Improving Joint Audio-Video Generation with Cross-Modal Context Learning
论文:Improving Joint Audio-Video Generation with Cross-Modal Context Learning
说明:根据当前检索结果,论文未提供官方 GitHub 或项目页,公开网络中也未检索到可确认的官方/非官方实现。因此下文中的 pseudocode 依据论文方法描述编写,并在代码映射处明确标注“代码搜索未找到开源实现”。
1. Motivation (研究动机)
当前 joint audio-video generation 的主流做法,是在预训练 video diffusion model 和 audio diffusion model 之上,采用 dual-stream transformer,并通过 bidirectional cross-attention 让音频流与视频流交换信息。这条路线已经能生成高质量、时序同步的 audio-video 内容,但论文指出其中仍有三类核心瓶颈。
第一,现有方法常用 gating mechanism 控制是否开启跨模态交互。对于 text/image-to-video、text-to-audio、audio-to-video、video-to-audio、joint audio-video 等多任务训练来说,gate 的开关会让优化目标在参数空间中形成 piecewise structure。这样相邻 step 的梯度方向会频繁变化,训练不稳定,收敛慢,最终限制生成质量。
第二,常规 cross-modal attention 容易在 background region 上学出错误的 positional bias。论文对 Ovi 的注意力可视化发现:背景 video token 会对某个 audio token 产生非语义性的高注意力,背景 audio token 也会对图像中的随机位置产生异常聚焦。也就是说,模型并没有真正学到 foreground-level 的跨模态对应,而是在大量无关区域中消耗学习能力,导致语义混淆和训练效率下降。
第三,multi-modal classifier-free guidance (CFG) 在训练与推理之间存在不一致。已有方法要么直接把另一模态 drop 掉作为 unconditional condition,要么使用手工构造的 static video / silent audio 作为 unconditional representation。这些 unconditional 信号不属于训练分布,且通常需要额外 forward pass,既带来分布偏移,也增加推理开销。同时,text control 与 cross-modal control 之间还会互相冲突,特别是在 audio stream 中,过强的 video-side guidance 可能损害 audio quality。
因此,这篇论文的目标不是重新设计整个生成框架,而是在保留 dual-stream transformer 范式的前提下,系统性修复其训练不稳定、跨模态对齐差、CFG 不一致这三类关键问题。这个问题值得研究,因为 joint audio-video generation 已经成为多模态生成的重要方向,而更好的同步性、可控性和更低训练成本,对学术研究与工业应用都很关键。
2. Idea (核心思想)
论文提出 Cross-Modal Context Learning (CCL)。核心思想是:不要让两种模态直接在大范围 token 上粗暴交互,而是先通过更合理的时序对齐与局部窗口约束缩小搜索空间,再引入一组可学习的跨模态 context token 作为稳定锚点,让 background token 有“默认落点”,最后用动态路由与新的 unconditional guidance 保证多任务训练和推理的一致性。
一句话概括,CCL 的创新在于把“跨模态交互”从直接、稀疏、容易失稳的 token-to-token 匹配,改成了 局部时序对齐 + context anchor + task-aware routing + train-inference consistent guidance 的组合设计。
与已有方法的根本区别在于:它不再依赖 gate 在不同任务间切换交互路径,也不再把 unconditional modality 简单地视为“缺失的模态”,而是通过 Learnable Context Tokens 学出稳定的 unconditional / context support,从而同时提升训练收敛和推理表现。
