来状态 latent 和 value 上,把动作生成从“平均猜测”变成“面向某个预测物理状态的计划”。
关键创新可以概括为三点:第一,用 world model 同时预测未来视觉状态和价值,把 value 作为 latent frame 与视觉 latent 拼接;第二,把 value 通过 -step TD 转成二值 improvement indicator ,并与 future latent 一起作为 VLA 条件;第三,通过 HIL rollout 采集 policy-native 分布中的成功/纠错数据,再持续更新 world model 与 policy。
与 RECAP / advantage-conditioned VLA 的根本区别是信息密度。RECAP 的条件主要是 ,只能提供粗粒度 preference;RAMP 的 携带预测几何结构、物体动态和未来阶段信息,因此降低 ,尤其适合需要多步物理状态演化的任务。
3. Method (方法)
3.1 Overall framework: GigaBrain-0.5 + RAMP
GigaBrain-0.5 继承 GigaBrain-0 的端到端 VLA 架构:PaliGemma-2 VLM 编码多模态输入,action Diffusion Transformer / flow matching 预测连续 action chunk,同时生成 embodied CoT(subgoal language、discrete action tokens、2D manipulation trajectories)。GigaBrain-0.5M* 在此基础上引入 RAMP,把 world model 的 value/future latent 接到 policy 条件空间中。
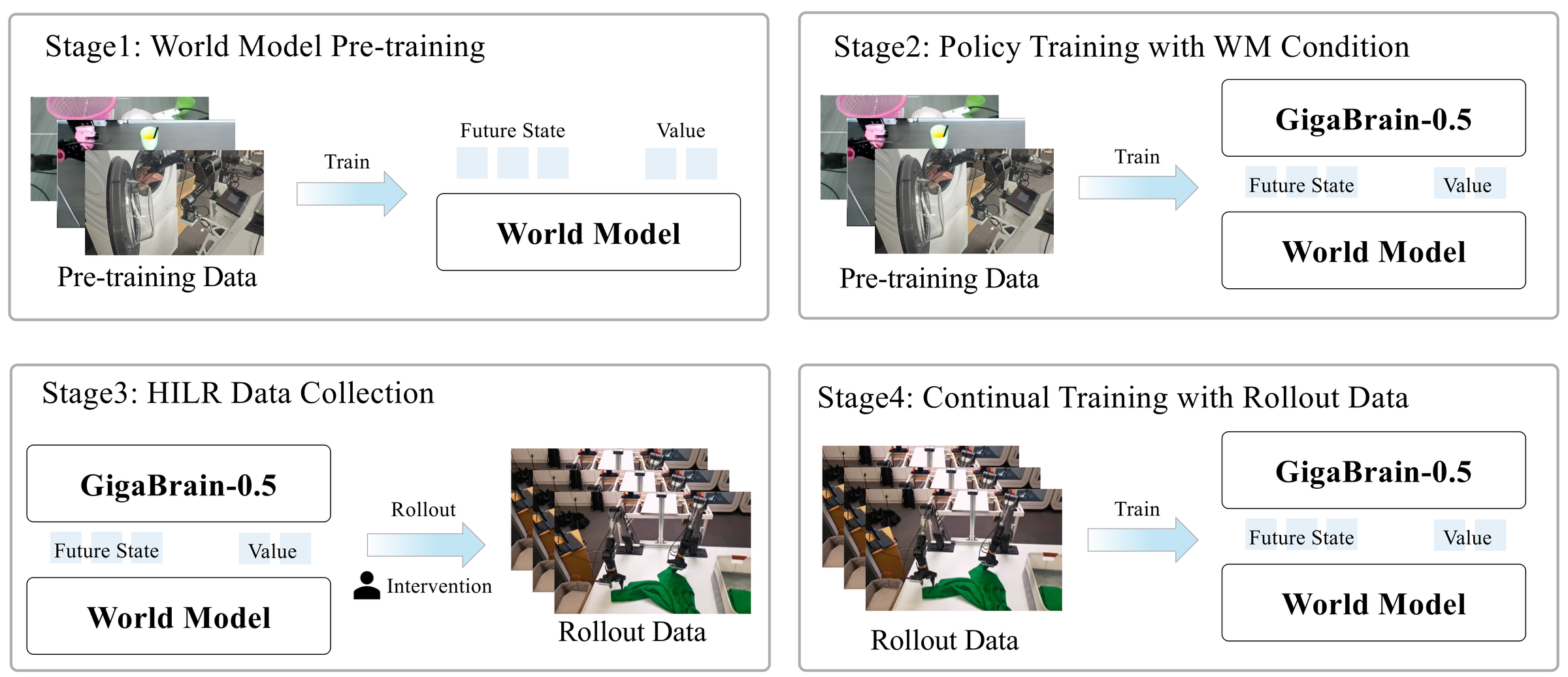
Figure 2 解读:RAMP 有四个 stage:world model pre-training、policy training with world model condition、HIL rollout data collection、continual training。注意 Stage 2 与 Stage 4 都让 policy 看见 world model condition;Stage 4 还联合更新 world model,避免 value/advantage 在 rollout 数据上坍缩到近似零。
为什么它能工作:长时程机器人任务的难点常常不是“下一步怎么动”,而是“下一步动作会不会让后面几步更容易”。World model 把这个未来信息压缩为 与 ;policy 不需要自己从当前图像中隐式推断所有未来分支,只需在显式 future/value condition 下学习 action distribution。随机 mask 又防止 policy 对 world model 过拟合,使它在没有 world model 的高频推理模式下仍可运行。
3.2 GigaBrain-0.5 base objective
基础 VLA 的联合训练目标包含 CoT token cross-entropy、action flow matching / diffusion loss、2D trajectory regression:
其中 是 reasoning stream token mask, 是 noisy action chunk, 是 2D manipulation trajectory keypoints。论文还强调 Knowledge Insulation 用于减少语言和动作 loss 间的优化干扰。
论文公式与 released code 实现差异:论文写作中定义 ,而 released giga_brain_0/giga_brain_0_loss.py 的 add_noise() 使用 x_t = time * noise + (1 - time) * actions,并令 u_t = noise - actions,随后对 model_pred['v_t'] 做 MSE。这可能只是 timestep convention 反向,但笔记不能把二者静默合并。
3.3 RAMP formulation
RAMP 把状态扩展为 ,其中 是 world model latent, 是 language instruction。KL-regularized RL 下的最优 policy 形式为:
为避免直接估计指数 advantage,论文引入 binary improvement indicator ,并用 Bayes 重写 advantage ratio,最终得到 supervised-style objective:
其中 。RECAP 是 RAMP 的退化情形:
这解释了为什么 RECAP 只能学到对未来 latent 边缘化后的 average policy,而 RAMP 可以对具体 future state 做条件化决策。
3.4 World model pre-training and value/future latent construction
Stage 1 训练 world model 同时预测未来视觉状态与 value。奖励来自 episode-level success label:
future observations 经 pretrained VAE 编成 ;value 与 proprioception 通过 spatial tiling projection 广播到同一空间尺寸,然后按 channel 拼接:
世界模型使用 Wan2.2 backbone 并以 flow matching 训练:
论文未详细说明 、、、 的具体取值;明确给出的实现细节包括:world model 用 4K 小时真实机器人操作数据训练,policy 训练时 world model tokens stochastic attention masking probability ,推理时 world model 只做 single denoising step 以降低开销。
3.5 Policy conditioning, HILR, and inference modes
Stage 2 从 GigaBrain-0.5 checkpoint 初始化 policy,并输入两个 world model 辅助信号:future state tokens 与 value estimate 。value 通过 -step TD 转 advantage:
然后二值化为 ,与 一起作为 action generation condition。Stage 3 在真实环境中部署 policy,通过 human-in-the-loop rollout 采集由 policy 自身分布产生的 autonomous trajectory 与 expert correction;论文特别提到其软件会自动检测并移除人工接管边界处的 transitional artifacts。Stage 4 用 HILR dataset 继续 fine-tune policy,并把 HILR/base data 一起用于 world model,避免 advantages collapse。
推理时固定 ,相当于采用 optimistic control。 有两种模式:efficient mode 下 attention mask 让 policy 看不到 future latent,从而绕过 world model 提高频率;standard mode 下 world model 生成 ,policy 可利用 dense look-ahead guidance 做复杂计划。
3.6 Released code applicability and source-based pseudocode
代码搜索找到公开仓库 open-gigaai/giga-brain-0,它在 README 中链接 GigaBrain-0.5M* report,但截至 main@61a91940 未发布 RAMP 专用实现:仓库搜索 RAMP / RECAP / advantage / world_model 只命中 README/news 或无关文本,没有 future latent/value conditioning、HILR 边界清洗、TD advantage 二值化、Wan2.2 world model training 的源码。因此下列伪代码分两类:前三段严格对应 released GigaBrain-0 源码;RAMP 段是论文方法的 PyTorch-style sketch,不应被当作已开源实现。
Code reference:
main@61a91940(2026-03-10) — pseudocode and mapping based on this commit; RAMP-specific modules are not present in the released repo.
