GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Authors: Lloyd Russell*, Anthony Hu*, Lorenzo Bertoni*, George Fedoseev*, Jamie Shotton, Elahe Arani, Gianluca Corrado* Affiliations: Wayve (英国自动驾驶公司) Year: 2025 Code: 未开源 (截至2026年3月)
1. Motivation (研究动机)
1.1 现有方法的问题
自动驾驶的训练和评估依赖大规模真实驾驶数据,但现有视频生成模型存在以下不足:
- 缺乏结构化控制: 通用视频生成模型(如 Sora、Stable Video Diffusion)主要关注视觉美学,不支持对自车动作、动态 agent、道路语义等自动驾驶关键要素的细粒度控制
- 不支持多相机一致性: 自动驾驶车辆需要多摄像头环视输入(通常 5-6 个摄像头),现有模型大多只支持单视角生成,无法保证多视角时空一致性
- 功能碎片化: 不同的条件控制类型(如 ego action、agent bbox、天气、国家等)分散在不同模型中,缺乏统一的生成框架
- 难以生成边缘场景: 真实数据中安全关键的 edge case(如紧急制动、逆行)极为稀少,现有方法难以可控地合成这些场景
1.2 核心洞察
将连续 latent 空间 + flow matching + 丰富的结构化条件统一到一个 latent diffusion 框架中,可以同时实现:
- 多相机环视视频的时空一致生成(最多 5 个摄像头, 分辨率)
- 通过 ego action、3D bbox、metadata、CLIP embedding、scenario embedding 等多种条件实现细粒度控制
- 从零生成、自回归续写、inpainting、场景编辑等多种推理模式
2. Idea (核心思想)
GAIA-2 的核心思想是构建一个领域专用的 latent diffusion world model,统一自动驾驶仿真所需的全部能力:
- 高压缩率 Video Tokenizer: 使用 空间 + 时间压缩(相比典型的 ),latent 维度提升到 64 通道,以更少的 token 保留更丰富的语义信息,总压缩率约 400 倍
- Flow Matching 训练: 在连续 latent 空间中使用 flow matching 替代 DDPM,提升训练稳定性和采样效率
- 多层次条件注入: 对不同类型的条件信号采用不同的注入方式 — adaptive layer norm(ego action)、cross-attention(agent bbox、metadata、embedding)、加法注入(camera 参数、timestamp)
- 统一多任务训练: 70% from-scratch 生成 + 20% context prediction + 10% spatial inpainting,使同一模型支持多种推理模式
3. Method (方法)
3.1 整体架构
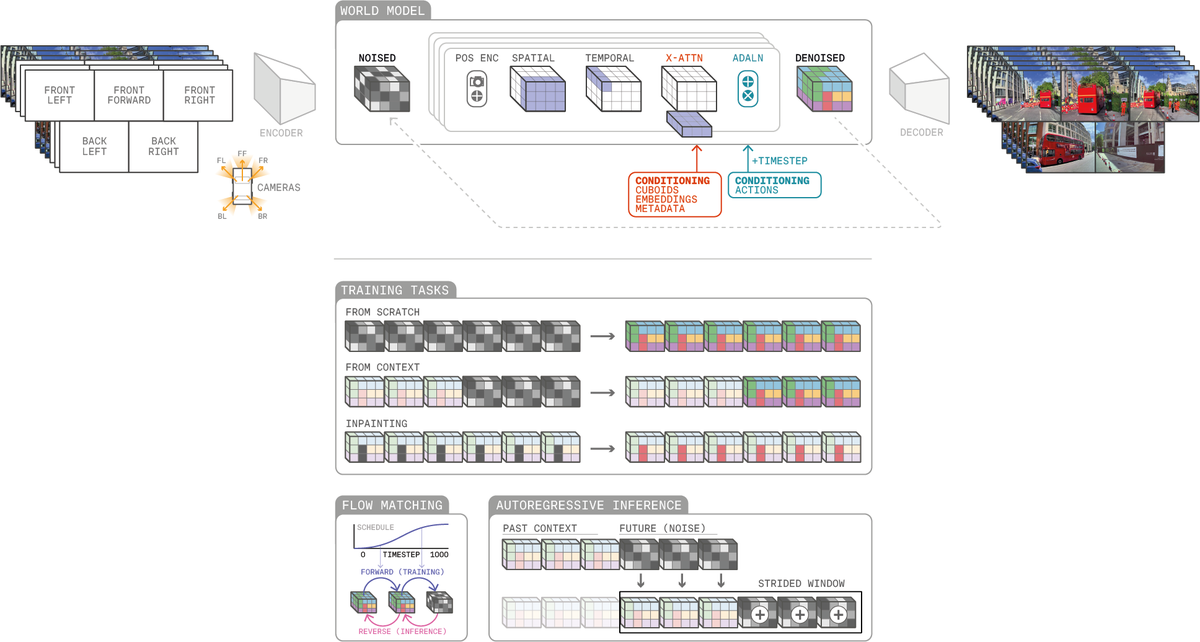
Figure 2 解读:GAIA-2 的整体架构示意图。系统由两个核心模块组成:Video Tokenizer(将多相机视频编码到连续 latent 空间)和 Latent World Model(在 latent 空间中进行条件生成)。多相机视频帧分别独立编码为 latent token,合并后加入 camera 参数和位置编码,送入 space-time factorized transformer。条件信号(actions、3D bbox、metadata、scenario embedding)通过 cross-attention 和 adaptive layer norm 注入。训练支持三种任务:from scratch(纯噪声生成)、from context(自回归预测)、inpainting(空间修复)。推理时通过 overlapping strides 的滑动窗口实现长视频自回归生成。
3.2 Video Tokenizer
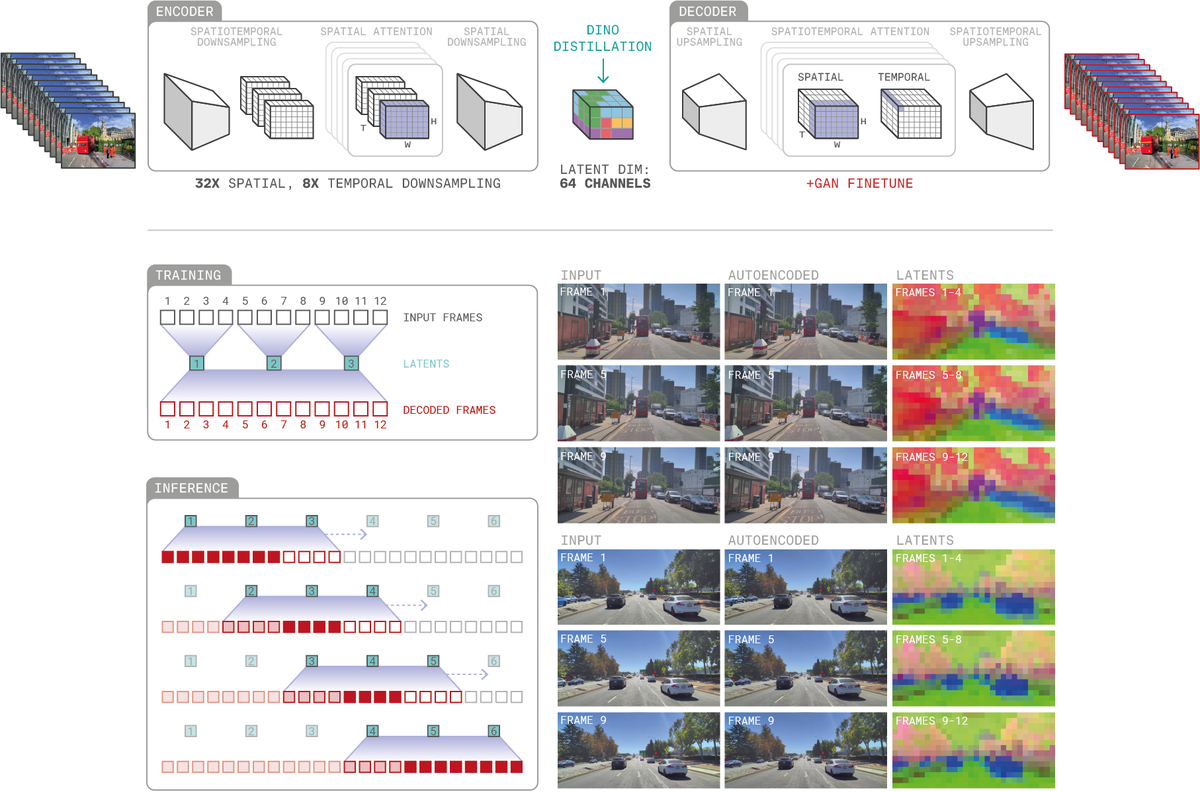
Figure 3 解读:Video Tokenizer 的编解码架构。编码器将输入帧进行时空下采样( 空间, 时间),每帧独立编码,输出 64 通道的 latent 表示。解码器利用完整的时空注意力从 latent 恢复视频帧,保证时间一致性。右侧展示了 latent space 的可视化(PCA 前3主成分映射为 RGB),可以看到 latent 空间在帧间和样本间语义稳定。底部展示了滚动推理机制:对长序列,使用过去和未来 context 的滑动窗口解码,确保时间一致性。
