NitroGen: An Open Foundation Model for Generalist Gaming Agents
Paper: arXiv:2601.02427 Code: MineDojo/NitroGen Code reference:
main@32608444(2026-01-25)
1. Motivation (研究动机)
通用 embodied agents 的一个长期瓶颈是缺少大规模、多样、带动作标签的数据。NLP/vision 可以用互联网文本/图像做 pre-training,但 embodied AI 通常要么依赖昂贵的人工演示,要么依赖专用 simulator/API。游戏是理想中间域:视觉丰富、任务多样、交互闭环明确,但现有 gaming agents 往往是单游戏专家,或者需要访问游戏内部状态/手写 API,难以扩展到任意商业游戏。
NitroGen 要解决的具体问题是:能否只用公开视频中的 gameplay 和 overlay controller inputs,自动抽取 frame-level actions,构建 internet-scale video-action dataset,并训练一个能跨游戏 zero-shot / post-training 迁移的 vision-action foundation model。它不试图马上解决长程规划,而是先证明“从 noisy internet gameplay videos 学到 fast-reacting system-1 policy”这条 scaling path 可行。
这个问题值得研究,因为游戏提供了比真实机器人便宜得多、规模大得多的 embodied interaction data。如果能从 40,000 小时、1,000+ games 的公开视频中自动抽取动作标签,就可以把 behavior cloning 的数据来源从手工录制扩展到互联网规模。
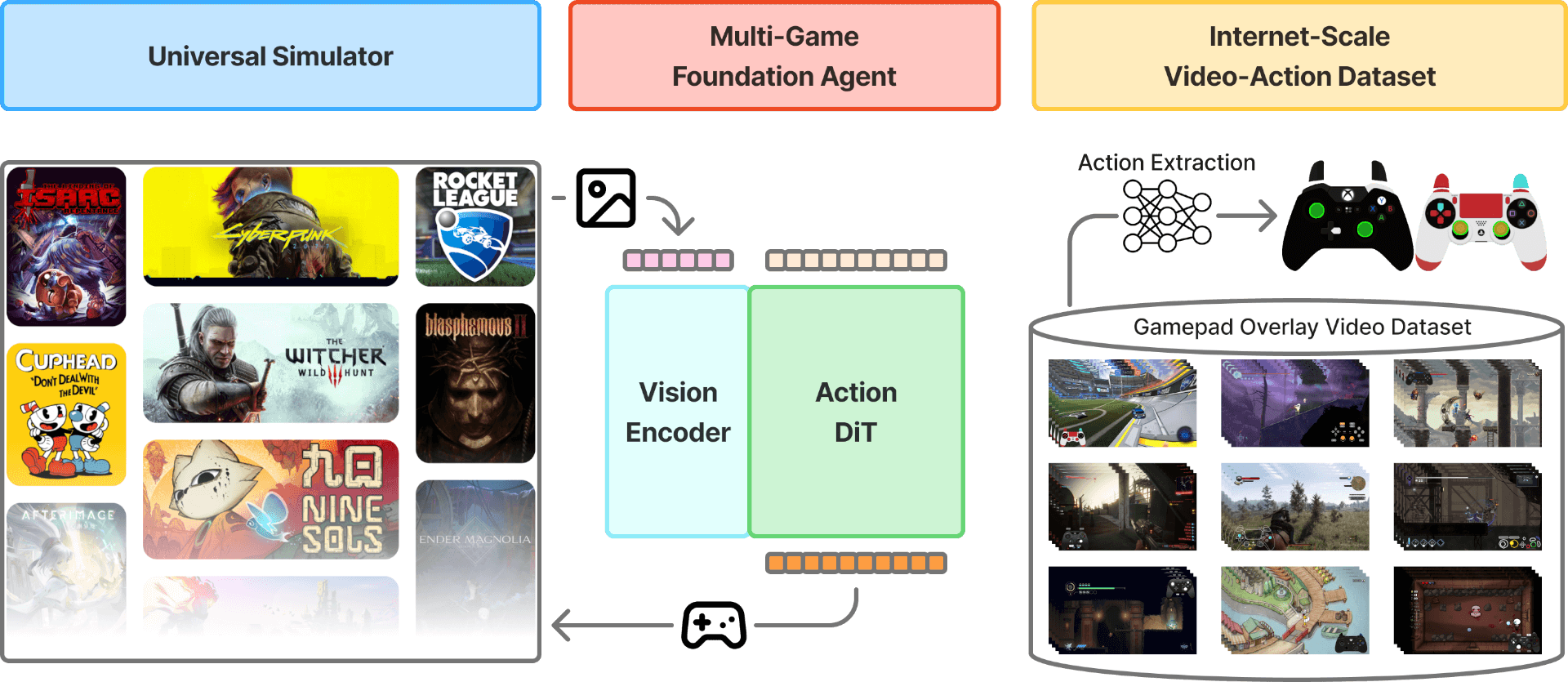
Figure 1 解读:NitroGen 有三个核心组件:中间是 multi-game foundation agent,从像素 observation 预测 gamepad actions;左侧是 universal simulator,把商业游戏包装成 Gymnasium API;右侧是 internet-scale dataset,从带 input overlay 的公开视频中抽取 action labels。图中最重要的设计取舍是:不要求访问游戏内部状态,也不要求每个游戏写专门 perception module,而是把像素到手柄动作建模为统一行为克隆问题。
2. Idea (核心思想)
核心 insight:大量游戏视频已经隐式包含人类策略演示;如果视频中叠加了 gamepad overlay,就可以把公开视频转成 action-labeled demonstrations。NitroGen 的本质创新是把“看视频学动作”变成可扩展 pipeline:controller overlay localization + action parsing + unified gamepad action space + flow-matching vision-action model。
关键创新包括:40,000 小时 / 1,000+ games 的视频-动作数据集、30 tasks / 10 commercial games 的评测环境、以及 500M DiT-based vision-action policy。模型不使用语言和状态输入,只用短视觉上下文生成 gamepad action chunks,因此更像可迁移的 sensory-motor prior,而不是完整 autonomous planner。
