OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
Authors: Shenghai Yuan*, Xianyi He*, Yufan Deng, Yang Ye, Jinfa Huang, Bin Lin, Jiebo Luo, Li Yuan† Affiliations: Peking University, University of Rochester, Rabbitpre AI arXiv: 2505.20292 Project Page: pku-yuangroup.github.io/OpenS2V-Nexus GitHub: PKU-YuanGroup/OpenS2V-Nexus Venue: Preprint (GitHub README 标注 NeurIPS 2025 D&B,待确认)
1. Motivation (研究动机)
Subject-to-Video (S2V) 生成旨在根据参考图像生成包含特定主体的视频,是视频生成领域的重要下游任务。然而,当前该领域存在两大核心缺口:
评测基准缺失:现有视频生成 benchmark(如 VBench、ChronoMagic-Bench)主要面向 Text-to-Video (T2V) 任务,缺乏针对 S2V 的专项评估。已有的 S2V benchmark(如 ConsisID-Bench、VACE-Bench、A2 Bench)存在明显不足:
- ConsisID-Bench 仅限于人脸一致性评估
- VACE-Bench 和 A2 Bench 虽支持 open-domain S2V,但评测维度粗粒度,且忽略了 subject naturalness(主体自然度)这一关键维度
- 这些 benchmark 继承自 VBench 的 subject consistency 指标,直接计算未裁剪视频帧与参考图像在 DINO/CLIP 空间的相似度,引入了背景噪声,导致评估不准确
训练数据匮乏:社区缺乏大规模的开源 S2V 数据集。现有大规模视频数据集(如 Panda-70M、Koala-36M)仅包含 text-video 对,不包含 subject 信息。S2V 模型面临三大核心挑战:
- Poor generalization(泛化能力差):在训练时未见过的 subject 类别上表现不佳
- Copy-paste issue(复制粘贴问题):模型倾向于直接复制参考图像的 pose、lighting、contour 到生成视频,导致不自然
- Inadequate human fidelity(人类身份保真度不足):模型在保持人类身份方面远不如非人类实体
2. Idea (核心思想)
本文提出 OpenS2V-Nexus,为 S2V 生成建立完整的基础设施,包含两个核心组件:
-
OpenS2V-Eval:首个全面的 S2V 评测 benchmark,包含 180 个 prompt、7 大类别、3 个专门设计的自动指标(NexusScore、NaturalScore、GmeScore),从 subject consistency、subject naturalness、text relevance 三个维度进行精细评估
-
OpenS2V-5M:首个开源百万级 S2V 数据集,包含 510 万常规 subject-text-video 三元组 + 35 万 Nexus Data(通过跨视频关联和 GPT-Image-1 生成多视角表示),从数据层面解决 S2V 的三大核心挑战
与现有方法的本质区别:不同于直接从训练帧中分割 subject(同视角、不完整、低分辨率),本文通过 cross-video association 和 GPT-Image-1 合成完整的、多视角的高质量 subject 图像,增强模型对 subject 内在知识的学习而非表面复制。
3. Method (方法)
3.1 整体框架
OpenS2V-Nexus 包含 benchmark 构建和 dataset 构建两条 pipeline:
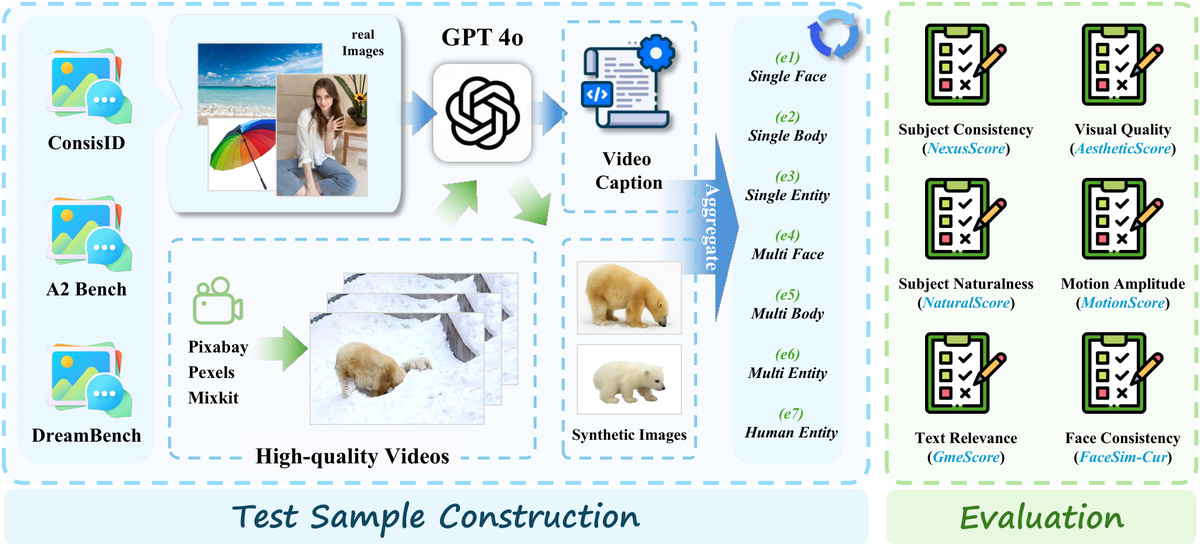
Figure 2 解读:左侧展示 test sample 的构建流程——从 ConsisID、A2 Bench、DreamBench 收集真实数据,从 Pixabay、Pexels、Mixkit 等版权友好平台获取高质量视频,并通过 GPT-Image-1 生成合成参考图像,最终构建覆盖 7 大类别的 180 个 subject-text 对。右侧展示 6 维评估体系:Subject Consistency (NexusScore)、Subject Naturalness (NaturalScore)、Text Relevance (GmeScore)、Visual Quality (AestheticScore)、Motion Amplitude (MotionScore)、Face Consistency (FaceSim-Cur)。
3.2 OpenS2V-Eval Benchmark
3.2.1 七大评测类别

Figure 1 解读:展示了 OpenS2V-Eval 的 7 大 S2V 类别示例——① Single-Face-to-Video、② Single-Body-to-Video、③ Single-Entity-to-Video、④ Multi-Face-to-Video、⑤ Multi-Body-to-Video、⑥ Multi-Entity-to-Video、⑦ Human-Entity-to-Video。每个类别包含参考图像和对应的生成视频帧,全面覆盖从单主体到多主体、从人类到非人类的各种 S2V 场景。
Benchmark 共收集 180 个高质量 subject-text 对:
- 真实样本 80 个:从 ConsisID(50个)和 A2 Bench(24个)收集用于类别 ①②⑥,其余 6 个真实样本来自其他来源
- 合成样本 100 个:从 DreamBench(30个参考图像 + GPT-4o 生成 caption)构建类别 ③,其余从版权免费平台(Pixabay、Pexels、Mixkit)获取高质量视频,通过 GPT-Image-1 提取 subject 图像,GPT-4o 生成 caption,构建类别 ④⑤⑥⑦
- 每个类别 30 个样本(④和⑤各 15 个),subject 图像数量限制在 3 个以内
3.2.2 Benchmark 统计
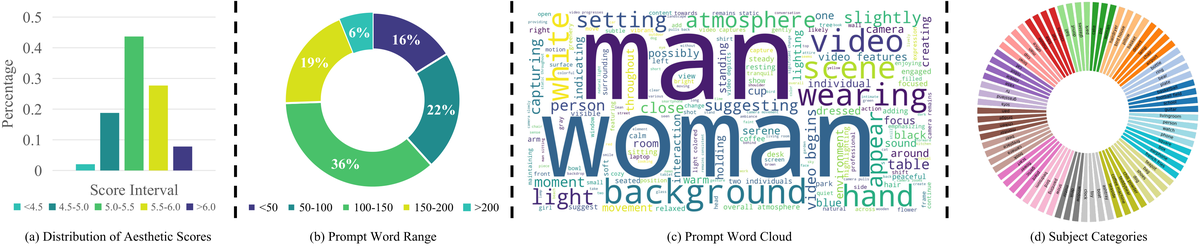
Figure 3 解读:(a) 参考图像的美学评分分布,大部分在 5 分以上,确保高质量;(b) Prompt 词数范围分布,涵盖短到长的多种长度;(c) Prompt 词云,“woman”、“man”、“background”、“wearing” 等高频词表明 benchmark 覆盖多种场景;(d) Subject 类别分布饼图,展示了丰富的视觉概念多样性。
3.2.3 三大自动评估指标
NexusScore(Subject Consistency 主体一致性)
现有方法直接计算未裁剪视频帧与参考图像在 DINO/CLIP 空间的相似度,引入背景噪声且特征空间不可靠。NexusScore 结合 image-prompt detection model (YOLOWorld)和 multimodal retrieval model (GME):
Step 1: 目标检测与裁剪。将参考图像 和视频帧 送入检测模型,生成包含目标的 bounding box:
裁剪得到 ,并与目标实体名 计算在统一文本-图像特征空间中的相似度:
Step 2: 过滤与评分。仅当 bbox 置信度 且相似度 时才纳入计算,最终在图像特征空间中评估裁剪区域与参考图像的相似度:
其中 是检测到目标的帧总数,除以 而非 是为了避免因少数高质量帧而产生偏高分数。
Algorithm: NexusScore Computation