3.2.1 Encoder 架构
给定输入视频 ,编码器 计算 latent token :
- 输入:
- 输出: ,latent 维度
- 总压缩率:
编码器结构:
- 下采样卷积块:stride (时间、高度、宽度),后接 stride 的卷积块,embedding dim = 512
- 24 层 spatial transformer blocks,dim = 512,16 heads
- 最终卷积 stride ,输出 通道(mean + std of Gaussian distribution)
3.2.2 Decoder 架构
- 线性投影 + 上采样卷积(stride ,depth-to-space)
- 16 层 space-time factorized transformer blocks,dim = 512,16 heads
- 上采样卷积(stride )+ 8 层 space-time transformer blocks
- 最终上采样卷积(stride ),输出 3 通道 RGB
关键区别: 编码器独立处理每帧(),解码器联合解码 个 temporal latent 为 帧视频,确保时间一致性。编码器 85M 参数,解码器 200M 参数。
3.2.3 训练损失
- DINO v2 (Large) 蒸馏: 在 latent 空间施加 cosine similarity loss,鼓励语义对齐,权重 0.1
- KL 散度: 正则化 latent 分布趋向标准正态,极小权重
- GAN 微调: 冻结编码器,使用 3D 卷积判别器(base channel 64, stride 2 in time, channel multipliers [2, 4, 8, 8], spectral norm, LeakyReLU 0.2)微调解码器 20,000 步,GAN loss 权重 0.1
Video Tokenizer 伪代码
class GAIA2_VideoTokenizer:
"""Video Tokenizer: 32x spatial, 8x temporal compression, 64-dim latent"""
def __init__(self):
# Encoder: 85M params
self.enc_conv1 = Conv3d(3, 512, stride=(2,8,8)) # temporal 2x, spatial 8x
self.enc_conv2 = Conv3d(512, 512, stride=(2,2,2)) # temporal 2x, spatial 2x
self.enc_transformers = [SpatialTransformer(512, heads=16) for _ in range(24)]
self.enc_proj = Conv3d(512, 128, stride=(1,2,2)) # -> 2L channels (mean+std)
# Decoder: 200M params
self.dec_proj = Linear(64, 512)
self.dec_up1 = UpsampleConv(512, 512, stride=(1,2,2)) # depth-to-space
self.dec_st_blocks1 = [STTransformer(512, heads=16) for _ in range(16)]
self.dec_up2 = UpsampleConv(512, 512, stride=(2,2,2))
self.dec_st_blocks2 = [STTransformer(512, heads=16) for _ in range(8)]
self.dec_up3 = UpsampleConv(512, 3, stride=(2,8,8)) # -> RGB
def encode(self, video):
"""video: [B, 24, 3, 448, 960] -> latent: [B, 3, 64, 14, 30]"""
x = self.enc_conv1(video) # [B, 12, 512, 56, 120]
x = self.enc_conv2(x) # [B, 6, 512, 28, 60]
for block in self.enc_transformers:
x = block(x) # spatial-only attention
params = self.enc_proj(x) # [B, 3, 128, 14, 30]
mean, log_std = params.chunk(2, dim=2) # each [B, 3, 64, 14, 30]
z = mean + torch.randn_like(mean) * log_std.exp()
