Cosmos-Predict2.5: World Simulation with Video Foundation Models for Physical AI
Affiliations: NVIDIA GitHub: nvidia-cosmos/cosmos-predict2.5, nvidia-cosmos/cosmos-transfer2.5 Year: 2025
1. Motivation (研究动机)
Physical AI 系统(具身智能体)在真实世界中训练成本高、速度慢且存在安全风险。需要一个世界模拟器 (World Simulator) 来生成高质量、多样化的视觉环境,让 Physical AI agent 能在硅基环境中安全地学习感知和控制技能。
现有问题:
- Cosmos-Predict1 (前代) 基于 EDM diffusion,使用 T5 text encoder,Text2World / Image2World / Video2World 是分离的能力
- 开源视频生成模型(Wan、CogVideoX 等)主要针对通用内容创作,在 Physical AI 领域(物体持久性、物理一致性、动作可控性)表现不足
- 闭源模型(Sora、Kling 等)无法被社区微调用于机器人、自动驾驶等下游任务
核心改进:
- 更强的数据过滤 pipeline,从 200M 原始视频中仅保留 4% 高质量片段
- 统一 Text2World / Image2World / Video2World 为单一模型
- 用 Cosmos-Reason1 (Physical AI VLM) 替换 T5 作为 text encoder,提供更丰富的文本理解
- 引入 RL-based post-training (GRPO + VideoAlign reward model)
2. Idea (核心思想)
核心思路是构建一个统一的 flow-based 视频世界基础模型,通过三阶段训练(预训练 → 领域 SFT + 模型合并 → RL 后训练)在 Physical AI 各领域达到 SOTA,并通过 control-net 衍生出 Cosmos-Transfer2.5 用于条件生成。
关键 idea:
- Flow Matching 替代 EDM:更直接的速度预测目标,训练更稳定
- Shifted logit-normal 噪声调度:将训练偏向高噪声区域,提升高分辨率生成质量
- Frame-replacement 策略:统一 Image2World 和 Video2World 的条件输入方式
- Domain-specific SFT + Model Merging:分别在各领域微调,再用 model soup 合并,兼顾通用性和专业性
- GRPO-based RL:使用 VideoAlign 多维度 reward model 进行强化学习后训练
3. Method (方法)
3.1 Flow Matching 公式
给定数据样本 ,噪声 ,时间步 (logit-normal 分布采样),插值 latent:
Ground-truth velocity:
训练目标(MSE loss):
Shifted logit-normal 调度(偏向高噪声区域):
其中 为 shift 超参数。 时无偏移, 越大越偏向高噪声。训练中随分辨率递增:256p 时 ,720p 时 。另外 5% 的训练样本从噪声分布最高 2% 区域显式采样,避免高噪声区域训练不足。
# Pseudocode: Flow Matching Training Step
def train_step(model, x, c, beta):
epsilon = torch.randn_like(x) # 采样噪声
t = torch.sigmoid(torch.randn(B)) # logit-normal 采样
t_s = beta * t / (1 + (beta - 1) * t) # shifted timestep
# 5% 的样本从 top 2% 噪声区间采样
high_noise_mask = torch.rand(B) < 0.05
t_s[high_noise_mask] = 1.0 - 0.02 * torch.rand(high_noise_mask.sum())
x_t = (1 - t_s) * x + t_s * epsilon # 插值 latent
v_t = epsilon - x # ground-truth velocity
v_pred = model(x_t, t_s, c) # 预测速度
loss = F.mse_loss(v_pred, v_t)
return loss3.2 网络架构
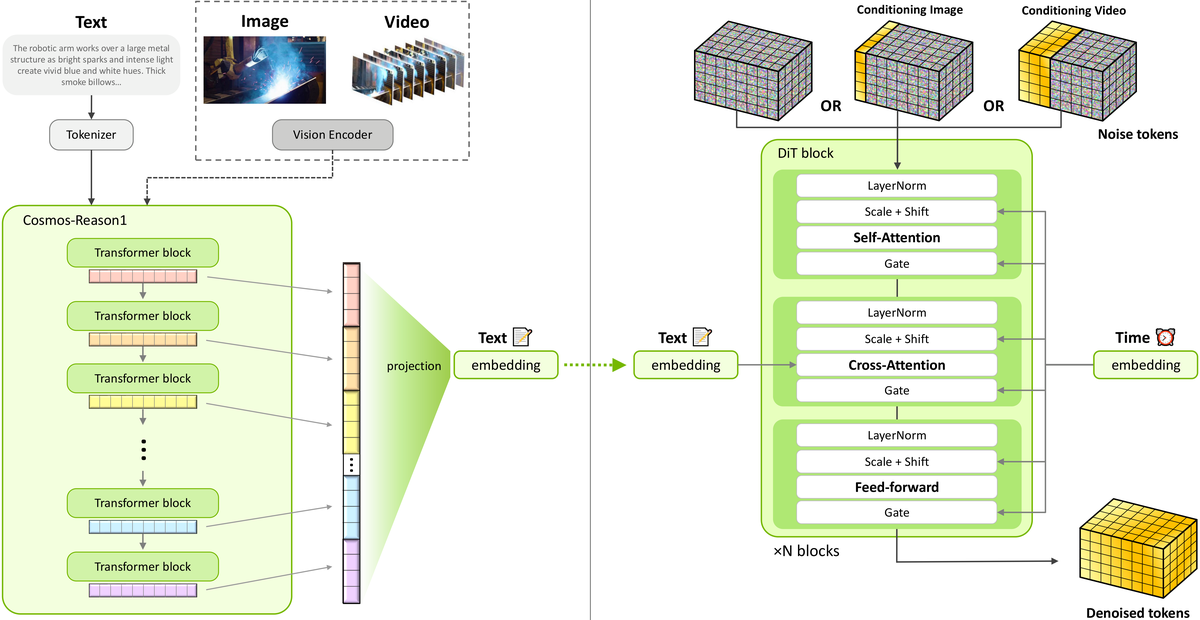
