1. Motivation (研究动机)
- 现有方法的问题:Video Diffusion Models (VDMs) 已经有很强的时空动态先验,但多数下游 multimodal graphics 方法仍按固定输入输出关系训练独立模型,例如
RGB → alpha、RGB → normal、intrinsic → RGB。这种做法带来两个硬伤:一是每个模型角色固定,应用里一旦条件模态变化就需要换模型;二是不同视觉模态之间的相关性没有在同一生成过程中建模,串行推理容易导致最终 RGB、albedo、irradiance、normal、alpha/FG/BG 等模态栈不一致。 - 本文要解决的具体问题:设计一个统一框架,让同一 VDM backbone 能在像素对齐的多视觉模态集合中任意选择一部分作为 clean conditions、另一部分作为 noisy targets,从而支持
Text → X、X → X、Text&X → X三类任务;作者将其落到两个实例:UniVid-Intrinsic(RGB / albedo / irradiance / normal)和 UniVid-Alpha(blended RGB / alpha / foreground / background)。 - 为什么值得研究:如果这个问题解决,视频生成模型不再只是 text-to-RGB engine,而可以变成统一的 video graphics prior:同一模型既能做 perception(inverse rendering、video matting),也能做 generation/editing(text-to-intrinsic、text-to-RGBA、relighting、inpainting、foreground/background replacement)。更重要的是,论文显示两个实例都在少于 1K training videos 的小数据条件下达到强结果,说明复用 VDM prior 比从零训练专用模型更高效。
2. Idea (核心思想)
核心洞察是:把多模态图形任务统一为“共享 multimodal latent space 内的 conditional flow matching”问题,而不是为每个方向单独定义模型。在同一组像素对齐模态中,训练时随机决定哪些模态保持干净作为条件、哪些模态加噪作为目标;推理时只需按任务设定对应的 clean/noisy 分区,就能得到 omni-directional generation。
关键创新有三点:SCM 用随机条件掩码打破固定 mapping;DGL 为每个目标模态使用独立 LoRA,并在该模态作为 condition 时关闭 LoRA,以保留 backbone 原生编码能力;CMSA 将不同模态的 keys/values 合并为共享上下文、queries 保持模态特异,从而让每个模态在 self-attention 内直接看见其他模态。
与典型竞品的根本差异:相对 NormalCrafter / RVM / MODNet 这类单任务或单输出方法,UniVidX 不是训练一个固定任务模型;相对 Ouroboros 这类串行 multimodal inference,UniVidX 在一个联合扩散过程内建模模态相关性;相对 channel-concatenation 类方法(如 Diffusion Renderer / Geo4D / CtrlVDiff 风格),UniVidX 不改 VDM 的输入输出 channel 结构,而是沿 batch 维组织模态,尽量不破坏预训练扩散先验。
3. Method (方法)
3.1 整体框架

Figure 1 解读:图 1 展示 UniVidX 的任务覆盖面。上半部分是 UniVid-Intrinsic:从文本生成 RGB/albedo/irradiance/normal,或从 RGB 反推 intrinsic maps,再组合做 relighting。下半部分是 UniVid-Alpha:从文本生成 BL/alpha/FG/BG,或从 BL 做 matting,再组合做 inpainting。右侧强调它支持 Text → X、X → X、Text&X → X 三类范式,并且训练视频数量低于 1K。