return z
def decode(self, z, context_window=None):
"""z: [B, 3, 64, 14, 30] -> video: [B, 24, 3, 448, 960]"""
x = self.dec_proj(z)
x = self.dec_up1(x)
for block in self.dec_st_blocks1:
x = block(x) # full spatiotemporal attention
x = self.dec_up2(x)
for block in self.dec_st_blocks2:
x = block(x)
video = self.dec_up3(x)
return video3.3 Latent World Model
World model 是一个 8.4B 参数的 space-time factorized transformer,使用 flow matching 训练。
3.3.1 架构
- 输入 latent: , = temporal window, = 相机数
- 22 层 space-time factorized transformer blocks,hidden dim ,32 heads
- 每个 transformer block 包含:
- Spatial attention(over space and cameras)
- Temporal attention
- Cross-attention(条件注入)
- MLP + Adaptive layer norm
- Query-key normalization 稳定训练
3.3.2 Flow Matching 训练
Flow matching 在连续 latent 空间中线性插值 target latent 和 noise:
速度目标(velocity target):
模型预测:
训练损失:
其中 为 context 帧数( 对应 from scratch 生成), 为 flow matching 时间步。
3.3.3 Flow Matching 时间分布
使用双峰 logit-normal 分布采样 :
| 模式 | 均值 | 标准差 | 概率 | 作用 |
|---|---|---|---|---|
| 主模式 | 0.5 | 1.4 | 0.8 | 偏向中低噪声,学习有效梯度 |
| 次模式 | -3.0 | 1.0 | 0.2 | 集中在 (近纯噪声),学习空间结构和低级动态 |
3.3.4 Latent 归一化
输入 latent 使用固定的 mean 和 std (从 tokenizer 训练中经验确定)进行归一化,确保信号与噪声的尺度匹配。
3.4 条件注入机制
GAIA-2 支持丰富的结构化条件,采用不同的注入方式:
| 条件类型 | 注入方式 | 说明 |
|---|---|---|
| Ego Action (speed, curvature) | Adaptive Layer Norm | 影响每个 spatial token,提供全局动态控制 |
| Flow matching time | Adaptive Layer Norm | 与 action 一起注入 |
| 3D Bounding Boxes | Cross-Attention | 动态 agent 的位置、方向、尺寸、类别 |
| Metadata(国家、天气等) | Cross-Attention | 场景级分类特征 |
| CLIP Embedding | Cross-Attention | 语义场景控制,支持零样本文本条件 |
| Scenario Embedding | Cross-Attention | 来自内部驾驶模型的场景表示 |
| Camera 参数 | 加法注入 | 内外参、畸变,加到每个 transformer block 开头 |
| Timestamp | 加法注入 | Fourier 特征编码 + MLP |
Action 归一化 — Symlog 变换
由于速度和曲率量级差异大,使用对称对数变换:
- 曲率: 单位 ,范围 0.0001~0.1,
- 速度: 单位 m/s,范围 0~75,(转为 km/h)
- 输出归一化到
3D Bounding Box 条件
- 3D bbox 由重新训练的 3D 检测器预测,编码位置、朝向、尺寸、类别
- 投影到 2D 图像平面并归一化,得到
- 每个特征维度独立通过单层 MLP 嵌入并聚合
- 特征维度 dropout :可以省略部分条件(如只给 2D 位置不给 3D)
- 实例级 dropout: 随机采样条件化的 agent 数量
Classifier-Free Guidance
- 默认不使用 CFG
