Seeing Fast and Slow: Learning the Flow of Time in Videos
1. Motivation (研究动机)
当前视觉基础模型在「时间感知」和「时间控制」两个层面都存在系统性缺口:
-
现有方法的问题:视频领域的主流模型绝大多数训练于 24–60 fps 的标准帧率视频(WebVid-10M、Panda-70M、OpenVid-1M 等),模型从未见过”不同播放速度”这一维度的数据。因此:
- VLM(如 Gemini 2.5)在判断”视频是否被加速/减速”、“加速了多少倍”这类问题上容易产生幻觉或预测错误(论文实验显示 Gemini 2.5 在速度变化检测上只有 59.5% 准确率,在速度估计 Pearson 相关系数仅 0.426)
- 视频生成模型(Wan2.1、Stable Video Diffusion 等)对 “ultra slow-motion”、“slow-motion” 等文本修饰符几乎不敏感,生成的视频速度基本不变,不具备可控时间速度生成能力
- 现有高帧率数据集要么规模过小(Adobe240fps 只有 118 视频),要么场景受限(SportsSloMo 只有体育),要么自采集(X4K1000FPS 仅 175 视频)
-
论文要解决的问题:将”时间流速”(flow of time) 作为一个可学习、可控的视觉概念,具体包含四个子任务:(a) speed-change detection——定位视频中播放速度切换的瞬间;(b) video speed estimation——估计视频相对真实世界被加速/减速的倍数;(c) 极端 temporal super-resolution——把低帧率、有运动模糊的输入转为高帧率清晰视频;(d) speed-conditioned video generation——按给定速度条件合成运动内容。
-
为什么值得研究:一旦模型能感知和操控时间流速,就能解锁 (i) 视频取证(判断片段是否被篡改过速度)、(ii) 可控慢动作视频生成(用户指定 0.01×–1.0× 任意速度)、(iii) 高帧率视频合成用于 VFI(video frame interpolation)以及 (iv) 更丰富的 world model——能真正理解事件在物理世界中以什么速度展开。本文同时贡献了迄今最大的通用慢动作视频数据集 SloMo-44K(44,632 个 clip / 1800 万帧 / 10000+ fps 原始帧率),比 X4K1000FPS 多 250 倍视频数,可作为整个视频研究社区的基础资源。
2. Idea (核心思想)
核心洞察:视频里的”时间流速”可以在不需要人工标注的前提下被自监督地学出来,因为视频自带两条强信号——(i) 音频的时频不变性(time-frequency scaling):加速视频时音频音调升高,减速时降低;(ii) 速度估计对时间重采样的等变性(equivariance under temporal rescaling):如果把视频加速 k 倍,一个合理的 speed predictor 的输出也应该等比例放大 k 倍。
把这两条 inductive bias 变成损失函数,就能从未标注的互联网慢动作视频里自动挖掘”速度变化点”和”播放速度”的伪标签,进而训练出速度理解模型,再用它去过滤、标注互联网上的野生慢动作视频,构建 SloMo-44K,最后用这些高质量数据去微调 Wan2.1-I2V/VACE,获得真正可控播放速度的视频生成器和极端 8× TSR 模型。
与现有方法的根本区别:
- 与 SpeedNet [Benaim 2020]、Pulse-of-Motion [Gao 2026] 这类 “pace classification / FPS prediction” 工作相比,他们训练数据集上限在 240 fps、预测范围只有 {1/2, 1, 2, 4}×,且使用离散分类;本文用连续回归 + 等变自监督损失,能覆盖 0.01×–1× 的广谱速度,且在 Pearson 相关系数上(0.735 vs 0.508)显著超越。
- 与 BulletTime [Wang 2025]、SpaceTimePilot [Huang 2025] 这类”时间编辑”工作相比,它们仅做相对时间重映射(rescale 已有视频的时间轴),无需理解真实物理速度;本文是绝对速度条件生成(从一张图 + prompt + 速度条件直接生成对应真实世界速度的动态),要求模型真正学到物理运动的”真实进度”。
3. Method (方法)
3.1 Overall framework(整体框架)
整个 pipeline 分为三个阶段:
- 感知(Perceiving):训练 speed-change detector(基于 VideoMAEv2)和 speed estimator(自监督 equivariance + 少量校准 + 迭代预测)
- 数据构建(Curating):用上述两个模型把从 YouTube/Vimeo/Flickr 抓来的 18,235 个野生视频切分成播放速度均匀的 clip,过滤掉非慢动作、CGI、低质量内容,最终得到 44,632 clip 的 SloMo-44K,覆盖 18M 帧
- 操控(Manipulating):在 SloMo-44K 上微调 Wan2.1-I2V-14B 得到 speed-conditioned 生成器,微调 Wan2.1-VACE-14B 得到 8× 极端 TSR 模型
直觉解释:为什么”等变性 + 音频时频不变性 + 迭代精化”这套组合能 work?核心观察是慢动作视频本身包含其自身”原始速度”的强信息——只要模型把视频加速一倍,预测出来的速度就必须也跟着变一倍,就强制模型把注意力放到”运动快慢”这个属性上,而不是场景外观。这是一个典型的把数据增广反过来用作监督信号的范式(类似 SimCLR 用裁剪做对比学习),但换成了时间维度。而音频时频关系提供了正交的跨模态校准信号,纠正自监督损失在绝对尺度上的歧义。最后迭代预测的直觉是:模型在训练分布(≈1× 左右)附近估计最准,所以对于 ultra-slow 视频(如 0.02×),先让模型粗估一次速度 x,把视频加速 x 倍拉回到 1× 附近,再让模型二次估计细化——相当于”分治”地把超出训练分布的样本拉回分布内。
3.2 Key components(关键组件)
3.2.1 Speed-change detector(速度变化检测器)

Figure 2 解读:左侧是一段视频对应的音频 spectrogram,横轴时间、纵轴频率;图中可以清晰看到在 speed change 标记处音频能量突然向高频偏移(对应播放速度从 slow-motion → normal 的切换,音调整体升高)。右侧是对应时间点 (a)(b)(c)(d) 的视频”平均图像”:在慢动作部分((a)(b)),相邻帧差异小、平均图几乎清晰;而在正常速度部分((c)(d)),相邻帧之间运动大,平均图变得模糊——这提供了平行于音频的视觉证据:motion blur 的强度本身就是速度的指示器。
做法:
- 音频挖掘伪标签:对于带原声(未被配乐覆盖)的视频,检测 pitch 突变点就能定位速度切换事件,自动收集了 8K+ 速度变化标签
- 用 VideoMAEv2 backbone + binary CE loss 微调二分类器,判断一个 2 秒 clip 的中间 1/3 时段是否包含速度切换
