MOVA - Scalable and Synchronized Video-Audio Generation
1. Motivation(研究动机)
- 现有方法的主要问题:多数视频生成模型忽略音频;业界常用级联管线(先视频后音频或反之),成本高、误差累积、两模态在合成过程中缺乏交互。端到端系统如 Veo 3、Sora 2 证明了同步音画联合建模的价值,但闭源限制了研究复现与改进。开源视频–音频模型多在小规模架构与有限数据上验证,能否随数据与算力扩展仍不明确。
- 本文要解决的具体问题:构建开源的 MOVA(MOSS Video and Audio),在 IT2VA(Image-Text to Video-Audio) 等设定下,联合生成高质量、时间对齐的视频与音频,覆盖对口型语音、环境/物理音效与内容相关音乐,并在**大参数量(32B 总参、18B 激活的 MoE)**上验证可扩展性。
- 为何值得研究:一旦联合音画生成在开放权重与代码下可用,社区可以系统研究模态融合、同步机制、数据管线与推理策略;同时释放 LoRA 微调、prompt 增强、高效推理 等工程能力,缩小与闭源产品的差距。
2. Idea(核心思想)
- 核心洞察:与其从零训练巨型多模态扩散模型,不如保留各自最强的预训练单模态先验——以 Wan2.2 I2V A14B(视频) 与 1.3B 量级、Wan2.1 风格的 text-to-audio DiT(音频) 为双塔骨干,仅用约 2.6B 参数的 Bridge 在 hidden state 层做双向 cross-attention,把“对齐”问题集中到浅层、可高效学习的交互模块上;再配合时间网格对齐的 RoPE与解耦噪声日程(Dual Sigma Shift),缓解音视频 token 密度不同带来的漂移。
- 与典型竞品的根本差异:相对 WAN2.1 + MMAudio 级联系统,MOVA 在单次联合扩散过程内通过 Bridge 交换中间表征;相对 Ovi / LTX-2 等联合模型,MOVA 强调非对称双塔 + 显式 Bridge + 推理期 Dual CFG 的可控对齐,并配套大规模细粒度音画 caption 数据管线支撑对口型与语义绑定。
3. Method(方法)
直觉段落(为何有效):视频 latent 时间下采样粗、音频 latent 沿时间更密,若直接在 cross-attention 里用“原始 token 下标”当位置,同一物理时刻在两种模态里会落到不同的 RoPE 相位,注意力会系统性错配,口型与音节更容易漂移。MOVA 把视频帧索引按 (f_a/f_v) 映射到音频时间单元,使 Bridge 在共享物理时间轴上交换信息;训练上又让两模态可选用不同 shift 的 flow 噪声强度,避免“为了迁就视频强去噪而毁掉音频音色”或相反。推理时把 文本条件 与 Bridge 隐含的跨模态条件 拆开做 Dual CFG,相当于在“跟 prompt 走”和“音画互相咬住”之间用两个标量独立调参——这与联合 latent 下单 CFG 的折中相比,更贴合实际产品里对口型与听感往往不同权重的需求。
3.1 问题形式与 Flow Matching 目标
视频 (V) 与 48 kHz 单声道音频 (A) 经预训练 VAE 得到 latent (x_v, x_a)。Flow matching 插值(论文式 (1)(2))下,目标速度为 (v_v=\varepsilon_v-x_v,; v_a=\varepsilon_a-x_a),训练目标为对两路速度场的 MSE(式 (3)):
3.1a 能力展示与双塔结构
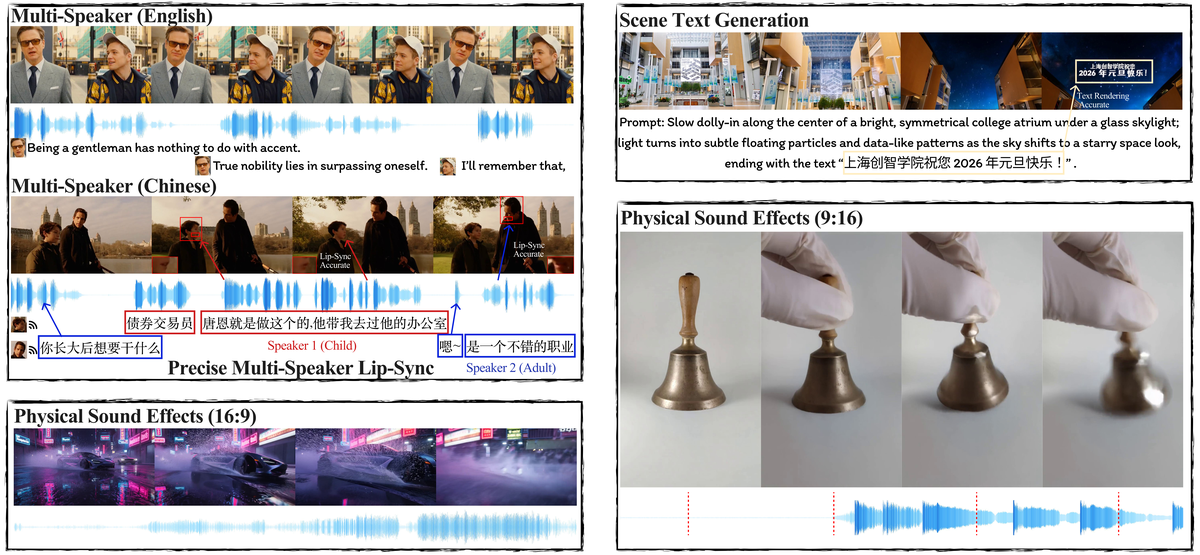
Figure 1 解读:展示 MOVA 在多说话人对口型(中英)、物理音效与画面对齐、场景文字生成以及 9:16 / 16:9 等设定下的联合生成能力,对应论文对“同步音画 + 多场景”的定位。

Figure 2 解读:左侧为 UMT5 文本编码 与 首帧条件 进入 Video DiT(高/低噪声两阶段各 10× 与 30× block 的示意);右侧为 Audio DiT;中间 Bridge Cross-Attention 在层间双向连接(A→V、V→A)。Bridge CFG 与 Text CFG 在推理期分别调制跨模态与文本引导强度,对应后文 Dual CFG。
3.2 Bridge 与对齐 RoPE