- 对 edge case 或 OOD 场景,使用 CFG guidance scale 2~20
- 空间选择性 CFG: 对 agent conditioning,仅在 3D bbox 对应的 latent token 上施加 guidance,不影响场景其他部分
World Model 伪代码
class GAIA2_WorldModel:
"""8.4B Latent World Model with Flow Matching"""
def __init__(self):
self.C = 4096 # hidden dimension
self.num_blocks = 22
self.num_heads = 32
# Positional encodings
self.spatial_pos_enc = SinusoidalEmbedding()
self.temporal_pos_enc = SinusoidalEmbedding() + MLP()
self.camera_enc = CameraEncoder() # intrinsic + extrinsic + distortion
# Conditioning encoders
self.action_enc = Linear(2, self.C) # speed + curvature (after symlog)
self.tau_enc = SinusoidalEmbedding(self.C)
self.bbox_enc = BBoxEncoder(in_dim=13, out_dim=self.C)
self.metadata_enc = CategoricalEmbeddings(self.C)
self.clip_proj = Linear(clip_dim, self.C)
self.scenario_proj = Linear(scenario_dim, self.C)
# Transformer blocks
self.blocks = nn.ModuleList([
SpaceTimeFactorizedBlock(
dim=self.C,
heads=self.num_heads,
has_spatial_attn=True,
has_temporal_attn=True,
has_cross_attn=True,
has_adaptive_ln=True,
qk_norm=True, # query-key normalization
) for _ in range(self.num_blocks)
])
def forward(self, x_tau, x_context, actions, conditions, tau):
"""
x_tau: noised future latents [B, T_future, N, H, W, L]
x_context: clean past latents [B, T_context, N, H, W, L]
actions: [B, T, 2] (speed, curvature after symlog)
conditions: dict of structured conditions
tau: flow matching time [B]
"""
# Concatenate context and noised future
x = concat([x_context, x_tau], dim=1) # [B, T, N, H, W, L]
# Project to hidden dim and add positional encodings
x = self.input_proj(x) # [B, T, N, H, W, C]
# Encode conditioning for adaptive layer norm
action_emb = self.action_enc(actions) # [B, T, C]
tau_emb = self.tau_enc(tau) # [B, C]
adaln_cond = action_emb + tau_emb # broadcast over T
# Encode conditioning for cross-attention
bbox_tokens = self.bbox_enc(conditions['bboxes']) # [B, T, N, B, C]
meta_tokens = self.metadata_enc(conditions['metadata'])# [B, K, C]
clip_tokens = self.clip_proj(conditions['clip']) # [B, K2, C]
cross_attn_tokens = concat_all_condition_tokens(...)