Figure 2 解读:Cosmos-Predict2.5 的整体架构。左侧为 text encoder (Cosmos-Reason1 VLM),将多层 transformer block 的 activations 拼接后投影到 1024 维空间,通过 cross-attention 注入 DiT。右侧为 DiT 主干,每个 block 包含 Self-Attention、Cross-Attention 和 Feed-forward 三个子层,均通过 Adaptive Layer Normalization (scale, shift, gate) 进行时间步 的条件调制。条件图像/视频通过 frame-replacement 策略与噪声 tokens 拼接输入。
架构细节:
| 配置 | 2B | 14B |
|---|---|---|
| Layers | 32 | 36 |
| Model Dim | 2,048 | 5,120 |
| FFN Hidden | 8,192 | 20,480 |
| AdaLN-LoRA Dim | 256 | 256 |
| Attention Heads | 16 | 40 |
| Head Dim | 128 | 128 |
| Activation | GELU | GELU |
| Positional Embedding | 3D RoPE | 3D RoPE |
关键架构改动(vs Cosmos-Predict1):
- 移除 absolute positional embeddings,仅保留 3D RoPE(相对位置编码),提升对未见分辨率/序列长度的泛化能力
- Visual Tokenizer: WAN2.1 VAE (causal VAE),压缩率 (时间 高 宽),之上再用 patchification
- Text Encoder: Cosmos-Reason1 (decoder-only VLM) 替代 T5,拼接多层 block 的 activations 投影到 1024 维
- 生成 93 帧 (24 latent frames),16 fps,约 5.8 秒视频
# Pseudocode: Frame-Replacement Conditioning (Image2World / Video2World)
def prepare_input(noise_latent, condition_frames, condition_mask):
"""
noise_latent: [B, T, C, H, W] - 全噪声 latent 序列
condition_frames: [B, K, C, H, W] - K 帧条件 (encoded ground-truth)
condition_mask: [B, T] - binary mask, 1=条件帧, 0=待生成帧
"""
# 将条件帧替换到序列对应位置
input_latent = noise_latent.clone()
input_latent[:, condition_mask] = condition_frames
# 拼接 mask token 用于标识条件/生成帧
mask_token = condition_mask.unsqueeze(-1).expand_as(input_latent)
dit_input = torch.cat([input_latent, mask_token], dim=-1)
# Denoising loss 仅作用于非条件帧
return dit_input, ~condition_mask # (input, loss_mask)3.3 数据处理 Pipeline

Figure 1 解读:视频数据处理流水线。从多域真实世界视频出发,经过 7 个阶段:(1) Shot-aware 视频分割,(2) GPU 转码,(3) 视频裁剪,(4) 多级过滤(美学/运动/OCR/感知质量/语义/VLM 过滤),(5) VLM 字幕生成(Qwen2.5-VL-7B,短/中/长三种),(6) 语义去重(embedding 聚类 + 保留高分辨率版本),(7) 分片(26 类内容分类,按类型/分辨率/宽高比/长度分片)。处理 35M 小时原始视频 → 6B 片段 → 200M 高质量训练片段(仅 4% 存活率)。
领域特定数据:5 个 Physical AI 领域
- Robotics: AgiBot(194k), Bridge(36k), DROID(39k), GR00T(3k), 1X(17k), OpenX(500), RoboMIND(16k)
- Autonomous Driving: 3.1M 20 秒 7 摄像头环视 clips
- Smart Spaces: 40K clips(工厂、仓库等)
- Human Dynamics: 人体出现 >40% 帧,1-8 人,人占画面 >3%
- Physics: 经典力学和流体力学现象(碎玻璃、滚球、流水等)
3.4 训练策略
Progressive Pre-training(渐进式预训练)
