A Pragmatic VLA Foundation Model
Paper: arXiv:2601.18692 Code: Robbyant/lingbot-vla Code reference:
main@46690e3a(2026-05-12)
1. Motivation (研究动机)
VLA 在真实机器人 manipulation 上的核心难点有两类:一是能力层面,模型要能跨任务、跨平台泛化,而不是只在某个数据量充足的机器人上工作;二是工程层面,大规模真实机器人数据昂贵,训练吞吐低会直接限制 scaling study 和实际迭代速度。论文指出,社区缺少对“真实机器人数据规模增大时 VLA 是否持续变好”的系统实证,也缺少能高效训练这些模型的 open codebase。
本文要解决的具体问题是:在 9 种主流双臂机器人配置、约 20,000 小时真实数据上训练一个可实用 post-training 的 VLA foundation model,并用 GM-100/RoboTwin 等严格协议评估其跨平台表现、data scaling、data efficiency 和 training throughput。作者把 LingBot-VLA 定位为 pragmatic:不仅要 benchmark 分数高,还要 post-training 成本低、代码高效、权重/数据/benchmark 可用。
这个问题值得研究,因为真实机器人部署经常受制于 post-training data budget。若一个 base VLA 在 130 条/任务甚至 80 条/任务的少量数据下就能比强 baseline 更好,那么它能显著降低新机器人/新任务落地成本。

Figure 1 解读:总览图展示了 LingBot-VLA 的完整闭环:真实双臂机器人数据采集、automatic annotation + human refinement、Unified Action Space、可选 depth query、Understanding Expert 与 Action Expert,以及跨 Agibot G1 / AgileX / Galaxea R1Pro 的 real-world deployment。该图的重点是“pragmatic”:模型、数据、训练系统、benchmark 同时设计,而不是只提出新 architecture。
2. Idea (核心思想)
核心 insight:真实 VLA scaling 不能只看模型结构,还要把 data scale、post-training protocol、robot platform consistency 和 training throughput 作为同一个系统优化。LingBot-VLA 的贡献是用 20,000 小时真实双臂数据训练 Qwen2.5-VL based MoT policy,再用统一评测协议证明数据规模和 depth distillation 都能稳定提升下游性能。
关键创新可以概括为:大规模真实双臂数据 + conditional flow matching action expert + depth token distillation + 高吞吐 FSDP2/FlexAttention 训练栈。depth 不是直接把深度图作为输入通道,而是用 learnable queries 与 LingBot-Depth token 对齐,把空间几何信息蒸馏进 VLM representation。
与 、GR00T N1.6、WALL-OSS 相比,LingBot-VLA 的主要差别不是单一模块更复杂,而是评测和训练协议更接近真实应用:所有模型都用同样 130 filtered trajectories per task、batch size 256、20 epochs 进行 post-training,并在同一 robot-task pair 上随机顺序评测。
3. Method (方法)
3.1 Overall framework
LingBot-VLA 基于 Qwen2.5-VL 的视觉语言表示,加入 action expert,以 Mixture-of-Transformers 风格让 VLM 与 action module 在 shared self-attention 中交互。每个时间步 的输入由三视角图像、语言任务、机器人状态组成,输出为未来 action chunk。模型有 depth-free 与 depth-distilled 两个版本;后者额外使用 LingBot-Depth 的 token 作为空间教师信号。

Figure 2 解读:该图展示预训练数据的机器人平台、视角与任务分布。LingBot-VLA 的数据不是 simulation,而是约 20,000 小时真实 dual-arm manipulation,来自 9 种机器人配置。对论文结论最关键的是这些数据覆盖 Agibot G1、AgileX、Galaxea R1Pro 等后续评测平台,因此模型能同时测试 cross-task 与 cross-platform generalization。

Figure 3 解读:数据标注流程先由人类把多视角视频切成 atomic action clips,去掉冗余静止片段,再用 Qwen3-VL-235B-A22B 生成 task/sub-task instructions,最后由人工 refinement 校验。这个流程让大规模真实数据获得可用于 VLA post-training 的语言监督。
3.2 Joint sequence and flow matching objective
论文把 observation context 写为:
其中三路 是 dual-arm robot 的 operational images, 是 task instruction, 是 robot state。对应 action chunk 为:
预训练阶段 。对 flow timestep 、噪声 ,论文定义:
Action expert 的 Flow Matching loss 为:
Blockwise causal attention 把 joint sequence 划分为 image/text block、state block 和 action block。同一 block 内双向 attention,不同 block 只能看当前与之前 block,从而允许 action expert 利用 observation knowledge,同时防止 future action token 泄漏到当前 observation representation。
3.3 Depth distillation
Depth 版本使用 learnable queries 对应三视角图像,并与 LingBot-Depth 的 depth tokens 对齐。蒸馏目标为:
其中 使用 cross-attention 做维度对齐。这个设计的直觉是:机器人 manipulation 的失败常来自空间关系不准,例如抓取深度、遮挡、左右手相对位置;depth teacher 提供 geometry prior,但部署时仍由 VLA 的 learned query representation 使用这些信息。
3.4 Efficient training stack
论文强调 codebase 吞吐:8-GPU setup 达到 261 samples/s,相比已有 VLA codebase 有 1.5–2.8× speedup。released config 使用 FSDP2、module FSDP、Torch Compile,并在 Qwen2.5-VL-3B- 与 PaliGemma-3B-pt-224- 两类模型上比较 8/16/32/128/256 GPUs 的 scaling。

Figure 4a 解读:该图展示 Qwen2.5-VL-3B- setting 下不同 GPU 数的 training throughput。曲线接近 theoretical linear scaling,说明作者的系统贡献不是附属项,而是支撑 20,000 小时真实数据 scaling 的必要条件。
3.5 Pseudocode (based on released code)
论文公式与 released code 实现差异:论文公式使用 、target ;released code modeling_lingbot_vla.py 使用 x_t = time * noise + (1 - time) * actions、u_t = noise - actions,推理时 dt=-1/num_steps 从 time=1 的 noise 积分到 action。两者是时间方向相反的等价约定,但符号看起来相反,笔记中不能静默对齐。
import torch
def lingbot_flow_matching_loss(model, images, img_masks, state, lang_tokens, lang_masks, actions):
"""Mirrors QwenvlWithExpertModel.forward in released LingBot-VLA code."""
noise = torch.randn_like(actions)
time = model.sample_time(actions.size(0), actions.device).to(actions.dtype)
time_expanded = time[:, None, None]
# Code convention: time=1 is noise, time=0 is data.
x_t = time_expanded * noise + (1.0 - time_expanded) * actions
u_t = noise - actions
prefix_embs, prefix_pad_masks, prefix_att_masks = model.embed_prefix(
images, img_masks, lang_tokens, lang_masks, vlm_causal=False, label=None
)
time_embs, suffix_embs, suffix_pad_masks, suffix_att_masks = model.embed_suffix(state, x_t, time)
outputs, suffix_out = model.qwenvl_with_expert.forward(
inputs_embeds=[prefix_embs, suffix_embs],
attention_mask=model.make_blockwise_mask(prefix_pad_masks, suffix_pad_masks),
position_ids=model.make_position_ids(prefix_pad_masks, suffix_pad_masks),
ada_cond=time_embs if model.config.adanorm_time else None,
)
pred = model.action_out_proj(suffix_out[:, -model.config.n_action_steps:])
return ((pred - u_t) ** 2).mean()import torch
def lingbot_depth_distill_loss(model, outputs_embeds, depth_targets, img_masks):
"""Reflects depth_emb_forward + align_params['depth_loss_weight']."""
depth_loss, depth_preds = model.depth_emb_forward(outputs_embeds, depth_targets, img_masks)
return depth_loss * model.config.align_params["depth_loss_weight"], depth_predsimport torch
@torch.no_grad()
def lingbot_euler_inference(model, images, img_masks, lang_tokens, lang_masks, state, num_steps=None):
"""Mirrors get_action: cache prefix once, integrate suffix velocity backward in time."""
