LTX-2: Efficient Joint Audio-Visual Foundation Model
Authors: Yoav HaCohen*, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, Victor Kulikov, Yaron Inger, Yonatan Shiftan, Zeev Melumian, Zeev Farbman Affiliations: Lightricks arXiv: 2601.03233 Project Page: ltx-2.run GitHub: Lightricks/LTX-2
1. Motivation (研究动机)
当前文本生成视频 (T2V) 扩散模型已经能够生成视觉质量很高的视频,但它们都是”沉默”的——缺少音频所提供的语义、情感和氛围线索。现有方法主要分为两类:
- 解耦序贯生成 (Decoupled Sequential):先生成视频再配音 (V2A),或先生成音频再生视频 (A2V)。这类方法存在 “modality-first” 瓶颈——后生成的模态受限于先生成模态的质量,且无法建模两种模态之间的真实联合分布(例如唇动同步由视觉驱动,而环境混响由音频驱动)。
- 对称双骨干 (Symmetric Dual-Backbone):如 Ovi 和 BridgeDiT,通常复制并组合现有 T2V 和 T2A 骨干,导致计算开销大且跨模态协同有限。
核心问题:如何设计一个高效的联合音视频生成模型,在单次前向过程中同时生成时间同步的高质量视频和音频(包含语音、背景音、拟音),同时避免过大的计算开销?
2. Idea (核心思想)
LTX-2 的核心思想是非对称双流 (Asymmetric Dual-Stream) 架构:
- 解耦潜在表示:视频和音频使用各自独立的 causal VAE 编码到不同的 latent space(视频为 3D 时空潜在,音频为 1D 时序潜在),而非强制共享同一 latent space。
- 非对称参数分配:视频流 14B 参数,音频流 5B 参数(实际论文中说是 3B 的轻量音频流扩展预训练 13B 视频骨干),反映视觉信息密度远高于音频。
- 双向跨模态注意力 + cross-modality AdaLN:每个 transformer block 中通过双向 cross-attention(使用 1D temporal RoPE)和跨模态 AdaLN 门控实现音视频特征交换与同步。
- Thinking Tokens 文本增强:使用 Gemma3-12B 多语言编码器 + 多层特征抽取 + thinking tokens 增强文本 conditioning,提升语音生成的语音学精度。
- Bimodal CFG:推理时引入跨模态 guidance 项,独立控制文本引导和跨模态引导强度。
3. Method (方法)
3.1 整体架构
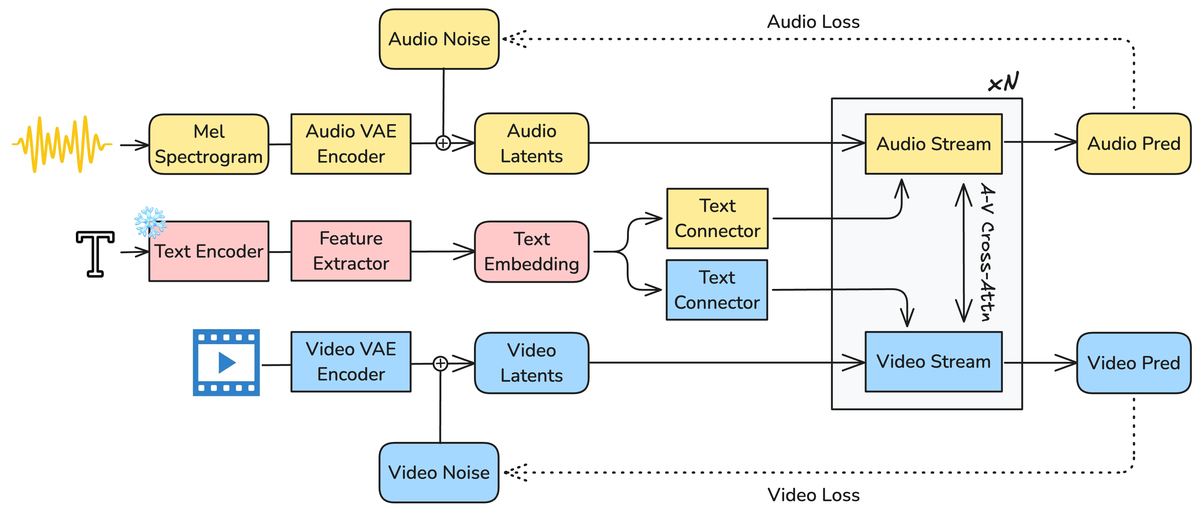
Figure 1 解读:LTX-2 整体架构概览。原始视频和音频信号分别通过各自的 causal VAE 编码为模态特有的 latent tokens。文本通过精细化的 embedding pipeline 处理。双流 diffusion transformer 联合去噪音频和视频 latents,通过双向 cross-attention 和文本 conditioning 进行信息交换,最终生成同步的音视频输出。
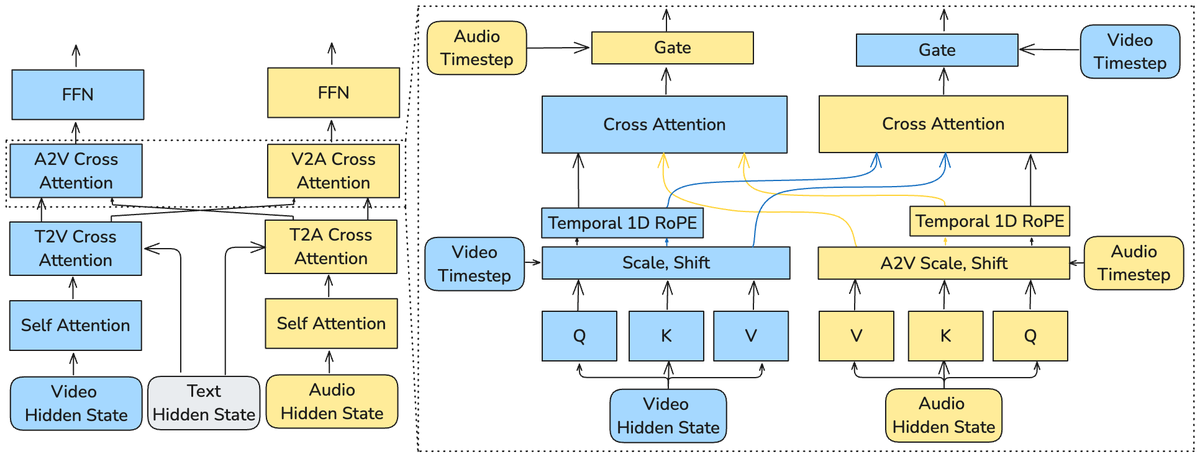
Figure 2 解读:(a) 双流骨干的整体结构——视频和音频流并行处理,通过双向 cross-attention 层交换信息。每个流包含 Self-Attention、Text Cross-Attention (T2V/T2A)、AV Cross-Attention 和 FFN 四个子操作。(b) Cross-Attention block 的详细设计——使用 Temporal 1D RoPE 进行位置对齐,AdaLN 根据各自 timestep 生成 scale/shift 参数来调制 Q 和 (K,V),最终通过门控输出。