Figure 2 解读:图 2 是核心架构。多模态视频先进入同一个 VAE latent space,SCM 将部分模态设为 clean condition、部分模态设为 noisy target;DiT blocks 内部插入 DGL,目标模态对应的 LoRA 亮起,条件模态的 LoRA 关闭;CMSA 在 self-attention 内将所有模态的 K/V 共享,使不同模态在去噪时互相对齐。
直觉段落(为什么有效):预训练 VDM 的强项是 RGB 视频动态、纹理和语义先验;如果为了多模态任务直接改输入通道或全量微调,很容易把这些先验冲掉。UniVidX 的做法更像“把多模态任务投影成 VDM 已经会处理的条件生成”:condition 模态保持 clean,让 backbone 用原生权重提取语义;target 模态加噪,只在需要生成目标模态时打开对应 LoRA 学习模态分布;attention 又把不同模态的 token 放到同一个 K/V 池里,使 albedo、normal、alpha、foreground 等输出不是各自独立生成,而是在同一步去噪中互相约束。
3.2 Stochastic Condition Masking (SCM)
令所有视觉模态的 latents 为集合 。训练时随机划分为 target subset 和 condition subset 。Target latents 被线性插值加噪,condition latents 固定在 clean state;Text-only 任务可令 。
论文给出的统一 flow matching 目标是:
其中 。当前官方代码使用 FlowMatchScheduler.add_noise() 的 约定:
并以 noise - sample 作为 training_target;这是与论文公式符号方向相反但与 scheduler step 一致的实现约定。
组件伪代码:SCM / task mode 到 noisy-target loss(对齐 src/pipelines/univid_intrinsic.py 与 src/pipelines/univid_alpha.py)
import torch
import torch.nn.functional as F
CLEAN_T = 999 # repo uses scheduler.timesteps[999] for clean condition slots
INTRINSIC_ORDER = ["rgb", "albedo", "irradiance", "normal"]
INTRINSIC_TARGETS = {
"t2RAIN": [0, 1, 2, 3],
"R2AIN": [1, 2, 3],
"A2RIN": [0, 2, 3],
"I2RAN": [0, 1, 3],
"N2RAI": [0, 1, 2],
"RA2IN": [2, 3],
"RI2AN": [1, 3],
"RN2AI": [1, 2],
"AI2RN": [0, 3],
"AN2RI": [0, 2],
"IN2RA": [0, 1],
"AIN2R": [0],
"RIN2A": [1],
"RAN2I": [2],
"RAI2N": [3],
}
def unividx_train_step(pipe, inputs):
mode = inputs["training_mode"]
target_ids = INTRINSIC_TARGETS[mode]
t_rand = pipe.scheduler.timesteps[torch.randint(0, pipe.scheduler.num_train_timesteps, (1,))]
t_clean = pipe.scheduler.timesteps[torch.tensor([CLEAN_T])]
timesteps = [t_rand if i in target_ids else t_clean for i in range(4)]
inputs["latents"], _ = pipe.scheduler.add_noise(
inputs["input_latents"], inputs["noise"], timesteps
)
target_velocity = pipe.scheduler.training_target(inputs["input_latents"], inputs["noise"], timesteps)
pred_velocity = pipe.model_fn(**inputs, timestep=timesteps)
loss = F.mse_loss(pred_velocity.float()[target_ids], target_velocity.float()[target_ids])
return loss * pipe.scheduler.training_weight(t_rand)3.3 Decoupled Gated LoRA (DGL)
DGL 的目标是在不破坏 Wan2.1-T2V-14B backbone 的情况下学习不同模态的分布。对第 个模态,冻结原权重 ,学习低秩更新 ,并用 gate 决定是否启用:
当模态是 generation target(noisy input)时 ,LoRA 激活;当模态是 clean condition 时 ,LoRA 关闭,使用 backbone 原始权重编码条件信息。代码里这一点体现在 adapter_names=[...]:目标模态传入对应 adapter 名称,条件模态传入 None。
组件伪代码:DGL adapter gating(对齐 SelfAttention.forward() 的 adapter_names 逻辑)
MODALITIES = ["rgb", "albedo", "irradiance", "normal"]
def adapter_names_for_mode(mode: str) -> list[str | None]:
target_ids = INTRINSIC_TARGETS[mode]
return [name if i in target_ids else None for i, name in enumerate(MODALITIES)]
def dgl_self_attention(self, x, freqs, mode: str):
adapters = adapter_names_for_mode(mode)
q = self.q(x, adapter_names=adapters)
k = self.k(x, adapter_names=adapters)
v = self.v(x, adapter_names=adapters)
q = rope_apply(self.norm_q(q), freqs, self.num_heads)
k = rope_apply(self.norm_k(k), freqs, self.num_heads)
x = flash_attention(q=q, k=k, v=v, num_heads=self.num_heads, drop_out=0)
return self.o(x, adapter_names=adapters)3.4 Cross-Modal Self-Attention (CMSA)
论文的 CMSA 将所有模态的 keys/values 合并,queries 保持模态特异:
官方代码的实现方式很直接:将 modality batch 的 K/V reshape 成 1 × heads × (batch * seq) × dim,再 repeat 给每个 modality query,因此每个模态都能 attend 到所有模态的 token。
组件伪代码:CMSA 的 shared K/V(对齐 flash_attention())
import torch.nn.functional as F
from einops import rearrange
def cross_modal_flash_attention(q, k, v, num_heads: int):
batch_size = q.shape[0] # here batch dimension is used for modalities
q = rearrange(q, "b s (n d) -> b n s d", n=num_heads)
k = rearrange(k, "b s (n d) -> 1 n (b s) d", n=num_heads).repeat(batch_size, 1, 1, 1)
v = rearrange(v, "b s (n d) -> 1 n (b s) d", n=num_heads).repeat(batch_size, 1, 1, 1)
x = F.scaled_dot_product_attention(q, k, v)
return rearrange(x, "b n s d -> b s (n d)", n=num_heads)3.5 两个实例与推理组织
UniVid-Intrinsic 的模态是 R/A/I/N:RGB、albedo、irradiance、normal。UniVid-Alpha 的模态是 R/P/F/B:blended RGB、alpha matte、foreground、background。两者各支持 15 个 task modes:
- UniVid-Intrinsic:
t2RAIN,R2AIN,RA2IN,RI2AN,RN2AI,RIN2A,RAN2I,RAI2N,AIN2R,A2RIN,I2RAN,N2RAI,AI2RN,AN2RI,IN2RA。 - UniVid-Alpha:
t2RPFB,R2PFB,RP2FB,RF2PB,RB2PF,FB2RP,PFB2R,RFB2P,RPB2F,RPF2B,P2RFB,F2RPB,B2RPF,PF2RB,PB2RF。
组件伪代码:推理时只更新 target latents(对齐 WanVideoPipeline.__call__() 中按 mode 更新 index 的逻辑)
@torch.no_grad()
def unividx_sample(pipe, latents, prompt_emb, mode: str, num_steps: int, cfg_scale: float):
target_ids = INTRINSIC_TARGETS[mode]
scheduler = pipe.scheduler
scheduler.set_timesteps(num_steps)
for t in scheduler.timesteps:
timesteps = [t if i in target_ids else scheduler.timesteps[999] for i in range(4)]
pred_cond = pipe.model_fn(
dit=pipe.dit,
latents=latents,
context=prompt_emb,
timestep=timesteps,
training_mode=mode,
)
pred = pred_cond # repo optionally applies classifier-free guidance before this step
next_latents = scheduler.step(pred, t, latents)
latents[target_ids] = next_latents[target_ids]
return pipe.vae.decode(latents[target_ids])3.6 Code-to-paper mapping
Code reference:
main@382b9002(2026-05-04) — pseudocode and mapping based on this commit.
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| SCM:clean condition / noisy target 的 task partition | src/pipelines/univid_intrinsic.py, src/pipelines/univid_alpha.py | WanVideoPipeline.training_loss() 中每个 training_mode 对应一组 clean timestep / random timestep;loss 只作用在 target indices |
| Flow matching scheduler | src/schedulers/flow_match.py | FlowMatchScheduler.set_timesteps(), add_noise(), training_target(), step() |
| DGL:per-modality LoRA 与 gating | src/models/wan_video_dit_intrinsic.py, src/models/wan_video_dit_alpha.py; src/trainers/util.py | SelfAttention.forward(..., training_mode), adapter_names=[...], add_multiple_loras_to_model() |
| CMSA:shared K/V, modality-specific Q | src/models/wan_video_dit_intrinsic.py, src/models/wan_video_dit_alpha.py | flash_attention() 将 K/V reshape 到 (batch * seq) 维度共享;SelfAttention.forward() 产生模态特异 Q |
| DiT forward / task mode 传递 | src/pipelines/univid_intrinsic.py, src/pipelines/univid_alpha.py | model_fn_wan_video() 将 training_mode 传给每个 DiT block |
| 训练入口与保存 trainable weights | scripts/train.py, src/trainers/unividx_trainer.py, src/trainers/util.py | Trainer, ModelCheckpointCallback, DiffusionTrainingModule |
| 推理入口与 mode 配置 | scripts/inference_univid_intrinsic.py, scripts/inference_univid_alpha.py, configs/*_inference.yaml | mode, resume_from_checkpoint, lora_target_modules, lora_rank |
实现注意:当前 repo 的训练 YAML 仍是模板形态(dataset 字段为空),论文中的数据规模与训练步数主要来自 paper;推理 YAML 明确使用 Wan2.1-T2V-14B、rank 32 LoRA、univid_intrinsic.safetensors / univid_alpha.safetensors checkpoints。
4. Experimental Setup (实验设置)
- Datasets 与规模:UniVid-Intrinsic 使用作者构建的 InteriorVid,包含 924 个高质量室内视频 clips,每个 21 frames、分辨率 ,并带 RGB/albedo/irradiance/normal ground truth;划分为 InteriorVid-Train 900 clips 与 InteriorVid-Test 24 clips。InteriorVid 来自 167 个 SuperHiveMarket 3D indoor scenes,经 Blender Cycles path tracing(128 samples)和 compositor 输出 OpenEXR 16-bit Float intrinsic components。UniVid-Alpha 使用 VideoMatte240K 的 484 个 videos 训练,分辨率 resize 到 ,并用 Qwen3-VL 生成 captions。MAW benchmark 约 850 images,用于 real-world albedo;Sintel benchmark 用于 normal estimation;VideoMatte benchmark 用于 matting。
- Baselines:Text-to-Intrinsic 对比 IntrinsiX;Text-to-RGBA 对比 LayerDiffuse;inverse/forward rendering 对比 RGBX、Diffusion Renderer、Ouroboros,并在 normal 上加入 Stable Normal、Lotus、NormalCrafter;albedo on MAW 对比 Bell et al., Li et al., Sengupta et al., NIID, IntrinsicAnything, Diffusion Renderer, Ouroboros 等;normal on Sintel 对比 DSINE、GeoWizard、GenPercept、Stable-Normal、Marigold-E2E-FT、Lotus、NormalCrafter;video matting 对比 MG methods(AdaM、FTP-VM、MaGGIe、MatAnyone)和 AF methods(RVM、MODNet、VMFormer)。
- Metrics:Text-to-X 使用 VBench Temporal Flickering(0–1,越高越稳定)和 1–10 分 user study(visual quality、TA=text alignment、MC=modality consistency)。Inverse/forward rendering 使用 PSNR、SSIM、LPIPS;normal 使用 MAE 和 阈值准确率;MAW albedo 使用 Intensity error 与 Chromaticity;video matting 使用 MAD、MSE、Grad、dtSSD、Conn,均越低越好。
- Training config:backbone 为 Wan2.1-T2V-14B;DGL LoRA rank 为 32,目标模块为
self_attn.q,self_attn.k,self_attn.v,self_attn.o,ffn.0,ffn.2,总 trainable parameters 为 385M;optimizer 为 AdamW(,weight decay ),Cosine Annealing 将 learning rate 从 衰减到 ;训练使用 4× NVIDIA H100 GPUs、BF16 mixed precision、每 GPU batch size 1、21 frames;UniVid-Intrinsic 训练 6,000 steps,UniVid-Alpha 训练 5,000 steps。
5. Experimental Results (实验结果)
5.1 Text-to-X generation