Bridge 在选定层上插入 ConditionalCrossAttentionBlock:音频 hidden 作为 KV 注入视频 block(a2v),视频 hidden 注入音频 block(v2a)。代码中 DualTowerConditionalBridge 用 interaction_strategy(如 shallow_focus)决定哪些层交互,并可选 apply_cross_rope;build_aligned_freqs 按 音频步长对应 (44100/2048) 与 视频 fps、VAE 时间步长(实现里对 temporal stride 有注释约定) 构造对齐的 RoPE cos/sin。
组件伪代码:Bridge 前向(对齐 interactionv2.DualTowerConditionalBridge)
def forward(
self,
layer_idx: int,
visual_hidden_states: torch.Tensor,
audio_hidden_states: torch.Tensor,
x_freqs=None,
y_freqs=None,
a2v_condition_scale=None,
v2a_condition_scale=None,
condition_scale=1.0,
video_grid_size=None,
):
visual_out = self.apply_conditional_control(
layer_idx, "a2v",
primary_hidden_states=visual_hidden_states,
condition_hidden_states=audio_hidden_states,
x_freqs=x_freqs,
y_freqs=y_freqs,
condition_scale=a2v_condition_scale or condition_scale,
video_grid_size=video_grid_size,
)
audio_out = self.apply_conditional_control(
layer_idx, "v2a",
primary_hidden_states=audio_hidden_states,
condition_hidden_states=visual_hidden_states,
x_freqs=y_freqs,
y_freqs=x_freqs,
condition_scale=v2a_condition_scale or condition_scale,
video_grid_size=video_grid_size,
)
return visual_out, audio_out3.3 训练:双塔联合、异构学习率、Dual Sigma Shift 与 MoE 交替步
- 异构 LR:Bridge (\eta_{br}=2\times 10^{-5}),骨干 DiT (\eta_b=1\times 10^{-5})(Figure 4d)。
- Dual Sigma Shift:训练时对 (t_v,t_a) 独立采样,各自用 (\sigma_m(t)=\frac{\mathrm{shift}_m\cdot t}{\mathrm{shift}_m+t(1-\mathrm{shift}_m)})(式 (4))。Phase 1 取 (\mathrm{shift}_v=5,\mathrm{shift}_a=1);Phase 2 令 (\mathrm{shift}_a=5) 与视频对齐以提升音色;Phase 3 720p 微调。
- MoE 视频塔与 FSDP:论文指出标准 FSDP 需一致计算图,故对 A14B MoE 采用奇偶步交替:奇步统一采高噪声步只更新高噪声 DiT;偶步采低噪声步只更新低噪声 DiT;Bridge 与音频塔每步都更新。
- 实现对应:
MOVATrain.training_step用global_step % 2在video_dit与video_dit_2间切换;sample_timestep_pair结合boundary_ratio与 scheduler 的pair_timesteps采样 (video_t, audio_t);损失为video_loss + audio_loss,目标为noise - clean_latent的 MSE(与 flow matching 速度场一致)。
组件伪代码:训练步(摘自 mova_train.py 逻辑)
