Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video
Paper: arXiv:2605.15182 Code: yyfz/Warp-as-History Code reference:
main@eb4332e0(2026-05-15)
1. Motivation (研究动机)
- 现有 camera-controlled video generation 的瓶颈:训练型方法通常把 camera 信息塞进 camera encoder、control branch、attention / positional encoding 修改等专门模块,因此需要大规模 camera-annotated videos;training-free 方法虽然避免 post-training,但常把代价转移到 test-time optimization、denoising-time guidance、warp-and-repaint 或 sampling-time constraints。
- 本文要解决的具体问题:给定 first frame 和目标 camera trajectory,让 frozen 或极低资源 finetuned 的 history-conditioned video generator 跟随相机运动,同时保持外观、完成 disocclusion,并允许前景对象有独立动态,而不是把 warp 当作硬渲染目标或新增 camera-control branch。
- 为什么值得做:如果 camera control 可以作为“已有 visual-history pathway 的接口问题”被激活,就能把交互式视角控制从“大规模相机标注训练 / 每个测试视频优化”转成 lightweight offline adaptation;这对可探索场景、长视频 rollouts、world exploration 类应用更接近实用。

Figure 1 解读:teaser 展示了本文主张的现象:只用一个 camera-annotated training video 做 LoRA finetuning 后,模型能在 unseen scenes / unseen trajectories 上跟随相机路径。这里的重点不是新建一个 camera model,而是把 camera-induced warp 变成“history evidence”,交给 video backbone 已经学会的 continuation 接口处理。
2. Idea (核心思想)
核心洞察:video history 不只是 temporal context,也可以是 camera-control interface。相机轨迹诱导出的 warped observations 不必作为硬约束或额外 control branch;只要把它们包装成 camera-warped pseudo-history,并把位置编码对齐到当前 denoising target frame,frozen history-conditioned generator 就会把几何证据解释成相机运动。
关键创新是三步接口设计:camera-warped pseudo-history 提供可见区域的几何证据;target-frame RoPE alignment 让第 个 warp latent 对应第 个 target latent;visible-token selection 删除没有 source observation 的 warp tokens,让 generator 自己补全 disocclusion。与 Gen3C / ViewCrafter / Voyager 这类需要大规模 camera-related training data 的方法相比,Warp-as-History 的最终模型只在一个独立 source video 上做 offline LoRA;与 training-free optimization / guidance 方法相比,它不引入测试时优化或额外 denoising-time guidance。
3. Method (方法)
3.1 Overall framework:把 warp 塞进 native history stream
论文把 history-conditioned backbone 写成:给定视频 、prompt 、chunk 起点 ,模型用 native history construction operator 处理过去帧,采样未来 chunk:
Warp-as-History 复用的就是这个接口:不是学习 camera encoder,而是让 target camera trajectory 先生成 warp video ,再经由同一个 编码成 pseudo-history:
其中 是 warp validity mask, 是在 native history construction 之后做的 visible-token selection。最终条件形式为:
论文未给出新的训练损失公式;它明确说 one-video LoRA 使用 backbone 原本的 video-generation objective,只优化 low-rank update。
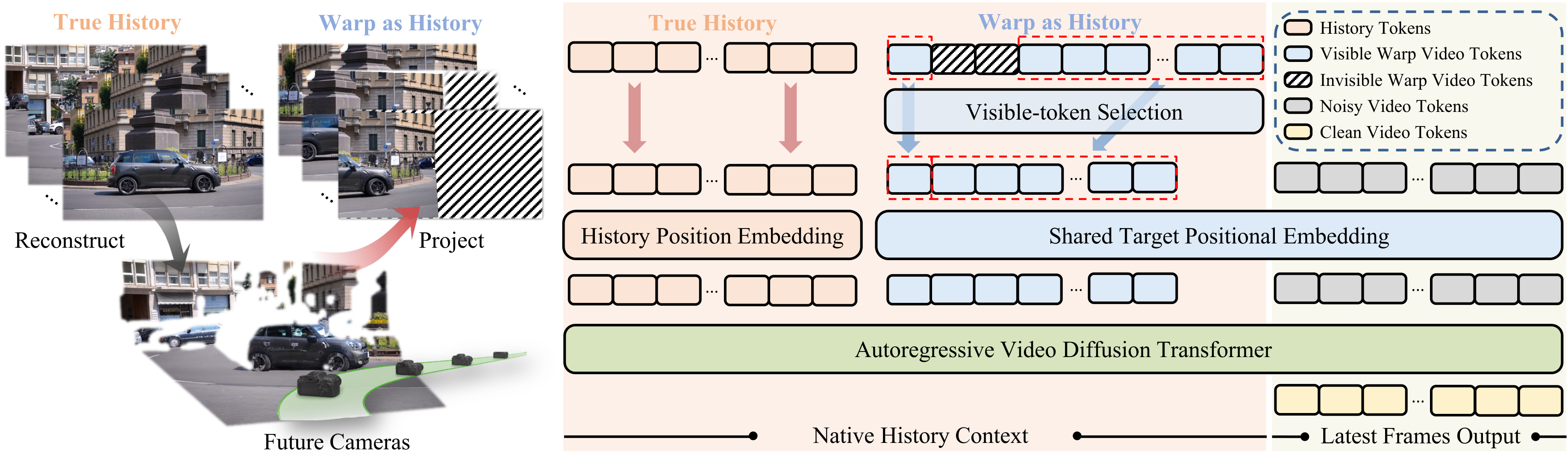
Figure 3 解读:左侧从 first frame / past observations 和 target camera trajectory 构造 warp video;中间把 warp 送入 visual-history encoder,而不是送进独立 camera branch;右侧关键是 shared target positional embedding 与 visible-token selection:warp tokens 仍然走 history path,但其 temporal RoPE index 对齐到当前 target latent,invalid tokens 则被丢弃,让 DiT 只看到可靠几何证据。
直觉上,这个设计把“相机控制”拆成两个互补角色:warp 对可见区域提供低频几何方向,pretrained generator 对不可见区域和动态物体负责生成。若把 warp 当硬目标,错误几何、holes、stretched textures 会被复制;若把 warp tokens 当普通历史,模型只把它理解成过去上下文而非当前 frame 的证据。target-frame alignment 解决“证据对应哪个时刻”的问题,visible-token selection 解决“哪些证据可信”的问题。
3.2 Camera-warped pseudo-history
