Phys-AR: Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Authors: Wang Lin*, Liyu Jia*, Wentao Hu*, Kaihang Pan, Zhongqi Yue, Wei Zhao, Jingyuan Chen†, Fei Wu, Hanwang Zhang Affiliations: Zhejiang University, Nanyang Technological University, Huawei Singapore Research Center arXiv: 2504.15932
1. Motivation(研究动机)
传统 diffusion-based 视频生成方法依赖数据驱动的近似来建模物理运动规律,在训练数据分布内(IID)表现尚可,但面对分布外(OOD)物理条件(如未见过的速度、质量)时泛化能力极差。根本原因是:这些模型缺乏从第一性原理出发的物理约束,仅通过大量数据拟合统计模式,无法真正”理解”牛顿力学等物理定律。
与此同时,大语言模型(DeepSeek-R1、OpenAI o1)在符号推理(symbolic reasoning)上展现了强大能力,这启发了一个关键问题:能否将视频生成重新表述为一个符号推理问题,让 LLM 对物理定律进行推理并生成物理一致的视频?
然而,直接将现有视觉 tokenizer(如 VQGAN)的 token 输入 LLM 面临根本困难:
- 空间 token 缺乏层级依赖:VQGAN 按 raster scan 顺序生成 spatial token,每个 token 编码图像的一个 patch,它们之间缺乏类似自然语言那样的递归、层级结构,不适合 LLM 的推理机制
- 空间对称性导致语义”反义词”:图像坐标的空间对称性使得 spatial token 的 embedding 变化方向与 text token 不一致(余弦相似度为负),破坏了 LLM 的推理能力
- 帧间语义不连续:相邻视频帧的 spatial token embedding 相似度远低于 text token,尤其在存在加速运动时更加明显
本文提出 Phys-AR 框架,通过 Diffusion Timestep Tokenizer(DDT)将图像编码为递归结构的离散 token,使其具有类似语言的层级依赖;再通过两阶段训练(SFT + RL)让 LLM 学会物理定律的符号推理,从而生成物理一致的视频。
2. Idea(核心思想)
Phys-AR 的核心思路可以概括为:利用 diffusion 过程逐步擦除视觉属性的特性,构造递归结构的视觉 token 序列,使其像语言一样可被 LLM 推理;然后通过 SFT 学习”外语”(视觉符号),再通过 RL 从符号操作中涌现物理定律。
具体而言:
-
Diffusion Timestep Tokenizer(DDT):利用 diffusion 过程中噪声逐步增加→视觉属性逐步丢失的特性,反过来在每个 timestep 恢复丢失的属性,构造一个递归扩展的 token 序列 。这种结构天然具有层级依赖,类似自然语言的递归特性。
-
两阶段训练:
- Stage 1(SFT):将 DDT 的 256 个视觉码本 ID 加入 LLM 词汇表,用 next-token prediction 训练 LLM 学习视觉 token 的”语法”——类比外语学习
- Stage 2(RL):基于 GRPO 算法,设计物理量(速度、质量)的 reward function,引导 LLM 通过策略梯度优化自主发现物理定律——类比数学推理