for block in self.blocks:
# Add camera + timestamp positional encodings
x = x + self.camera_enc(conditions['cameras'])
x = x + self.temporal_pos_enc(conditions['timestamps'])
x = x + self.spatial_pos_enc(positions)
# Space-time factorized transformer
x = block.qk_norm_spatial_attn(x) # attend over (N, H, W)
x = block.qk_norm_temporal_attn(x) # attend over T
x = block.cross_attn(x, cross_attn_tokens)
x = block.adaptive_ln_mlp(x, adaln_cond) # adaptive layer norm
v_hat = self.output_proj(x[:, T_context:]) # predicted velocity
return v_hat
def sample(self, x_context, actions, conditions, num_steps=50):
"""Inference: denoise from pure noise using linear-quadratic schedule"""
x = torch.randn_like(future_shape) # pure Gaussian noise
# Linear-quadratic noise schedule: linear early, quadratic late
taus = linear_quadratic_schedule(num_steps)
for tau_curr, tau_next in zip(taus[:-1], taus[1:]):
v_hat = self.forward(x, x_context, actions, conditions, tau_curr)
x = x + (tau_next - tau_curr) * v_hat # Euler step
return x # denoised future latents3.5 训练任务分布
| 任务 | 比例 | 说明 |
|---|---|---|
| From scratch | 70% | , context 帧数为 0,从纯噪声生成 |
| Context prediction | 20% | ,给定过去帧预测未来 |
| Spatial inpainting | 10% | 对部分空间区域 mask 后重新生成 |
为实现 classifier-free guidance,每个条件变量独立以 80% 概率 drop,所有条件同时以 10% 概率 drop。输入 camera view 以 10% 概率 drop。
3.6 推理模式

Figure 1 解读:GAIA-2 from scratch 生成的多样性展示。每行是一个独立生成的驾驶场景,展示 5 个摄像头视角(BACK LEFT, FRONT LEFT, FRONT FORWARD, FRONT RIGHT, BACK RIGHT)。场景涵盖不同国家(英国、美国、德国)、不同天气(晴天、雨天、夜晚、日落)、不同道路类型(城市、郊区、高速)。