实现中,camera warp 可来自两条路径:用户直接传入 warp_video / warp_visibility_mask,或传入 camera_poses 让代码在线用 Pi3X 估计 first-frame geometry 并 render target views。论文里的 对应 released code 中的 Pi3XWarpRenderer.render() / render_pi3x_camera_warp():先估计 first-frame geometry,再按 target camera poses rollout,返回 warped frames 与 visibility mask。

Figure 2 解读:四行分别是 ground truth、camera-induced warp、zero-shot Warp-as-History、one-training-video finetuning。warp 本身只是几何提示,会有不可见区域和动态物体错误;frozen model 已经能从 pseudo-history 中读出相机运动,但质量和边界不稳;one-video LoRA 主要稳定“何时信 warp、何时交给 prior”。
3.3 Target-frame positional alignment
普通 history placement 会把 warp frame 看作过去上下文;本文保留 history patchification path,但把第 个 warp latent 的 RoPE index 赋成对应第 个 noisy target latent 的 index。代码里这对应 rope_alignment=True 时 WarpAsHistoryPipeline._build_pyramid_base_histories() 构造 warp_indices = official_target_start ... official_target_start + K,并在 training 侧 make_histories() / remap_history_rope_indices() 支持 history_positioning=last_n_same_order。
3.4 Visible-token selection
相机运动会产生 disocclusion;first-frame warp 无法知道新露出的内容。论文选择不把 invalid mask 当额外 control input,而是把 warp validity mask 下采样到 latent-token grid,删除有效支持不足的 history tokens。released code 中 inference 默认 visible_token_drop=True,threshold 来自 WAH_VISIBLE_TOKEN_THRESHOLD = 0.1;training 脚本默认 --visible_token_drop 且 --visible_token_threshold 0.1。

Figure 6 解读:这是 frozen-model zero-shot ablation 的可视化链条。native warp history 已经给出弱 camera-follow signal;加入 target-frame positional alignment 后,相机跟随立刻变强;再加入 visible-token selection 后,无效 warp 区域不再强行污染 history stream,模型能更自然地补全新可见区域。
3.5 One-training-video LoRA finetuning
最终模型只在一个独立 camera-annotated video 上做 offline LoRA。论文强调 LoRA 不是学习新 camera branch,而是校准 history reader:可见 warp tokens 提供 camera-induced motion cues,pretrained prior 负责 independent dynamics 和 disocclusion。released training script 对 Helios-Mid 训练 LoRA,再把 update mount 到 distilled inference model;LoRA 只插在第一、最低分辨率 Helios stage,后续高分辨率 stages 用 native refinement path。

Figure 4 解读:该 qualitative comparison 在 in-the-wild videos 上对比 camera-induced warp、ground truth、ViewCrafter、Gen3C、Voyager 与 Ours。图的作用是展示 Warp-as-History 不是简单复制 warp:相对 warp-based baselines,它更少暴露 warp artifacts / blur / distorted objects,同时保留更干净的 foreground motion。

Figure 5 解读:该图在 WorldScore-sampled 30-second trajectories 上和 HyWorldPlay 对比,帧位置为 0、12、24、30 秒。它主要用于 long-video setting:Ours 使用 direct sampler 和 pseudo-history 继续 roll out,相机路径可控,但 VBench Overall / Imaging / Dynamic 等指标仍不全面超过 HyWorldPlay。

Figure 7 解读:补充定性对比延续 Figure 4 的列布局,用更多 in-the-wild examples 检查同一 target camera setting 下不同方法的内容保持、相机跟随与动态质量。它补强了主文结论:Warp-as-History 的优势主要来自把可靠几何证据交给 history pathway,而不是把 warp 当最终渲染。
3.6 Pseudocode:基于 released code 的关键组件
import torch
import torch.nn.functional as F
def render_camera_warp(first_frame, camera_poses, renderer, height=384, width=640):
"""Matches warp_as_history/camera_warp.py: Pi3XWarpRenderer.render."""
geometry = renderer.estimate_first_frame_geometry(first_frame)
pose_rollout = prepare_camera_pose_rollout(camera_poses, num_frames=33)
rendered = renderer.render_from_geometry(
geometry=geometry,
target_relative_poses=pose_rollout,
height=height,
width=width,
invisible_fill_mode="mean_first_frame",
render_mode="target_fill",
)