bsize = state.shape[0]
num_steps = num_steps or model.config.num_steps
x_t = torch.randn(bsize, model.config.n_action_steps, model.config.max_action_dim, device=state.device)
prefix_embs, prefix_pad_masks, prefix_att_masks = model.embed_prefix(images, img_masks, lang_tokens, lang_masks, False)
_, kv_cache = model.qwenvl_with_expert.forward(
inputs_embeds=[prefix_embs, None],
attention_mask=model.make_att_2d_masks(prefix_pad_masks, prefix_att_masks),
fill_kv_cache=True,
use_cache=True,
)
dt = torch.tensor(-1.0 / num_steps, device=state.device, dtype=state.dtype)
time = torch.tensor(1.0, device=state.device, dtype=state.dtype)
while time >= -dt / 2:
v_t = model.predict_velocity(state, prefix_pad_masks, kv_cache, x_t, time.expand(bsize))
x_t = x_t + dt * v_t
time = time + dt
return x_tCode reference:
main@46690e3a(2026-05-12) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Qwen2.5-VL + action expert MoT | lingbotvla/models/vla/pi0/modeling_lingbot_vla.py | QwenvlWithExpertModel, QwenvlWithExpertConfig |
| Flow Matching action loss | lingbotvla/models/vla/pi0/modeling_lingbot_vla.py | forward, predict_velocity, get_action |
| Depth distillation | lingbotvla/models/vla/pi0/modeling_lingbot_vla.py, tasks/vla/train_lingbotvla.py | depth_emb_forward, build_depth_model, align_params |
| Post-training configs | configs/vla/real_load20000h.yaml, configs/vla/real_load20000h_depth.yaml | lr=5e-5, max_steps=40000, depth_loss_weight=0.004 |
| RoboTwin configs | configs/vla/robotwin_load20000h.yaml, configs/vla/robotwin_load20000h_depth.yaml | loss_type=L1_fm, lr=1e-4, max_steps=20000 |
| Data loading | lingbotvla/data/vla_data/base_dataset.py | LeRobotDataset, VLADataset |
| Launch wrapper | train.sh | torchrun, GPU count from nvidia-smi / CUDA_VISIBLE_DEVICES |
4. Experimental Setup (实验设置)
Datasets
- Pre-training data:约 20,000 hours real-world dual-arm manipulation data,来自 9 popular dual-arm robot configurations。
- GM-100 real-world benchmark:3 robotic platforms(Agibot G1、AgileX、Galaxea R1Pro),每个平台 100 tasks;post-training 使用每 task 130 filtered trajectories;evaluation 每 model 在同一 hardware-task pair 上随机顺序测试,每 task-robot pair 15 trials,时间限制 3 minutes。