3. Method (方法)
3.1 Overall framework
CCL 整体仍然是 dual-stream transformer。video 被 3D VAE 压缩到 latent space,audio 先转成 Mel-spectrogram,再用 audio VAE 压缩成 1D latent。之后两条流都经过若干 transformer block,每个 block 包含:self-attention、text cross-attention、Temporally Aligned RoPE and Partitioning (TARP)、Cross-Modal Context Attention (CCA)、FFN。
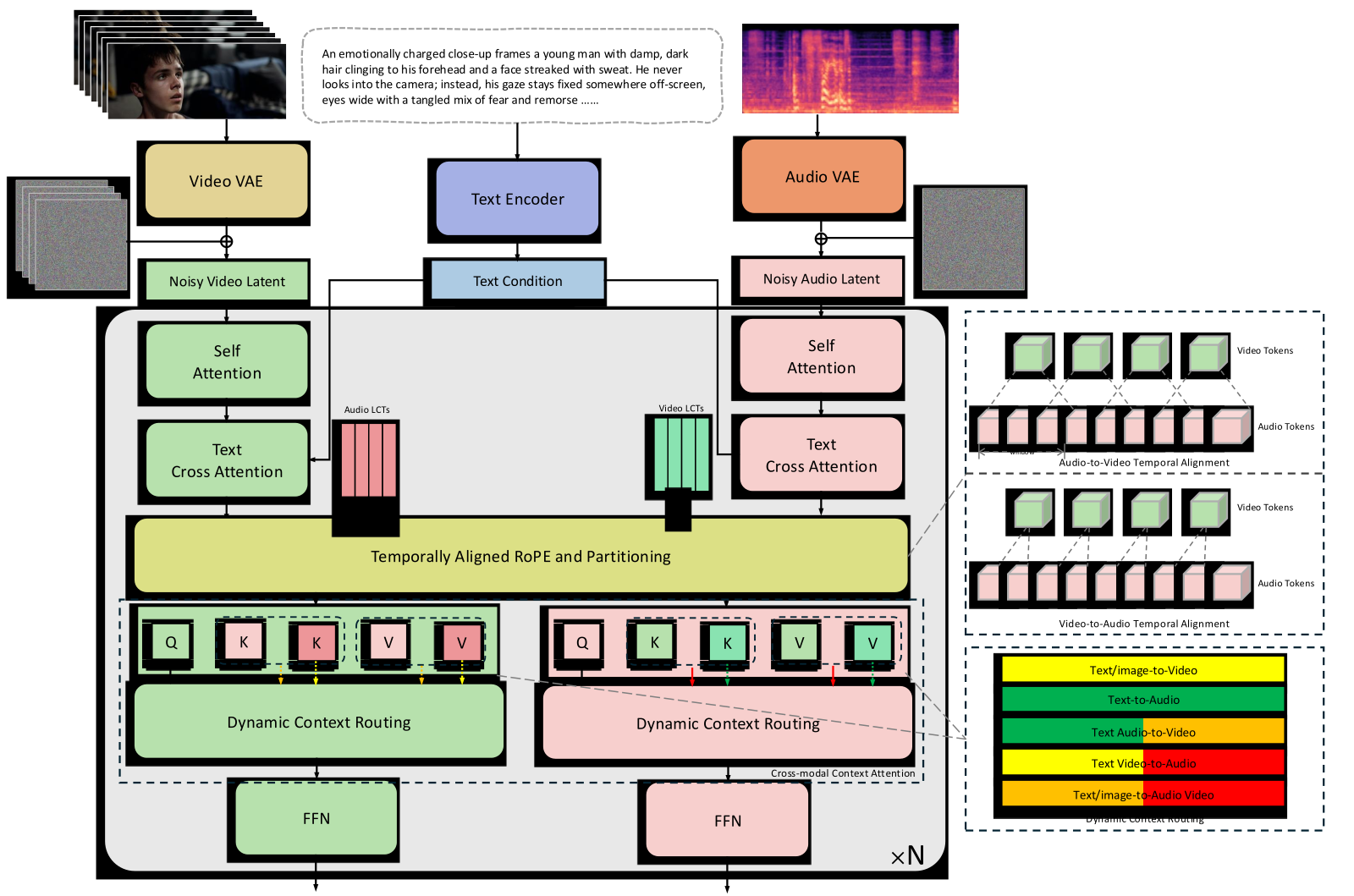
Figure 4 解读: 这张图给出了论文的完整 pipeline。左上是 video branch:Noisy Video Latent 经由 self-attention、text cross-attention 后进入跨模态交互模块;左下是 audio branch:Noisy Audio Latent 也走一套对称结构。中间部分是 CCL 的三个关键设计:首先,TARP 对 audio 和 video token 做时间轴上的 RoPE 对齐,并对 cross-attention 施加 local temporal window;其次,CCA 在原始跨模态 attention 之外加入 Audio LCTs 和 Video LCTs;最后,Dynamic Context Routing 根据训练任务决定当前 block 中哪些 path 被激活。图中不同颜色对应不同任务下的路由模式,这说明 CCL 并不是始终让所有跨模态连接全开,而是按任务动态选择。整体上,Figure 4 说明论文方法的关键不在 backbone 本身,而在跨模态交互方式的重新设计。
形式化地,论文定义 audio latent 为:
video latent 为:
其中 是 batch size, 是 audio token 数, 是 video 时间维 token 数, 是 video latent 的空间分辨率, 分别是 audio/video stream 的 hidden dimension。
由于 ,CCA 中要通过 QKV projection 对齐维度,得到:
3.2 Revisiting the dual-stream transformer limitations
论文在提出 CCL 之前,先分析了现有 dual-stream transformer 的问题来源。
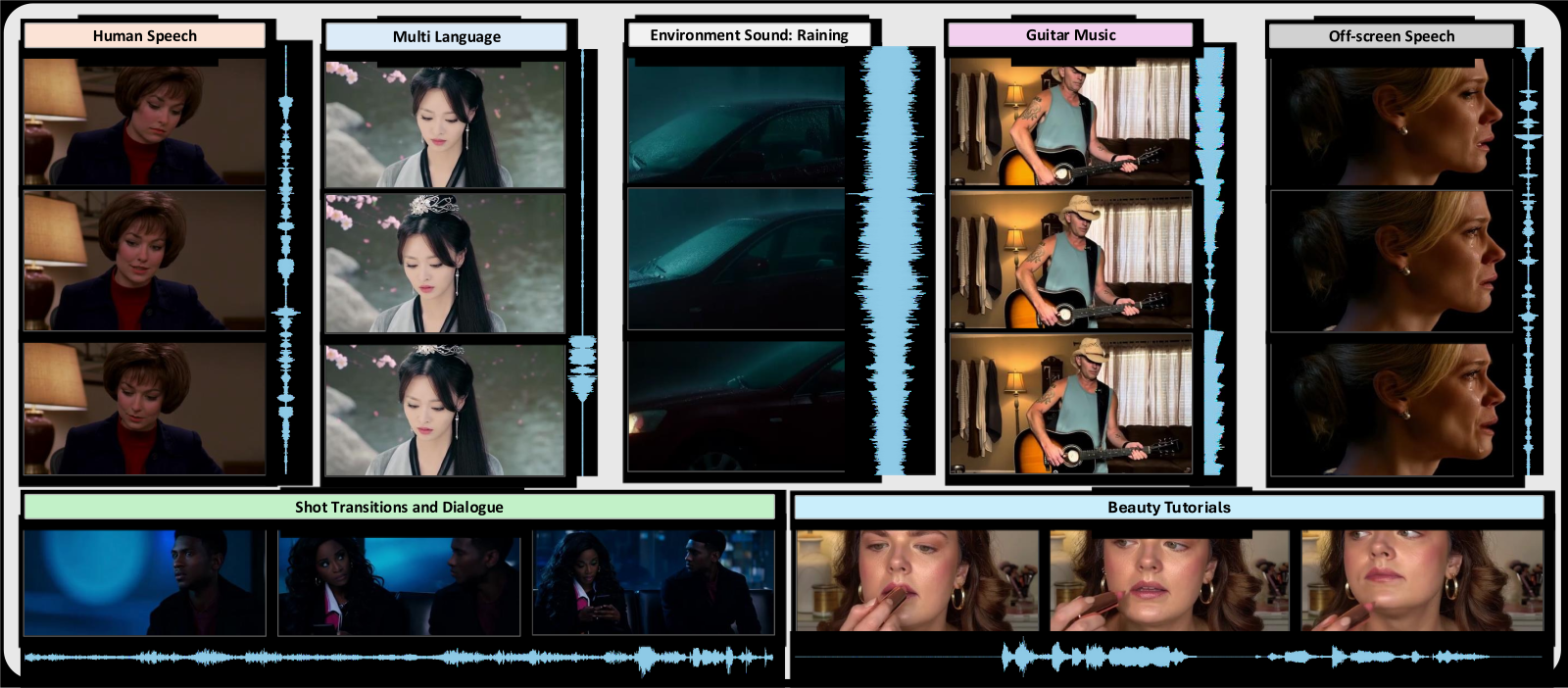
Figure 1 解读: Figure 1 展示了 CCL 的应用能力,包括 multilingual human speech、environmental sound、music generation、background speech、shot transition 和 dialogue generation 等。它的作用更多是展示模型能力边界,而不是直接解释方法结构。论文把这张图放在前面,是为了说明 joint audio-video generation 不只是在 talking head 之类的窄场景里有意义,而是能覆盖更广泛的真实视频生成任务。
传统 gating mechanism 可以写成:
其中 控制是否引入另一模态的信息。
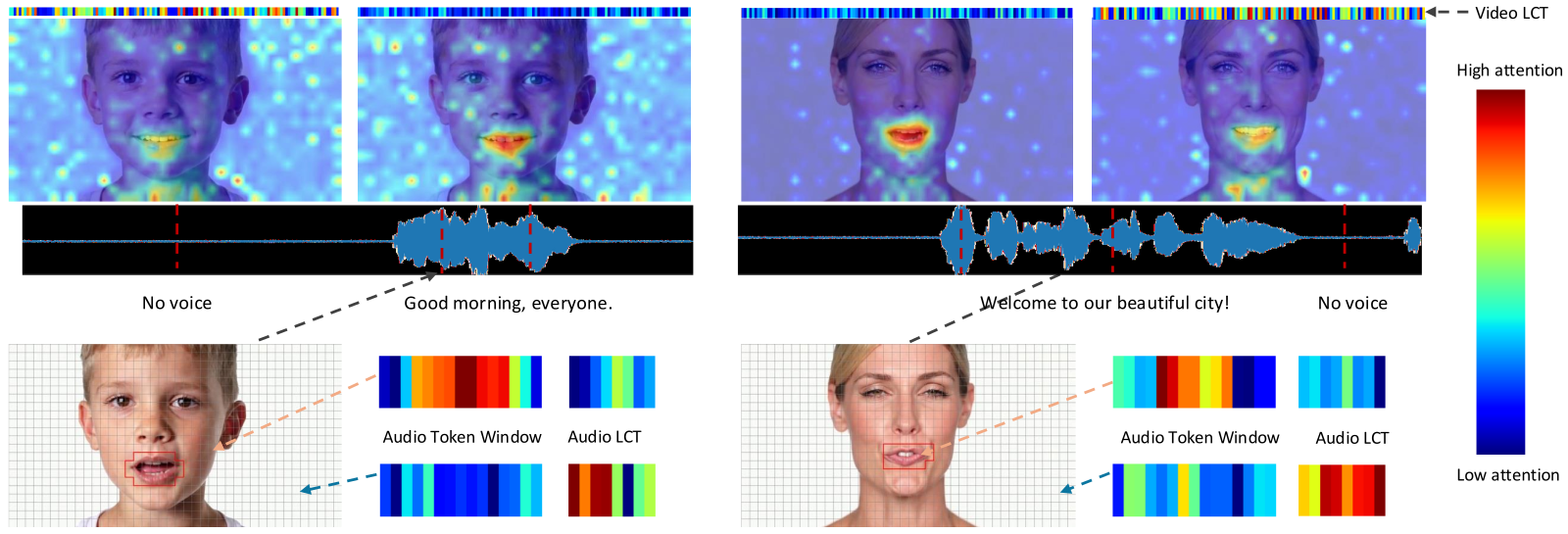
Figure 2 解读: 这张预览图的左半部分对应论文中的 Figure 2,用来说明 gating mechanism 会如何改变优化目标。作者的核心观点是:在多任务训练里,gate 的开关会让同一组参数在不同 step 面对不连续的目标面,导致梯度方向不稳定。Figure 2 的意义不是给出精确公式,而是用示意方式说明“gate 切换会扰乱优化过程”,这也是后续用 DCR 替代硬 gate 的直接动机。
Figure 3 解读: 这张预览图的右半部分对应论文中的 Figure 3,展示 Ovi 的 cross-modal attention 可视化。可以看到,background audio/video token 会对与语义无关的位置产生异常高注意力,说明模型并没有把注意力稳定地集中在真正的跨模态对应区域,而是在背景上学出了偏置模式。论文借助 Figure 3 论证:现有方法的问题不是容量不足,而是跨模态交互机制本身容易引入噪声与语义错配。