warp_video = rendered["warp_video"] # [B, C, T, H, W]
visibility_mask = rendered["warp_visibility_mask"] # [B, 1, T, H, W]
return warp_video, visibility_maskdef build_warp_as_history(
pipe,
first_frame_latents,
warp_video,
visibility_mask,
prev_history_latent_window=None,
base_latents_history_short=None,
chunk_index=0,
):
"""Matches WarpAsHistoryPipeline._build_pyramid_base_histories."""
long_size, mid_size, short_size = (16, 2, 1)
latent_window = 9
warp_latents = pipe.prepare_video_latents(
warp_video,
num_latent_frames_per_chunk=latent_window,
dtype=torch.float32,
)[1]
warp_latents = add_noise_to_warp_history_latents(warp_latents, 0.111, 0.135)
visibility_latents = resize_mask_to_latent_grid(
visibility_mask,
latent_frames=latent_window,
temporal_scale=pipe.vae_scale_factor_temporal,
)
# Real code also preserves previous long/mid/short history windows.
total_prev = long_size + mid_size + short_size
prev_window = warp_latents.new_zeros(*warp_latents.shape[:2], total_prev, *warp_latents.shape[-2:])
prev_visible = warp_latents.new_zeros(warp_latents.shape[0], 1, total_prev, *warp_latents.shape[-2:])
if chunk_index > 0 and prev_history_latent_window is not None:
keep = min(prev_history_latent_window.shape[2], total_prev)
prev_window[:, :, -keep:] = prev_history_latent_window[:, :, -keep:]
prev_visible[:, :, -keep:] = 1.0
elif base_latents_history_short is not None and base_latents_history_short.shape[2] > 1:
fake_count = min(short_size, base_latents_history_short.shape[2] - 1)
prev_window[:, :, total_prev - fake_count:] = base_latents_history_short[:, :, 1:1 + fake_count]
prev_visible[:, :, total_prev - fake_count:] = 1.0
prev_long, prev_mid, prev_short = prev_window.split((long_size, mid_size, short_size), dim=2)
vis_long, vis_mid, vis_short = prev_visible.split((long_size, mid_size, short_size), dim=2)
official_target_start = 1 + total_prev
target_indices = torch.arange(official_target_start, official_target_start + latent_window)
prev_indices = torch.arange(official_target_start - total_prev, official_target_start)
idx_long, idx_mid, idx_short = prev_indices.split((long_size, mid_size, short_size), dim=0)
prefix_latent = first_frame_latents[:, :, :1]
prefix_index = torch.zeros(1, dtype=torch.long)
history_short = torch.cat([prefix_latent, prev_short, warp_latents], dim=2)
visible_short = torch.cat([torch.ones_like(visibility_latents[:, :, :1]), vis_short, visibility_latents], dim=2)
return {
"latents_history_short": history_short,
"latents_history_mid": prev_mid,
"latents_history_long": prev_long,
"indices_latents_history_short": torch.cat([prefix_index, idx_short, target_indices]).unsqueeze(0),
"indices_latents_history_mid": idx_mid.unsqueeze(0),
"indices_latents_history_long": idx_long.unsqueeze(0),
"history_visible_mask_short": visible_short,
"history_visible_mask_mid": vis_mid,
"history_visible_mask_long": vis_long,
"indices_hidden_states": target_indices.unsqueeze(0),
}def infer_warp_as_history(pipe, prompt, image, camera_poses=None, warp_video=None, lora_path=None):
"""Matches WarpAsHistoryPipeline.__call__ + generate_next_chunk loop."""