与 VPT、MineDojo、Voyager 类方法相比,NitroGen 不依赖 Minecraft 这种单一平台,也不依赖文本 API 或游戏内部状态;与 RL 单游戏专家相比,它牺牲长程最优性,换取跨游戏数据规模和 post-training 起点。
3. Method (方法)
3.1 Dataset pipeline
NitroGen 的数据来源是公开 gameplay videos,其中一部分创作者会在画面上显示 input overlay。作者先收集 71,000 小时 raw videos,再通过 overlay 检测、action parsing、过滤,得到 40,000 小时、1,000+ games 的 labeled video-action dataset。论文还报告数据集包含 38,739 小时有效 gameplay,846 个游戏超过 1 小时数据。
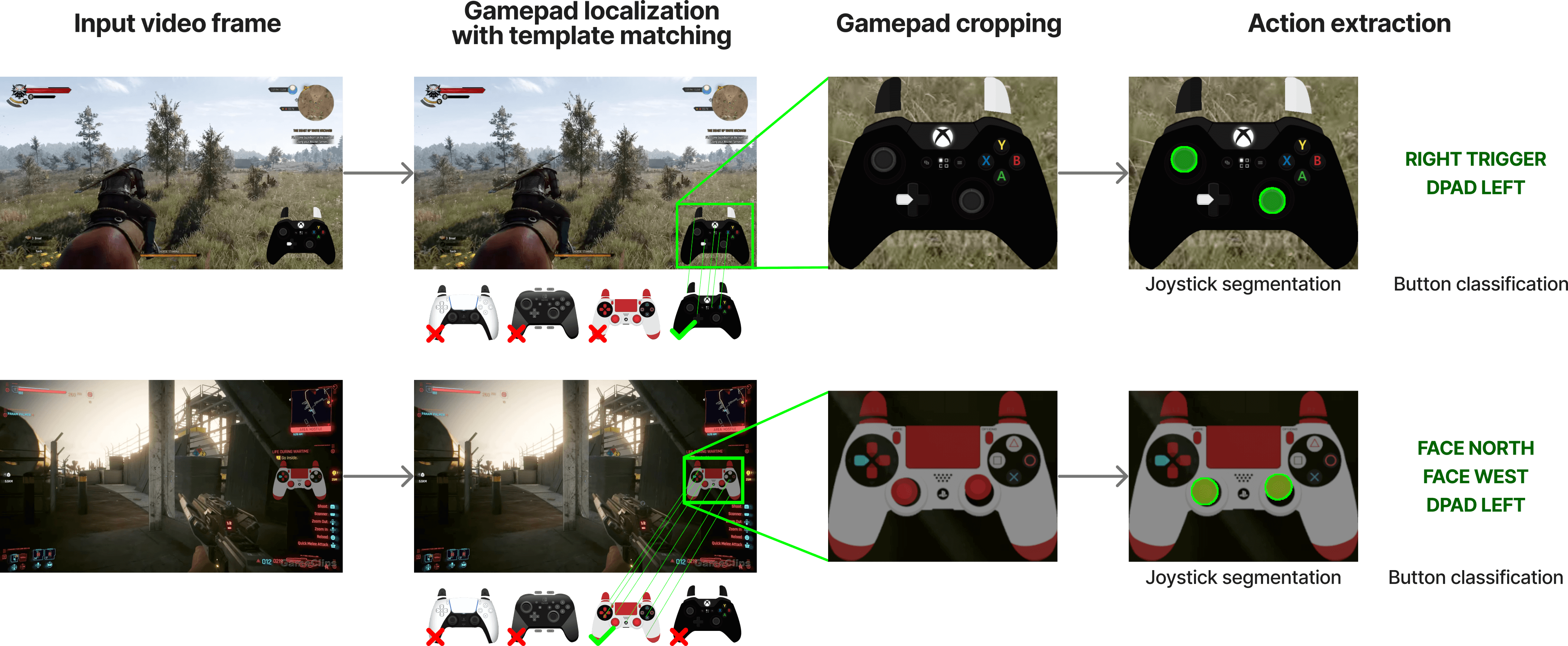
Figure 2 解读:数据 pipeline 分两步。Stage 1 是 dataset curation:从公开视频中找到带 gamepad overlay 的片段;Stage 2 是 action extraction:先用 template matching 定位 gamepad,再用 hybrid classification-segmentation network 解析 joystick 和 buttons。这个图解释了 NitroGen 能规模化的关键:动作标签不是人工逐帧标注,而是从画面 overlay 自动恢复。
具体 action extraction 有两个阶段:
- Template matching:使用约 300 个 controller templates;每个视频采样 25 帧,使用 SIFT 与 XFeat 做 feature matching;估计 affine transform,并要求至少 20 个 inliers 才接受匹配。
- Gamepad action parsing:fine-tuned SegFormer 处理连续两帧拼接输入,输出 joystick 在 grid 上的位置 segmentation mask,以及 binary button states。作者发现 joystick 用 segmentation mask 明显优于直接回归坐标。

Figure 3 解读:数据分布图显示 NitroGen 覆盖大量游戏与 genre,但也能看出偏向 action/gamepad-friendly games。这个分布直接影响 transfer:常见 3D action-RPG 技能迁移更好,而少见的等距 roguelike 或 game-specific mechanics 收益较小。
3.2 Benchmark and universal simulator
评测 suite 覆盖 10 个 commercial games、30 tasks:11 个 combat tasks、10 个 navigation tasks、9 个 game-specific tasks。每个 task 有明确 start/goal states,attempt 通常持续几分钟,人类有些任务可能需要数小时反复尝试。论文选择 initial visual state 足以触发正确行为的任务,把 language-conditioned specification 留给未来工作。