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Data transform: robot embodiment, delta action, state/action normalization, image/token transforms | giga_brain_0/giga_brain_0_transforms.py | GigaBrain0Transform.__call__ |
| Base VLA training loop: add noise to action chunk, forward policy, compute losses | giga_brain_0/giga_brain_0_trainer.py | GigaBrain0Trainer.forward_step |
| Flow/action diffusion loss + optional language/trajectory losses | giga_brain_0/giga_brain_0_loss.py | GigaBrain0Loss.add_noise, GigaBrain0Loss.forward |
| Public training configs, not paper RAMP configs | configs/giga_brain_0_from_scratch.py, configs/giga_brain_0_agilex_finetune.py, configs/giga_brain_0_agibot_finetune.py | config dict |
| Inference server/pipeline wrapper | scripts/inference.py, scripts/inference_server.py | GigaBrain0Pipeline, get_policy, inference_giga_brain_0 |
| RAMP world model/value/HILR implementation | Not released in this repo | 代码搜索未找到对应源码 |
def transform_batch_from_released_code(data, transform):
robot_type = data["meta"].info["robot_type"]
embodiment_id = int(transform.robot_type_mapping[robot_type])
data["embodiment_id"] = embodiment_id
if transform.use_delta_joint_actions:
data = transform.delta_action_transform(data)
data["observation.state"] = transform.state_normalize_transform(
data["observation.state"], embodiment_id=embodiment_id
)
data["action"] = transform.action_normalize_transform(
data["action"], embodiment_id=embodiment_id
)
lang_tokens, lang_masks, lang_att_masks, lang_loss_masks, fast_indicator, predict_subtask = \
transform.prompt_tokenizer_transform(data)
data = transform.pad_transform(data)
images, image_masks, image_params = transform.image_transform(data)
action_loss_mask = ~data["action_is_pad"]
if predict_subtask:
action_loss_mask = torch.zeros_like(action_loss_mask)
batch = {
"images": images,
"image_masks": image_masks,
"lang_tokens": lang_tokens,
"lang_masks": lang_masks,
"lang_att_masks": lang_att_masks,
"lang_loss_masks": lang_loss_masks,
"fast_action_indicator": fast_indicator,
"observation.state": data["observation.state"],
"action": data["action"],
"action_loss_mask": action_loss_mask,
"embodiment_id": torch.tensor(embodiment_id, dtype=torch.long),
}
return batchdef released_gigabrain0_train_step(policy, batch, loss_fn):
actions = batch["action"]
noise = torch.randn_like(actions)
time = sample_beta(alpha=1.5, beta=1.0, bsize=actions.shape[0], device=actions.device)
time = time * 0.999 + 0.001
x_t = time[:, None, None] * noise + (1.0 - time[:, None, None]) * actions
u_t = noise - actions
pred = policy(
batch["images"],
batch["image_masks"],
batch["lang_tokens"],
batch["lang_masks"],
x_t,
time,
batch["embodiment_id"],
lang_att_masks=batch["lang_att_masks"],
fast_action_indicator=batch["fast_action_indicator"],
)
diffusion_loss = F.mse_loss(pred["v_t"], u_t, reduction="none")
diffusion_loss = diffusion_loss.mean(dim=-1) * batch["action_loss_mask"]
losses = {"diffusion_loss": diffusion_loss.mean(dim=-1)}
if "lang_logits" in pred:
losses["llm_loss"] = masked_next_token_cross_entropy(
pred["lang_logits"], batch["lang_tokens"], batch["lang_loss_masks"]
)
if "traj_pred" in pred and "traj" in batch:
losses["traj_loss"] = masked_mse(pred["traj_pred"], batch["traj"], batch["traj_loss_mask"])
return losses@torch.no_grad()
def released_inference_wrapper(pipe, data, autoregressive_mode_only=False):
images = {
"observation.images.cam_high": data["observation.images.cam_high"],
"observation.images.cam_left_wrist": data["observation.images.cam_left_wrist"],
"observation.images.cam_right_wrist": data["observation.images.cam_right_wrist"],
}
if pipe.enable_depth_img:
for cam in ["cam_high", "cam_left_wrist", "cam_right_wrist"]:
key = f"observation.depth_images.{cam}"
if key in data:
images[key] = data[key]
return pipe(images, data["task"], data["observation.state"],
autoregressive_mode_only=autoregressive_mode_only)def ramp_training_step_paper_sketch(policy, world_model, batch, gamma=0.99, eps=0.0, mask_prob=0.2):