if camera_poses is None and warp_video is None:
return pipe._run_original_helios(prompt=prompt, image=image, num_frames=33)
state = pipe.init_autoregressive_state(
prompt=prompt,
image=image,
conditioning_type="camera" if warp_video is None else "warp",
lora_path=lora_path,
visible_token_drop=True,
rope_alignment=True,
height=384,
width=640,
num_frames=33,
)
for chunk_index in range(state["num_warp_chunks"]):
if warp_video is None:
chunk_poses = slice_camera_window(camera_poses, chunk_index)
pipe.generate_next_chunk(state, camera_poses=chunk_poses, output_type="latent")
else:
chunk_warp, chunk_mask = slice_warp_window(warp_video, chunk_index)
pipe.generate_next_chunk(
state,
warp_video=chunk_warp,
warp_visibility_mask=chunk_mask,
output_type="latent",
)
return pipe.finalize_autoregressive_state(state, output_type="np")def train_one_video_lora(pipe, prepared_items, max_steps=1000):
"""Matches scripts/train_warp_as_history_lora.py + training/core.py."""
adapter_name, lora_params, _ = setup_visible_lora(
pipe.transformer,
lora_rank=32,
lora_alpha=32,
target_modules=["attn1.to_q", "attn1.to_k", "attn1.to_v", "attn1.to_out.0"],
)
optimizer = torch.optim.AdamW(lora_params, lr=1e-4, weight_decay=0.01)
for step in range(max_steps):
item = prepared_items.sample()
loss, stats, _ = flow_matching_loss(
pipe,
item["prompt_embeds"],
item["target_latents"],
item["histories"],
)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(lora_params, max_norm=1.0)
optimizer.step()
pipe.transformer.set_adapter(adapter_name)
save_visible_lora_state(pipe.transformer, "runs/warp_as_history_lora", adapter_name)论文公式与 released code 实现差异:未发现公式层面的直接矛盾;released code 额外显式实现了论文未在公式中展开的工程细节,包括 camctl23x. / wah. prompt trigger、warp latent noise range 0.111–0.135、Pi3X online renderer、以及只在 Helios stage0 加 LoRA 和 aligned warp history。
Code reference:
main@eb4332e0(2026-05-15) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Camera-warped pseudo-history / online warp | warp_as_history/camera_warp.py | Pi3XWarpRenderer, render_pi3x_camera_warp() |
| Inference entry and original Helios fallback | warp_as_history/pipeline.py | WarpAsHistoryPipeline.__call__(), _run_original_helios() |
| Target-frame RoPE alignment and history packing | warp_as_history/pipeline.py | _build_pyramid_base_histories() |
| Visible-token selection mask path | warp_as_history/pipeline.py, warp_as_history/training/core.py | _visibility_mask_to_history_latents(), make_histories() |
| One-video LoRA training loop | scripts/train_warp_as_history_lora.py | parse_args(), build_exact_args(), main() |
| Flow-matching training loss and LoRA setup | warp_as_history/training/core.py | flow_matching_loss_train_exact(), setup_visible_lora() |
| Data / online warp training cache | warp_as_history/training/data.py | OnlineWarpTrainingCache, prepare_online_warp_item() |
4. Experimental Setup (实验设置)
Datasets and scale
- WorldScore:main WorldScore report 使用