Figure 4 解读:rollout 图展示 NitroGen 在 2D/3D、固定布局/程序生成环境中的行为片段。论文想说明:即使数据来自 noisy internet videos,单个模型仍能在不同视觉风格和机制下完成非平凡行为;但这些仍是短上下文 fast-reacting tasks,不等同于长程战略规划。
3.3 Foundation model architecture
NitroGen 使用 flow matching 生成 future action chunks。RGB 输入 ,由 SigLIP 2 ViT 编码,每帧产生 256 image tokens。动作生成器是 DiT:noisy action chunks 先经 MLP 编成每个 timestep 一个 action token,然后经过交替 self-attention / cross-attention 的 DiT blocks;cross-attention 让 action tokens 条件化于 frame tokens;最后 MLP 独立解码每个时间步的 continuous action vectors。
论文的设计选择很克制:虽然模型可以 condition on multiple frames,但作者发现多帧没有明显收益,因此使用 single context frame;模型生成 16-action chunks。released README 也明确当前模型是 500M parameter DiT,只能看 last frame,是 fast-reacting system-1 sensory model,不具备长程规划、自我改进或完全 unseen game 的能力。
3.4 Flow matching objective
给定 ground-truth action chunk 、observation 、flow timestep 、Gaussian noise ,论文构造:
条件速度场为:
Conditional Flow Matching loss:
其中 是 DiT, 是 image encoder。论文采用 shifted beta distribution 采样 ,偏向 small timesteps。推理时初始化 ,用 Euler integration 迭代 denoise;作者使用 denoising steps,因为更多 step 没有可测收益:
3.5 Pseudocode (based on paper + released inference code)
论文公式与 released code 实现差异:released GitHub repo 主要包含 inference/server/play code,不包含论文中的 dataset extraction、training loop、DiT training config;因此训练伪代码依据论文公式,推理伪代码依据 nitrogen/inference_session.py。README 说明当前 500M 模型“can only see the last frame”,而 code 中 InferenceSession 仍通过 checkpoint config 支持 context_length / frame_per_sample buffer;实际上下文长度由 checkpoint 配置决定。
import cv2
import torch
def parse_gamepad_overlay(video, templates, segformer, min_inliers=20):
"""Paper-level action extraction pipeline; training code is not in released repo."""