四种推理模式:
- Generation from scratch: 从纯 Gaussian noise 出发,通过条件变量引导去噪,生成完整驾驶视频
- Autoregressive prediction: 给定 个 temporal latent 作为 context,预测下一组 latent,通过滑动窗口实现长视频 rollout
- Inpainting: 对 latent 施加 spatial-temporal mask,通过条件去噪重新生成 masked 区域(如在场景中插入 agent)
- Scene editing: 对真实视频的 latent 部分加噪后,用修改后的条件去噪,实现天气/时间/道路布局等变换
推理使用 50 步去噪,采用 linear-quadratic noise schedule(前期线性捕捉粗结构,后期二次方细化高频细节)。
3.7 数据增强与场景编辑

Figure 6 解读:Partial noise-and-denoise 场景编辑。将真实驾驶视频编码为 latent,添加部分噪声后用修改的条件(如不同天气、时间)重新去噪。保留了原始的语义内容和自车运动,但视觉外观发生变化 — 同一轨迹可以在晴天、雨天、日落、夜间、下雪等多种环境下生成变体。

Figure 4 解读:CLIP 文本条件生成。通过 CLIP text encoder 将自然语言描述(如 “A BUSY ROAD THROUGH A CITY AT TWILIGHT, LOTS OF CARS”、“AN OPEN STRAIGHT ROAD THROUGH THE SANDY DESERT” 等)编码后作为条件,GAIA-2 可以生成对应语义的驾驶场景。展示了城市、沙漠、森林、山区、海滨 5 种不同环境,实现零样本语义控制。
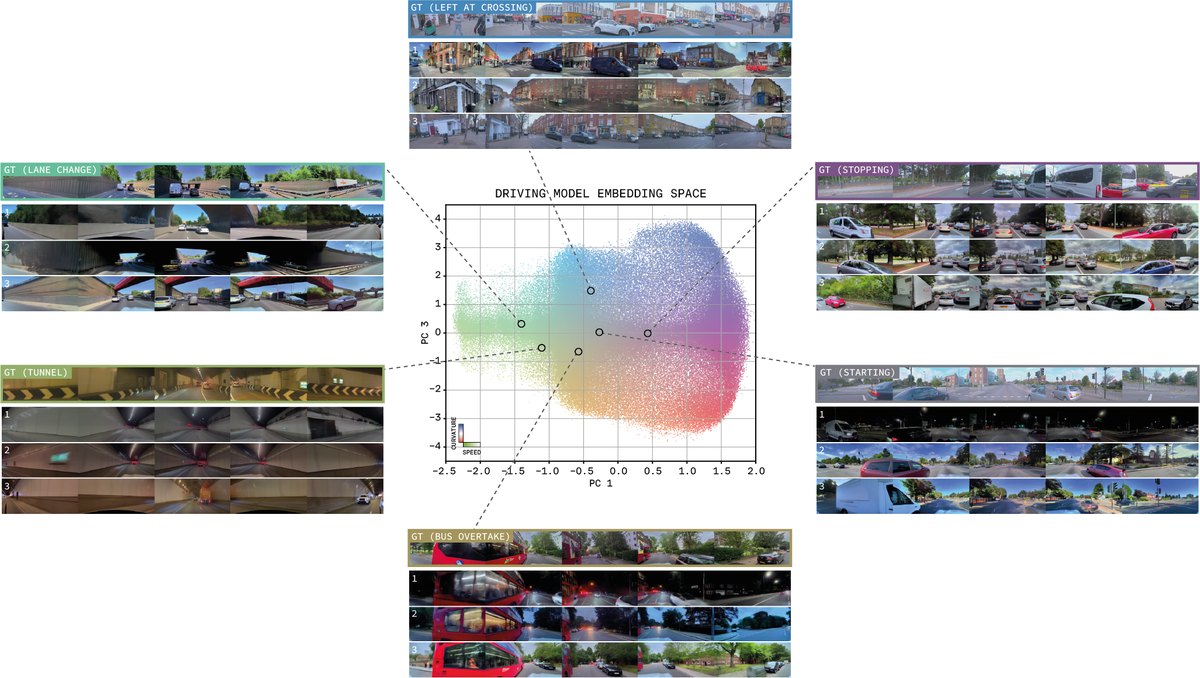
Figure 7 解读:Scenario embedding 条件生成。中间是驾驶模型 embedding 空间的 2D 可视化,不同区域对应不同驾驶语义(变道、刹车、超车等)。顶行是真实数据(embedding 来源),下方三行是以该 embedding 为条件生成的合成变体。通过在 embedding 空间中选择不同位置,可以可控地生成加速、减速、超车等特定驾驶行为。

Figure 8 解读:基于 action(speed + curvature)的从零生成。三个示例:(1) “start from stopped” — 从静止加速,模型生成了红灯变绿的场景;(2) “slow to a stop” — 减速停车,模型生成了跟在出租车后方减速的场景;(3) “U-turn” — 大曲率低速转弯,模型生成了 U 型掉头场景。每个场景展示 5 个摄像头视角在多个时间步的输出。

Figure 5 解读:多平台多 camera rig 支持。GAIA-2 通过 camera 参数条件化,支持不同车辆平台(运动型轿车、SUV、大型货车)的不同摄像头配置,生成在空间和时间上一致的环视视频。
3.8 安全关键场景生成

Figure 9 解读:自车诱导的安全关键场景。给定真实视频帧作为 context,施加”不安全”的 action 条件(如驶向对面车道的曲率),GAIA-2 自回归生成后续帧。模型生成了自车偏入对向车道、对向车辆闪避的逼真场景,可用于测试自动驾驶系统的安全边界。