3.3 TARP: Temporally Aligned RoPE and Partitioning
TARP 的目标是解决 audio 与 video token 在时间轴上的错位问题,并进一步把 cross-modal attention 限制在局部时间窗口内,降低优化难度。
由于 与 不一致,若对 audio/video latent 直接套标准 RoPE,位置编码与真实时间位置并不对齐。论文对 audio 侧 query / key 的索引做缩放:
video 侧则保留标准 RoPE:
随后,论文引入 partitioning。令:
表示每个 video frame 对应的严格对齐 audio latent token 数。对于第 个 video frame,窗口中心为:
论文在 audio-to-video 方向设置窗口大小:
即 video token 只在一个局部 audio token window 上做跨模态 attention,而不是对整个 audio 序列全局检索。对 video-to-audio 方向,由于论文认为 audio 对 video 的时间敏感性更弱,因此直接设定 ,相当于 nearest-neighbor 对齐。
这样做的效果有两个:
- 时间位置对齐更准确;
- 搜索空间更小,模型更容易学到局部同步而不是全局噪声匹配。
3.4 CCA: Cross-Modal Context Attention
CCA 是论文的核心模块,它建立在普通 bidirectional cross-attention 上,但额外引入了 Learnable Context Tokens (LCT) 和 Dynamic Context Routing (DCR)。
3.4.1 Learnable Context Tokens (LCT)
论文为每个 audio-to-video CCA block 引入 audio context token:
为每个 video-to-audio CCA block 引入 video context token:
其中 是 LCT 数量。
LCT 经过 KV projection 后,与来自另一模态的局部 token window 拼接:
然后做跨模态 attention:
这里的关键在于:LCT 不带 RoPE,因为它被视为 temporal-insensitive 的 context anchor。论文希望它们学到“另一模态的稳定平均表示”,使当前模态中与跨模态无关的 background token 可以优先去关注这些 LCT,而不是被迫在另一模态的所有真实 token 中寻找不存在的对应项。
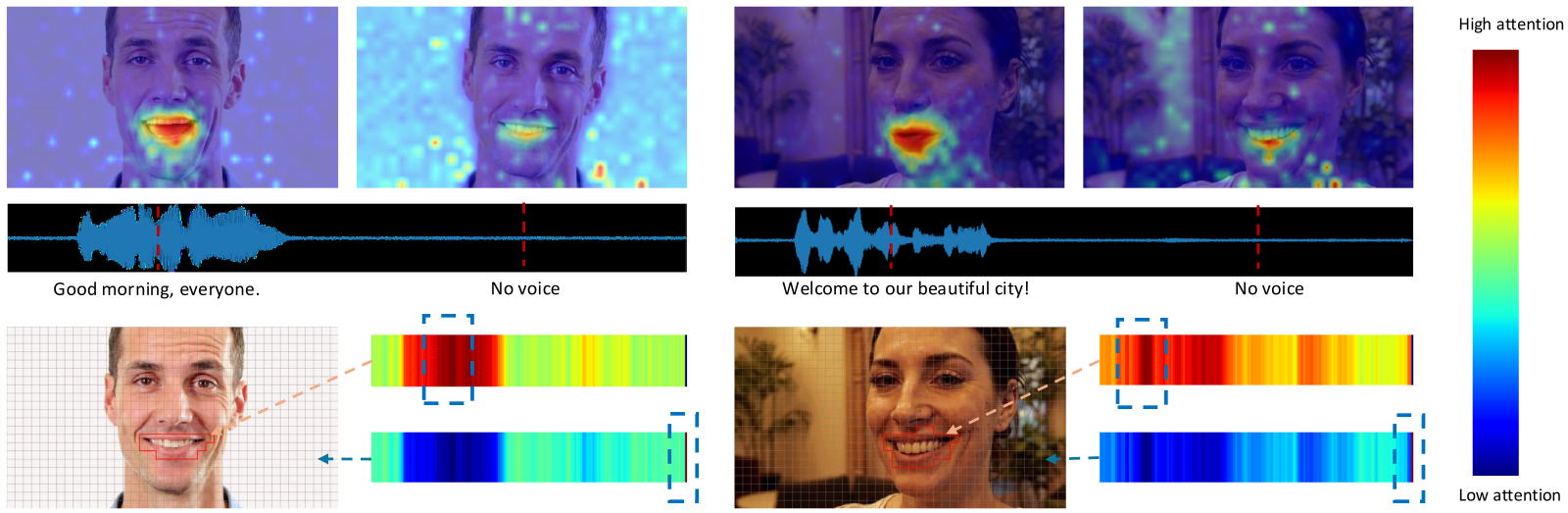
Figure 6 解读: Figure 6 展示了 CCL 学到的 attention map。与 Figure 3 中 Ovi 的异常 attention 相比,这里 background audio / video token 更倾向于关注 LCT,而不是随机的另一模态 token。这说明 LCT 起到了“背景锚点”的作用,把 foreground-level 的精细对齐与 background-level 的默认承载分开了,从而减少了语义错配。
3.4.2 Dynamic Context Routing (DCR)
DCR 用于替代 gating mechanism。核心想法是,不同任务下 CCA 的 key / value 组成不同,但这种变化不是通过硬 gate 对 cross-modal attention 做乘法开关,而是通过改变输入给 CCA 的 context 组成来实现。
论文考虑 5 类训练任务:
- text/image-to-video
- text-to-audio
- audio-to-video
- video-to-audio
- joint audio-video generation
DCR 规则如下:
- text/image-to-video 与 text-to-audio:CCA 仅与本 block 对应的 LCT 交互,不接入另一模态 latent。两条流互不影响。
- audio-to-video:audio stream timestep 设为 0。audio stream 只和 video LCT 交互,不和真实 video latent 交互;video stream 同时与 audio LCT 和 audio latent 交互。