3.2 Dual-Stream Transformer Block
每个 dual-stream block 执行四步操作:
- Self-Attention:各模态内部的自注意力,视频流用 3D RoPE ,音频流用 1D RoPE
- Text Cross-Attention:与文本 embedding 的 cross-attention conditioning
- Audio-Visual Cross-Attention:双向——视频 query 关注音频 key/value (A2V),音频 query 关注视频 key/value (V2A)
- Feed-Forward Network (FFN):各模态独立的 MLP 层
所有子层之间穿插 RMS Normalization,并使用 cross-modality AdaLN gates 进行调制。
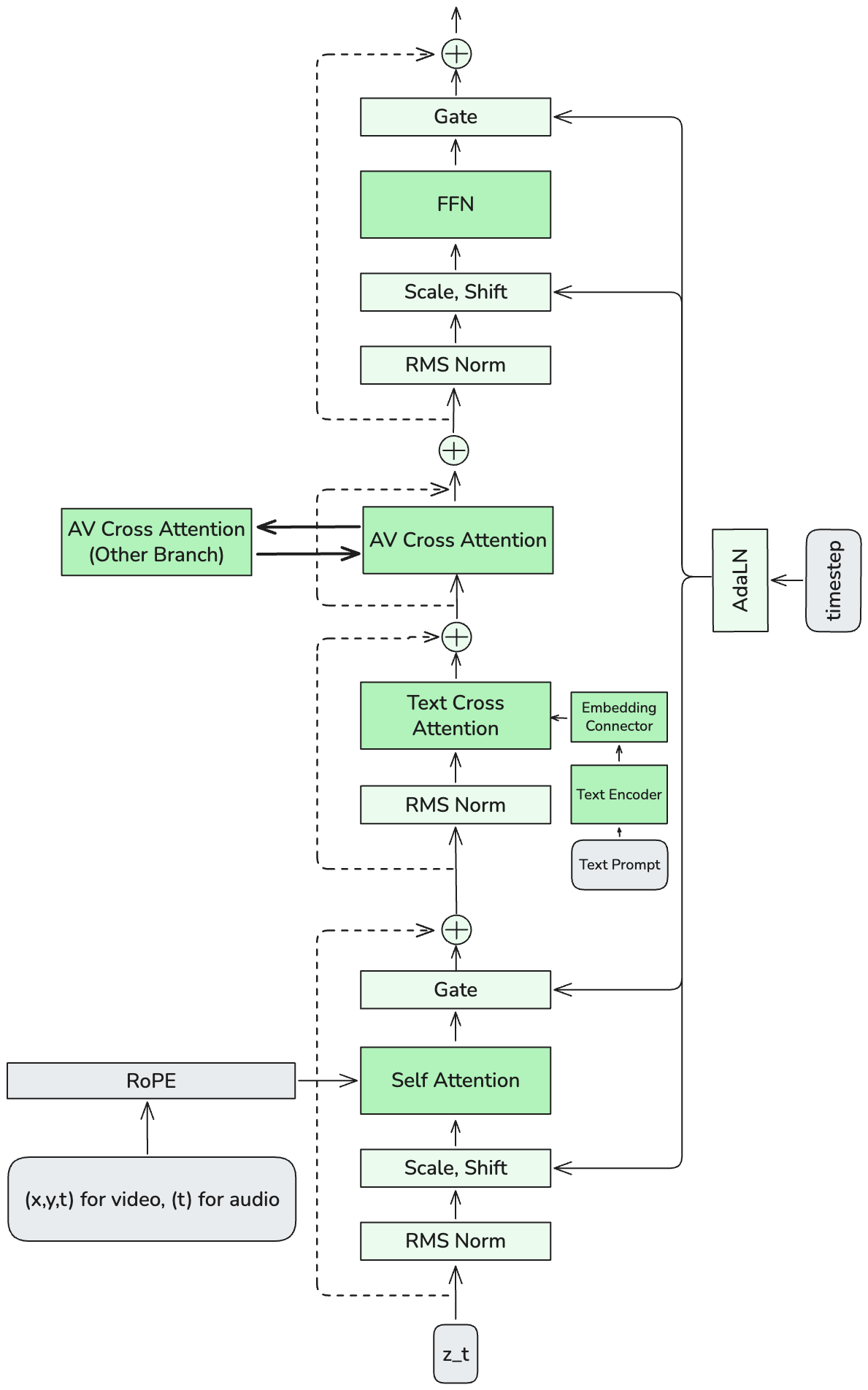
Figure A2 解读:单个流的详细内部结构。从底部输入 latent ,依次经过:RMS Norm → Scale/Shift (AdaLN) → Self-Attention (with RoPE) → Gate → 残差连接 → RMS Norm → Text Cross-Attention → 残差连接 → AV Cross-Attention (从另一个流获取 K,V) → 残差连接 → RMS Norm → Scale/Shift → FFN → Gate → 残差连接 → 输出。AdaLN 的参数由 timestep embedding 生成。
Cross-Modality AdaLN 机制
跨模态 AdaLN 是实现音视频同步的关键。在 AV cross-attention 中,一个模态的 scale/shift 参数由另一个模态的 diffusion timestep 来条件化:
其中 和 是从另一模态的 timestep embedding 通过线性层生成的 scale 和 shift 参数。
Positional Encoding (RoPE)
- 视频流:3D RoPE 沿 三个轴注入位置信息
- 音频流:1D RoPE 仅沿时间维度
- 跨模态交互时:只使用 temporal 分量,确保注意力聚焦于时间同步而非空间对齐
Audio-Visual Cross-Attention 详细流程
在每一层中,视频和音频的 hidden states 通过学习的线性投影转换为 Q, K, V:
- AdaLN modulation(基于当前流的 timestep)分别 scale/shift Q 和 (K, V)
- Temporal RoPE 应用于 Q 和 K,在共享时间轴上对齐
- 标准 cross-attention 计算:视频 Q attend 音频 K/V,反方向亦然
- 输出通过额外的 AdaLN gate(参数依赖另一模态的 timestep)控制跨模态信息融合量

Figure 3 解读:AV cross-attention maps 可视化。左列为 V2A attention(Q=Audio, KV=Video),右列为 A2V attention(Q=Video, KV=Audio)。热力图显示:(1) 汽车经过场景中,模型能空间追踪移动车辆;(2) 说话+鼓掌场景中,注意力在不同声音事件间动态切换;(3) 多人说话场景中,注意力能区分不同说话者并在双人同时说话时同时关注两人;(4) 近景说话时聚焦嘴唇区域。
Pseudocode: Dual-Stream Transformer Block
class DualStreamTransformerBlock:
def forward(self, video_hidden, audio_hidden, text_emb,
video_timestep, audio_timestep):
# 1. Self-Attention (each modality independently)
v_scale, v_shift, v_gate = self.adaln(video_timestep) # video AdaLN params
a_scale, a_shift, a_gate = self.adaln(audio_timestep) # audio AdaLN params
video_norm = rms_norm(video_hidden) * v_scale + v_shift
audio_norm = rms_norm(audio_hidden) * a_scale + a_shift
video_sa = self.video_self_attn(video_norm, rope=rope_3d) # 3D RoPE (x,y,t)
audio_sa = self.audio_self_attn(audio_norm, rope=rope_1d) # 1D RoPE (t)
video_hidden = video_hidden + v_gate * video_sa
audio_hidden = audio_hidden + a_gate * audio_sa
# 2. Text Cross-Attention
video_hidden = video_hidden + self.video_text_cross_attn(
q=rms_norm(video_hidden), kv=text_emb
)
audio_hidden = audio_hidden + self.audio_text_cross_attn(
q=rms_norm(audio_hidden), kv=text_emb
)
# 3. Bidirectional AV Cross-Attention
# Video attends to Audio (A2V direction)
av_v_scale, av_v_shift, av_v_gate = self.av_adaln(audio_timestep)
video_q = rms_norm(video_hidden) * av_v_scale + av_v_shift
a2v_out = cross_attn(q=video_q, kv=audio_hidden, rope=temporal_rope_1d)
video_hidden = video_hidden + av_v_gate * a2v_out
# Audio attends to Video (V2A direction)
av_a_scale, av_a_shift, av_a_gate = self.av_adaln(video_timestep)
audio_q = rms_norm(audio_hidden) * av_a_scale + av_a_shift
v2a_out = cross_attn(q=audio_q, kv=video_hidden, rope=temporal_rope_1d)
audio_hidden = audio_hidden + av_a_gate * v2a_out
# 4. Feed-Forward Network
video_hidden = video_hidden + ffn_gate_v * self.video_ffn(
rms_norm(video_hidden) * ffn_scale_v + ffn_shift_v
)
audio_hidden = audio_hidden + ffn_gate_a * self.audio_ffn(
rms_norm(audio_hidden) * ffn_scale_a + ffn_shift_a