- Inference 时完全不用音频,检测器纯 visual,这样即使面对配乐覆盖的电影素材(如 X-Men 的时间凝固场景)也能工作
3.2.2 Speed estimator(播放速度估计器)
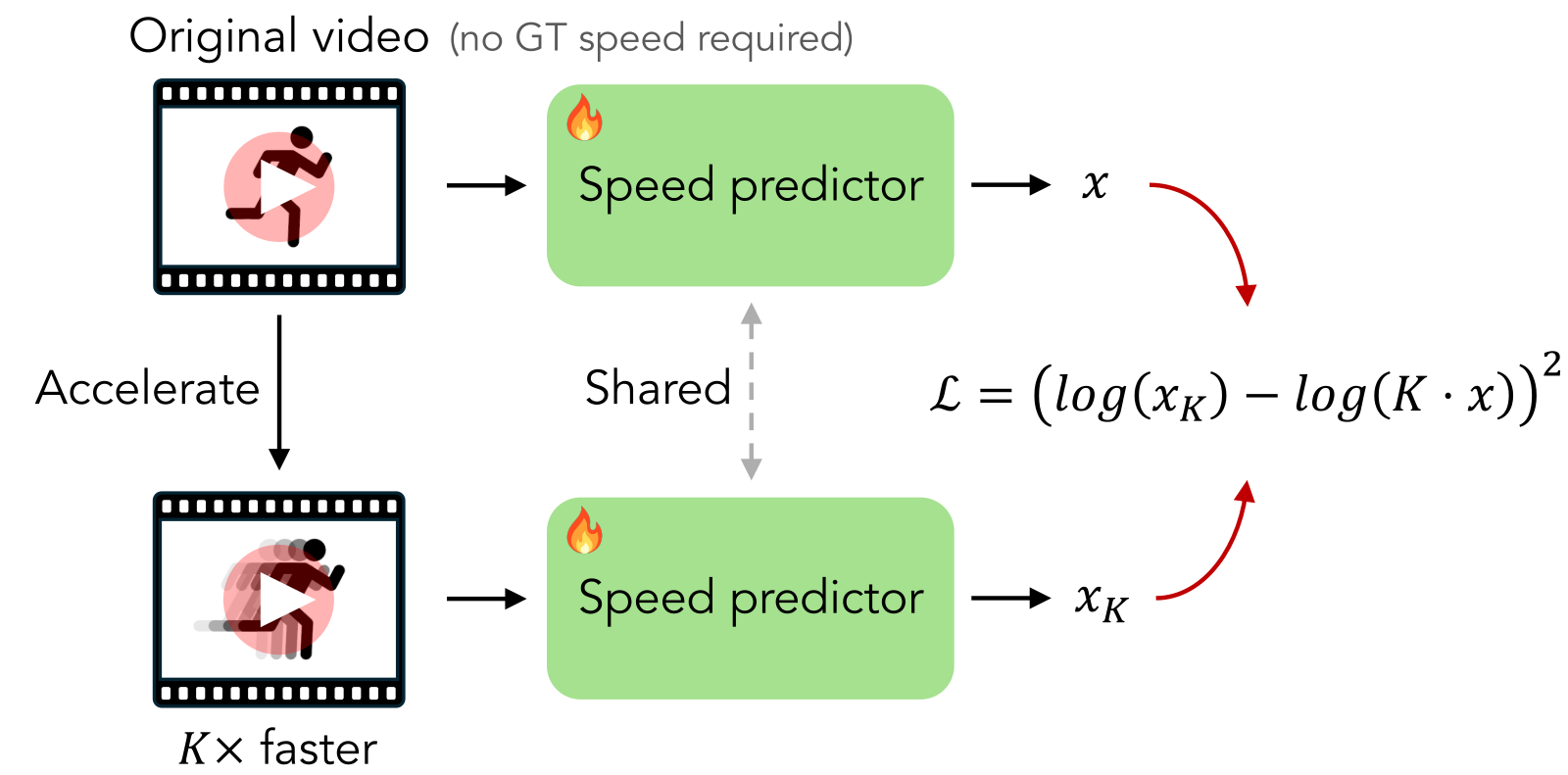
Figure 3 解读:图示自监督训练流程——上支路输入原视频 V 经过 speed predictor 得到预测速度 x;下支路对 V 做 K 倍时间加速(帧采样)得到 ,再过共享权重的 predictor 得到 。约束 应该等于 (在 log 空间约束差的平方),这就是时间重采样的等变性。关键点:没有用到任何真值速度,只用”加速前后的相对关系”作为监督信号。
自监督核心损失(论文 Eq. 1):
其中 是 V 的 k 倍加速版本,,T 是视频总长。在 log 空间做回归,保证速度的尺度不变性(0.5→1 和 2→4 的”误差”应该等价)。
校准(Calibration):纯自监督只能保证”相对正确”,但不能锚定绝对尺度。作者额外用一小部分带真值的 Adobe240fps 数据做有监督正则,同样在 log 空间回归,防止整体预测漂移到错误的绝对标尺。
迭代预测(Iterative Prediction, IP):对于 extreme slow(0.01× 级)视频,motion cue 往往过于微弱,模型第一次预测会严重低估。IP 的做法是——如果第一次预测到速度 x,就把视频加速 x 倍,再让模型预测一次;重复 3 次即可收敛。直觉是把超出训练分布的样本反复”拉回”模型熟悉的 ≈1× 邻域。
3.2.3 SloMo-44K 数据集构建
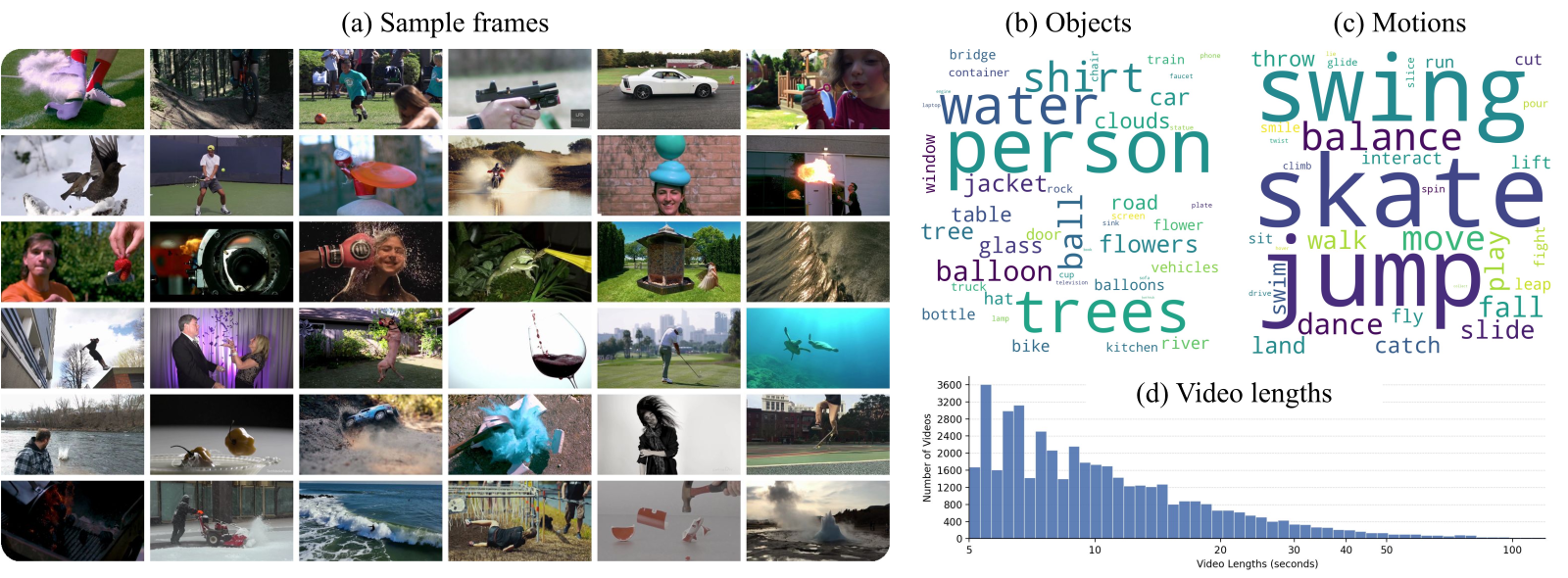
Figure 8 解读:(a) 采样帧网格展示了覆盖的场景丰富度(人物、动物、液体、爆破、机械运动等),(b) 名词词云以 “person, water, trees, balloon” 为主,(c) 动词词云以 “skate, jump, swing, balance” 为主——说明数据明显偏向高动态运动场景;(d) 视频长度分布以 5–15 秒为主,长尾拖到 100 秒。
构建流水线:
- 采集:YouTube、Vimeo、Flickr 用 “slow motion”、“high frame rate”、“high-speed camera” 等关键词搜索
- 粗过滤:TransNetv2 切 shot → OCR 滤字幕 → Qwen2.5-VL 滤 CGI/屏录 → VQA 滤低质量
- 速度均匀化:speed-change detector 把视频按速度变化点切段,保留播放速度均匀的 clip
- 慢动作筛选(本文独有):双模型共识:(a) Gemini 2.5 需要把视频识别为 ≥10% 慢动作;(b) 微调后的 VideoMAEv2 slow-motion 分类器给的 slow-motion 概率需 >0.998。验证集上 Gemini 单独 74.8%、VideoMAEv2 单独 84.4%,组合后达到 98% precision / 44% recall
- 标注:speed estimator 标播放速度 + InternVL3 生成长短双字幕
最终得到 44,632 clips / 18M frames,比既有最大数据集 X4K1000FPS 多 70 倍视频数、150 倍帧数。
3.2.4 Speed-conditioned Video Generation(速度条件视频生成)
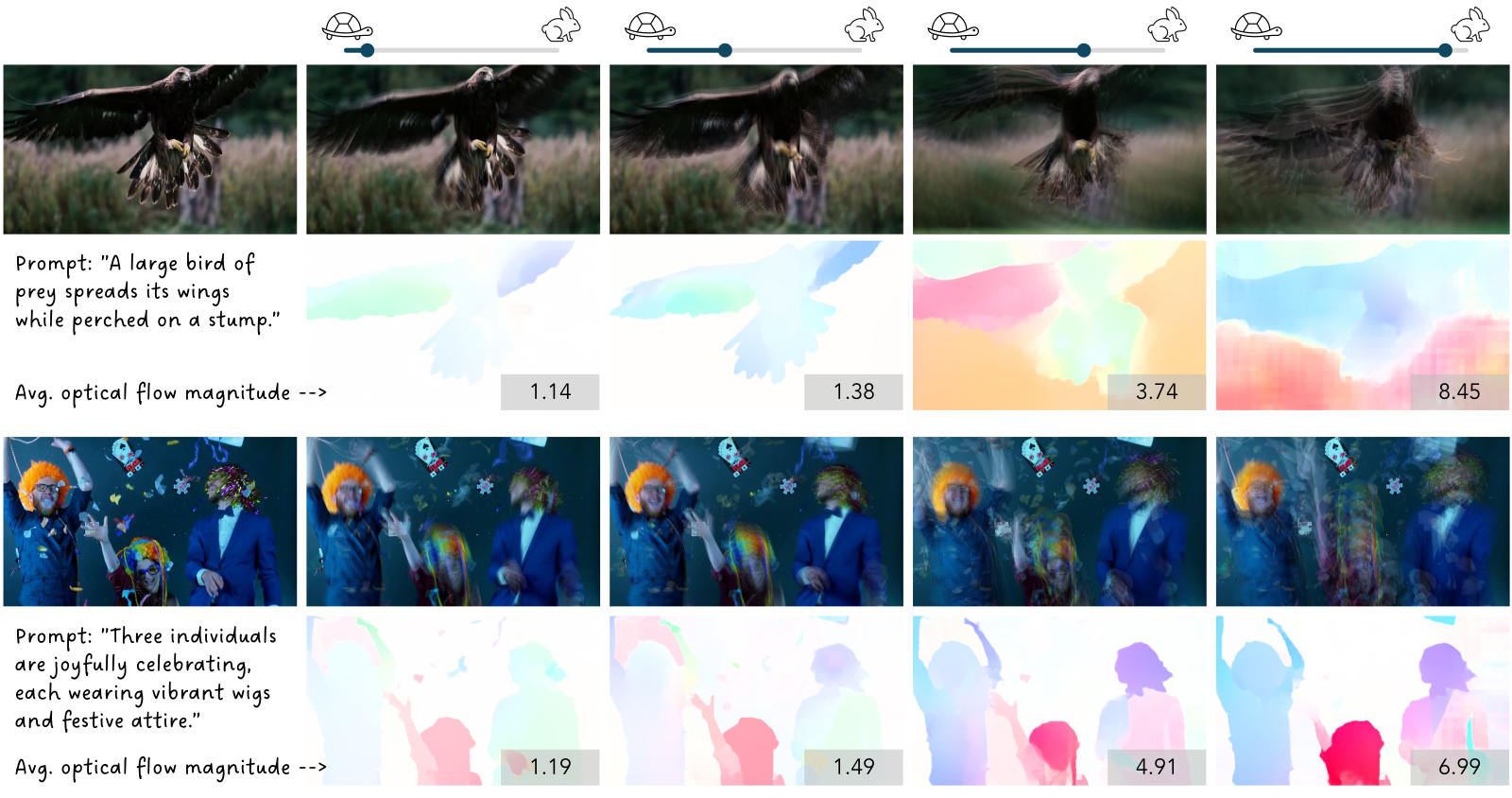
Figure 4 解读:每组两行:第一行是生成视频的”平均图”,第二行是首末帧之间的光流可视化。从左到右速度条件(control value)由小到大(对应 ultra-slow → normal):