Input: reference images {R_i}, video frames {I_t}, thresholds α, β
Output: NexusScore
1: Load YOLOWorld detector M_detect and GME retrieval model M_retrieve
2: for each video file:
3: frames = sample_video_frames(video_path, num_frames=32)
4: for each reference image R_i:
5: for each frame I_t:
6: # Detect subject in frame using reference as prompt
7: B_i,t, c_i,t = yoloworld_inference(M_detect, R_i, I_t)
8: if c_i,t > α:
9: C_i,t = crop(I_t, B_i,t) # Crop detected region
10: s_i,t = M_retrieve.similarity(C_i,t, E_i,t) # Text-image sim
11: if s_i,t > β:
12: score += M_retrieve.similarity(C_i,t, R_i) # Image-image sim
13: valid_count += 1
14: NexusScore = score / valid_countNaturalScore(Subject Naturalness 主体自然度)
针对 S2V 模型普遍存在的 copy-paste 问题,评估生成的 subject 是否看起来自然、符合物理规律。尝试了 AIGC 异常检测模型和开源多模态大模型,但前者准确度不足,后者指令跟随差且易产生幻觉。最终采用 GPT-4o 作为评估器,设计基于常识和物理定律的五分制评分标准:
从视频中均匀采样 帧,每帧独立送入 GPT-4o 评分(1-5分),取平均值。
Algorithm: NaturalScore Computation
Input: video file, GPT-4o API
Output: NaturalScore (1-5 scale)
1: frames = extract_frames_uniformly(video, num_frames=16)
2: for each frame I_t:
3: resize I_t to 512px on long side
4: encode I_t as base64
5: prompt = five_point_naturalness_criteria # Common sense, physics, artifacts
6: score_t = call_gpt4o(prompt, base64_image) # With retry logic
7: NaturalScore = mean(scores)GmeScore(Text Relevance 文本相关性)
现有方法用 CLIP/BLIP 计算文本相关性,但其特征空间存在缺陷且文本编码器限制在 77 tokens,不适合当前 DiT 模型偏好的长文本 prompt。本文使用 GME(基于 Qwen2-VL 微调的通用多模态检索模型),天然支持变长文本:
Algorithm: GmeScore Computation
Input: video frames, text prompt, GME model
Output: GmeScore
1: frames = sample_video_frames(video_path, num_frames=32)
2: e_query = gme.get_text_embeddings(
3: texts=[prompt] * len(frames),
4: instruction="Find an image that matches the given text."