)
return video_hidden, audio_hidden3.3 Deep Text Conditioning and Thinking Tokens
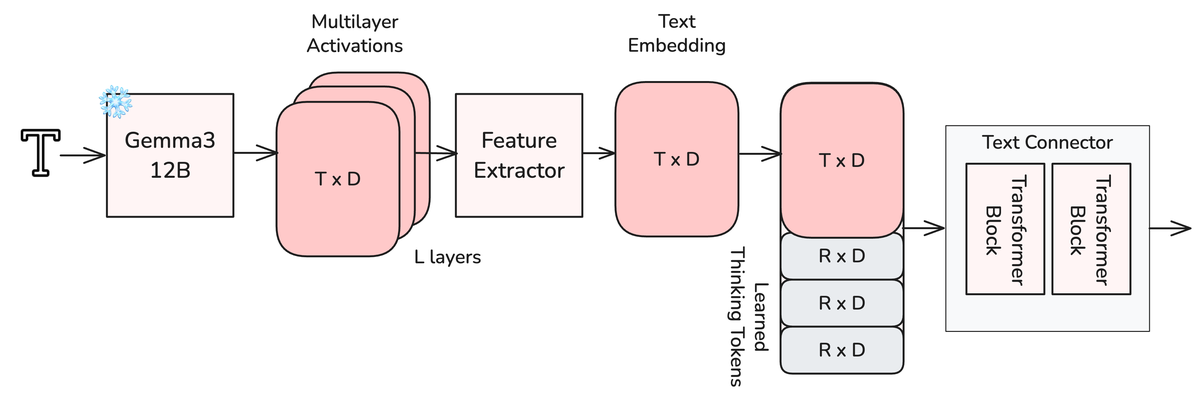
Figure 4 解读:文本理解 pipeline 概览。文本 prompt 通过 Gemma3-12B 编码,提取所有 decoder 层的中间激活 (Multilayer Activations),经 Feature Extractor 投影到统一维度,再与可学习的 Thinking Tokens 拼接后送入 Text Connector(由多个 bidirectional transformer block 组成),最终输出用于条件化 DiT 的文本 embedding。
3.3.1 Multi-Layer Feature Extractor
不依赖 LLM 的最后一层输出,而是从所有 层 decoder 中提取中间表示,捕获从底层语音学到高层语义的层次化信息:
- 对每层输出在 sequence 和 embedding 维度上做 mean-centered scaling
- 将所有层输出 flatten 为
- 通过可学习的投影矩阵 投影回目标维度 :
投影矩阵 在初始训练阶段与 LTX-2 模型联合优化(使用 MSE loss),之后冻结。LLM 权重始终保持冻结。
3.3.2 Text Connector with Thinking Tokens
Text Connector 由多个具有完全双向注意力的 transformer blocks 组成:
- 接收 Feature Extractor 的输出 embedding
- 在输入 token 后附加可学习的 Thinking Tokens,替换 padding 位置
- Thinking Tokens 作为全局信息载体,聚合上下文信息和缺失细节
- 每个模态(视频/音频)有独立的 Text Connector
- Text Connector 与主 DiT blocks 一同训练
Pseudocode: Text Conditioning Pipeline
class TextConditioningPipeline:
def __init__(self, num_layers, hidden_dim, num_thinking_tokens):
self.text_encoder = Gemma3_12B(frozen=True)
self.projection = nn.Linear(hidden_dim * num_layers, hidden_dim)
self.thinking_tokens = nn.Parameter(
torch.randn(num_thinking_tokens, hidden_dim)
)
self.video_connector = TransformerBlocks(bidirectional=True)
self.audio_connector = TransformerBlocks(bidirectional=True)
def extract_features(self, text_tokens):
# Extract all decoder layer activations [B, T, D, L]
all_layer_outputs = self.text_encoder.get_all_layers(text_tokens)
# Mean-centered scaling per layer
for i in range(num_layers):
h = all_layer_outputs[:, :, :, i]
mean = h.mean(dim=(1, 2), keepdim=True)
all_layer_outputs[:, :, :, i] = h - mean