| 阶段 | 任务 | 分辨率 | 帧数 |
|---|---|---|---|
| 1 | Text2Image | 256p (320x192) | 1 |
| 2 | Text2Image + Video2World | 256p | 1 / 93 |
| 3 | Text2Image + Video2World | 480p (832x480) | 1 / 93 |
| 4 | Text2Image + Video2World | 720p (1280x704) | 1 / 93 |
| 5 | Text2Image + Video2World + Text2World | 720p | 1 / 93 / 93 |
条件帧数量:0/1/2 帧,概率分别为 0.5, 0.25, 0.25。
训练超参数:
- Optimizer: AdamW (, )
- Learning rate: (2B) / (14B)
- Weight decay: 0.001
- LR scheduler: 线性衰减 + 2000 步 warmup
- 训练硬件: 4096 NVIDIA H100 GPUs
- MFU: 36.49% (2B) / 33.08% (14B)
# Pseudocode: Progressive Pre-training Schedule
stages = [
{"task": "T2I", "res": "256p", "frames": 1, "beta": 1},
{"task": "T2I+V2W", "res": "256p", "frames": 93, "beta": 1},
{"task": "T2I+V2W", "res": "480p", "frames": 93, "beta": 3},
{"task": "T2I+V2W", "res": "720p", "frames": 93, "beta": 5},
{"task": "T2I+V2W+T2W", "res": "720p", "frames": 93, "beta": 5},
]
for stage in stages:
train_until_convergence(model, stage)
# 进入下一阶段前检查收敛和视觉质量Domain-Specific SFT + Model Merging
SFT 数据分布(InternVideo2 分类器筛选):
| 领域 | Object Permanence | High Motion | Complex Scenes | Driving | Robotic Manipulation | 4K |
|---|---|---|---|---|---|---|
| 数据量 | 10.4M | 1.0M | 1.6M | 3.1M | 730K | 388K |
每个领域独立微调 30K iterations,batch size 256。然后用 Model Soup 合并(grid search 超参数,>20 个候选模型),另加 4K 数据 cooldown 阶段。

Figure 3 解读:Domain-specific SFT 在各领域均显著超越预训练模型的 human preference win rate。Object Permanence 领域 SFT win rate 50.9%,Robotic Manipulation 领域 SFT win rate 高达 72.6%。

Figure 4 解读:Model Merging(Model Soup 方法)在所有领域和通用任务上取得最佳平衡。Radar chart 显示 Model Soup(绿色)在 6 个维度上均优于或接近 Base Model(红色),证明合并策略能”取各家之长”。
Reinforcement Learning Post-training
使用 VideoAlign reward model(VLM-based,评估 text alignment / motion quality / visual quality 三个维度),采用 GRPO 算法:
# Pseudocode: GRPO-based RL Post-training
def rl_post_train(model, prompts, reward_fn, steps=256):
for step in range(steps):
for prompt in sample_batch(prompts, batch_size=32):
# 生成 8 个候选(20 diffusion steps each)
outputs = [model.generate(prompt, steps=20) for _ in range(8)]
rewards = [reward_fn(out, prompt) for out in outputs] # VideoAlign