5: )
6: e_corpus = gme.get_image_embeddings(images=frames, is_query=False)
7: gme_scores = (e_query * e_corpus).sum(-1) # Cosine similarity
8: GmeScore = gme_scores.mean()总分计算
六维指标归一化后加权求和:
Open-domain 权重:, , , , ,
Human-domain 权重:, , , ,
3.3 OpenS2V-5M Dataset

Figure 4 解读:左侧是数据处理 pipeline——先从 Open-Sora Plan 的 14.8M 原始视频中筛选(去低质量、保留人类相关视频),得到 5.4M clips,再通过 GroundingDINO + SAM2.1 提取 subject 图像,获得 Regular Data。右侧展示 Nexus Data 的两种构建方式:Cross-Frame Pairs 通过同一长视频的不同片段进行跨视频 subject 对齐(Group → Deletion → Boundary → Cluster);GPT-Frame Pairs 使用 GPT-Image-1 从视频首帧合成完整的多视角 subject 图像。
3.3.1 Subject-Driven Processing(Regular Data)
数据筛选:从 Open-Sora Plan 获取 14,818,489 个原始视频片段(无转场、有详细 caption),设计 100 个人类相关动词和名词作为搜索词,筛选出 12,654,783 个人类相关视频。再通过 Aesthetic Predictor、OpenCV motion score、DOVER technical score、PaddleOCR 水印检测进行质量过滤,最终得到 5,437,544 个高质量片段。
Subject 标注:
- 用 Qwen2.5-VL-7B 生成以 subject 为中心的视频 caption
- 用 DeepSeekV3 从 caption 中提取环境和物体关键词
- 用 GroundingDINO 输入首帧和关键词进行开放词汇目标检测
- 将检测框送入 SAM2.1 生成 mask,无背景地提取参考图像
- 用 Aesthetic Score 和 GmeScore 对参考图像进行质量评分
3.3.2 Generalized Nexus Construction(Nexus Data)
问题:Regular Data 中的 subject 图像从训练帧分割而来,与训练视频共享同一视角,可能不完整,导致模型学习”表面捷径”而非内在知识。

Figure 5 解读:对比 Regular Data(上)和 Nexus Data(下)的 subject 图像质量。Regular Data 的 subject 不完整、同视角、低分辨率(如狗只露出半边身体、碗被遮挡)。Nexus Data 的 subject 完整、多视角、高分辨率(完整的狗和碗的不同角度),能更好地帮助模型学习 subject 的内在特征。
GPT-Frame Pairs:给定视频首帧 和 subject 关键词集合 ,输入 GPT-Image-1 生成完整的 subject 图像:
Prompt 格式:"Extract the {tag} as a separate image based on the elements in this picture, realistic-style, only one element."。筛选条件:bbox 面积占原图 > 8%,tag 属于有效类别(background、subject、object)。从 5M 数据中选取平均得分最高的 top 10K 样本构建 GPT-Frame Pairs。
Cross-Frame Pairs:利用同一长视频切分的多个 clips 之间的天然时空关联。将同一长视频的所有 clips 聚合,使用 GME 计算跨 clip 的 subject 相似度:
其中 表示不同片段, 和 表示不同 subject。文本和图像相似度阈值均为 0.6。最终识别出 0.35M 个 clustering centers,每个平均包含 10.13 个样本。
Algorithm: Cross-Frame Pair Construction
Input: clustered video clips, GME model, thresholds (text=0.6, image=0.6)
Output: cross-frame pairs with similarity scores
1: for each cluster of clips from same long video:
2: for each pair (C_ij, C_kl) where i ≠ k: # Different segments
3: # Extract subject regions using RLE masks
4: subject_i = extract_subject_image(frame_i, mask_i)
5: subject_k = extract_subject_image(frame_k, mask_k)
6: # Compute text embedding similarity (class name matching)
7: text_sim = cosine_sim(gme.text_embed(class_j), gme.text_embed(class_l))
8: if text_sim > 0.6:
9: # Compute image embedding similarity
10: img_sim = cosine_sim(gme.image_embed(subject_i), gme.image_embed(subject_k))
11: if img_sim > 0.6:
12: save_pair(C_ij, C_kl, text_sim, img_sim)3.4 代码-论文映射表
