1. Motivation (研究动机)
现有 autoregressive streaming video diffusion 解决了长视频逐块生成的问题,但仍依赖 distillation 才能达到可交互速度;主流 Distribution Matching Distillation (DMD) 又把每个 rollout、每一帧、每个像素都当作同等可靠的监督。论文指出这会把两个本应分开的决策混在一起:是否应该从这个 rollout 学,以及应该在该 rollout 的哪些时空位置投入更多优化。
具体瓶颈有两类。第一是 Inter-Reliability:DMD 梯度 只是 teacher/student score 的估计;当 student rollout 已靠近 teacher 高质量模式时, 给出的局部修正更可信,但当 rollout 已落在低质量区域时,teacher denoiser 只能做局部低质量修补,梯度未必指向高质量模式。第二是 Intra-Perplexity:同一个视频内部,不同空间区域和时间帧的质量缺陷不同;uniform pixel/frame loss 会在 reward 已接近饱和的区域浪费梯度预算,却低估更值得修复的缺陷区域。
Stream-R1 要解决的具体目标是:在不改 student 架构、不增加推理成本的前提下,把 reward model 的标量评价和梯度敏感性注入 DMD loss,使 streaming video generator 在 4-step causal 生成速度下仍能提升视觉质量、运动一致性和文本对齐。这个问题值得研究,因为一旦 distillation 不再只是“压缩 teacher”,而能有选择地追高 reward 区域,few-step streaming video model 就可能同时获得长视频可扩展性、低延迟和接近/超过 teacher 的质量。
2. Idea (核心思想)
核心 insight:DMD supervision 不是均质信号;高 reward rollout 更可能提供可靠的 score-matching 梯度,而 reward 对输入更敏感的时空位置更可能是当前仍有提升空间的“高困惑度”区域。Stream-R1 用同一个 pretrained video reward model 同时回答 “learn from which rollout” 和 “optimize which pixels/frames”。
关键创新可以概括为三步:用 在 rollout 层面做 Inter-Reliability reweighting;对 reward model 反传,得到 VQ/MQ/TA 三个质量轴的 pixel/patch saliency;再把 saliency 分解为空间权重和时间权重,形成 去调制 DMD element-wise loss。与 Reward Forcing 这类只使用全局 scalar reward 的方法不同,Stream-R1 不只是把整个视频的 loss 放大/缩小,而是把 reward 信号局部化到帧和区域。
3. Method (方法)
3.1 Overall framework
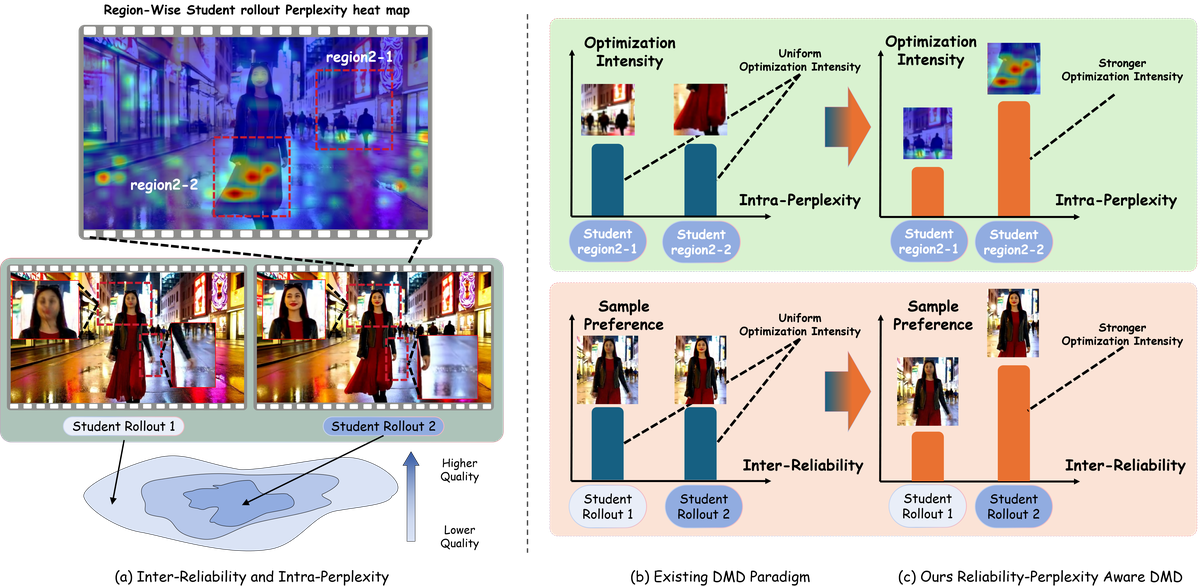
Figure 1 解读:左侧说明 DMD supervision 同时存在 rollout 间可靠性差异和 rollout 内时空困惑度差异;中间展示传统 DMD 把所有样本、所有区域等权处理;右侧展示 Stream-R1 的目标:高可靠 rollout 得到更大 sample preference,高困惑度区域得到更高 optimization intensity。这个图是论文的动机图,不是完整架构,但明确了两个 reweighting 维度。
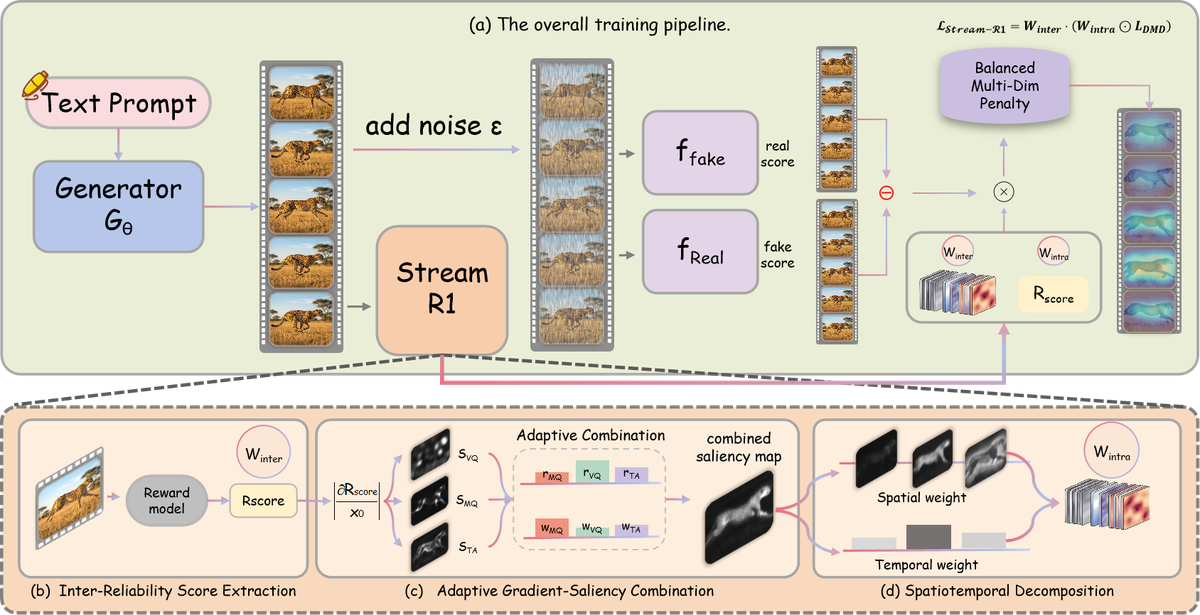
Figure 2 解读:上半部分是训练链路:student generator 产生 fake rollout,经 DMD 的 与 得到基础 distillation signal;Stream-R1 module 额外从同一 rollout 计算 和 ,最终形成 。下半部分拆开 Stream-R1 module:reward score extraction 产生全局可靠性分数和三轴 saliency;adaptive combination 按当前弱项融合 saliency;spatiotemporal decomposition 把统一 saliency map 分解为 frame-level temporal weight 与 per-frame spatial weight。
基础 DMD 设置中,student 生成 clean latent ,在随机 timestep 加噪得到 ,real/fake critic 估计 score functions:
基础 distillation loss 是:
其中 是 normalized gradient, 是 stop-gradient。
3.2 Inter-Reliability weighting