- video-to-audio:video stream timestep 设为 0。video stream 只和 audio LCT 交互;audio stream 同时与 video LCT 和 video latent 交互。
- joint audio-video generation:两条流 timestep 同步,双方都同时接收对方 LCT 与真实 latent。
这种设计的好处是,模型在多任务训练中始终保留稳定的 context representation,不再因为 gate 在不同任务上 0/1 切换而产生激烈的目标变化。
3.5 UCG: Unconditional Context Guidance
UCG 的关键观察是:LCT 在训练后天然学成了稳定的 unconditional representation,因此可以拿来替代传统 multi-modal CFG 中“缺失模态”或“手工构造静态模态”的 unconditional condition。
若使用两次推理完成 guidance,论文给出:
其中 是当前模态 guidance scale, 表示当前模态对应的 LCT。
如果要解耦 text control 与 cross-modal control,则使用三次推理版本:
相比传统做法,UCG 有三点优势:
- unconditional information 与训练分布更一致;
- 避免额外手工先验;
- 缓解 text condition 与 cross-modal condition 的冲突,特别是 audio stream 中的冲突。
3.6 Multi-task training objective
论文用 flow matching 训练生成目标,并为不同任务设置不同 loss 组合:
其中在 audio-to-video 与 video-to-audio 中,reference stream 的梯度会被 detach,防止 timestep 为 0 的 reference branch 被过优化并产生异常行为。
3.7 Pseudocode
由于未检索到公开代码,下面 pseudocode 基于论文方法说明编写,尽量贴近 PyTorch 风格实现。
3.7.1 TARP
import torch
def temporal_aligned_partition(q_audio, k_audio, v_audio, q_video, k_video, v_video, t_a, t_v, h, w):
"""
q_audio: [B, t_a, d_a]
k_audio, v_audio: [B, t_a, d_v]
q_video: [B, t_v*h*w, d_v]
k_video, v_video: [B, t_v*h*w, d_a]
"""
scale = t_v / t_a
q_audio_rope = apply_rope(q_audio, position_scale=scale)
k_audio_rope = apply_rope(k_audio, position_scale=scale)
q_video_rope = apply_rope(q_video, position_scale=1.0)
k_video_rope = apply_rope(k_video, position_scale=1.0)
c = max(t_a // t_v, 1)
video_window = 3 * c
audio_windows_k = []
audio_windows_v = []
for i in range(t_v):
center = c // 2 + c * i
start = max(center - video_window // 2, 0)
end = min(start + video_window, t_a)
audio_windows_k.append(k_audio_rope[:, start:end])
audio_windows_v.append(v_audio[:, start:end])
audio_windows_k = pad_and_stack(audio_windows_k) # [B*t_v, s, d_v]
audio_windows_v = pad_and_stack(audio_windows_v) # [B*t_v, s, d_v]