# Paper-derived sketch only: RAMP-specific released code was not found.
with torch.no_grad():
future_latents, values = world_model.predict_future_and_value(
obs=batch["images"], proprio=batch["observation.state"], actions=batch["action"]
)
rewards = sparse_episode_success_reward(batch["episode_success"], batch["t"], batch["T"])
advantages = n_step_td_advantage(rewards, values, gamma=gamma)
improve = (advantages > eps).long()
keep = (torch.rand(batch_size(batch), device=advantages.device) > mask_prob)
wm_tokens = project_future_latents(future_latents)
wm_tokens = torch.where(keep[:, None, None], wm_tokens, torch.zeros_like(wm_tokens))
improve = torch.where(keep, improve, torch.ones_like(improve))
logits_or_actions = policy(
images=batch["images"],
task_tokens=batch["lang_tokens"],
state=batch["observation.state"],
world_model_tokens=wm_tokens,
improvement_indicator=improve,
)
return supervised_action_nll_or_diffusion_loss(logits_or_actions, batch["action"])4. Experimental Setup (实验设置)
4.1 Data and training
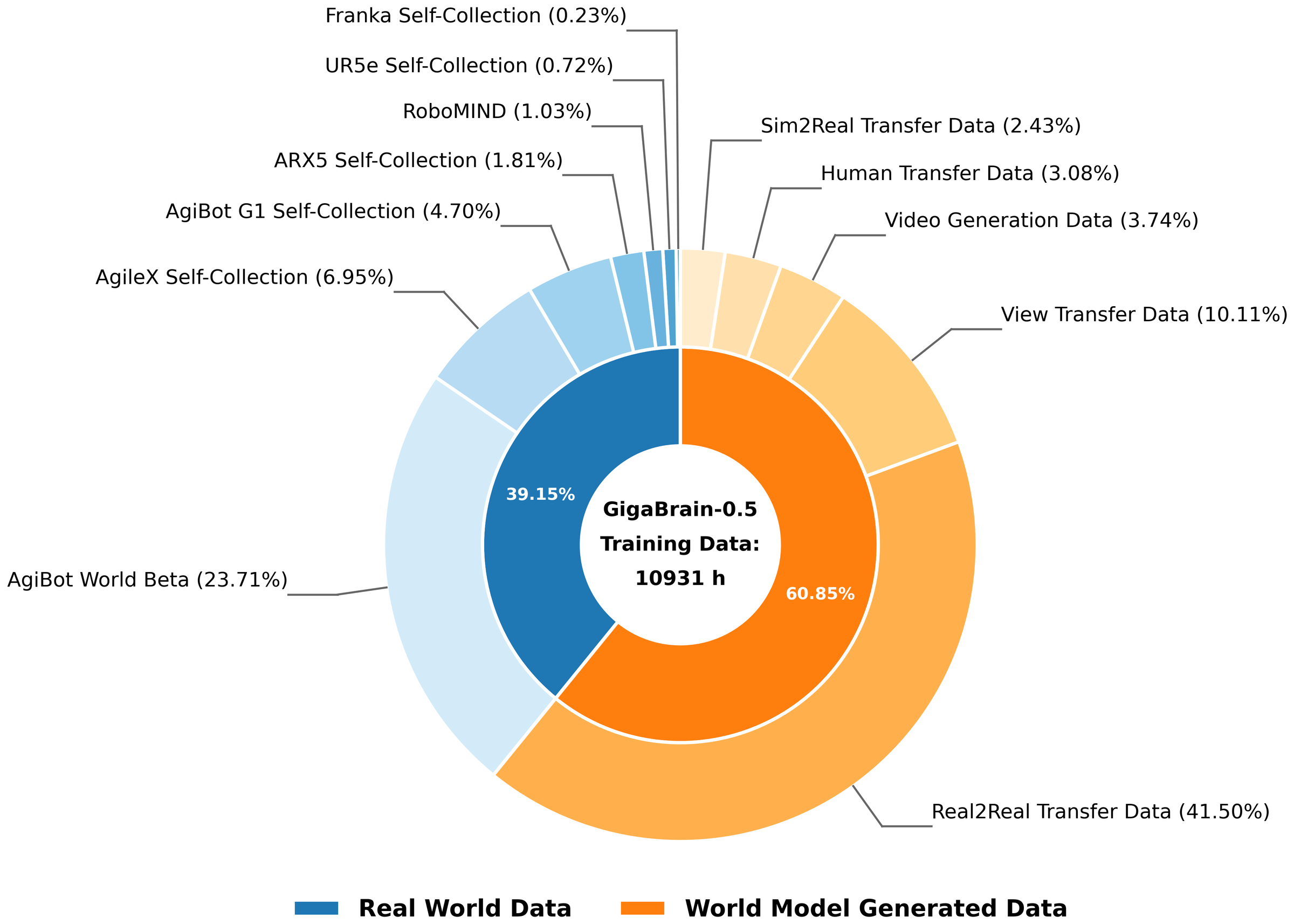
Figure 3 解读:GigaBrain-0.5 的预训练数据超过 10,000 小时;论文文字给出近似组成:超过 6,000 小时 world-model generated data,加上约 4,000 小时 real-robot collected data。项目页进一步给出 10,931 小时总量、其中 6,653 小时 synthetic / 4,278 小时 real,但论文正文使用的是“over 10,000 / over 6,000 / approximately 4,000”的表述。