-
关键洞察:DDT token 的递归结构赋予 RL exploration 天然优势,类似于数学中 “20=((((16)+1)+1)+1)” 的回溯机制,使模型能高效探索符号空间。
3. Method(方法)
3.1 整体框架
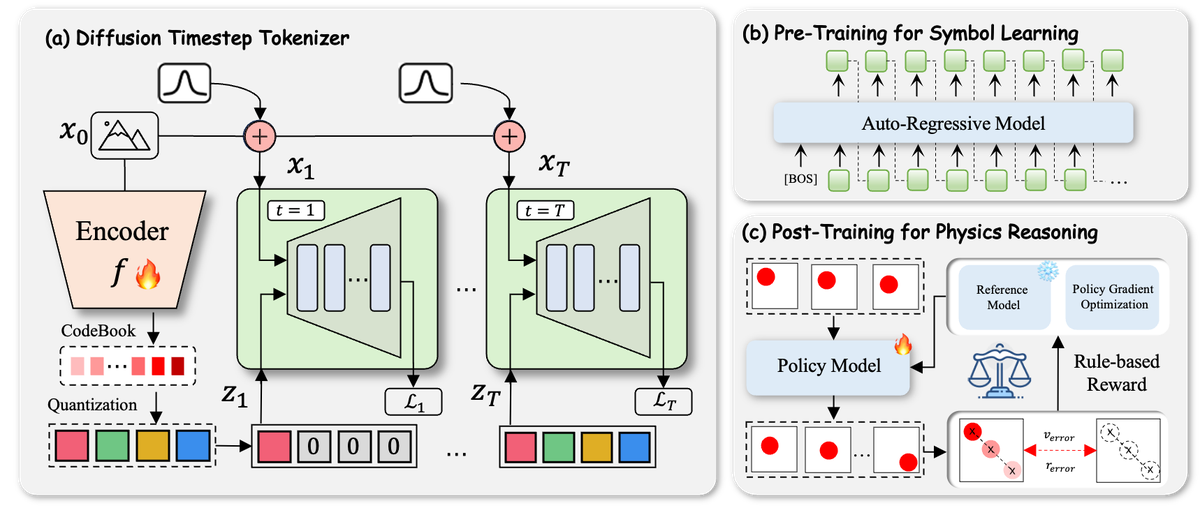
Figure 2 解读:框架图展示了 Phys-AR 的三个核心组件。(a) Diffusion Timestep Tokenizer:左侧的 Encoder 将无噪声图像 编码,在每个 diffusion timestep 生成扩展的 token 序列 ,通过 Codebook 量化为离散 token;Decoder 利用 MMDiT 架构从量化 token 重建图像。(b) Pre-Training for Symbol Learning:将所有帧的 DDT token 拼接为一维序列,以 next-token prediction 方式训练 Auto-Regressive 模型(Llama3.1-8B)。(c) Post-Training for Physics Reasoning:Policy Model 生成候选视频 token 序列,通过 Rule-based Reward( 和 )计算奖励,Reference Model 提供 KL 约束,Policy Gradient Optimization 更新策略。
3.2 物理视频生成的问题定义
将物理模拟定义为 first-principle 方程的状态转移:
其中 是不同时间步的物理状态(如自由落体中 )。视频生成则是:
本文的目标是将两者统一:
即在生成视频帧 的同时,确保生成过程遵循物理定律 。
3.3 Diffusion Timestep Tokenizer(DDT)
DDT 的核心直觉:在 Diffusion Model 中,噪声逐步增加会逐步擦除视觉属性(位置→大小→颜色等)。DDT 反过来利用这一过程,在每个 timestep 恢复丢失的属性,构造递归 token 序列。
Encoder
使用预训练 VAE 提取 latent features:
然后通过 Q-former encoder(含两个独立 Transformer,各 12 层,hidden dim=128)处理 个 learnable query tokens ,得到 1D latent 序列:
# DDT Encoder 伪代码
def ddt_encode(image):
# Step 1: VAE feature extraction
V = vae_encoder(image) # V: [1024, 256]
# Step 2: Q-former encoding with learnable queries
Q = learnable_queries # Q: [T=16, d=256]
# Two independent transformers with unified attention
Z_1D = qformer_encoder(Q, V)[:T] # Keep query latent only: [16, 256]
return Z_1DQuantizer
使用 EMA-variant 的 Vector Quantization,codebook ():
- 线性投影 256-d → 16-d(降维)
- L2 归一化
- 余弦相似度匹配最近邻码本向量
- 每步监控 dead entries(匹配频率极低的码本向量),重置为随机