- 小速度条件下:平均图保持清晰(场景变化小),光流颜色很淡(motion magnitude 小,如 1.14、1.19)
- 大速度条件下:平均图严重模糊(运动大),光流色彩高度饱和(magnitude 达 8.45、6.99)
这直接证明 speed control signal 被模型显式地学到了,不是 prompt 表面 trick。
做法:基于 Wan2.1-I2V 做两项关键改动。
(1) Bucket embedding:把目标速度先对数分桶(从 0.01× 到 1.0× 分 10 个 log-spaced buckets,与 SloMo-44K 的速度分布匹配),桶 id 用正弦位置编码后过 MLP 加到 timestep embedding 上:
这让每个去噪步都知道当前要生成的播放速度,相当于把速度作为一个全局调制信号。
(2) Frame-wise conditioning:对每个时间索引 i 的 latent 做帧级调制:
这把”第 i 帧相对于第 0 帧应该走多远”的时间进度编码进空间 latent,让连续帧之间的运动幅度和 speed 解耦对齐。
训练时只优化 speed-conditioning 模块(线性投影)和 transformer backbone 的 LoRA adapter;4 × GB200 GPU 跑 2 天;speed-conditioning LR = 1e-5,LoRA LR = 1e-4。
3.2.5 Extreme Temporal Super-Resolution(极端 TSR)
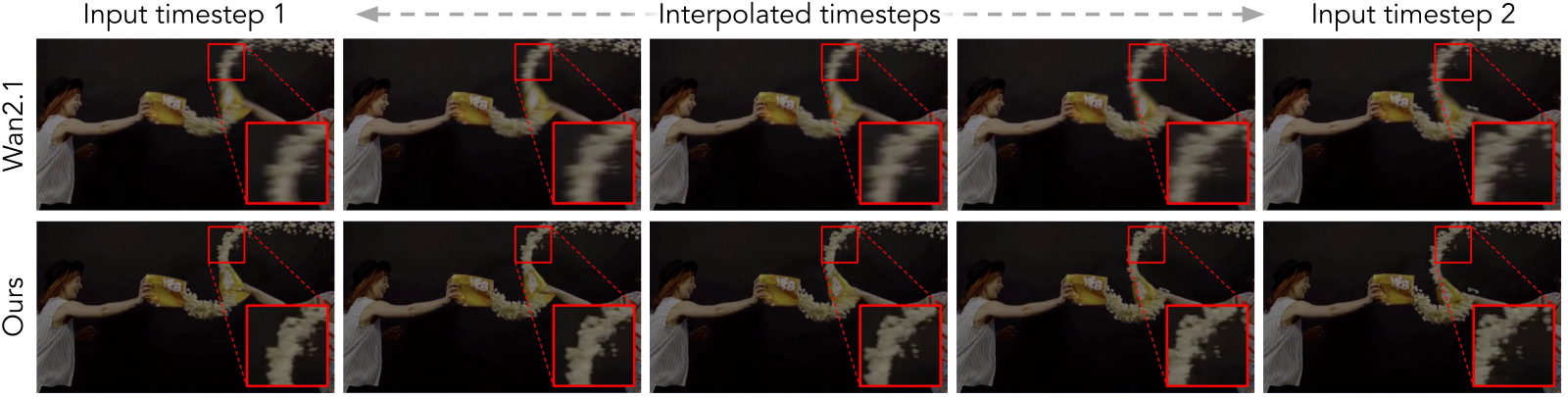
Figure 5 解读:在带 motion blur 的低帧率输入下(两端两列为两输入帧,中间三列为 interpolated),Wan2.1 baseline 产生模糊失真的中间帧(裙摆散落的花瓣结构错乱),Ours 生成清晰有连贯运动轨迹的中间帧——零件(花瓣)在空间和时间上都保持一致。

Figure 14 解读:给定仅两张强运动模糊的输入帧(第一行),5 种方法都要生成 5 帧中间 interpolated 结果。FILM、LDMVFI、GI 产生的花瓣拖影像”popcorn trajectory”(明显不连续),Wan2.1 产生糊掉的 ghost;只有 Ours 在 5 个中间时刻都保持了花瓣清晰的几何形状和连续的空间-时间轨迹,接近高速相机拍摄的效果。
做法:
- 数据合成:从 SloMo-44K 里取高帧率视频,模拟低 FPS 运动模糊(平均 8 个相邻帧 + 时间下采样),得到成对 (blurry low-FPS, clean high-FPS) 训练数据
- 模型:Wan2.1-VACE-14B 骨干(因其支持任意 mask 的视频条件生成),只微调 LoRA adapter
- 训练:8× upsampling;4 × GB200 GPU 跑 2 天;训一个 Clear-input 版本、一个 Blurred-input/Real-input 版本
- 模型同时学习 deblur + frame interpolation,这是和传统 TSR 最大的不同
3.3 Key formulas 总览
| 组件 | 公式 | 作用 |
|---|---|---|
| Self-supervised speed loss | 用时间加速等变性做自监督 | |
| Bucket encoding | 把连续速度离散化到 log-spaced buckets | |
| Time-emb modulation | 把速度作为全局 DiT 调制信号 | |