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| NexusScore | eval/get_nexusscore.py | main(), yoloworld_inference(), generate_image_embeddings() |
| NaturalScore | eval/get_naturalscore.py | GPT-4o API call with 5-point criteria |
| GmeScore | eval/get_gmescore.py | GmeQwen2VL, get_text_embeddings(), get_image_embeddings() |
| AestheticScore | eval/get_aesscore.py | improved-aesthetic-predictor |
| MotionScore | eval/get_motion_amplitude.py | OpticalFlowFarneback |
| FaceSim | eval/get_facesim.py | InsightFace + CurricularFace |
| Subject Extraction | data_process/step5-2_get_subject_image.py | GroundingDINO + SAM2.1 |
| GPT-Frame Pairs | data_process/step6-4_get_gpt-frame.py | call_gpt(), GPT-Image-1 API |
| Cross-Frame Pairs | data_process/step6-2_get_cross-frame.py | GME similarity matching |
| Subject Captioning | data_process/step3-1_get_caption.py | Qwen2.5-VL-7B |
| Tag Extraction | data_process/step4-1_get_tag_*.py | DeepSeekV3 |
| Score Aggregation | eval/merge_result.py | Weighted sum normalization |
4. 实验设置 (Experimental Setup)
数据集与评测范围
- Benchmark: OpenS2V-Eval,180 prompts,7 类别
- 评测分为三个域:
- Open-Domain S2V:全部 7 个类别
- Human-Domain S2V:仅 ①②(人脸/人体),只输入人脸图像
- Single-Domain S2V:仅 ①②③(单 subject)
Baseline 方法
Closed-source (4个):Vidu 2.0, Pika 2.1, Kling 1.6, Hailuo S2V-01
Open-source (14个):
- Open-domain:VACE (P1.3B/1.3B/14B), Phantom (1.3B/14B), SkyReels-A2-P14B, HunyuanCustom
- Human-domain:ConsisID, Concat-ID (CogVideoX/Wan-AdaLN), FantasyID, EchoVideo, VideoMaker, ID-Animator
评估指标 (6维)
| 指标 | 评估维度 | 模型/方法 | 归一化范围 |
|---|---|---|---|
| NexusScore | Subject Consistency | YOLOWorld + GME | [0, 0.05] |
| NaturalScore | Subject Naturalness | GPT-4o (5-point) | [1, 5] |
| GmeScore | Text Relevance | GME-Qwen2-VL-7B | [0, 1] |
| FaceSim-Cur | Face Consistency | InsightFace + CurricularFace | [0, 1] |
| AestheticScore | Visual Quality | improved-aesthetic-predictor | [0, 1] |
| MotionScore | Motion Amplitude | OpticalFlowFarneback | [4, 7] |
训练配置
- 实验硬件:NVIDIA A100(论文未注明具体数量)
- 所有模型使用官方代码和权重,保持默认推理设置
- 每个 prompt 生成 1 个视频,seed 固定为 42
- 除 MotionScore 使用全部帧外,其他指标均匀采样 32 帧
- NaturalScore 使用
gpt-4o-2024-11-20,每帧运行 3 次取平均
5. 实验结果 (Experimental Results)
5.1 Open-Domain S2V 定量结果 (Table 3)
| Method | Venue | Total↑ | Aesthetic↑ | Motion↑ | FaceSim↑ | GmeScore↑ | NexusScore↑ | NaturalScore↑ |
|---|---|---|---|---|---|---|---|---|
| Kling 1.6 | Closed | 54.46% | 44.60% | 41.60% | 40.10% | 66.20% | 45.81% | 79.06% |
| Vidu 2.0 | Closed | 47.59% | 41.47% | 13.52% | 35.11% | 67.57% | 43.55% | 71.44% |
| Pika 2.1 | Closed | 48.88% | 46.87% | 24.70% | 30.80% | 69.21% | 45.41% | 69.79% |