# Quantizer 伪代码
def quantize(Z_1D, codebook):
Z_proj = linear_project(Z_1D) # [T, 256] -> [T, 16]
Z_norm = l2_normalize(Z_proj) # L2 normalization
# Cosine similarity lookup
indices = []
for z in Z_norm:
sim = cosine_similarity(z, codebook) # [N=256]
idx = argmax(sim)
indices.append(idx)
V_quantized = codebook[indices] # Discrete timestep tokens
return V_quantized, indicesDecoder
基于 MMDiT 架构(12 层,latent dim=512),使用两个独立 Transformer 分别处理 visual noise sequence 和 timestep tokens ,通过 attention 操作合并:
训练损失
遵循 Rectified Flow,采样噪声图像 ,训练 decoder 从 expanding token set 重建原图:
加上 commitment loss 正则化:
# DDT Training 伪代码
def ddt_training_step(x0):
# Encode
Z_1D = ddt_encode(x0)
V_quant, _ = quantize(Z_1D, codebook)
# Sample timestep and noise
t = uniform(0, 1)
eps = randn_like(x0)
x_t = t * eps + (1 - t) * x0 # Rectified Flow interpolation
# Decoder reconstructs from expanding token set (V_1, ..., V_t)
V_expanding = V_quant[:int(t * T)] # First t tokens
x0_pred = mmddit_decoder(x_t, t, V_expanding)
# Reconstruction loss + commitment loss
L_recon = mse(x0_pred, x0)
L_commit = sum(mse(V_hat_i, V_i) for i in range(T))
loss = L_recon + L_commit
return loss3.4 Pre-Training for Symbol Learning(SFT 阶段)
将 DDT 的 个视觉码本 ID 作为新”词汇”加入 LLM(Llama3.1-8B)的词汇表,用标准 next-token prediction 训练:
其中 是序列长度, 是视觉 token。训练过程类比”外语学习”——LLM 学习 DDT token 之间的语法规则和帧间转换模式。
关键细节:推理时 mask 掉文本 token 的 logits,只对视觉 token 采样。
# SFT Pre-training 伪代码
def sft_pretrain(video_frames, llm):
# Step 1: Tokenize all frames via DDT
all_tokens = []
for frame in video_frames: # 32 frames