Stream-R1 用 reward score 作为 rollout supervision reliability 的 proxy。若 reward model 认为当前 student rollout 已位于高质量区域,那么 teacher denoiser 的局部修正更可能接近高质量 mode 的残差方向;反之,低 reward rollout 的 DMD gradient 可能只是低质量区域内部的修补。
给定质量维度集合 ,最终 reward 来自 Eq. (12) 的 balanced multi-dimensional reward。rollout-level 权重为:
控制重加权锐度。论文实验设置写的是 reward mode = Overall(VQ/MQ/TA 平均)且 beta = 2.0;released code 的 configs/exp_stream_r1.yaml 在此基础上使用 reward_mode: BalancedOverall,会额外启用 improvement-balance penalty。
3.3 Adaptive gradient-saliency combination
Intra-Perplexity 的直觉是:reward 对输入梯度大的区域,是 reward landscape 尚未 flatten、局部扰动最能改变质量评分的位置,因此也是更值得优化的位置。对每个质量维度 ,reward model 输出 scalar score ,其 saliency 为:
三轴 saliency 不是简单平均,而是对低分维度分配更高权重:
当 时近似只关注当前最差质量轴;当 时退化为均匀平均。论文实验使用 ;spatial minimum weight ,temporal minimum weight 。
3.4 Spatiotemporal saliency decomposition
Stream-R1 不直接全局 normalize ,因为全局归一化会把“哪一帧整体更重要”和“同一帧内哪块区域更重要”缠在一起。论文把 saliency 拆成 temporal profile 和 per-frame spatial map。
Temporal profile 先对空间平均:
再 min-max normalize,并用 floor 防止某帧完全被抑制:
随后对 做 mean-normalization,使平均 loss scale 保持不变。空间权重在每一帧内部独立归一化:
最终 element weight 为:
这种分解的直觉是:temporal weight 决定哪一段/哪一帧应该得到更多训练信号,spatial weight 决定该帧内部该修哪里;二者都归一化,避免引入无意义的 loss scale 变化。
3.5 Balanced multi-dimensional reward
直接平均 VQ/MQ/TA 可能导致优化偏向最容易提升的维度。Stream-R1 在滑动窗口中记录各维度 reward,比较窗口前后两半的均值差:
平衡惩罚为各维度 improvement 的标准差:
最终 reward:
该 penalty 在 warmup 后才启用;代码默认 reward_balance_window=50、reward_balance_warmup=50、reward_balance_lambda=0.5。
3.6 Overall objective
完整 generator loss 为:
会 broadcast 到 channel 维度。reward saliency 只在训练时需要一次 reward model backward,推理时没有额外开销。
3.7 Pseudocode from released code
Inter-Reliability 与基础 DMD loss(对应 model/stream_r1.py::compute_rewarded_distribution_matching_loss):
import torch
import torch.nn.functional as F
def stream_r1_dmd_loss(model, latent, pixels, prompt, cond, uncond, beta=2.0):
videos = ((pixels + 1.0) / 2.0).clamp(0, 1)
reward = model.inferencer.reward_from_frames([videos[0]], [prompt], use_norm=True)
timestep = model.sample_dmd_timestep(latent)
noisy = model.scheduler.add_noise(latent, torch.randn_like(latent), timestep)
grad = model.compute_kl_grad(noisy, latent, timestep, cond, uncond)
combined_reward = select_reward(reward, mode=model.reward_mode)
if model.reward_mode == "BalancedOverall":