GigaBrain-0.5 pre-training 使用 GigaTrain,batch size 3,072,100,000 optimization steps;为降低显存,使用 FSDP v2,并选择性 shard 所有 SiglipEncoderLayer 与前 16 层 Gemma2DecoderLayerWithExpert。Post-training 在目标机器人平台收集 task-specific demonstrations,覆盖 8 个 internal tasks:Juice Preparation、Box Moving、Table Bussing、Paper Towel Preparation、Laundry Folding、Laundry Collection、Box Packing、Espresso Preparation;每个任务 batch size 256,20,000 optimization steps。
RoboChallenge 评估覆盖 30 个标准化 manipulation tasks,平台含 20 台真实机器人、4 类平台(UR5、Franka、ARX5、ALOHA),公开数据集 736 GB。RAMP 的 value prediction validation set 约 1 million frames,来自 Fig. 4 所示 8 个 manipulation tasks;latency 在 A800 GPU 上报告。World-model-conditioning ablation 中,single-task policy 各训 20,000 steps / batch 256;multi-task policy 均匀混合四个任务数据,训练 60,000 steps / batch 256,且只使用 RAMP Stage-2 dataset,不加入 generated rollout data。
released code 配置不等同于论文 RAMP 训练配置:configs/giga_brain_0_from_scratch.py 中公开示例是 8 GPU、per-GPU batch 32、AdamW lr 2.5e-5、warmup 1000、decay 200000、max_steps 250000;configs/giga_brain_0_agilex_finetune.py / configs/giga_brain_0_agibot_finetune.py 是 max_steps 50000 的 finetune 示例。笔记中的论文实验数值以上述正文/图表为准,不把公开 repo 默认配置误当成 GigaBrain-0.5M* RAMP 真实配置。