Figure 3 解读:图 3 对比 text-to-intrinsic。IntrinsiX 在多个样例中出现 RGB、albedo、normal 不对齐或细节不稳定;UniVid-Intrinsic 同时生成视频和 intrinsic maps,猫毛、几何边界和 illumination 更一致,体现 CMSA 对跨模态一致性的收益。

Figure 4 解读:图 4 展示 text-to-RGBA。LayerDiffuse 是 image-level baseline,且常需要为不同 layer 写不同 prompts;UniVid-Alpha 生成动态 BL/FG/BG/alpha 视频,并能用 shared prompt 保持 layer separation,说明 DGL 的模态解耦对 RGBA 层分离很关键。
| Task | Method | Temporal Flickering | User study visual quality | TA | MC |
|---|---|---|---|---|---|
| Text-to-Intrinsic | IntrinsiX | - / - / - | RGB 7.82, Albedo 8.44, Normal 8.12 | 8.65 | 7.02 |
| Text-to-Intrinsic | UniVid-Intrinsic | RGB 0.9876, Albedo 0.9885, Normal 0.9874 | RGB 9.34, Albedo 9.23, Normal 9.17 | 9.04 | 9.29 |
| Text-to-RGBA | LayerDiffuse | - / - / - | BL 9.12, FG 8.91, BG 8.41 | 8.89 | 8.61 |
| Text-to-RGBA | UniVid-Alpha | BL 0.9912, FG 0.9954, BG 0.9891 | BL 9.30, FG 9.12, BG 9.25 | 9.04 | 9.35 |
关键结论:两个 text-to-X 任务中,UniVidX 在 user study 的 visual quality、text alignment 和 modality consistency 上都优于对应 image baseline;Temporal Flickering 接近 1.0,说明其输出视频稳定性是 image baseline 不具备的优势。
5.2 Inverse rendering / forward rendering / albedo / normal