Z_1D = ddt_encode(frame)
_, indices = quantize(Z_1D, codebook) # [T=16] integers in [0, 255]
all_tokens.extend(indices)
# Step 2: Prepend [BOS], create AR sequence
input_seq = [BOS] + all_tokens[:-1]
target_seq = all_tokens
# Step 3: Standard cross-entropy loss
logits = llm(input_seq)
loss = cross_entropy(logits, target_seq)
return loss3.5 Post-Training for Physics Reasoning(RL 阶段)
Reward Function 设计
基于两个物理量设计 rule-based reward:
1) Velocity Error:通过检测相邻帧中圆的圆心轨迹计算速度误差:
其中 是生成视频的计算速度, 是 ground truth 速度, 是球的数量, 是有效帧数。
2) Velocity Reward:采用指数衰减函数将误差转化为奖励:
其中 控制最大奖励, 控制衰减率。这个非线性映射在低误差区域产生陡峭梯度,增强模型对精确预测的敏感度。
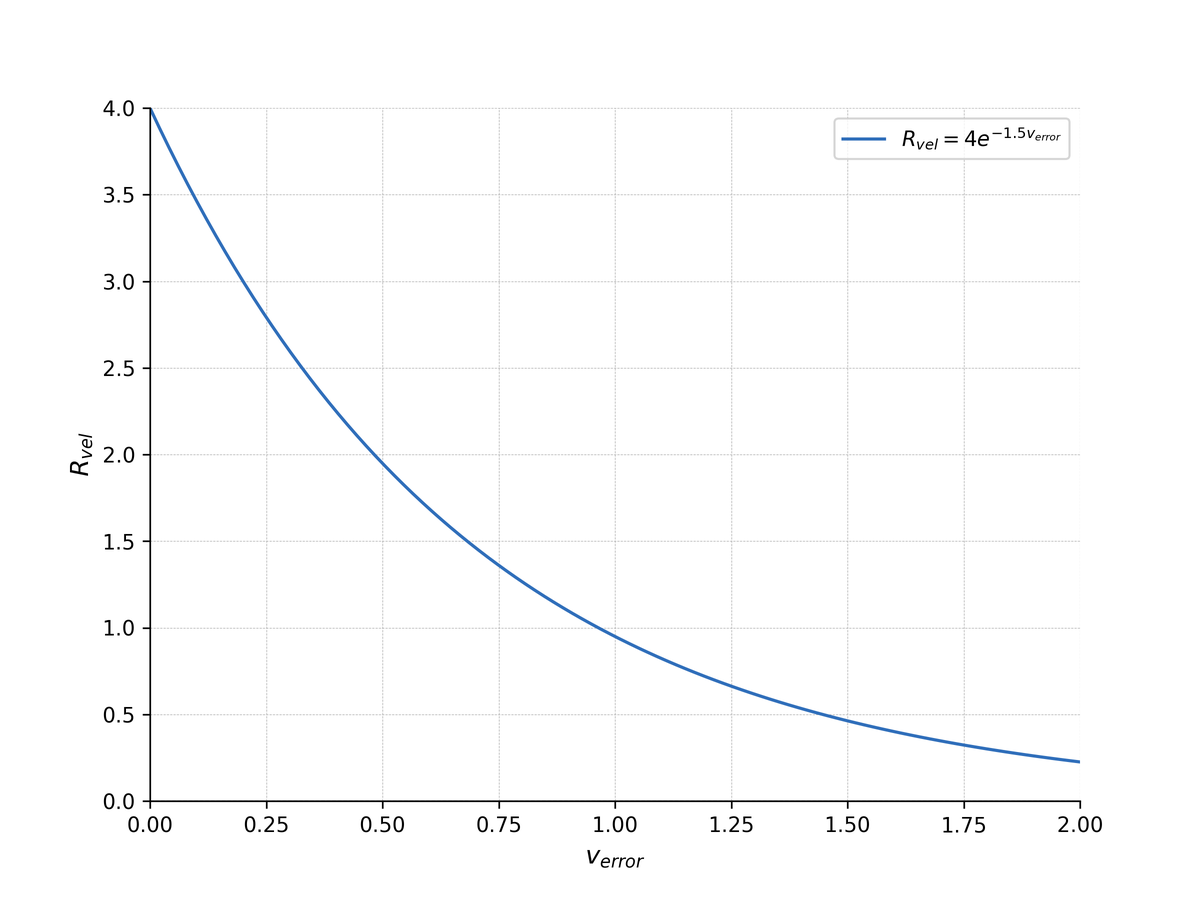
Figure 9 解读:速度 reward 函数的可视化。横轴为 ,纵轴为 。曲线 在 时接近最大值 4,且梯度非常陡峭;当 时奖励趋近于 0。这种设计使模型在”接近正确”时获得最大的梯度信号,高效引导优化方向。
3) Mass Reward:假设球密度均匀,通过半径表征质量:
其中 是通过检测生成球的 mask 区域计算的半径误差。
4) 总 Reward:
GRPO 算法
给定输入条件帧 ,当前策略 生成 个候选预测 ,计算各自 reward ,归一化得到相对优势:
优化目标:
其中 控制 KL 散度约束。
# GRPO Post-training 伪代码
def grpo_training_step(condition_frames, policy_model, ref_model):
# Step 1: Tokenize condition frames
cond_tokens = tokenize_frames(condition_frames[:3]) # First 3 frames
# Step 2: Generate g candidate predictions
g = group_size # number of candidates
predictions = []
for _ in range(g):
pred = policy_model.generate(
cond_tokens,
max_new_tokens=29 * 16, # 29 frames x 16 tokens/frame
top_k=50, top_p=0.95
)
predictions.append(pred)
# Step 3: Decode and compute rewards
rewards = []
for pred in predictions:
frames = decode_tokens_to_frames(pred)
v_err = compute_velocity_error(frames, ground_truth)