- RoboTwin 2.0 simulation:50 representative manipulation tasks;clean scenes 用 2,500 demonstrations(50/task),randomized scenes 用 25,000 demonstrations(500/task),包含背景、桌面杂物、桌高、光照变化。
Baselines
Real-world GM-100 对比 WALL-OSS、GR00T N1.6、、LingBot-VLA w/o depth、LingBot-VLA w/ depth。Simulation RoboTwin 2.0 对比 与 LingBot-VLA 两个版本。
Metrics
- Success Rate (SR):3 分钟内完成全部 task steps 的 trial 比例。
- Progress Score (PS):按 sequential subtask checkpoints 计算部分完成度;例如 6-step task 完成 4 步得 。
- Training throughput:samples/s,用于比较 codebase scaling efficiency。
Training config
论文评测协议:所有 real-world baselines 都从公开 pretrained checkpoints 出发,使用相同 post-training pipeline;GM-100 使用 130 filtered trajectories per task,batch size 256,epochs 20。
Released config anchor:
LingBot-VLA real robot post-training
- Config path:
configs/vla/real_load20000h.yaml - Model:
robbyant/lingbot-vla-4b,tokenizerQwen/Qwen2.5-VL-3B-Instruct - Data:3 cameras(
camera_top,camera_wrist_left,camera_wrist_right),joints:arm.position:14,effector.position:2,norm_type=meanstd - Optimization:FSDP2,
use_compile=true,lr=5.0e-5,constant LR,micro_batch_size=32,gradient_accumulation_steps=1,8 GPUs 时 global batch size 256,max_steps=40000,save_steps=10000 - Action/state:
max_action_dim=75,max_state_dim=75,tokenizer_max_length=72,action expertenable_fp32=true
LingBot-VLA depth version
- Config path:
configs/vla/real_load20000h_depth.yaml - Depth teacher:
moge_path=morgbd/moge2-vitb-normal.pt,morgbd_path=lingbot_depth/model_mdm_pre.pt - Alignment:
mode=query,num_task_tokens=8,use_image_tokens=True,use_contrastive=True,contrastive_loss_weight=0.3,depth_loss_weight=0.004
RoboTwin post-training
- Config paths:
configs/vla/robotwin_load20000h.yaml与configs/vla/robotwin_load20000h_depth.yaml - Differences:
loss_type=L1_fm,lr=1.0e-4,max_steps=20000,norm_type=bounds_99,norm_stats_file=assets/norm_stats/robotwin_50.json
5. Experimental Results (实验结果)
Real-world GM-100
| Platform | WALL-OSS SR/PS | GR00T N1.6 SR/PS | SR/PS | Ours w/o depth SR/PS | Ours w/ depth SR/PS |