# GRPO: 组内归一化 reward 计算 advantage
mean_r, std_r = mean(rewards), std(rewards)
advantages = [(r - mean_r) / std_r for r in rewards]
# 将去噪轨迹视为 state-action 序列
# 分解轨迹概率为条件概率之和
# 每 2 步计算一次梯度,累积 10 步后更新(GPU 显存限制)
for i in range(0, 20, 2):
grad = compute_policy_gradient(outputs, advantages, step_range=(i, i+2))
accumulate_gradient(grad)
optimizer.step()
# 使用 diffusion loss 作为正则化,防止 reward hacking
reg_loss = diffusion_loss(model, sft_data)
optimizer.step(reg_loss)
# 释放 EMA weight 作为最终 checkpoint
return model.ema_weights
Figure 5 解读:RL 后训练效果的 human voting 验证。左图(Pretrained+RL):RL win 41.1% vs Before RL 18.9%。右图(Merged+RL):RL win 37.0% vs Before RL 16.3%。两种基线上 RL 都能显著提升生成质量。
RL 前后 reward 变化 (VideoAlign on PAI-Bench):
| 模型 | Text2World Sum | Image2World Sum |
|---|---|---|
| Predict2.5-2B [pre-train] | 1.08 | 0.23 |
| + RL | 1.69 | 0.42 |
| Predict2.5-2B [merged] | 1.23 | 0.24 |
| + RL | 1.74 | 0.45 |
Timestep Distillation
使用 rCM (reverse Consistency Model) 框架,混合 forward-reverse consistency distillation + distribution matching,仅需 4 步即可生成高质量样本,质量接近 teacher model。
蒸馏结果 (PAI-Bench):
| 模型 | Domain Score | Quality Score | Overall Score |
|---|---|---|---|
| Teacher (T2W) | 0.804 | 0.732 | 0.768 |
| Distilled (T2W) | 0.797 | 0.731 | 0.764 |
| Teacher (I2W) | 0.840 | 0.779 | 0.810 |
| Distilled (I2W) | 0.842 | 0.790 | 0.816 |
3.5 Cosmos-Transfer2.5 (ControlNet)
基于 Cosmos-Predict2.5-2B 构建,支持多种空间控制输入(edge, blur, segmentation, depth map)。
架构改进(vs Transfer1-7B):4 个 control block 从序列开头分布到主干中每隔 7 个 block 插入一个,实现更均匀的条件信息注入。模型大小仅为前代的 。
长视频质量评估指标 RNDS(Relative Normalized Dover Score):
其中 为 chunk 索引,DOVER 为视频质量分数。RNDS 始终从 开始,方便比较不同模型的长视频质量衰减趋势。
![]()
Figure 10 解读:长视频生成的误差累积对比(Edge Control 示例)。蓝线为 Cosmos-Transfer1-7B,绿线为 Cosmos-Transfer2.5-2B。在 edge/blur/depth/seg 四种控制模态下,Transfer2.5(绿色)RNDS 衰减明显更小,表示长视频生成中幻觉和误差累积更少,尽管模型小 3.5 倍。
3.6 Action-Conditioned World Generation
通过添加 action embedder MLP 将 7-DoF 机器人动作 映射为 tensor,加到 DiT 的 timestep embedding 上(而非 cross-attention 或 channel concat,消融实验证明此方法最优)。
# Pseudocode: Action-Conditioned Generation
class ActionEmbedder(nn.Module):
def __init__(self, action_dim=7, embed_dim=256):
self.mlp = nn.Sequential(