def training_step(self, video, audio, first_frame, caption, global_step, video_fps=24.0, cp_mesh=None):
with torch.no_grad():
context = self._get_t5_prompt_embeds(caption)
video_latents = self.normalize_video_latents(self.video_vae.encode(video).latent_dist.mode())
y = self.encode_first_frame_condition(first_frame, video.shape) # mask + latent
audio_latents = self.encode_audio_latents(audio)
boundary = (self.scheduler.timesteps >= self.boundary_ratio * self.scheduler.num_train_timesteps).sum().item()
boundary = boundary / self.scheduler.num_train_timesteps
cfg = TimestepConfig(
max_timestep_boundary=boundary if global_step % 2 == 0 else 1.0,
min_timestep_boundary=0.0 if global_step % 2 == 0 else boundary,
)
timestep, audio_timestep = self.sample_timestep_pair(cfg)
v_noise, a_noise = torch.randn_like(video_latents), torch.randn_like(audio_latents)
noisy_v = self.scheduler.add_noise(video_latents, v_noise, timestep)
noisy_a = self.scheduler.add_noise(audio_latents, a_noise, audio_timestep)
cur_dit = self.video_dit if global_step % 2 == 0 else self.video_dit_2
v_pred, a_pred = self.inference_single_step(
cur_dit, noisy_v, noisy_a, y, context, timestep[:1], audio_timestep[:1], video_fps, cp_mesh
)
v_tgt, a_tgt = v_noise - video_latents, a_noise - audio_latents
v_loss = F.mse_loss(v_pred.to(v_tgt.dtype), v_tgt)
a_loss = F.mse_loss(a_pred.to(a_tgt.dtype), a_tgt)
return {"loss": v_loss + a_loss, "video_loss": v_loss, "audio_loss": a_loss}组件伪代码:双 sigma 日程(仓库入口为 FlowMatchPairScheduler.set_pair_postprocess_by_name("dual_sigma_shift", ...))
# 配置侧:注册按模态独立的 sigma 曲线,训练/推理时 pair_timesteps[:,0] 与 [:,1] 可不同。
scheduler.set_pair_postprocess_by_name(
"dual_sigma_shift",
visual_shift=5.0,
audio_shift=1.0, # Phase 1 示例;Phase 2 可将 audio_shift 对齐到 5.0
visual_denoising_strength=1.0,
audio_denoising_strength=1.0,
)