|---|---|---|---|---|---|
| Agibot G1 | 2.99 / 8.75 | 5.23 / 12.63 | 7.77 / 21.98 | 12.82 / 30.04 | 11.98 / 30.47 |
| AgileX | 2.26 / 8.16 | 3.26 / 10.52 | 17.20 / 34.82 | 15.50 / 36.31 | 18.93 / 40.36 |
| Galaxea R1Pro | 6.89 / 14.13 | 14.29 / 24.83 | 14.10 / 26.14 | 18.89 / 34.71 | 20.98 / 35.40 |
| Average | 4.05 / 10.35 | 7.59 / 15.99 | 13.02 / 27.65 | 15.74 / 33.69 | 17.30 / 35.41 |
LingBot-VLA w/ depth 在平均 SR 上比 高 4.28 个百分点,PS 高 7.76 个百分点;w/o depth 也明显优于 WALL-OSS 与 GR00T N1.6。Galaxea R1Pro 上 GR00T N1.6 接近 ,论文解释为其 pre-training 中包含较多 Galaxea R1Pro data,说明结构相似的数据预训练对下游表现很关键。
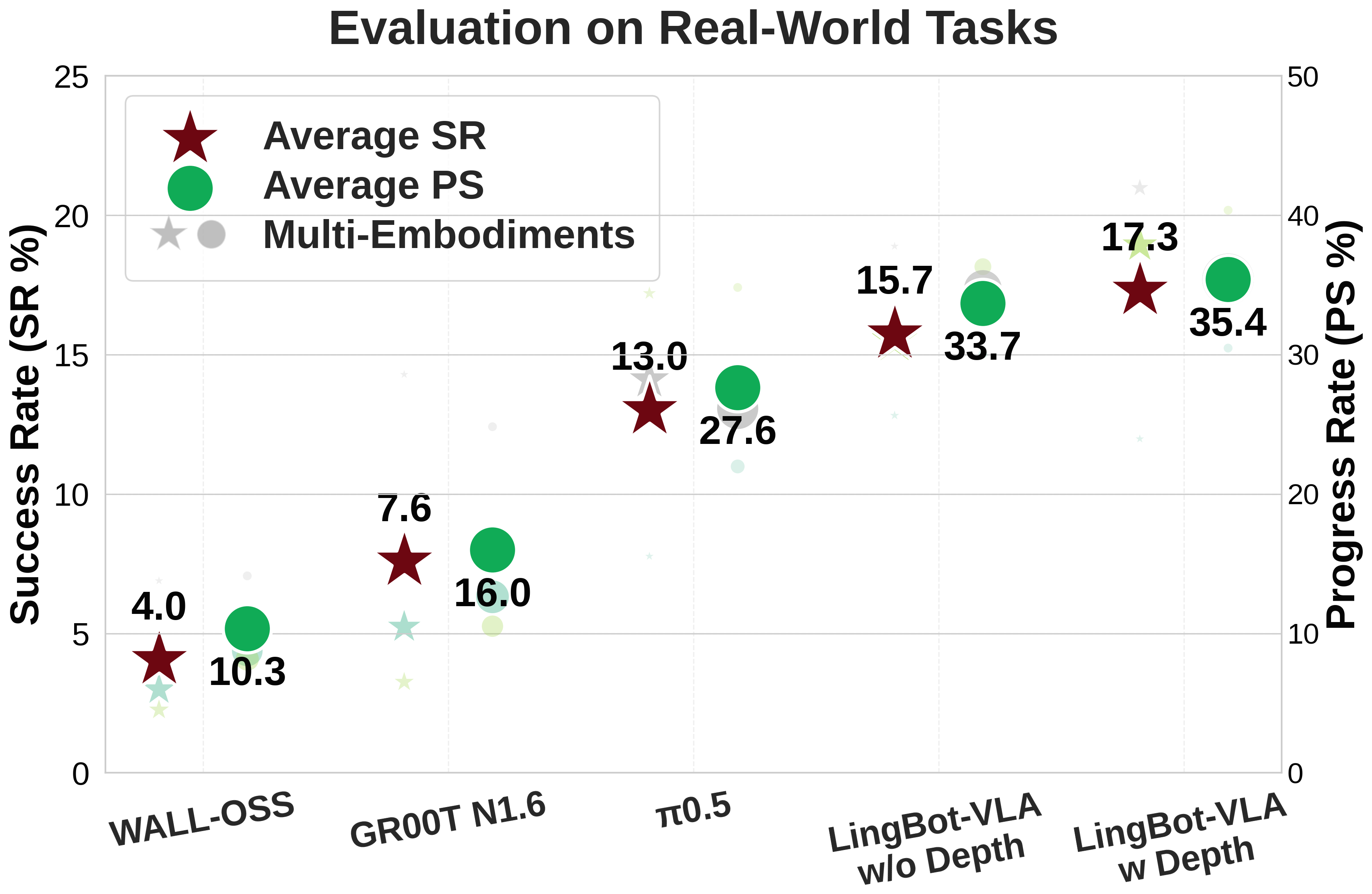
Figure GM-100 解读:该图用双轴展示 real-world SR/PS,对应表 1 的核心结论。Depth 版整体最好,但不同平台上 depth 的收益不完全一致:Agibot G1 SR 略低于 w/o depth,PS 略高;AgileX 与 Galaxea R1Pro 上 depth 同时提升 SR/PS。
RoboTwin 2.0 simulation
| Setting | Avg. SR | Ours w/o depth Avg. SR | Ours w/ depth Avg. SR |
|---|---|---|---|
| Clean scenes | 82.74% | 86.50% | 88.56% |
| Randomized scenes | 76.76% | 85.34% | 86.68% |