| VACE-14B | Open | 52.87% | 47.21% | 15.02% | 55.09% | 67.27% | 44.20% | 72.78% |
| Phantom-14B | Open | 52.32% | 46.99% | 33.42% | 51.48% | 70.65% | 37.43% | 66.66% |
| SkyReels-A2 | Open | 49.61% | 39.40% | 25.60% | 34.95% | 64.54% | 43.77% | 67.22% |
关键发现:
- Closed-source 模型总体优于 Open-source,Kling 1.6 以 54.46% 总分领先,生成视频保真度和真实感最高
- VACE-14B 在 open-source 中最强(52.87%),通过扩大参数量和数据集实现全面提升
- SkyReels-A2 NexusScore 高但 NaturalScore 低,存在明显的 copy-paste 问题
- Pika 2.1 GmeScore 最高(69.21%),文本对齐最好
5.2 Human-Domain S2V 定量结果 (Table 4)
| Method | Domain | Total↑ | NexusScore↑ | NaturalScore↑ |
|---|---|---|---|---|
| Hailuo | Closed | 60.20% | 71.42% | 74.52% |
| Kling 1.6 | Open-Domain | 59.13% | 45.81% | 78.28% |
| Phantom-14B | Open-Domain | 53.64% | 72.17% | 71.13% |
| Ours† (w/ Nexus) | - | 51.67% | 72.12% | 65.42% |
| Ours‡ (w/o Nexus) | - | 52.97% | 72.35% | 66.80% |
- Human-domain 中,Hailuo 以 60.20% 总分最高,在保持人类身份方面表现突出
- ConsisID 和 Concat-ID 虽有较高 FaceSim,但 NaturalScore 显著偏低,copy-paste 问题严重
5.3 Qualitative Analysis

Figure 6 解读:Open-Domain S2V 定性对比。展示两个案例,左侧为室内场景(人在桌旁),右侧为户外场景(亚洲男性 + 鹦鹉)。Closed-source 模型(Kling)总体能力最强,但也存在 Poor generalization(case 2 中背景错误)。Open-source 模型中 VACE 和 Phantom 在缩小差距,但三大核心问题仍然普遍:非人类实体的保持优于人类身份,单 subject 优于多 subject。

Figure 7 解读:Human-Domain S2V 定性对比。左侧为驾车场景,右侧为古装场景。SkyReels-A2 和 VACE 存在明显的 copy-paste 问题——直接复制参考图像的表情、光照、姿态。所有模型在生成侧脸时均难以保持身份一致性。Kling 仅在前半段维持人类身份,后半段也逐渐丢失。

Figure 8 解读:Single-Domain S2V 定性对比。所有模型在单 subject 任务上表现优于多 subject 任务。
5.4 Metrics vs Human Perception

Figure 10 解读:(a) NexusScore vs DINO-I、GmeScore vs CLIP-I/CLIP-T 的人类偏好对齐对比,本文提出的指标在所有对比中均优于现有指标。(b) 定性示例展示 NexusScore 能更准确区分一致性差异,GmeScore 能更好衡量文本相关性。

Figure 11 解读:对比不同 Subject Naturalness 评估方法。现有 AIGC 检测模型(NYUAD-ComNets、DualSight、SAFE)和多模态模型(Qwen2.5-VL-7B)均容易将生成内容误判为真实,而 NaturalScore(基于 GPT-4o)能给出 60% 的合理分数,更准确地识别不自然内容。
5.5 Dataset Validation

Figure 9 解读:(a) 自动指标与人类偏好的相关性验证——173 名参与者投票,三个新指标与人类偏好的对齐程度与 AestheticScore、MotionScore 等成熟指标相当(约 75%)。(b) 在 ConsisID + Wan2.1 1.3B 上用 300K 样本微调验证数据集有效性——使用 Nexus Data(Ours†)显著优于不使用(Ours‡),证明 Nexus Data 对解决三大核心问题至关重要。
5.6 Ablation: 关键观察
- 随着参考图像数量增加,subject 保持能力逐渐降低
- 初始帧常出现模糊或直接复制参考图像的现象(与使用 VAE 作为控制信号有关)
- Subject 一致性随时间推移逐渐衰减(Consistency Fade)
- 约 75% 的 NexusScore/NaturalScore 与人类判断一致,仍有提升空间
5.7 模型选择指南 (来自 Appendix B.5)

Figure 14 解读:三个域(Open-Domain、Human-Domain、Single-Domain)所有模型的六维雷达图可视化。清晰展示各模型的优劣势分布。
- 内容创作者:优选 Kling(最灵活),性价比替代 Pika/Vidu
- 社区开发者:推荐基于 Phantom 或 VACE 进行微调
- 人类视频需求:Hailuo 在人类身份保持方面最优
- Human-centric S2V 开发:HunyuanCustom、ConsisID 提供高质量预训练权重
5.8 局限性
- NexusScore 和 NaturalScore 与人类偏好的相关性仅约 75%
- OpenS2V-5M 中仅约 4M 视频符合 CC BY 4.0 / CC0 许可证
- 验证实验(Ours†/‡)受计算资源限制,仅用 300K 样本和 MSE loss 训练,未达最优性能