# 内部对 linspace 得到的 sigma 列分别施加 shift_m * x / (1 + (shift_m - 1) * x)(与论文式 (4) 一致),再拼成 [N,2]。3.4 数据工程(Figure 3)

Figure 3 解读:三阶段管线:预处理(720p、24 fps、8.05 s clip、VAD + 场景切分、9:16/16:9 pad);质量过滤(Audiobox 美学、DOVER 视频质量、SynchFormer 时序对齐、ImageBind 语义对齐等);音画 caption(MiMo-VL 视频描述 + Qwen3-Omni 语音/非语音 + GPT-OSS 合并)。Table 1 给出各阶段时长保留率(Raw→Stage1 全量 84.57% / 仅语音 58.75%→Stage2 26.39%)。
3.5 训练流程(Figure 4)
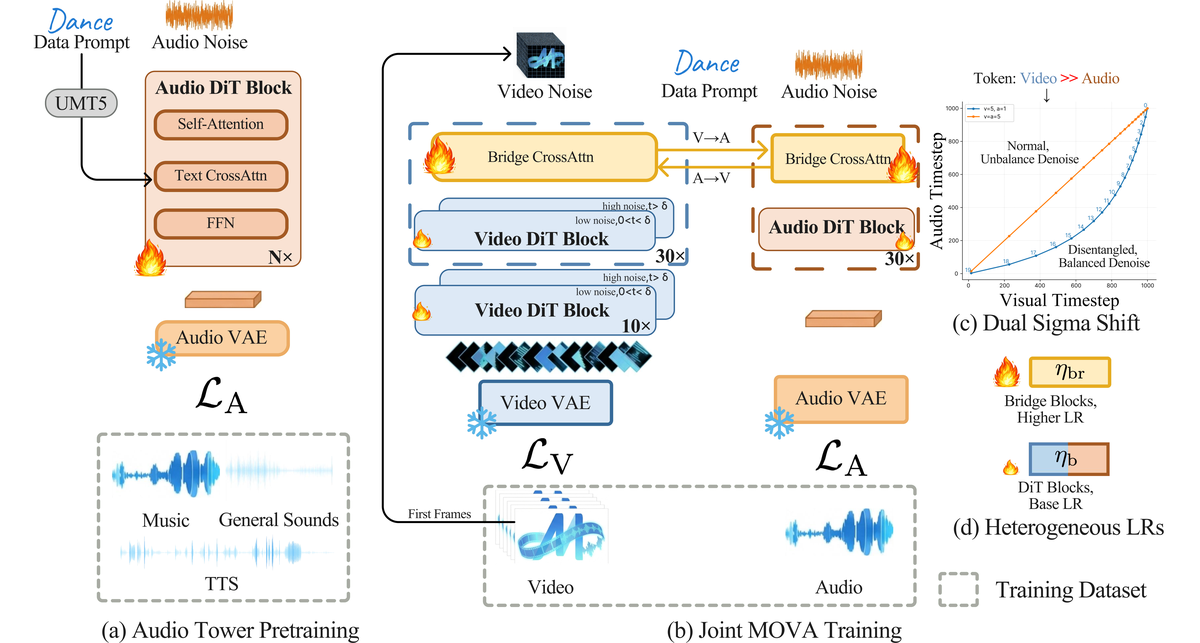
Figure 4 解读:(a)1.3B 音频塔在音乐/音效/TTS 上预训练,Audio VAE 冻结;(b)视频 A14B 与音频塔经 Bridge 联合训练;(c)独立采样音视频时间步以实现 Dual Sigma Shift;(d)Bridge 更大学习率以加快跨模态对齐。整体与代码中 冻结 VAE、双视频 DiT 分阶段、scheduler pair 一致。
3.6 推理:Dual CFG 与 Prompt 工作流(Figure 5)
论文给出双条件分解(式 (5)(6)),用 (s_B,s_T) 分别放大 Bridge(跨模态) 与 文本 引导。Text-only CFG((s_B=1))语义对齐强但 DeSync 偏高;Text + modality CFG((s_B=s_T=s))在无条件分支关闭 Bridge,口型更好但可能牺牲部分文本遵从。默认完整 Dual CFG 每步 NFE=3。

Figure 5 解读:Qwen3-VL 从首帧抽四类结构化视觉描述 → Gemini 2.5 Pro(示例)做 prompt rewrite → MOVA 在增强文本 + 首帧条件下生成音画;无图时可用白图占位走 T2VA。
组件伪代码:推理单步 velocity 预测后 CFG(pipeline_mova.py 简化)
def denoise_step(self, latents, audio_latents, cond, neg_cond, timestep, audio_timestep, cfg_scale, cur_dit):
pos_v, pos_a = self.inference_single_step(cur_dit, latents, audio_latents, cond, timestep, audio_timestep)
if cfg_scale == 1.0:
return pos_v, pos_a
neg_v, neg_a = self.inference_single_step(cur_dit, latents, audio_latents, neg_cond, timestep, audio_timestep)
v = neg_v + cfg_scale * (pos_v - neg_v)
a = neg_a + cfg_scale * (pos_a - neg_a)
return v, a说明:仓库 MOVA.__call__ 中 cfg_mode="text" 分支实现标准 text CFG;论文中的 full dual CFG(三前向) 需在推理脚本侧扩展 cfg_mode 或对 Bridge 条件单独 dropout,与论文式 (6) 完全对齐时请以官方推理配置为准。
3.7 评测构造与规模化对口型(Figure 6–9)

Figure 6 解读:自建 benchmark 的类别分布与 prompt 长度分布,用于覆盖多说话人、电影叙事、体育、游戏直播、镜头运动与动漫等细分类。

Figure 7 解读:内部 Arena 上 prompt rewriter、360p/720p、dual CFG 对人类偏好的影响;带 rewriter 的 MOVA-720p ELO 最高(论文报告 1025.3),验证分布对齐训练 caption 风格的重要性。

Figure 8a 解读:相对 LTX-2、Ovi、WAN2.1+MMAudio 的 ELO 主结果(论文报告 MOVA-720p 约 1113.8)。

Figure 8b 解读:MOVA 在成对比较中的 胜率,尤其对 Ovi 与级联基线超过 70%(与正文描述一致)。

Figure 9 解读:三阶段训练下 LSE-C / LSE-D 随步数变化,说明先强对齐再对齐 sigma、最后升分辨率对口型指标的单调改善。
3.8 LoRA 与低资源训练