static_cc_dev32,共 32 deterministic samples = 2 visual styles × 2 scene types × 8 single-camera motions;HyWorldPlay comparison 另随机采样 50 images,每张 3 个 camera directions,生成 30-second videos。 - DAVIS:77-video common-33-frame first-chunk protocol;每个视频从 frame 0 开始,使用前 33 frames;one-shot training source 是 DAVIS
car-roundabout,论文表中写作1 video → 4 clips。 - RealEstate10K / RE10K:DAVIS-aligned ablation 用 fixed 100-sequence test subset;external-baseline report 用同一组 99 RE10K sequences,排除 1 条 ViewCrafter output unavailable 的 sequence;camera metrics 使用 33 frames、Pi3X frame stride 4。
Baselines
- WorldScore:CogVideoX-I2V、Voyager、FantasyWorld-1.0、Helios-Distilled text-only、Ours zero-shot、Ours one-shot。
- External camera-control baselines:Gen3C、Voyager、ViewCrafter;training scale 分别约 90K videos、78K videos → 100K clips、85K videos → 632K clips。
- Ablation baselines:NoAlign、NoVisDrop、ChFusion、SeqConcat、Full;zero-shot rows 不用 LoRA,one-shot rows 用同一 stage0-only distilled inference protocol。
Metrics
- Camera / geometry:PSNR、SSIM、LPIPS、visible-region LPIPS、rotation error
R-Err、translation errorT-Err。 - Quality / dynamics:FID、FVD、DOVER、VBench Flicker、Motion Smoothness、Subject Consistency、Background Consistency、Dynamic Degree、Imaging Quality。
- WorldScore axes:Avg.、Camera Control、Object Control、Content Alignment、3D Consistency、Photometric Consistency、Style Consistency、Subjective Quality。
Training and inference config
- Backbone:Helios;zero-shot 用 Helios-Distilled,LoRA finetuning 在 Helios-Mid 上训练 update,再 mount 到 distilled checkpoint 推理。
- Launch source:
README.mdtraining command +scripts/train_warp_as_history_lora.pyparser/build config;README 指定--prompt_csv data/training/training_data.csv --data_root data/training --output_dir runs/warp_as_history_lora --max_steps 1000 --save_every 1000 --log_every 10 --overwrite。 - Key hyperparameters:resolution
384×640,num_frames=33,latent frames per chunk9,history sizes(16,2,1),pyramid denoising steps2+2+2,stage samplingfixedstage 0,history positioninglast_n_same_order,LoRA rank32/ alpha32/ dropout0.0,target modulesattn1.to_q,to_k,to_v,to_out.0,LR1e-4,AdamW weight decay0.01,warmup20,max grad norm1.0。 - Hardware / runtime:论文称 one-training-video LoRA 1000 iterations 约 1 hour on single NVIDIA A800 GPU;runtime table 同样在 single A800 上测 33-frame chunk。
5. Experimental Results (实验结果)
Main benchmark numbers
WorldScore:相对 text-only Helios-Distilled,Warp-as-History 把 Camera Control 从 26.42 提高到 zero-shot 61.32 和 one-shot 62.00;one-shot 还把 Subjective Quality 从 zero-shot 47.37 提高到 54.83。
| Method | Avg. | Camera Control | Object Control | Content Align. | 3D Cons. | Photo. Cons. | Style Cons. | Subjective Quality |
|---|---|---|---|---|---|---|---|---|
| CogVideoX-I2V | 62.15 | 38.27 | 40.07 | 36.73 | 86.21 | 88.12 | 83.22 | 62.44 |
| Voyager | 77.62 | 85.95 | 66.92 | 68.92 | 81.56 | 85.99 | 84.89 | 71.09 |
| FantasyWorld-1.0 | 80.45 | 81.45 | 87.90 | 66.94 | 84.62 | 94.07 | 86.69 | 61.46 |
| Helios-Distilled (text-only) | 62.42 | 26.42 | 42.66 | 37.75 | 92.54 | 93.93 | 90.41 | 53.21 |