video_nn_k = nearest_neighbor_temporal_pick(k_video_rope, t_a, t_v, h, w)
video_nn_v = nearest_neighbor_temporal_pick(v_video, t_a, t_v, h, w)
return {
"q_audio": q_audio_rope,
"k_audio_local": audio_windows_k,
"v_audio_local": audio_windows_v,
"q_video": q_video_rope,
"k_video_local": video_nn_k,
"v_video_local": video_nn_v,
}3.7.2 CCA with LCT
import torch
import torch.nn as nn
class CrossModalContextAttention(nn.Module):
def __init__(self, d_audio, d_video, n_audio_lct=8, n_video_lct=128):
super().__init__()
self.audio_lct = nn.Parameter(torch.randn(n_audio_lct, d_video))
self.video_lct = nn.Parameter(torch.randn(n_video_lct, d_audio))
self.audio_lct_k = nn.Linear(d_video, d_video)
self.audio_lct_v = nn.Linear(d_video, d_video)
self.video_lct_k = nn.Linear(d_audio, d_audio)
self.video_lct_v = nn.Linear(d_audio, d_audio)
def forward(self, q_audio, q_video, k_audio_local, v_audio_local, k_video_local, v_video_local):
B = q_audio.shape[0]
t_v = k_audio_local.shape[0] // B
t_a = k_video_local.shape[0] // B
audio_lct_k = self.audio_lct_k(self.audio_lct).unsqueeze(0).repeat(B * t_v, 1, 1)
audio_lct_v = self.audio_lct_v(self.audio_lct).unsqueeze(0).repeat(B * t_v, 1, 1)
video_lct_k = self.video_lct_k(self.video_lct).unsqueeze(0).repeat(B * t_a, 1, 1)
video_lct_v = self.video_lct_v(self.video_lct).unsqueeze(0).repeat(B * t_a, 1, 1)
k_for_video = torch.cat([k_audio_local, audio_lct_k], dim=1)
v_for_video = torch.cat([v_audio_local, audio_lct_v], dim=1)
k_for_audio = torch.cat([k_video_local, video_lct_k], dim=1)
v_for_audio = torch.cat([v_video_local, video_lct_v], dim=1)
out_audio = attention(q_audio, k_for_audio, v_for_audio)
out_video = attention(q_video, k_for_video, v_for_video)
return out_audio, out_video3.7.3 Dynamic Context Routing
def route_context(task, audio_latent, video_latent, audio_lct, video_lct):
if task in {"text_to_audio", "text_image_to_video"}:
return {
"audio_context": [video_lct],
"video_context": [audio_lct],
}
if task == "audio_to_video":