仓库 low_resource_trainer.py + lora_layers.py 支持对选定模块注入 LoRA、梯度检查点与可选 FP8 CPU offload,便于消费级 GPU 微调。
Code reference:
main@692ac3ae(2026-04-01) — 伪代码与映射基于该 commit
| 论文概念 | 源码路径 | 关键类/函数 |
|---|---|---|
| 联合训练与 Flow Matching 损失 | mova/diffusion/pipelines/mova_train.py | MOVATrain.training_step, forward_dual_tower_dit |
| 推理管线与 CFG | mova/diffusion/pipelines/pipeline_mova.py | MOVA.__call__, inference_single_step |
| Bridge / 对齐 RoPE | mova/diffusion/models/interactionv2.py | DualTowerConditionalBridge, build_aligned_freqs |
| 双塔 timestep / dual sigma | mova/diffusion/schedulers/flow_match_pair.py | FlowMatchPairScheduler.set_pair_postprocess_by_name("dual_sigma_shift", ...) |
| LoRA 微调 | mova/engine/trainer/low_resource/low_resource_trainer.py | LowResourceTrainer, LoRAManager |
4. Experimental Setup(实验设置)
- 数据集:训练侧使用 VGGSound、AutoReCap、ChronoMagic-Pro、ACAV-100M、OpenHumanVid、SpeakerVid-5M、OpenVid-1M 等公开数据子集及大量 in-house 数据;音频塔另用 WavCaps、JamendoMaxCaps、自研 TTS 等。评测视频侧:Verse-Bench(600 image–text 对,用 GPT-5 统一音画描述 prompt)+ 自建六类场景 benchmark(732 主观样本中部分来自该集)。
- 基线:LTX-2、Ovi、WAN2.1 + MMAudio(级联)。
- 指标:IS(PANNs)、DNSMOS、DeSync(Synchformer)、IB-Score(ImageBind)、LSE-C/D(SyncNet)、cpCER(多说话人)、AudioCaps / AudioBox(音频塔)、主观 ELO。
- 训练配置:三阶段 1024 GPU(128 节点 ×8卡),360p 两阶段各约 15/7 天,720p 约 20 天,合计约 43k GPU·days;360p CP=8、有效 batch 128;720p CP=16、有效 batch 64;音频塔 1.3B NFE=100 等见 Table 2–3。
5. Experimental Results(实验结果)
5.1 音频塔(Table 2–3,论文原表数值)
Table 2(AudioCaps)
| Model | Params | NFE | FD openl3↓ | KL passt↓ | CLAP↑ | IS↑ |
|---|---|---|---|---|---|---|
| TangoFLUX | 516M | 50 | 80.47 | 1.02 | 0.546 | 13.28 |
| AudioLDM2 | 346M | 200 | 72.04 | 1.66 | 0.409 | 7.79 |
| Ours | 1.3B | 100 | 72.25 | 1.47 | 0.463 | 10.54 |
Table 3(AudioBox)
| Model | CE | CU | PC | PQ |
|---|---|---|---|---|
| AudioLDM | 3.27 | 5.10 | 3.23 | 5.82 |
| AudioLDM2 | 3.48 | 5.54 | 3.00 | 6.09 |
| Make-An-Audio 2 | 3.23 | 4.98 | 3.17 | 5.58 |
| Tango 2 | 3.47 | 5.20 | 3.84 | 5.89 |