| Ours (zero-shot) | 63.26 | 61.32 | 33.07 | 39.92 | 87.27 | 88.18 | 85.67 | 47.37 |
| Ours (one-shot) | 65.64 | 62.00 | 32.82 | 38.60 | 89.36 | 90.43 | 91.46 | 54.83 |
DAVIS / RE10K geometry:Ours 用 1 video → 4 clips,在 DAVIS 上 PSNR 15.21、Vis. LPIPS 0.2236、R-Err 2.97;在 RE10K 上 PSNR 17.15、Vis. LPIPS 0.1426、R-Err 1.28。它没有全面超过大规模训练 baseline,但以极小训练数据进入 comparable camera-following range。
| Dataset | Method | Training scale | PSNR | SSIM | LPIPS | Vis. LPIPS | R-Err | T-Err |
|---|---|---|---|---|---|---|---|---|
| DAVIS | Gen3C | ~90K videos | 16.29 | 0.5267 | 0.3539 | 0.1930 | 2.24 | 0.0663 |
| DAVIS | Voyager | ~78K videos → ~100K clips | 14.75 | 0.3983 | 0.4431 | 0.2558 | 3.05 | 0.0706 |
| DAVIS | ViewCrafter | ~85K videos → ~632K clips | 14.72 | 0.4133 | 0.3925 | 0.2308 | 3.85 | 0.1031 |
| DAVIS | Ours (one-shot) | 1 video → 4 clips | 15.21 | 0.3976 | 0.3794 | 0.2236 | 2.97 | 0.0942 |
| RE10K | Gen3C | ~90K videos | 20.10 | 0.7775 | 0.1523 | 0.0828 | 0.62 | 0.0158 |
| RE10K | Voyager | ~78K videos → ~100K clips | 19.03 | 0.6914 | 0.2304 | 0.1268 | 0.86 | 0.0322 |
| RE10K | ViewCrafter | ~85K videos → ~632K clips | 15.86 | 0.6765 | 0.2636 | 0.2015 | 0.83 | 0.0237 |
| RE10K | Ours (one-shot) | 1 video → 4 clips | 17.15 | 0.6214 | 0.2343 | 0.1426 | 1.28 | 0.0454 |
DAVIS / RE10K visual quality:DAVIS 上 Ours 得到 best FID 68.18、FVD 57.95、Subject 0.941、Background 0.940;RE10K 上 Ours 得到 best DOVER 0.442、Subject 0.956、Background 0.958、Imaging 65.97。
Ablations and sensitivity
- Interface ablation:zero-shot Full 在 DAVIS 上 R-Err
3.41、VisLPIPS0.274,优于 NoAlign 的 R-Err7.33;one-shot Full 在 RE10K 上 R-Err1.28、T-Err0.0454、VisLPIPS0.143,说明 target alignment 和 visible-token filtering 都是打开 frozen prior 的关键。 - Few-shot sensitivity:DAVIS+RE10K mean 从 0-video zero-shot 到 1-video LoRA 的增益最明显:PSNR
13.38 → 16.02、LPIPS0.4178 → 0.3136、R-Err2.81 → 2.25、T-Err0.0958 → 0.0766、DOVER0.381 → 0.447、Img.59.93 → 64.47。增加到 3/5/7/10/12 videos 并非单调提升,论文把它作为 sensitivity check,而不是主方法 claim。 - Runtime:single A800 生成 33-frame chunk 时,86% visible tokens 下 end-to-end
15.83s → 23.63s(+7.81s);47% visible tokens 下15.78s → 20.40s(+4.62s)。主要 overhead 来自 transformer / sampling 的序列变长,而不是 camera render 或 warp VAE encode。
Limitations
作者明确列出的限制是:方法依赖 warp construction 的质量和成本;当前实现使用外部 reconstruction model 投影到 future cameras,因此会继承 geometry、visibility、disocclusion 错误;额外 history tokens 会增加 transformer runtime;它本质是 invocation interface 而不是新 video generator,因此泛化上限受 pretrained backbone 的 visual-history comprehension、dynamic preservation 和 content completion 能力限制。
Overall conclusion
Warp-as-History 的实验证明了一个较强的低资源结论:history-conditioned video model 中已经存在弱 camera-follow prior;只要把 camera-induced warp 作为 target-aligned、visibility-aware pseudo-history 输入,就能 zero-shot 激活该能力,而一个 separate video 的 LoRA 就足以显著稳定它。它不是在所有指标上压过大规模 camera-control systems,但以 1 video → 4 clips 的训练规模获得了可比的 camera adherence 和强视觉质量,是“控制接口设计”而非“专用 camera 模块训练”的代表性结果。