4.2 Baselines and metrics
基础模型评估 baseline 包括 、、GigaBrain-0 与 GigaBrain-0.5。RAMP baseline 包括:GigaBrain-0.5 pretrain、GigaBrain-0.5 + AWR、GigaBrain-0.5 + RECAP、GigaBrain-0.5 + RAMP(即 GigaBrain-0.5M*)。
Value prediction metrics:MAE、MSE、RMSE 越低越好,Kendall’s tau 越高越好;另报告 inference time。Policy metrics 主要是真实机器人 success rate;RoboChallenge 使用平均 success rate。
5. Experimental Results (实验结果)
5.1 Foundation model performance
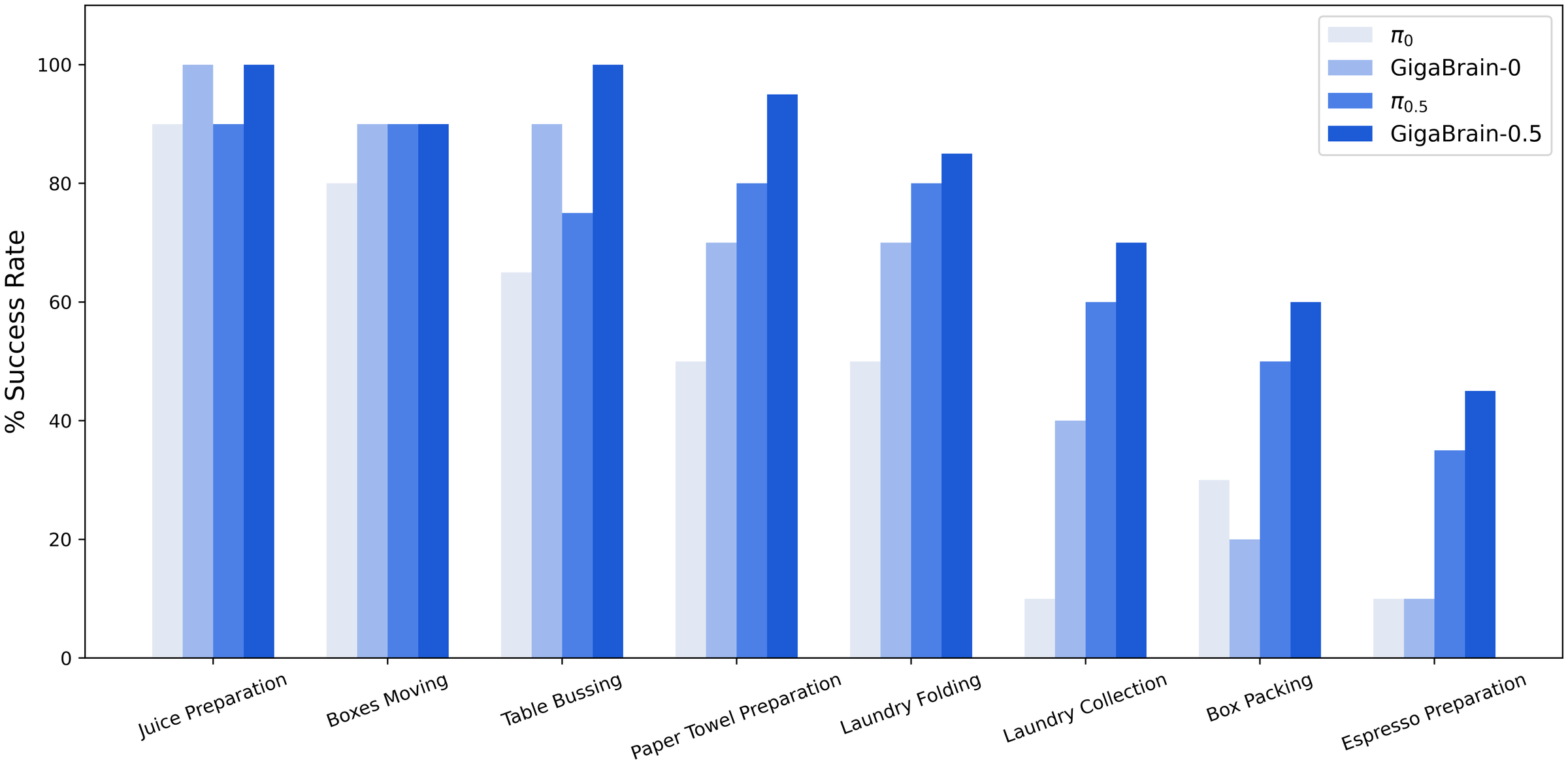
Figure 4 解读:GigaBrain-0.5 在 8 个 internal real-robot tasks 中均为最高或并列最高。论文正文给出几个关键精确结论:Juice Preparation 达到 100%,超过 GigaBrain-0 的 90%;Box Packing 和 Espresso Preparation 相比 分别提升 10% 和 20%;Paper Towel Preparation、Laundry Folding、Laundry Collection 均超过 80%,分别比 高 15%、5%、10%。
RoboChallenge 上,GigaBrain-0.1 作为 intermediate model 在 2026-02-09 leaderboard 排名第一,平均 success rate 为 51.67%,比 的 42.67% 高 9 个百分点。需要注意:这个公开榜单数字是 GigaBrain-0.1 / foundation model 侧结果,不是 GigaBrain-0.5M* RAMP 的最终三任务结果。

Figure 5 解读:Box Packing 是 PiPER 双臂真实部署示例,强调多物体整理、放置顺序和空间约束。它也是 RAMP 相比 RECAP 提升最明显的任务之一。

Figure 6 解读:Box Moving 展示 G1 humanoid robot 的移动/搬运任务,考察跨 embodiment 与长时程状态保持。