return {
"audio_context": [video_lct],
"video_context": [audio_lct, audio_latent],
}
if task == "video_to_audio":
return {
"audio_context": [video_lct, video_latent],
"video_context": [audio_lct],
}
if task == "joint_audio_video":
return {
"audio_context": [video_lct, video_latent],
"video_context": [audio_lct, audio_latent],
}
raise ValueError(f"Unknown task: {task}")3.7.4 UCG inference
def ucg_two_pass(model, x_t, t, uc_text, c_text, c_modal, modal_lct, s_modal):
uncond = model(x_t, t, text=uc_text, modal=modal_lct)
cond = model(x_t, t, text=c_text, modal=c_modal)
guided = uncond + s_modal * (cond - uncond)
return guided
def ucg_three_pass(model, x_t, t, uc_text, c_text, c_modal, modal_lct, s_text, s_modal):
base = model(x_t, t, text=uc_text, modal=modal_lct)
text_guided = model(x_t, t, text=c_text, modal=modal_lct)
modal_guided = model(x_t, t, text=uc_text, modal=c_modal)
guided = base + s_text * (text_guided - base) + s_modal * (modal_guided - base)
return guided3.8 Code-to-paper mapping table
| Paper Concept | Source File | Key Class/Function |
|---|---|---|
| CCL overall pipeline | 代码搜索未找到开源实现 | 未知 |
| TARP | 代码搜索未找到开源实现 | 未知 |
| CCA | 代码搜索未找到开源实现 | 未知 |
| Learnable Context Tokens (LCT) | 代码搜索未找到开源实现 | 未知 |
| Dynamic Context Routing (DCR) | 代码搜索未找到开源实现 | 未知 |
| Unconditional Context Guidance (UCG) | 代码搜索未找到开源实现 | 未知 |
| Multi-task training / flow matching | 代码搜索未找到开源实现 | 未知 |
4. Experimental Setup (实验设置)
4.1 Datasets
论文构建了一个 million-level audio-video pairs 的 joint training dataset,其中包含公开数据集 OpenHumanVid 以及额外的 in-house collections,来源包括 interviews、short dramas、films 等。为了预训练 audio diffusion model,还使用了学术音频数据集 WavCaps 与 VGGSound。
4.2 Backbone and training pipeline
- Video diffusion stream 初始化:使用 Wan2.1-14B 参数。
- Audio diffusion stream:与 video stream 架构相同,但 channel number 更小,以提高 parameter efficiency。
- CCA integration:在网络每个 block 中加入一个 CCA module。
- Training stages:
- audio diffusion pretraining
- joint audio-video training