# Flatten and project: [B, T, D*L] -> [B, T, D]
flat = all_layer_outputs.flatten(start_dim=2) # [B, T, D*L]
text_emb = self.projection(flat) # [B, T, D]
return text_emb
def forward(self, text_tokens, modality="video"):
text_emb = self.extract_features(text_tokens) # [B, T, D]
# Append thinking tokens (replace padding)
thinking = self.thinking_tokens.expand(B, -1, -1) # [B, R, D]
combined = torch.cat([text_emb, thinking], dim=1) # [B, T+R, D]
# Process through bidirectional transformer
if modality == "video":
output = self.video_connector(combined)
else:
output = self.audio_connector(combined)
return output # [B, T+R, D]3.4 Audio VAE and Latent Space
音频 VAE 采用紧凑的 latent 表示,灵感来自 LTX-Video 的 deep latent space:
- 输入:立体声波形 → 16 kHz 采样率 → 双通道 mel spectrogram → 沿 channel 维度拼接
- 编码器:causal audio autoencoder,包含下采样块、残差连接、注意力机制
- 输出 latent:每个 token 对应约 秒音频,表示为 128 维特征向量
- 解码器:对称架构重建 mel spectrogram
3.4.1 Vocoder
基于 HiFi-GAN 架构,改造用于立体声合成和上采样:
- 输入:双通道 mel spectrogram(16 kHz 计算,每个立体声通道一个)
- 输出:24 kHz 立体声波形
- 为适应立体声建模复杂度,generator 通道数相比原始 HiFi-GAN V1 翻倍
Pseudocode: Audio VAE
class AudioVAE:
def encode(self, waveform):
# waveform: [B, 2, T_audio] stereo at 16kHz
mel_left = compute_mel_spectrogram(waveform[:, 0]) # [B, n_mels, T_mel]
mel_right = compute_mel_spectrogram(waveform[:, 1]) # [B, n_mels, T_mel]
mel_stereo = torch.cat([mel_left, mel_right], dim=1) # [B, 2*n_mels, T_mel]
# Causal encoder with downsampling
latent = self.encoder(mel_stereo) # [B, 128, T_latent]
latent = self.normalize(latent) # per-channel statistics norm
return latent # each token ~ 1/25 sec, 128-dim
def decode(self, latent):
latent = self.denormalize(latent)
mel_recon = self.decoder(latent) # [B, 2*n_mels, T_mel]