| TangoFLUX | 3.54 | 5.07 | 3.64 | 5.78 |
| Ours | 3.41 | 5.56 | 3.04 | 6.20 |
5.2 Verse-Bench 主表(Table 4)
| Model | (s_B) | IS↑ | DNSMOS↑ | DeSync↓ | IB-Score↑ | LSE-D↓ | LSE-C↑ | cpCER↓ |
|---|---|---|---|---|---|---|---|---|
| LTX-2 | - | 3.066 | 3.635 | 0.451 | 0.213 | 7.261 | 6.109 | 0.220 |
| Ovi | - | 3.680 | 3.516 | 0.515 | 0.190 | 7.468 | 6.378 | 0.436 |
| WAN2.1 + MMAudio | - | 4.036 | – | 0.260 | 0.317 | – | – | – |
| MOVA-360p | 1.0 | 4.269 | 3.797 | 0.475 | 0.286 | 8.098 | 6.278 | 0.177 |
| MOVA-360p w/ dual CFG | 3.5 | 4.169 | 3.674 | 0.351 | 0.315 | 7.004 | 7.800 | 0.247 |
| MOVA-720p | 1.0 | 3.936 | 3.671 | 0.485 | 0.277 | 8.048 | 6.593 | 0.149 |
| MOVA-720p w/ dual CFG | 3.5 | 3.814 | 3.751 | 0.370 | 0.297 | 7.094 | 7.452 | 0.218 |
5.3 (s_B) 消融(Table 5,节选)
| 配置 | (s_B) | IS↑ | DNSMOS↑ | DeSync↓ | IB-Score↑ | LSE-D↓ | LSE-C↑ | cpCER↓ |
|---|---|---|---|---|---|---|---|---|
| MOVA-360p | 1.0 | 4.269 | 3.797 | 0.475 | 0.286 | 8.098 | 6.278 | 0.177 |
| + dual CFG | 2.0 | 4.222 | 3.748 | 0.421 | 0.305 | 7.323 | 7.331 | 0.185 |
| 3.0 | 4.319 | 3.686 | 0.388 | 0.312 | 7.014 | 7.774 | 0.188 | |
| 3.5 | 4.169 | 3.674 | 0.351 | 0.315 | 7.004 | 7.800 | 0.247 | |
| 4.0 | 4.225 | 3.631 | 0.365 | 0.316 | 6.957 | 7.891 | 0.264 |
消融要点:增大 (s_B) 一致改善 DeSync、IB-Score、LSE,但 DNSMOS 与 cpCER 变差,作者解释为过强的对齐引导与文本/说话人指令竞争。
5.4 T2VA(Table 6)
| Model | IS↑ | DNSMOS↑ | DeSync↓ | IB-Score↑ | LSE-D↓ | LSE-C↑ | cpCER↓ |
|---|---|---|---|---|---|---|---|
| MOVA-360p | 4.269 | 3.797 | 0.475 | 0.286 | 8.098 | 6.278 | 0.177 |
| MOVA-360p-T2VA | 4.370 | 3.767 | 0.441 | 0.281 | 8.362 | 5.830 | 0.188 |
5.5 局限(作者叙述)
- Dual CFG 提升客观对齐但可能削弱人类主观分与说话人遵从( rewriter 设定下 ELO 从 1025.3 降至 1014.5)。
- 对口型不仅依赖架构,更依赖数据规模与训练阶段;需与 Figure 9 的阶段性曲线合读。
- 完整 Dual CFG(三前向) 的默认实现若在代码中与论文存在分支差异,应以官方发布配置为准(见 Method 3.6 说明)。
5.6 结论
MOVA 在开源权重与代码前提下,通过非对称双塔 + Bridge + 数据管线 + Dual Sigma Shift + Dual CFG,在音画对齐、口型、多说话人归因等指标上相对强基线取得整体优势,并给出可扩展训练(MoE 交替步、大规模 GPU)与工程化推理/微调路径。