4.3 Hyperparameters
Audio pretraining stage
- learning rate:
- training steps: 160,000
- batch size: 3200
Joint audio-video training
- cross-modal attention parameters learning rate:
- all other parameters learning rate:
Ablation phase
- steps: 6000
- batch size: 128
Final setting
- batch size: 320
- training steps: 12,000
- audio LCT number
- video LCT number
- multi-task sampling probabilities:
- text/image-to-audio/video: 0.1
- audio-to-video: 0.15
- video-to-audio: 0.15
- joint audio-video generation: 0.6
- resolution:
4.4 Evaluation metrics
论文构建了一个 200-sample test set,保证与训练集无重叠。每个样本包含一张 image 和一个同时描述 video content 与 audio content 的 prompt。测试集分为:
- easy subset:portrait / upper-body shot,人物静止
- hard subset:full-body,包含 body movement
评估维度分为三类:
-
Audio Quality
- CU (Content Usefulness)
- PQ (Production Quality)
- WER (Whisper-large-v3)
-
Lip Sync
- Sync-C
- Sync-D (通过 SyncNet 计算)
-
AV-Alignment
- DeSync(Synchformer)
- IB / IB-Score(ImageBind)
论文分别在 easy/hard subset 上报告 Lip Sync 和 AV-Alignment,Audio Quality 则汇报两个 subset 的平均分。
5. Experimental Results (实验结果)
5.1 Main comparison results
Figure 5 解读: Figure 5 对比了使用传统 gating mechanism 与使用 CCL 时的 training loss 下降曲线。图中可以看到,CCL 的 loss 下降更快、更平滑,说明它让优化过程更稳定,也更容易更早进入低 loss 区域。论文强调这里只可视化了 joint audio-video generation task 的 loss,并且使用了 EMA 平滑,因此重点是展示训练稳定性趋势,而不是绝对 loss 数值。
表 1 比较了 CCL 与 Ovi、LTX-2、MOVA:
| Method | Data | CU↑ | PQ↑ | WER↓ | Sync-C easy↑ | Sync-D easy↓ | Sync-C hard↑ | Sync-D hard↓ | DeSync easy↓ | IB easy↑ | DeSync hard↓ | IB hard↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ovi | 30.7M | 5.88 | 6.14 | 17.51% | 8.47 | 7.32 | 5.96 | 8.57 | 1.11 | 0.20 | 1.18 | 0.21 |
| LTX-2 | - | 5.12 | 5.35 | 11.04% | 7.67 | 7.90 | 5.47 | 8.93 | 1.18 | 0.19 | 1.20 | 0.21 |
| MOVA | 50M | 6.34 | 7.24 | 8.09% | 7.79 | 7.70 | 5.38 | 8.87 | 1.15 | 0.20 | 1.22 | 0.19 |
| CCL | 4M | 5.71 | 6.42 | 4.62% | 8.45 | 7.48 | 6.12 | 8.25 | 1.11 | 0.23 | 1.19 | 0.22 |
从结果看:
- Audio quality:MOVA 在 CU/PQ 上最高,但 CCL 的 WER 最好,仅 4.62%,相比 MOVA 的 8.09% 低 3.47 个百分点。
- Lip sync:CCL 在 easy set 的 Sync-C 略低于 Ovi(8.45 vs 8.47),但其余 lip-sync 指标最好,尤其 hard set 上显著领先。
- AV alignment:CCL 在 easy set 的 IB 达到 0.23,优于其他方法;DeSync 也整体处于最优或并列最优水平。
- Data efficiency:最值得注意的是,CCL 只用了 4M 数据,而 Ovi 和 MOVA 分别是 30.7M / 50M,说明方法改进带来了明显的数据效率收益。
5.2 Ablation study
表 2 的消融结果如下:
| TARP | LCT/DCR | UCG | SyncCFG [20] | WER↓ | Sync-C↑ | Sync-D↓ | DeSync↓ | IB↑ |
|---|---|---|---|---|---|---|---|---|
| 4.52% | 4.53 | 10.81 | 1.20 | 0.20 | ||||
| ✓ | 4.67% | 5.05 | 10.17 | 1.20 | 0.20 | |||
| ✓ | ✓ | 4.81% | 5.62 | 9.12 | 1.18 | 0.21 | ||
| ✓ | ✓ | ✓ | 4.63% | 6.14 | 8.09 | 1.16 | 0.22 | |
| ✓ | ✓ | ✓ | ✓ | 5.59% | 5.85 | 8.46 | 1.18 | 0.20 |
论文对这些结果的解读是:
- TARP 提升了收敛效率,Sync-C 从 4.53 提升到 5.05,Sync-D 从 10.81 降到 10.17。
- LCT + DCR 替代 gating 后带来更显著提升,说明稳定的 context anchor 与动态路由确实改善了优化难度。
- UCG 进一步改善 lip sync 与 AV alignment:Sync-C 提升 0.52,Sync-D 降低 1.03,DeSync 降低 0.02,IB 提升 0.01。
- 将 SyncCFG 的 static-unconditional 设计接入后,所有指标都有小幅下降,说明 UCG 不仅更高效,而且 unconditional representation 的质量更高。
5.3 Qualitative findings
从 Figure 1 与 Figure 6 可以总结出两个 qualitative 结论:
- CCL 可以覆盖多语言 speech、ambient sound、music、dialogue 等更复杂的场景,不只是 talking head。
- 背景 token 向 LCT 聚焦,说明模型在内部建立了“背景信息的稳定承载位”,减少了跨模态语义错配。
5.4 Limitations
论文没有单独列出限制章节,但从内容中可以推断出几项潜在限制:
- 方法仍然依赖 dual-stream transformer backbone,并没有解决 backbone 自身的规模和计算成本问题。
- Video diffusion stream 直接初始化自 Wan2.1-14B,仍然需要强大的预训练基础模型支撑。
- 论文使用了 in-house million-level dataset,公开复现门槛较高。
- 当前尚无公开代码,实际工程细节与复现成本仍不透明。
5.5 Overall conclusion
这篇论文的价值在于:它不是简单在现有 joint audio-video generation 框架上加一个更复杂的 attention,而是把问题拆成了三个层面——时间对齐、上下文锚点、训练/推理一致性——分别给出结构化解决方案。最终结果表明,CCL 在只用 4M 数据的情况下,达到了比近期方法更好的整体效果,尤其在 WER、hard subset lip-sync 和 AV alignment 上表现突出。
从研究角度看,最有启发性的地方是 Learnable Context Tokens + Dynamic Context Routing + UCG 这条路线:它把“无条件信息”从人为 drop 掉模态,变成模型内部学出的稳定 context representation,这个思想不仅适用于 audio-video generation,也可能迁移到更广泛的多模态 joint generation 和 agent memory / context routing 场景中。