waveform = self.vocoder(mel_recon) # HiFi-GAN: 16kHz mel -> 24kHz stereo
return waveform # [B, 2, T_audio_24k]3.5 Modality-Aware Classifier-Free Guidance (Bimodal CFG)
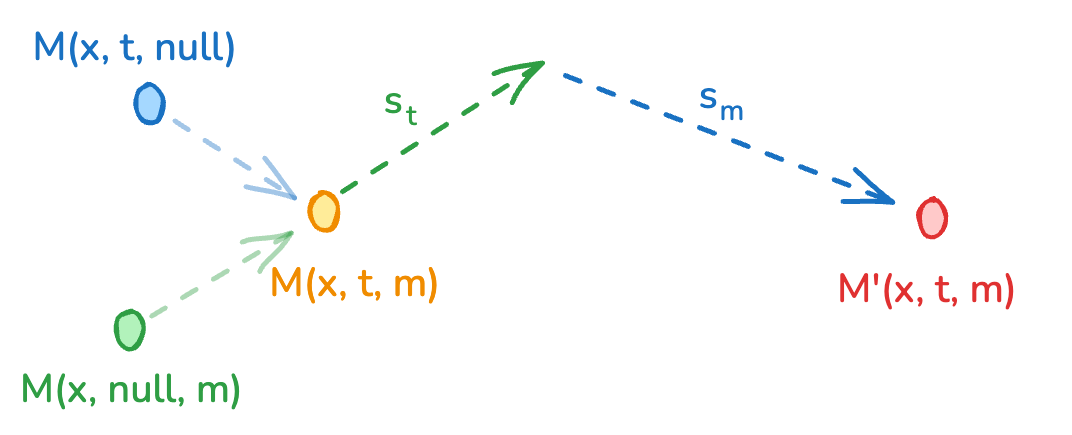
Figure 5 解读:多模态 Classifier-Free Guidance 示意图。引导预测(红色点)由完全条件化的模型输出(橙色点)加上两个独立的引导方向构成:文本引导项(绿色,强度 )和跨模态引导项(蓝色,强度 )。这支持在推理时独立控制文本 conditioning 和跨模态对齐强度。
标准 CFG 仅包含文本 guidance。LTX-2 扩展为 Bimodal CFG,引入额外的跨模态 guidance 项:
其中:
- :当前模态的 latent
- :文本条件
- :互补模态的特征
- :文本引导强度
- :跨模态引导强度
- :去掉文本条件的预测
- :去掉跨模态条件的预测
默认参数设置:
- 视频流:,
- 音频流:,
增大 可促进模态间的互信息,改善时间同步和语义一致性。
Pseudocode: Bimodal CFG
def bimodal_cfg(model, x, text_cond, cross_modal_feat, s_t, s_m):
# Full conditional prediction
pred_full = model(x, text=text_cond, cross_modal=cross_modal_feat)
# Text-unconditional prediction (drop text)
pred_no_text = model(x, text=None, cross_modal=cross_modal_feat)
# Cross-modal-unconditional prediction (drop other modality)
pred_no_cross = model(x, text=text_cond, cross_modal=None)
# Bimodal guided prediction
guided = (
pred_full
+ s_t * (pred_full - pred_no_text)
+ s_m * (pred_full - pred_no_cross)
)
return guided3.6 Multi-Scale, Multi-Tile Inference
为在不超出 GPU 显存的情况下生成 Full HD (1080p) 内容,采用三阶段推理策略:
- Base Generation:在低分辨率(约 0.5 MP)生成 “base” latent,建立全局场景构成、运动和音视频同步基础
- Latent Upscaling:专用 latent upscaler 提升视频 latent 的空间分辨率,保持时间一致性和听觉对齐
- Tiled Refinement:将高分辨率 latent 划分为重叠的时空 tile,各 tile 独立精细化(使用同一基础模型参数),然后在 latent space 中混合以确保无缝过渡,最后进行 VAE 解码
3.7 Training Pipeline
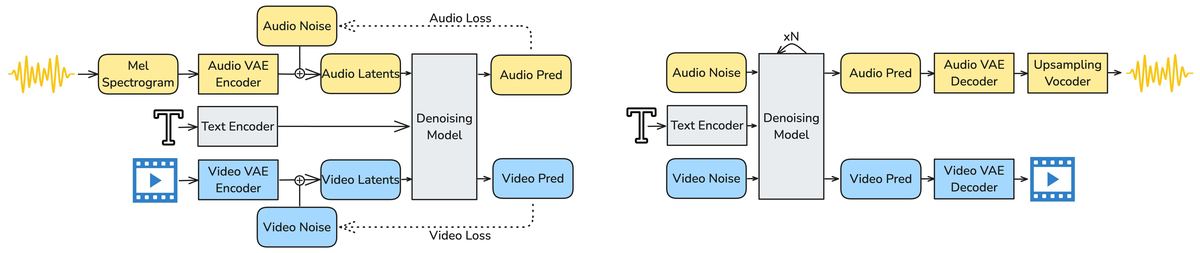
Figure A1 解读:(a) 训练 pipeline:音频和视频输入编码为 latents,模型训练目标是使用 flow-matching loss 匹配 velocity fields。(b) 推理 pipeline:从音频和视频 latent space 中的噪声出发,模型迭代去噪 步,VAE 解码器和上采样 vocoder 重建最终波形和视频。