Figure 7 解读:Espresso Preparation 是多步骤流程任务,要求模型按正确阶段执行取杯、操作机器、放置等动作;论文报告 RAMP 在该任务上比 RECAP 高约 30 个百分点。

Figure 8 解读:Juice Preparation 展示 G1 humanoid robot 的顺序操作能力;基础 GigaBrain-0.5 在该任务达到 100% success rate。

Figure 9 解读:Laundry Collection 侧重 deformable object 的抓取和收集,要求模型处理布料形变与遮挡。

Figure 10 解读:Laundry Folding 是 RAMP 的核心长时程任务之一;world model value visualization 也用该任务说明 value 会在绿色衣物干扰折叠时下降,并在移除障碍后恢复。

Figure 11 解读:Paper Towel Preparation 属于精细操作与流程结合任务;论文指出 GigaBrain-0.5 比 高 15%。

Figure 12 解读:Table Bussing 展示 G1 humanoid robot 清理桌面的真实部署,和 Box/Paper/Laundry 任务一起用于 world-model-conditioning ablation。
5.2 Value prediction and world-model conditioning
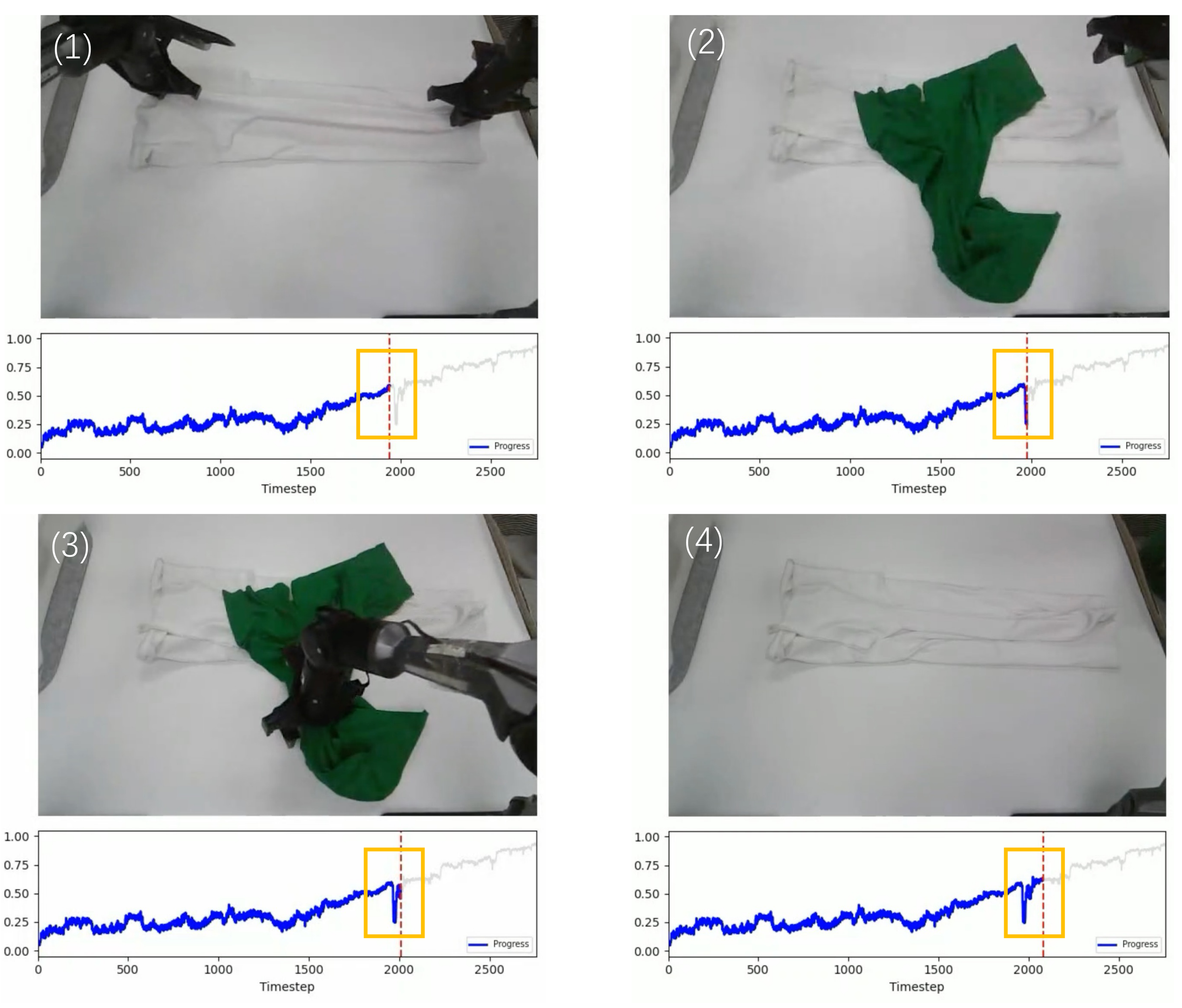
Figure 13 解读:world model 的 value 曲线能捕捉任务中间失败风险。橙色框处绿色衣物干扰 Laundry Folding,value drop;机械臂移除干扰后 value 恢复。这说明 value 不是静态成功分类,而是对未来完成难度的时序估计。
| Value Predictor | Inference Time (s) | MAE ↓ | MSE ↓ | RMSE ↓ | Kendall ↑ |
|---|---|---|---|---|---|
| VLM-based | 0.32 | 0.0683 | 0.0106 | 0.1029 | 0.7972 |
| WM-based (value only) | 0.11 | 0.0838 | 0.0236 | 0.1433 | 0.7288 |
| WM-based (state+value) | 0.25 | 0.0621 | 0.0099 | 0.0989 | 0.8018 |
结论:value-only world model 虽然最快(0.11 s),但 MAE/Kendall 都差;state+value joint prediction 在 0.25 s 下取得最低 MAE 0.0621 和最高 Kendall 0.8018,说明 future state prediction 对 value grounding 很重要。