r_err = compute_radius_error(frames, ground_truth)
R_vel = 4.0 * exp(-1.4 * v_err)
R_mass = 1.0 - r_err
rewards.append(R_vel + R_mass)
# Step 4: Compute group-relative advantages
mean_r = mean(rewards)
std_r = std(rewards)
advantages = [(r - mean_r) / std_r for r in rewards]
# Step 5: GRPO policy gradient with KL constraint
for pred, adv in zip(predictions, advantages):
log_prob = policy_model.log_prob(pred, cond_tokens)
ref_log_prob = ref_model.log_prob(pred, cond_tokens)
kl = log_prob - ref_log_prob
loss = -(adv * log_prob - beta * kl)
return loss3.6 DDT Token 为何像语言?(三大性质)
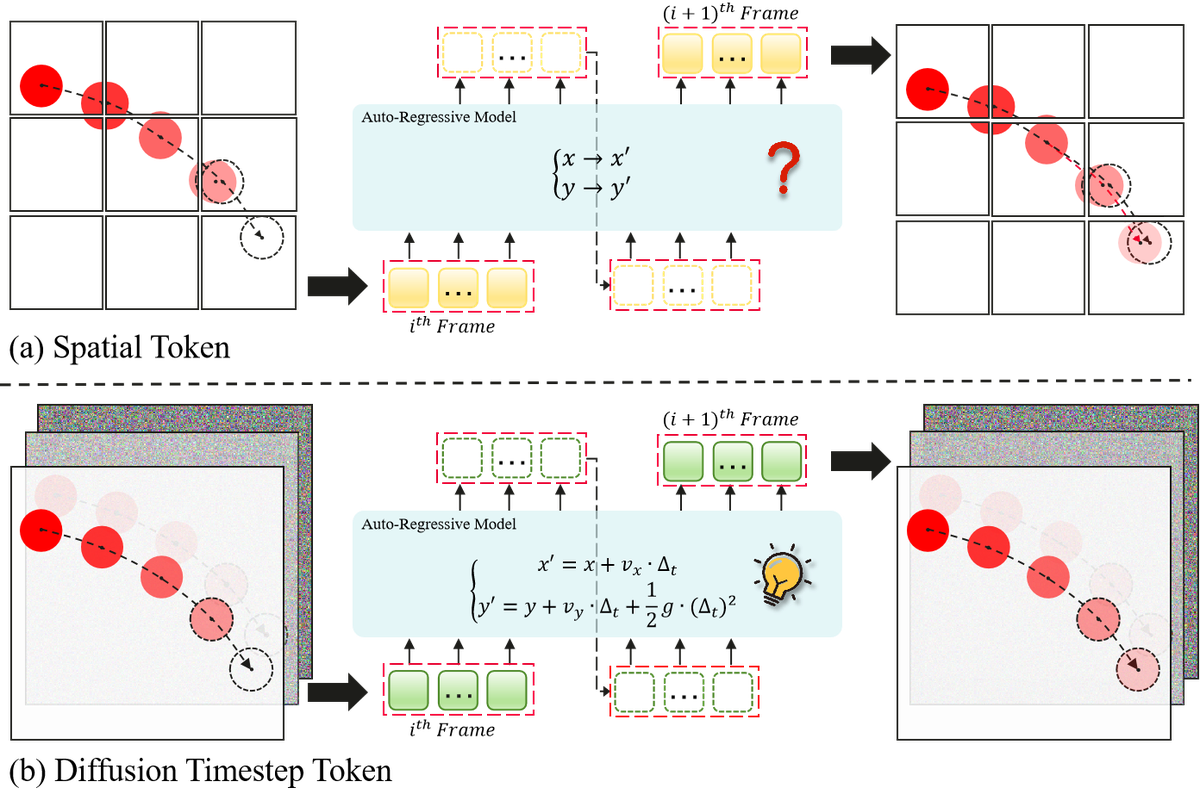
Figure 1 解读:对比 spatial token 和 DDT token 的自回归物理视频生成效果。(a) Spatial Token:给定前 3 帧后,基于 spatial token 的 AR 模型(经过 Jello Regression Model 推理后)预测的球轨迹偏离正确物理轨迹,说明模型未能正确推理物理定律。(b) Diffusion Timestep Token:基于 DDT 的 AR 模型正确生成了符合物理定律的视频,球按照正确轨迹运动。这直观展示了递归结构 token 对物理推理的关键作用。
性质 1:递归结构(Recursive Structure)
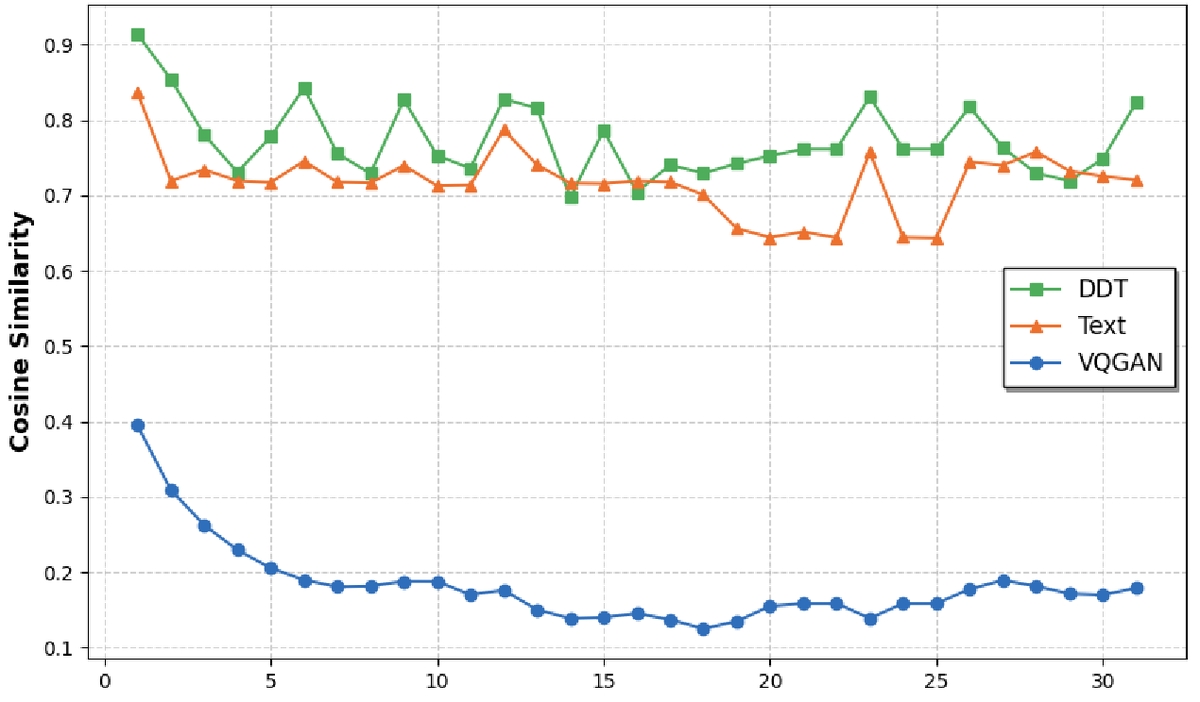
Figure 7 解读:Counterfactual Interpolation 实验。对 VQGAN token 做 token 替换等价于 CutMix——直接拼接两张图像的不同区域(空间分割)。而对 DDT token 做 token 替换则实现了语义属性的交换(如半径、位置),不同 token 编码不同的视觉属性。这证明 DDT token 具有解耦的递归结构,每个 token 负责不同层级的视觉属性。
性质 2:对图像变化的一致响应
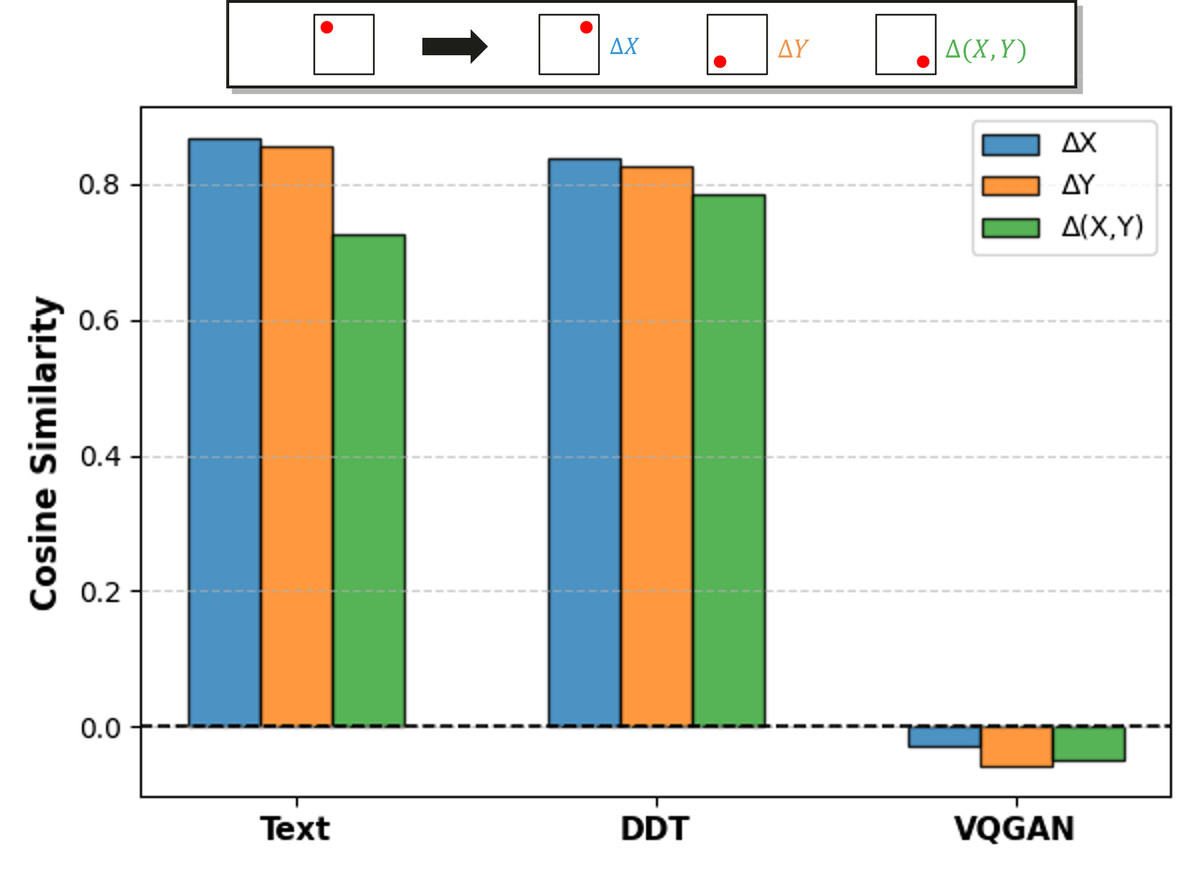
Figure 5 解读:对比三种 token embedding 对图像坐标变化的响应。随机生成 5k 组坐标变化(如从 (0.5, 0.5) 变为 (1.2, 0.5)),比较 token embedding 变化与 text token embedding 变化的余弦相似度。Text 和 DDT token 对 、、 的 embedding 变化方向一致(正余弦相似度 ~0.73-0.86);而 VQGAN token 的余弦相似度接近 0 甚至略为负,因为 2D 空间对称性导致了语义上的”反义词”效应。
性质 3:帧间动态的平滑变化
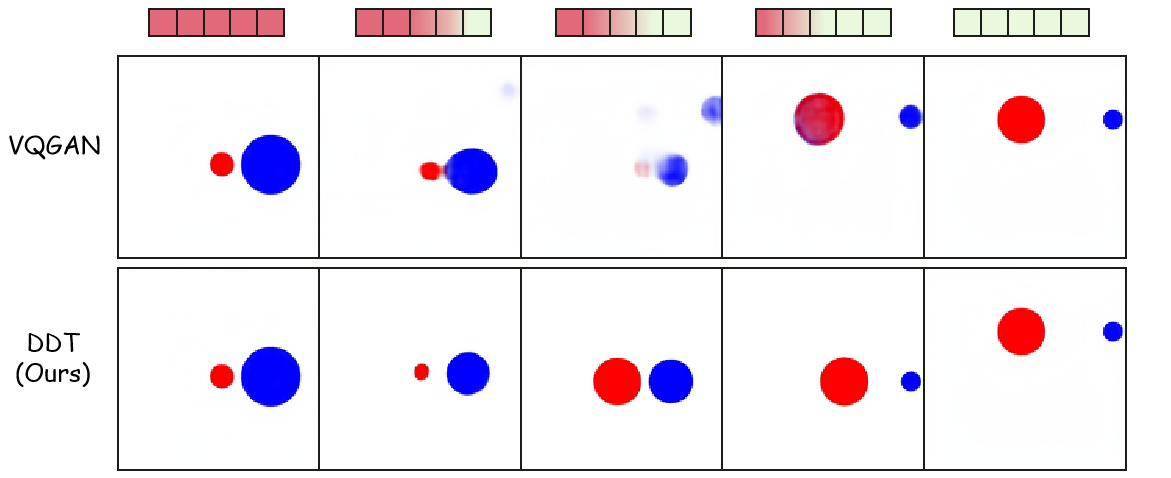