训练数据使用 LTX-Video 数据集的子集,聚焦于包含显著且信息丰富的音频成分的视频片段。训练了专用的视频 captioning 系统,同时详细描述视觉和听觉信息(包括音乐、环境音、对话转录、说话者语言和口音识别等)。
Code-to-Paper Mapping Table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| Dual-Stream Transformer Block | packages/ltx-core/src/ltx_core/model/transformer/transformer.py | BasicAVTransformerBlock |
| Self-Attention & Cross-Attention | packages/ltx-core/src/ltx_core/model/transformer/attention.py | Attention, apply_rotary_emb |
| AdaLN / Cross-Modality AdaLN | packages/ltx-core/src/ltx_core/model/transformer/adaln.py | AdaLayerNormSingle, adaln_embedding_coefficient |
| RoPE (3D/1D) | packages/ltx-core/src/ltx_core/model/transformer/rope.py | generate_freqs, apply_rotary_emb |
| Text Caption Projection | packages/ltx-core/src/ltx_core/model/transformer/text_projection.py | PixArtAlphaTextProjection, create_caption_projection |
| Modality Handling | packages/ltx-core/src/ltx_core/model/transformer/modality.py | Modality enum/config |
| Model Configuration | packages/ltx-core/src/ltx_core/model/transformer/model_configurator.py | Model config builder |
| Audio VAE Encoder/Decoder | packages/ltx-core/src/ltx_core/model/audio_vae/audio_vae.py | AudioEncoder, AudioDecoder, encode_audio, decode_audio |
| Vocoder (HiFi-GAN) | packages/ltx-core/src/ltx_core/model/audio_vae/vocoder.py | Vocoder |
| Video VAE | packages/ltx-core/src/ltx_core/model/video_vae/video_vae.py | Video VAE encoder/decoder |
| T2V Inference Pipeline | packages/ltx-pipelines/src/ltx_pipelines/ti2vid_one_stage.py | One-stage T2V pipeline |
| Two-Stage Inference | packages/ltx-pipelines/src/ltx_pipelines/ti2vid_two_stages.py | Two-stage T2V pipeline |
| Training Loop | packages/ltx-trainer/src/ltx_trainer/trainer.py | Training orchestration |