Clean scenes 中 depth version 比 高 5.82 个百分点;randomized scenes 中高 9.92 个百分点。w/o depth 也分别高 3.76 与 8.58 个百分点,说明模型本身的 pretraining/action expert 已经有效,depth distillation 进一步增强空间 robustness。
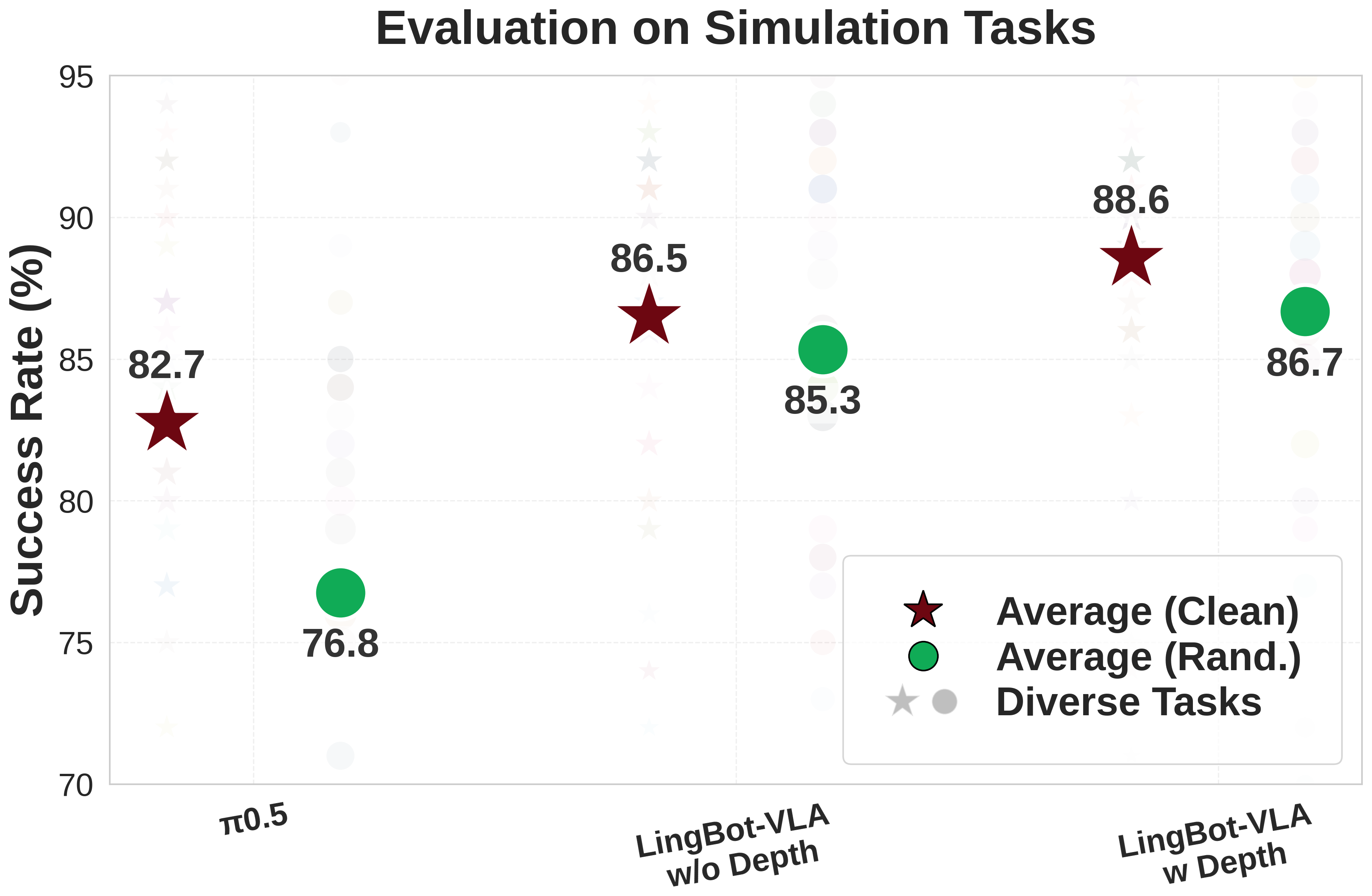
Figure RoboTwin 解读:图中 clean/randomized 两组结果都显示 LingBot-VLA 优于 ,且 randomized 场景提升更明显。这说明 depth/query alignment 对背景、杂物、桌高、光照变化带来的空间不确定性更有帮助。
Scaling and data efficiency
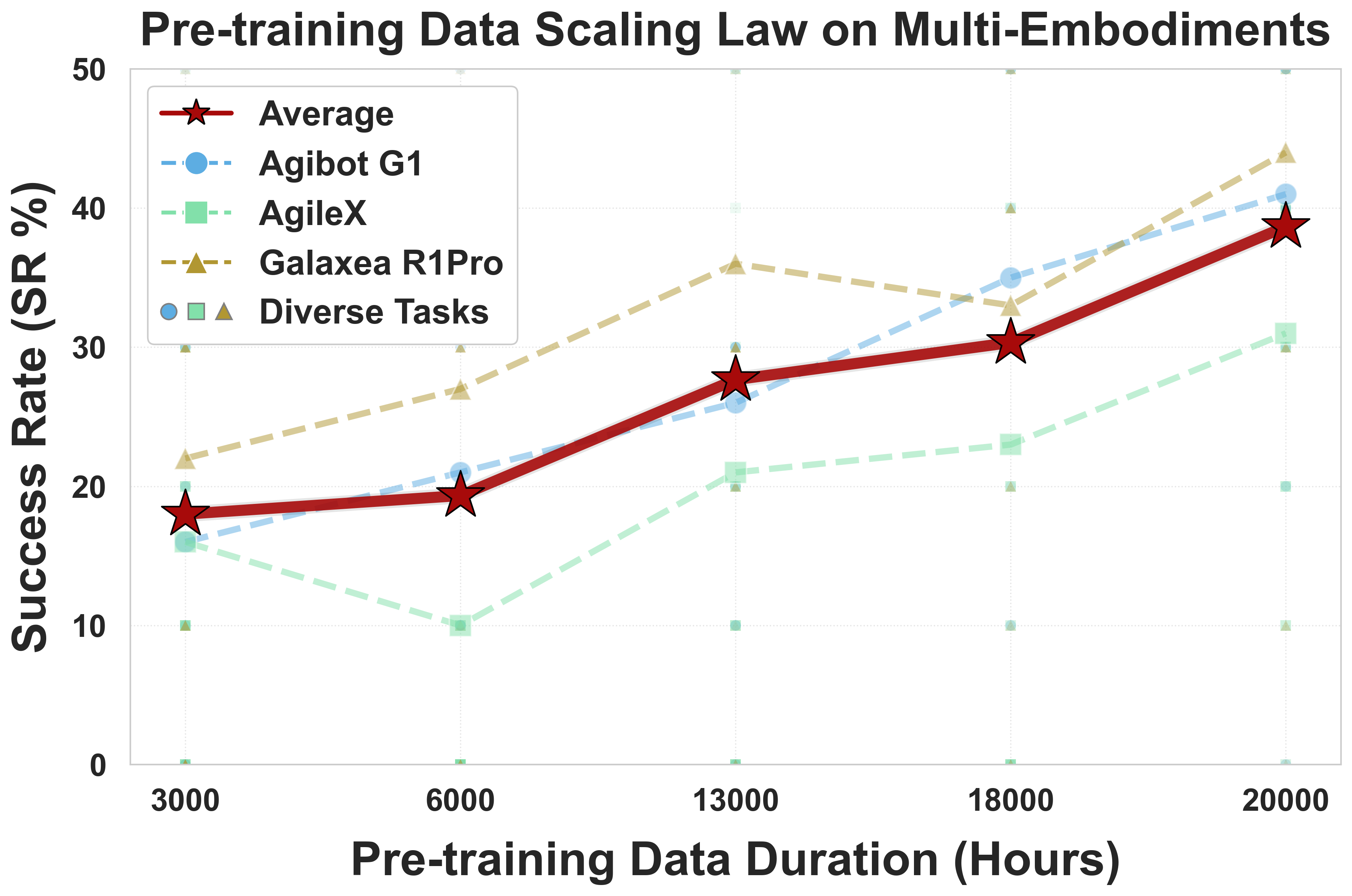
Figure 5 解读:预训练数据从 3,000 小时增加到 20,000 小时时,SR 持续上升,且 Agibot G1、AgileX、Galaxea R1Pro 的趋势大体一致。论文强调 20,000 小时处尚未看到明显饱和,这支持继续扩大 real-world robot data 的 scaling hypothesis。
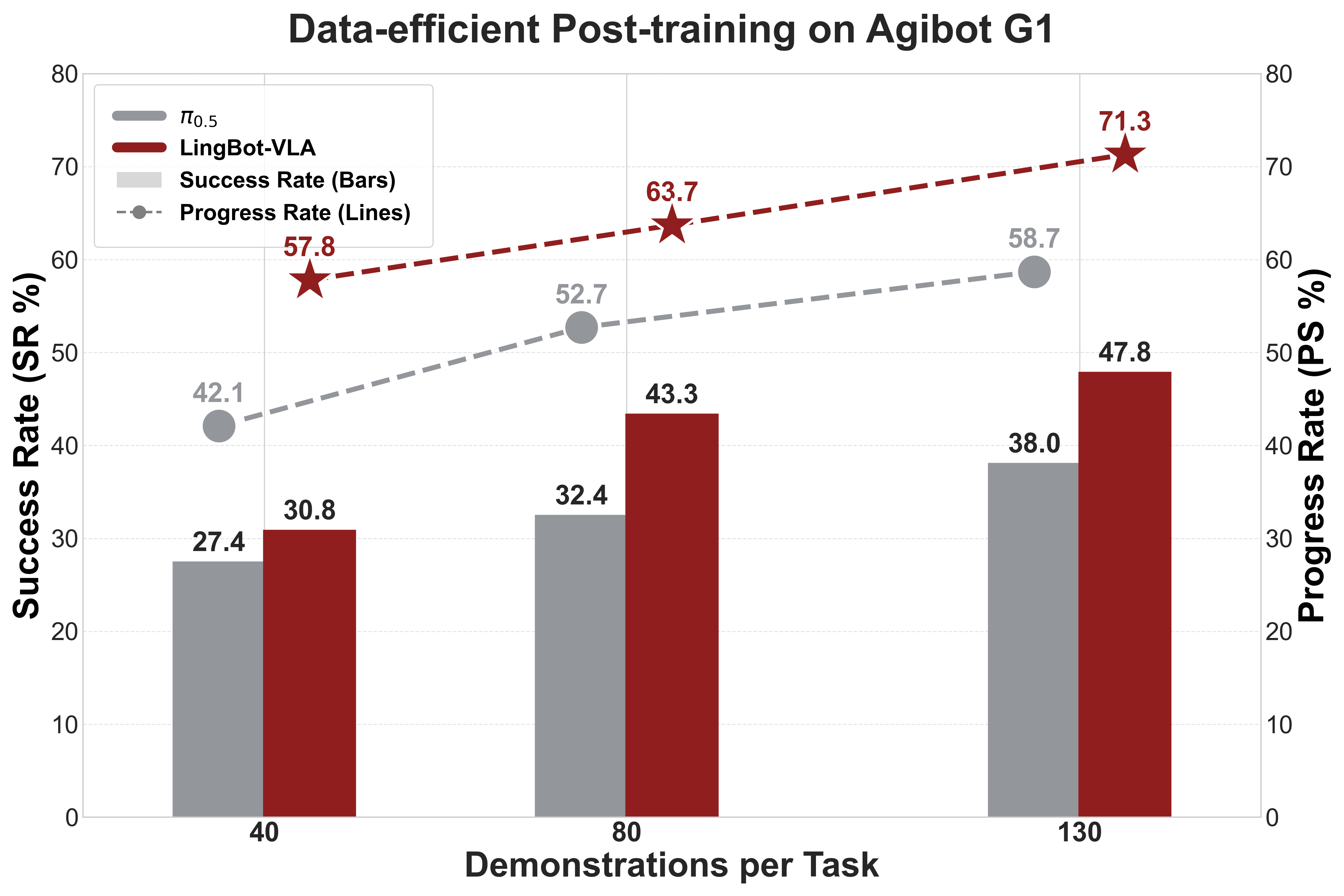
Figure 6 解读:在 GM-100 中选 8 个任务、Agibot G1 平台上做 data-efficient post-training。论文文字指出:只用 80 demonstrations/task 时,LingBot-VLA 已经在 PS 与 SR 上超过使用 full 130 demonstrations 的 ;随着 post-training 数据增加,LingBot-VLA 与 的差距继续扩大。
Limitations
作者明确把 future research 指向更广泛的机器人形态:当前数据和评测主要集中在 dual-arm manipulation,后续需要整合 single-arm 和 mobile robotic data。另一个实际限制是,20,000 小时真实数据与 GM-100 评测虽然显著推进了真实机器人 VLA,但 SR 绝对值仍不高:最佳平均 SR 为 17.30%,说明在 100 个真实任务上的可靠完成率距离生产级部署仍有很大差距。