| Frame-wise modulation | 把”帧位置 × 速度”作为帧级条件 |
3.4 Pseudocode(伪代码)
代码搜索未找到官方开源实现(作者仅提供 project page,没有 release GitHub 仓库;依赖的 Wan2.1、VideoMAEv2 均开源)。以下伪代码基于论文描述。
自监督 speed estimator 训练循环:
import torch
import torch.nn.functional as F
def train_step_speed_estimator(model, video_batch, k_dist):
"""
video_batch: (B, T, C, H, W) - a batch of in-the-wild videos
k_dist: distribution over acceleration factors, k ~ N(1, T/2) in the paper
model: video encoder + scalar head (e.g., VideoMAEv2 + linear), outputs predicted
playback speed x = f_theta(V) > 0
"""
B, T, C, H, W = video_batch.shape
k = k_dist.sample((B,)).clamp(min=0.1)
x_orig = model(video_batch)
accelerated = []
for b in range(B):
idx = torch.arange(0, T, k[b].item()).long()
idx = idx[idx < T]
clip = video_batch[b, idx]
clip = _pad_or_trim_to_length(clip, T)
accelerated.append(clip)
video_accel = torch.stack(accelerated, dim=0)
x_accel = model(video_accel)
loss_ssl = ((torch.log(x_accel) - torch.log(k * x_orig)) ** 2).mean()
return loss_ssl
def train_step_with_calibration(model, video_batch, k_dist,
cal_batch, cal_gt_speed, lambda_cal=0.1):
"""
cal_batch: calibration videos (e.g., from Adobe240fps) with known speed
cal_gt_speed: ground-truth playback speeds for cal_batch
"""
loss_ssl = train_step_speed_estimator(model, video_batch, k_dist)
x_cal = model(cal_batch)
loss_cal = ((torch.log(x_cal) - torch.log(cal_gt_speed)) ** 2).mean()
return loss_ssl + lambda_cal * loss_cal迭代预测(IP)推理:
@torch.no_grad()
def iterative_speed_prediction(model, video, n_iters=3):
"""Iteratively refine speed estimate for extreme slow-motion videos."""