sampled_frames = sample_25_frames(video)
best_crop = None
best_score = -1
for frame in sampled_frames:
for template in templates: # about 300 controller templates
keypoints = match_sift_and_xfeat(frame, template)
affine, inliers = estimate_affine(keypoints)
if inliers >= min_inliers and inliers > best_score:
best_score = inliers
best_crop = crop_with_affine(frame, affine)
actions = []
prev_crop = None
for crop in stream_gamepad_crops(video, best_crop):
pair = concatenate_two_frames(prev_crop or crop, crop)
seg_mask, button_logits = segformer(pair)
joystick = decode_11x11_grid(seg_mask)
buttons = (button_logits.sigmoid() > 0.5).float()
actions.append(to_unified_gamepad_vector(joystick, buttons))
prev_crop = crop
return torch.stack(actions)import torch
def nitrogen_cfm_train_step(policy_dit, image_encoder, obs, action_chunk):
"""Paper formula: a in R^{16 x 24}, obs at 256 x 256."""
eps = torch.randn_like(action_chunk)
t = sample_shifted_beta(action_chunk.shape[0]).to(action_chunk.device)
a_t = (1.0 - t[:, None, None]) * eps + t[:, None, None] * action_chunk
target_velocity = action_chunk - eps
image_tokens = image_encoder(obs) # SigLIP 2, 256 image tokens per frame
pred_velocity = policy_dit(a_t, image_tokens, t)
return ((pred_velocity - target_velocity) ** 2).mean()import torch
from collections import deque
@torch.no_grad()
def nitrogen_inference_session_step(session, obs):
"""Mirrors nitrogen/inference_session.py: buffer frames/actions, choose FM or AR path."""
current_frame = session.img_proc([obs], return_tensors="pt")["pixel_values"]
session.obs_buffer.append(current_frame)
pixel_values = torch.cat(list(session.obs_buffer), dim=0)
if session.action_buffer:
action_tensors = {k: torch.cat([a[k] for a in session.action_buffer], dim=0)
for k in session.action_buffer[0]}
else:
action_tensors = session.zero_action_context()
if session.modality_config.action_interleaving:
predicted = session._predict_ar(pixel_values, action_tensors)
else:
predicted = session._predict_flowmatching(pixel_values, action_tensors)
session.action_buffer.append(predicted)
return convert_model_actions_to_gamepad_events(predicted)Code reference:
main@32608444(2026-01-25) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Checkpoint/model loading | nitrogen/inference_session.py | load_model, InferenceSession.from_ckpt |
| Frame/action buffers | nitrogen/inference_session.py | InferenceSession.__init__, reset, predict |
| Flow-matching inference path | nitrogen/inference_session.py | _predict_flowmatching |
| Model server | scripts/serve.py | InferenceSession.from_ckpt, socket request loop |
| Game interaction wrapper | scripts/play.py | GamepadEnv, action conversion, policy.predict(obs) |
| Client API | nitrogen/inference_client.py | ModelClient.predict, reset, info |
| Released training/data code status | repository root | training/action-extraction code not present in this commit |
4. Experimental Setup (实验设置)
Datasets
- Raw videos:71,000 hours publicly available gameplay videos with gamepad overlays collected before filtering.