nn.Linear(action_dim, embed_dim),
nn.SiLU(),
nn.Linear(embed_dim, embed_dim)
)
def forward(self, actions):
return self.mlp(actions) # [B, T, embed_dim]
# 在 DiT block 中注入
time_emb = time_embed(t) + action_embedder(actions) # 加到时间步嵌入4. Experimental Setup (实验设置)
评估基准
- PAI-Bench: Physical AI 生成与理解评估
- Domain Score: 7 个领域 (av, common, human, industry, misc, physics, robotics) 的 VQA 评估
- Quality Score: 8 个 VBench 指标 (text-to-video + image-to-video)
- Overall Score = (Domain + Quality) / 2
- PAIBench-Transfer: 600 视频,评估 control adherence + quality
- DreamGen Bench: VLA 合成数据质量评估(object/behavior/environment 泛化)
- Human Evaluation: 成对偏好投票
Baseline 对比模型
- Wan2.1-1.3B, Wan2.1-14B
- Wan2.2-5B, Wan2.2-27B-A14B
- Cosmos-Predict1, Cosmos-Transfer1-7B
- Hunyuan, CogVideoX
训练基础设施
- FSDP2 (Hybrid Sharded Mode): per-parameter sharding,支持异步分布式 checkpointing
- Ulysses-style Context Parallelism: 支持数十万 token 序列,利用 intra-node all-to-all collectives
- Selective Activation Checkpointing (SAC): 轻量算子优先 recompute,重算子保留
- Elastic Reward Service: producer-consumer pipeline,CUDA IPC zero-copy 通信,Redis 存储 reward
5. Experimental Results (实验结果)
5.1 PAI-Bench 主要结果
Text2World (PAI-Bench):
| 模型 | Domain Score | Quality Score | Overall Score |
|---|---|---|---|
| Cosmos-Predict2.5-2B [post-train] | 0.804 | 0.732 | 0.768 |
| Cosmos-Predict2.5-14B [post-train] | 0.803 | 0.732 | 0.768 |
| Wan2.1-14B | 0.794 | 0.727 | 0.761 |
| Wan2.2-5B | 0.797 | 0.730 | 0.764 |
| Wan2.2-27B-A14B | 0.810 | 0.728 | 0.769 |
Image2World (PAI-Bench):
| 模型 | Domain Score | Quality Score | Overall Score |
|---|---|---|---|
| Cosmos-Predict2.5-2B [post-train] | 0.840 | 0.779 | 0.810 |
| Cosmos-Predict2.5-14B [post-train] | 0.838 | 0.781 | 0.810 |
| Wan2.1-14B | 0.827 | 0.768 | 0.797 |
| Wan2.2-27B-A14B | 0.834 | 0.772 | 0.806 |
Cosmos-Predict2.5 在 I2W 上是所有模型中 Overall Score 最高的(0.810),在 T2W 上与大 2 倍的 Wan2.2-27B-A14B 打平。
5.2 Human Evaluation

Figure 6 解读:Human preference 对比。尽管 2B 模型比 Wan2.2-5B 小 60%、比 Wan2.1-14B 小 85.7%,Cosmos-Predict2.5-2B 仍然在 I2W+T2W 评估中被更多人偏好(vs Wan2.2-5B: 30.0% vs 26.2%; vs Wan2.1-14B: 33.0% vs 34.8% 基本持平)。