Figure 5 解读:图 5 展示 albedo estimation。UniVid-Intrinsic 的 albedo 更接近 ground truth,尤其在材质颜色和局部边界上比 RGBX、Diffusion Renderer、Ouroboros 更干净。

Figure 6 解读:图 6 展示 irradiance estimation。相比其他方法,UniVid-Intrinsic 的光照分量更稳定,减少了把纹理误当光照的泄漏。

Figure 7 解读:图 7 展示 normal estimation。UniVid-Intrinsic 更好保留几何边缘和细节,说明 VDM prior 加上 normal target LoRA 后能迁移到几何预测。

Figure 8 解读:图 8 展示由 intrinsic maps forward rendering 回 RGB 的结果。UniVid-Intrinsic 的重建 RGB 更接近 ground truth,说明它学习的 albedo/irradiance/normal 不是孤立好看,而是能组合回物理一致的 RGB。

Figure 9 解读:图 9 是 cinematic video sequence 的 normal 对比。Stable Normal、Lotus、NormalCrafter 等专用方法在时间稳定性或细节上仍有问题;UniVid-Intrinsic 能保持较连续的 normals,并恢复人脸等高频几何。
| Method | Albedo PSNR | Albedo LPIPS | Albedo SSIM | Irradiance PSNR | Irradiance LPIPS | Irradiance SSIM | Normal MAE | Normal | Forward PSNR | Forward LPIPS | Forward SSIM |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RGBX | 11.64 | 0.3324 | 0.6462 | 11.29 | 0.3734 | 0.7182 | 18.48 | 50.88 | 13.48 | 0.2728 | 0.6842 |
| Stable Normal | - | - | - | - | - | - | 13.68 | 61.23 | - | - | - |
| Lotus | - | - | - | - | - | - | 14.51 | 58.21 | - | - | - |
| NormalCrafter | - | - | - | - | - | - | 12.49 | 64.13 | - | - | - |
| Diffusion Renderer | 13.59 | 0.2624 | 0.6817 | - | - | - | 15.76 | 54.42 | 9.87 | 0.2920 | 0.6142 |
| Ouroboros | 14.21 | 0.2639 | 0.7063 | 9.7309 | 0.4560 | 0.6460 | 14.52 | 57.58 | 13.15 | 0.2701 | 0.6700 |
| UniVid-Intrinsic | 16.89 | 0.2248 | 0.7812 | 13.46 | 0.3674 | 0.7895 | 11.09 | 70.52 | 15.31 | 0.2567 | 0.7031 |
MAW real-world albedo:UniVid-Intrinsic 的 Intensity error 为 0.44(表内最佳),Chromaticity 为 3.60(第三);Diffusion Renderer 为 0.46 / 3.53,Ouroboros 为 0.48 / 5.47,Colorful 为 0.54 / 3.37。这个结果重要,因为 UniVid-Intrinsic 只在 synthetic InteriorVid 上训练,却能迁移到真实 MAW benchmark。
Sintel normal:UniVid-Intrinsic 使用 19K training frames,Mean 33.5、Med 25.8、 21.6、 43.2、 57.3、Rank 3.1。NormalCrafter 最强但使用 860K frames,Mean 30.7、Med 23.9、 23.5、 47.5、 60.1、Rank 1.0;论文强调 UniVid-Intrinsic 的训练帧数少 45×+,数据效率更高。
5.3 Video matting