combined_reward = apply_balance_penalty(model, combined_reward, reward)
target = (latent.double() - grad.double()).detach()
element_loss = (latent.double() - target) ** 2
if model.spatial_reward:
weight = compute_intra_weight(model, videos, prompt, reward, latent.shape)
weighted = weight.double() * element_loss
else:
weighted = element_loss
return 0.5 * torch.exp(beta * combined_reward) * weighted.mean()Adaptive saliency fusion(对应 model/stream_r1.py::_compute_spatial_reward_mask 与 videoalign/wan_inference.py::compute_pixel_spatial_saliency):
def compute_adaptive_saliency(inferencer, videos, prompt, reward, latent_shape):
saliency_maps = inferencer.compute_pixel_spatial_saliency(
[videos[0]], [prompt], metrics=("MQ", "VQ", "TA"), latent_shape=latent_shape
)
reward_vals = torch.tensor(
[reward[m].item() for m in ("MQ", "VQ", "TA")],
device=videos.device,
dtype=torch.float32,
)
alpha = torch.softmax(-reward_vals / 1.0, dim=0)
combined = sum(alpha[i].item() * saliency_maps[m].to(videos.device).float()
for i, m in enumerate(("MQ", "VQ", "TA")))
return combinedSpatiotemporal decomposition(对应 model/stream_r1.py::_compute_spatial_reward_mask):
def decompose_spatiotemporal_weight(combined, sigma_min=0.15, tau_min=0.20):
temporal_profile = combined.mean(dim=(1, 2))
t_min, t_max = temporal_profile.min(), temporal_profile.max()
if t_max - t_min > 1e-8:
temporal = (temporal_profile - t_min) / (t_max - t_min)
else:
temporal = torch.ones_like(temporal_profile)
temporal = temporal.clamp(min=tau_min)
temporal = temporal / temporal.mean()
spatial = torch.empty_like(combined)
for f in range(combined.shape[0]):
frame = combined[f]
f_min, f_max = frame.min(), frame.max()
spatial[f] = (frame - f_min) / (f_max - f_min) if f_max - f_min > 1e-8 else torch.ones_like(frame)
spatial = spatial.clamp(min=sigma_min)
spatial = spatial / spatial.mean(dim=(1, 2), keepdim=True)
final_weight = temporal[:, None, None] * spatial
final_weight = final_weight / final_weight.mean()
return final_weight[None, :, None] # [1, F, 1, H, W]BalancedOverall reward(对应 model/stream_r1.py::_apply_balance_penalty):
def apply_balance_penalty(state, combined_reward, reward_dict):
state.balance_step += 1
for dim in state.reward_dims:
state.reward_history[dim].append(float(reward_dict[dim].item()))
if state.balance_step < state.reward_balance_warmup:
return combined_reward
if not all(len(state.reward_history[d]) >= 4 for d in state.reward_dims):
return combined_reward
deltas = []
for dim in state.reward_dims:
hist = list(state.reward_history[dim])
half = max(1, len(hist) // 2)
baseline = sum(hist[:half]) / half
recent = sum(hist[half:]) / max(1, len(hist) - half)
deltas.append(recent - baseline)
penalty = torch.tensor(deltas, device=combined_reward.device).std()
return combined_reward - state.reward_balance_lambda * penaltyCode reference:
main@b5e3982b(2026-05-06) — pseudocode and mapping based on this commit
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Stream-R1 generator/fake-score model | model/stream_r1.py | StreamR1 |
| DMD gradient and rewarded DMD loss | model/stream_r1.py | _compute_kl_grad, compute_rewarded_distribution_matching_loss |
| Inter-Reliability exponential multiplier | model/stream_r1.py | torch.exp(beta * combined_reward) in compute_rewarded_distribution_matching_loss |
| Adaptive saliency fusion and | model/stream_r1.py | _compute_spatial_reward_mask |
| BalancedOverall reward penalty | model/stream_r1.py | _select_reward, _apply_balance_penalty |
| Pixel/patch saliency through VideoReward | videoalign/wan_inference.py | reward_from_frames, compute_pixel_spatial_saliency, compute_spatial_saliency |
| Training loop and logging | trainer/rewarded_distillation.py | Trainer, fwdbwd_one_step, train |
| Experiment configuration | configs/exp_stream_r1.yaml | reward_mode, spatial_reward_*, temporal_saliency_*, beta |
| Launcher | run_stream_r1.sh | run_experiment, make_config |

Figure 5 解读:图中把 Gaussian blur 注入每帧下半部分,并让模糊区域从左到右逐步扩大。上排 reward-gradient saliency 会逐渐转向更大的退化区域;下排 temporal weights 从 0.587 增长到 2.117,说明 确实会把更多训练信号分配给质量缺陷更严重的帧,而不是手工指定某些位置。
4. Experimental Setup (实验设置)
- Training data:filtered VidProM prompts,并用 LLM-based prompt rewriting 做增强;student 初始化来自 16k ODE solution pairs 训练出的 ODE regression checkpoint。
- Models / generation setup:student 为 Wan2.1-T2V-1.3B,teacher 为 Wan2.1-T2V-14B;生成 5-second videos at ;chunk-wise denoising,每 chunk 3 latent frames,denoising steps 为 ,attention window size 为 9。