- NitroGen dataset:40,000 hours gameplay videos across 1,000+ games;论文进一步报告 38,739 hours effective gameplay,846 games 有超过 1 hour 数据。
- Action parsing benchmark:作者用 OBS 录制 6 个游戏,并随机化 opacity、gamepad size、gamepad type;ground-truth controller inputs 每帧记录,用于评估 action extraction。
- Evaluation suite:10 commercial games、30 tasks;11 combat、10 navigation、9 game-specific;每个游戏/任务类型按 3 tasks、每 task 5 rollouts 评估 task completion。
Baselines
主要对比不是固定公开模型排行榜,而是:pre-trained NitroGen vs identical architecture trained from scratch。Post-training 实验中,作者在 held-out game 上 fine-tune NitroGen checkpoint,并用相同 architecture、相同数据和 compute budget 的 scratch model 对比。
Metrics
- Task completion rate (%):人类评估的任务完成率;Figure 6 每个 game/type 使用 3 tasks × 5 rollouts。
- Joystick :预测 joystick 坐标与 ground truth 的相关评分,左右 joystick 平均。
- Button frame accuracy:逐帧 button state accuracy。
- Relative improvement (%):fine-tuned NitroGen 相对 scratch model 的 task-completion rate 提升。
Training config
论文报告的训练设置:
- Model:500M parameter DiT,SigLIP 2 vision transformer,RGB ,每帧 256 image tokens,single context frame,16-action chunks,action vector 。
- Optimization:AdamW,weight decay 0.001,WSD schedule,constant learning rate phase 0.0001,EMA decay 0.9999;所有结果使用 EMA weights。
- Augmentations:random brightness / contrast / saturation / hue,random rotation ,random crops。
- Inference:Euler denoising, denoising steps。
Released code config anchor:repo 当前没有训练 launch config;README.md 给出 inference usage:python scripts/serve.py <path_to_ng.pt> 启动 server,python scripts/play.py --process '<game_executable_name>.exe' 连接 Windows game;checkpoint 从 HuggingFace nvidia/NitroGen 下载为 ng.pt。
5. Experimental Results (实验结果)
Action extraction quality

Figure 5 解读:controller parsing benchmark 上,joystick position 的 overall average ,button frame accuracy 的 overall average 为 0.96。图中不同 controller family(Xbox/PlayStation 等)有差异,但总体说明自动抽取的 action labels 足以支撑大规模 noisy behavior cloning。
Zero-shot / pre-training performance

Figure 6 解读:NitroGen 500M 在未针对具体游戏 fine-tune 的情况下,在 3D、2D top-down、2D side-scrolling 多种视觉风格上取得非平凡 task completion。图中文字可读出的主要完成率包括 61.2%、61.5%、55.0%、56.3%、52.0%、54.0%、46.0%、44.8%、37.9%。论文强调这些任务中既有可能被记忆的固定布局,也有 procedurally generated、每次 playthrough 不同的任务,而模型在两类中没有显著差异。
Transfer / post-training

Figure 7 解读:held-out game fine-tuning 显示 pre-training 能提高下游 sample efficiency。varying data quantity 的 isometric roguelike 中,fine-tuning 平均相对提升 10%;3D action-RPG 平均相对提升 25%。在 30h low-data regime 中,combat task 提升 52%,navigation 提升 25%,game-specific task 仅提升 5%。这说明 NitroGen 学到的是 common gameplay patterns,对罕见、游戏专属机制的迁移较弱。
Main findings
- 数据可扩展性:从 overlay videos 自动抽取动作标签可行,40,000 小时/1,000+ games 的规模明显超过人工演示路线。
- 模型能力:单个 500M vision-action policy 在多 genre 上能完成非平凡任务,但仍是 short-context sensory model。
- 迁移性:pre-training 对 common skills(combat、navigation)更有帮助,对 game-specific mechanics 收益小。
- 开源边界:论文释放 dataset、evaluation suite、model weights;GitHub 当前主要提供 inference/server/play pipeline,未包含训练与数据抽取完整实现。
Limitations
作者明确指出 NitroGen 不能长程规划、不能 follow language instructions,只能对短上下文做快速反应;它也不能自我改进或端到端玩完全 unseen game。数据分布偏向 action games 和 gamepad-friendly games,keyboard-only、strategy、simulation、复杂操作类游戏代表性不足。因此 NitroGen 更适合作为未来 language following / RL post-training 的 foundation,而不是完整通用游戏智能体。