Figure 10 解读:图 10 是 auxiliary-free video matting 对比。RVM、MODNet、VMFormer 等 AF 方法容易出现背景泄漏和边缘 artifacts;UniVid-Alpha 只用 RGB 输入也能得到更干净的 matte,尤其在多人和复杂背景中更稳。
| Method | Type | MAD | MSE | Grad | dtSSD | Conn |
|---|---|---|---|---|---|---|
| AdaM | MG | 4.80 | 0.76 | 2.15 | 1.45 | 0.30 |
| FTP-VM | MG | 7.45 | 2.14 | 4.76 | 2.07 | 0.31 |
| MaGGIe | MG | 4.46 | 0.80 | 2.41 | 1.46 | 0.31 |
| MatAnyone | MG | 4.37 | 0.74 | 2.57 | 1.42 | 0.26 |
| RVM | AF | 5.47 | 0.78 | 2.64 | 1.61 | 0.30 |
| MODNet | AF | 10.11 | 4.80 | 5.53 | 2.44 | 0.81 |
| VM-Former | AF | 6.25 | 1.48 | 3.13 | 2.24 | 0.37 |
| UniVid-Alpha | AF | 4.24 | 0.69 | 1.86 | 1.39 | 0.52 |
关键结论:UniVid-Alpha 在 MAD、MSE、Grad、dtSSD 上取得表内最佳,并且作为 auxiliary-free method 仍优于多种 mask-guided methods;Conn 不是最佳(0.52,MatAnyone 为 0.26),说明边通性指标仍有提升空间。
5.4 Ablation studies

Figure 11 解读:图 11 说明为什么不用 channel-concatenation。把多模态 latents 沿 channel 拼接需要改输入/输出结构,有限数据下会破坏 VDM prior,导致 albedo 或 FG 直接崩坏;UniVidX 沿 batch 维组织模态,保持 backbone 结构不变,因此更适合少数据迁移。

Figure 12 解读:图 12 对比 DGL decoupling。LayerDiffuse 和 w/o Dec. 在 shared prompt 下容易 FG/BG 混淆;UniVid-Alpha 在 distinct prompt 与 shared prompt 下都能保持层分离,说明 per-modality LoRA 比共享 LoRA 更能隔离不同模态分布。

Figure 13 解读:图 13 可视化第 20 个 DiT block、denoising step 25/50 的 CMSA attention maps。完整模型中 FG branch 关注前景主体、BG branch 关注背景;w/o Dec. 的 attention map 更混乱,说明缺少 decoupled adapters 会导致跨层/跨模态 feature leakage。

Figure 14 解读:图 14 对比 w/o Gating。若 LoRA 对 clean condition 也持续打开,backbone 原生编码能力被扰动,normal 中会出现错误背景和纹理损失;完整 gating 只在 target 上启用 LoRA,能更好复用原始 VDM prior。

Figure 15 解读:图 15 对比 CMSA 和 vanilla self-attention。vanilla attention 各模态独立处理,导致 RGB、albedo、irradiance、normal 的结构细节不一致;CMSA 共享 K/V 后,宇航服等细节在多个模态之间保持对齐。
| Gating ablation | Albedo PSNR | Albedo LPIPS | Albedo SSIM | Irradiance PSNR | Irradiance LPIPS | Irradiance SSIM | Normal MAE | Normal |
|---|---|---|---|---|---|---|---|---|
| w/o Gating | 15.02 | 0.2884 | 0.7112 | 12.04 | 0.4012 | 0.7058 | 13.01 | 59.75 |
| UniVid-Intrinsic | 16.89 | 0.2248 | 0.7812 | 13.46 | 0.3674 | 0.7895 | 11.09 | 70.52 |
消融结论:去掉 gating 后 albedo PSNR 从 16.89 降到 15.02(下降 1.87 dB),normal 从 70.52 降到 59.75;去掉 decoupling 会导致 FG/BG 和 layer semantics 混淆;换成 vanilla attention 会削弱跨模态几何/外观对齐;channel-concatenation 在少数据条件下直接破坏 prior。
5.5 Multi-condition perception、applications 与 limitations