Figure 11 解读:他车诱导的安全关键场景。通过 3D bounding box 精确控制其他 agent 的位置和运动,生成紧急制动、超车、闯入路口等危险场景,用于测试自动驾驶的反应能力。

Figure 12 解读:Agent inpainting 能力。上方为原始场景,下方展示通过 spatial-temporal mask + 3D bbox conditioning,在同一场景中分别插入自行车手、汽车、卡车、公交车。背景保持一致,插入的 agent 在语义和视觉上自然融入场景。

Figure 10 解读:极端泛化能力。当条件为高速 + 大曲率(超出正常驾驶分布)时,GAIA-2 外推生成了偏离道路的轨迹(如驶入田野、森林),展示了模型对 OOD 条件的合理泛化。
4. Experimental Setup (实验设置)
4.1 数据集
| 属性 | 值 |
|---|---|
| 视频总量 | ~2500万段 2秒视频序列 |
| 采集时间 | 2019-2024年 |
| 采集国家 | 英国、美国、德国 |
| 车辆平台 | 3种轿车 + 2种货车 |
| 摄像头数 | 5或6个(360度环视) |
| 采集帧率 | 20 / 25 / 30 Hz |
| 验证策略 | 地理围栏(排除特定区域),确保在未见位置评估 |
| 数据平衡 | 对特征联合分布进行平衡,非仅单独特征 |
4.2 Video Tokenizer 训练
| 参数 | 值 |
|---|---|
| 训练步数 | 300,000 步 |
| GPU | 128 × H100 |
| Batch size | 128 |
| 输入 | 帧,随机裁剪 |
| 优化器 | AdamW, lr , betas [0.9, 0.95], weight decay 0.1 |
| 学习率调度 | 2,500 warmup + 5,000 cooldown, 最终 lr |
| 梯度裁剪 | 1.0 |
| EMA | decay 0.9999 |
| GAN 微调 | 额外 20,000 步,lr |
4.3 World Model 训练
| 参数 | 值 |
|---|---|
| 模型参数 | 8.4B |
| 训练步数 | 460,000 步 |
| GPU | 256 × H100 |
| Batch size | 256 |
| 输入 | 48 帧 (原始帧率), 5 cameras, |
| Latent token 数 | |
| 优化器 | AdamW, lr , betas [0.9, 0.99], weight decay 0.1 |
| 学习率调度 | 2,500 warmup, cosine decay 至 |
| 梯度裁剪 | 1.0 |
| EMA | decay 0.9999 |
| 训练任务分布 | 70% from-scratch / 20% context / 10% inpainting |
| 条件 dropout | 单独 80% / 全部 10% |
| Camera view dropout | 10% |
4.4 评估指标
| 指标 | 说明 |
|---|---|
| FDD (Frechet DINO Distance) | DINOv2 ViT-L/14 特征,输入分辨率 ,衡量视觉保真度 |
| FID (Frechet Inception Distance) | InceptionV3 特征,输入分辨率 |
| FVMD (Frechet Video Motion Distance) | 关键点运动特征分布距离,衡量时间一致性 |