- Training config:8×A100,1,000 optimizer steps;per-GPU batch size 1,gradient accumulation 8,有效 batch size 64;AdamW,generator LR ,fake score LR ;generator 每 5 steps 更新;EMA decay 0.99,从 step 200 开始;总训练约 56 hours。
- Evaluation:短视频用 946 official VBench prompts,每个 prompt 5 seeds;长视频用 MovieGen Video Bench 前 128 prompts,评估 10s/30s/60s/120s/180s autoregressive generation;额外用 Qwen3-VL-235B-A22B-Instruct 对 60s 视频打分,并在 50 个 60s 长视频上做 5 annotators human preference。
Baselines 包括 diffusion models:LTX-Video、Wan2.1;autoregressive/streaming models:SkyReels-V2、MAGI-1、NOVA、Pyramid Flow、CausVid、Self Forcing、LongLive、Rolling Forcing;reward-guided distillation baseline:Reward Forcing。指标包括 VBench Total/Quality/Semantic、长视频六个 VBench per-metric scores、VLM Visual/Dynamic/Text,以及 human preference 的 Temporal Consistency、Dynamic Reasonableness、Visual Quality & Aesthetics、Text-Video Alignment、Overall Preference。
5. Experimental Results (实验结果)
5.1 Short video VBench
| Model | Params | FPS↑ | Total↑ | Quality↑ | Semantic↑ |
|---|---|---|---|---|---|
| LTX-Video | 1.9B | 8.98 | 80.00 | 82.30 | 70.79 |
| Wan2.1 | 1.3B | 0.78 | 84.26 | 85.30 | 80.09 |
| SkyReels-V2 | 1.3B | 0.49 | 82.67 | 84.70 | 74.53 |
| MAGI-1 | 4.5B | 0.19 | 79.18 | 82.04 | 67.74 |
| NOVA | 0.6B | 0.88 | 80.12 | 80.39 | 79.05 |
| Pyramid Flow | 2B | 6.7 | 81.72 | 84.74 | 69.62 |
| CausVid | 1.3B | 17.0 | 82.88 | 83.93 | 78.69 |
| Self Forcing | 1.3B | 17.0 | 83.80 | 84.59 | 80.64 |
| LongLive | 1.3B | 20.7 | 83.22 | 83.68 | 81.37 |
| Rolling Forcing | 1.3B | 17.5 | 81.22 | 84.08 | 69.78 |
| Reward Forcing | 1.3B | 23.1 | 84.13 | 84.84 | 81.32 |
| Stream-R1 | 1.3B | 23.1 | 84.40 | 85.14 | 81.44 |
Stream-R1 在 Total 上达到 84.40,超过 Wan2.1 teacher 的 84.26 和 Reward Forcing 的 84.13;Quality 达到 85.14,在 streaming/autoregressive models 中最高;Semantic 达到 81.44,为所有方法最高。相对 Reward Forcing,同时提升 Total/Quality/Semantic:+0.27/+0.30/+0.12。论文强调 4-step distilled student 以 23.1 FPS 超过 0.78 FPS multi-step teacher 的 Total 与 Semantic,约 30× speedup。
5.2 Long video / VLM / human results
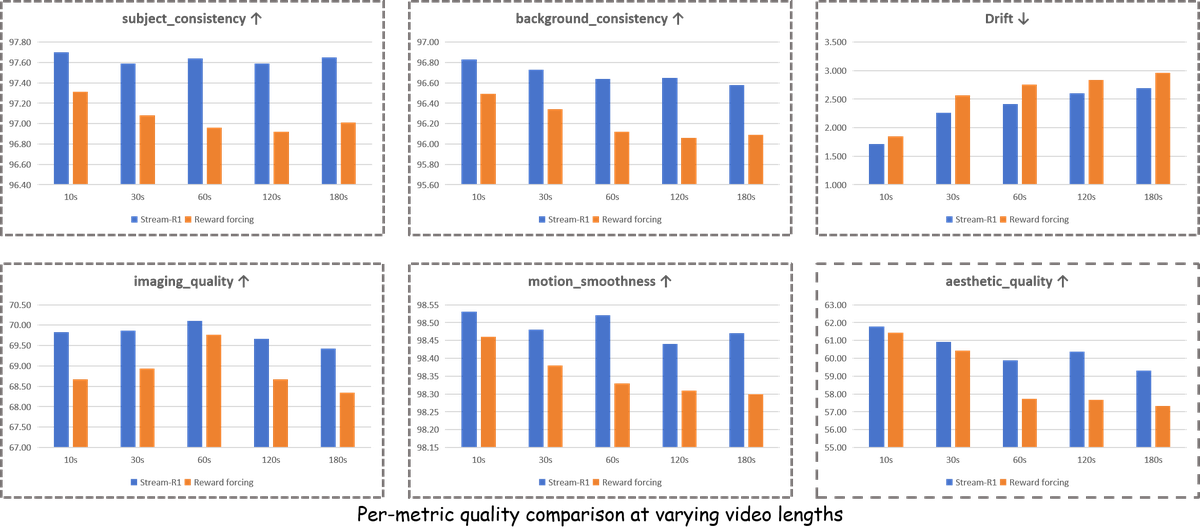
Figure 4 解读:图中比较 10s 到 180s 不同时长下的六个 VBench 指标,Stream-R1 蓝色柱在每个时长、每个指标上都高于 Reward Forcing 橙色柱。差距在 120s 和 180s 更明显,说明 temporal saliency weighting 不只是改善单帧质量,也减缓 autoregressive rollout 的长期质量漂移。
| Model | Visual↑ | Dynamic↑ | Text↑ |