T = video.shape[0]
cumulative_speed = 1.0
for it in range(n_iters):
x_hat = model(video.unsqueeze(0)).item()
cumulative_speed *= x_hat
if x_hat > 1.01:
stride = x_hat
idx = torch.arange(0, T, stride).long()
idx = idx[idx < T]
video = video[idx]
T = video.shape[0]
if T < model.min_frames:
break
else:
break
return cumulative_speedSpeed-conditioned I2V 生成器(Wan2.1-I2V + speed modulation):
import torch.nn as nn
class SpeedConditionedI2V(nn.Module):
def __init__(self, base_wan2_i2v, n_buckets=10, min_speed=0.01, max_speed=1.0,
hidden_dim=1024):
super().__init__()
self.base = base_wan2_i2v
self.n_buckets = n_buckets
self.log_min = torch.log(torch.tensor(min_speed))
self.log_max = torch.log(torch.tensor(max_speed))
self.bucket_pos = SinusoidalEmbedding(dim=hidden_dim)
self.frame_pos = SinusoidalEmbedding(dim=hidden_dim)
self.mlp_theta = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim), nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim),
)
self.mlp_psi = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim), nn.SiLU(),
nn.Linear(hidden_dim, hidden_dim),
)
def speed_to_bucket(self, speed):
log_speed = torch.log(speed.clamp(min=1e-6))
norm = (log_speed - self.log_min) / (self.log_max - self.log_min)
bucket = (norm * self.n_buckets).floor().long().clamp(0, self.n_buckets - 1)
return bucket
def forward(self, latent, timestep, text_emb, image_emb, speed):
"""
latent: (B, T, C, H, W) noisy latent being denoised
speed: (B,) target playback speed in [0.01, 1.0]
"""
B, T = latent.shape[:2]
time_emb = self.base.timestep_embedding(timestep)
bucket_id = self.speed_to_bucket(speed)
bucket_emb = self.mlp_theta(self.bucket_pos(bucket_id.float()))
time_emb = time_emb + bucket_emb
frame_idx = torch.arange(T, device=latent.device).float()
frame_arg = frame_idx[None, :] * speed[:, None]
frame_mod = self.mlp_psi(self.frame_pos(frame_arg))
latent = latent + frame_mod.view(B, T, 1, 1, 1, -1).squeeze(-1).expand_as(latent)
return self.base.forward(latent, time_emb, text_emb, image_emb)TSR(基于 Wan2.1-VACE + 模拟运动模糊)数据合成:
def simulate_low_fps_blurry_input(clean_video_high_fps, window=8, stride=8):
"""
clean_video_high_fps: (T, C, H, W), e.g., from SloMo-44K at 240+ fps
Returns: (T//stride, C, H, W) low-FPS blurry video
"""
T, C, H, W = clean_video_high_fps.shape
blurry_frames = []
for t in range(window // 2, T - window // 2, stride):
patch = clean_video_high_fps[t - window // 2 : t + window // 2]
blurry_frames.append(patch.mean(dim=0))
return torch.stack(blurry_frames, dim=0)
def tsr_training_pair(clean_hi_fps, upsampling=8):
low_fps_blur = simulate_low_fps_blurry_input(
clean_hi_fps, window=upsampling, stride=upsampling)
mask = torch.ones_like(clean_hi_fps[:, :1])
mask[::upsampling] = 0
return low_fps_blur, clean_hi_fps, mask3.5 Code-to-paper mapping table
Code reference: 论文未发布官方实现(截至 2026-04-24 项目页 https://seeing-fast-and-slow.github.io/ 仅有视频展示)。以下表格给出论文每个组件 → 其依赖开源项目相应模块的映射,便于读者在
Wan-Video/Wan2.1@main、OpenGVLab/VideoMAEv2@master、OpenGVLab/InternVL@main、soCzech/TransNetV2@master基础上自行复现。