| Dynamic Agent IoU | 3D bbox 投影 vs OneFormer 分割 mask 的 class-based IoU |
| 评估样本数 | ,from scratch 任务 |
5. Experimental Results (实验结果)
5.1 定量结果
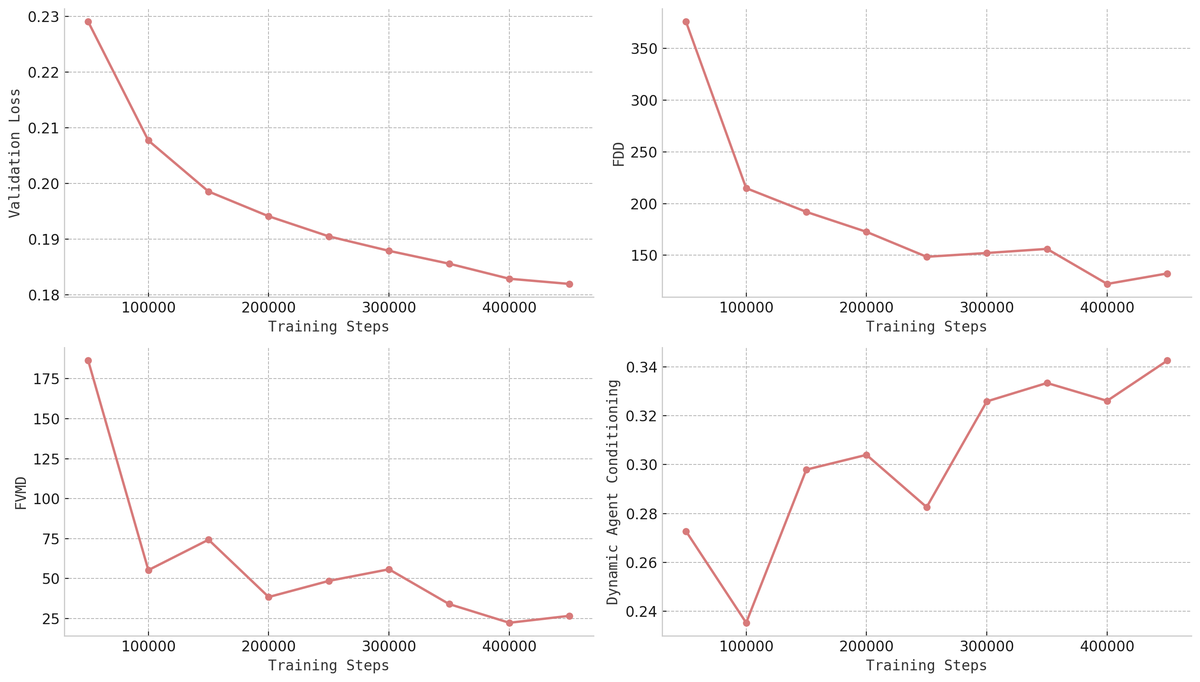
Figure 13 解读:训练过程中四个指标随步数的变化趋势(在 1024 个 from-scratch 样本上评估)。Validation Loss(左上)持续下降至约 0.18。FID(右上)从约 370 初始下降后在约 100-200 间波动。FVMD(左下)从约 175 下降至约 25,表明时间一致性显著提升。Dynamic Agent Conditioning(右下)从约 0.23 上升至约 0.34(IoU 越高表示 agent 位置与生成结果的匹配度越好),说明 agent 控制精度持续改善。validation loss 与人类感知偏好相关性最强。
5.2 关键定性发现
- 多地域高保真生成: 成功生成涵盖英国、美国、德国的高分辨率环视驾驶视频,包含不同驾驶习惯(左行/右行)
- 精确 action 控制: 给定 speed/curvature profile,模型生成语义匹配的场景(加速 → 绿灯,减速 → 前方有车,大曲率 → 转弯/掉头)
- 安全关键场景: 成功模拟自车偏离车道、对向 agent 紧急闪避等稀有场景
- 跨平台泛化: 同一模型适应不同车辆和摄像头配置
- 数据增强: 通过 partial noise-denoise 将单条真实轨迹扩展为多种天气/光照变体
- FDD 优于 FID: FDD 噪声更小,更早饱和,是更稳定的视觉质量代理指标
5.3 局限性
- 长视频或复杂场景偶尔出现时间/语义不一致
- 实时或近实时生成仍有计算瓶颈(8.4B 参数 + 50 步去噪)
- 条件控制虽丰富但仍不够精细(如更复杂的 agent 行为建模、开放式自然语言控制)
5.4 Source Code
截至 2026 年 3 月,GAIA-2 未开源代码或模型权重。该工作来自 Wayve(商业自动驾驶公司),目前仅提供论文和项目展示页面。
附录: Code-to-Paper 映射表
| 论文组件 | 代码对应 | 状态 |
|---|---|---|
| Video Tokenizer Encoder | - | 未开源 |
| Video Tokenizer Decoder | - | 未开源 |
| Space-Time Factorized Transformer | - | 未开源 |
| Flow Matching Training | - | 未开源 |
| Adaptive Layer Norm (Action) | - | 未开源 |
| Cross-Attention (Multi-condition) | - | 未开源 |
| 3D BBox Conditioning | - | 未开源 |
| Symlog Normalization | - | 未开源 |
| Linear-Quadratic Noise Schedule | - | 未开源 |
| Spatially Selective CFG | - | 未开源 |
注: GAIA-2 为 Wayve 公司内部项目,截至 2026 年 3 月无公开代码仓库。上述伪代码基于论文描述重建,供理解参考。