Figure 6 解读:对比三种 tokenizer 在相邻视频帧之间的 token embedding 余弦相似度。统计 1000 个随机视频的结果:DDT token(绿色)和 Text token(橙色)在帧间保持高相似度(~0.65-0.9),且变化平滑;VQGAN spatial token(蓝色)的帧间相似度显著更低(~0.1-0.4),尤其在后期帧(加速运动导致更大的像素变化)时进一步下降。这说明 DDT token 的帧间语义变化更平滑,更适合 LLM 进行时序推理。
4. Experimental Setup(实验设置)
数据集
使用 PhyWorld 数据集,基于 Box2D 物理模拟器:
- 三种物理运动:匀速直线运动(Uniform)、抛物线运动(Parabola)、碰撞(Collision)
- 世界设置: 网格,时间步 0.1 秒,总时间跨度 3.2 秒(32 帧)
- 输入/输出:前 3 帧为条件输入,预测后 29 帧
数据分布
| 阶段 | 半径 | 速度 |
|---|---|---|
| SFT 训练(IID) | ||
| RL Post-training | ||
| OOD 测试 |
注意:RL 阶段使用训练分布边界附近的数据,OOD 测试使用远离训练分布的数据。
Tokenizer 设置
| 参数 | 值 |
|---|---|
| Token 数量 | 16 per image |
| Codebook 大小 | 256 |
| 图像分辨率 | |
| Encoder | Q-former, 2 transformers, 12 layers, dim=128 |
| Decoder | MMDiT, 12 layers, latent dim=512 |
训练超参数
| 参数 | Tokenizer | LLM Pre-train (SFT) | LLM Post-train (RL) |
|---|---|---|---|
| 基座模型 | - | Llama3.1-8B | LLM-pre-train |
| Optimizer | AdamW | AdamW | AdamW |
| Peak LR | 1e-4 | 1e-4 | 3e-6 |
| Batch size | 1024 | 768 | 28 |
| Training steps | 140K | 360K | 1600 |
| Warmup steps | 5K | 5K | 100 |
| Weight decay | 0.0 | 0.05 | 0.05 |
| Precision | bfloat16 | bfloat16 | bfloat16 |
| GPU 资源 | 32 NVIDIA A800 | 80 NVIDIA A800 | 8 NVIDIA A800 |
| Sampling | - | - | top_k=50, top_p=0.95 |
Baseline 方法
- Diffusion-based:DiT-S / DiT-B / DiT-L(不同参数量的 DiT 模型)
- AR + Spatial Token:Qwen-1.5B / Qwen-7B / Llama3.1-8B(使用 VQGAN token)
- AR + DDT:Llama3.1-8B(使用 DDT token,本文方法)
评估指标
- Velocity Error():生成视频中球的计算速度与 ground truth 速度的绝对误差(Eq. 4)
5. Results(实验结果)
5.1 主实验结果