| Paper Concept | Dependency Source | Relevant Module |
|---|---|---|
| Speed-change detection backbone | OpenGVLab/VideoMAEv2 (master) | models/modeling_finetune.py 上加 binary CE head(按 K400 finetune 模板替换最后一层 classifier) |
| Speed estimator backbone | OpenGVLab/VideoMAEv2 (master) | models/modeling_finetune.py 上把 classification head 改成 scalar regression head |
| Speed-conditioned I2V base model | Wan-Video/Wan2.1 (main) | wan/image2video.py(pipeline)+ wan/modules/model.py(DiT 主干,加载 Wan2.1-I2V-14B-480P 权重) |
| LoRA fine-tuning of transformer | Wan-Video/Wan2.1 + peft | 在 wan/modules/model.py 的 attention/FFN 投影层挂 LoRA adapters |
| Temporal super-resolution base model | Wan-Video/Wan2.1 (main) | wan/vace.py(VACE pipeline)+ wan/modules/vace_model.py(mask-conditional video editing 模型,对应 Wan2.1-VACE-14B 权重) |
| Shot segmentation | soCzech/TransNetV2 (master) | inference/transnetv2.py(PyTorch 推理在 inference-pytorch/) |
| Dense video captioning | OpenGVLab/InternVL (main,v3 weights) | internvl_chat/(chat 推理入口;用 InternVL3 prompt template 生成 caption) |
4. Experimental Setup (实验设置)
-
数据集:
- SloMo-44K(本文贡献):44,632 个慢动作 clip / 18,235 个源视频 / 18M 帧 / 原始帧率 ≥10,000 fps,从 YouTube/Vimeo/Flickr 抓取
- 速度估计评测集:111 个带 verified 真值速度的 YouTube 视频(源视频标题注明了速度)
- 速度变化检测评测集:来自 SloMo-44K 的音频伪标签 + 4 人工审核 2 秒 clip(只保留人工与音频一致的样本)
- TSR 评测集:DAVIS(50 视频,real-input 设置)、SloMo-44K-Test(clear-input / blurred-input 设置)
- I2V 生成评测集:SloMo-44K 的 56 对 image-prompt,每对 4 速度设定
- 训练校准用:Adobe240fps [Su 2017](118 视频)
-
Baseline 方法:
- 速度变化检测:Gemini 2.5(SOTA VideoLLM)、基于 SEA-RAFT 的光流阈值法
- 速度估计:Gemini 2.5、SpeedNet [Benaim 2020]、Pulse-of-Motion [Gao 2026]、光流幅值、人类专家
- 视频帧插值/TSR:FILM [Reda 2022]、LDMVFI [Danier 2024]、Generative Inbetween [Wang 2024]、vanilla Wan2.1-VACE
- 速度条件生成:Wan2.1(用 “ultra slow-motion” 等 prompt 修饰符近似)、ATI [Wang 2025](基于 trajectory 的 motion control,用 CoTracker3 提取基准视频的 tracklet 再线性缩放)
-
评估指标:
- 速度估计:log 空间的 Pearson 相关系数 ρ、Spearman rs、RMSE、eRMSE(指数化的 RMSE,反映乘性误差)
- 速度变化检测:二分类 accuracy
- TSR:LPIPS [Zhang 2018]、FID [Heusel 2017]、FloLPIPS [Danier 2022]、FVD [Unterthiner 2019]、人类偏好率
- I2V 生成:FID、FVD、optical flow magnitude(评估 speed controllability)、VBench 指标(仅作补充)
-
训练配置:
- Speed-conditioned I2V:基于 Wan2.1-I2V-14B-480P,在 4 × NVIDIA GB200 GPU 上训练 2 天;speed-conditioning 模块 LR = 1 × 10⁻⁵,LoRA LR = 1 × 10⁻⁴,,IP 展开 3 次
- TSR:基于 Wan2.1-VACE-14B,4 × GB200 GPU 训 2 天,LoRA LR = 1 × 10⁻⁴,8× upsampling
- 速度估计器:基于 VideoMAEv2,,自监督 + Adobe240fps 校准,迭代预测 3 次
5. Experimental Results (实验结果)
5.1 核心数值
Speed-Change Detection(论文 Sec. 5.1):
| Method | Accuracy |
|---|---|
| Gemini 2.5 | 59.5% |
| Flow-based (SEA-RAFT) | 80.4% |
| Ours | 92.4% |
Video Speed Estimation(Table 2):
| Method | ρ ↑ | rs ↑ | RMSE ↓ | eRMSE ↓ |
|---|---|---|---|---|
| Human expert | 0.880 | 0.783 | 0.492 | 1.636 |
| Optical flow | 0.385 | 0.354 | - | - |
| VideoLLM (Gemini 2.5) | 0.426 | 0.308 | 1.568 | 4.796 |
| SpeedNet | 0.476 | 0.331 | 1.261 | 3.529 |
| Pulse-of-Motion | 0.508 | 0.525 | 1.181 | 3.258 |