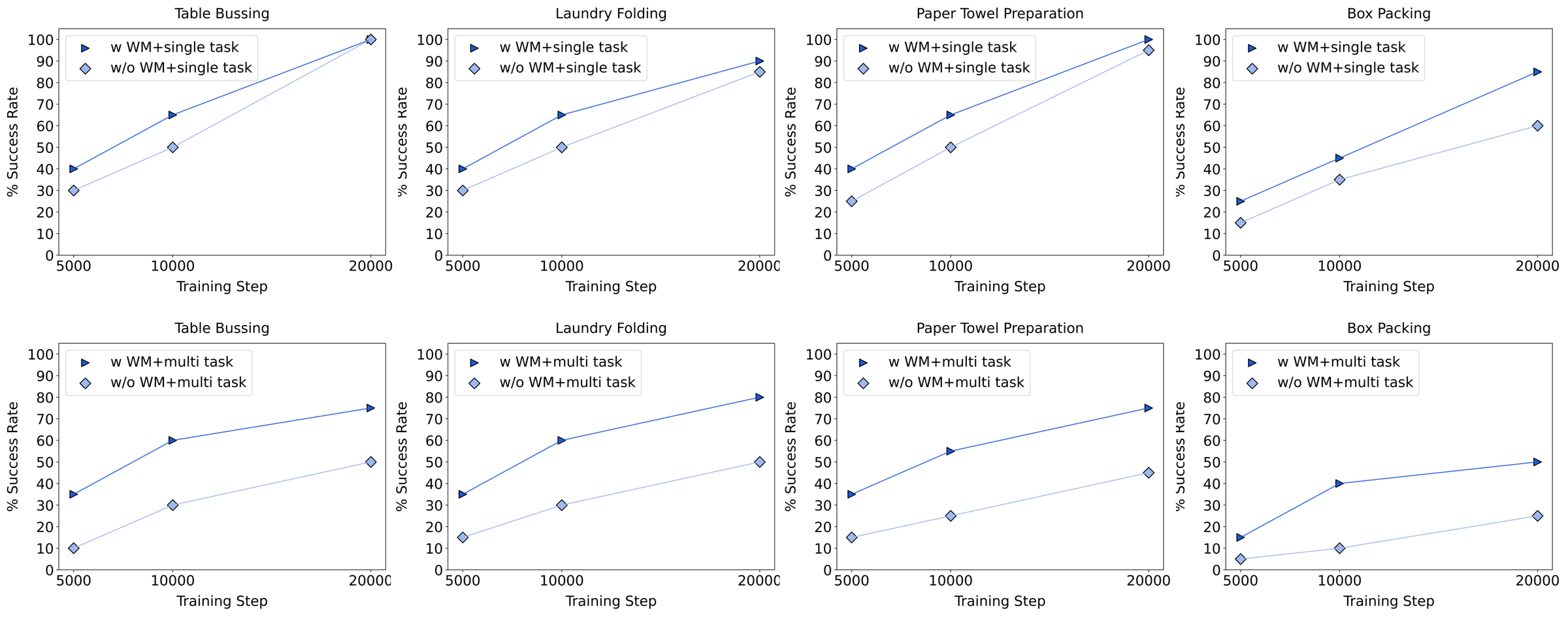
Figure 14 解读:在 single-task 和 multi-task 训练中,world model condition 曲线整体优于无 world model condition。论文强调该实验只用 Stage-2 dataset,不加入 generated rollout data,因此收益主要来自 future/value conditioning 本身;在 multi-task setting 中,Box Packing 在 20,000 step 处的差距达到约 30%。
5.3 RAMP vs RL baselines
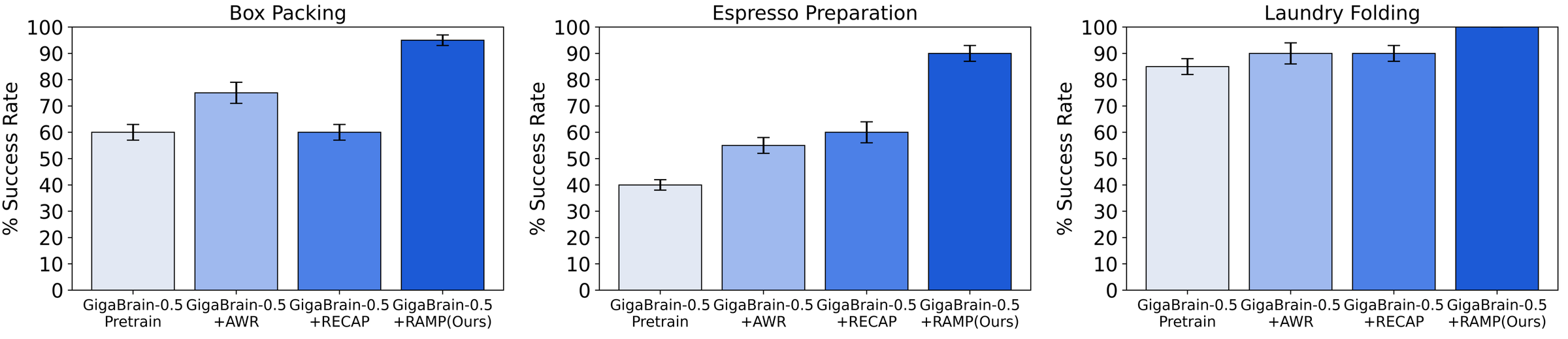
Figure 15 解读:RAMP 在三项困难任务上均达到最高 success rate。图中柱状值为:Box Packing:GigaBrain-0.5 pretrain 60%、+AWR 75%、+RECAP 60%、+RAMP 100%;Espresso Preparation:40%、55%、60%、90%;Laundry Folding:85%、90%、90%、100%。因此 RAMP 不只是比 pretrain 强,也明显超过 advantage-only 的 RECAP,尤其 Box Packing 和 Espresso Preparation 分别高约 40 和 30 个百分点。
综合来看,本文最有价值的实验证据有三层:基础 GigaBrain-0.5 在 internal/RoboChallenge 证明了 foundation policy 强度;value table 证明 state+value world model 是更好的 conditioning source;RAMP 三任务结果证明把 future latent + value/improvement 输入 policy 能显著改善真实长时程任务。
作者在 conclusion/future work 中承认仍需研究更高效利用 model rollout data、降低 synthetic trajectory 信息成本,以及更可扩展的 self-evolution / autonomous data curation / closed-loop policy refinement。对读者而言,当前最大限制是 RAMP 专用训练代码、HILR 数据清洗软件、world model checkpoint 与若干关键超参未公开,导致方法可复现性主要依赖论文描述而非 released implementation。