Figure 3 解读:不同方法在三种物理运动(Uniform、Collision、Parabola)上的 velocity error 随训练数据量(30K → 300K → 3M)的变化。实线代表 IID 数据,虚线代表 OOD 数据。关键发现:(1) 所有方法在 IID 上随数据增加误差下降;(2) DiT-L(蓝色虚线)在 OOD 上误差不降反升,说明 diffusion 模型的泛化能力有限;(3) AR+VQGAN(绿色虚线)在 OOD 上有一定改善但仍然较高( 量级);(4) AR+DDT(橙色虚线)在 OOD 上误差达到 量级,比其他方法低一个数量级。
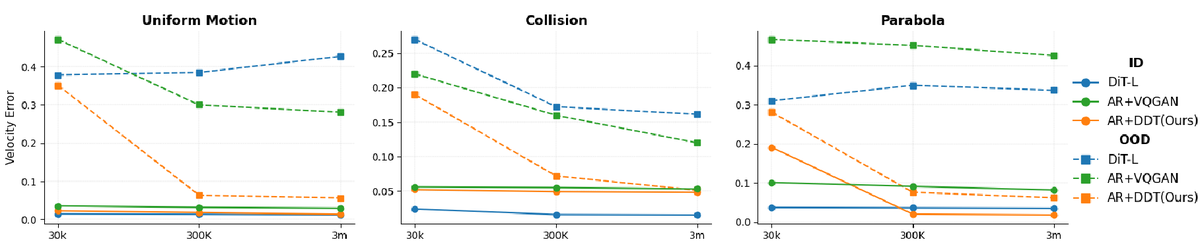
Figure 10 解读:不同模型架构和参数量的 velocity error 对比。
| 方法 | Uniform IID/OOD | Parabola IID/OOD | Collision IID/OOD |
|---|---|---|---|
| DiT-S | 0.015 / 0.288 | 0.052 / 0.311 | 0.023 / 0.153 |
| DiT-B | 0.014 / 0.358 | 0.036 / 0.287 | 0.018 / 0.211 |
| DiT-L | 0.012 / 0.427 | 0.035 / 0.337 | 0.015 / 0.161 |
| Qwen-1.5B | 0.025 / 0.271 | 0.023 / 0.399 | 0.056 / 0.185 |
| Qwen-7B | 0.016 / 0.071 | 0.017 / 0.068 | 0.043 / 0.047 |
| Llama3.1-8B (Ours) | 0.014 / 0.057 | 0.018 / 0.062 | 0.048 / 0.051 |
关键发现:
- DiT 模型增大参数量(S→B→L)对 OOD 无明显帮助,甚至 DiT-L 在 Uniform OOD 上误差最高(0.427)
- AR 模型中,参数量从 1.5B 到 7B/8B 显著降低 OOD 误差,说明更大的 LLM 具有更强的推理能力
- Llama3.1-8B + DDT 在所有 OOD 场景上均达到最优(Uniform: 0.057, Parabola: 0.062, Collision: 0.051)
5.2 生成视频可视化

Figure 4 解读:三种物理运动的生成视频对比。每组对比包含 DiT、AR+VQGAN、AR+DDT(Ours)和 Ground Truth(GT)。左侧为匀速运动和碰撞的帧序列,虚线标注正确运动轨迹,箭头表示时间方向。右上为 parabola 运动的轨迹叠加图。可以看到:DiT 和 AR+VQGAN 在 OOD 条件下轨迹明显偏离(球位置错误、大小不准),而 AR+DDT 的轨迹与 GT 高度吻合。
5.3 RL 的效果分析

Figure 8 解读:RL 对两种 tokenizer(VQGAN vs DDT)的影响可视化。四个子图分别为:(a) VQGAN w/o RL,(b) VQGAN w/ RL,(c) DDT w/o RL,(d) DDT w/ RL。每个子图中水平和垂直误差箭头表示 radius error 和 velocity error,绿色区域为 pre-training 数据范围,黄色为 post-training 范围,红色为 OOD 测试范围。关键观察:(c) DDT w/o RL 存在系统性偏差——倾向生成较小的球和较慢的运动;(d) DDT w/ RL 几乎消除了所有偏差,箭头显著缩短。而 VQGAN 即使加上 RL(b),在 OOD 区域仍有大量误差箭头。