| Ours | 0.735 | 0.706 | 0.649 | 1.913 |
本文方法把 Pearson 相关从 Pulse-of-Motion 的 0.508 推到 0.735,与人类 0.880 的差距从 0.372 缩小到 0.145。
Temporal Super-Resolution(Clear-input)(Table 3):
| Method | DAVIS FloLPIPS ↓ | LPIPS ↓ | FID ↓ | FVD ↓ | SloMo-44K FloLPIPS ↓ | LPIPS ↓ | FID ↓ | FVD ↓ |
|---|---|---|---|---|---|---|---|---|
| FILM | 0.252 | 0.200 | 20.7 | 711.3 | 0.087 | 0.066 | 10.7 | 257.6 |
| LDMVFI | 0.307 | 0.251 | 31.6 | 916.0 | 0.139 | 0.113 | 22.7 | 443.0 |
| GI | 0.353 | 0.234 | 21.4 | 552.1 | 0.124 | 0.093 | 14.9 | 503.6 |
| Wan2.1-VACE | 0.316 | 0.260 | 24.7 | 634.5 | 0.108 | 0.078 | 16.6 | 594.0 |
| Ours | 0.242 | 0.203 | 18.2 | 394.0 | 0.078 | 0.061 | 10.9 | 182.2 |
Temporal Super-Resolution(Blurred-input, SloMo-44K-Test)(Table 4):
| Method | FloLPIPS ↓ | LPIPS ↓ | FID ↓ | FVD ↓ |
|---|---|---|---|---|
| FILM | 0.099 | 0.080 | 20.3 | 250.0 |
| LDMVFI | 0.136 | 0.117 | 31.4 | 340.4 |
| GI | 0.123 | 0.108 | 26.1 | 439.4 |
| Wan2.1-VACE | 0.126 | 0.095 | 28.5 | 436.1 |
| Ours | 0.067 | 0.058 | 12.4 | 134.3 |
Speed-conditioned Generation(Table 5):
| Method | FID ↓ | FVD ↓ |
|---|---|---|
| ATI | 73.4 | 1473.5 |
| Wan2.1 | 72.2 | 1266.8 |
| Ours | 68.4 | 1114.1 |
5.2 User Study 与可控性分析
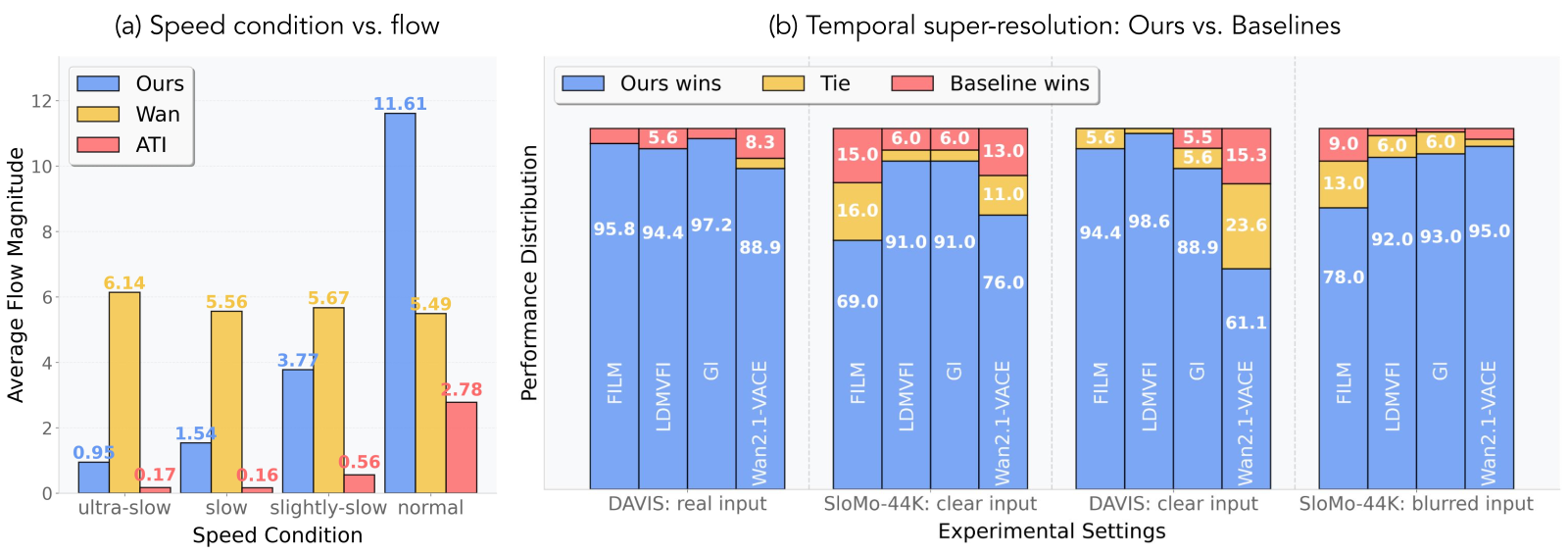
Figure 6 解读:
- (a) Speed condition vs flow(左):Ours(蓝)从 ultra-slow 到 normal 光流平均幅度 0.95 → 11.61,呈清晰单调递增;Wan2.1(黄)的 prompt-modifier 近似方法在所有速度设定下光流都在 5–6 徘徊(几乎不受 prompt 控制);ATI(红)因为是 trajectory-based,仅能做 0.16–2.78 的小范围调整。Ours 的速度可控性压倒性优于 baseline。
- (b) TSR user study(右):4 个设定下人类偏好率——在 DAVIS real-input 下 Ours 相对所有 baseline 都有 88.9%–97.2% 的 win rate;在最关键的 SloMo-44K clear-input 下 win rate 69.0–91.0%;blurred-input 设定下也达到 78.0–95.0%。
5.3 消融研究
迭代预测(IP)的作用(Table 7):
| Model | IP | ρ ↑ | rs ↑ | RMSE ↓ |
|---|---|---|---|---|
| VideoLLM | × | 0.426 | 0.308 | 1.568 |
| VideoLLM | ✓ | 0.552 | 0.479 | 1.221 |
| Ours | × | 0.680 | 0.684 | 0.917 |
| Ours | ✓ | 0.735 | 0.706 | 0.649 |
IP 对 VideoLLM 和本文模型都有显著提升,ρ 分别 +0.126 和 +0.055。说明”把 out-of-distribution 样本拉回训练分布再预测”是一个模型无关的通用技巧。
训练数据的重要性(Tables 6 & 8):
| Training data | Speed predictor ρ ↑ (+IP) | Speed-cond gen FID ↓ | FVD ↓ |
|---|---|---|---|
| Standard videos (Adobe240fps + normal) | 0.632 | 72.4 | 1392.9 |
| SloMo-44K (Ours) | 0.735 | 68.4 | 1114.1 |
SloMo-44K 比单纯用 Adobe240fps + 标准视频训练显著更好,这是验证作者”大规模真实慢动作数据不可替代”论点的关键。论文还定性展示了只用”人工减速的标准视频”训练会产生明显的 stuttering artifact(抖动),而 SloMo-44K 训练的模型产生流畅的物理运动。
5.4 局限性(作者自述)
- 速度理解模型在运动线索稀疏或人物故意慢动作的场景下会被误导(把艺术性慢动作误判为高速相机慢动作)
- 生成模型基于 Wan2.1 骨干,提升空间受限于预训练权重质量;架构创新或 full fine-tuning 可能会带来进一步提升
- 当前实现只做到 8× TSR(受 Wan2.1-VACE 窗口限制),对 100× 以上的极端超分还需要进一步研究
5.5 总体结论
本文最重要的结论有三点:
- 时间流速是可学的:利用视频原生的音频-视觉耦合 + 时间重采样等变性,无需人工标注即可训练出感知速度的模型,并把速度估计的 Pearson 相关系数从 ≤0.51 提升到 0.735
- 数据是瓶颈:SloMo-44K(44K 视频、10K+ fps 源)是一个比现有最大公开数据集大 70 倍的慢动作资源,既支持速度感知训练,也支持速度可控生成;用它微调的 Wan2.1-I2V 在 FVD 上从 1266 降到 1114,速度可控性光流幅度覆盖 0.95–11.61
- 极端 TSR 是新方向:Wan2.1-VACE + SloMo-44K + 模拟 motion blur 训练数据的组合实现 8× 极端超分,在 blurred-input 设定下 FVD 从 250 降到 134,用户偏好率 >70%,打开了 low-FPS 旧视频修复的新可能