Figure 16 解读:图 16 展示 multi-condition perception 的价值。只有 RGB 时,远处模糊星球被误判为空天空;加入 albedo 作为结构约束后,normal 能恢复该物体几何,说明 UniVidX 的灵活输入路径可以缓解 inverse rendering 的歧义。

Figure 17 解读:图 17 是 UniVid-Intrinsic 的 video relighting:先从 RGB 做 inverse rendering 得到 albedo 和 normal,再以目标文本控制新的 irradiance/RGB;albedo 和 normal 锁定材质与几何,文本主要改变光照。

Figure 18 解读:图 18 是 text-driven video retexturing:先 text-to-intrinsic 生成完整 intrinsic stack,再冻结 normal/irradiance 作为条件,重生成 RGB/albedo;这允许改外观而保持几何和光照结构。

Figure 19 解读:图 19 是 material editing:先把输入 RGB 分解成 intrinsic maps,手工修改 albedo/normal,再用原 irradiance 做 forward rendering;这展示了 UniVidX 不只是 perception 模型,也可作为可控 renderer。

Figure 20 解读:图 20 是 UniVid-Alpha 的 video inpainting:先分解得到 alpha/background,再以 alpha 和 background 约束新前景和 BL;alpha 提供空间边界,background 保留原场景上下文。

Figure 21 解读:图 21 是 background replacement:从源 prompt 得到 alpha/foreground 后,用新背景 prompt 生成 background 和最终 BL,体现 foreground 与 background 可以分开控制。
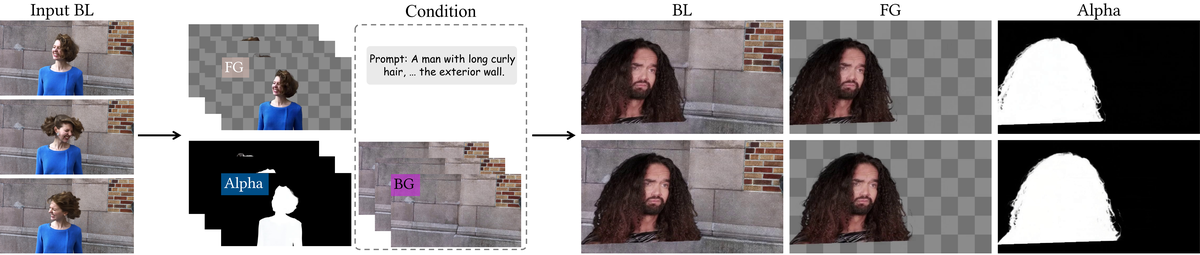
Figure 22 解读:图 22 是 foreground replacement:先从输入视频提取 background,再用目标 foreground prompt 生成新的 blended RGB、foreground 和 alpha,适合在固定场景中替换主体。

Figure 23 解读:图 23 是 failure cases。UniVid-Intrinsic 对透明玻璃的 normal 有空间不一致:能重建靠右玻璃,但中心玻璃盖会错误穿透到内部细节;UniVid-Alpha 对透明冰块能生成合理 BL/FG,却把 alpha 预测成完全不透明。作者将这归因于训练数据偏置:InteriorVid 中中心区域常是高频物体,VideoMatte240K 主要是人像 matte,缺少半透明物体标签。
总体结论:UniVidX 证明了一个强命题——VDM prior 可以通过 SCM+DGL+CMSA 被改造成统一 multimodal video generation/perception 框架,并在少数据下覆盖 30 个方向性任务(两个实例各 15 个)。但当前仍有三类限制:一是 intrinsic 和 alpha 因缺少联合标注数据而训练为两个模型;二是 14B backbone 带来显存压力,当前最多处理 4 个模态、21 frames、480p;三是强依赖 VDM prior 和小规模 domain data,透明玻璃、半透明物体等 corner cases 会受数据分布偏置影响。