4. Experimental Setup (实验设置)
评估维度
LTX-2 在三个关键维度进行评估:
- 音视频质量 (Audiovisual Quality):联合生成质量
- 纯视频性能 (Video-Only Benchmarks):作为视频生成模型的独立表现
- 推理性能与可扩展性 (Inference Performance):计算效率
评估方法
- 音视频评估:human preference study,参与者基于视觉真实感、音频保真度和时间同步(唇同步、拟音准确性)进行评价
- 纯视频评估:Artificial Analysis 公开排行榜
- 推理速度:在 NVIDIA H100 GPU 上对比每个 diffusion step 的耗时
对比模型
- 开源:Ovi, Wan 2.2-14B
- 闭源:Veo 3 (Google DeepMind), Sora 2 (OpenAI), Sora 2 Pro, Wan 2.5
模型规格
| 配置 | 参数 |
|---|---|
| 视频流参数量 | 14B |
| 音频流参数量 | 5B (论文 conclusion 中说 3B) |
| 总参数量 | 19B |
| 文本编码器 | Gemma3-12B (frozen) |
| Audio VAE latent 维度 | 128-dim, ~1/25 sec/token |
| 推理 benchmark 设置 | 121 frames, 720p, single-step Euler solver, CFG=1 |
| 最大生成时长 | 20 秒连续视频 + 同步立体声音频 |
5. Experimental Results (实验结果)
5.1 Audiovisual Evaluation (音视频质量)
- LTX-2 显著优于开源音视频模型(如 Ovi)
- 达到与闭源领先模型(Veo 3, Sora 2)相当的 human preference scores
- 确立为开源统一音视频合成的最佳基础模型
5.2 Video-Only Benchmarks (纯视频)
在 Artificial Analysis 公开排行榜(截至 2025.11.6):
- Image-to-Video: 第 3 名
- Text-to-Video: 第 4 名
- 超过 Sora 2 Pro 和 Wan 2.2-14B 等大模型
- 证明联合训练策略和架构设计不会损害视觉质量
5.3 Inference Performance (推理速度)
Table 1: Inference Speed (H100 GPU, per diffusion step)
| Model | Modality | Params | Sec/Step |
|---|---|---|---|
| Wan 2.2-14B | Video Only | 14B | 22.30s |
| LTX-2 | Audio + Video | 19B | 1.22s |
核心结论:
- LTX-2 比 Wan 2.2 快约 18x,尽管 LTX-2 同时生成音频和视频
- 得益于优化的 latent space 机制,在更高分辨率和更长时长下性能差距进一步扩大
- 由于非对称设计,LTX-2 也比使用两个 Wan 2.2-5B 流的 Ovi 更快
5.4 Temporal Scope (时间范围)
LTX-2 可生成最长 20 秒连续视频 + 同步立体声音频,超过:
- Veo 3: 12s
- Sora 2: 16s
- Ovi: 10s
- Wan 2.5: 10s
5.5 Limitations (局限性)
- 低资源语言/方言的语音准确度和音视频对齐较弱
- 多说话者场景中可能混淆角色对话分配
- 超过约 20 秒后可能出现 temporal drift、同步退化或场景多样性下降
- 作为生成式扩散模型,不具备显式推理或 world-modeling 能力