Figure 7 解读:14B 模型的 human preference。vs Wan2.1-14B: 48.6% win vs 31.8%,大幅领先。vs Wan2.2-27B-A14B(参数量 2 倍): 38.1% vs 35.9%,基本持平。
5.3 Cosmos-Transfer2.5 结果
Transfer 模型对比 (PAIBench-Transfer, Uniform Weights):
| 模型 | Blur SSIM | Edge F1 | Depth si-RMSE↓ | Seg mIoU | Quality Score |
|---|---|---|---|---|---|
| Transfer1-7B | 0.82 | 0.26 | 0.70 | 0.74 | 9.24 |
| Transfer2.5-2B | 0.87 | 0.41 | 0.67 | 0.76 | 9.31 |
Transfer2.5 在所有指标上超越 Transfer1,尽管模型小 3.5 倍。
5.4 Robot Policy Learning(Cosmos-Transfer2.5 数据增强)
| 策略 | 10 场景总成功率 |
|---|---|
| Base (100 demos, 无增强) | 1/30 |
| Baseline (标准图像增强) | 5/30 |
| Proposed (Transfer2.5 增强) | 24/30 |
Transfer2.5 增强的 policy 在 9 个 OOD 场景中展现显著的泛化能力(更换物体颜色、桌布、背景、光照等)。
5.5 Driving Simulation (Multi-view)
| 模型 | FVD StyleGAN↓ | FVD I3D↓ | FID↓ |
|---|---|---|---|
| Predict2.5-2B/auto/mv | 23.060 | 25.308 | 12.095 |
| Predict1-7B-Sample-AV | 63.685 | 69.613 | 25.341 |
多视角驾驶视频生成质量提升 ~2.3x (FVD/FID)。
5.6 Action-Conditioned Generation (Bridge)
| 方法 | PSNR↑ | SSIM↑ | Latent L2↓ | FVD↓ |
|---|---|---|---|---|
| Predict1-7B-ActionCond | 21.14 | 0.82 | 0.32 | 190 |
| Predict2.5-2B/action-cond | 24.95 | 0.85 | 0.28 | 146 |
5.7 VLA Synthetic Data (DreamGen Bench)
| 模型 | Object (GPT/Qwen) | Behavior (GPT/Qwen) | Env (GPT/Qwen) |
|---|---|---|---|
| Hunyuan | 38.0/26.0 | 38.3/10.6 | 27.6/27.6 |
| WAN2.1 | 72.0/58.0 | 72.3/55.3 | 48.3/65.5 |
| Predict2.5-14B | 91.8/69.4 | 70.2/59.6 | 69.0/69.0 |
在 Object 和 Env 泛化维度上大幅领先所有竞争者。
6. Code-to-Paper Mapping
| 论文组件 | 代码位置 (cosmos-predict2.5 repo) |
|---|---|
| DiT 模型定义 | cosmos_predict2/model/ |
| Flow Matching 采样 | cosmos_predict2/diffusion/ (UniPC solver) |
| WAN2.1 VAE Tokenizer | cosmos_predict2/tokenizer/ |
| Cosmos-Reason1 Text Encoder | cosmos_predict2/text_encoder/ |
| Text2World 推理 | documentations/inference_text2world.md |
| Image2World 推理 | documentations/inference_image2world.md |
| Video2World 推理 | documentations/inference_video2world.md |
| LoRA 微调 | documentations/post_training_lora.md |
| DMD2 蒸馏 | documentations/post_training_dmd2.md |
| Diffusers 集成 | documentations/diffusers.md |
| Transfer2.5 ControlNet | cosmos-transfer2.5 |
| 预训练权重 (HuggingFace) | nvidia/cosmos-predict2.5-* |