|---|---|---|---|
| SkyReels-V2 | 3.30 | 3.05 | 2.70 |
| CausVid | 4.66 | 3.16 | 3.32 |
| Self Forcing | 3.89 | 3.44 | 3.11 |
| LongLive | 4.79 | 3.81 | 3.98 |
| Reward Forcing | 4.82 | 4.18 | 4.04 |
| Stream-R1 | 4.92 | 4.04 | 4.11 |
Qwen3-VL evaluation 中,Stream-R1 的 Visual=4.92、Text=4.11 为最高,Dynamic=4.04 低于 Reward Forcing 的 4.18 但仍为第二。论文解释这符合 multi-dimensional reward 的 balanced profile:不把所有优化都压到单一运动指标上。
| Dimension | Win | Tie | Lose | Win Rate |
|---|---|---|---|---|
| Temporal Consistency | 25 | 1 | 24 | 51.0% |
| Dynamic Reasonableness | 30 | 3 | 17 | 63.0% |
| Visual Quality & Aesthetics | 29 | 2 | 19 | 60.0% |
| Text-Video Alignment | 22 | 9 | 18 | 54.1% |
| Overall Preference | 28 | 1 | 21 | 57.0% |
Human preference 在五个维度全部偏向 Stream-R1,最大提升来自 Dynamic Reasonableness 63.0% 和 Visual Quality & Aesthetics 60.0%。这补充了自动指标的局限:flow-based dynamic score 未必区分 camera motion 和 subject motion,而人工判断更关注可感知运动合理性。

Figure 3 解读:每组上排是 Reward Forcing,下排是 Stream-R1。论文用该图展示长视频中 Stream-R1 的背景、主体外观和运动更稳定,而 Reward Forcing 更容易随时间出现 drift、deformation 或背景不一致。
5.3 Ablation
| Variant | Short Total↑ | Short Quality↑ | Short Semantic↑ | Long Total↑ | Drift↓ |
|---|---|---|---|---|---|
| Baseline | 83.44 | 84.16 | 80.55 | 79.45 | 2.479 |
| + Spatial reward () | 83.67 | 84.46 | 80.51 | 80.71 | 2.653 |
| + Balanced Multi-Dim reward () | 83.67 | 84.45 | 80.54 | 80.72 | 2.651 |
| + Temporal reward () [Full] | 84.40 | 85.14 | 81.44 | 80.86 | 2.417 |
| (spatial only) | 83.68 | 84.44 | 80.62 | 80.73 | 2.697 |
| 83.42 | 84.21 | 80.24 | 80.40 | 2.475 |
Spatial saliency 把 Short Quality 从 84.16 提到 84.46,Long Total 从 79.45 提到 80.71。Balanced Multi-Dim reward 主要把 Semantic 从 80.51 小幅提升到 80.54,并基本维持 Quality/Long Total;表中 80.62 属于 的 spatial-only hyperparameter row,不是 Balanced Multi-Dim row。Temporal decomposition 是最大增益来源:Short Total 从 83.68 到 84.40(+0.72),Drift 从 2.697 降到 2.417。 会削弱帧间权重对比,Short Total 降到 83.42,说明 temporal floor 过高会把 temporal saliency 退化为接近 uniform weighting。
作者没有在正文中单列 failure cases;可明确的限制是:训练阶段需要 pretrained VideoReward 的 forward/backward 与 8×A100 约 56 小时训练,且方法质量依赖 reward model 对 VQ/MQ/TA 的可微评分是否与人类偏好一致。总体结论是,Stream-R1 把 DMD 从 indiscriminative matching 改成 reliability-perplexity aware matching,在不改变推理图的条件下提升短视频指标、长视频稳定性和人工偏好。