| 方法 | Uniform IID/OOD | Parabola IID/OOD | Collision IID/OOD |
|---|---|---|---|
| VQGAN w/o RL | 0.032 / 0.884 | 0.090 / 0.951 | 0.054 / 0.322 |
| VQGAN w/ RL | 0.030 / 0.281 | 0.082 / 0.426 | 0.053 / 0.120 |
| DDT w/o RL | 0.032 / 0.763 | 0.024 / 0.685 | 0.050 / 0.184 |
| DDT w/ RL | 0.014 / 0.057 | 0.018 / 0.062 | 0.048 / 0.051 |
Table 2 关键发现:
- RL 对 DDT 的 OOD 提升巨大:Uniform 0.763→0.057(13.4x),Parabola 0.685→0.062(11x),Collision 0.184→0.051(3.6x)
- RL 对 VQGAN 的 OOD 提升有限:Uniform 0.884→0.281(3.1x),Parabola 0.951→0.426(2.2x)
- 根本原因:DDT 的递归结构支持高效的 RL 探索(类似数学中的回溯),而 spatial token 缺乏递归结构,需要更大的搜索空间
5.4 Tokenizer 重建质量
| 场景 | Ground Truth | VAE (DiT) | VQGAN | DDT |
|---|---|---|---|---|
| Uniform | 0.0099 | 0.0105 | 0.0118 | 0.0121 |
| Collision | 0.0117 | 0.0131 | 0.0155 | 0.0147 |
| Parabola | 0.0210 | 0.0210 | 0.0231 | 0.0198 |
Table 4 关键发现:三种 tokenizer 的重建误差均与 Ground Truth 非常接近,说明性能差异不来自编解码精度,而来自 token 结构对 LLM 推理的适配性。
6. Code-to-Paper Mapping
| Paper 组件 | 代码模块(推测) | 说明 |
|---|---|---|
| DDT Encoder | encoder.py / Q-former | 基于 SD3 的 Q-former 架构,两个独立 Transformer |
| DDT Quantizer | quantizer.py | EMA-VQ,codebook size=256,含 dead entry 监控 |
| DDT Decoder | decoder.py / MMDiT | 基于 SD3 MMDiT,12 层,latent dim=512 |
| SFT Pre-training | pretrain.py | 标准 next-token prediction,基于 Llama3.1-8B |
| GRPO Post-training | rl_training.py | GRPO 算法,reward = |
| Reward Function | reward.py | 速度误差 + 半径误差, |
| PhyWorld Dataset | data/phyworld/ | Box2D 模拟器,3 种运动,32 帧视频 |
注:本文截至 2026-03-12 未公开源代码。以上为基于论文描述的代码结构推测。